 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PAGP: A physics-assisted Gaussian process framework with active learning for forward and inverse problems of partial differential equations
Apr 06, 2022
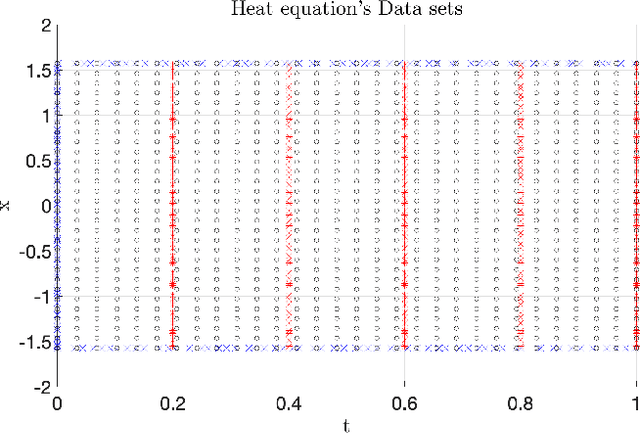
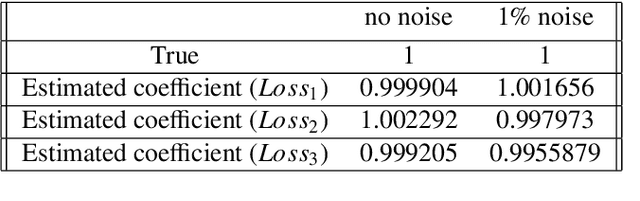
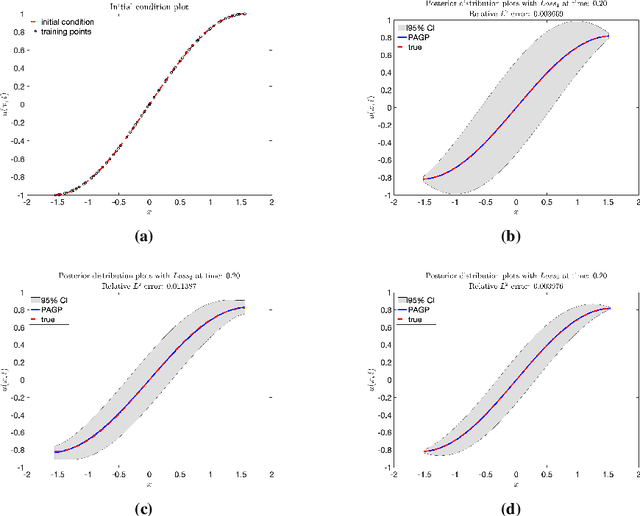

In this work, a Gaussian process regression(GPR) model incorporated with given physical information in partial differential equations(PDEs) is developed: physics-assisted Gaussian processes(PAGP). The targets of this model can be divided into two types of problem: finding solutions or discovering unknown coefficients of given PDEs with initial and boundary conditions. We introduce three different models: continuous time, discrete time and hybrid models. The given physical information is integrated into Gaussian process model through our designed GP loss functions. Three types of loss function are provided in this paper based on two different approaches to train the standard GP model. The first part of the paper introduces the continuous time model which treats temporal domain the same as spatial domain. The unknown coefficients in given PDEs can be jointly learned with GP hyper-parameters by minimizing the designed loss function. In the discrete time models, we first choose a time discretization scheme to discretize the temporal domain. Then the PAGP model is applied at each time step together with the scheme to approximate PDE solutions at given test points of final time. To discover unknown coefficients in this setting, observations at two specific time are needed and a mixed mean square error function is constructed to obtain the optimal coefficients. In the last part, a novel hybrid model combining the continuous and discrete time models is presented. It merges the flexibility of continuous time model and the accuracy of the discrete time model. The performance of choosing different models with different GP loss functions is also discussed. The effectiveness of the proposed PAGP methods is illustrated in our numerical section.
