 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022
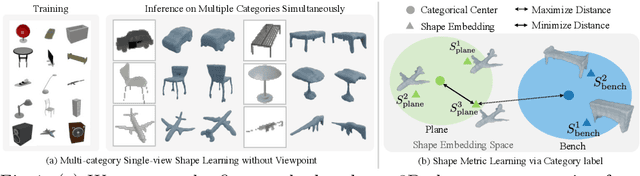

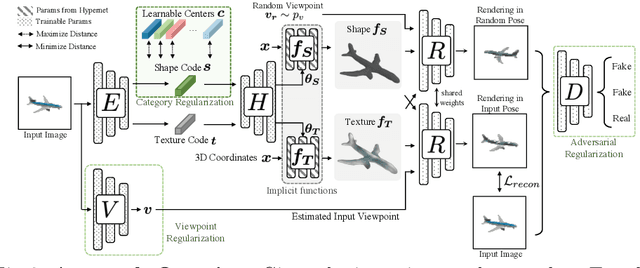
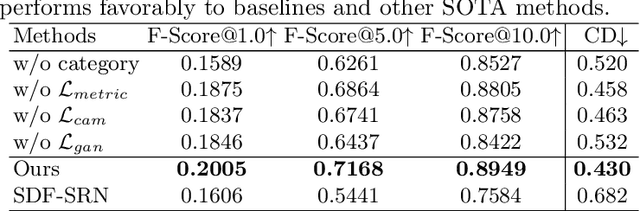
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.
An Accurate Unsupervised Method for Joint Entity Alignment and Dangling Entity Detection
Mar 10, 2022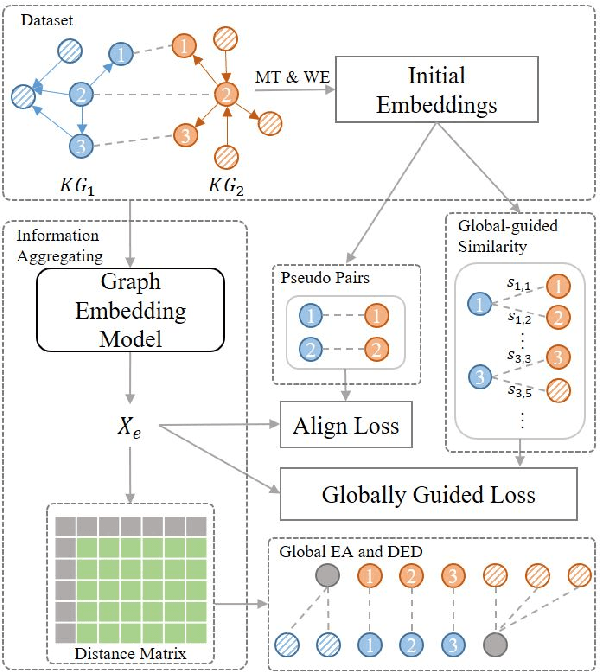
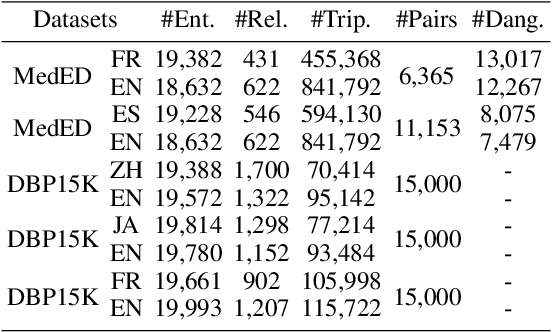
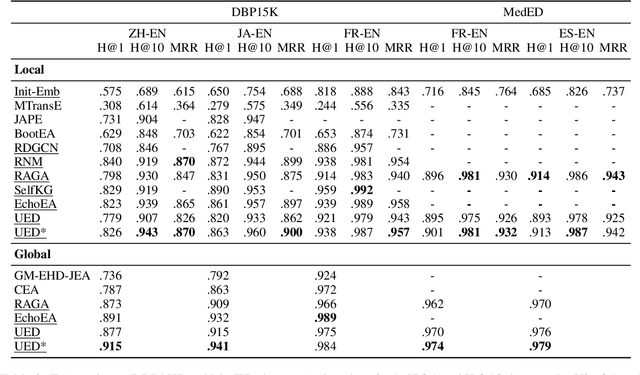
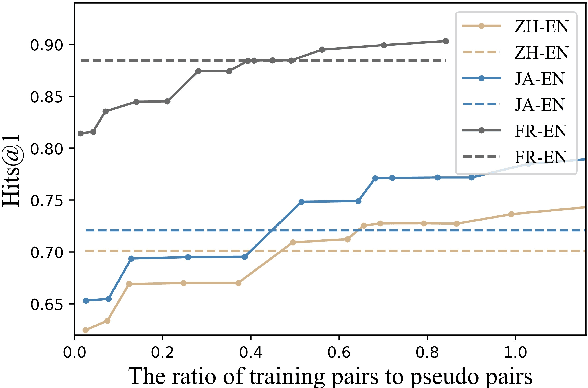
Knowledge graph integration typically suffers from the widely existing dangling entities that cannot find alignment cross knowledge graphs (KGs). The dangling entity set is unavailable in most real-world scenarios, and manually mining the entity pairs that consist of entities with the same meaning is labor-consuming. In this paper, we propose a novel accurate Unsupervised method for joint Entity alignment (EA) and Dangling entity detection (DED), called UED. The UED mines the literal semantic information to generate pseudo entity pairs and globally guided alignment information for EA and then utilizes the EA results to assist the DED. We construct a medical cross-lingual knowledge graph dataset, MedED, providing data for both the EA and DED tasks. Extensive experiments demonstrate that in the EA task, UED achieves EA results comparable to those of state-of-the-art supervised EA baselines and outperforms the current state-of-the-art EA methods by combining supervised EA data. For the DED task, UED obtains high-quality results without supervision.
Gaussian Process Self-triggered Policy Search in Weakly Observable Environments
