 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Acquiring a Dynamic Light Field through a Single-Shot Coded Image
Apr 26, 2022
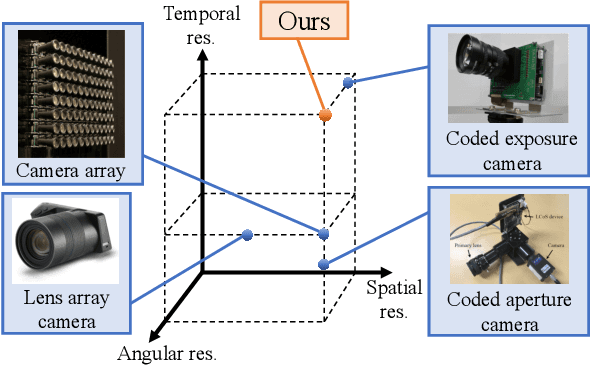
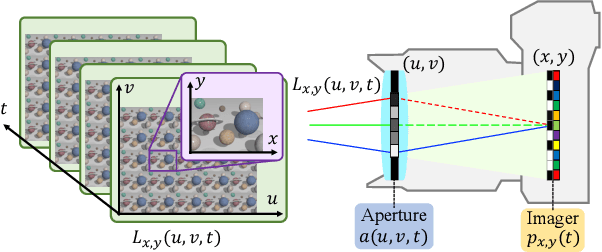
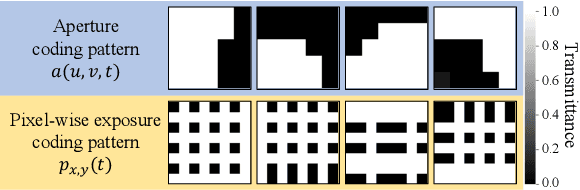

We propose a method for compressively acquiring a dynamic light field (a 5-D volume) through a single-shot coded image (a 2-D measurement). We designed an imaging model that synchronously applies aperture coding and pixel-wise exposure coding within a single exposure time. This coding scheme enables us to effectively embed the original information into a single observed image. The observed image is then fed to a convolutional neural network (CNN) for light-field reconstruction, which is jointly trained with the camera-side coding patterns. We also developed a hardware prototype to capture a real 3-D scene moving over time. We succeeded in acquiring a dynamic light field with 5x5 viewpoints over 4 temporal sub-frames (100 views in total) from a single observed image. Repeating capture and reconstruction processes over time, we can acquire a dynamic light field at 4x the frame rate of the camera. To our knowledge, our method is the first to achieve a finer temporal resolution than the camera itself in compressive light-field acquisition. Our software is available from our project webpage
Domain Invariant Masked Autoencoders for Self-supervised Learning from Multi-domains
May 10, 2022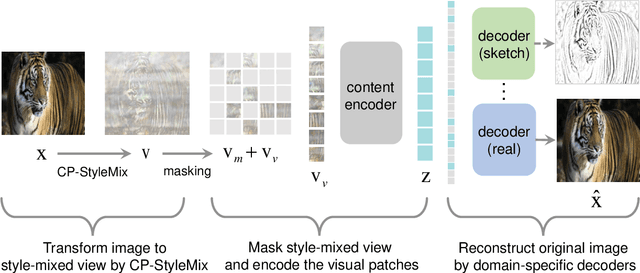

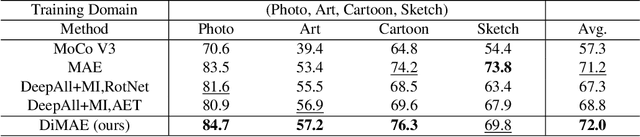
Generalizing learned representations across significantly different visual domains is a fundamental yet crucial ability of the human visual system. While recent self-supervised learning methods have achieved good performances with evaluation set on the same domain as the training set, they will have an undesirable performance decrease when tested on a different domain. Therefore, the self-supervised learning from multiple domains task is proposed to learn domain-invariant features that are not only suitable for evaluation on the same domain as the training set but also can be generalized to unseen domains. In this paper, we propose a Domain-invariant Masked AutoEncoder (DiMAE) for self-supervised learning from multi-domains, which designs a new pretext task, \emph{i.e.,} the cross-domain reconstruction task, to learn domain-invariant features. The core idea is to augment the input image with style noise from different domains and then reconstruct the image from the embedding of the augmented image, regularizing the encoder to learn domain-invariant features. To accomplish the idea, DiMAE contains two critical designs, 1) content-preserved style mix, which adds style information from other domains to input while persevering the content in a parameter-free manner, and 2) multiple domain-specific decoders, which recovers the corresponding domain style of input to the encoded domain-invariant features for reconstruction. Experiments on PACS and DomainNet illustrate that DiMAE achieves considerable gains compared with recent state-of-the-art methods.
