 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Long Time No See! Open-Domain Conversation with Long-Term Persona Memory
Mar 14, 2022
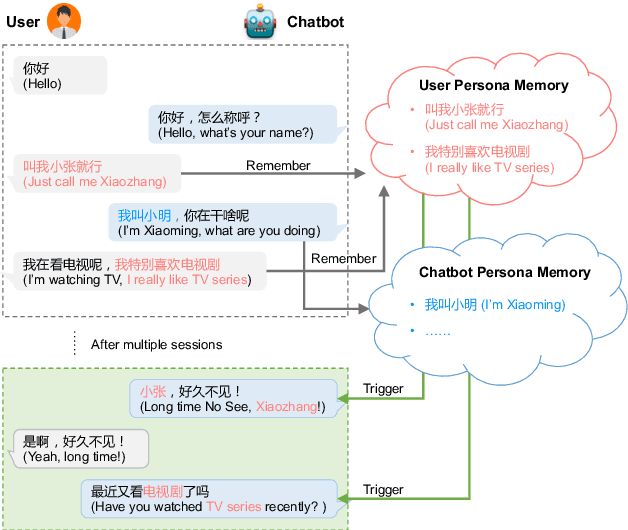
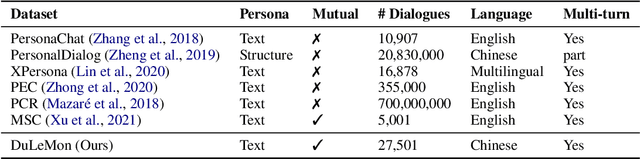
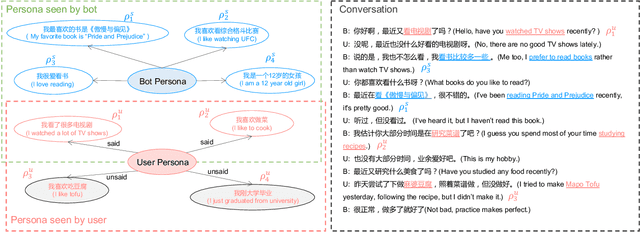
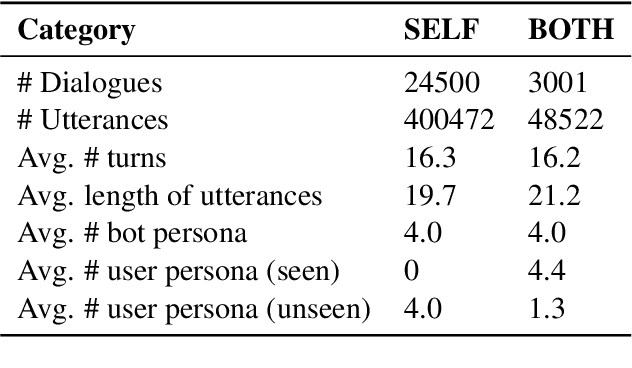
Most of the open-domain dialogue models tend to perform poorly in the setting of long-term human-bot conversations. The possible reason is that they lack the capability of understanding and memorizing long-term dialogue history information. To address this issue, we present a novel task of Long-term Memory Conversation (LeMon) and then build a new dialogue dataset DuLeMon and a dialogue generation framework with Long-Term Memory (LTM) mechanism (called PLATO-LTM). This LTM mechanism enables our system to accurately extract and continuously update long-term persona memory without requiring multiple-session dialogue datasets for model training. To our knowledge, this is the first attempt to conduct real-time dynamic management of persona information of both parties, including the user and the bot. Results on DuLeMon indicate that PLATO-LTM can significantly outperform baselines in terms of long-term dialogue consistency, leading to better dialogue engagingness.
