 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AQuaMoHo: Localized Low-Cost Outdoor Air Quality Sensing over a Thermo-Hygrometer
Apr 25, 2022


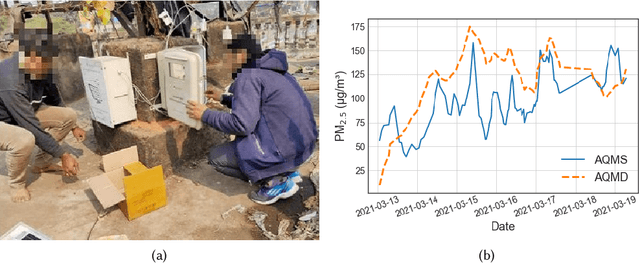
Efficient air quality sensing serves as one of the essential services provided in any recent smart city. Mostly facilitated by sparsely deployed Air Quality Monitoring Stations (AQMSs) that are difficult to install and maintain, the overall spatial variation heavily impacts air quality monitoring for locations far enough from these pre-deployed public infrastructures. To mitigate this, we in this paper propose a framework named AQuaMoHo that can annotate data obtained from a low-cost thermo-hygrometer (as the sole physical sensing device) with the AQI labels, with the help of additional publicly crawled Spatio-temporal information of that locality. At its core, AQuaMoHo exploits the temporal patterns from a set of readily available spatial features using an LSTM-based model and further enhances the overall quality of the annotation using temporal attention. From a thorough study of two different cities, we observe that AQuaMoHo can significantly help annotate the air quality data on a personal scale.
TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models
Apr 29, 2022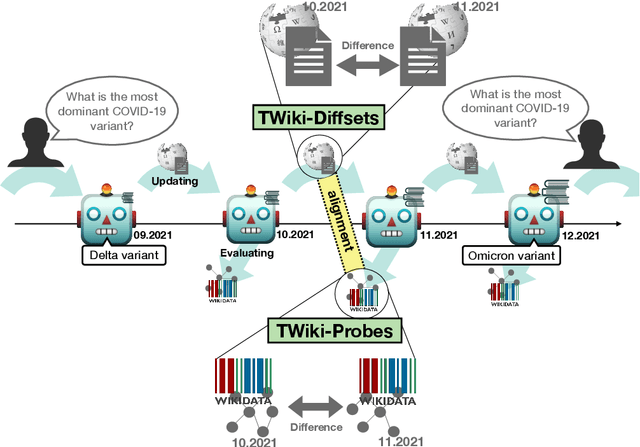

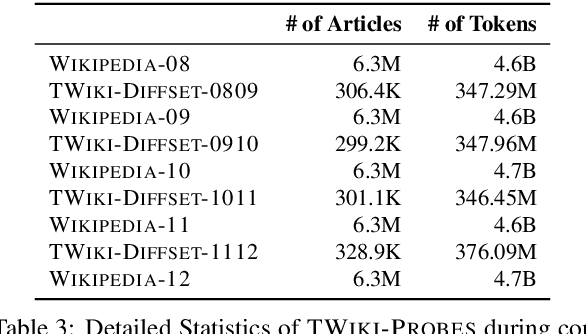
Language Models (LMs) become outdated as the world changes; they often fail to perform tasks requiring recent factual information which was absent or different during training, a phenomenon called temporal misalignment. This is especially a challenging problem because the research community still lacks a coherent dataset for assessing the adaptability of LMs to frequently-updated knowledge corpus such as Wikipedia. To this end, we introduce TemporalWiki, a lifelong benchmark for ever-evolving LMs that utilizes the difference between consecutive snapshots of English Wikipedia and English Wikidata for training and evaluation, respectively. The benchmark hence allows researchers to periodically track an LM's ability to retain previous knowledge and acquire updated/new knowledge at each point in time. We also find that training an LM on the diff data through continual learning methods achieves similar or better perplexity than on the entire snapshot in our benchmark with 12 times less computational cost, which verifies that factual knowledge in LMs can be safely updated with minimal training data via continual learning. The dataset and the code are available at https://github.com/joeljang/temporalwiki .
