 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Edge-enhanced Feature Distillation Network for Efficient Super-Resolution
Apr 19, 2022

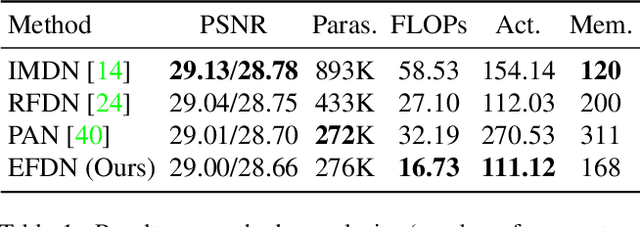
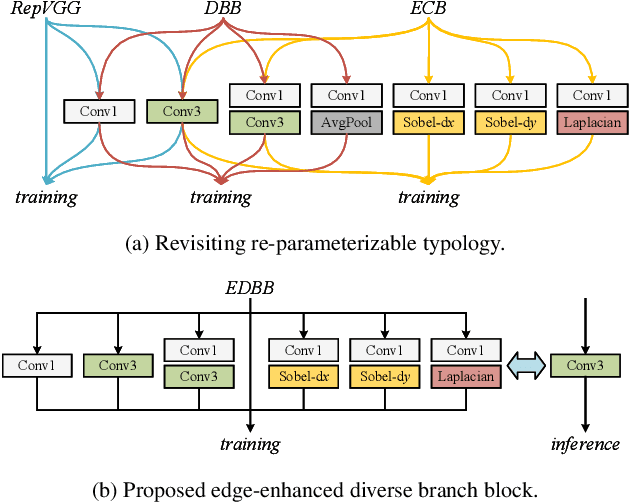

With the recently massive development in convolution neural networks, numerous lightweight CNN-based image super-resolution methods have been proposed for practical deployments on edge devices. However, most existing methods focus on one specific aspect: network or loss design, which leads to the difficulty of minimizing the model size. To address the issue, we conclude block devising, architecture searching, and loss design to obtain a more efficient SR structure. In this paper, we proposed an edge-enhanced feature distillation network, named EFDN, to preserve the high-frequency information under constrained resources. In detail, we build an edge-enhanced convolution block based on the existing reparameterization methods. Meanwhile, we propose edge-enhanced gradient loss to calibrate the reparameterized path training. Experimental results show that our edge-enhanced strategies preserve the edge and significantly improve the final restoration quality. Code is available at https://github.com/icandle/EFDN.
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022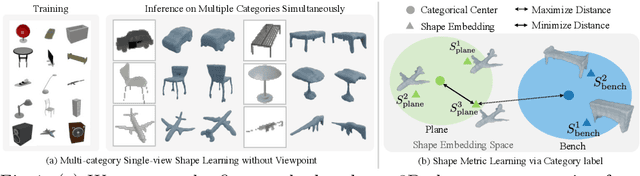

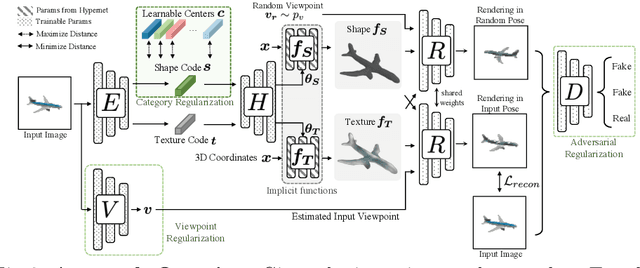
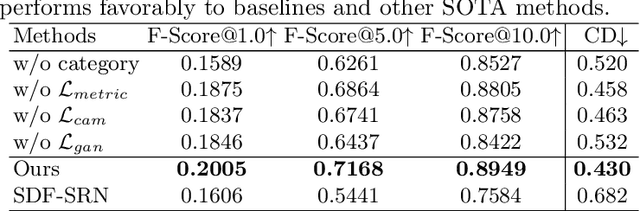
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.