l-Leaks: Membership Inference Attacks with Logits
May 13, 2022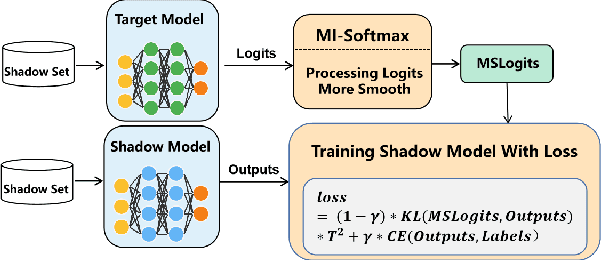

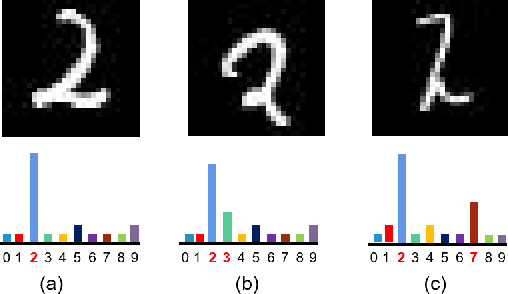

Machine Learning (ML) has made unprecedented progress in the past several decades. However, due to the memorability of the training data, ML is susceptible to various attacks, especially Membership Inference Attacks (MIAs), the objective of which is to infer the model's training data. So far, most of the membership inference attacks against ML classifiers leverage the shadow model with the same structure as the target model. However, empirical results show that these attacks can be easily mitigated if the shadow model is not clear about the network structure of the target model. In this paper, We present attacks based on black-box access to the target model. We name our attack \textbf{l-Leaks}. The l-Leaks follows the intuition that if an established shadow model is similar enough to the target model, then the adversary can leverage the shadow model's information to predict a target sample's membership.The logits of the trained target model contain valuable sample knowledge. We build the shadow model by learning the logits of the target model and making the shadow model more similar to the target model. Then shadow model will have sufficient confidence in the member samples of the target model. We also discuss the effect of the shadow model's different network structures to attack results. Experiments over different networks and datasets demonstrate that both of our attacks achieve strong performance.
Skeptical binary inferences in multi-label problems with sets of probabilities
May 02, 2022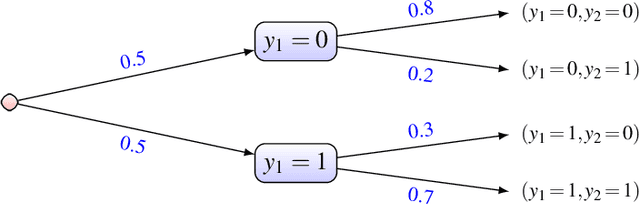

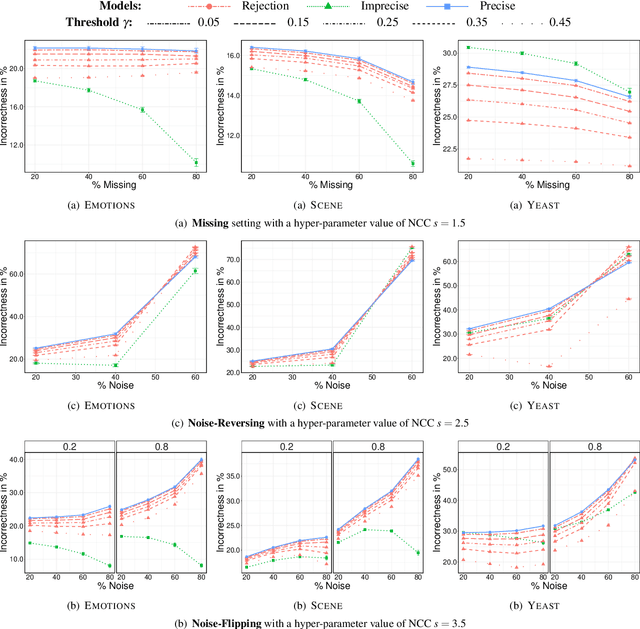
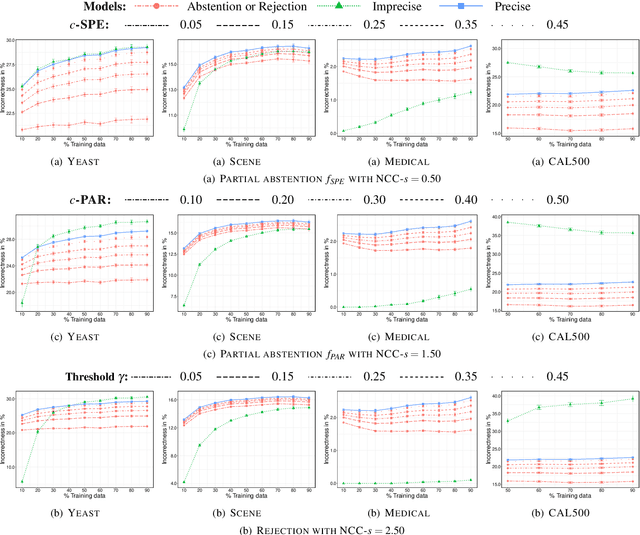
