 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LPGNet: Link Private Graph Networks for Node Classification
May 06, 2022
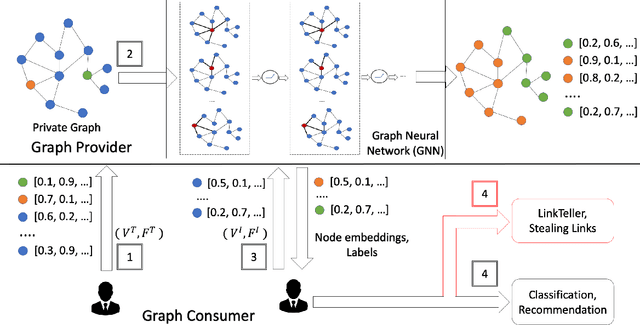

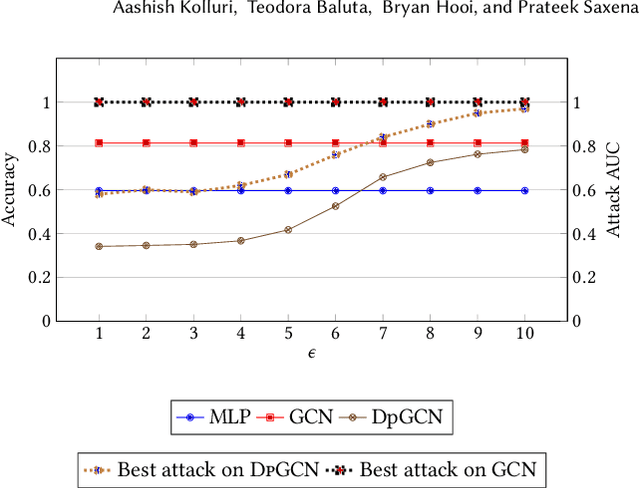
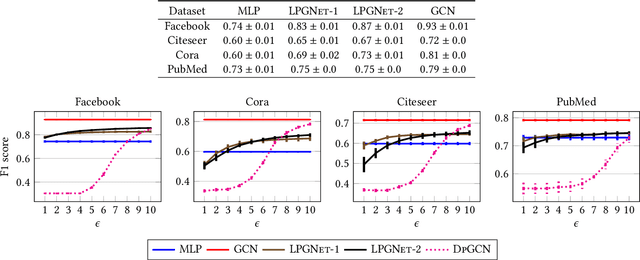
Classification tasks on labeled graph-structured data have many important applications ranging from social recommendation to financial modeling. Deep neural networks are increasingly being used for node classification on graphs, wherein nodes with similar features have to be given the same label. Graph convolutional networks (GCNs) are one such widely studied neural network architecture that perform well on this task. However, powerful link-stealing attacks on GCNs have recently shown that even with black-box access to the trained model, inferring which links (or edges) are present in the training graph is practical. In this paper, we present a new neural network architecture called LPGNet for training on graphs with privacy-sensitive edges. LPGNet provides differential privacy (DP) guarantees for edges using a novel design for how graph edge structure is used during training. We empirically show that LPGNet models often lie in the sweet spot between providing privacy and utility: They can offer better utility than "trivially" private architectures which use no edge information (e.g., vanilla MLPs) and better resilience against existing link-stealing attacks than vanilla GCNs which use the full edge structure. LPGNet also offers consistently better privacy-utility tradeoffs than DPGCN, which is the state-of-the-art mechanism for retrofitting differential privacy into conventional GCNs, in most of our evaluated datasets.
