 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spike-based computational models of bio-inspired memories in the hippocampal CA3 region on SpiNNaker
May 10, 2022
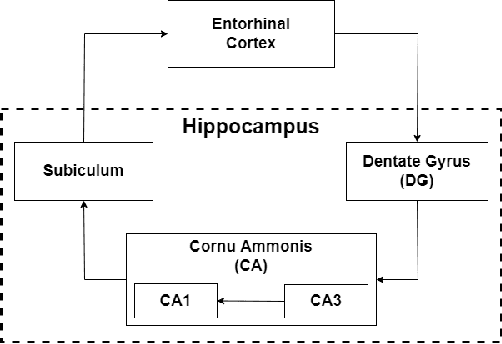
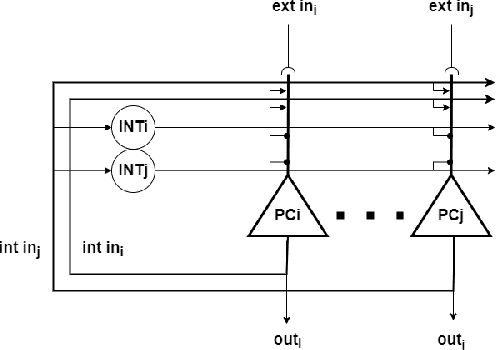
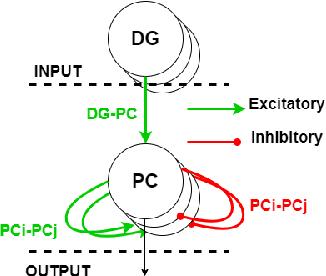
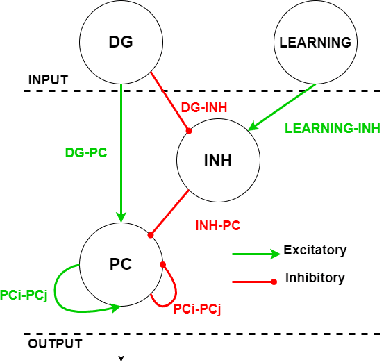
The human brain is the most powerful and efficient machine in existence today, surpassing in many ways the capabilities of modern computers. Currently, lines of research in neuromorphic engineering are trying to develop hardware that mimics the functioning of the brain to acquire these superior capabilities. One of the areas still under development is the design of bio-inspired memories, where the hippocampus plays an important role. This region of the brain acts as a short-term memory with the ability to store associations of information from different sensory streams in the brain and recall them later. This is possible thanks to the recurrent collateral network architecture that constitutes CA3, the main sub-region of the hippocampus. In this work, we developed two spike-based computational models of fully functional hippocampal bio-inspired memories for the storage and recall of complex patterns implemented with spiking neural networks on the SpiNNaker hardware platform. These models present different levels of biological abstraction, with the first model having a constant oscillatory activity closer to the biological model, and the second one having an energy-efficient regulated activity, which, although it is still bio-inspired, opts for a more functional approach. Different experiments were performed for each of the models, in order to test their learning/recalling capabilities. A comprehensive comparison between the functionality and the biological plausibility of the presented models was carried out, showing their strengths and weaknesses. The two models, which are publicly available for researchers, could pave the way for future spike-based implementations and applications.
Imagination-Augmented Natural Language Understanding
Apr 18, 2022
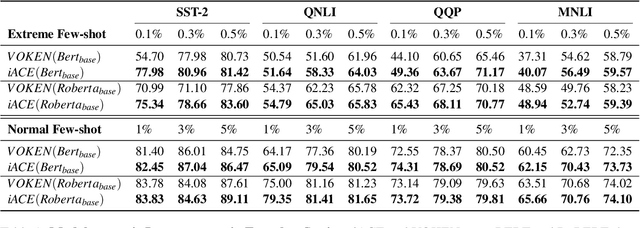
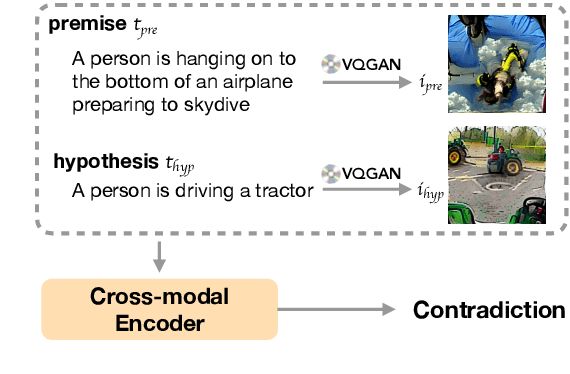
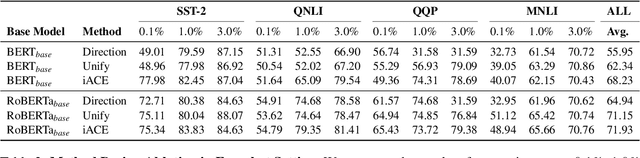
Human brains integrate linguistic and perceptual information simultaneously to understand natural language, and hold the critical ability to render imaginations. Such abilities enable us to construct new abstract concepts or concrete objects, and are essential in involving practical knowledge to solve problems in low-resource scenarios. However, most existing methods for Natural Language Understanding (NLU) are mainly focused on textual signals. They do not simulate human visual imagination ability, which hinders models from inferring and learning efficiently from limited data samples. Therefore, we introduce an Imagination-Augmented Cross-modal Encoder (iACE) to solve natural language understanding tasks from a novel learning perspective -- imagination-augmented cross-modal understanding. iACE enables visual imagination with external knowledge transferred from the powerful generative and pre-trained vision-and-language models. Extensive experiments on GLUE and SWAG show that iACE achieves consistent improvement over visually-supervised pre-trained models. More importantly, results in extreme and normal few-shot settings validate the effectiveness of iACE in low-resource natural language understanding circumstances.
PENELOPIE: Enabling Open Information Extraction for the Greek Language through Machine Translation
Mar 28, 2021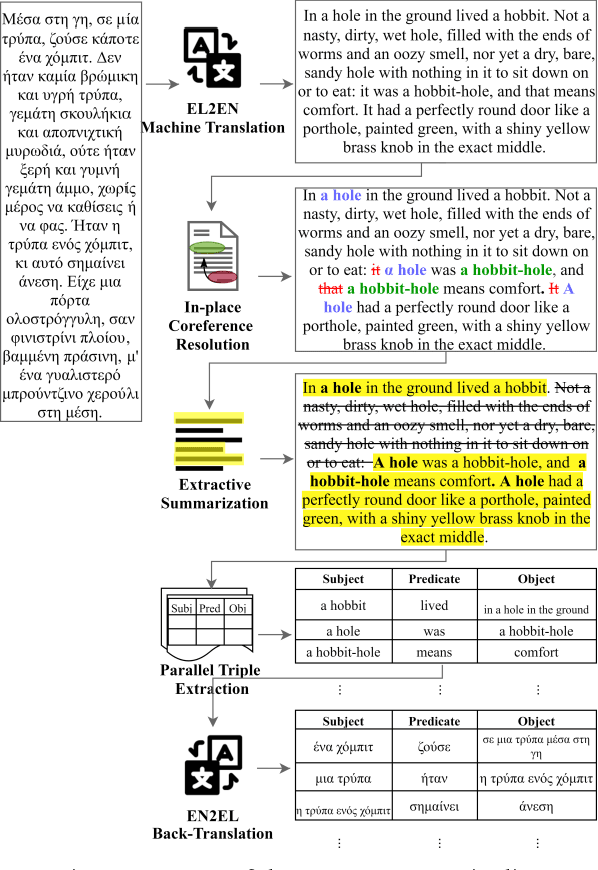
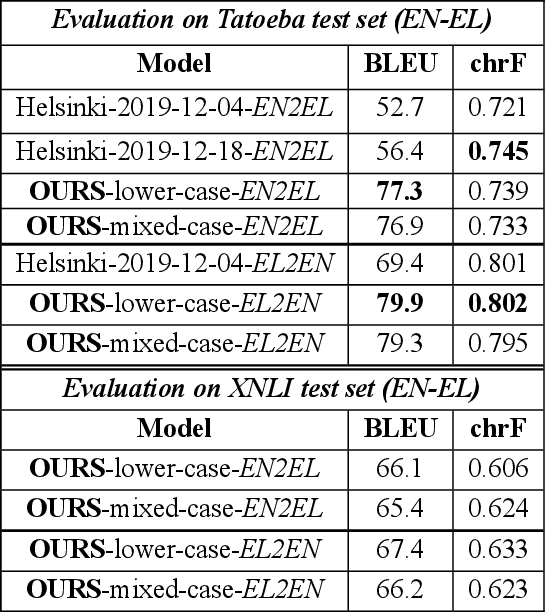
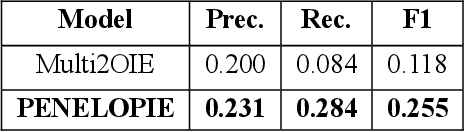
In this paper we present our submission for the EACL 2021 SRW; a methodology that aims at bridging the gap between high and low-resource languages in the context of Open Information Extraction, showcasing it on the Greek language. The goals of this paper are twofold: First, we build Neural Machine Translation (NMT) models for English-to-Greek and Greek-to-English based on the Transformer architecture. Second, we leverage these NMT models to produce English translations of Greek text as input for our NLP pipeline, to which we apply a series of pre-processing and triple extraction tasks. Finally, we back-translate the extracted triples to Greek. We conduct an evaluation of both our NMT and OIE methods on benchmark datasets and demonstrate that our approach outperforms the current state-of-the-art for the Greek natural language.
Tensor Decompositions for Hyperspectral Data Processing in Remote Sensing: A Comprehensive Review
May 13, 2022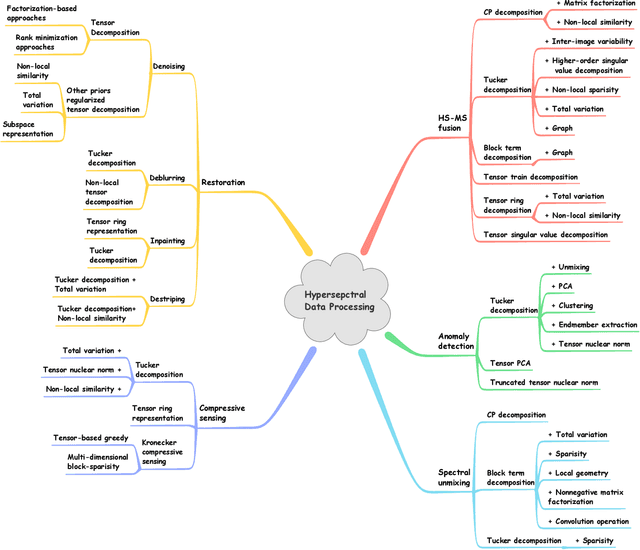



Owing to the rapid development of sensor technology, hyperspectral (HS) remote sensing (RS) imaging has provided a significant amount of spatial and spectral information for the observation and analysis of the Earth's surface at a distance of data acquisition devices, such as aircraft, spacecraft, and satellite. The recent advancement and even revolution of the HS RS technique offer opportunities to realize the full potential of various applications, while confronting new challenges for efficiently processing and analyzing the enormous HS acquisition data. Due to the maintenance of the 3-D HS inherent structure, tensor decomposition has aroused widespread concern and research in HS data processing tasks over the past decades. In this article, we aim at presenting a comprehensive overview of tensor decomposition, specifically contextualizing the five broad topics in HS data processing, and they are HS restoration, compressed sensing, anomaly detection, super-resolution, and spectral unmixing. For each topic, we elaborate on the remarkable achievements of tensor decomposition models for HS RS with a pivotal description of the existing methodologies and a representative exhibition on the experimental results. As a result, the remaining challenges of the follow-up research directions are outlined and discussed from the perspective of the real HS RS practices and tensor decomposition merged with advanced priors and even with deep neural networks. This article summarizes different tensor decomposition-based HS data processing methods and categorizes them into different classes from simple adoptions to complex combinations with other priors for the algorithm beginners. We also expect this survey can provide new investigations and development trends for the experienced researchers who understand tensor decomposition and HS RS to some extent.
KANT: A tool for Grounding and Knowledge Management
Apr 18, 2022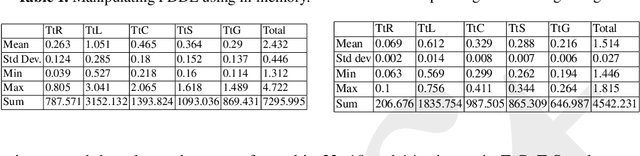
The intelligent robotics community usually organizes knowledge into symbolic and sub-symbolic levels. These two levels establish the set of symbols and rules for manipulating knowledge based on their (symbol system - dictionary). Thus, the correspondences -- Grounding or knowledge representation -- require specific software techniques for anchoring continuous and discrete state variables between these two levels. This paper presents the design and evaluation of an Open Source tool called KANT(Knowledge mAnagemeNT) to let different components of the system architecture controlling the robot query, save, edit, and delete the data from the Knowledge Base without having to worry about the type and the implementation of the source data. Using KANT, components managing subsymbolic information can smoothly interact with symbolic components. Besides, implementation mechanisms used in KANT, such as the use of in-memory and non-SQL databases, improve the performance of the knowledge management systems in ROS middleware, as shown by the evaluations presented in this work.
MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation
Apr 27, 2022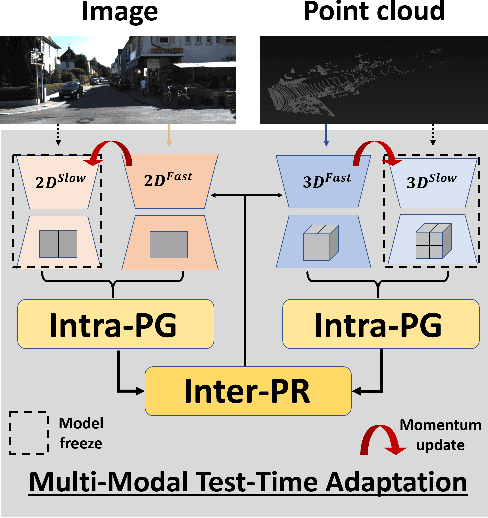
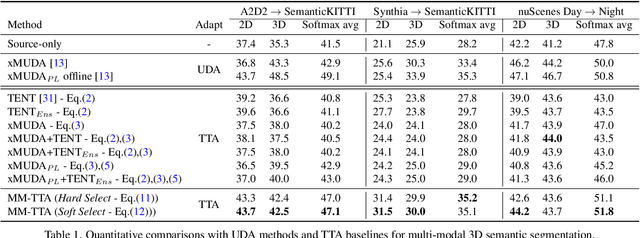
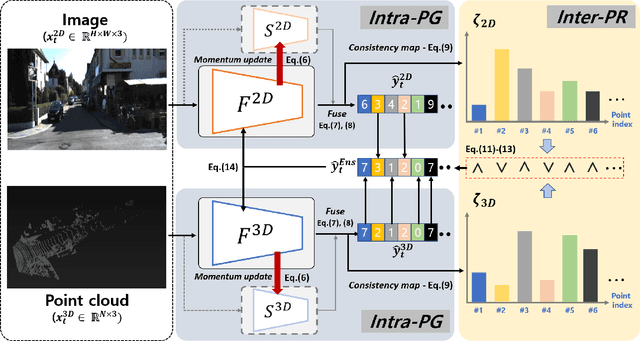
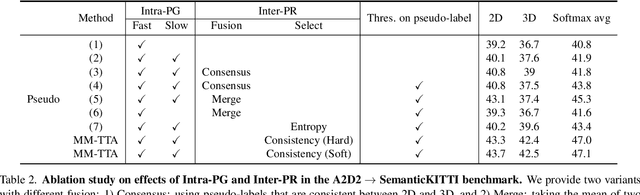
Test-time adaptation approaches have recently emerged as a practical solution for handling domain shift without access to the source domain data. In this paper, we propose and explore a new multi-modal extension of test-time adaptation for 3D semantic segmentation. We find that directly applying existing methods usually results in performance instability at test time because multi-modal input is not considered jointly. To design a framework that can take full advantage of multi-modality, where each modality provides regularized self-supervisory signals to other modalities, we propose two complementary modules within and across the modalities. First, Intra-modal Pseudolabel Generation (Intra-PG) is introduced to obtain reliable pseudo labels within each modality by aggregating information from two models that are both pre-trained on source data but updated with target data at different paces. Second, Inter-modal Pseudo-label Refinement (Inter-PR) adaptively selects more reliable pseudo labels from different modalities based on a proposed consistency scheme. Experiments demonstrate that our regularized pseudo labels produce stable self-learning signals in numerous multi-modal test-time adaptation scenarios for 3D semantic segmentation. Visit our project website at https://www.nec-labs.com/~mas/MM-TTA.
Information-Theoretic Probing for Linguistic Structure
Apr 07, 2020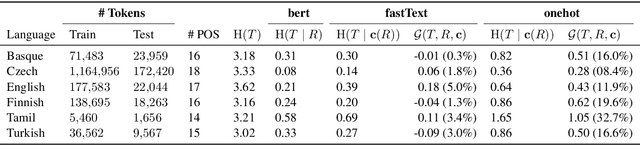
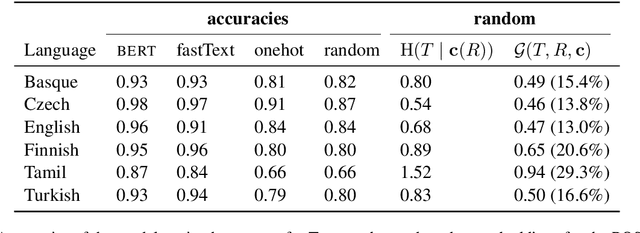
The success of neural networks on a diverse set of NLP tasks has led researchers to question how much do these networks actually know about natural language. Probes are a natural way of assessing this. When probing, a researcher chooses a linguistic task and trains a supervised model to predict annotation in that linguistic task from the network's learned representations. If the probe does well, the researcher may conclude that the representations encode knowledge related to the task. A commonly held belief is that using simpler models as probes is better; the logic is that such models will identify linguistic structure, but not learn the task itself. We propose an information-theoretic formalization of probing as estimating mutual information that contradicts this received wisdom: one should always select the highest performing probe one can, even if it is more complex, since it will result in a tighter estimate. The empirical portion of our paper focuses on obtaining tight estimates for how much information BERT knows about parts of speech in a set of five typologically diverse languages that are often underrepresented in parsing research, plus English, totaling six languages. We find BERT accounts for only at most 5% more information than traditional, type-based word embeddings.
CyNER: A Python Library for Cybersecurity Named Entity Recognition
Apr 08, 2022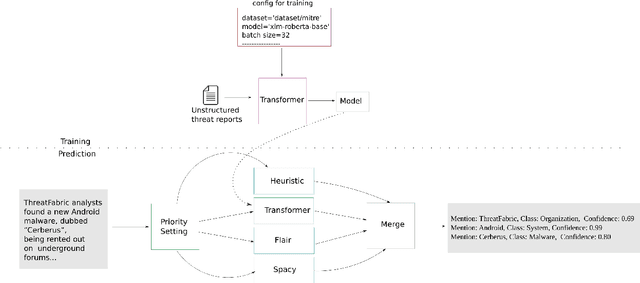


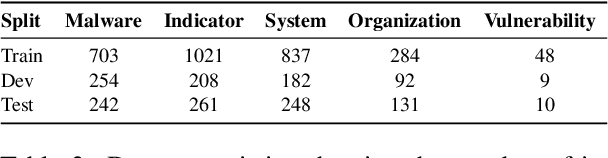
Open Cyber threat intelligence (OpenCTI) information is available in an unstructured format from heterogeneous sources on the Internet. We present CyNER, an open-source python library for cybersecurity named entity recognition (NER). CyNER combines transformer-based models for extracting cybersecurity-related entities, heuristics for extracting different indicators of compromise, and publicly available NER models for generic entity types. We provide models trained on a diverse corpus that users can readily use. Events are described as classes in previous research - MALOnt2.0 (Christian et al., 2021) and MALOnt (Rastogi et al., 2020) and together extract a wide range of malware attack details from a threat intelligence corpus. The user can combine predictions from multiple different approaches to suit their needs. The library is made publicly available.
Precognition in Task-oriented Dialogue Understanding: Posterior Regularization by Future Context
Mar 07, 2022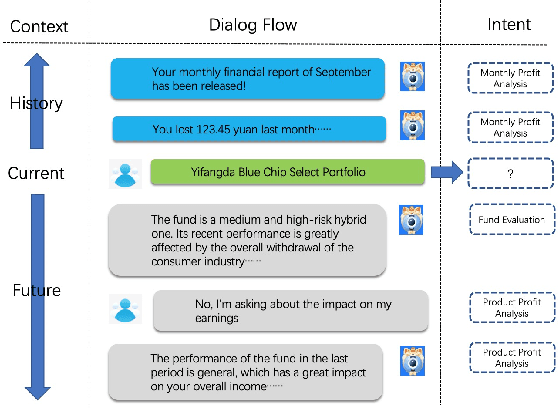
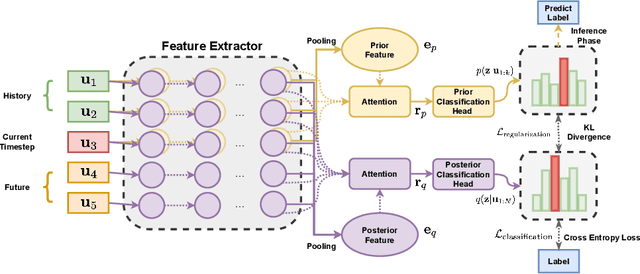

Task-oriented dialogue systems have become overwhelmingly popular in recent researches. Dialogue understanding is widely used to comprehend users' intent, emotion and dialogue state in task-oriented dialogue systems. Most previous works on such discriminative tasks only models current query or historical conversations. Even if in some work the entire dialogue flow was modeled, it is not suitable for the real-world task-oriented conversations as the future contexts are not visible in such cases. In this paper, we propose to jointly model historical and future information through the posterior regularization method. More specifically, by modeling the current utterance and past contexts as prior, and the entire dialogue flow as posterior, we optimize the KL distance between these distributions to regularize our model during training. And only historical information is used for inference. Extensive experiments on two dialogue datasets validate the effectiveness of our proposed method, achieving superior results compared with all baseline models.
Graph Refinement for Coreference Resolution
Mar 30, 2022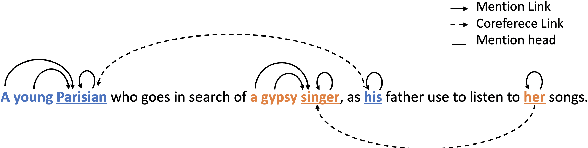
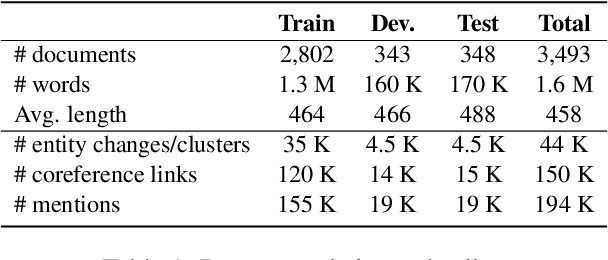
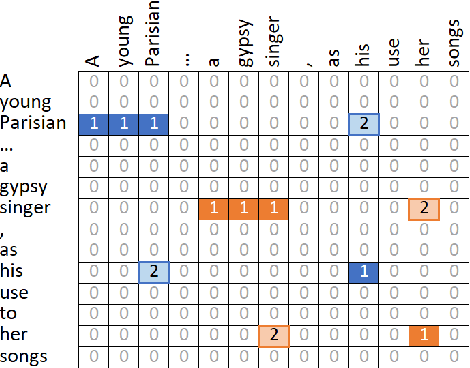
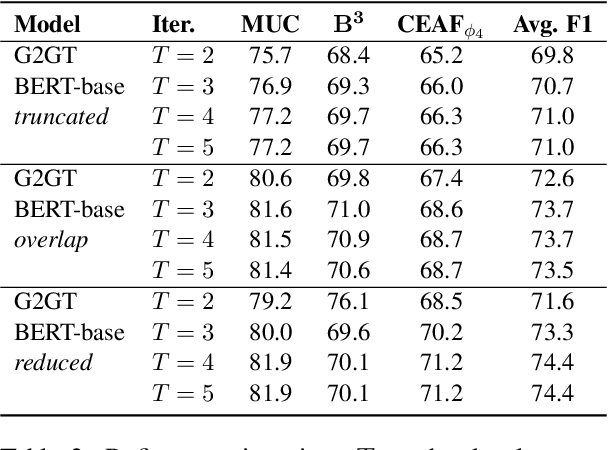
The state-of-the-art models for coreference resolution are based on independent mention pair-wise decisions. We propose a modelling approach that learns coreference at the document-level and takes global decisions. For this purpose, we model coreference links in a graph structure where the nodes are tokens in the text, and the edges represent the relationship between them. Our model predicts the graph in a non-autoregressive manner, then iteratively refines it based on previous predictions, allowing global dependencies between decisions. The experimental results show improvements over various baselines, reinforcing the hypothesis that document-level information improves conference resolution.