Finding MNEMON: Reviving Memories of Node Embeddings
Apr 14, 2022
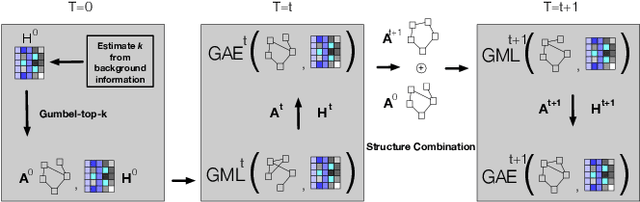
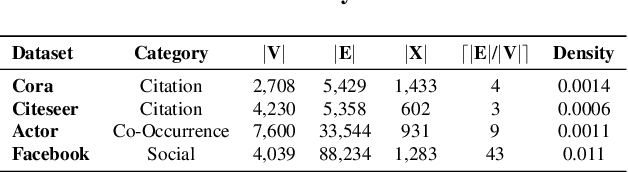
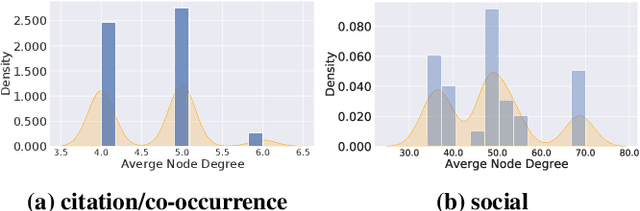
Previous security research efforts orbiting around graphs have been exclusively focusing on either (de-)anonymizing the graphs or understanding the security and privacy issues of graph neural networks. Little attention has been paid to understand the privacy risks of integrating the output from graph embedding models (e.g., node embeddings) with complex downstream machine learning pipelines. In this paper, we fill this gap and propose a novel model-agnostic graph recovery attack that exploits the implicit graph structural information preserved in the embeddings of graph nodes. We show that an adversary can recover edges with decent accuracy by only gaining access to the node embedding matrix of the original graph without interactions with the node embedding models. We demonstrate the effectiveness and applicability of our graph recovery attack through extensive experiments.
VesNet-RL: Simulation-based Reinforcement Learning for Real-World US Probe Navigation
May 10, 2022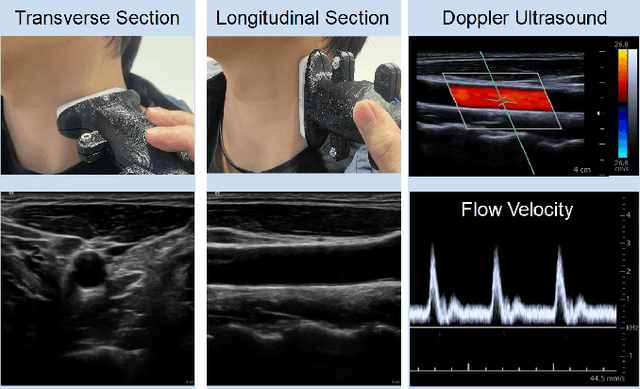
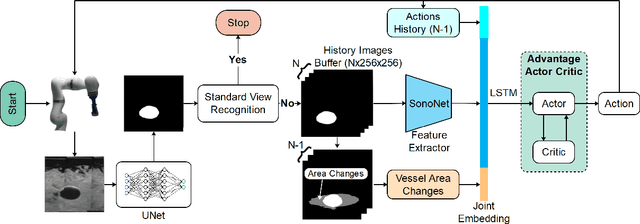
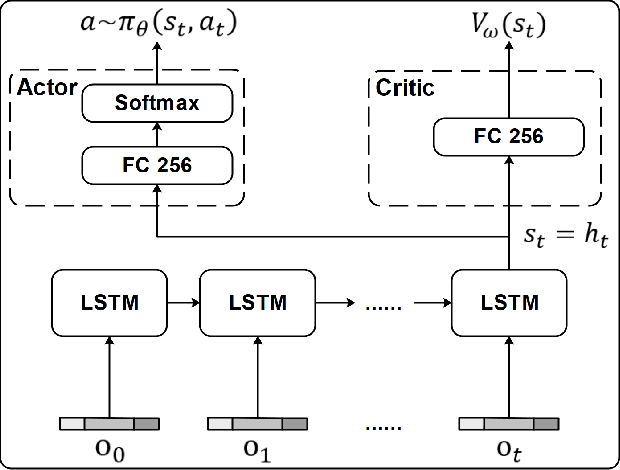
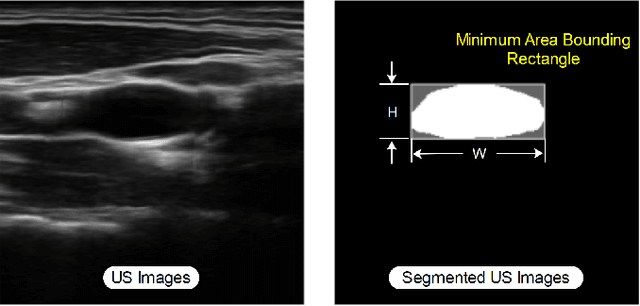
Ultrasound (US) is one of the most common medical imaging modalities since it is radiation-free, low-cost, and real-time. In freehand US examinations, sonographers often navigate a US probe to visualize standard examination planes with rich diagnostic information. However, reproducibility and stability of the resulting images often suffer from intra- and inter-operator variation. Reinforcement learning (RL), as an interaction-based learning method, has demonstrated its effectiveness in visual navigating tasks; however, RL is limited in terms of generalization. To address this challenge, we propose a simulation-based RL framework for real-world navigation of US probes towards the standard longitudinal views of vessels. A UNet is used to provide binary masks from US images; thereby, the RL agent trained on simulated binary vessel images can be applied in real scenarios without further training. To accurately characterize actual states, a multi-modality state representation structure is introduced to facilitate the understanding of environments. Moreover, considering the characteristics of vessels, a novel standard view recognition approach based on the minimum bounding rectangle is proposed to terminate the searching process. To evaluate the effectiveness of the proposed method, the trained policy is validated virtually on 3D volumes of a volunteer's in-vivo carotid artery, and physically on custom-designed gel phantoms using robotic US. The results demonstrate that proposed approach can effectively and accurately navigate the probe towards the longitudinal view of vessels.