Bi-Phasic Quasistatic Brain Communication for Fully Untethered Connected Brain Implants
May 18, 2022Wireless communication using electro-magnetic (EM) fields acts as the backbone for information exchange among wearable devices around the human body. However, for Implanted devices, EM fields incur high amount of absorption in the tissue, while alternative modes of transmission including ultrasound, optical and magneto-electric methods result in large amount of transduction losses due to conversion of one form of energy to another, thereby increasing the overall end-to-end energy loss. To solve the challenge of powering and communication in a brain implant with low end-end channel loss, we present Bi-Phasic Quasistatic Brain Communication (BP-QBC), achieving < 60dB worst-case end-to-end channel loss at a channel length of 55mm, by avoiding the transduction losses during field-modality conversion. BP-QBC utilizes dipole coupling based signal transmission within the brain tissue using differential excitation in the transmitter and differential signal pick-up at the receiver, and offers 41X lower power w.r.t. traditional Galvanic Human Body Communication at a carrier frequency of 1MHz, by blocking any DC current paths through the brain tissue. Since the electrical signal transfer through the human tissue is electro-quasistatic up to several 10's of MHz range, BP-QBC allows a scalable (bps-10Mbps) duty-cycled uplink from the implant to an external wearable. The power consumption in the BP-QBC TX is only 0.52uW at 1Mbps (with 1% duty cycling), which is within the range of harvested body-coupled power in the downlink from an external wearable to the brain implant. Furthermore, BP-QBC eliminates the need for sub-cranial repeaters, as it utilizes quasi-static electrical signals, thereby avoiding any transduction losses. Such low end-to-end channel loss with high data rates would find applications in neuroscience, brain-machine interfaces, electroceuticals and connected healthcare.
