 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Painful intelligence: What AI can tell us about human suffering
May 27, 2022
This book uses the modern theory of artificial intelligence (AI) to understand human suffering or mental pain. Both humans and sophisticated AI agents process information about the world in order to achieve goals and obtain rewards, which is why AI can be used as a model of the human brain and mind. This book intends to make the theory accessible to a relatively general audience, requiring only some relevant scientific background. The book starts with the assumption that suffering is mainly caused by frustration. Frustration means the failure of an agent (whether AI or human) to achieve a goal or a reward it wanted or expected. Frustration is inevitable because of the overwhelming complexity of the world, limited computational resources, and scarcity of good data. In particular, such limitations imply that an agent acting in the real world must cope with uncontrollability, unpredictability, and uncertainty, which all lead to frustration. Fundamental in such modelling is the idea of learning, or adaptation to the environment. While AI uses machine learning, humans and animals adapt by a combination of evolutionary mechanisms and ordinary learning. Even frustration is fundamentally an error signal that the system uses for learning. This book explores various aspects and limitations of learning algorithms and their implications regarding suffering. At the end of the book, the computational theory is used to derive various interventions or training methods that will reduce suffering in humans. The amount of frustration is expressed by a simple equation which indicates how it can be reduced. The ensuing interventions are very similar to those proposed by Buddhist and Stoic philosophy, and include mindfulness meditation. Therefore, this book can be interpreted as an exposition of a computational theory justifying why such philosophies and meditation reduce human suffering.
Rethinking Position Bias Modeling with Knowledge Distillation for CTR Prediction
Apr 01, 2022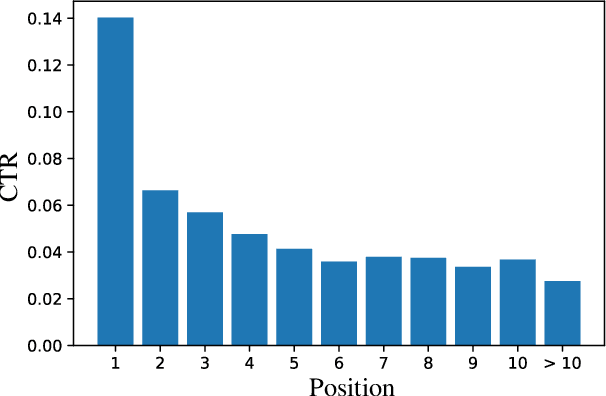
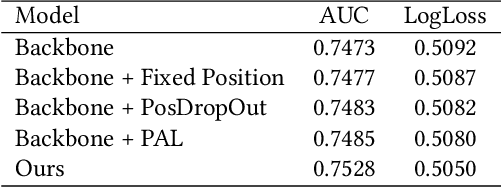
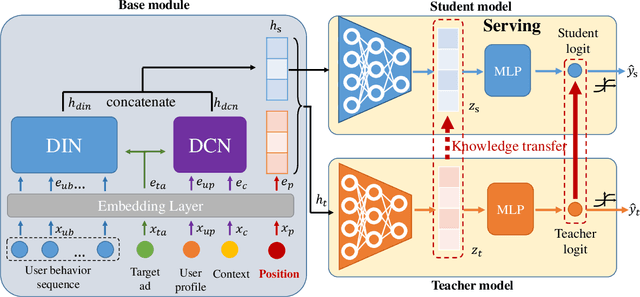
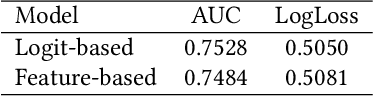
Click-through rate (CTR) Prediction is of great importance in real-world online ads systems. One challenge for the CTR prediction task is to capture the real interest of users from their clicked items, which is inherently biased by presented positions of items, i.e., more front positions tend to obtain higher CTR values. A popular line of existing works focuses on explicitly estimating position bias by result randomization which is expensive and inefficient, or by inverse propensity weighting (IPW) which relies heavily on the quality of the propensity estimation. Another common solution is modeling position as features during offline training and simply adopting fixed value or dropout tricks when serving. However, training-inference inconsistency can lead to sub-optimal performance. Furthermore, post-click information such as position values is informative while less exploited in CTR prediction. This work proposes a simple yet efficient knowledge distillation framework to alleviate the impact of position bias and leverage position information to improve CTR prediction. We demonstrate the performance of our proposed method on a real-world production dataset and online A/B tests, achieving significant improvements over competing baseline models. The proposed method has been deployed in the real world online ads systems, serving main traffic on one of the world's largest e-commercial platforms.