May 07, 2022
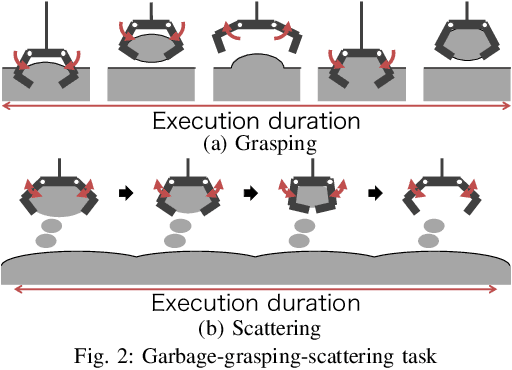
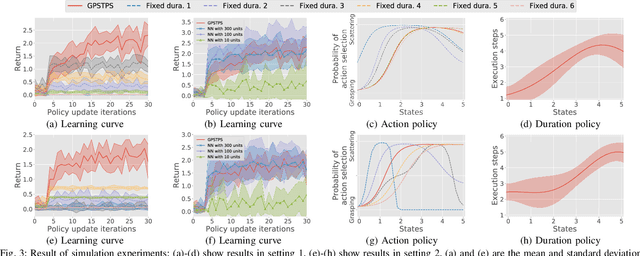

The environments of such large industrial machines as waste cranes in waste incineration plants are often weakly observable, where little information about the environmental state is contained in the observations due to technical difficulty or maintenance cost (e.g., no sensors for observing the state of the garbage to be handled). Based on the findings that skilled operators in such environments choose predetermined control strategies (e.g., grasping and scattering) and their durations based on sensor values, %thereby improving the robustness of their actions, we propose a novel non-parametric policy search algorithm: Gaussian process self-triggered policy search (GPSTPS). GPSTPS has two types of control policies: action and duration. A gating mechanism either maintains the action selected by the action policy for the duration specified by the duration policy or updates the action and duration by passing new observations to the policy; therefore, it is categorized as self-triggered. GPSTPS simultaneously learns both policies by trial and error based on sparse GP priors and variational learning to maximize the return. To verify the performance of our proposed method, we conducted experiments on garbage-grasping-scattering task for a waste crane with weak observations using a simulation and a robotic waste crane system. As experimental results, the proposed method acquired suitable policies to determine the action and duration based on the garbage's characteristics.