In this paper, we consider the problem of making distributionally robust, skeptical inferences for the multi-label problem, or more generally for Boolean vectors. By distributionally robust, we mean that we consider a set of possible probability distributions, and by skeptical we understand that we consider as valid only those inferences that are true for every distribution within this set. Such inferences will provide partial predictions whenever the considered set is sufficiently big. We study in particular the Hamming loss case, a common loss function in multi-label problems, showing how skeptical inferences can be made in this setting. Our experimental results are organised in three sections; (1) the first one indicates the gain computational obtained from our theoretical results by using synthetical data sets, (2) the second one indicates that our approaches produce relevant cautiousness on those hard-to-predict instances where its precise counterpart fails, and (3) the last one demonstrates experimentally how our approach copes with imperfect information (generated by a downsampling procedure) better than the partial abstention [31] and the rejection rules.
TransFusion: Multi-view Divergent Fusion for Medical Image Segmentation with Transformers
Mar 21, 2022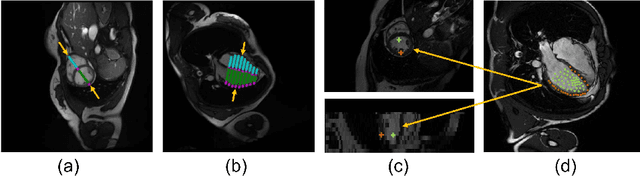
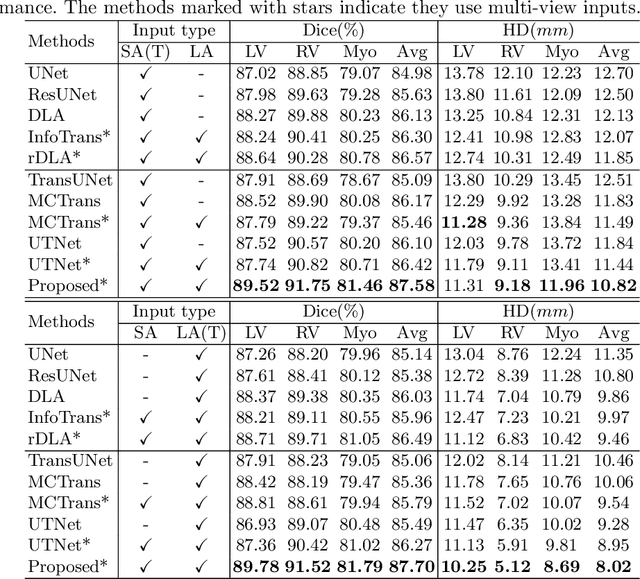
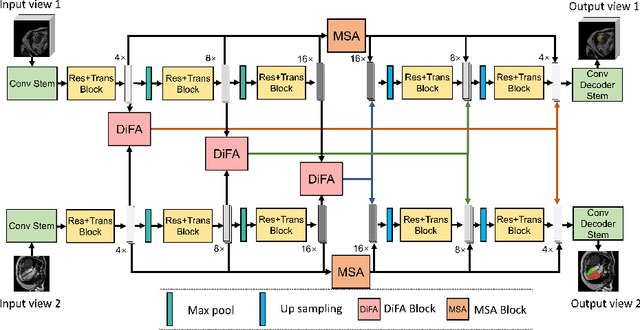
Combining information from multi-view images is crucial to improve the performance and robustness of automated methods for disease diagnosis. However, due to the non-alignment characteristics of multi-view images, building correlation and data fusion across views largely remain an open problem. In this study, we present TransFusion, a Transformer-based architecture to merge divergent multi-view imaging information using convolutional layers and powerful attention mechanisms. In particular, the Divergent Fusion Attention (DiFA) module is proposed for rich cross-view context modeling and semantic dependency mining, addressing the critical issue of capturing long-range correlations between unaligned data from different image views. We further propose the Multi-Scale Attention (MSA) to collect global correspondence of multi-scale feature representations. We evaluate TransFusion on the Multi-Disease, Multi-View \& Multi-Center Right Ventricular Segmentation in Cardiac MRI (M\&Ms-2) challenge cohort. TransFusion demonstrates leading performance against the state-of-the-art methods and opens up new perspectives for multi-view imaging integration towards robust medical image segmentation.