SE-GAN: Skeleton Enhanced GAN-based Model for Brush Handwriting Font Generation
Apr 22, 2022
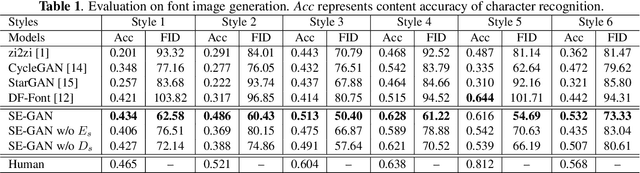
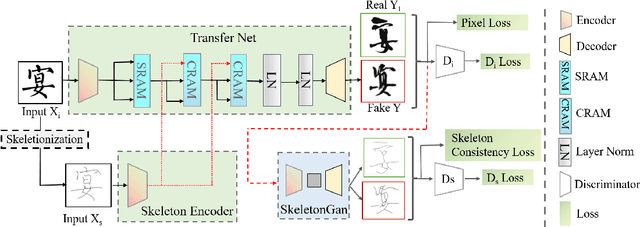
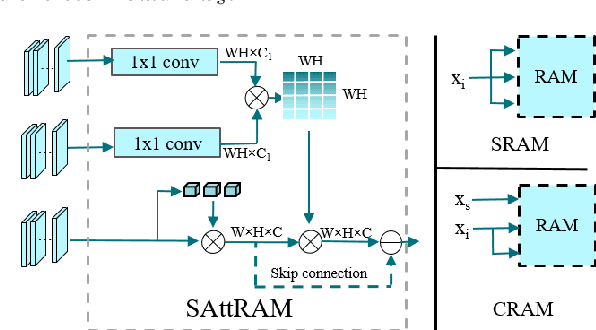
Previous works on font generation mainly focus on the standard print fonts where character's shape is stable and strokes are clearly separated. There is rare research on brush handwriting font generation, which involves holistic structure changes and complex strokes transfer. To address this issue, we propose a novel GAN-based image translation model by integrating the skeleton information. We first extract the skeleton from training images, then design an image encoder and a skeleton encoder to extract corresponding features. A self-attentive refined attention module is devised to guide the model to learn distinctive features between different domains. A skeleton discriminator is involved to first synthesize the skeleton image from the generated image with a pre-trained generator, then to judge its realness to the target one. We also contribute a large-scale brush handwriting font image dataset with six styles and 15,000 high-resolution images. Both quantitative and qualitative experimental results demonstrate the competitiveness of our proposed model.
Coherent FDA Radar Systems: Joint Design of Transmitting and Receiving Array Weighters
Apr 14, 2022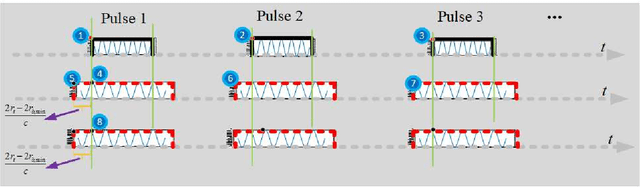

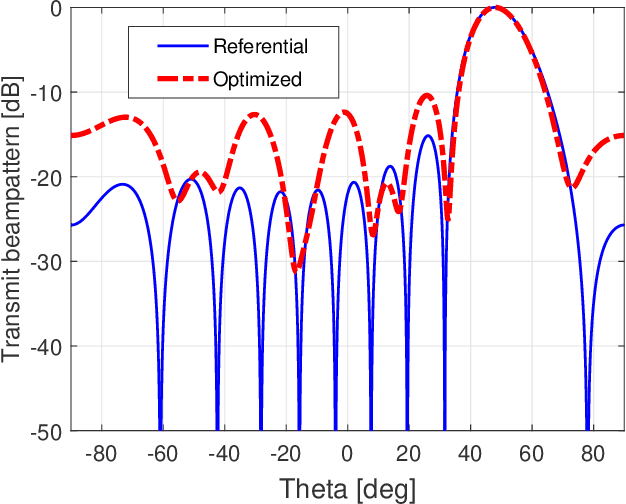
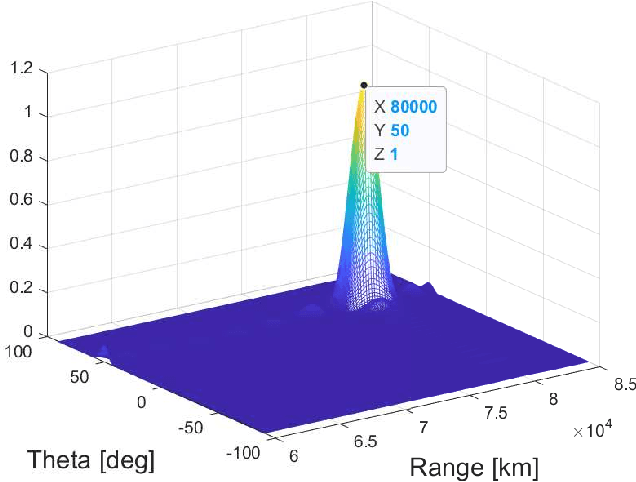
Due to the frequency offset across its array elements, frequency diverse array (FDA) will generate angle-range-dependent and time-variant transmit beampattern. Since existing investigations usually focus on FDA transmitter and only instantaneous beampattern is considered, which cannot fully exploit the time-range characteristics of FDA radar for enhanced performance, in this paper we formulate a multi-carrier mixing receiver for coherent pulsed-Doppler