 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Accurate Unsupervised Method for Joint Entity Alignment and Dangling Entity Detection
Mar 10, 2022
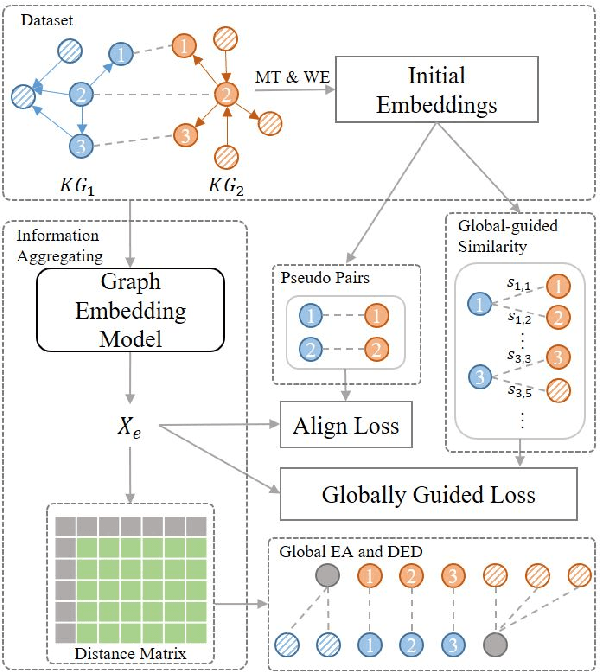
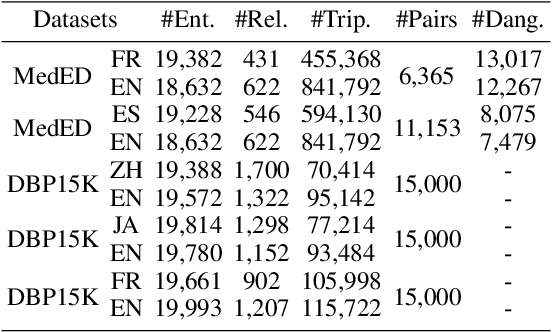
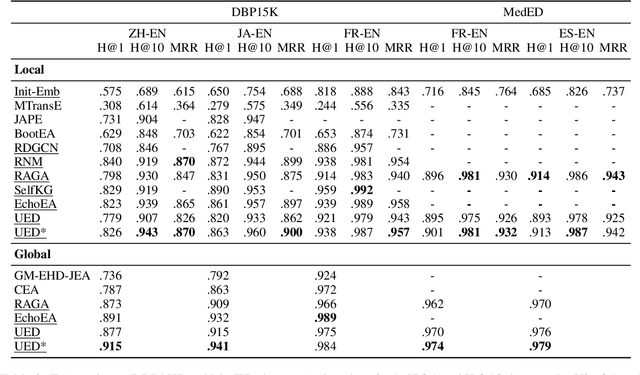
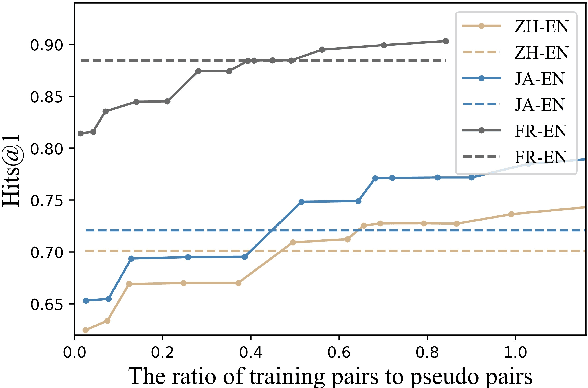
Knowledge graph integration typically suffers from the widely existing dangling entities that cannot find alignment cross knowledge graphs (KGs). The dangling entity set is unavailable in most real-world scenarios, and manually mining the entity pairs that consist of entities with the same meaning is labor-consuming. In this paper, we propose a novel accurate Unsupervised method for joint Entity alignment (EA) and Dangling entity detection (DED), called UED. The UED mines the literal semantic information to generate pseudo entity pairs and globally guided alignment information for EA and then utilizes the EA results to assist the DED. We construct a medical cross-lingual knowledge graph dataset, MedED, providing data for both the EA and DED tasks. Extensive experiments demonstrate that in the EA task, UED achieves EA results comparable to those of state-of-the-art supervised EA baselines and outperforms the current state-of-the-art EA methods by combining supervised EA data. For the DED task, UED obtains high-quality results without supervision.