Reasoning over Public and Private Data in Retrieval-Based Systems
Mar 14, 2022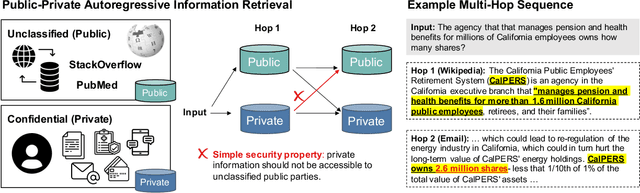


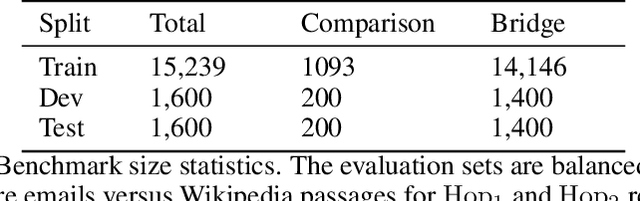
Users and organizations are generating ever-increasing amounts of private data from a wide range of sources. Incorporating private data is important to personalize open-domain applications such as question-answering, fact-checking, and personal assistants. State-of-the-art systems for these tasks explicitly retrieve relevant information to a user question from a background corpus before producing an answer. While today's retrieval systems assume the corpus is fully accessible, users are often unable or unwilling to expose their private data to entities hosting public data. We first define the PUBLIC-PRIVATE AUTOREGRESSIVE INFORMATION RETRIEVAL (PAIR) privacy framework for the novel retrieval setting over multiple privacy scopes. We then argue that an adequate benchmark is missing to study PAIR since existing textual benchmarks require retrieving from a single data distribution. However, public and private data intuitively reflect different distributions, motivating us to create ConcurrentQA, the first textual QA benchmark to require concurrent retrieval over multiple data-distributions. Finally, we show that existing systems face large privacy vs. performance tradeoffs when applied to our proposed retrieval setting and investigate how to mitigate these tradeoffs.
Brain Principles Programming
Mar 14, 2022
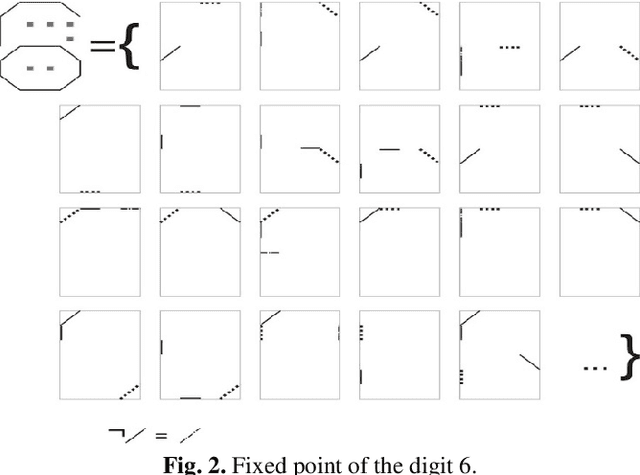
In the monograph, STRONG ARTIFICIAL INTELLIGENCE. On the Approaches to Superintelligence, published by Sberbank, provides a cross-disciplinary review of general artificial intelligence. As an anthropomorphic direction of research, it considers Brain Principles Programming, BPP) the formalization of universal mechanisms (principles) of the brain's work with information, which are implemented at all levels of the organization of nervous tissue. This monograph provides a formalization of these principles in terms of the category theory. However, this formalization is not enough to develop algorithms for working with information. In this paper, for the description and modeling of Brain Principles Programming, it is proposed to apply mathematical models and algorithms developed by us earlier that model cognitive functions, which are based on well-known physiological, psychological and other natural science theories. The paper uses mathematical models and algorithms of the following theories: P.K.Anokhin's Theory of Functional Brain Systems, Eleonor Rosh's prototypical categorization theory, Bob Rehter's theory of causal models and natural classification. As a result, the formalization of the BPP is obtained and computer examples are given that demonstrate the algorithm's operation.