FDA radar to effectively retain the range information of FDA radar returned signals in subsequent receiver processing. Accordingly, the joint transmitter and receiver is systematically modeled with time-range relationship consideration. More importantly, we optimally design the joint transmitting and receiving weighters by maximizing the radiated energy within the desired range-angle sections for given total energy. All proposed methods are verified by simulation results.
Information Requirements of Collision-Based Micromanipulation
Jul 17, 2020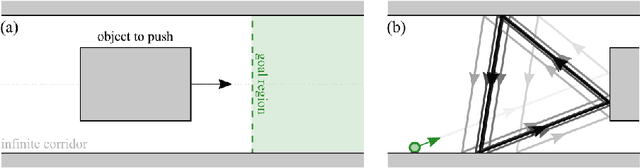
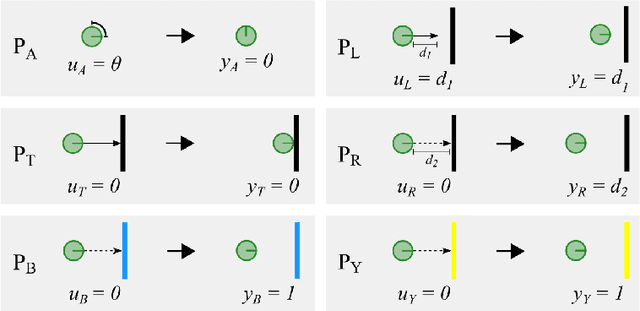
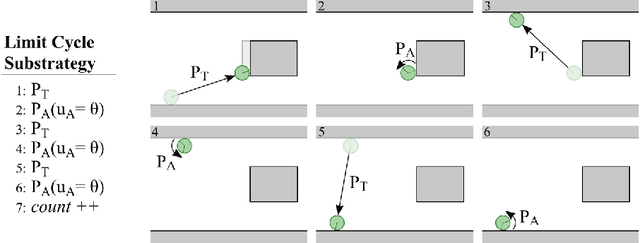
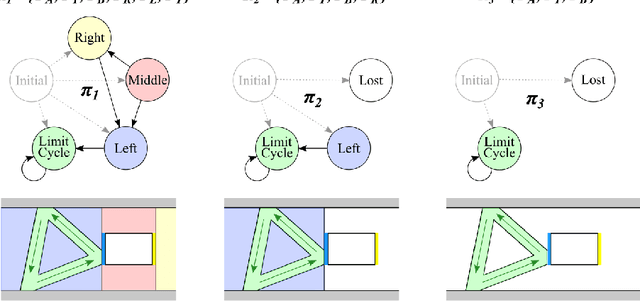
We present a task-centered formal analysis of the relative power of several robot designs, inspired by the unique properties and constraints of micro-scale robotic systems. Our task of interest is object manipulation because it is a fundamental prerequisite for more complex applications such as micro-scale assembly or cell manipulation. Motivated by the difficulty in observing and controlling agents at the micro-scale, we focus on the design of boundary interactions: the robot's motion strategy when it collides with objects or the environment boundary, otherwise known as a bounce rule. We present minimal conditions on the sensing, memory, and actuation requirements of periodic ``bouncing'' robot trajectories that move an object in a desired direction through the incidental forces arising from robot-object collisions. Using an information space framework and a hierarchical controller, we compare several robot designs, emphasizing the information requirements of goal completion under different initial conditions, as well as what is required to recognize irreparable task failure. Finally, we present a physically-motivated model of boundary interactions, and analyze the robustness and dynamical properties of resulting trajectories.