Challenges for Open-domain Targeted Sentiment Analysis
Apr 15, 2022
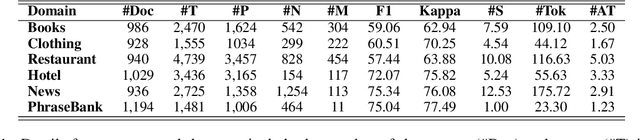
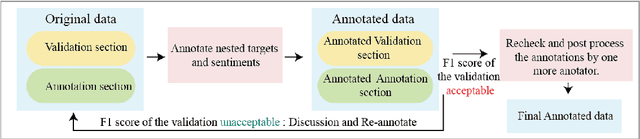
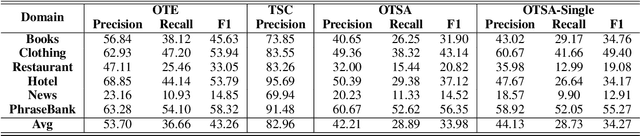
Since previous studies on open-domain targeted sentiment analysis are limited in dataset domain variety and sentence level, we propose a novel dataset consisting of 6,013 human-labeled data to extend the data domains in topics of interest and document level. Furthermore, we offer a nested target annotation schema to extract the complete sentiment information in documents, boosting the practicality and effectiveness of open-domain targeted sentiment analysis. Moreover, we leverage the pre-trained model BART in a sequence-to-sequence generation method for the task. Benchmark results show that there exists large room for improvement of open-domain targeted sentiment analysis. Meanwhile, experiments have shown that challenges remain in the effective use of open-domain data, long documents, the complexity of target structure, and domain variances.
A Unifying Framework for Some Directed Distances in Statistics
Mar 02, 2022Density-based directed distances -- particularly known as divergences -- between probability distributions are widely used in statistics as well as in the adjacent research fields of information theory, artificial intelligence and machine learning. Prominent examples are the Kullback-Leibler information distance (relative entropy) which e.g. is closely connected to the omnipresent maximum likelihood estimation method, and Pearson's chisquare-distance which e.g. is used for the celebrated chisquare goodness-of-fit test. Another line of statistical inference is built upon distribution-function-based divergences such as e.g. the prominent (weighted versions of) Cramer-von Mises test statistics respectively Anderson-Darling test statistics which are frequently applied for goodness-of-fit investigations; some more recent methods deal with (other kinds of) cumulative paired divergences and closely related concepts. In this paper, we provide a general framework which covers in particular both the above-mentioned density-based and distribution-function-based divergence approaches; the dissimilarity of quantiles respectively of other statistical functionals will be included as well. From this framework, we structurally extract numerous classical and also state-of-the-art (including new) procedures. Furthermore, we deduce new concepts of dependence between random variables, as alternatives to the celebrated mutual information. Some variational representations are discussed, too.