MANet: Improving Video Denoising with a Multi-Alignment Network
Feb 20, 2022
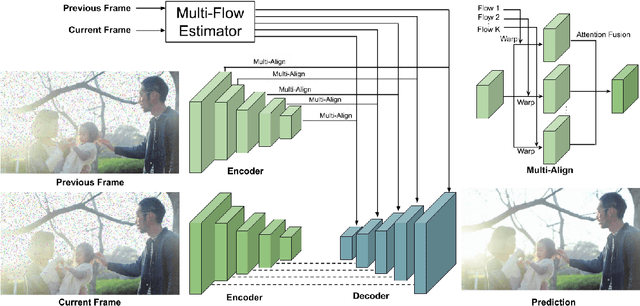
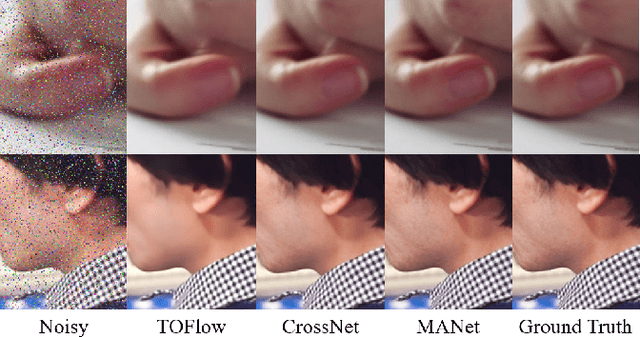
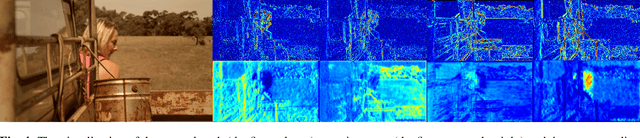
In video denoising, the adjacent frames often provide very useful information, but accurate alignment is needed before such information can be harnassed. In this work, we present a multi-alignment network, which generates multiple flow proposals followed by attention-based averaging. It serves to mimics the non-local mechanism, suppressing noise by averaging multiple observations. Our approach can be applied to various state-of-the-art models that are based on flow estimation. Experiments on a large-scale video dataset demonstrate that our method improves the denoising baseline model by 0.2dB, and further reduces the parameters by 47% with model distillation.