Vision-Language Pre-Training with Triple Contrastive Learning
Mar 03, 2022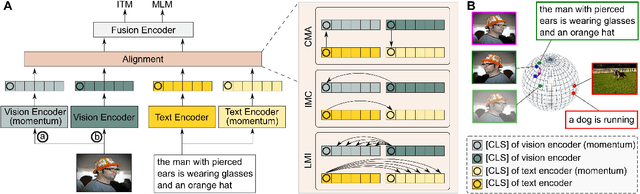

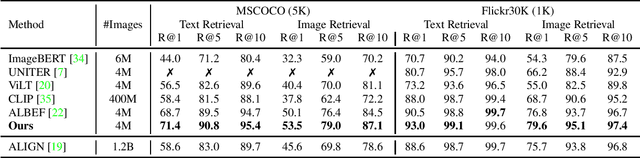
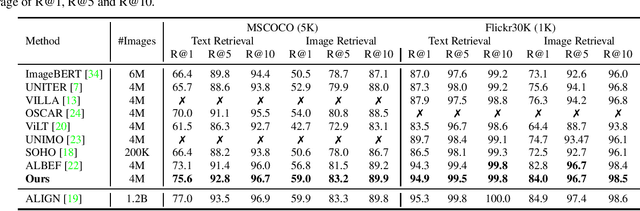
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieve the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Improved Object Pose Estimation via Deep Pre-touch Sensing
Apr 09, 2022

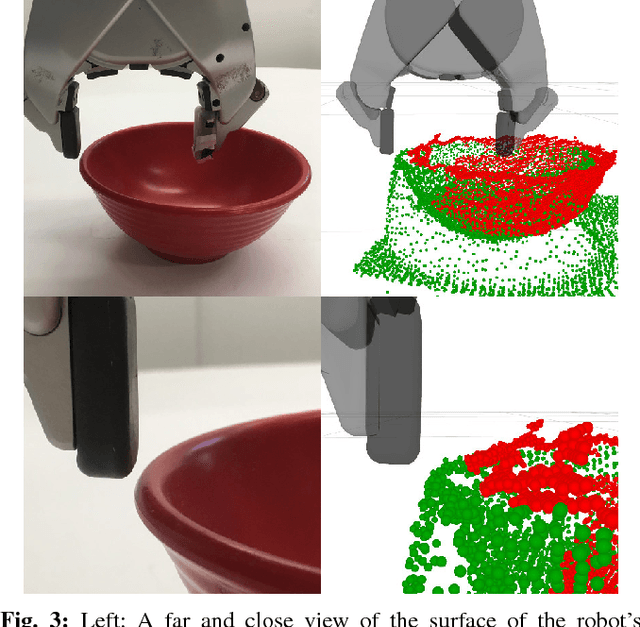

For certain manipulation tasks, object pose estimation from head-mounted cameras may not be sufficiently accurate. This is at least in part due to our inability to perfectly calibrate the coordinate frames of today's high degree of freedom robot arms that link the head to the end-effectors. We present a novel framework combining pre-touch sensing and deep learning to more accurately estimate pose in an efficient manner. The use of pre-touch sensing allows our method to localize the object directly with respect to the robot's end effector, thereby avoiding error caused by miscalibration of the arms. Instead of requiring the robot to scan the entire object with its pre-touch sensor, we use a deep neural network to detect object regions that contain distinctive geometric features. By focusing pre-touch sensing on these regions, the robot can more efficiently gather the information necessary to adjust its original pose estimate. Our region detection network was trained using a new dataset containing objects of widely varying geometries and has been labeled in a scalable fashion that is free from human bias. This dataset is applicable to any task that involves a pre-touch sensor gathering geometric information, and has been made publicly available. We evaluate our framework by having the robot re-estimate the pose of a number of objects of varying geometries. Compared to two simpler region proposal methods, we find that our deep neural network performs significantly better. In addition, we find that after a sequence of scans, objects can typically be localized to within 0.5 cm of their true position. We also observe that the original pose estimate can often be significantly improved after collecting a single quick scan.