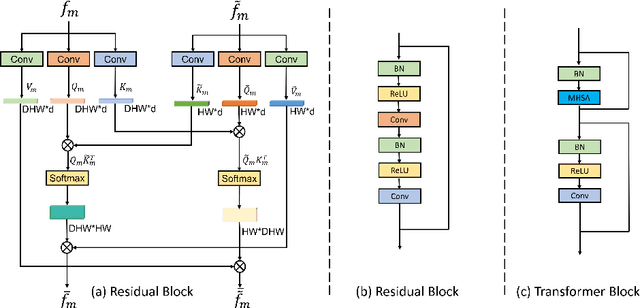
HierAttn: Effectively Learn Representations from Stage Attention and Branch Attention for Skin Lesions Diagnosis
May 16, 2022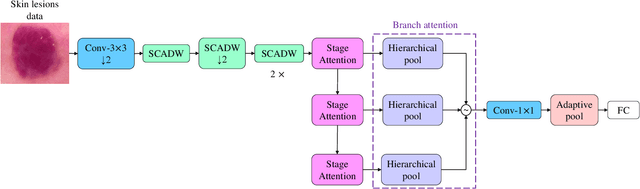
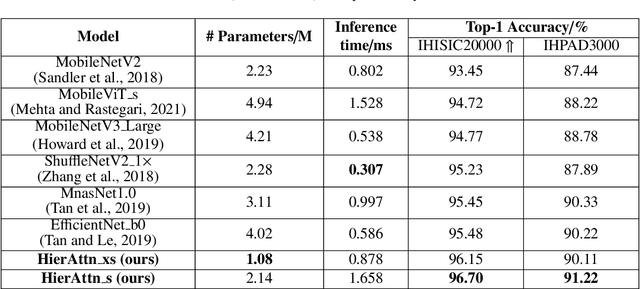
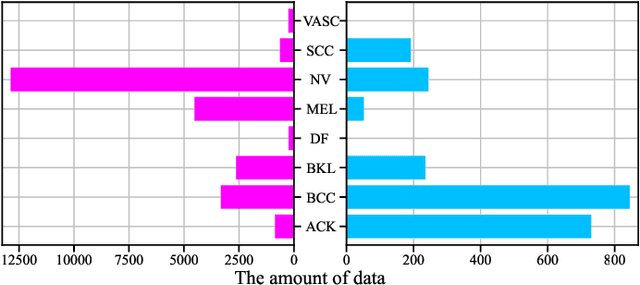
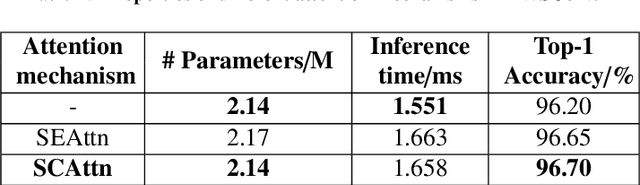
Accurate and unbiased examinations of skin lesions are critical for early diagnosis and treatment of skin conditions and disorders. Visual features of skin lesions vary significantly because the skin images are collected from patients with different skin colours by using dissimilar type of imaging equipment. Recent studies have reported ensembled convolutional neural networks (CNNs) to classify the images for early diagnosis of skin disorders. However, the practical use of CNNs is limited because the majority of networks are heavyweight and inadequate to use the contextual information. Although lightweight networks (e.g., MobileNetV3 and EfficientNet) were developed to save the computational cost for implementing deep neural networks on mobile devices, not sufficient representation depth restricts their performance. To address the limitations, we introduce a new light and effective neural network, namely HierAttn network. The HierAttn applies a novel strategy to balance the learning local and global features by using a multi-stage attention mechanism in a hierarchical architecture. The efficacy of HierAttn was evaluated by using the dermoscopy images dataset ISIC2019 and smartphone photos dataset PAD-UFES-20. The experimental results show that HierAttn achieves the best top-1 accuracy and AUC among the state-of-the-art light-weight networks. The new light HierAttn network has the potential in promoting the use of deep learning in clinics and allowing patients for early diagnosis of skin disorders with personal devices. The code is available at https://github.com/anthonyweidai/HierAttn.