Viko 2.0: A Hierarchical Gecko-inspired Adhesive Gripper with Visuotactile Sensor
Apr 21, 2022
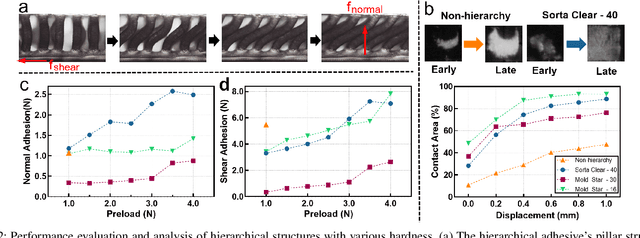
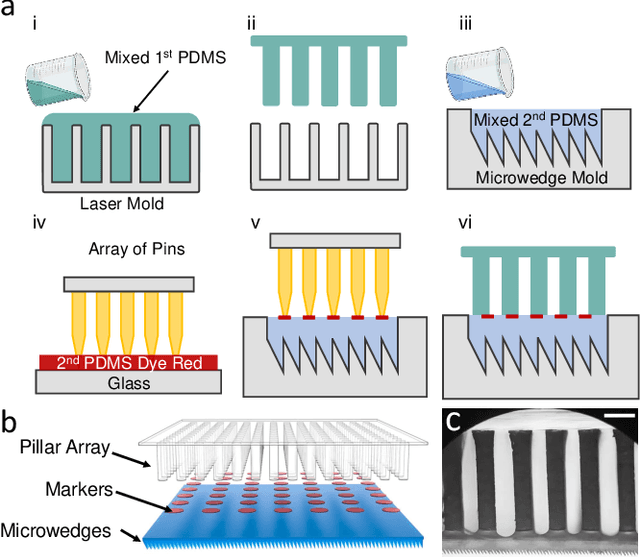
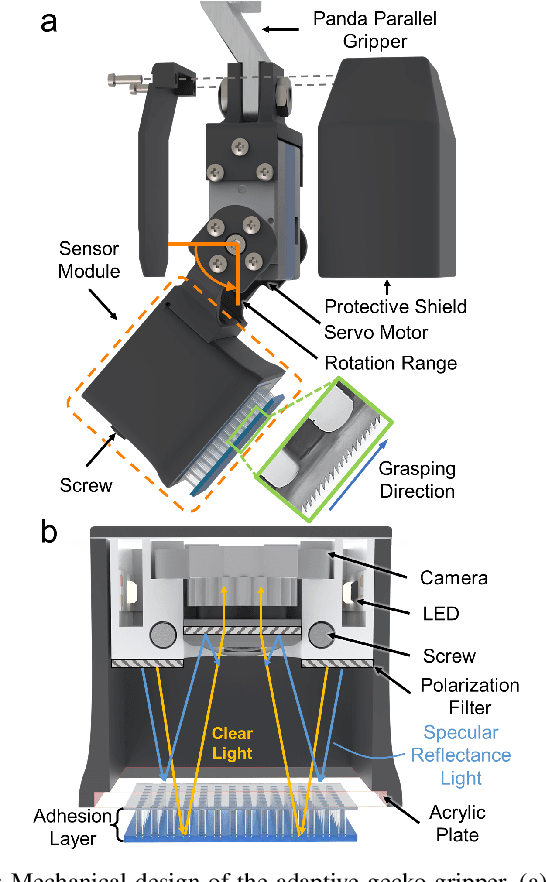
Robotic grippers with visuotactile sensors have access to rich tactile information for grasping tasks but encounter difficulty in partially encompassing large objects with sufficient grip force. While hierarchical gecko-inspired adhesives are a potential technique for bridging performance gaps, they require a large contact area for efficient usage. In this work, we present a new version of an adaptive gecko gripper called Viko 2.0 that effectively combines the advantage of adhesives and visuotactile sensors. Compared with a non-hierarchical structure, a hierarchical structure with a multimaterial design achieves approximately a 1.5 times increase in normal adhesion and double in contact area. The integrated visuotactile sensor captures a deformation image of the hierarchical structure and provides a real-time measurement of contact area, shear force, and incipient slip detection at 24 Hz. The gripper is implemented on a robotic arm to demonstrate an adaptive grasping pose based on contact area, and grasps objects with a wide range of geometries and textures.