GaitEdge: Beyond Plain End-to-end Gait Recognition for Better Practicality
Mar 08, 2022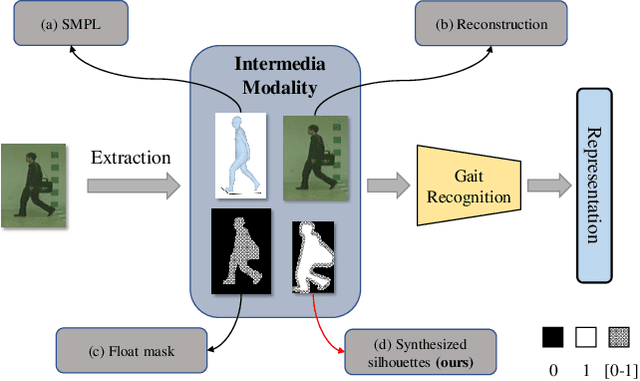
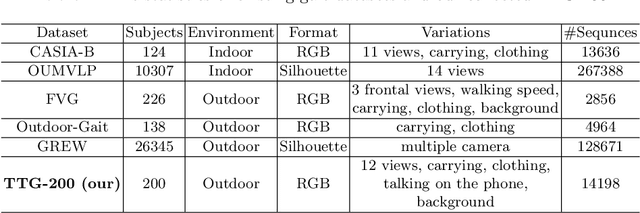
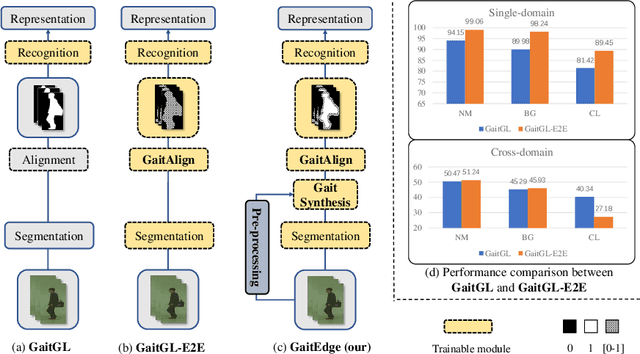
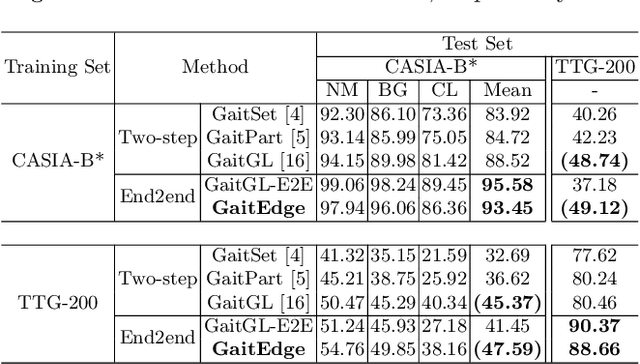
Gait is one of the most promising biometrics to identify individuals at a long distance. Although most previous methods have focused on recognizing the silhouettes, several end-to-end methods that extract gait features directly from RGB images perform better. However, we argue that these end-to-end methods inevitably suffer from the gait-unrelated noises, i.e., low-level texture and colorful information. Experimentally, we design both the cross-domain evaluation and visualization to stand for this view. In this work, we propose a novel end-to-end framework named GaitEdge which can effectively block gait-unrelated information and release end-to-end training potential. Specifically, GaitEdge synthesizes the output of the pedestrian segmentation network and then feeds it to the subsequent recognition network, where the synthetic silhouettes consist of trainable edges of bodies and fixed interiors to limit the information that the recognition network receives. Besides, GaitAlign for aligning silhouettes is embedded into the GaitEdge without loss of differentiability. Experimental results on CASIA-B and our newly built TTG-200 indicate that GaitEdge significantly outperforms the previous methods and provides a more practical end-to-end paradigm for blocking RGB noises effectively. All the source code will be released.