Reasoning over Public and Private Data in Retrieval-Based Systems
Mar 14, 2022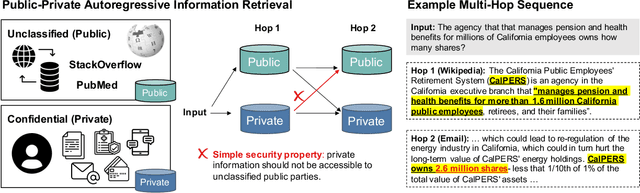


Users and organizations are generating ever-increasing amounts of private data from a wide range of sources. Incorporating private data is important to personalize open-domain applications such as question-answering, fact-checking, and personal assistants. State-of-the-art systems for these tasks explicitly retrieve relevant information to a user question from a background corpus before producing an answer. While today's retrieval systems assume the corpus is fully accessible, users are often unable or unwilling to expose their private data to entities hosting public data. We first define the PUBLIC-PRIVATE AUTOREGRESSIVE INFORMATION RETRIEVAL (PAIR) privacy framework for the novel retrieval setting over multiple privacy scopes. We then argue that an adequate benchmark is missing to study PAIR since existing textual benchmarks require retrieving from a single data distribution. However, public and private data intuitively reflect different distributions, motivating us to create ConcurrentQA, the first textual QA benchmark to require concurrent retrieval over multiple data-distributions. Finally, we show that existing systems face large privacy vs. performance tradeoffs when applied to our proposed retrieval setting and investigate how to mitigate these tradeoffs.
Science Checker: Extractive-Boolean Question Answering For Scientific Fact Checking
Apr 29, 2022
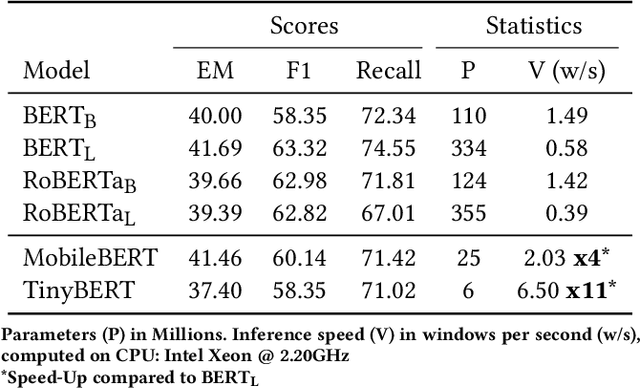
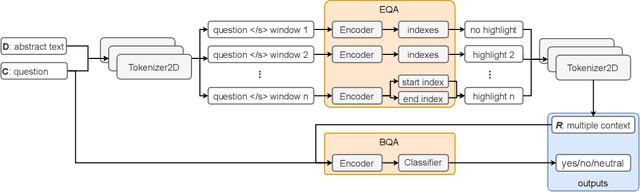
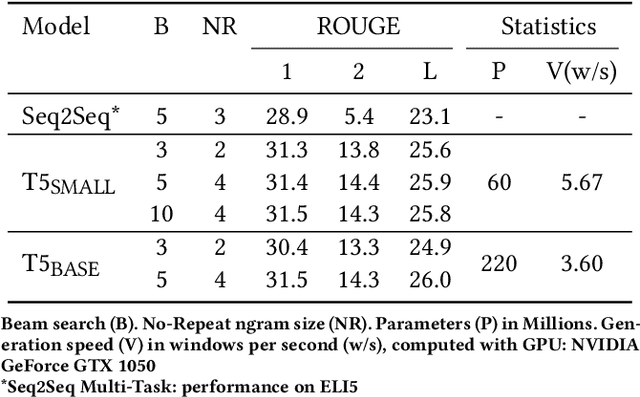
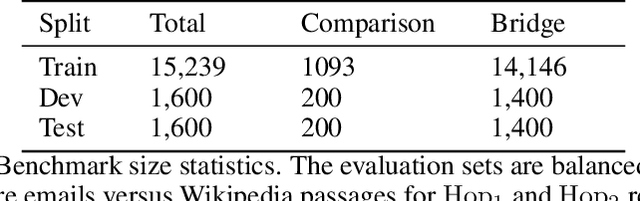
With the explosive growth of scientific publications, making the synthesis of scientific knowledge and fact checking becomes an increasingly complex task. In this paper, we propose a multi-task approach for verifying the scientific questions based on a joint reasoning from facts and evidence in research articles. We propose an intelligent combination of (1) an automatic information summarization and (2) a Boolean Question Answering which allows to generate an answer to a scientific question from only extracts