Scheduling with Speed Predictions
May 02, 2022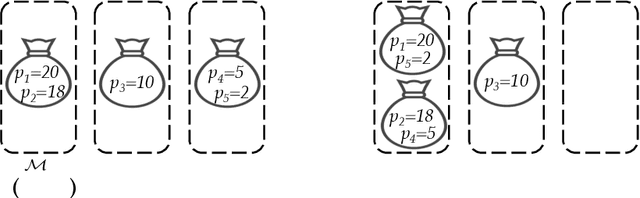
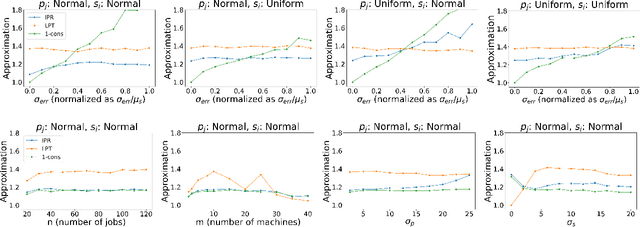
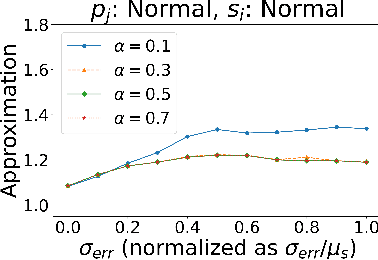
Algorithms with predictions is a recent framework that has been used to overcome pessimistic worst-case bounds in incomplete information settings. In the context of scheduling, very recent work has leveraged machine-learned predictions to design algorithms that achieve improved approximation ratios in settings where the processing times of the jobs are initially unknown. In this paper, we study the speed-robust scheduling problem where the speeds of the machines, instead of the processing times of the jobs, are unknown and augment this problem with predictions. Our main result is an algorithm that achieves a $\min\{\eta^2(1+\epsilon)^2(1+\alpha), (1+\epsilon)(2 + 2/\alpha)\}$ approximation, for any constants $\alpha, \epsilon \in (0,1)$, where $\eta \geq 1$ is the prediction error. When the predictions are accurate, this approximation improves over the previously best known approximation of $2-1/m$ for speed-robust scheduling, where $m$ is the number of machines, while simultaneously maintaining a worst-case approximation of $(1+\epsilon)(2 + 2/\alpha)$ even when the predictions are wrong. In addition, we obtain improved approximations for the special cases of equal and infinitesimal job sizes, and we complement our algorithmic results with lower bounds. Finally, we empirically evaluate our algorithm against existing algorithms for speed-robust scheduling.
Price graphs: Utilizing the structural information of financial time series for stock prediction
Jun 04, 2021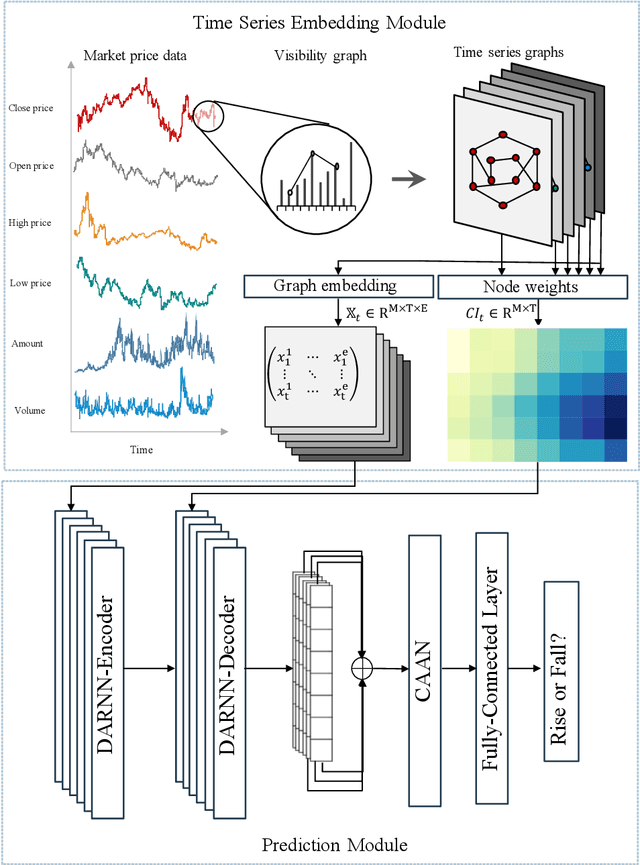
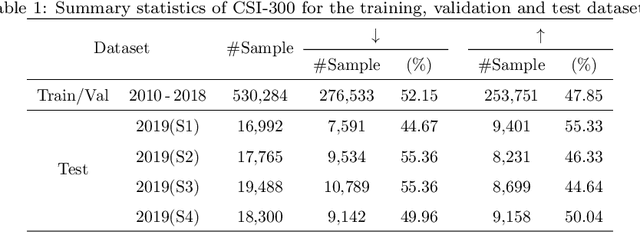
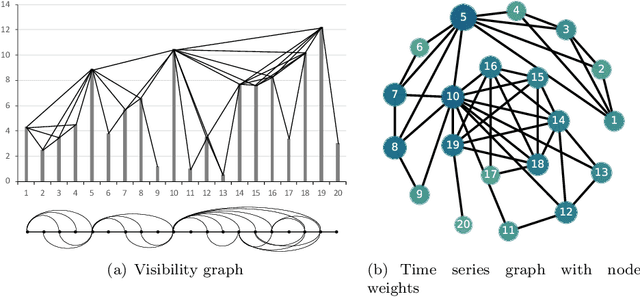
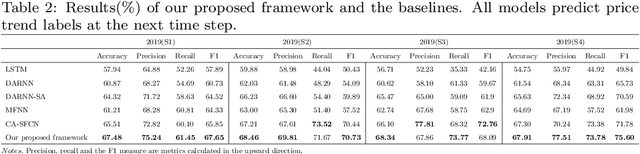