Super-resolved multi-temporal segmentation with deep permutation-invariant networks
Apr 06, 2022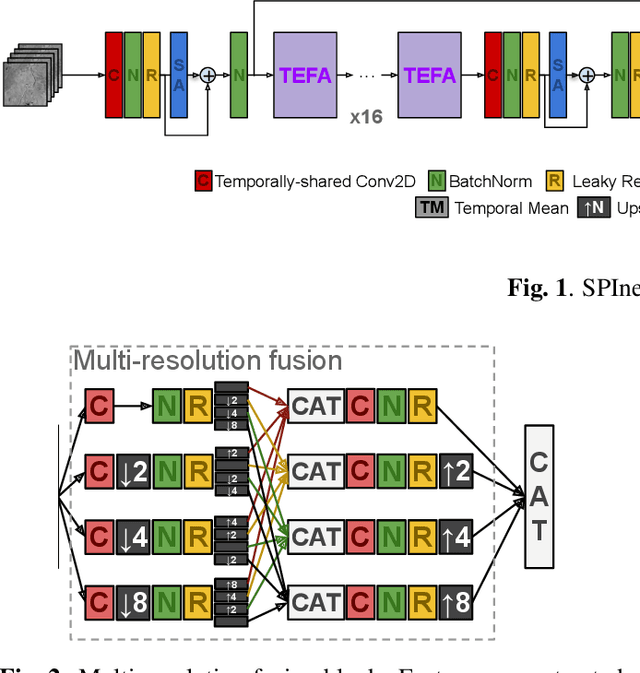
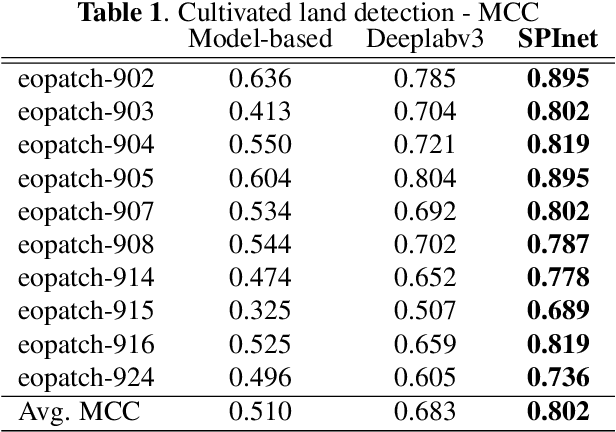


Multi-image super-resolution from multi-temporal satellite acquisitions of a scene has recently enjoyed great success thanks to new deep learning models. In this paper, we go beyond classic image reconstruction at a higher resolution by studying a super-resolved inference problem, namely semantic segmentation at a spatial resolution higher than the one of sensing platform. We expand upon recently proposed models exploiting temporal permutation invariance with a multi-resolution fusion module able to infer the rich semantic information needed by the segmentation task. The model presented in this paper has recently won the AI4EO challenge on Enhanced Sentinel 2 Agriculture.
Graph Fusion Network for Multi-Oriented Object Detection
May 07, 2022
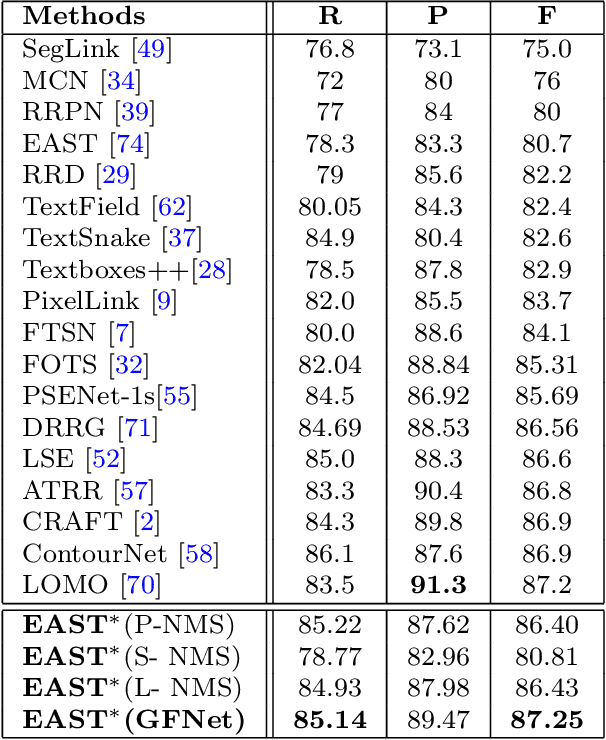
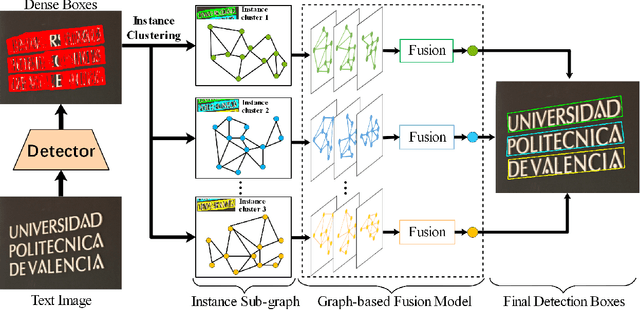
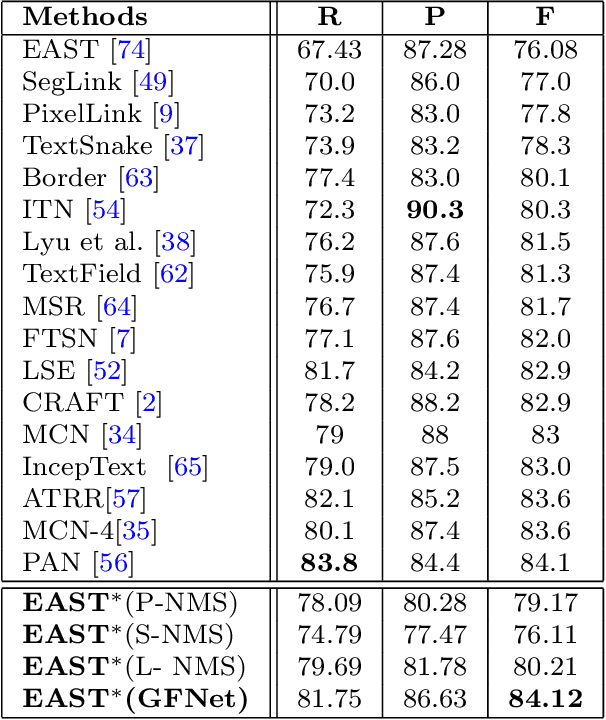
In object detection, non-maximum suppression (NMS) methods are extensively adopted to remove horizontal duplicates of detected dense boxes for generating final object instances. However, due to the degraded quality of dense detection boxes and not explicit exploration of the context information, existing NMS methods via simple intersection-over-union (IoU) metrics tend to underperform on multi-oriented and long-size objects detection. Distinguishing with general NMS methods via duplicate removal, we propose a novel graph fusion network, named GFNet, for multi-oriented object detection. Our GFNet is extensible and adaptively fuse dense detection boxes to detect more accurate and holistic multi-oriented object instances. Specifically, we