Automated Mobility Context Detection with Inertial Signals
May 16, 2022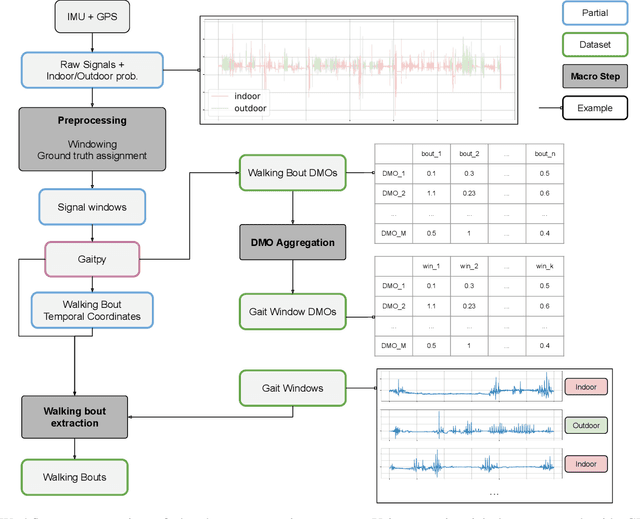
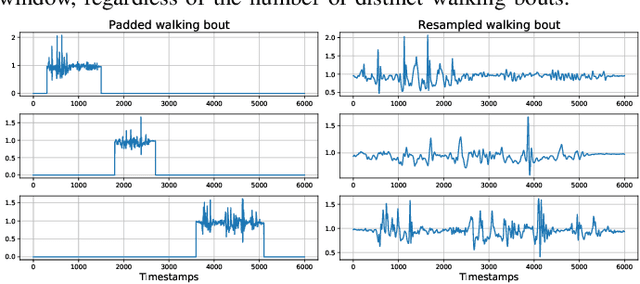
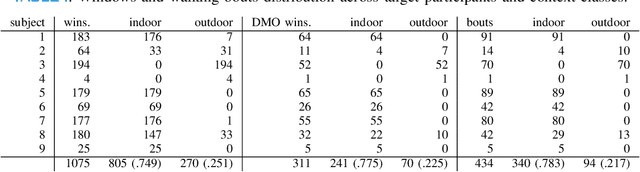
Remote monitoring of motor functions is a powerful approach for health assessment, especially among the elderly population or among subjects affected by pathologies that negatively impact their walking capabilities. This is further supported by the continuous development of wearable sensor devices, which are getting progressively smaller, cheaper, and more energy efficient. The external environment and mobility context have an impact on walking performance, hence one of the biggest challenges when remotely analysing gait episodes is the ability to detect the context within which those episodes occurred. The primary goal of this paper is the investigation of context detection for remote monitoring of daily motor functions. We aim to understand whether inertial signals sampled with wearable accelerometers, provide reliable information to classify gait-related activities as either indoor or outdoor. We explore two different approaches to this task: (1) using gait descriptors and features extracted from the input inertial signals sampled during walking episodes, together with classic machine learning algorithms, and (2) treating the input inertial signals as time series data and leveraging end-to-end state-of-the-art time series classifiers. We directly compare the two approaches through a set of experiments based on data collected from 9 healthy individuals. Our results indicate that the indoor/outdoor context can be successfully derived from inertial data streams. We also observe that time series classification models achieve better accuracy than any other feature-based models, while preserving efficiency and ease of use.