SoftEdge: Regularizing Graph Classification with Random Soft Edges
Apr 21, 2022
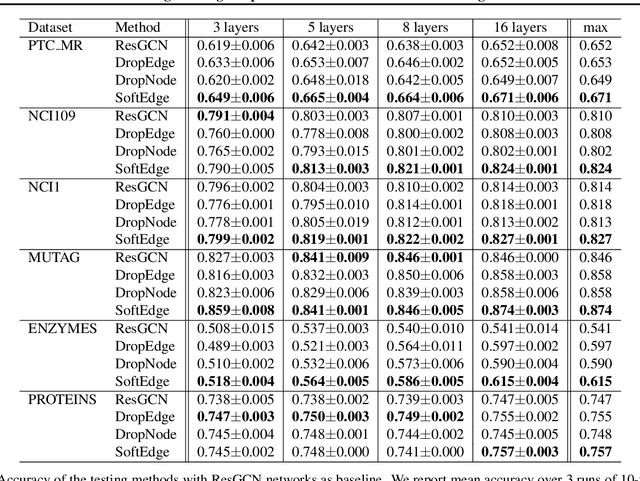
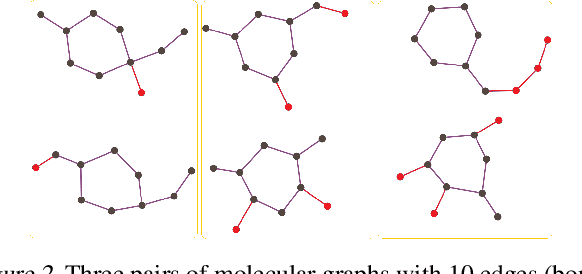
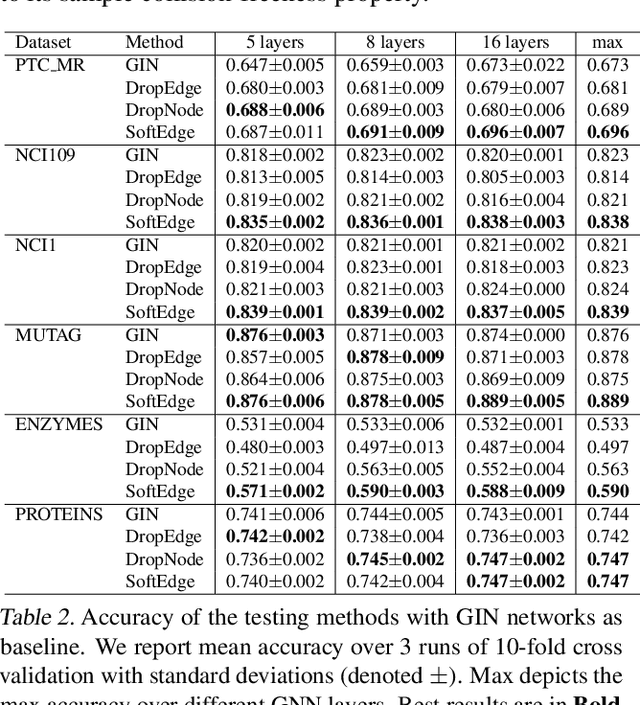
Graph data augmentation plays a vital role in regularizing Graph Neural Networks (GNNs), which leverage information exchange along edges in graphs, in the form of message passing, for learning. Due to their effectiveness, simple edge and node manipulations (e.g., addition and deletion) have been widely used in graph augmentation. In this paper, we identify a limitation in such a common augmentation technique. That is, simple edge and node manipulations can create graphs with an identical structure or indistinguishable structures to message passing GNNs but of conflict labels, leading to the sample collision issue and thus the degradation of model performance. To address this problem, we propose SoftEdge, which assigns random weights to a portion of the edges of a given graph to construct dynamic neighborhoods over the graph. We prove that SoftEdge creates collision-free augmented graphs. We also show that this simple method obtains superior accuracy to popular node and edge manipulation approaches and notable resilience to the accuracy degradation with the GNN depth.