first adopt a locality-aware clustering algorithm to group dense detection boxes into different clusters. We will construct an instance sub-graph for the detection boxes belonging to one cluster. Then, we propose a graph-based fusion network via Graph Convolutional Network (GCN) to learn to reason and fuse the detection boxes for generating final instance boxes. Extensive experiments both on public available multi-oriented text datasets (including MSRA-TD500, ICDAR2015, ICDAR2017-MLT) and multi-oriented object datasets (DOTA) verify the effectiveness and robustness of our method against general NMS methods in multi-oriented object detection.
CSI2Image: Image Reconstruction from Channel State Information Using Generative Adversarial Networks
Sep 16, 2020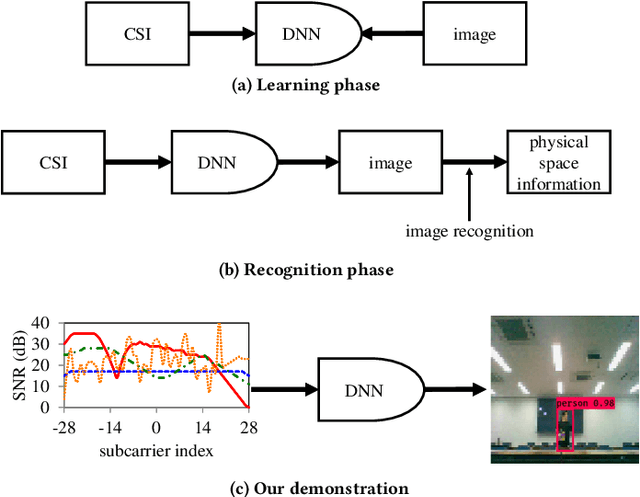

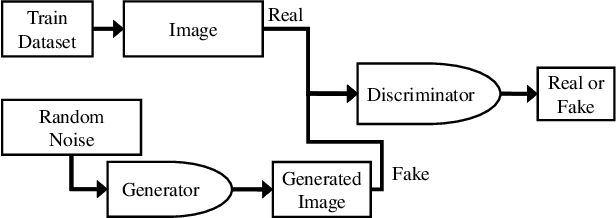

This study aims to find the upper limit of the wireless sensing capability of acquiring physical space information. This is a challenging objective, because at present, wireless sensing studies continue to succeed in acquiring novel phenomena. Thus, although a complete answer cannot be obtained yet, a step is taken towards it here. To achieve this, CSI2Image, a novel channel-state-information (CSI)-to-image conversion method based on generative adversarial networks (GANs), is proposed. The type of physical information acquired using wireless sensing can be estimated by checking wheth\-er the reconstructed image captures the desired physical space information. Three types of learning methods are demonstrated: gen\-er\-a\-tor-only learning, GAN-only learning, and hybrid learning. Evaluating the performance of CSI2Image is difficult, because both the clarity of the image and the presence of the desired physical space information