obtained after summarization. Thus on a given topic, our proposed approach conducts structured content modeling based on paper abstracts to answer a scientific question while highlighting texts from paper that discuss the topic. We based our final system on an end-to-end Extractive Question Answering (EQA) combined with a three outputs classification model to perform in-depth semantic understanding of a question to illustrate the aggregation of multiple responses. With our light and fast proposed architecture, we achieved an average error rate of 4% and a F1-score of 95.6%. Our results are supported via experiments with two QA models (BERT, RoBERTa) over 3 Million Open Access (OA) articles in the medical and health domains on Europe PMC.
* 8 pages, 4 figures
Brain Principles Programming
Mar 14, 2022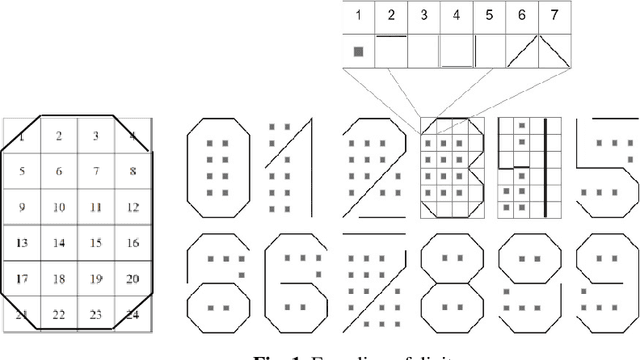
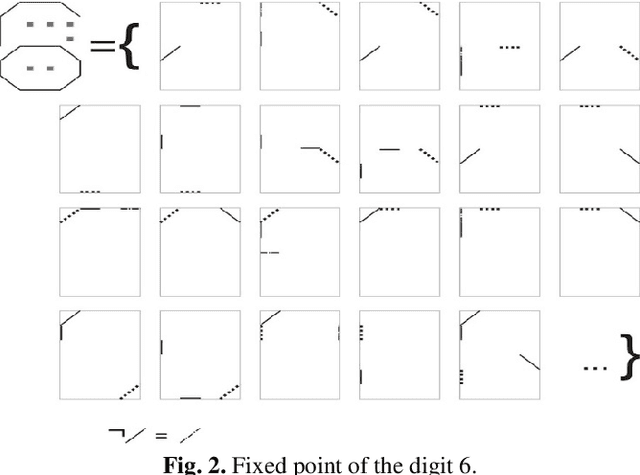
In the monograph, STRONG ARTIFICIAL INTELLIGENCE. On the Approaches to Superintelligence, published by Sberbank, provides a cross-disciplinary review of general artificial intelligence. As an anthropomorphic direction of research, it considers Brain Principles Programming, BPP) the formalization of universal mechanisms (principles) of the brain's work with information, which are implemented at all levels of the organization of nervous tissue. This monograph provides a formalization of these principles in terms of the category theory. However, this formalization is not enough to develop algorithms for working with information. In this paper, for the description and modeling of Brain Principles Programming, it is proposed to apply mathematical models and algorithms developed by us earlier that model cognitive functions, which are based on well-known physiological, psychological and other natural science theories. The paper uses mathematical models and algorithms of the following theories: P.K.Anokhin's Theory of Functional Brain Systems, Eleonor Rosh's prototypical categorization theory, Bob Rehter's theory of causal models and natural classification. As a result, the formalization of the BPP is obtained and computer examples are given that demonstrate the algorithm's operation.