nigam@COLIEE-22: Legal Case Retrieval and Entailment using Cascading of Lexical and Semantic-based models
Apr 16, 2022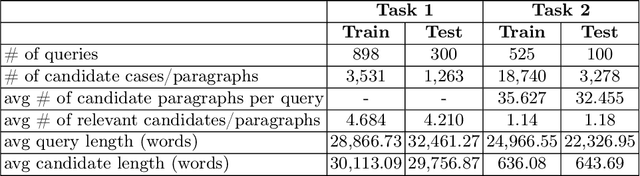
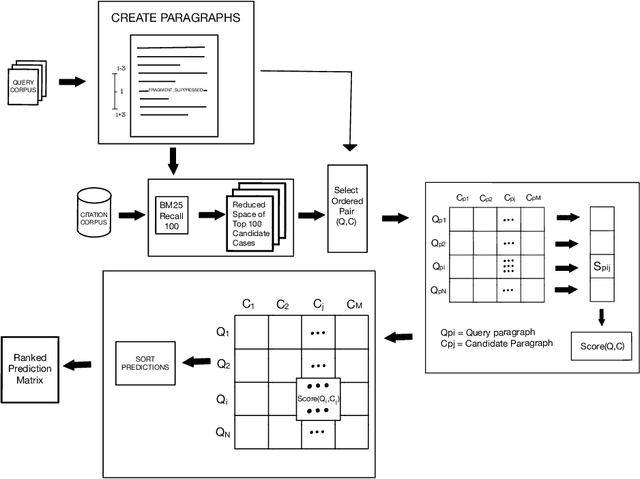
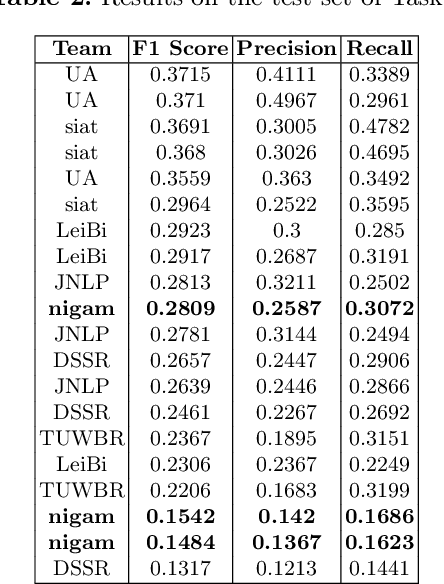
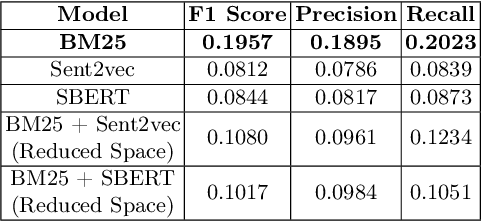
This paper describes our submission to the Competition on Legal Information Extraction/Entailment 2022 (COLIEE-2022) workshop on case law competition for tasks 1 and 2. Task 1 is a legal case retrieval task, which involves reading a new case and extracting supporting cases from the provided case law corpus to support the decision. Task 2 is the legal case entailment task, which involves the identification of a paragraph from existing cases that entails the decision in a relevant case. We employed the neural models Sentence-BERT and Sent2Vec for semantic understanding and the traditional retrieval model BM25 for exact matching in both tasks. As a result, our team ("nigam") ranked 5th among all the teams in Tasks 1 and 2. Experimental results indicate that the traditional retrieval model BM25 still outperforms neural network-based models.
BronchoPose: an analysis of data and model configuration for vision-based bronchoscopy pose estimation
Apr 25, 2022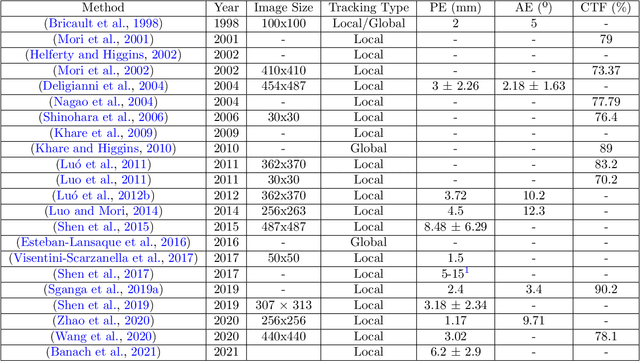
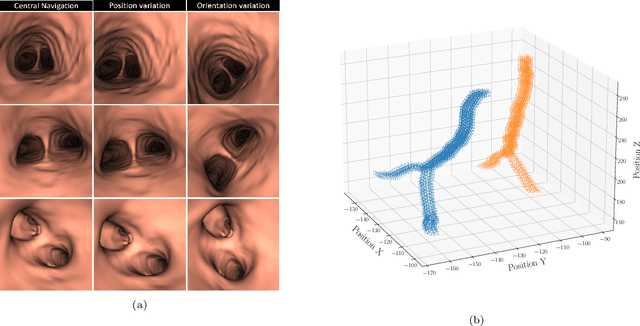