must be evaluated. To solve this problem, a quantitative evaluation methodology using an object detection library is also proposed. CSI2Image was implemented using IEEE 802.11ac compressed CSI, and the evaluation results show that the image was successfully reconstructed. The results demonstrate that gen\-er\-a\-tor-only learning is sufficient for simple wireless sensing problems, but in complex wireless sensing problems, GANs are important for reconstructing generalized images with more accurate physical space information.
Neural Compression-Based Feature Learning for Video Restoration
Mar 18, 2022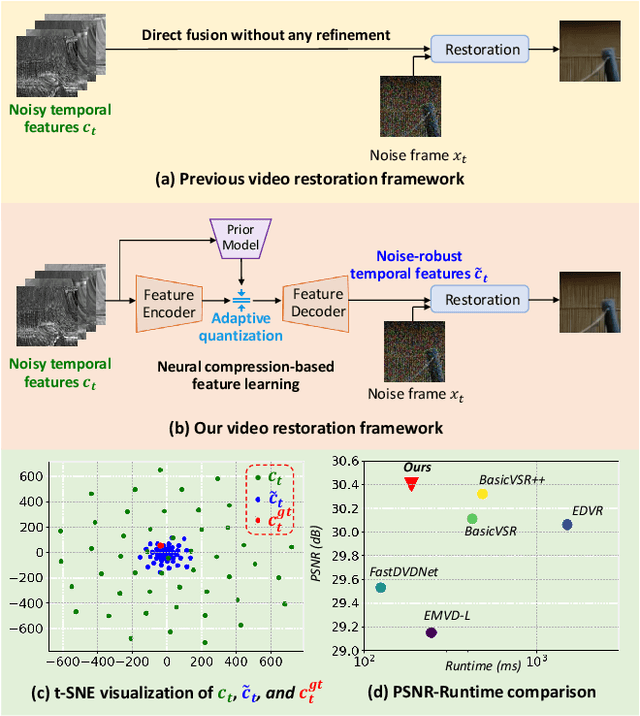



How to efficiently utilize the temporal features is crucial, yet challenging, for video restoration. The temporal features usually contain various noisy and uncorrelated information, and they may interfere with the restoration of the current frame. This paper proposes learning noise-robust feature representations to help video restoration. We are inspired by that the neural codec is a natural denoiser. In neural codec, the noisy and uncorrelated contents which are hard to predict but cost lots of bits are more inclined to be discarded for bitrate saving. Therefore, we design a neural compression module to filter the noise and keep the most useful information in features for video restoration. To achieve robustness to noise, our compression module adopts a spatial channel-wise quantization mechanism to adaptively determine the quantization step size for each position in the latent. Experiments show that our method can significantly boost the performance on video denoising, where we obtain 0.13 dB improvement over BasicVSR++ with only 0.23x FLOPs. Meanwhile, our method also obtains SOTA results on video deraining and dehazing.