Which Discriminator for Cooperative Text Generation?
Apr 25, 2022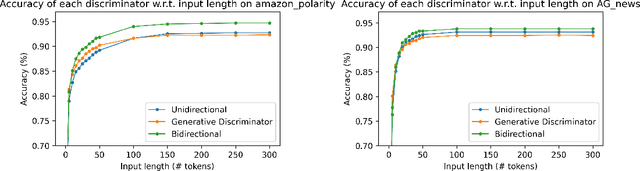

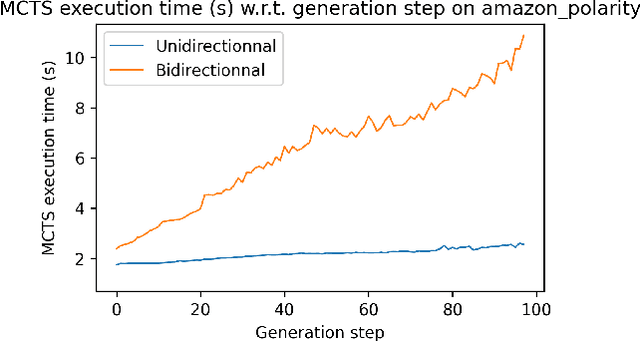
Language models generate texts by successively predicting probability distributions for next tokens given past ones. A growing field of interest tries to leverage external information in the decoding process so that the generated texts have desired properties, such as being more natural, non toxic, faithful, or having a specific writing style. A solution is to use a classifier at each generation step, resulting in a cooperative environment where the classifier guides the decoding of the language model distribution towards relevant texts for the task at hand. In this paper, we examine three families of (transformer-based) discriminators for this specific task of cooperative decoding: bidirectional, left-to-right and generative ones. We evaluate the pros and cons of these different types of discriminators for cooperative generation, exploring respective accuracy on classification tasks along with their impact on the resulting sample quality and computational performances. We also provide the code of a batched implementation of the powerful cooperative decoding strategy used for our experiments, the Monte Carlo Tree Search, working with each discriminator for Natural Language Generation.
Ultra-low Latency Spiking Neural Networks with Spatio-Temporal Compression and Synaptic Convolutional Block