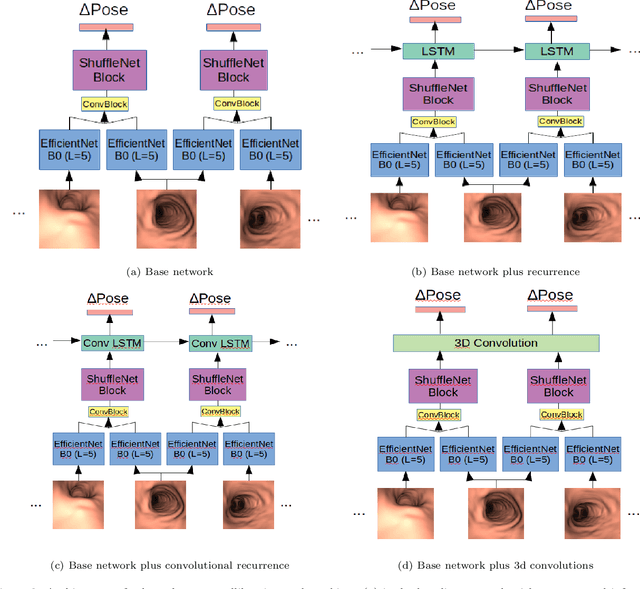
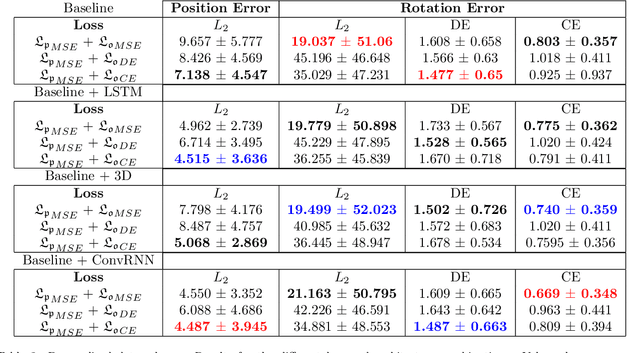
Vision-based bronchoscopy (VB) models require the registration of the virtual lung model with the frames from the video bronchoscopy to provide effective guidance during the biopsy. The registration can be achieved by either tracking the position and orientation of the bronchoscopy camera or by calibrating its deviation from the pose (position and orientation) simulated in the virtual lung model. Recent advances in neural networks and temporal image processing have provided new opportunities for guided bronchoscopy. However, such progress has been hindered by the lack of comparative experimental conditions. In the present paper, we share a novel synthetic dataset allowing for a fair comparison of methods. Moreover, this paper investigates several neural network architectures for the learning of temporal information at different levels of subject personalization. In order to improve orientation measurement, we also present a standardized comparison framework and a novel metric for camera orientation learning. Results on the dataset show that the proposed metric and architectures, as well as the standardized conditions, provide notable improvements to current state-of-the-art camera pose estimation in video bronchoscopy.