Domain Invariant Masked Autoencoders for Self-supervised Learning from Multi-domains
May 10, 2022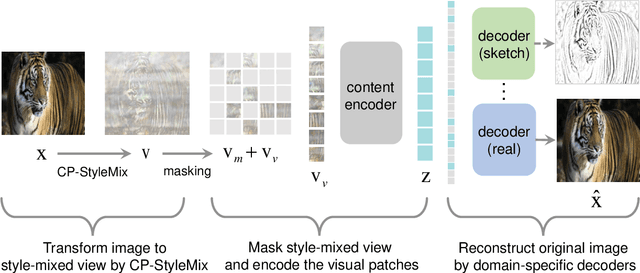
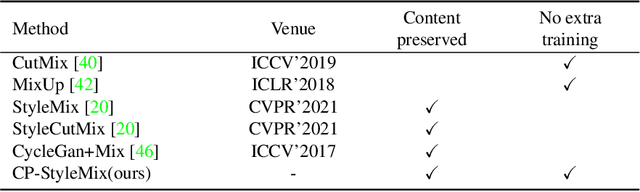

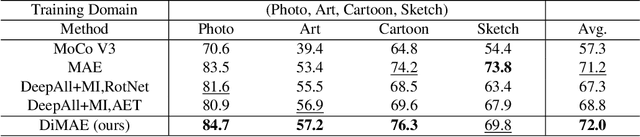
Generalizing learned representations across significantly different visual domains is a fundamental yet crucial ability of the human visual system. While recent self-supervised learning methods have achieved good performances with evaluation set on the same domain as the training set, they will have an undesirable performance decrease when tested on a different domain. Therefore, the self-supervised learning from multiple domains task is proposed to learn domain-invariant features that are not only suitable for evaluation on the same domain as the training set but also can be generalized to unseen domains. In this paper, we propose a Domain-invariant Masked AutoEncoder (DiMAE) for self-supervised learning from multi-domains, which designs a new pretext task, \emph{i.e.,} the cross-domain reconstruction task, to learn domain-invariant features. The core idea is to augment the input image with style noise from different domains and then reconstruct the image from the embedding of the augmented image, regularizing the encoder to learn domain-invariant features. To accomplish the idea, DiMAE contains two critical designs, 1) content-preserved style mix, which adds style information from other domains to input while persevering the content in a parameter-free manner, and 2) multiple domain-specific decoders, which recovers the corresponding domain style of input to the encoded domain-invariant features for reconstruction. Experiments on PACS and DomainNet illustrate that DiMAE achieves considerable gains compared with recent state-of-the-art methods.