Multi-Layer Modeling of Dense Vegetation from Aerial LiDAR Scans
Apr 25, 2022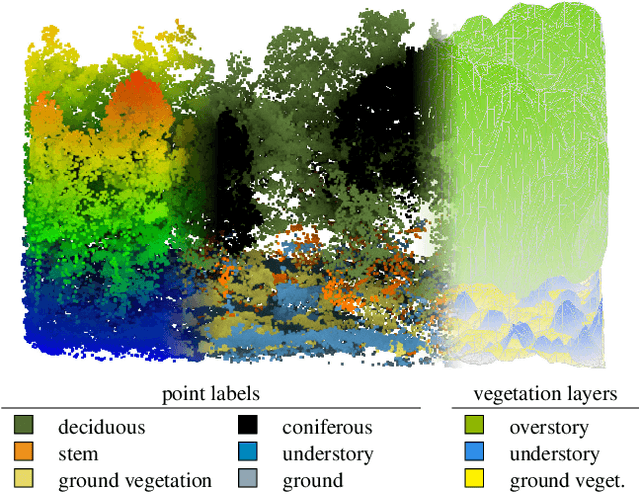

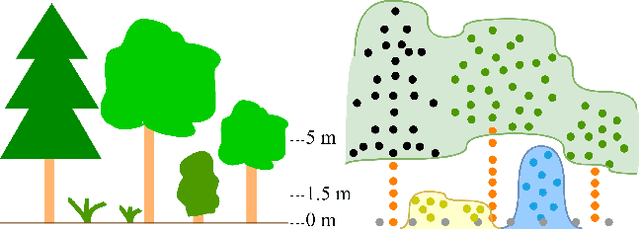
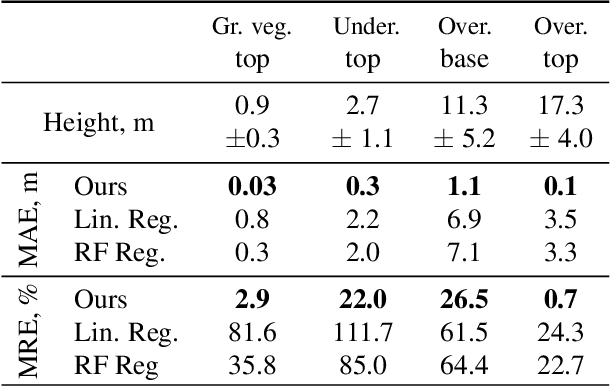
The analysis of the multi-layer structure of wild forests is an important challenge of automated large-scale forestry. While modern aerial LiDARs offer geometric information across all vegetation layers, most datasets and methods focus only on the segmentation and reconstruction of the top of canopy. We release WildForest3D, which consists of 29 study plots and over 2000 individual trees across 47 000m2 with dense 3D annotation, along with occupancy and height maps for 3 vegetation layers: ground vegetation, understory, and overstory. We propose a 3D deep network architecture predicting for the first time both 3D point-wise labels and high-resolution layer occupancy rasters simultaneously. This allows us to produce a precise estimation of the thickness of each vegetation layer as well as the corresponding watertight meshes, therefore meeting most forestry purposes. Both the dataset and the model are released in open access: https://github.com/ekalinicheva/multi_layer_vegetation.