Mar 18, 2022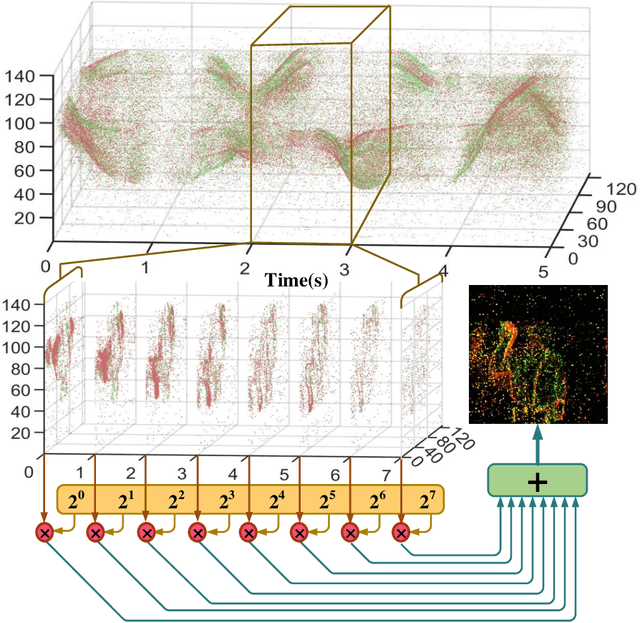
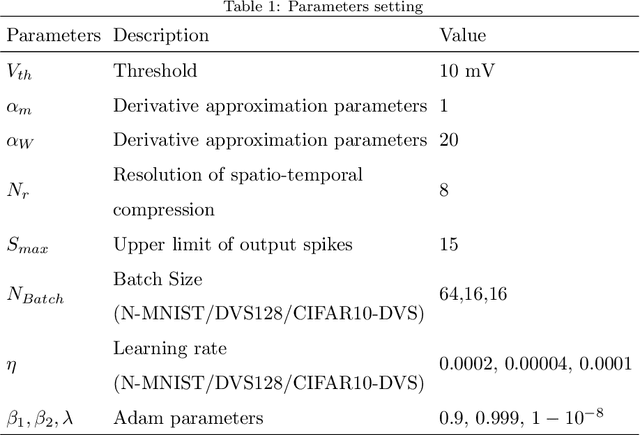
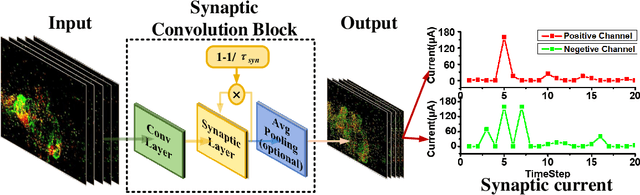
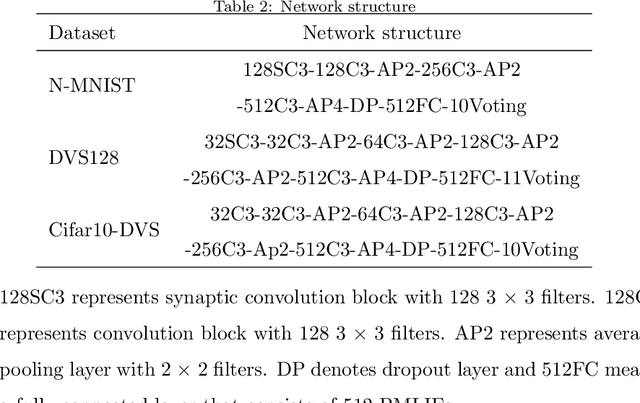
Spiking neural networks (SNNs), as one of the brain-inspired models, has spatio-temporal information processing capability, low power feature, and high biological plausibility. The effective spatio-temporal feature makes it suitable for event streams classification. However, neuromorphic datasets, such as N-MNIST, CIFAR10-DVS, DVS128-gesture, need to aggregate individual events into frames with a new higher temporal resolution for event stream classification, which causes high training and inference latency. In this work, we proposed a spatio-temporal compression method to aggregate individual events into a few time steps of synaptic current to reduce the training and inference latency. To keep the accuracy of SNNs under high compression ratios, we also proposed a synaptic convolutional block to balance the dramatic change between adjacent time steps. And multi-threshold Leaky Integrate-and-Fire (LIF) with learnable membrane time constant is introduced to increase its information processing capability. We evaluate the proposed method for event streams classification tasks on neuromorphic N-MNIST, CIFAR10-DVS, DVS128 gesture datasets. The experiment results show that our proposed method outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps.