Stock prediction, with the purpose of forecasting the future price trends of stocks, is crucial for maximizing profits from stock investments. While great research efforts have been devoted to exploiting deep neural networks for improved stock prediction, the existing studies still suffer from two major issues. First, the long-range dependencies in time series are not sufficiently captured. Second, the chaotic property of financial time series fundamentally lowers prediction performance. In this study, we propose a novel framework to address both issues regarding stock prediction. Specifically, in terms of transforming time series into complex networks, we convert market price series into graphs. Then, structural information, referring to associations among temporal points and the node weights, is extracted from the mapped graphs to resolve the problems regarding long-range dependencies and the chaotic property. We take graph embeddings to represent the associations among temporal points as the prediction model inputs. Node weights are used as a priori knowledge to enhance the learning of temporal attention. The effectiveness of our proposed framework is validated using real-world stock data, and our approach obtains the best performance among several state-of-the-art benchmarks. Moreover, in the conducted trading simulations, our framework further obtains the highest cumulative profits. Our results supplement the existing applications of complex network methods in the financial realm and provide insightful implications for investment applications regarding decision support in financial markets.
$\textit{latent}$-GLAT: Glancing at Latent Variables for Parallel Text Generation
Apr 05, 2022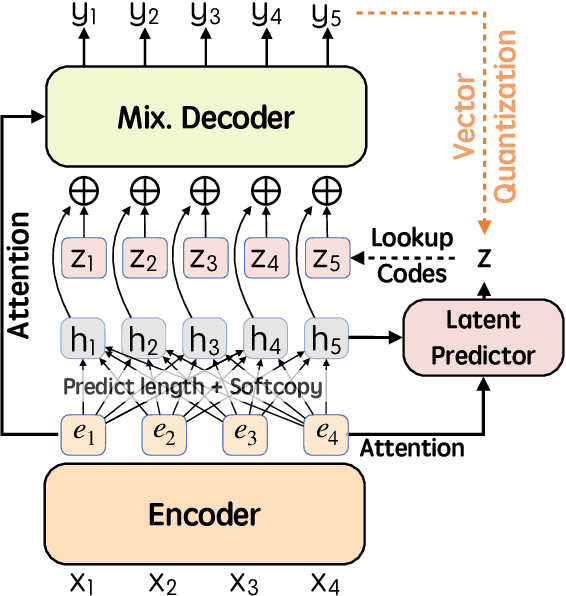
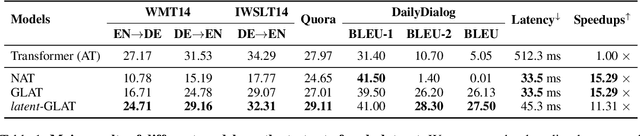
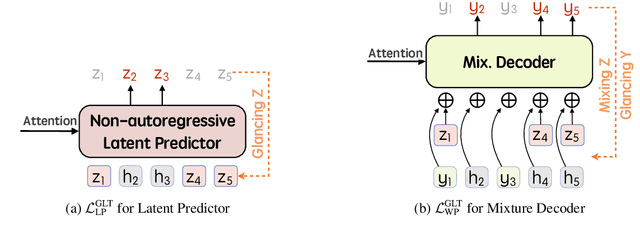
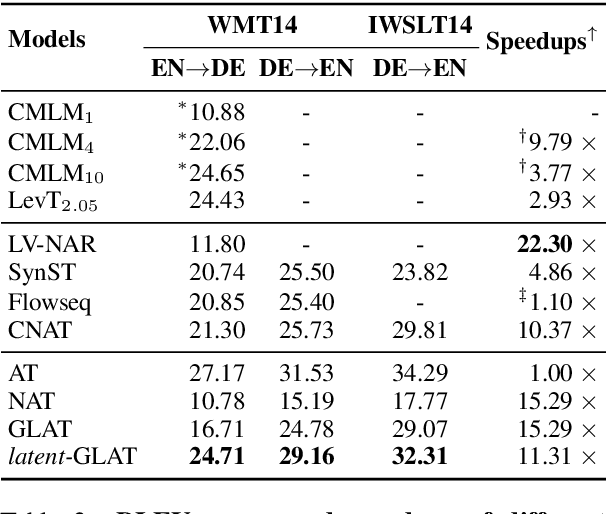