Attention based Memory video portrait matting
Mar 21, 2022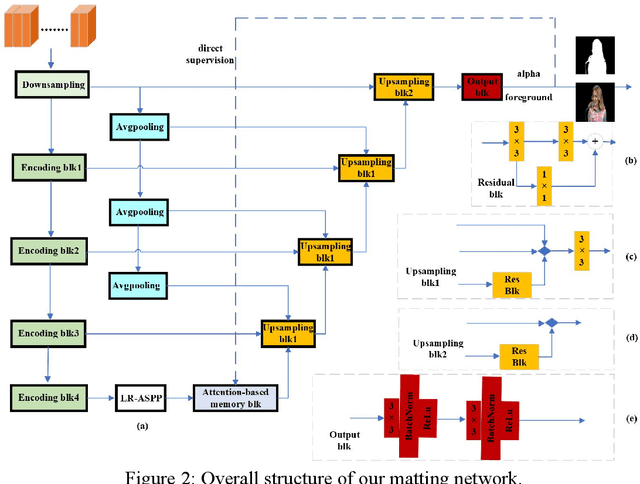

We proposed a novel trimap free video matting method based on the attention mechanism. By the nature of the problem, most existing approaches use either multiple computational expansive modules or complex algorithms to exploit temporal information fully. We designed a temporal aggregation module to compute the temporal coherence between the current frame and its two previous frames.
Low Resolution Information Also Matters: Learning Multi-Resolution Representations for Person Re-Identification
May 26, 2021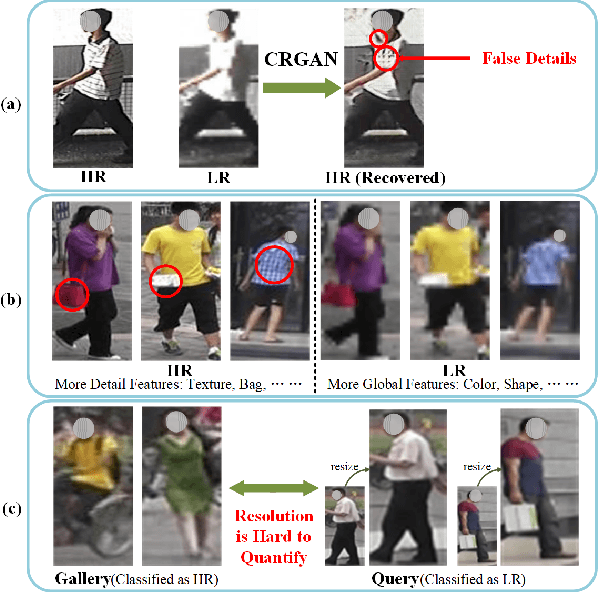
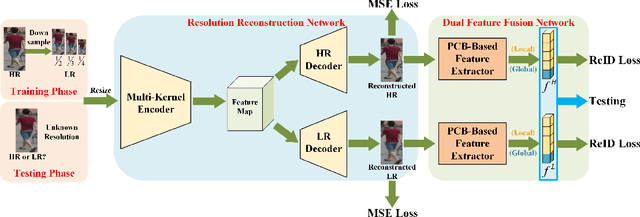
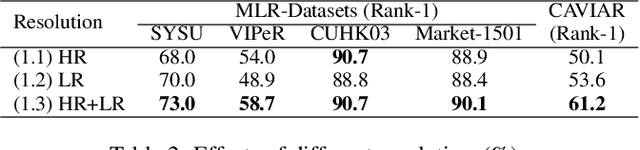
As a prevailing task in video surveillance and forensics field, person re-identification (re-ID) aims to match person images captured from non-overlapped cameras. In unconstrained scenarios, person images often suffer from the resolution mismatch problem, i.e., \emph{Cross-Resolution Person Re-ID}. To overcome this problem, most existing methods restore low resolution (LR) images to high resolution (HR) by super-resolution (SR). However, they only focus on the HR feature extraction and ignore the valid information from original LR images. In this work, we explore the influence of resolutions on feature extraction and develop a novel method for cross-resolution person re-ID called \emph{\textbf{M}ulti-Resolution \textbf{R}epresentations \textbf{J}oint \textbf{L}earning} (\textbf{MRJL}). Our method consists of a Resolution Reconstruction Network (RRN) and a Dual Feature Fusion Network (DFFN). The RRN uses an input image to construct a HR version and a LR version with an encoder and two decoders, while the DFFN adopts a dual-branch structure to generate person representations from multi-resolution images. Comprehensive experiments on five benchmarks verify the superiority of the proposed MRJL over the relevent state-of-the-art methods.