BronchoPose: an analysis of data and model configuration for vision-based bronchoscopy pose estimation
Apr 25, 2022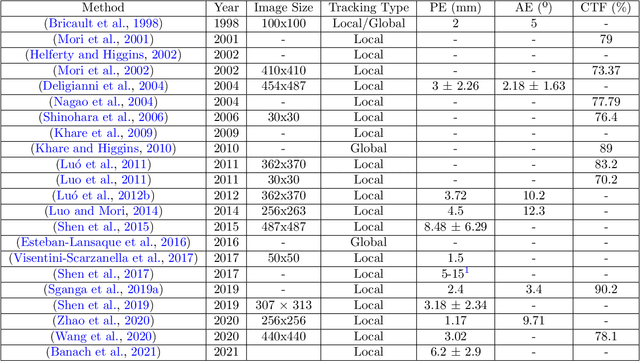
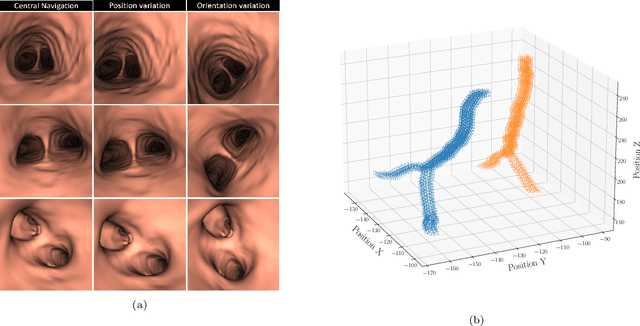
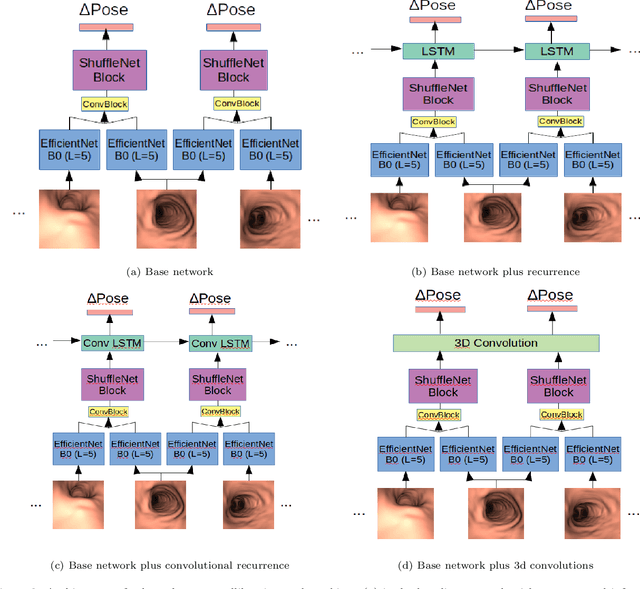
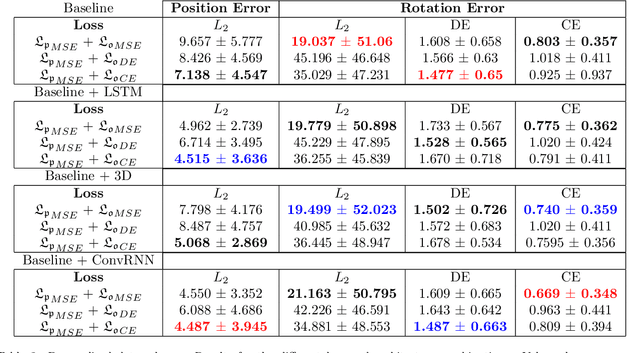
Vision-based bronchoscopy (VB) models require the registration of the virtual lung model with the frames from the video bronchoscopy to provide effective guidance during the biopsy. The registration can be achieved by either tracking the position and orientation of the bronchoscopy camera or by calibrating its deviation from the pose (position and orientation) simulated in the virtual lung model. Recent advances in neural networks and temporal image processing have provided new opportunities for guided bronchoscopy. However, such progress has been hindered by the lack of comparative experimental conditions. In the present paper, we share a novel synthetic dataset allowing for a fair comparison of methods. Moreover, this paper investigates several neural network architectures for the learning of temporal information at different levels of subject personalization. In order to improve orientation measurement, we also present a standardized comparison framework and a novel metric for camera orientation learning. Results on the dataset show that the proposed metric and architectures, as well as the standardized conditions, provide notable improvements to current state-of-the-art camera pose estimation in video bronchoscopy.
Predicting vacant parking space availability zone-wisely: a graph based spatio-temporal prediction approach
May 03, 2022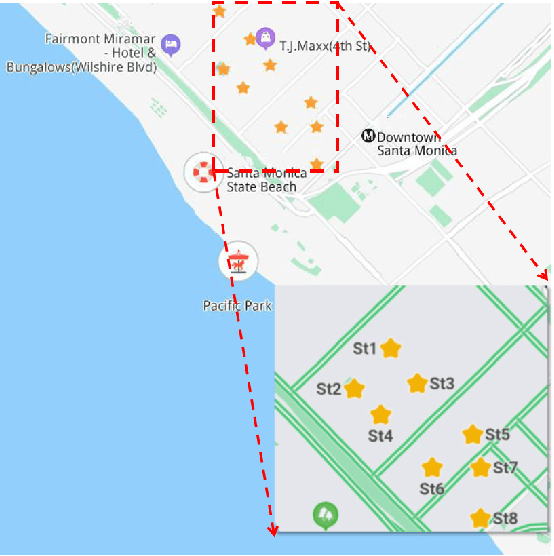
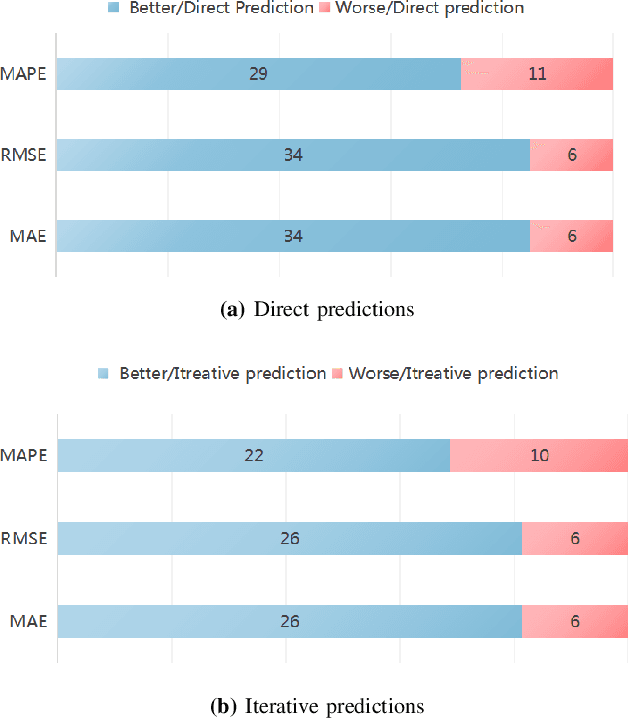
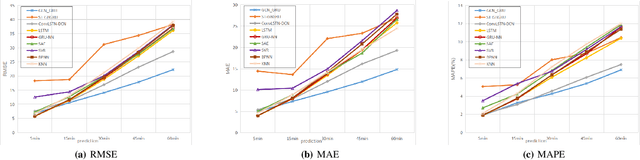