lpSpikeCon: Enabling Low-Precision Spiking Neural Network Processing for Efficient Unsupervised Continual Learning on Autonomous Agents
May 24, 2022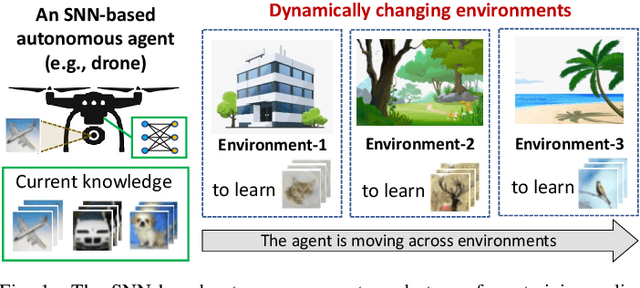
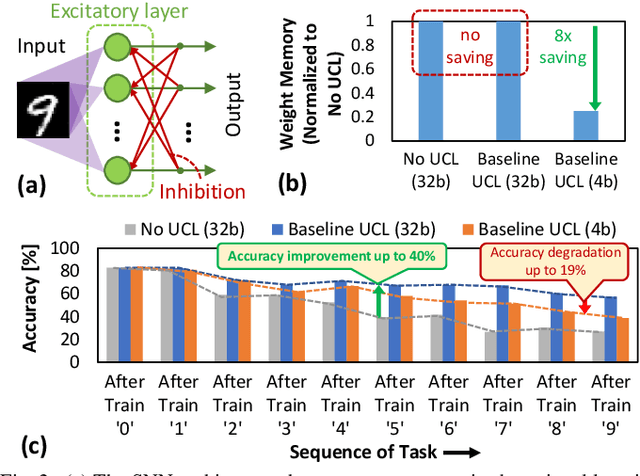
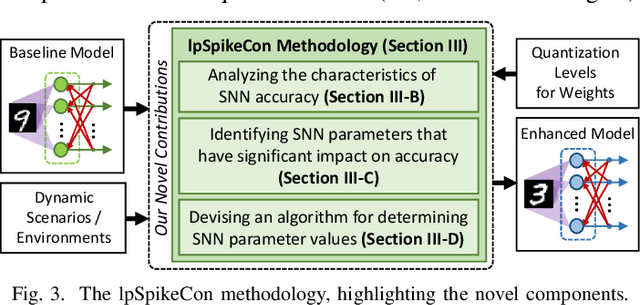
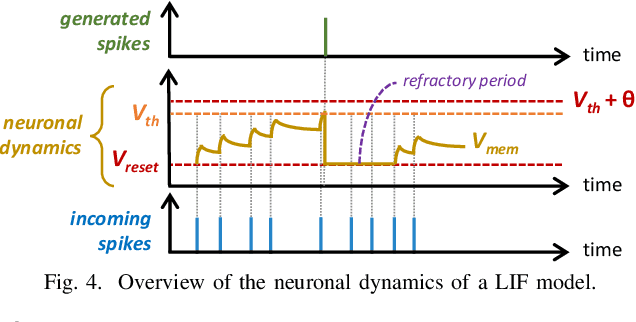
Recent advances have shown that SNN-based systems can efficiently perform unsupervised continual learning due to their bio-plausible learning rule, e.g., Spike-Timing-Dependent Plasticity (STDP). Such learning capabilities are especially beneficial for use cases like autonomous agents (e.g., robots and UAVs) that need to continuously adapt to dynamically changing scenarios/environments, where new data gathered directly from the environment may have novel features that should be learned online. Current state-of-the-art works employ high-precision weights (i.e., 32 bit) for both training and inference phases, which pose high memory and energy costs thereby hindering efficient embedded implementations of such systems for battery-driven mobile autonomous systems. On the other hand, precision reduction may jeopardize the quality of unsupervised continual learning due to information loss. Towards this, we propose lpSpikeCon, a novel methodology to enable low-precision SNN processing for efficient unsupervised continual learning on resource-constrained autonomous agents/systems. Our lpSpikeCon methodology employs the following key steps: (1) analyzing the impacts of training the SNN model under unsupervised continual learning settings with reduced weight precision on the inference accuracy; (2) leveraging this study to identify SNN parameters that have a significant impact on the inference accuracy; and (3) developing an algorithm for searching the respective SNN parameter values that improve the quality of unsupervised continual learning. The experimental results show that our lpSpikeCon can reduce weight memory of the SNN model by 8x (i.e., by judiciously employing 4-bit weights) for performing online training with unsupervised continual learning and achieve no accuracy loss in the inference phase, as compared to the baseline model with 32-bit weights across different network sizes.