I Can Read Your Mind: Control Mechanism Secrecy of Networked Dynamical Systems under Inference Attacks
May 07, 2022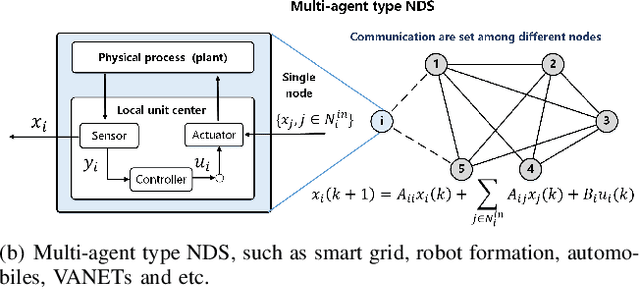
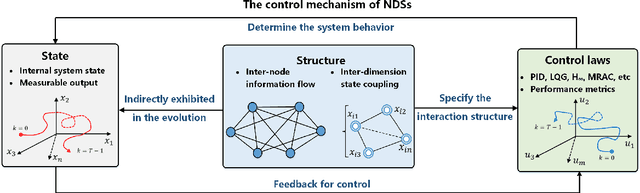

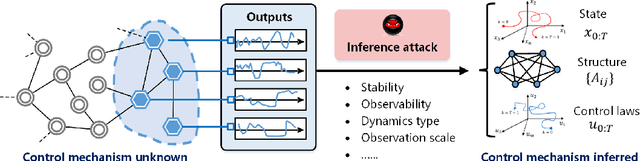
Recent years have witnessed the fast advance of security research for networked dynamical system (NDS). Considering the latest inference attacks that enable stealthy and precise attacks into NDSs with observation-based learning, this article focuses on a new security aspect, i.e., how to protect control mechanism secrets from inference attacks, including state information, interaction structure and control laws. We call this security property as control mechanism secrecy, which provides protection of the vulnerabilities in the control process and fills the defense gap that traditional cyber security cannot handle. Since the knowledge of control mechanism defines the capabilities to implement attacks, ensuring control mechanism secrecy needs to go beyond the conventional data privacy to cover both transmissible data and intrinsic models in NDSs. The prime goal of this article is to summarize recent results of both inference attacks on control mechanism secrets and countermeasures. We first introduce the basic inference attack methods on the state and structure of NDSs, respectively, along with their inference performance bounds. Then, the corresponding countermeasures and performance metrics are given to illustrate how to preserve the control mechanism secrecy. Necessary conditions are derived to guide the secrecy design. Finally, thorough discussions on the control laws and open issues are presented, beckoning future investigation on reliable countermeasure design and tradeoffs between the secrecy and control performance.
Gaussian Process Self-triggered Policy Search in Weakly Observable Environments
May 07, 2022
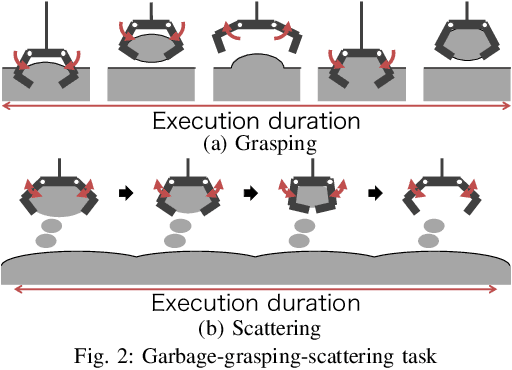
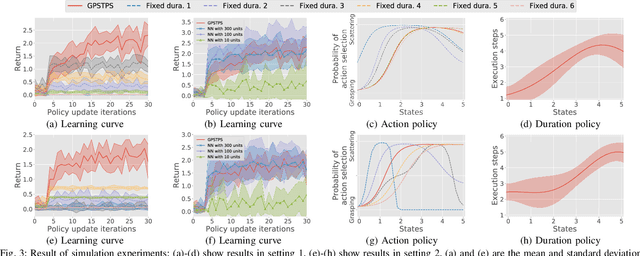

The environments of such large industrial machines as waste cranes in waste incineration plants are often weakly observable, where little information about the environmental state is contained in the observations due to technical difficulty or maintenance cost (e.g., no sensors for observing the state of the garbage to be handled). Based on the findings that skilled operators in such environments choose predetermined control strategies (e.g., grasping and scattering) and their durations based on sensor values, %thereby improving the robustness of their actions, we propose a novel non-parametric policy search algorithm: Gaussian process self-triggered policy search (GPSTPS). GPSTPS has two types of control policies: action and duration. A gating mechanism either maintains the action selected by the action policy for the duration specified by the duration policy or updates the action and duration by passing new observations to the policy; therefore, it is categorized as self-triggered. GPSTPS simultaneously learns both policies by trial and error based on sparse GP priors and variational learning to maximize the return. To verify the performance of our proposed method, we conducted experiments on garbage-grasping-scattering task for a waste crane with weak observations using a simulation and a robotic waste crane system. As experimental results, the proposed method acquired suitable policies to determine the action and duration based on the garbage's characteristics.