Ultra-low Latency Spiking Neural Networks with Spatio-Temporal Compression and Synaptic Convolutional Block
Mar 18, 2022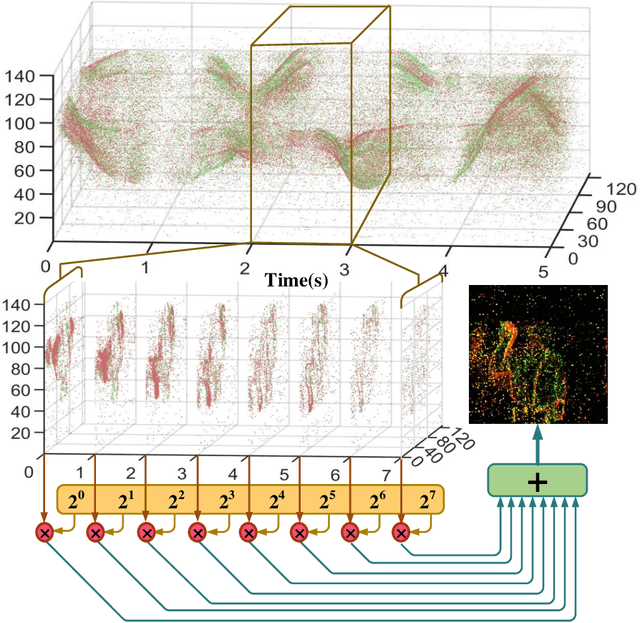
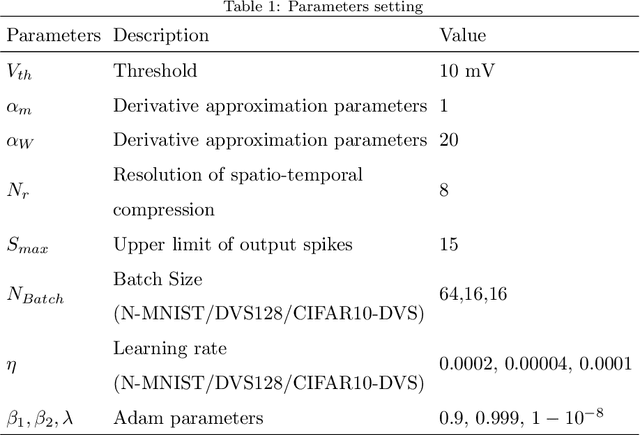
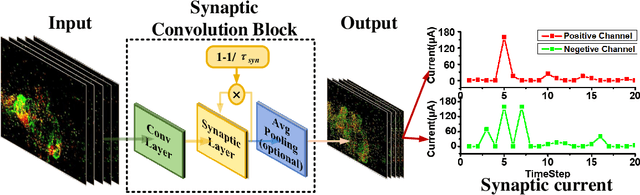
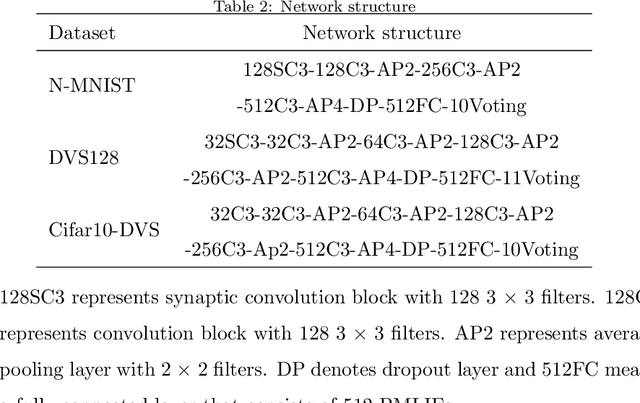
Spiking neural networks (SNNs), as one of the brain-inspired models, has spatio-temporal information processing capability, low power feature, and high biological plausibility. The effective spatio-temporal feature makes it suitable for event streams classification. However, neuromorphic datasets, such as N-MNIST, CIFAR10-DVS, DVS128-gesture, need to aggregate individual events into frames with a new higher temporal resolution for event stream classification, which causes high training and inference latency. In this work, we proposed a spatio-temporal compression method to aggregate individual events into a few time steps of synaptic current to reduce the training and inference latency. To keep the accuracy of SNNs under high compression ratios, we also proposed a synaptic convolutional block to balance the dramatic change between adjacent time steps. And multi-threshold Leaky Integrate-and-Fire (LIF) with learnable membrane time constant is introduced to increase its information processing capability. We evaluate the proposed method for event streams classification tasks on neuromorphic N-MNIST, CIFAR10-DVS, DVS128 gesture datasets. The experiment results show that our proposed method outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps.