 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Computer Science Named Entity Recognition in the Open Research Knowledge Graph
Mar 28, 2022

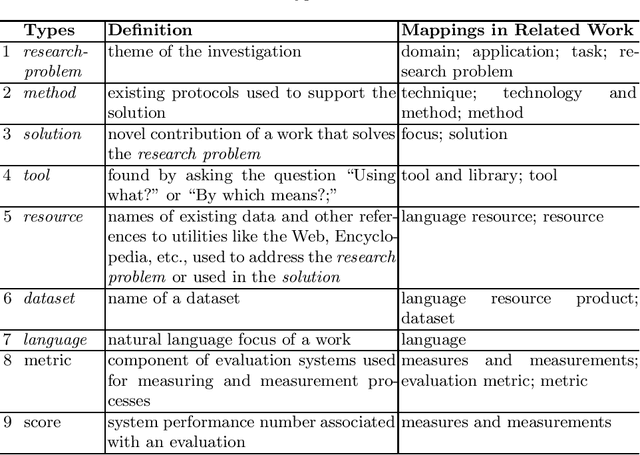
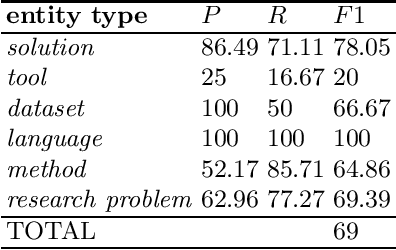
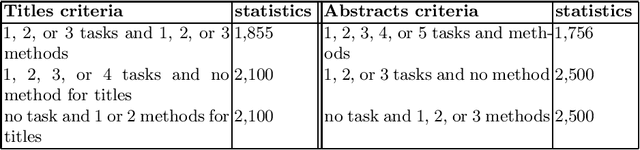
Domain-specific named entity recognition (NER) on Computer Science (CS) scholarly articles is an information extraction task that is arguably more challenging for the various annotation aims that can beset the task and has been less studied than NER in the general domain. Given that significant progress has been made on NER, we believe that scholarly domain-specific NER will receive increasing attention in the years to come. Currently, progress on CS NER -- the focus of this work -- is hampered in part by its recency and the lack of a standardized annotation aim for scientific entities/terms. This work proposes a standardized task by defining a set of seven contribution-centric scholarly entities for CS NER viz., research problem, solution, resource, language, tool, method, and dataset. Following which, its main contributions are: combines existing CS NER resources that maintain their annotation focus on the set or subset of contribution-centric scholarly entities we consider; further, noting the need for big data to train neural NER models, this work additionally supplies thousands of contribution-centric entity annotations from article titles and abstracts, thus releasing a cumulative large novel resource for CS NER; and, finally, trains a sequence labeling CS NER model inspired after state-of-the-art neural architectures from the general domain NER task. Throughout the work, several practical considerations are made which can be useful to information technology designers of the digital libraries.
A Rich Recipe Representation as Plan to Support Expressive Multi Modal Queries on Recipe Content and Preparation Process
Mar 31, 2022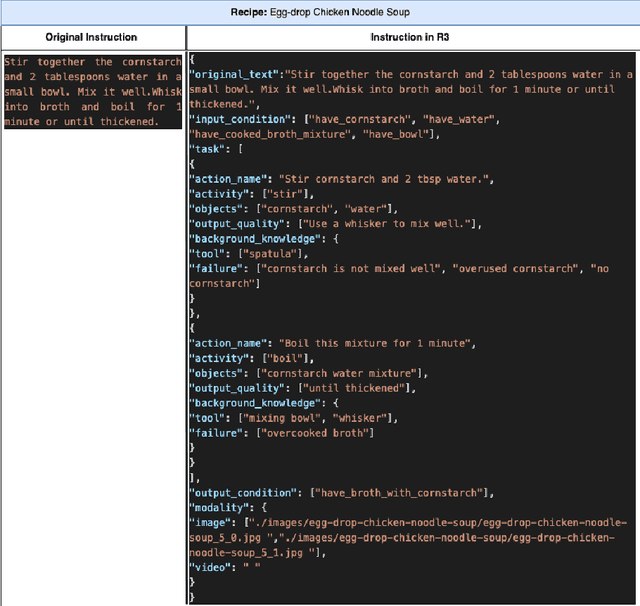
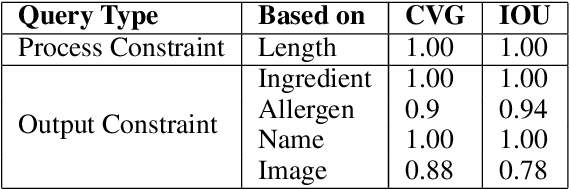
