 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Dual Encoder Architectures for Question Answering
Apr 14, 2022

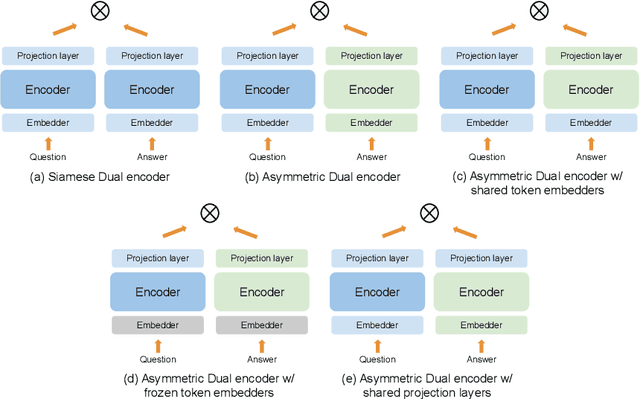
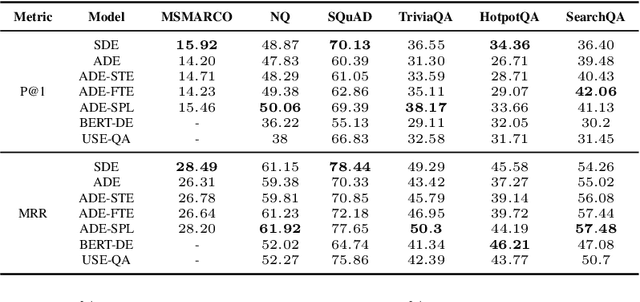

Dual encoders have been used for question-answering (QA) and information retrieval (IR) tasks with good results. There are two major types of dual encoders, Siamese Dual Encoders (SDE), with parameters shared across two encoders, and Asymmetric Dual Encoder (ADE), with two distinctly parameterized encoders. In this work, we explore the dual encoder architectures for QA retrieval tasks. By evaluating on MS MARCO and the MultiReQA benchmark, we show that SDE performs significantly better than ADE. We further propose three different improved versions of ADEs. Based on the evaluation of QA retrieval tasks and direct analysis of the embeddings, we demonstrate that sharing parameters in projection layers would enable ADEs to perform competitively with SDEs.
CAR: Class-aware Regularizations for Semantic Segmentation
Mar 14, 2022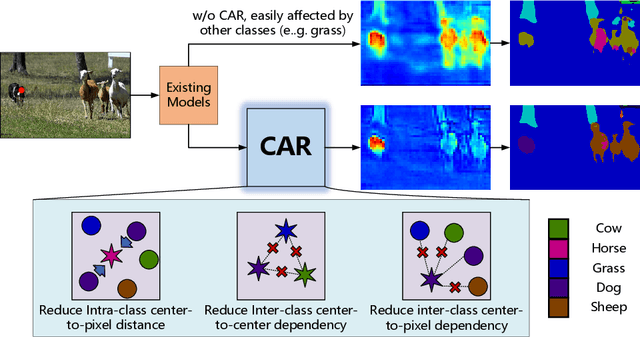
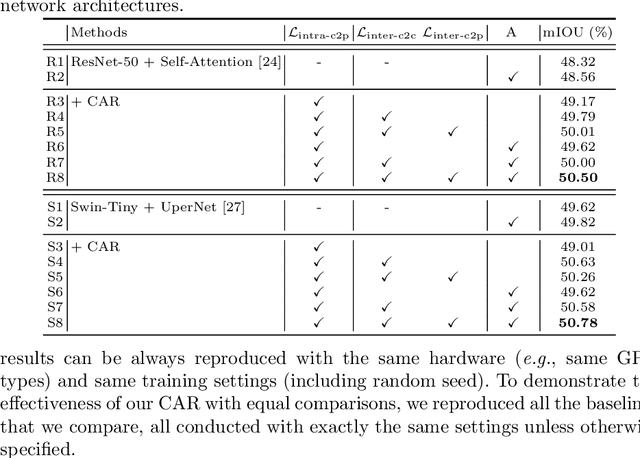


Recent segmentation methods, such as OCR and CPNet, utilizing "class level" information in addition to pixel features, have achieved notable success for boosting the accuracy of existing network modules. However, the extracted class-level information was simply concatenated to pixel features, without explicitly being exploited for better pixel representation learning. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. In this paper, aiming to use class level information more effectively, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Three novel loss functions are proposed. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. Our method can be easily applied to most existing segmentation models during training, including OCR and CPNet, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. The complete code is available at https://github.com/edwardyehuang/CAR.