Recently, parallel text generation has received widespread attention due to its success in generation efficiency. Although many advanced techniques are proposed to improve its generation quality, they still need the help of an autoregressive model for training to overcome the one-to-many multi-modal phenomenon in the dataset, limiting their applications. In this paper, we propose $\textit{latent}$-GLAT, which employs the discrete latent variables to capture word categorical information and invoke an advanced curriculum learning technique, alleviating the multi-modality problem. Experiment results show that our method outperforms strong baselines without the help of an autoregressive model, which further broadens the application scenarios of the parallel decoding paradigm.
Mutual Information Maximization for Robust Plannable Representations
May 16, 2020
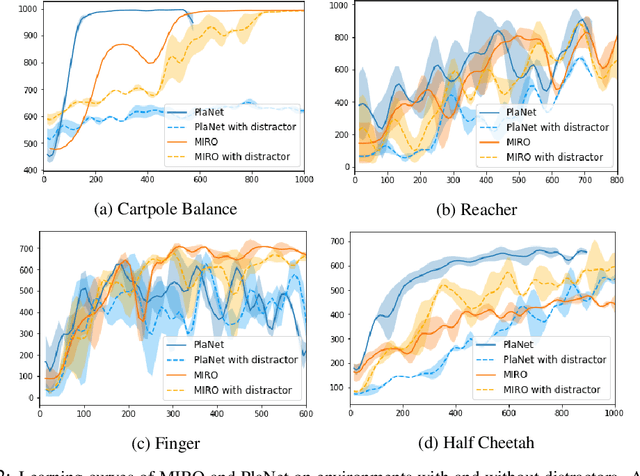
Extending the capabilities of robotics to real-world complex, unstructured environments requires the need of developing better perception systems while maintaining low sample complexity. When dealing with high-dimensional state spaces, current methods are either model-free or model-based based on reconstruction objectives. The sample inefficiency of the former constitutes a major barrier for applying them to the real-world. The later, while they present low sample complexity, they learn latent spaces that need to reconstruct every single detail of the scene. In real environments, the task typically just represents a small fraction of the scene. Reconstruction objectives suffer in such scenarios as they capture all the unnecessary components. In this work, we present MIRO, an information theoretic representational learning algorithm for model-based reinforcement learning. We design a latent space that maximizes the mutual information with the future information while being able to capture all the information needed for planning. We show that our approach is more robust than reconstruction objectives in the presence of distractors and cluttered scenes