VesNet-RL: Simulation-based Reinforcement Learning for Real-World US Probe Navigation
May 10, 2022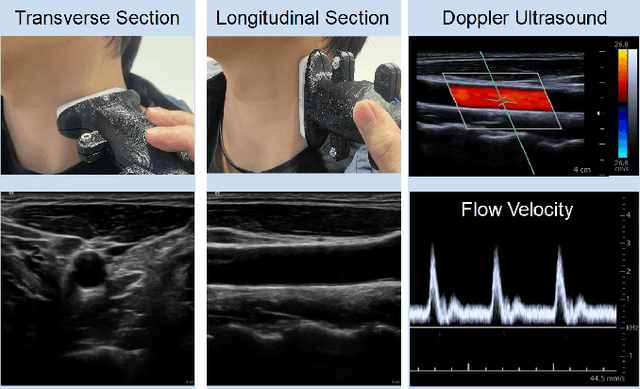
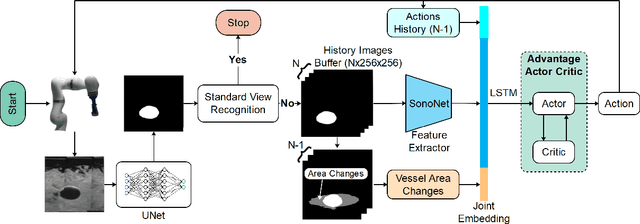
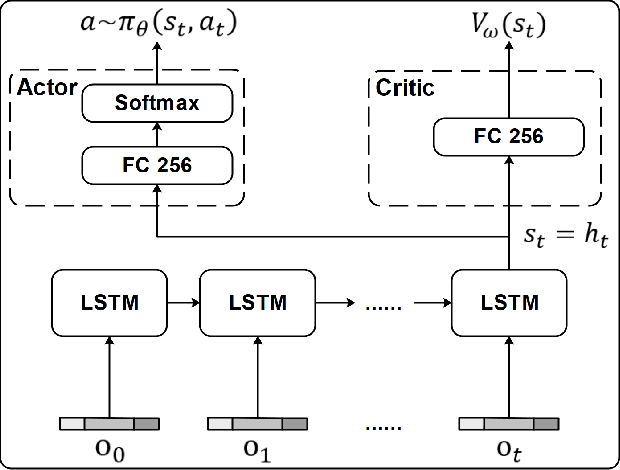
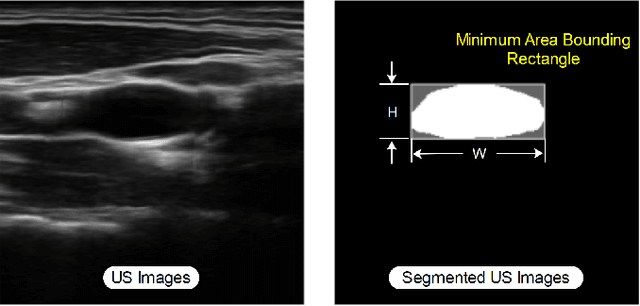
Ultrasound (US) is one of the most common medical imaging modalities since it is radiation-free, low-cost, and real-time. In freehand US examinations, sonographers often navigate a US probe to visualize standard examination planes with rich diagnostic information. However, reproducibility and stability of the resulting images often suffer from intra- and inter-operator variation. Reinforcement learning (RL), as an interaction-based learning method, has demonstrated its effectiveness in visual navigating tasks; however, RL is limited in terms of generalization. To address this challenge, we propose a simulation-based RL framework for real-world navigation of US probes towards the standard longitudinal views of vessels. A UNet is used to provide binary masks from US images; thereby, the RL agent trained on simulated binary vessel images can be applied in real scenarios without further training. To accurately characterize actual states, a multi-modality state representation structure is introduced to facilitate the understanding of environments. Moreover, considering the characteristics of vessels, a novel standard view recognition approach based on the minimum bounding rectangle is proposed to terminate the searching process. To evaluate the effectiveness of the proposed method, the trained policy is validated virtually on 3D volumes of a volunteer's in-vivo carotid artery, and physically on custom-designed gel phantoms using robotic US. The results demonstrate that proposed approach can effectively and accurately navigate the probe towards the longitudinal view of vessels.