Restoring Negative Information in Few-Shot Object Detection
Oct 22, 2020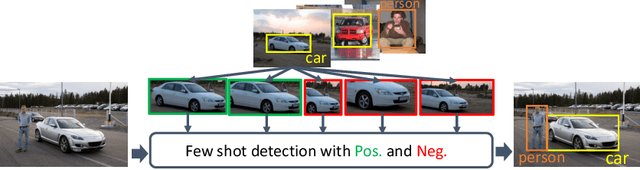
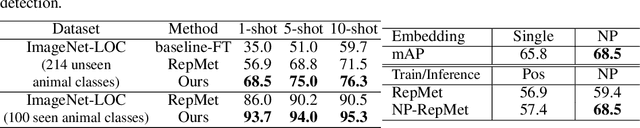
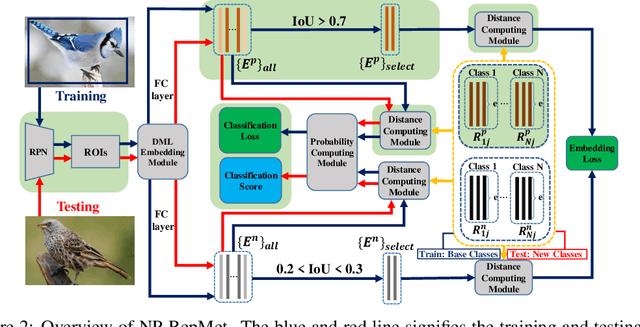

Few-shot learning has recently emerged as a new challenge in the deep learning field: unlike conventional methods that train the deep neural networks (DNNs) with a large number of labeled data, it asks for the generalization of DNNs on new classes with few annotated samples. Recent advances in few-shot learning mainly focus on image classification while in this paper we focus on object detection. The initial explorations in few-shot object detection tend to simulate a classification scenario by using the positive proposals in images with respect to certain object class while discarding the negative proposals of that class. Negatives, especially hard negatives, however, are essential to the embedding space learning in few-shot object detection. In this paper, we restore the negative information in few-shot object detection by introducing a new negative- and positive-representative based metric learning framework and a new inference scheme with negative and positive representatives. We build our work on a recent few-shot pipeline RepMet with several new modules to encode negative information for both training and testing. Extensive experiments on ImageNet-LOC and PASCAL VOC show our method substantially improves the state-of-the-art few-shot object detection solutions. Our code is available at https://github.com/yang-yk/NP-RepMet.
Deep Neural Convolutive Matrix Factorization for Articulatory Representation Decomposition
Apr 08, 2022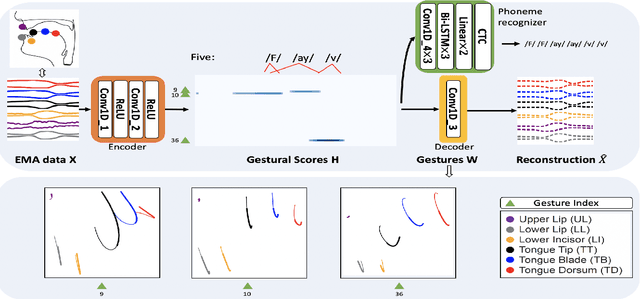
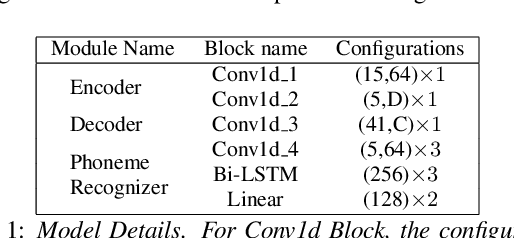
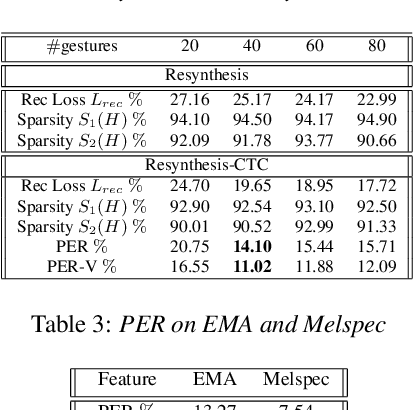
Most of the research on data-driven speech representation learning has focused on raw audios in an end-to-end manner, paying little attention to their internal phonological or gestural structure. This work, investigating the speech representations derived from articulatory kinematics signals, uses a neural implementation of convolutive sparse matrix factorization to decompose the articulatory data into interpretable gestures and gestural scores. By applying sparse constraints, the gestural scores leverage the discrete combinatorial properties of phonological gestures. Phoneme recognition experiments were additionally performed to show that gestural scores indeed code phonological information successfully. The proposed work thus makes a bridge between articulatory phonology and deep neural networks to leverage informative, intelligible, interpretable,and efficient speech representations.