Local Hypergraph-based Nested Named Entity Recognition as Query-based Sequence Labeling
Apr 25, 2022

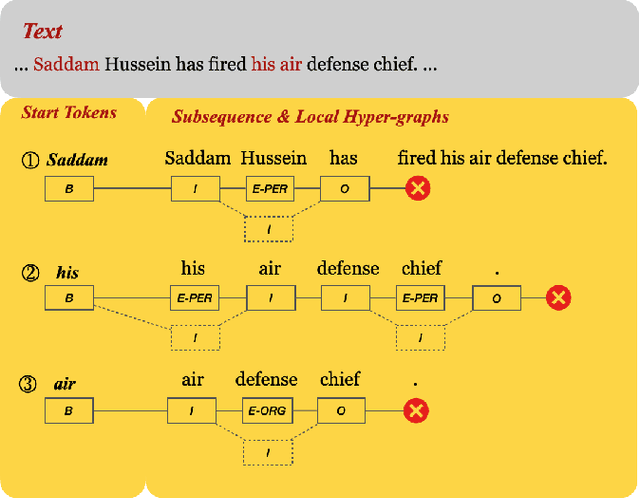
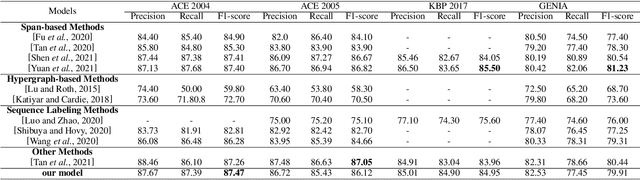
There has been a growing academic interest in the recognition of nested named entities in many domains. We tackle the task with a novel local hypergraph-based method: We first propose start token candidates and generate corresponding queries with their surrounding context, then use a query-based sequence labeling module to form a local hypergraph for each candidate. An end token estimator is used to correct the hypergraphs and get the final predictions. Compared to span-based approaches, our method is free of the high computation cost of span sampling and the risk of losing long entities. Sequential prediction makes it easier to leverage information in word order inside nested structures, and richer representations are built with a local hypergraph. Experiments show that our proposed method outperforms all the previous hypergraph-based and sequence labeling approaches with large margins on all four nested datasets. It achieves a new state-of-the-art F1 score on the ACE 2004 dataset and competitive F1 scores with previous state-of-the-art methods on three other nested NER datasets: ACE 2005, GENIA, and KBP 2017.
Table Structure Recognition with Conditional Attention
Mar 08, 2022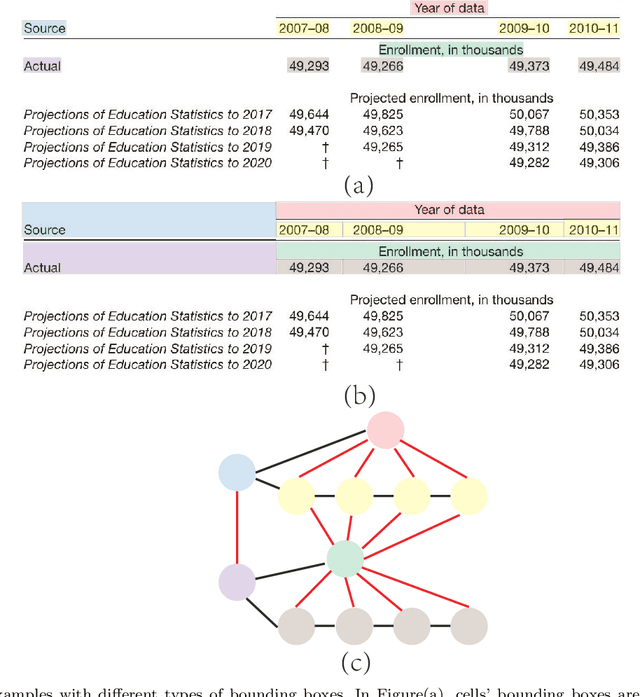

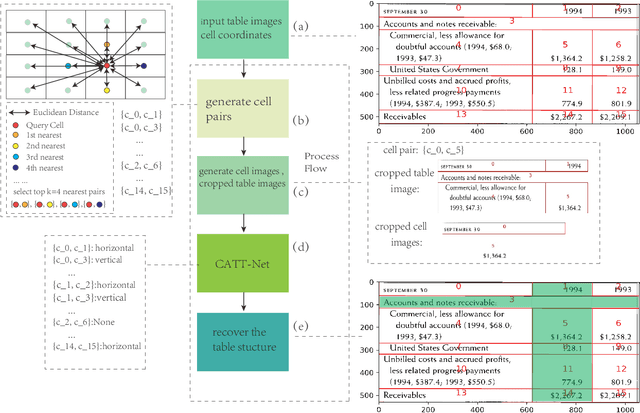

Tabular data in digital documents is widely used to express compact and important information for readers. However, it is challenging to parse tables from unstructured digital documents, such as PDFs and images, into machine-readable format because of the complexity of table structures and the missing of meta-information. Table Structure Recognition (TSR) problem aims to recognize the structure of a table and transform the unstructured tables into a structured and machine-readable