Improving the Generalizability of Depression Detection by Leveraging Clinical Questionnaires
Apr 21, 2022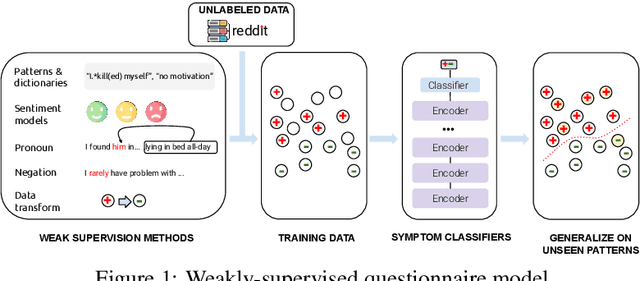
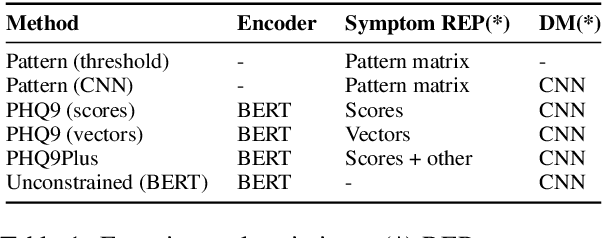
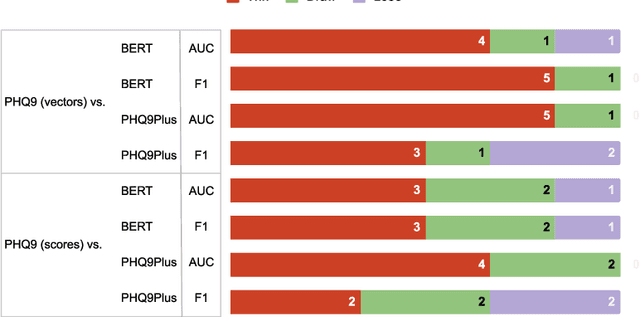
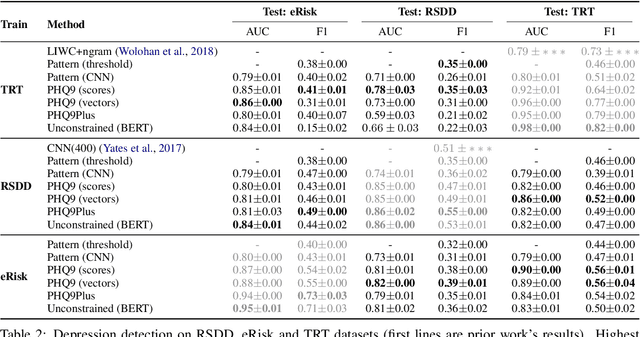
Automated methods have been widely used to identify and analyze mental health conditions (e.g., depression) from various sources of information, including social media. Yet, deployment of such models in real-world healthcare applications faces challenges including poor out-of-domain generalization and lack of trust in black box models. In this work, we propose approaches for depression detection that are constrained to different degrees by the presence of symptoms described in PHQ9, a questionnaire used by clinicians in the depression screening process. In dataset-transfer experiments on three social media datasets, we find that grounding the model in PHQ9's symptoms substantially improves its ability to generalize to out-of-distribution data compared to a standard BERT-based approach. Furthermore, this approach can still perform competitively on in-domain data. These results and our qualitative analyses suggest that grounding model predictions in clinically-relevant symptoms can improve generalizability while producing a model that is easier to inspect.