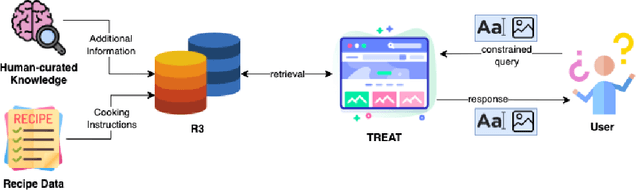
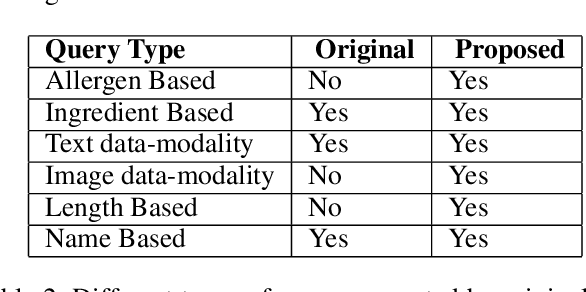
Food is not only a basic human necessity but also a key factor driving a society's health and economic well-being. As a result, the cooking domain is a popular use-case to demonstrate decision-support (AI) capabilities in service of benefits like precision health with tools ranging from information retrieval interfaces to task-oriented chatbots. An AI here should understand concepts in the food domain (e.g., recipes, ingredients), be tolerant to failures encountered while cooking (e.g., browning of butter), handle allergy-based substitutions, and work with multiple data modalities (e.g. text and images). However, the recipes today are handled as textual documents which makes it difficult for machines to read, reason and handle ambiguity. This demands a need for better representation of the recipes, overcoming the ambiguity and sparseness that exists in the current textual documents. In this paper, we discuss the construction of a machine-understandable rich recipe representation (R3), in the form of plans, from the recipes available in natural language. R3 is infused with additional knowledge such as information about allergens and images of ingredients, possible failures and tips for each atomic cooking step. To show the benefits of R3, we also present TREAT, a tool for recipe retrieval which uses R3 to perform multi-modal reasoning on the recipe's content (plan objects - ingredients and cooking tools), food preparation process (plan actions and time), and media type (image, text). R3 leads to improved retrieval efficiency and new capabilities that were hither-to not possible in textual representation.
Contrastive Learning for Automotive mmWave Radar Detection Points Based Instance Segmentation
Mar 13, 2022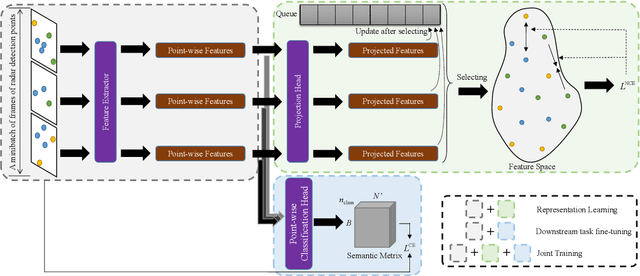
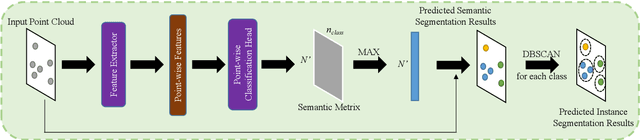
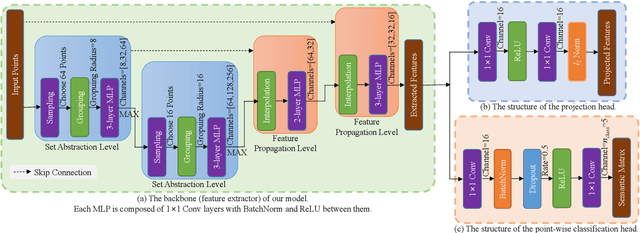
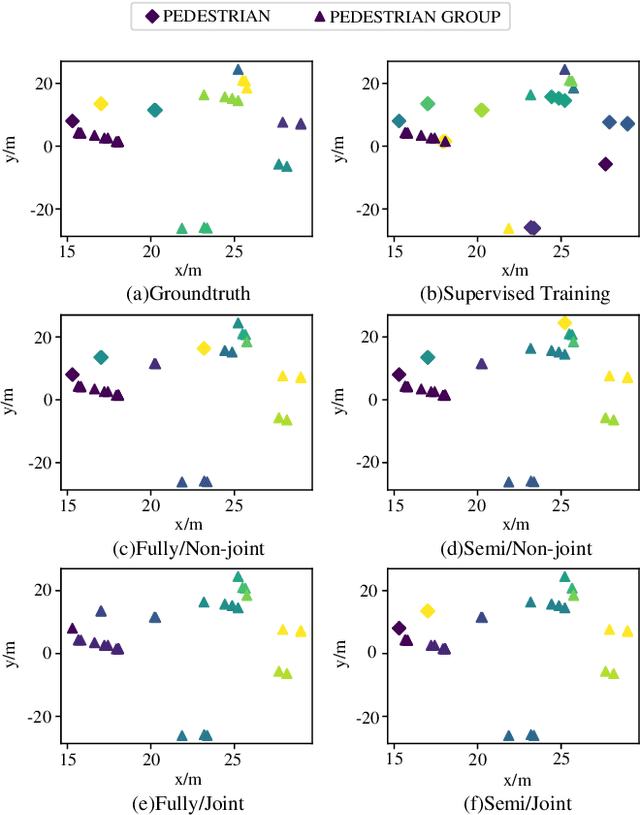