A Framework for Event-based Computer Vision on a Mobile Device
May 13, 2022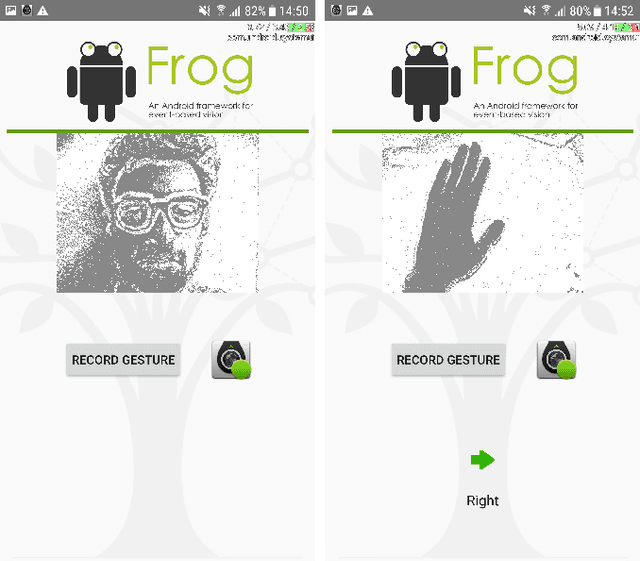
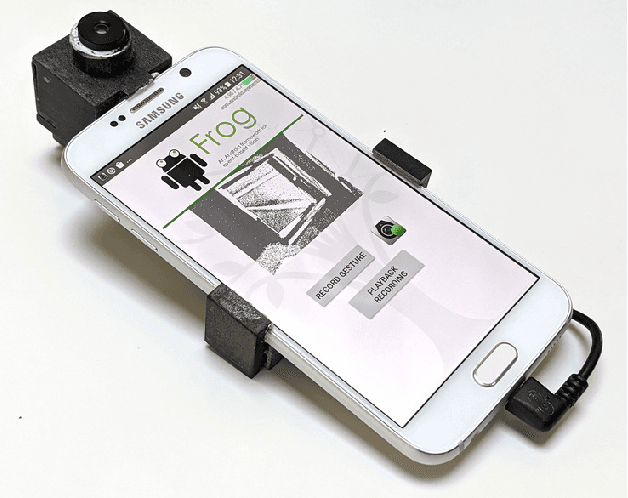
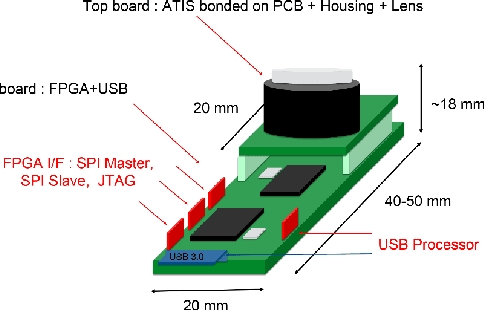
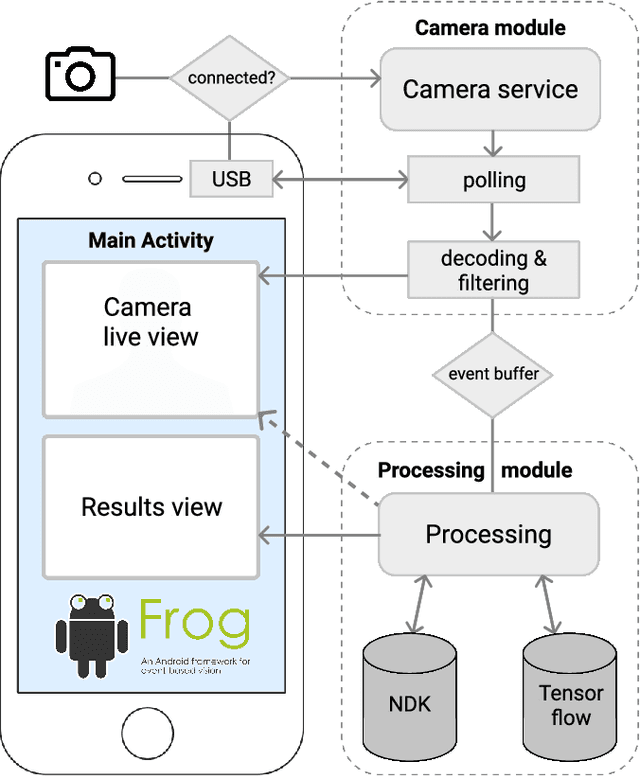
We present the first publicly available Android framework to stream data from an event camera directly to a mobile phone. Today's mobile devices handle a wider range of workloads than ever before and they incorporate a growing gamut of sensors that make devices smarter, more user friendly and secure. Conventional cameras in particular play a central role in such tasks, but they cannot record continuously, as the amount of redundant information recorded is costly to process. Bio-inspired event cameras on the other hand only record changes in a visual scene and have shown promising low-power applications that specifically suit mobile tasks such as face detection, gesture recognition or gaze tracking. Our prototype device is the first step towards embedding such an event camera into a battery-powered handheld