VRConvMF: Visual Recurrent Convolutional Matrix Factorization for Movie Recommendation
Feb 16, 2022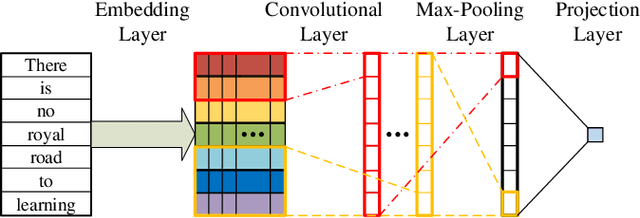
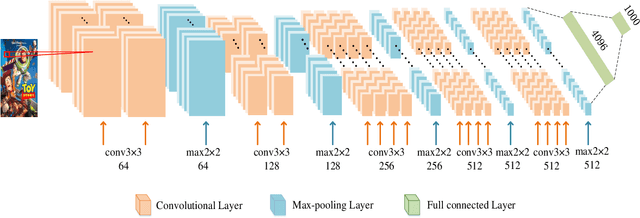
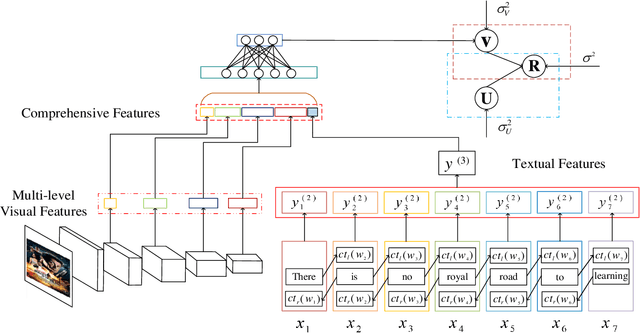
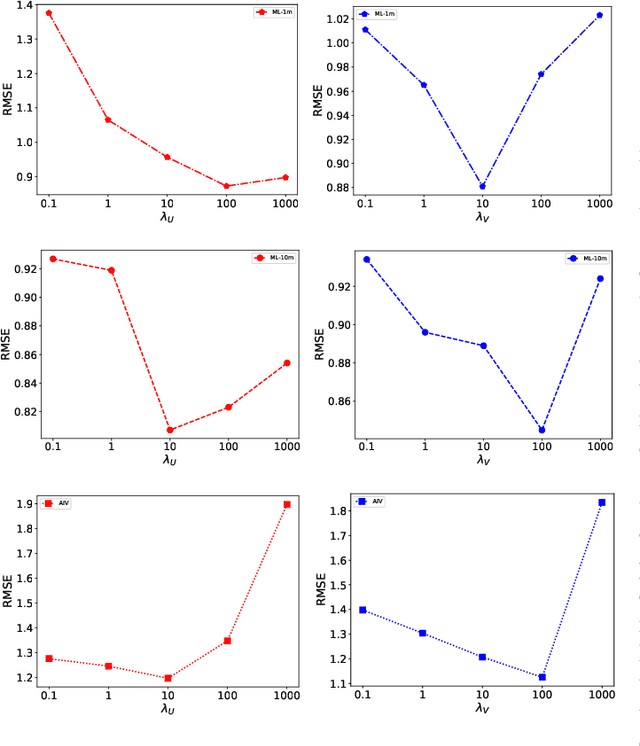
Sparsity of user-to-item rating data becomes one of challenging issues in the recommender systems, which severely deteriorates the recommendation performance. Fortunately, context-aware recommender systems can alleviate the sparsity problem by making use of some auxiliary information, such as the information of both the users and items. In particular, the visual information of items, such as the movie poster, can be considered as the supplement for item description documents, which helps to obtain more item features. In this paper, we focus on movie recommender system and propose a probabilistic matrix factorization based recommendation scheme called visual recurrent convolutional matrix factorization (VRConvMF), which utilizes the textual and multi-level visual features extracted from the descriptive texts and posters respectively. We implement the proposed VRConvMF and conduct extensive experiments on three commonly used real world datasets to validate its effectiveness. The experimental results illustrate that the proposed VRConvMF outperforms the existing schemes.