One Model, Multiple Modalities: A Sparsely Activated Approach for Text, Sound, Image, Video and Code
May 12, 2022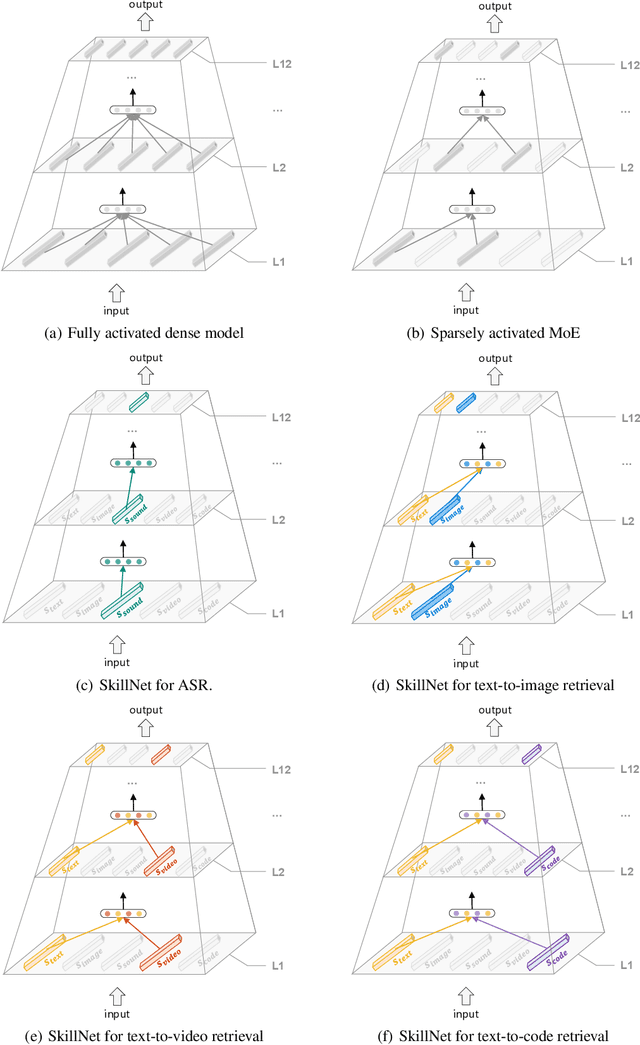

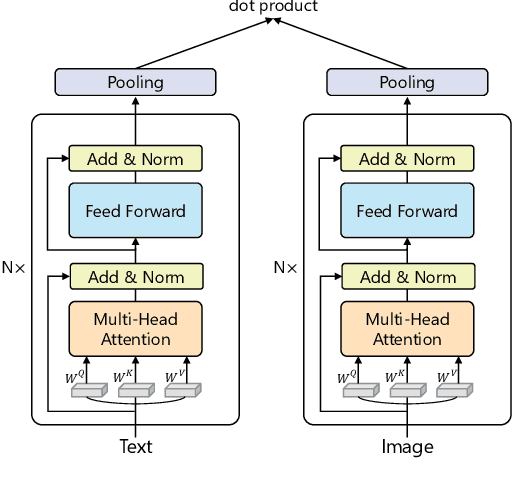
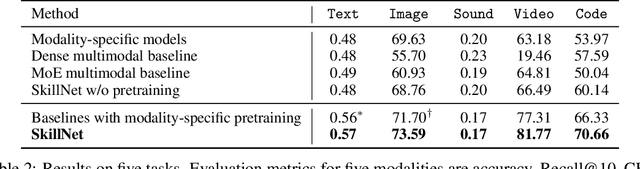
People perceive the world with multiple senses (e.g., through hearing sounds, reading words and seeing objects). However, most existing AI systems only process an individual modality. This paper presents an approach that excels at handling multiple modalities of information with a single model. In our "{SkillNet}" model, different parts of the parameters are specialized for processing different modalities. Unlike traditional dense models that always activate all the model parameters, our model sparsely activates parts of the parameters whose skills are relevant to the task. Such model design enables SkillNet to learn skills in a more interpretable way. We develop our model for five modalities including text, image, sound, video and code. Results show that, SkillNet performs comparably to five modality-specific fine-tuned models. Moreover, our model supports self-supervised pretraining with the same sparsely activated way, resulting in better initialized parameters for different modalities. We find that pretraining significantly improves the performance of SkillNet on five modalities, on par with or even better than baselines with modality-specific pretraining. On the task of Chinese text-to-image retrieval, our final system achieves higher accuracy than existing leading systems including Wukong{ViT-B} and Wenlan 2.0 while using less number of activated parameters.