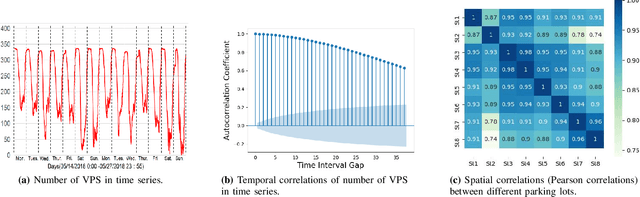
Vacant parking space (VPS) prediction is one of the key issues of intelligent parking guidance systems. Accurately predicting VPS information plays a crucial role in intelligent parking guidance systems, which can help drivers find parking space quickly, reducing unnecessary waste of time and excessive environmental pollution. Through the simple analysis of historical data, we found that there not only exists a obvious temporal correlation in each parking lot, but also a clear spatial correlation between different parking lots. In view of this, this paper proposed a graph data-based model ST-GBGRU (Spatial-Temporal Graph Based Gated Recurrent Unit), the number of VPSs can be predicted both in short-term (i.e., within 30 min) and in long-term (i.e., over 30min). On the one hand, the temporal correlation of historical VPS data is extracted by GRU, on the other hand, the spatial correlation of historical VPS data is extracted by GCN inside GRU. Two prediction methods, namely direct prediction and iterative prediction, are combined with the proposed model. Finally, the prediction model is applied to predict the number VPSs of 8 public parking lots in Santa Monica. The results show that in the short-term and long-term prediction tasks, ST-GBGRU model can achieve high accuracy and have good application prospects.
Viko 2.0: A Hierarchical Gecko-inspired Adhesive Gripper with Visuotactile Sensor
Apr 21, 2022
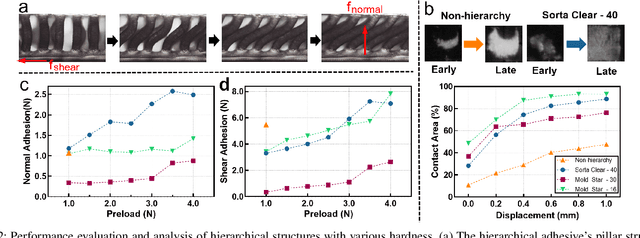
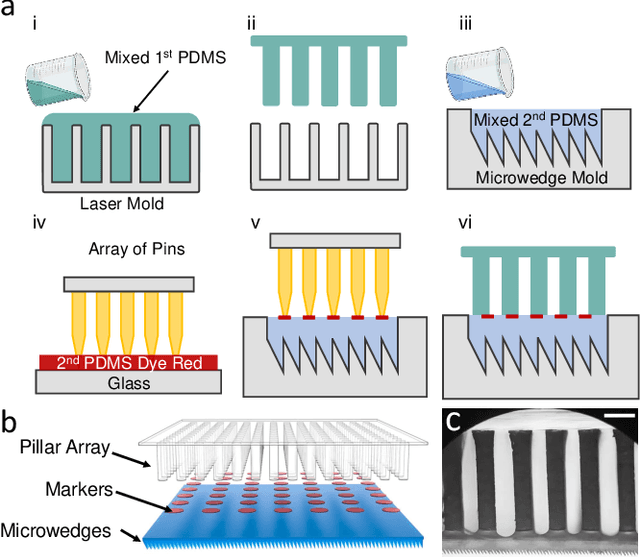
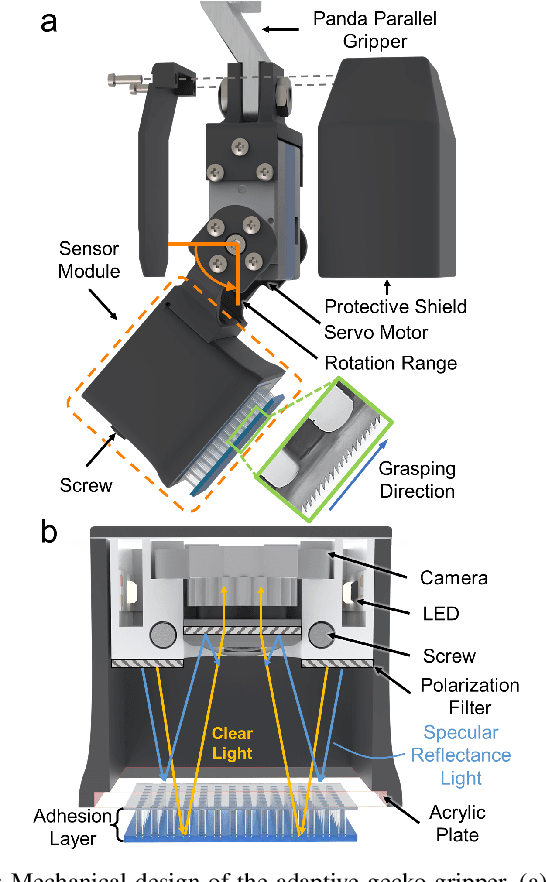
Robotic grippers with visuotactile sensors have access to rich tactile information for grasping tasks but encounter difficulty in partially encompassing large objects with sufficient grip force. While hierarchical gecko-inspired adhesives are a potential technique for bridging performance