The automotive mmWave radar plays a key role in advanced driver assistance systems (ADAS) and autonomous driving. Deep learning-based instance segmentation enables real-time object identification from the radar detection points. In the conventional training process, accurate annotation is the key. However, high-quality annotations of radar detection points are challenging to achieve due to their ambiguity and sparsity. To address this issue, we propose a contrastive learning approach for implementing radar detection points-based instance segmentation. We define the positive and negative samples according to the ground-truth label, apply the contrastive loss to train the model first, and then perform training for the following downstream task. In addition, these two steps can be merged into one, and pseudo labels can be generated for the unlabeled data to improve the performance further. Thus, there are four different training settings for our method. Experiments show that when the ground-truth information is only available for 5% of the training data, our method still achieves a comparable performance to the approach trained in a supervised manner with 100% ground-truth information.
GAM(e) changer or not? An evaluation of interpretable machine learning models based on additive model constraints
Apr 19, 2022
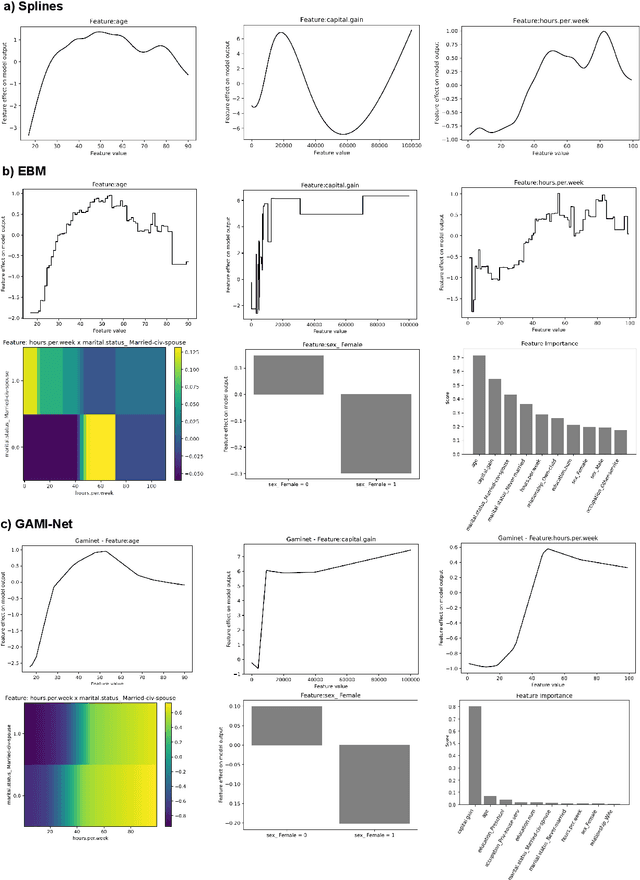
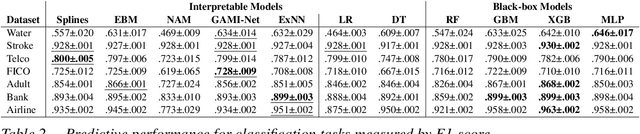
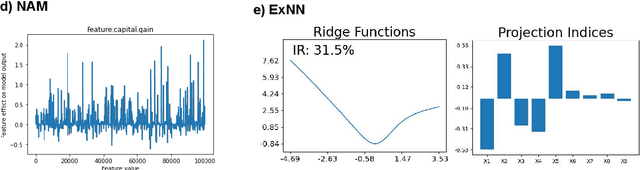
The number of information systems (IS) studies dealing with explainable artificial intelligence (XAI) is currently exploding as the field demands more transparency about the internal decision logic of machine learning (ML) models. However, most techniques subsumed under XAI provide post-hoc-analytical explanations, which have to be considered with caution as they only use approximations of the underlying ML model. Therefore, our paper investigates a series of intrinsically interpretable ML models and discusses their suitability for the IS community. More specifically, our focus is on advanced extensions of generalized additive models (GAM) in which predictors are modeled independently in a non-linear way to generate shape functions that can capture arbitrary patterns but remain fully interpretable. In our study, we evaluate the prediction qualities of five GAMs as compared to six traditional ML models and assess their visual outputs for model interpretability. On this basis, we investigate their merits and limitations and derive design implications for further improvements.
Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes
Apr 28, 2022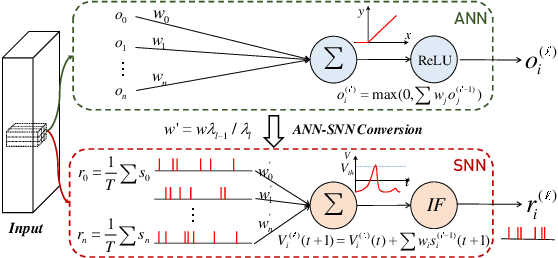
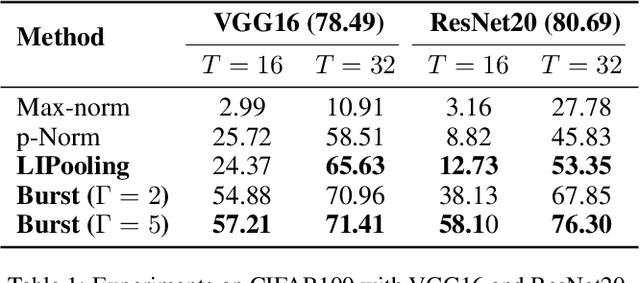
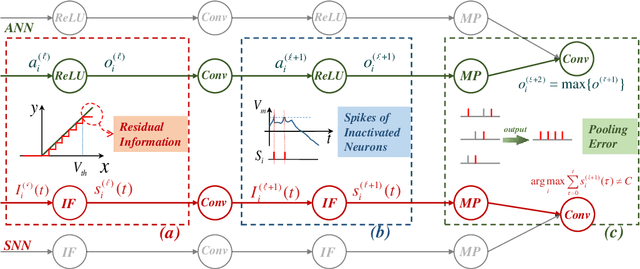
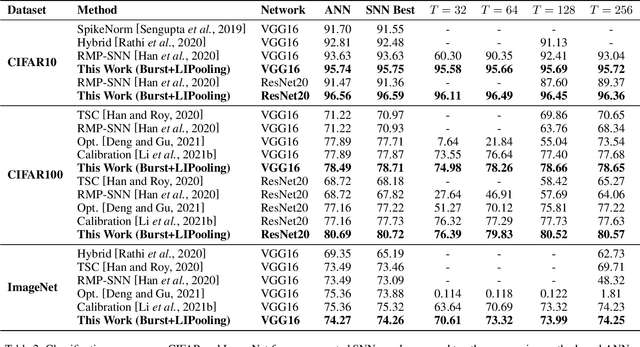
Spiking neural network (SNN), as a brain-inspired energy-efficient neural network, has attracted the interest of researchers. While the training of spiking neural networks is still an open problem. One effective way is to map the weight of trained ANN to SNN to achieve high reasoning ability. However, the converted spiking neural network often suffers from performance degradation and a considerable time delay. To speed up the inference process and obtain higher accuracy, we theoretically analyze the errors in the conversion process from three perspectives: the differences between IF and ReLU, time dimension, and pooling operation. We propose a neuron model for releasing burst spikes, a cheap but highly efficient method to solve residual information. In addition, Lateral Inhibition Pooling (LIPooling) is proposed to solve the inaccuracy problem caused by MaxPooling in the conversion process. Experimental results on CIFAR and ImageNet demonstrate that our algorithm is efficient and accurate. For example, our method can ensure nearly lossless conversion of SNN and only use about 1/10 (less than 100) simulation time under 0.693$\times$ energy consumption of the typical method. Our code is available at https://github.com/Brain-Inspired-Cognitive-Engine/Conversion_Burst.
Jensen-Shannon Information Based Characterization of the Generalization Error of Learning Algorithms
Oct 23, 2020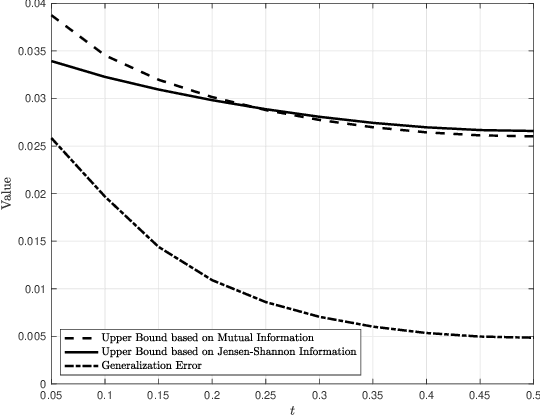
Generalization error bounds are critical to understanding the performance of machine learning models. In this work, we propose a new information-theoretic based generalization error upper bound applicable to supervised learning scenarios. We show that our general bound can specialize in various previous bounds. We also show that our general bound can be specialized under some conditions to a new bound involving the Jensen-Shannon information between a random variable modelling the set of training samples and another random variable modelling the set of hypotheses. We also prove that our bound can be tighter than mutual information-based bounds under some conditions.
There is a Time and Place for Reasoning Beyond the Image
Mar 28, 2022
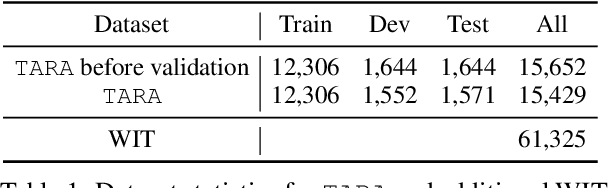

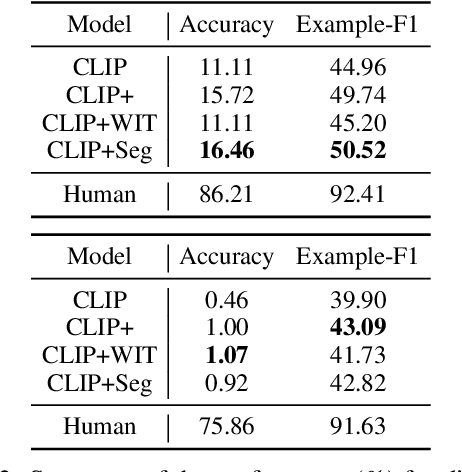
Images are often more significant than only the pixels to human eyes, as we can infer, associate, and reason with contextual information from other sources to establish a more complete picture. For example, in Figure 1, we can find a way to identify the news articles related to the picture through segment-wise understandings of the signs, the buildings, the crowds, and more. This reasoning could provide the time and place the image was taken, which will help us in subsequent tasks, such as automatic storyline construction, correction of image source in intended effect photographs, and upper-stream processing such as image clustering for certain location or time. In this work, we formulate this problem and introduce TARA: a dataset with 16k images with their associated news, time, and location, automatically extracted from New York Times, and an additional 61k examples as distant supervision from WIT. On top of the extractions, we present a crowdsourced subset in which we believe it is possible to find the images' spatio-temporal information for evaluation purpose. We show that there exists a $70\%$ gap between a state-of-the-art joint model and human performance, which is slightly filled by our proposed model that uses segment-wise reasoning, motivating higher-level vision-language joint models that can conduct open-ended reasoning with world knowledge. The data and code are publicly available at https://github.com/zeyofu/TARA.
Unsupervised Speech Decomposition via Triple Information Bottleneck
Apr 23, 2020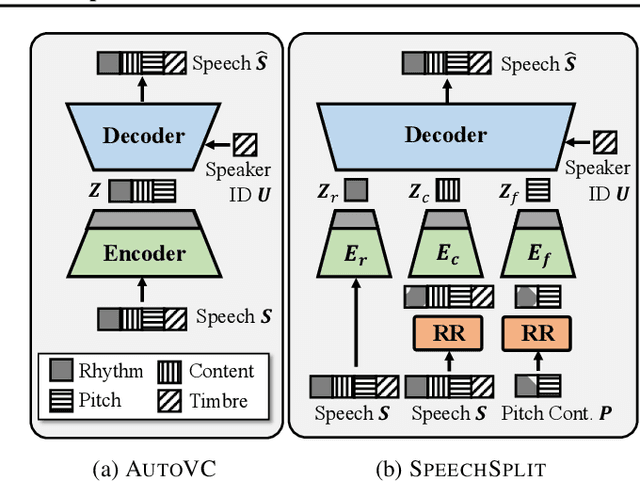
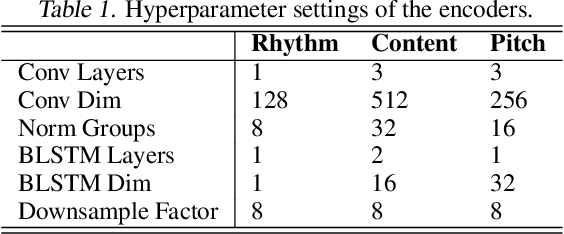
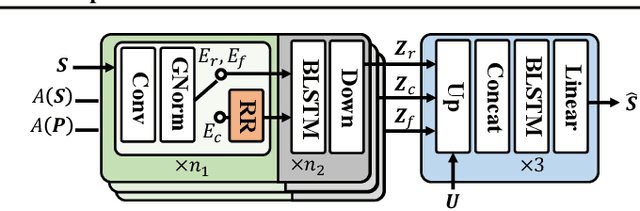

Speech information can be roughly decomposed into four components: language content, timbre, pitch, and rhythm. Obtaining disentangled representations of these components is useful in many speech analysis and generation applications. Recently, state-of-the-art voice conversion systems have led to speech representations that can disentangle speaker-dependent and independent information. However, these systems can only disentangle timbre, while information about pitch, rhythm and content is still mixed together. Further disentangling the remaining speech components is an under-determined problem in the absence of explicit annotations for each component, which are difficult and expensive to obtain. In this paper, we propose SpeechSplit, which can blindly decompose speech into its four components by introducing three carefully designed information bottlenecks. SpeechSplit is among the first algorithms that can separately perform style transfer on timbre, pitch and rhythm without text labels.
Deriving the Traveler Behavior Information from Social Media: A Case Study in Manhattan with Twitter
Jan 27, 2021
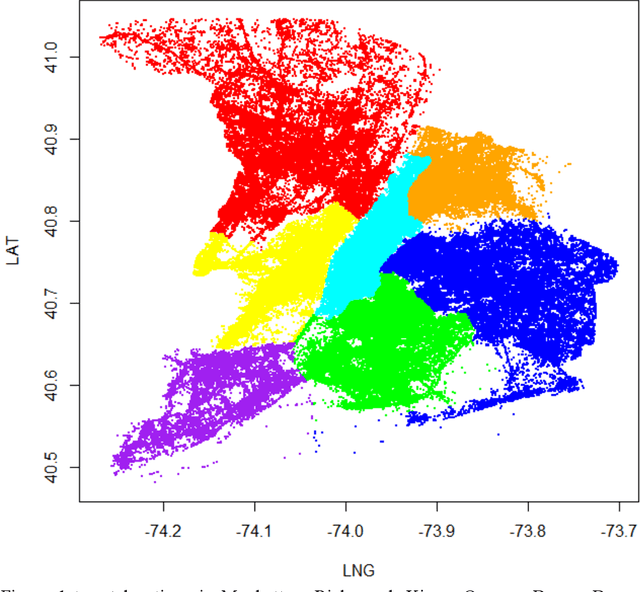

Social media platforms, such as Twitter, provide a totally new perspective in dealing with the traffic problems and is anticipated to complement the traditional methods. The geo-tagged tweets can provide the Twitter users' location information and is being applied in traveler behavior analysis. This paper explores the full potentials of Twitter in deriving travel behavior information and conducts a case study in Manhattan Area. A systematic method is proposed to extract displacement information from Twitter locations. Our study shows that Twitter has a unique demographics which combine not only local residents but also the tourists or passengers. For individual user, Twitter can uncover his/her travel behavior features including the time-of-day and location distributions on both weekdays and weekends. For all Twitter users, the aggregated travel behavior results also show that the time-of-day travel patterns in Manhattan Island resemble that of the traffic flow; the identification of OD pattern is also promising by comparing with the results of travel survey.
GiraffeDet: A Heavy-Neck Paradigm for Object Detection
Feb 09, 2022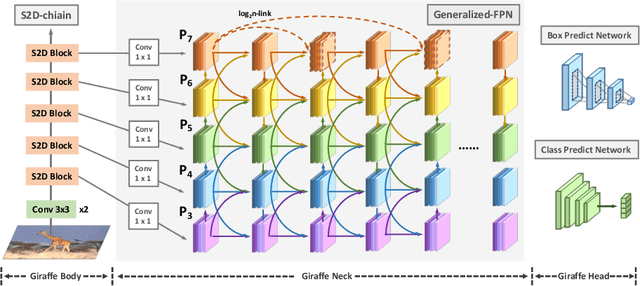
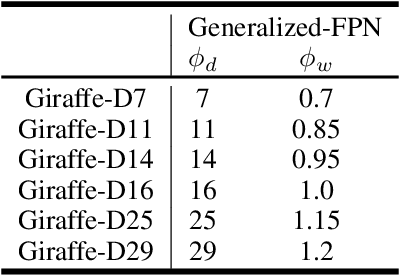
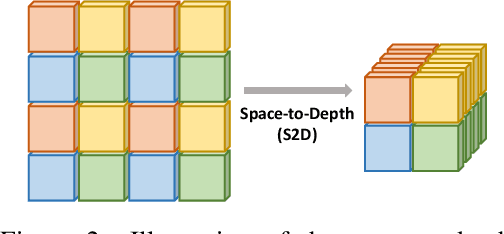
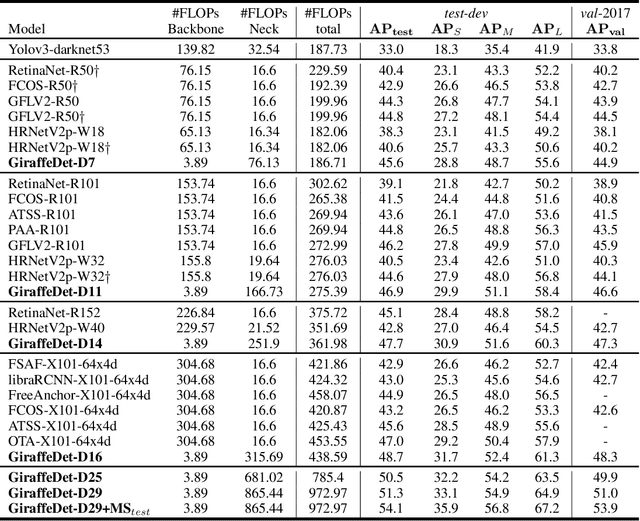
In conventional object detection frameworks, a backbone body inherited from image recognition models extracts deep latent features and then a neck module fuses these latent features to capture information at different scales. As the resolution in object detection is much larger than in image recognition, the computational cost of the backbone often dominates the total inference cost. This heavy-backbone design paradigm is mostly due to the historical legacy when transferring image recognition models to object detection rather than an end-to-end optimized design for object detection. In this work, we show that such paradigm indeed leads to sub-optimal object detection models. To this end, we propose a novel heavy-neck paradigm, GiraffeDet, a giraffe-like network for efficient object detection. The GiraffeDet uses an extremely lightweight backbone and a very deep and large neck module which encourages dense information exchange among different spatial scales as well as different levels of latent semantics simultaneously. This design paradigm allows detectors to process the high-level semantic information and low-level spatial information at the same priority even in the early stage of the network, making it more effective in detection tasks. Numerical evaluations on multiple popular object detection benchmarks show that GiraffeDet consistently outperforms previous SOTA models across a wide spectrum of resource constraints.