Causal learning with sufficient statistics: an information bottleneck approach
Oct 12, 2020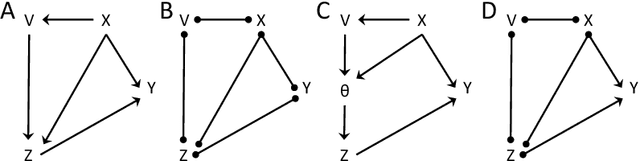
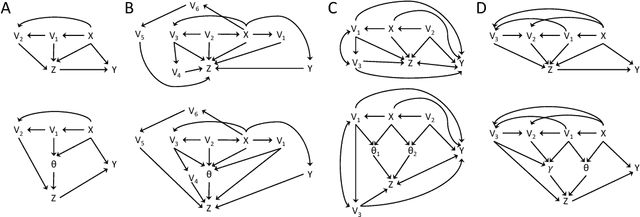
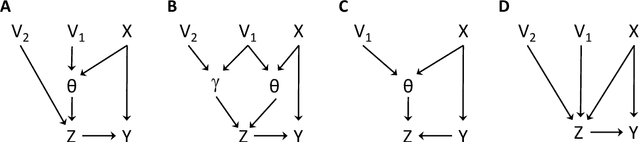
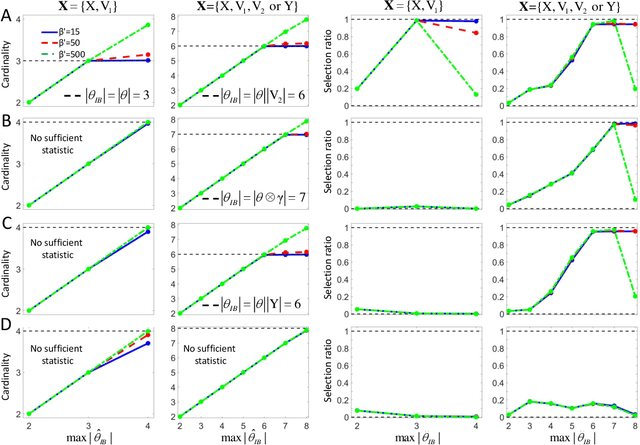
The inference of causal relationships using observational data from partially observed multivariate systems with hidden variables is a fundamental question in many scientific domains. Methods extracting causal information from conditional independencies between variables of a system are common tools for this purpose, but are limited in the lack of independencies. To surmount this limitation, we capitalize on the fact that the laws governing the generative mechanisms of a system often result in substructures embodied in the generative functional equation of a variable, which act as sufficient statistics for the influence that other variables have on it. These functional sufficient statistics constitute intermediate hidden variables providing new conditional independencies to be tested. We propose to use the Information Bottleneck method, a technique commonly applied for dimensionality reduction, to find underlying sufficient sets of statistics. Using these statistics we formulate new additional rules of causal orientation that provide causal information not obtainable from standard structure learning algorithms, which exploit only conditional independencies between observable variables. We validate the use of sufficient statistics for structure learning both with simulated systems built to contain specific sufficient statistics and with benchmark data from regulatory rules previously and independently proposed to model biological signal transduction networks.