format so that the tabular data can be further analysed by the down-stream tasks, such as semantic modeling and information retrieval. In this study, we hypothesize that a complicated table structure can be represented by a graph whose vertices and edges represent the cells and association between cells, respectively. Then we define the table structure recognition problem as a cell association classification problem and propose a conditional attention network (CATT-Net). The experimental results demonstrate the superiority of our proposed method over the state-of-the-art methods on various datasets. Besides, we investigate whether the alignment of a cell bounding box or a text-focused approach has more impact on the model performance. Due to the lack of public dataset annotations based on these two approaches, we further annotate the ICDAR2013 dataset providing both types of bounding boxes, which can be a new benchmark dataset for evaluating the methods in this field. Experimental results show that the alignment of a cell bounding box can help improve the Micro-averaged F1 score from 0.915 to 0.963, and the Macro-average F1 score from 0.787 to 0.923.
Quantification of Robotic Surgeries with Vision-Based Deep Learning
May 06, 2022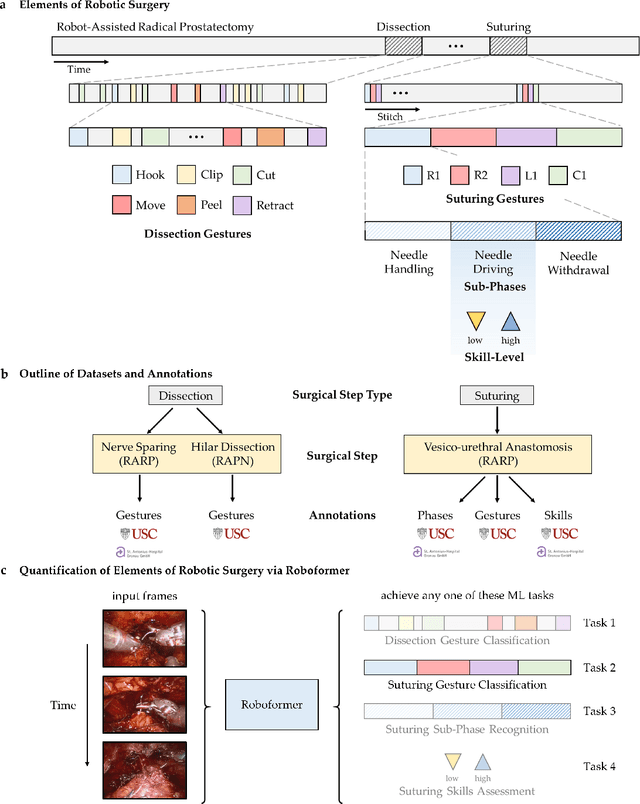
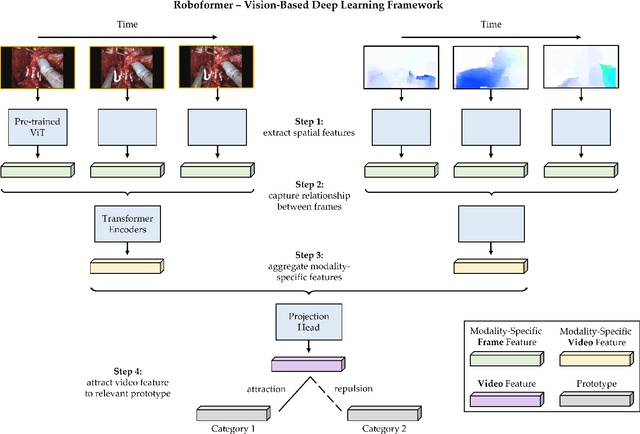
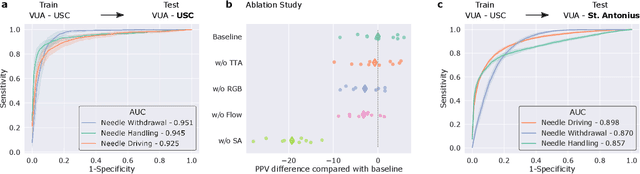
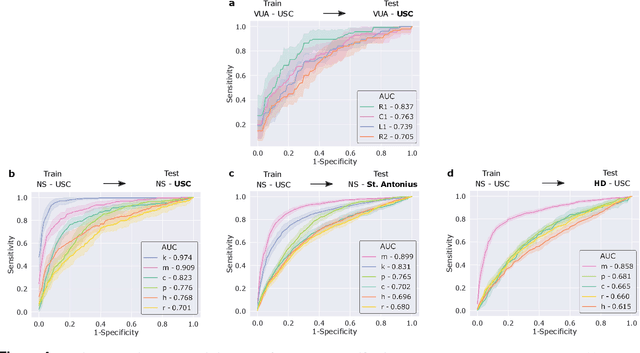
Surgery is a high-stakes domain where surgeons must navigate critical anatomical structures and actively avoid potential complications while achieving the main task at hand. Such surgical activity has been shown to affect long-term patient outcomes. To better understand this relationship, whose mechanics remain unknown for the majority of surgical procedures, we hypothesize that the core elements of surgery must first be quantified in a reliable, objective, and scalable manner. We believe this is a prerequisite for the provision of surgical feedback and modulation of surgeon performance in pursuit of improved patient outcomes. To holistically quantify surgeries, we propose a unified deep learning framework, entitled Roboformer, which operates exclusively on videos recorded during surgery to independently achieve multiple tasks: surgical phase recognition (the what of surgery), gesture classification and skills assessment (the how of surgery). We validated our framework on four video-based datasets of two commonly-encountered types of steps (dissection and suturing) within minimally-invasive robotic surgeries. We demonstrated that our framework can generalize well to unseen videos, surgeons, medical centres, and surgical procedures. We also found that our framework, which naturally lends itself to explainable findings, identified relevant information when achieving a particular task. These findings are likely to instill surgeons with more confidence in our framework's behaviour, increasing the likelihood of clinical adoption, and thus paving the way for more targeted surgical feedback.
MANet: Improving Video Denoising with a Multi-Alignment Network
Feb 20, 2022
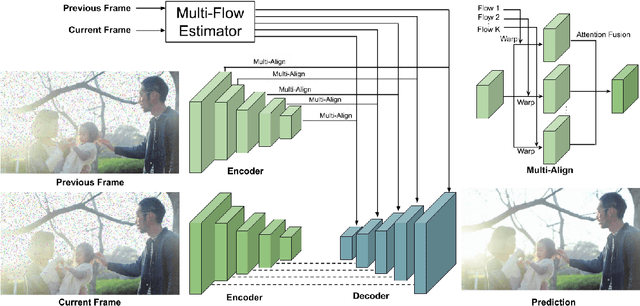
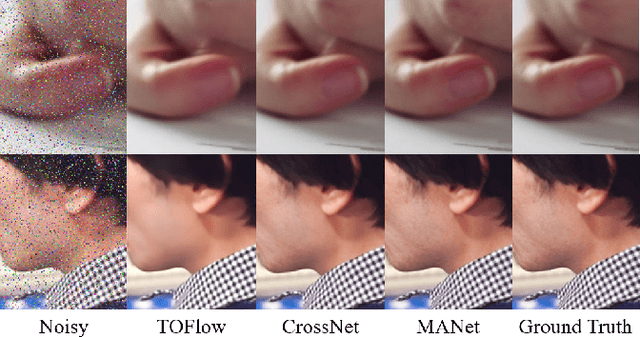
In video denoising, the adjacent frames often provide very useful information, but accurate alignment is needed before such information can be harnassed. In this work, we present a multi-alignment network, which generates multiple flow proposals followed by attention-based averaging. It serves to mimics the non-local mechanism, suppressing noise by averaging multiple observations. Our approach can be applied to various state-of-the-art models that are based on flow estimation. Experiments on a large-scale video dataset demonstrate that our method improves the denoising baseline model by 0.2dB, and further reduces the parameters by 47% with model distillation.
Identifying Scenarios in Field Data to Enable Validation of Highly Automated Driving Systems
Mar 09, 2022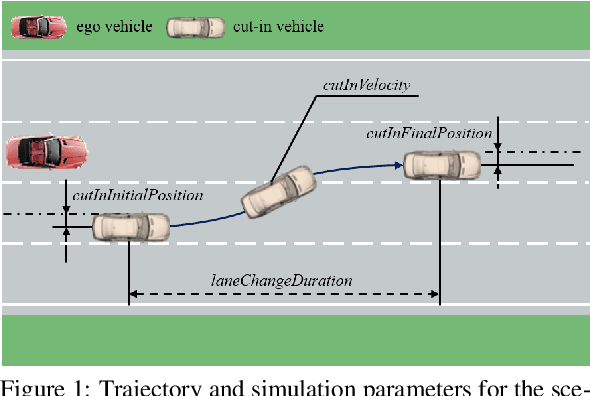
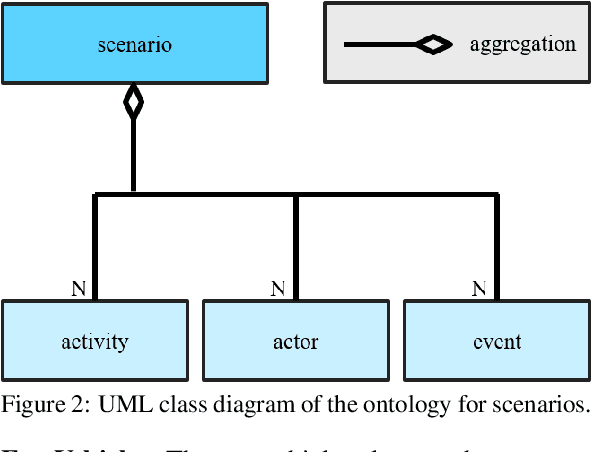

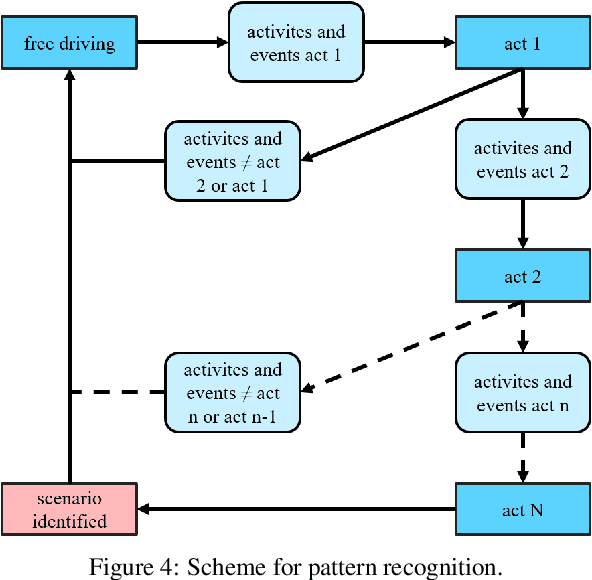
Scenario-based approaches for the validation of highly automated driving functions are based on the search for safety-critical characteristics of driving scenarios using software-in-the-loop simulations. This search requires information about the shape and probability of scenarios in real-world traffic. The scope of this work is to develop a method that identifies redefined logical driving scenarios in field data, so that this information can be derived subsequently. More precisely, a suitable approach is developed, implemented and validated using a traffic scenario as an example. The presented methodology is based on qualitative modelling of scenarios, which can be detected in abstracted field data. The abstraction is achieved by using universal elements of an ontology represented by a domain model. Already published approaches for such an abstraction are discussed and concretised with regard to the given application. By examining a first set of test data, it is shown that the developed method is a suitable approach for the identification of further driving scenarios.