gaps, they require a large contact area for efficient usage. In this work, we present a new version of an adaptive gecko gripper called Viko 2.0 that effectively combines the advantage of adhesives and visuotactile sensors. Compared with a non-hierarchical structure, a hierarchical structure with a multimaterial design achieves approximately a 1.5 times increase in normal adhesion and double in contact area. The integrated visuotactile sensor captures a deformation image of the hierarchical structure and provides a real-time measurement of contact area, shear force, and incipient slip detection at 24 Hz. The gripper is implemented on a robotic arm to demonstrate an adaptive grasping pose based on contact area, and grasps objects with a wide range of geometries and textures.
nigam@COLIEE-22: Legal Case Retrieval and Entailment using Cascading of Lexical and Semantic-based models
Apr 16, 2022
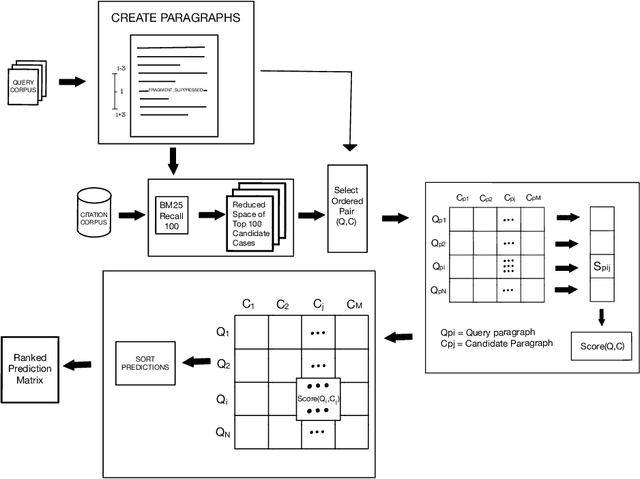
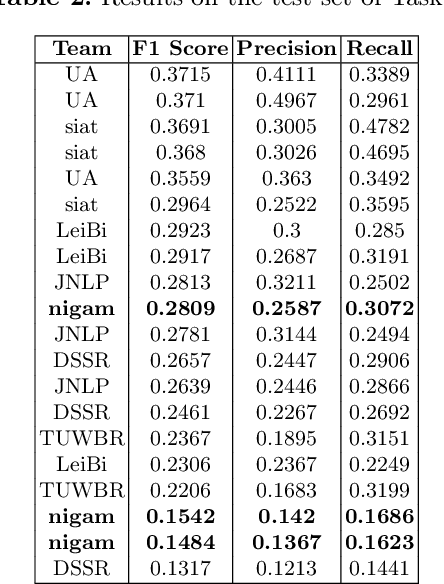
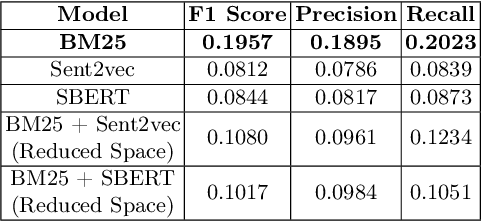
This paper describes our submission to the Competition on Legal Information Extraction/Entailment 2022 (COLIEE-2022) workshop on case law competition for tasks 1 and 2. Task 1 is a legal case retrieval task, which involves reading a new case and extracting supporting cases from the provided case law corpus to support the decision. Task 2 is the legal case entailment task, which involves the identification of a paragraph from existing cases that entails the decision in a relevant case. We employed the neural models Sentence-BERT and Sent2Vec for semantic understanding and the traditional retrieval model BM25 for exact matching in both tasks. As a result, our team ("nigam") ranked 5th among all the teams in Tasks 1 and 2. Experimental results indicate that the traditional retrieval model BM25 still outperforms neural network-based models.
K-textures, a self supervised hard clustering deep learning algorithm for satellite images segmentation
May 18, 2022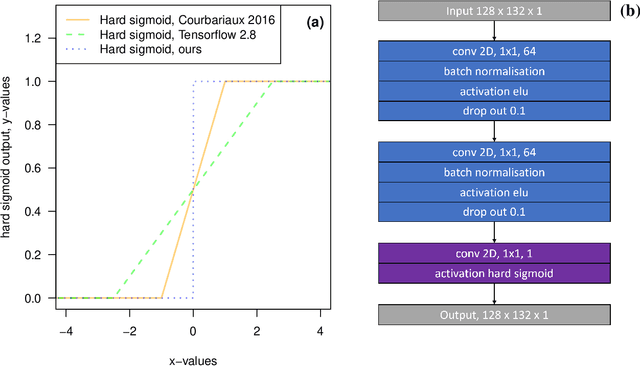
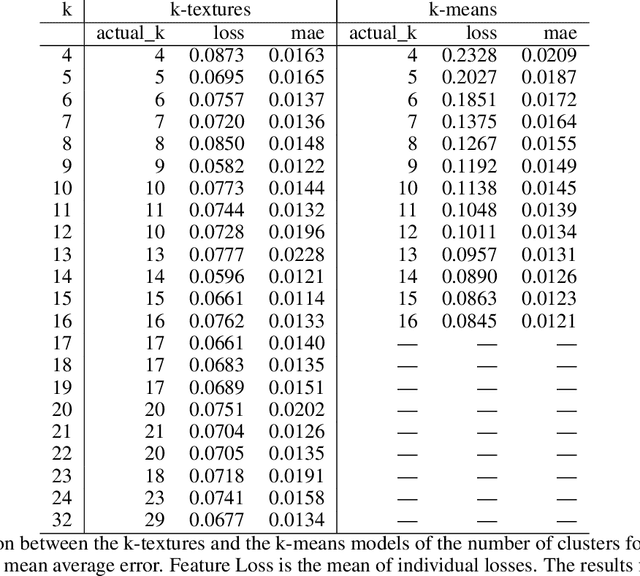
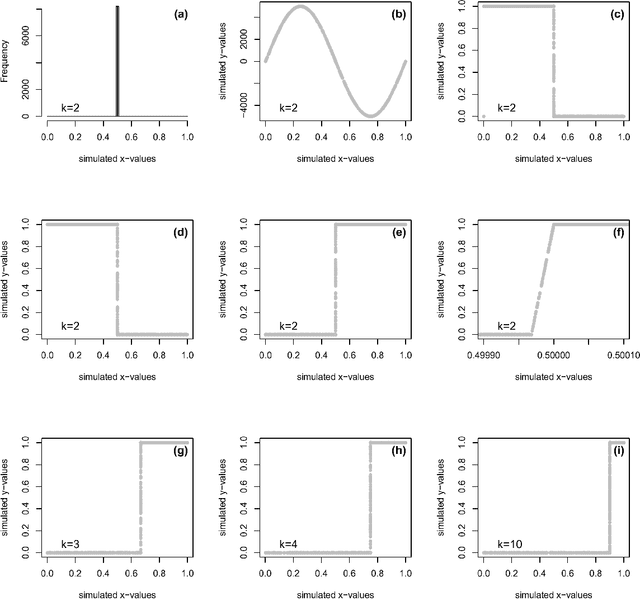
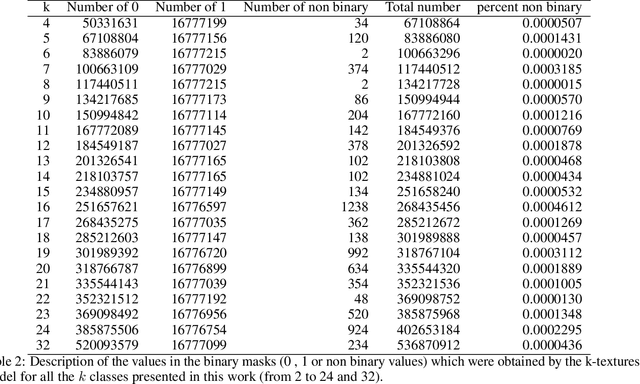
Deep learning self supervised algorithms that can segment an image in a fixed number of hard labels such as the k-means algorithm and only relying only on deep learning techniques are still lacking. Here, we introduce the k-textures algorithm which provides self supervised segmentation of a 4-band image (RGB-NIR) for a $k$ number of classes. An example of its application on high resolution Planet satellite imagery is given. Our algorithm shows that discrete search is feasible using convolutional neural networks (CNN) and gradient descent. The model detects $k$ hard clustering classes represented in the model as $k$ discrete binary masks and their associated $k$ independently generated textures, that combined are a simulation of the original image. The similarity loss is the mean squared error between the features of the original and the simulated image, both extracted from the penultimate convolutional block of Keras 'imagenet' pretrained VGG-16 model and a custom feature extractor made with Planet data. The main advances of the k-textures model are: first, the $k$ discrete binary masks are obtained inside the model using gradient descent. The model allows for the generation of discrete binary masks using a novel method using a hard sigmoid activation function. Second, it provides hard clustering classes -- each pixels has only one class. Finally, in comparison to k-means, where each pixel is considered independently, here, contextual information is also considered and each class is not associated only to a similar values in the color channels but to a texture. Our approach is designed to ease the production of training samples for satellite image segmentation. The model codes and weights are available at https://doi.org/10.5281/zenodo.6359859
Improving Transferability for Domain Adaptive Detection Transformers
Apr 29, 2022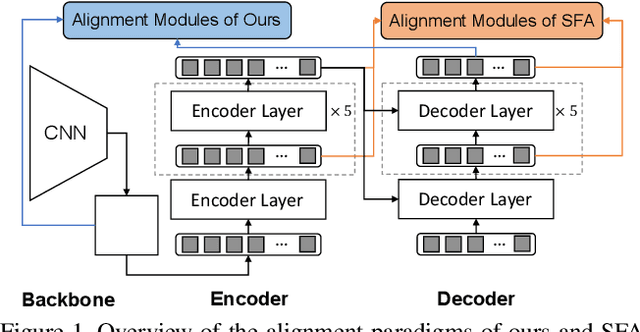
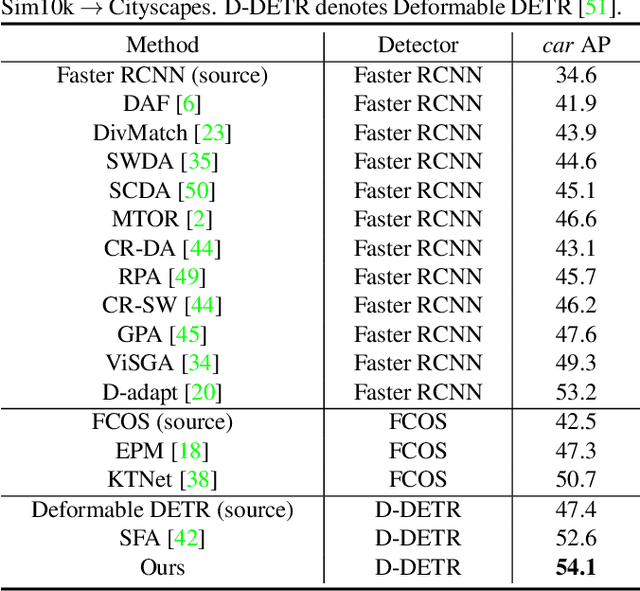
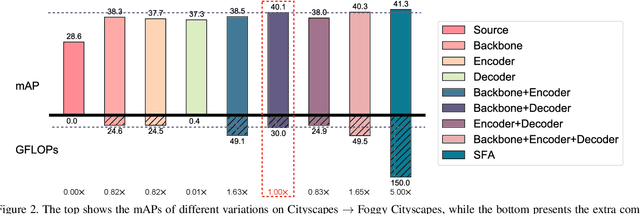
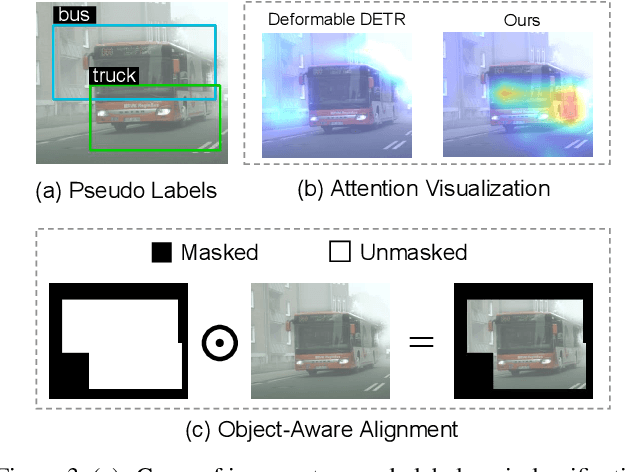
DETR-style detectors stand out amongst in-domain scenarios, but their properties in domain shift settings are under-explored. This paper aims to build a simple but effective baseline with a DETR-style detector on domain shift settings based on two findings. For one, mitigating the domain shift on the backbone and the decoder output features excels in getting favorable results. For another, advanced domain alignment methods in both parts further enhance the performance. Thus, we propose the Object-Aware Alignment (OAA) module and the Optimal Transport based Alignment (OTA) module to achieve comprehensive domain alignment on the outputs of the backbone and the detector. The OAA module aligns the foreground regions identified by pseudo-labels in the backbone outputs, leading to domain-invariant based features. The OTA module utilizes sliced Wasserstein distance to maximize the retention of location information while minimizing the domain gap in the decoder outputs. We implement the findings and the alignment modules into our adaptation method, and it benchmarks the DETR-style detector on the domain shift settings. Experiments on various domain adaptive scenarios validate the effectiveness of our method.
Adaptive Local Kernels Formulation of Mutual Information with Application to Active Post-Seismic Building Damage Inference
May 24, 2021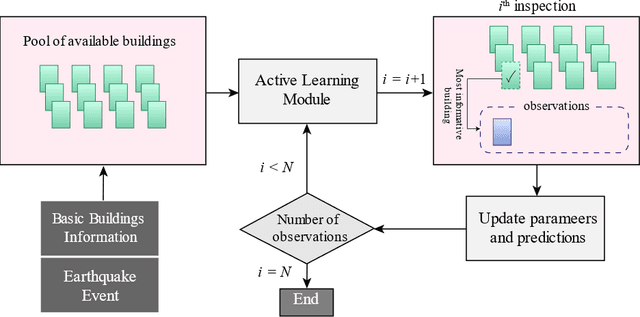

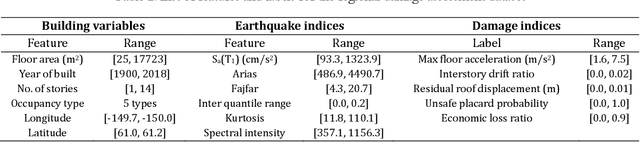