Ultrathin, high-speed, all-optical photoacoustic endomicroscopy probe for guiding minimally invasive surgery
May 06, 2022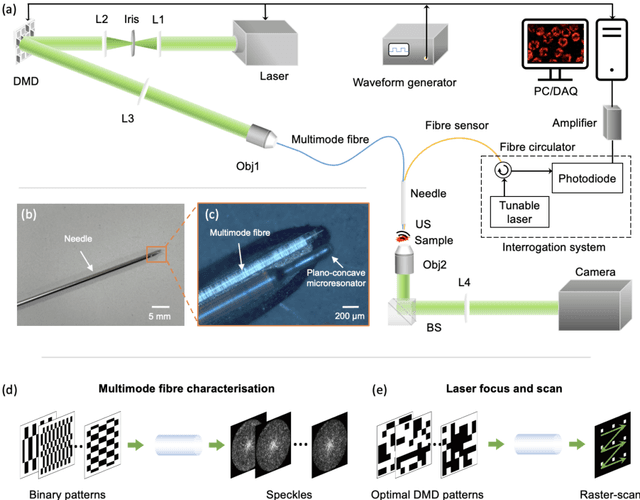
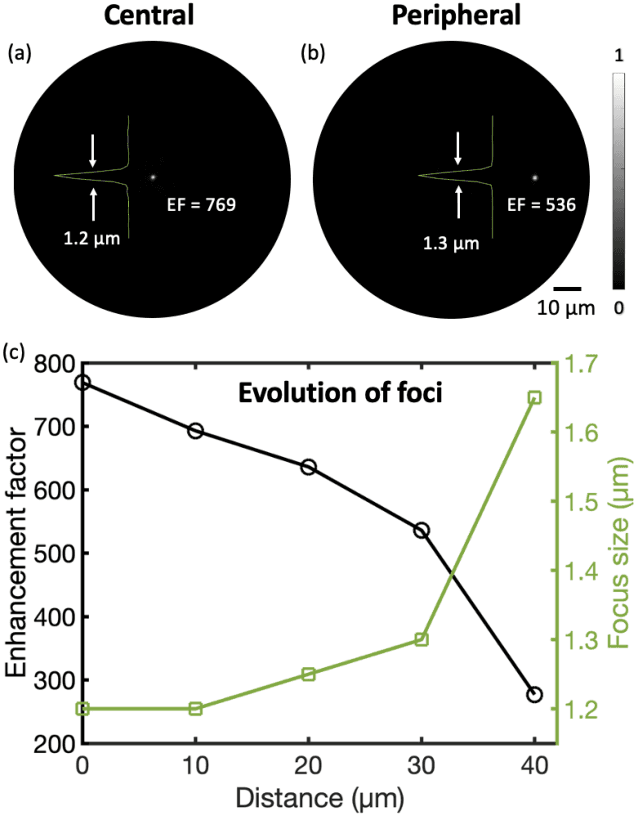
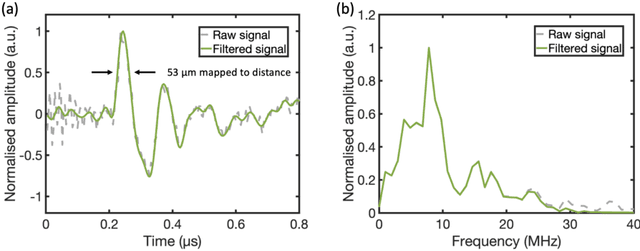
Photoacoustic (PA) endoscopy has shown significant potential for clinical diagnosis and surgical guidance. Multimode fibres (MMFs) are becoming increasing attractive for the development of miniature endoscopy probes owing to ultrathin size, low cost and diffraction-limited spatial resolution enabled by wavefront shaping. However, current MMF-based PA endomicroscopy probes are either limited by a bulky ultrasound detector or a low imaging speed which hindered their usability. In this work, we report the development of a highly miniaturised and high-speed PA endomicroscopy probe that is integrated within the cannula of a 20 gauge medical needle. This probe comprises a MMF for delivering the PA excitation light and a single-mode optical fibre with a plano-concave microresonator for ultrasound detection. Wavefront shaping with a digital micromirror device enabled rapid raster-scanning of a focused light spot at the distal end of the MMF for tissue interrogation. High-resolution PA imaging of mouse red blood cells covering an area 100 microns in diameter was achieved with the needle probe at ~3 frames per second. Mosaicing imaging was performed after fibre characterisation by translating the needle probe to enlarge the field-of-view in real-time. The developed ultrathin PA endomicroscopy probe is promising for guiding minimally invasive surgery by providing functional, molecular and microstructural information of tissue in real-time.