Online Graph Learning from Social Interactions
Mar 11, 2022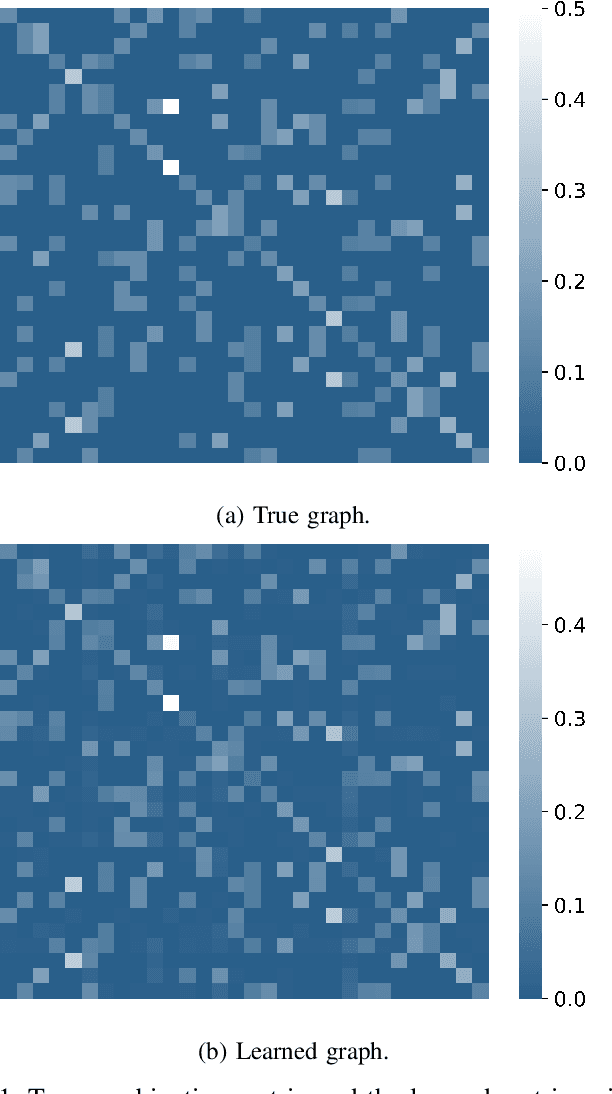
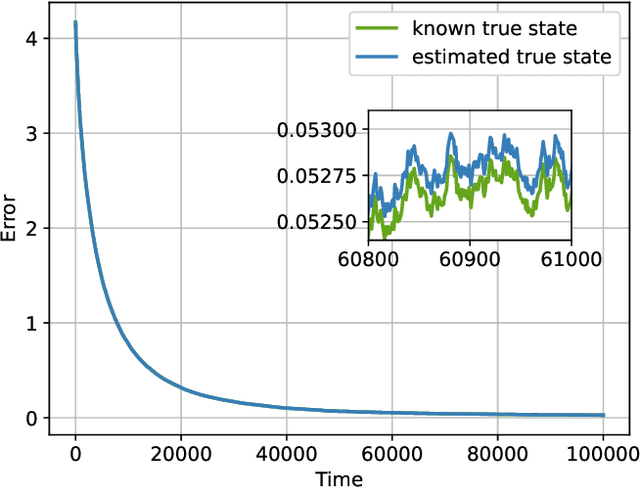
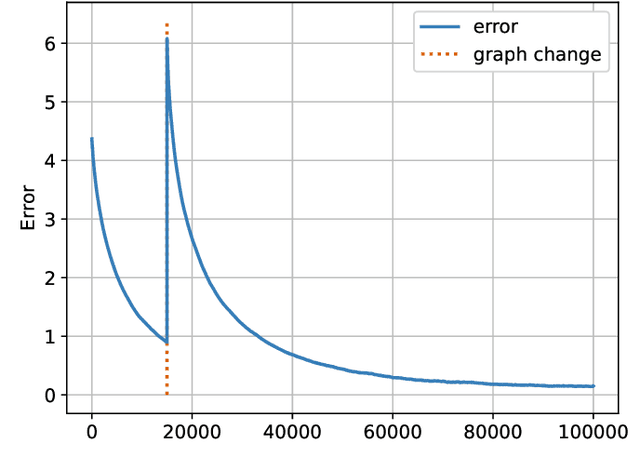
Social learning algorithms provide models for the formation of opinions over social networks resulting from local reasoning and peer-to-peer exchanges. Interactions occur over an underlying graph topology, which describes the flow of information and relative influence between pairs of agents. For a given graph topology, these algorithms allow for the prediction of formed opinions. In this work, we study the inverse problem. Given a social learning model and observations of the evolution of beliefs over time, we aim at identifying the underlying graph topology. The learned graph allows for the inference of pairwise influence between agents, the overall influence agents have over the behavior of the network, as well as the flow of information through the social network. The proposed algorithm is online in nature and can adapt dynamically to changes in the graph topology or the true hypothesis.
Image Steganography based on Style Transfer
Mar 09, 2022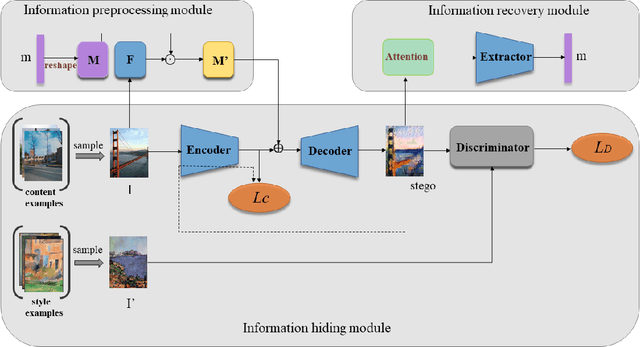
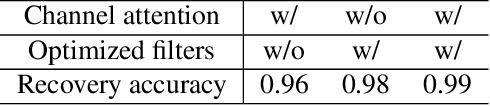
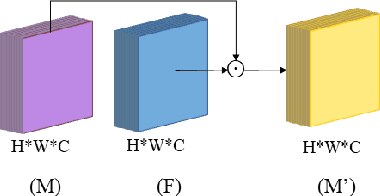
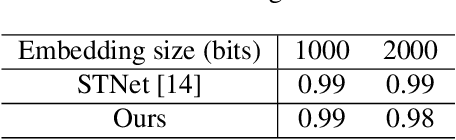
Image steganography is the art and science of using images as cover for covert communications. With the development of neural networks, traditional image steganography is more likely to be detected by deep learning-based steganalysis. To improve upon this, we propose image steganography network based on style transfer, and the embedding of secret messages can be disguised as image stylization. We embed secret information while transforming the content image style. In latent space, the secret information is integrated into the latent representation of the cover image to generate the stego images, which are indistinguishable from normal stylized images. It is an end-to-end unsupervised model without pre-training. Extensive experiments on the benchmark dataset demonstrate the reliability, quality and security of stego images generated by our steganographic network.