The abundance of training data is not guaranteed in various supervised learning applications. One of these situations is the post-earthquake regional damage assessment of buildings. Querying the damage label of each building requires a thorough inspection by experts, and thus, is an expensive task. A practical approach is to sample the most informative buildings in a sequential learning scheme. Active learning methods recommend the most informative cases that are able to maximally reduce the generalization error. The information theoretic measure of mutual information (MI) is one of the most effective criteria to evaluate the effectiveness of the samples in a pool-based sample selection scenario. However, the computational complexity of the standard MI algorithm prevents the utilization of this method on large datasets. A local kernels strategy was proposed to reduce the computational costs, but the adaptability of the kernels to the observed labels was not considered in the original formulation of this strategy. In this article, an adaptive local kernels methodology is developed that allows for the conformability of the kernels to the observed output data while enhancing the computational complexity of the standard MI algorithm. The proposed algorithm is developed to work on a Gaussian process regression (GPR) framework, where the kernel hyperparameters are updated after each label query using the maximum likelihood estimation. In the sequential learning procedure, the updated hyperparameters can be used in the MI kernel matrices to improve the sample suggestion performance. The advantages are demonstrated on a simulation of the 2018 Anchorage, AK, earthquake. It is shown that while the proposed algorithm enables GPR to reach acceptable performance with fewer training data, the computational demands remain lower than the standard local kernels strategy.