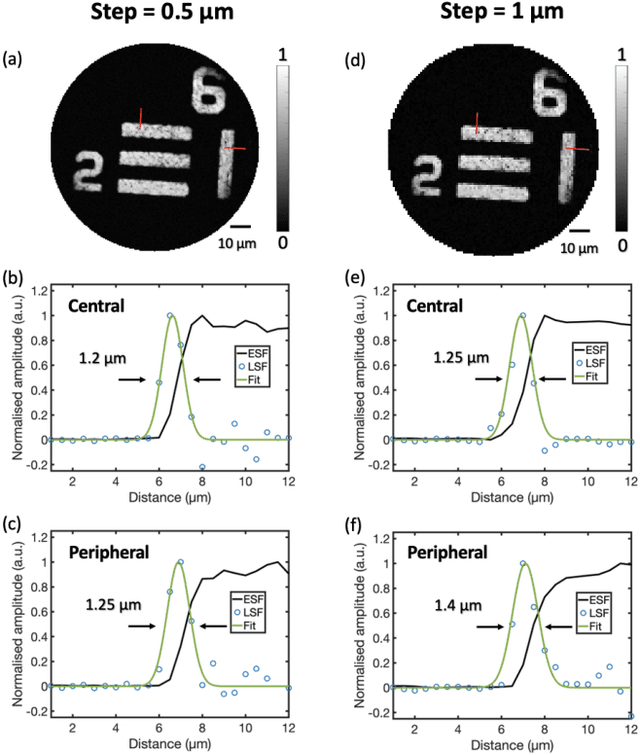
Fourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022
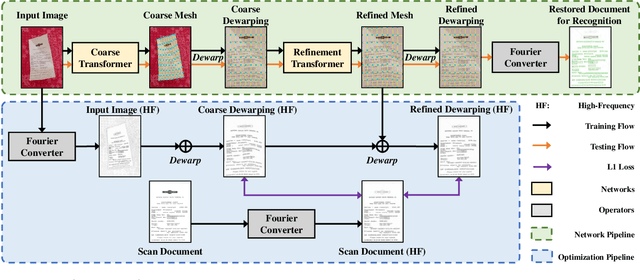
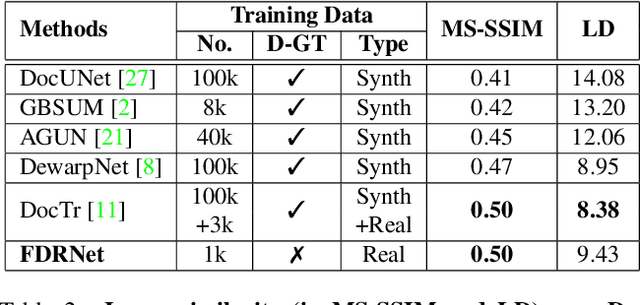
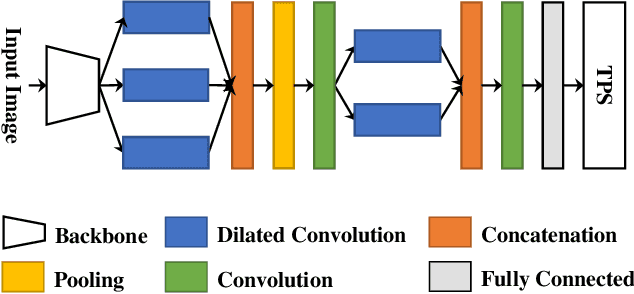
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.