Geometric Methods for Sampling, Optimisation, Inference and Adaptive Agents
Mar 20, 2022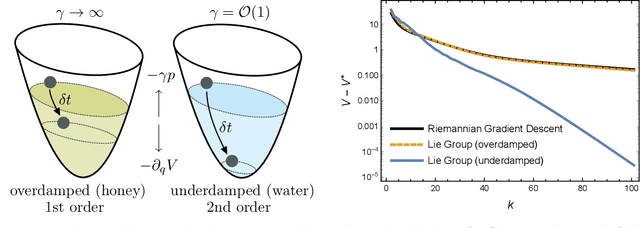
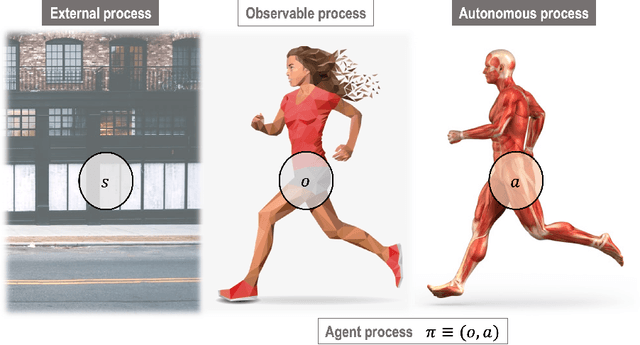
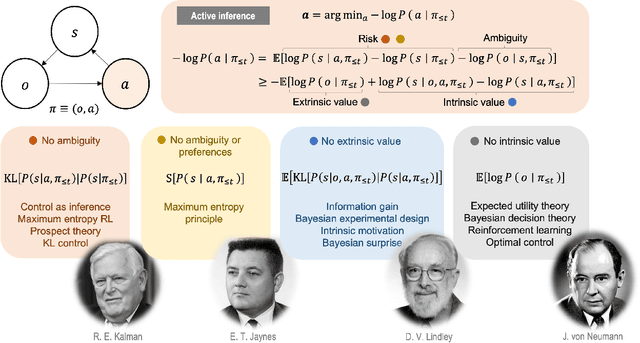
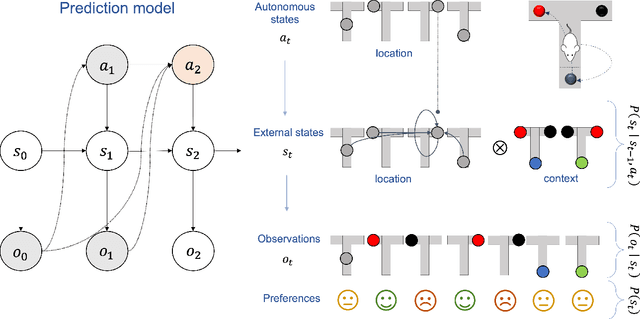
In this chapter, we identify fundamental geometric structures that underlie the problems of sampling, optimisation, inference and adaptive decision-making. Based on this identification, we derive algorithms that exploit these geometric structures to solve these problems efficiently. We show that a wide range of geometric theories emerge naturally in these fields, ranging from measure-preserving processes, information divergences, Poisson geometry, and geometric integration. Specifically, we explain how \emph{(i)} leveraging the symplectic geometry of Hamiltonian systems enable us to construct (accelerated) sampling and optimisation methods, \emph{(ii)} the theory of Hilbertian subspaces and Stein operators provides a general methodology to obtain robust estimators, \emph{(iii)} preserving the information geometry of decision-making yields adaptive agents that perform active inference. Throughout, we emphasise the rich connections between these fields; e.g., inference draws on sampling and optimisation, and adaptive decision-making assesses decisions by inferring their counterfactual consequences. Our exposition provides a conceptual overview of underlying ideas, rather than a technical discussion, which can be found in the references herein.