device. The mobile framework allows us to stream events in real-time and opens up the possibilities for always-on and on-demand sensing on mobile phones. To liaise the asynchronous event camera output with synchronous von Neumann hardware, we look at how buffering events and processing them in batches can benefit mobile applications. We evaluate our framework in terms of latency and throughput and show examples of computer vision tasks that involve both event-by-event and pre-trained neural network methods for gesture recognition, aperture robust optical flow and grey-level image reconstruction from events. The code is available at https://github.com/neuromorphic-paris/frog
Financial data analysis application via multi-strategy text processing
Apr 25, 2022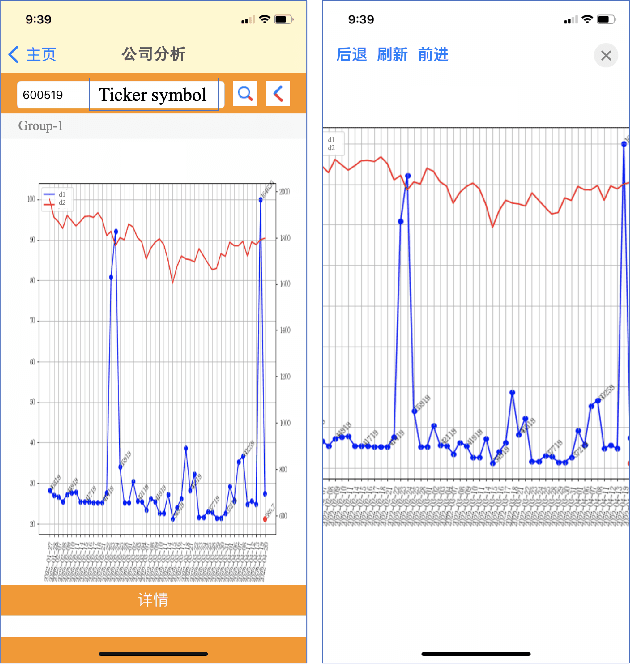
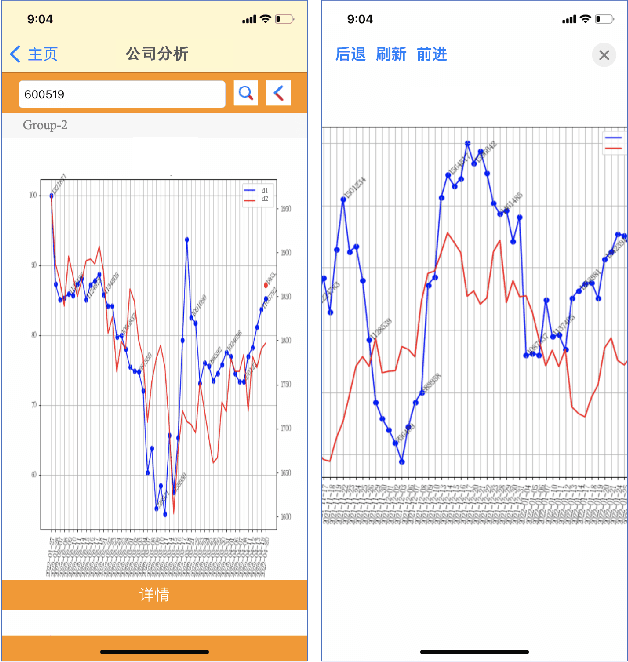
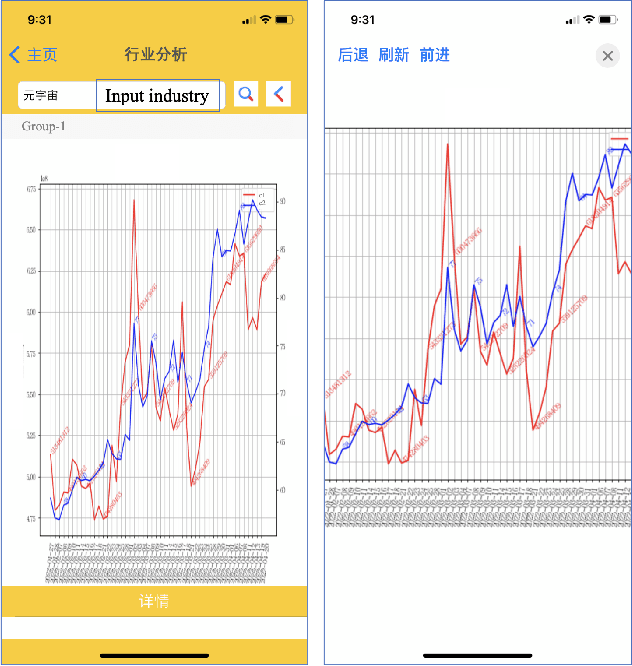
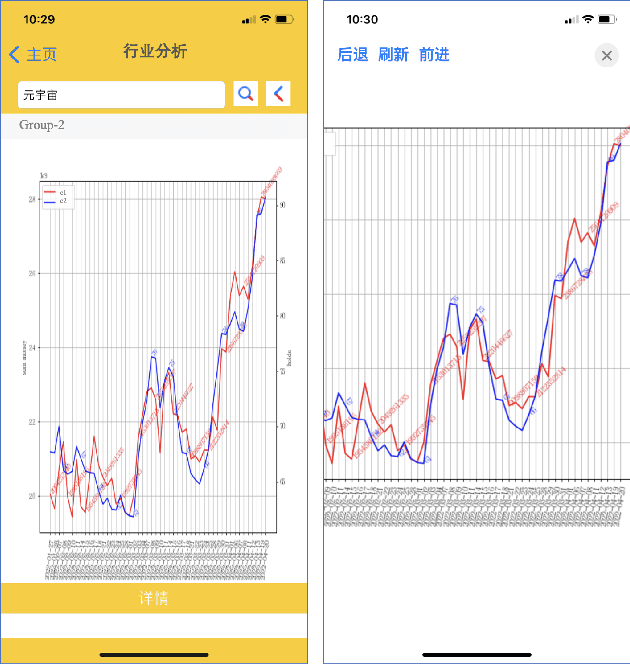
Maintaining financial system stability is critical to economic development, and early identification of risks and opportunities is essential. The financial industry contains a wide variety of data, such as financial statements, customer information, stock trading data, news, etc. Massive heterogeneous data calls for intelligent algorithms for machines to process and understand. This paper mainly focuses on the stock trading data and news about China A-share companies. We present a financial data analysis application, Financial Quotient Porter, designed to combine textual and numerical data by using a multi-strategy data mining approach. Additionally, we present our efforts and plans in deep learning financial text processing application scenarios using natural language processing (NLP) and knowledge graph (KG) technologies. Based on KG technology, risks and opportunities can be identified from heterogeneous data. NLP technology can be used to extract entities, relations, and events from unstructured text, and analyze market sentiment. Experimental results show market sentiments towards a company and an industry, as well as news-level associations between companies.