UNetFormer: A Unified Vision Transformer Model and Pre-Training Framework for 3D Medical Image Segmentation
Apr 05, 2022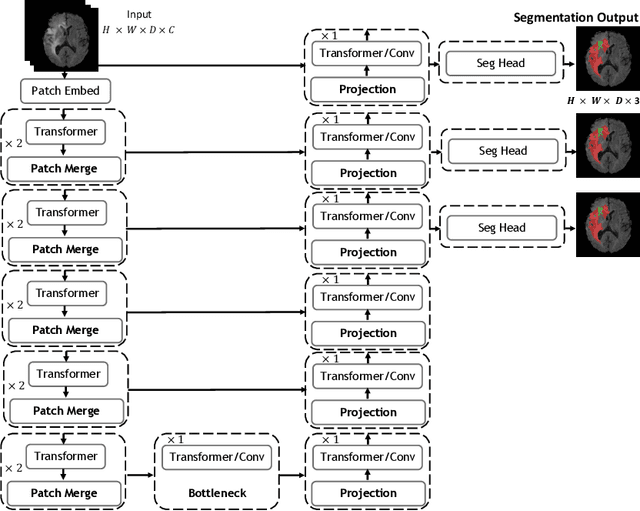
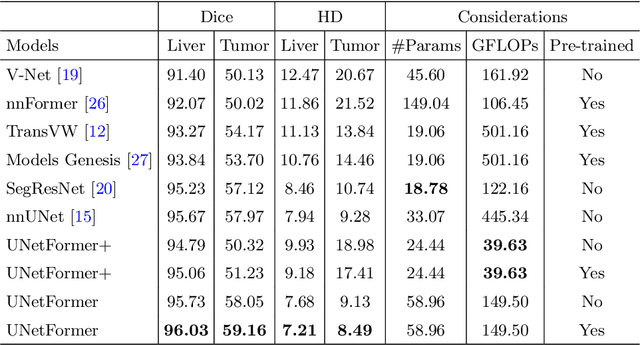
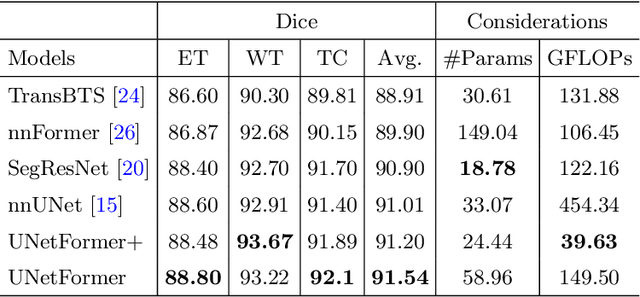
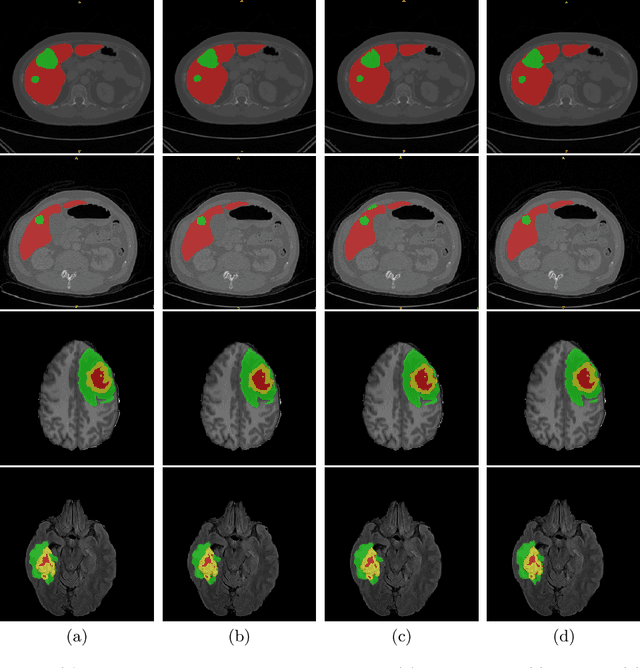
Vision Transformers (ViT)s have recently become popular due to their outstanding modeling capabilities, in particular for capturing long-range information, and scalability to dataset and model sizes which has led to state-of-the-art performance in various computer vision and medical image analysis tasks. In this work, we introduce a unified framework consisting of two architectures, dubbed UNetFormer, with a 3D Swin Transformer-based encoder and Convolutional Neural Network (CNN) and transformer-based decoders. In the proposed model, the encoder is linked to the decoder via skip connections at five different resolutions with deep supervision. The design of proposed architecture allows for meeting a wide range of trade-off requirements between accuracy and computational cost. In addition, we present a methodology for self-supervised pre-training of the encoder backbone via learning to predict randomly masked volumetric tokens using contextual information of visible tokens. We pre-train our framework on a cohort of $5050$ CT images, gathered from publicly available CT datasets, and present a systematic investigation of various components such as masking ratio and patch size that affect the representation learning capability and performance of downstream tasks. We validate the effectiveness of our pre-training approach by fine-tuning and testing our model on liver and liver tumor segmentation task using the Medical Segmentation Decathlon (MSD) dataset and achieve state-of-the-art performance in terms of various segmentation metrics. To demonstrate its generalizability, we train and test the model on BraTS 21 dataset for brain tumor segmentation using MRI images and outperform other methods in terms of Dice score. Code: https://github.com/Project-MONAI/research-contributions
A lightweight and accurate YOLO-like network for small target detection in Aerial Imagery
Apr 05, 2022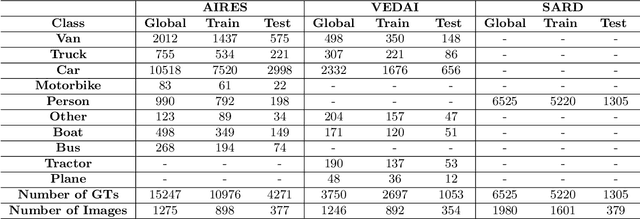

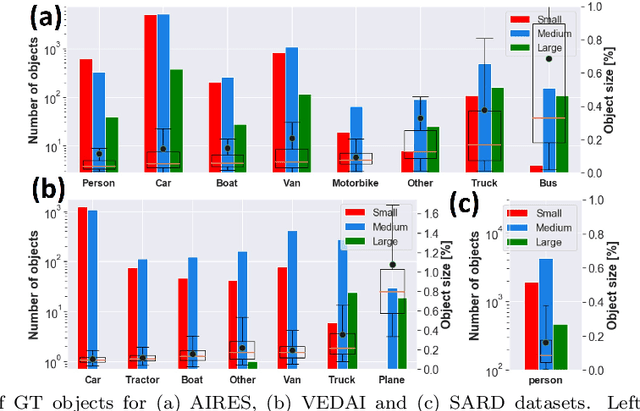
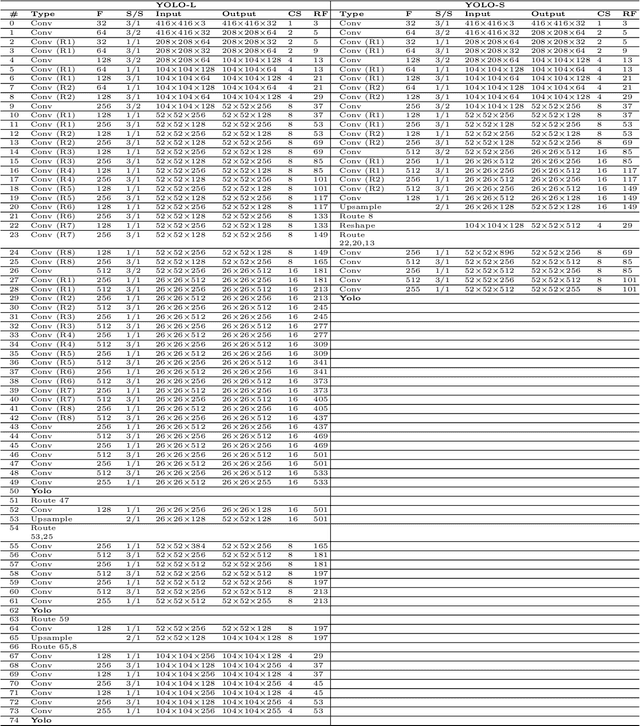
Despite the breakthrough deep learning performances achieved for automatic object detection, small target detection is still a challenging problem, especially when looking at fast and accurate solutions suitable for mobile or edge applications. In this work we present YOLO-S, a simple, fast and efficient network for small target detection. The architecture exploits a small feature extractor based on Darknet20, as well as skip connection, via both bypass and concatenation, and reshape-passthrough layer to alleviate the vanishing gradient problem, promote feature reuse across network and combine low-level positional information with more meaningful high-level information. To verify the performances of YOLO-S, we build "AIRES", a novel dataset for cAr detectIon fRom hElicopter imageS acquired in Europe, and set up experiments on both AIRES and VEDAI datasets, benchmarking this architecture with four baseline detectors. Furthermore, in order to handle efficiently the issue of data insufficiency and domain gap when dealing with a transfer learning strategy, we introduce a transitional learning task over a combined dataset based on DOTAv2 and VEDAI and demonstrate that can enhance the overall accuracy with respect to more general features transferred from COCO data. YOLO-S is from 25% to 50% faster than YOLOv3 and only 15-25% slower than Tiny-YOLOv3, outperforming also YOLOv3 in terms of accuracy in a wide range of experiments. Further simulations performed on SARD dataset demonstrate also its applicability to different scenarios such as for search and rescue operations. Besides, YOLO-S has an 87% decrease of parameter size and almost one half FLOPs of YOLOv3, making practical the deployment for low-power industrial applications.
Imagination-Augmented Natural Language Understanding
Apr 21, 2022
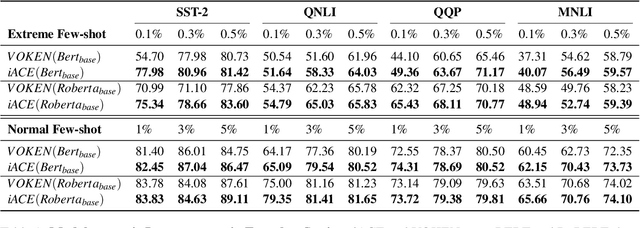
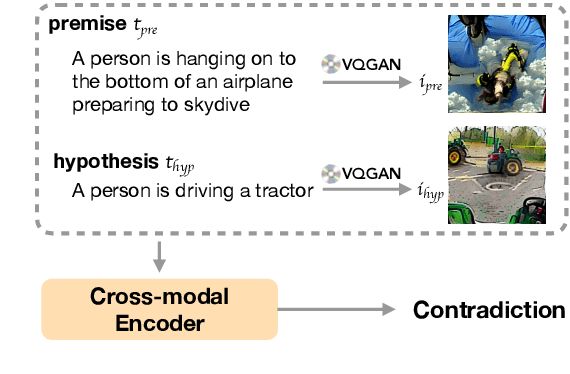
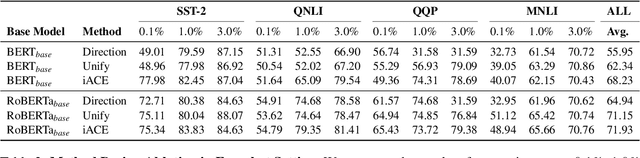
Human brains integrate linguistic and perceptual information simultaneously to understand natural language, and hold the critical ability to render imaginations. Such abilities enable us to construct new abstract concepts or concrete objects, and are essential in involving practical knowledge to solve problems in low-resource scenarios. However, most existing methods for Natural Language Understanding (NLU) are mainly focused on textual signals. They do not simulate human visual imagination ability, which hinders models from inferring and learning efficiently from limited data samples. Therefore, we introduce an Imagination-Augmented Cross-modal Encoder (iACE) to solve natural language understanding tasks from a novel learning perspective -- imagination-augmented cross-modal understanding. iACE enables visual imagination with external knowledge transferred from the powerful generative and pre-trained vision-and-language models. Extensive experiments on GLUE and SWAG show that iACE achieves consistent improvement over visually-supervised pre-trained models. More importantly, results in extreme and normal few-shot settings validate the effectiveness of iACE in low-resource natural language understanding circumstances.