Conditional $β$-VAE for De Novo Molecular Generation
May 01, 2022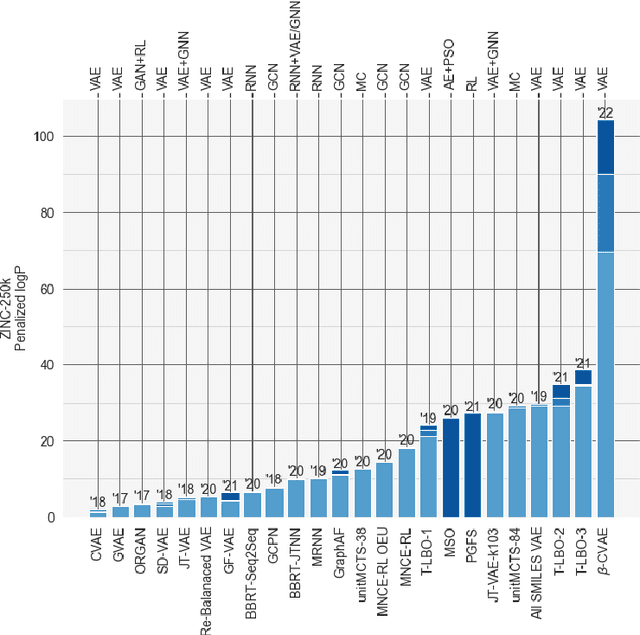
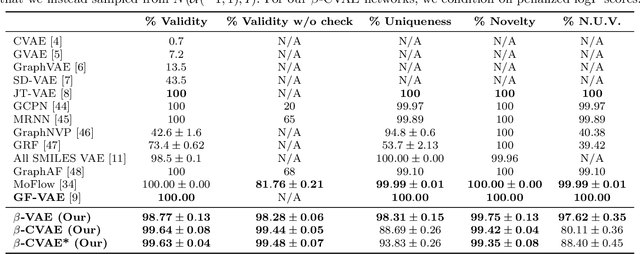
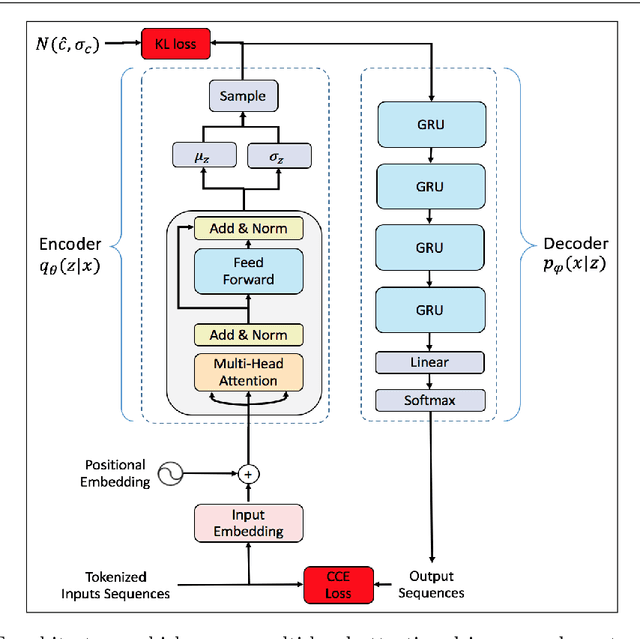
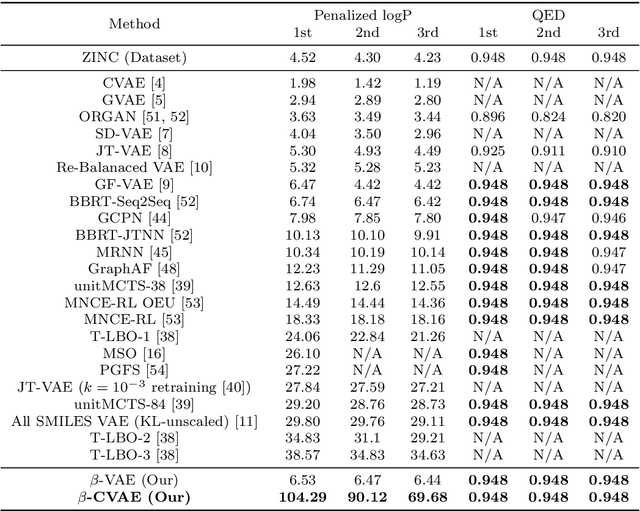
Deep learning has significantly advanced and accelerated de novo molecular generation. Generative networks, namely Variational Autoencoders (VAEs) can not only randomly generate new molecules, but also alter molecular structures to optimize specific chemical properties which are pivotal for drug-discovery. While VAEs have been proposed and researched in the past for pharmaceutical applications, they possess deficiencies which limit their ability to both optimize properties and decode syntactically valid molecules. We present a recurrent, conditional $\beta$-VAE which disentangles the latent space to enhance post hoc molecule optimization. We create a mutual information driven training protocol and data augmentations to both increase molecular validity and promote longer sequence generation. We demonstrate the efficacy of our framework on the ZINC-250k dataset, achieving SOTA unconstrained optimization results on the penalized LogP (pLogP) and QED scores, while also matching current SOTA results for validity, novelty and uniqueness scores for random generation. We match the current SOTA on QED for top-3 molecules at 0.948, while setting a new SOTA for pLogP optimization at 104.29, 90.12, 69.68 and demonstrating improved results on the constrained optimization task.
IA-GCN: Interactive Graph Convolutional Network for Recommendation
Apr 08, 2022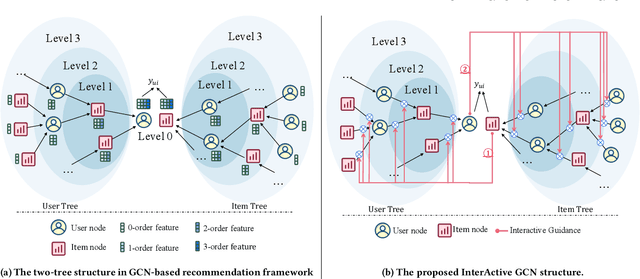

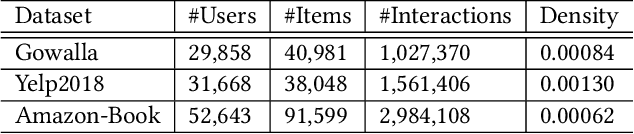
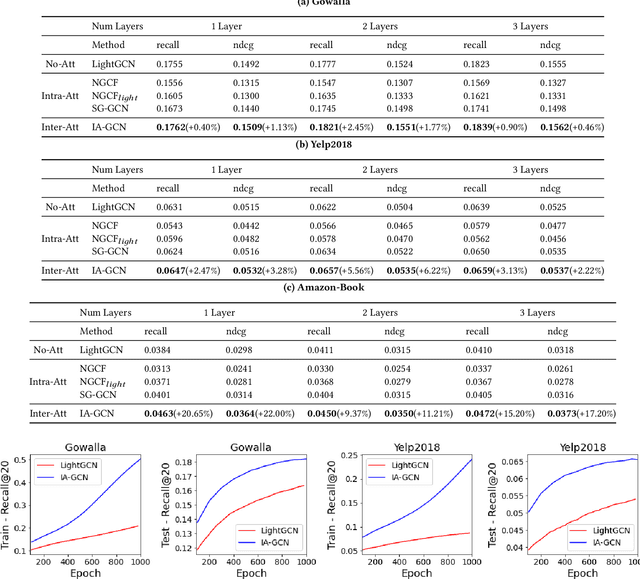
Recently, Graph Convolutional Network (GCN) has become a novel state-of-art for Collaborative Filtering (CF) based Recommender Systems (RS). It is a common practice to learn informative user and item representations by performing embedding propagation on a user-item bipartite graph, and then provide the users with personalized item suggestions based on the representations. Despite effectiveness, existing algorithms neglect precious interactive features between user-item pairs in the embedding process. When predicting a user's preference for different items, they still aggregate the user tree in the same way, without emphasizing target-related information in the user neighborhood. Such a uniform aggregation scheme easily leads to suboptimal user and item representations, limiting the model expressiveness to some extent. In this work, we address this problem by building bilateral interactive guidance between each user-item pair and proposing a new model named IA-GCN (short for InterActive GCN). Specifically, when learning the user representation from its neighborhood, we assign higher attention weights to those neighbors similar to the target item. Correspondingly, when learning the item representation, we pay more attention to those neighbors resembling the target user. This leads to interactive and interpretable features, effectively distilling target-specific information through each graph convolutional operation. Our model is built on top of LightGCN, a state-of-the-art GCN model for CF, and can be combined with various GCN-based CF architectures in an end-to-end fashion. Extensive experiments on three benchmark datasets demonstrate the effectiveness and robustness of IA-GCN.
A Summary of the ALQAC 2021 Competition
Apr 25, 2022


We summarize the evaluation of the first Automated Legal Question Answering Competition (ALQAC 2021). The competition this year contains three tasks, which aims at processing the statute law document, which are Legal Text Information Retrieval (Task 1), Legal Text Entailment Prediction (Task 2), and Legal Text Question Answering (Task 3). The final goal of these tasks is to build a system that can automatically determine whether a particular statement is lawful. There is no limit to the approaches of the participating teams. This year, there are 5 teams participating in Task 1, 6 teams participating in Task 2, and 5 teams participating in Task 3. There are in total 36 runs submitted to the organizer. In this paper, we summarize each team's approaches, official results, and some discussion about the competition. Only results of the teams who successfully submit their approach description paper are reported in this paper.
UPB at SemEval-2021 Task 8: Extracting Semantic Information on Measurements as Multi-Turn Question Answering
Apr 09, 2021

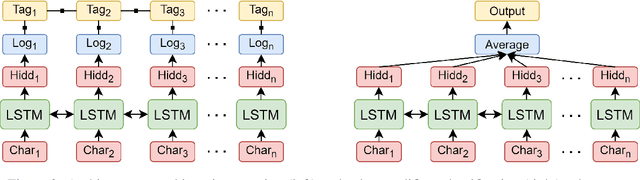

Extracting semantic information on measurements and counts is an important topic in terms of analyzing scientific discourses. The 8th task of SemEval-2021: Counts and Measurements (MeasEval) aimed to boost research in this direction by providing a new dataset on which participants train their models to extract meaningful information on measurements from scientific texts. The competition is composed of five subtasks that build on top of each other: (1) quantity span identification, (2) unit extraction from the identified quantities and their value modifier classification, (3) span identification for measured entities and measured properties, (4) qualifier span identification, and (5) relation extraction between the identified quantities, measured entities, measured properties, and qualifiers. We approached these challenges by first identifying the quantities, extracting their units of measurement, classifying them with corresponding modifiers, and afterwards using them to jointly solve the last three subtasks in a multi-turn question answering manner. Our best performing model obtained an overlapping F1-score of 36.91% on the test set.
Saliency-based segmentation of dermoscopic images using color information
Nov 26, 2020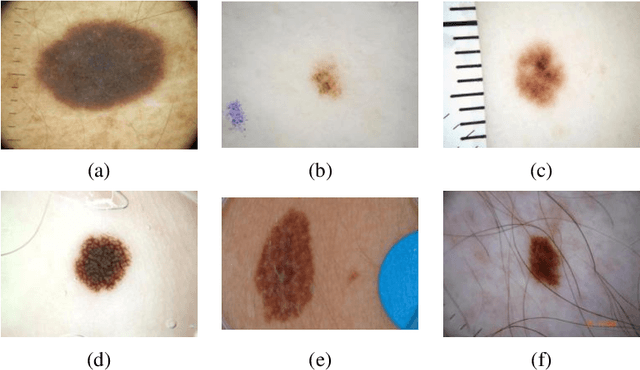
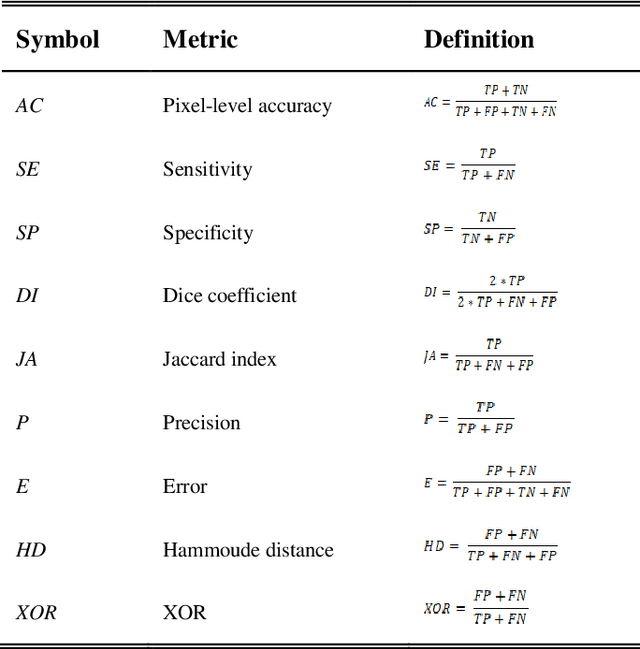
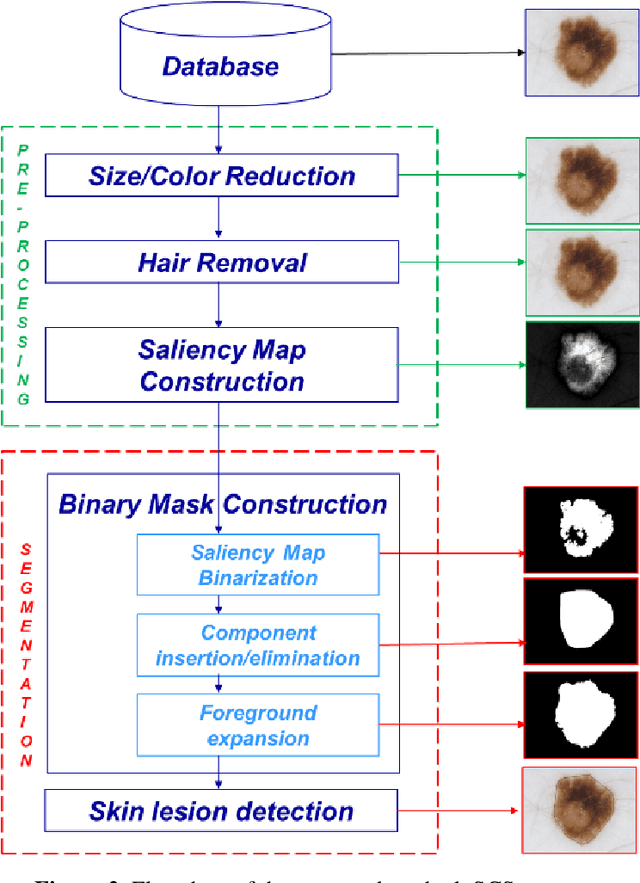
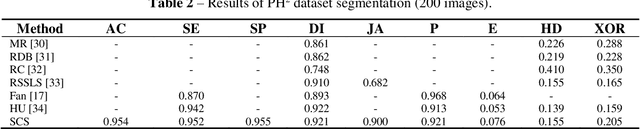
Skin lesion segmentation is one of the crucial steps for an efficient non-invasive computer-aided early diagnosis of melanoma. In this paper, we investigate how saliency and color information can be usefully employed to determine the lesion region. Unlike most existing saliency-based methods, to discriminate against the skin lesion from the surrounding regions we enucleate some properties related to saliency and color information and we propose a novel segmentation process using binarization coupled with new perceptual criteria based on these properties. To refine the accuracy of the proposed method, the segmentation step is preceded by a pre-processing aimed at reducing the computation burden, removing artifacts, and improving contrast. We have assessed the method on two public databases including 1497 dermoscopic images and compared its performance with that of classical saliency-based methods and with that of some more recent saliency-based methods specifically applied to dermoscopic images. Results of qualitative and quantitative evaluations of the proposed method are promising as the obtained skin lesion segmentation is accurate and the method performs satisfactorily in comparison to other existing saliency-based segmentation methods.