Unified Pretraining Framework for Document Understanding
Apr 28, 2022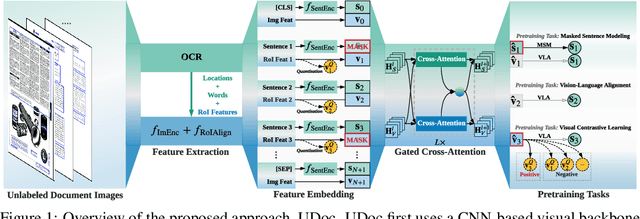
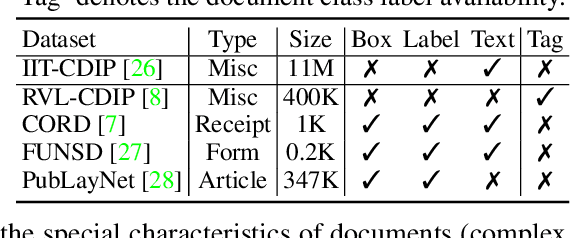
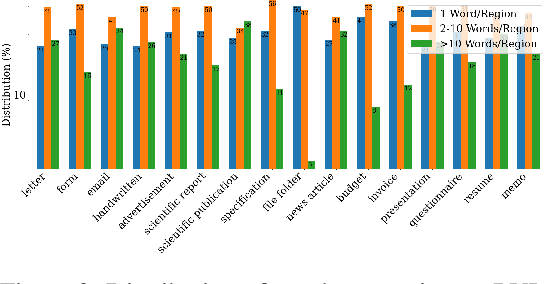
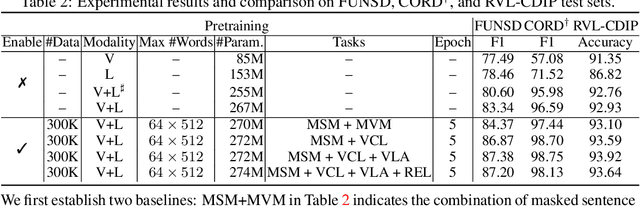
Document intelligence automates the extraction of information from documents and supports many business applications. Recent self-supervised learning methods on large-scale unlabeled document datasets have opened up promising directions towards reducing annotation efforts by training models with self-supervised objectives. However, most of the existing document pretraining methods are still language-dominated. We present UDoc, a new unified pretraining framework for document understanding. UDoc is designed to support most document understanding tasks, extending the Transformer to take multimodal embeddings as input. Each input element is composed of words and visual features from a semantic region of the input document image. An important feature of UDoc is that it learns a generic representation by making use of three self-supervised losses, encouraging the representation to model sentences, learn similarities, and align modalities. Extensive empirical analysis demonstrates that the pretraining procedure learns better joint representations and leads to improvements in downstream tasks.
Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion
May 04, 2022
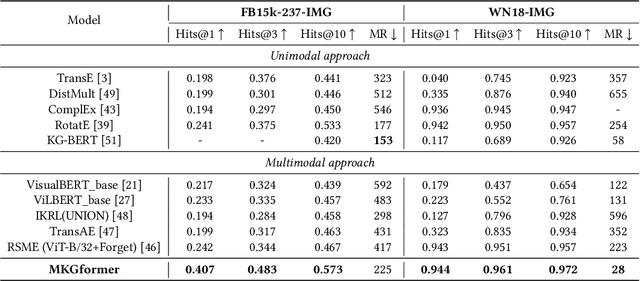
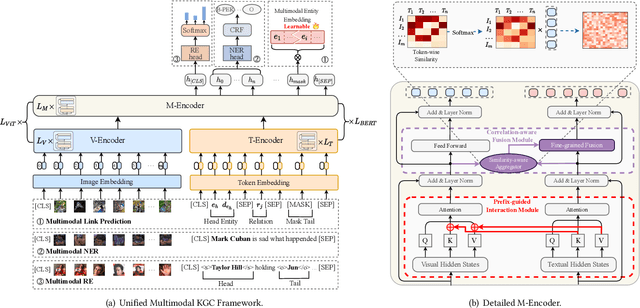
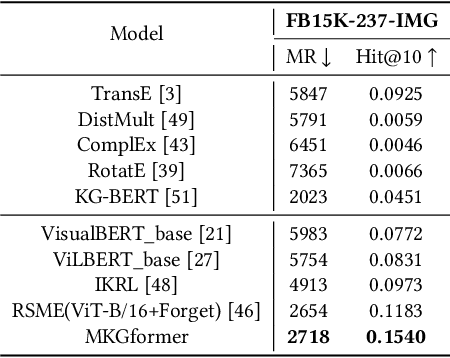
Multimodal Knowledge Graphs (MKGs), which organize visual-text factual knowledge, have recently been successfully applied to tasks such as information retrieval, question answering, and recommendation system. Since most MKGs are far from complete, extensive knowledge graph completion studies have been proposed focusing on the multimodal entity, relation extraction and link prediction. However, different tasks and modalities require changes to the model architecture, and not all images/objects are relevant to text input, which hinders the applicability to diverse real-world scenarios. In this paper, we propose a hybrid transformer with multi-level fusion to address those issues. Specifically, we leverage a hybrid transformer architecture with unified input-output for diverse multimodal knowledge graph completion tasks. Moreover, we propose multi-level fusion, which integrates visual and text representation via coarse-grained prefix-guided interaction and fine-grained correlation-aware fusion modules. We conduct extensive experiments to validate that our MKGformer can obtain SOTA performance on four datasets of multimodal link prediction, multimodal RE, and multimodal NER. Code is available in https://github.com/zjunlp/MKGformer.
Learning from the Best: Rationalizing Prediction by Adversarial Information Calibration
Dec 18, 2020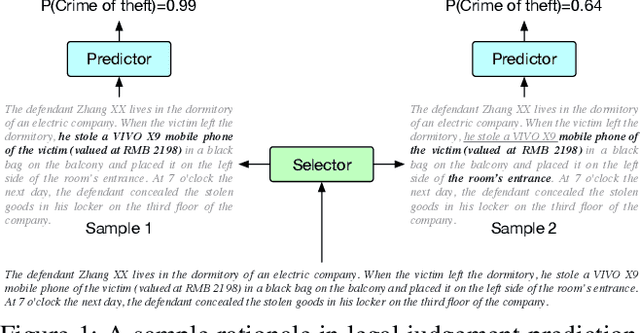
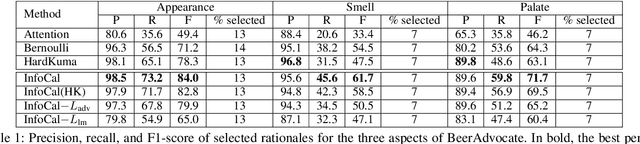
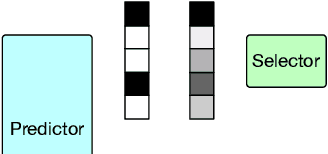

Explaining the predictions of AI models is paramount in safety-critical applications, such as in legal or medical domains. One form of explanation for a prediction is an extractive rationale, i.e., a subset of features of an instance that lead the model to give its prediction on the instance. Previous works on generating extractive rationales usually employ a two-phase model: a selector that selects the most important features (i.e., the rationale) followed by a predictor that makes the prediction based exclusively on the selected features. One disadvantage of these works is that the main signal for learning to select features comes from the comparison of the answers given by the predictor and the ground-truth answers. In this work, we propose to squeeze more information from the predictor via an information calibration method. More precisely, we train two models jointly: one is a typical neural model that solves the task at hand in an accurate but black-box manner, and the other is a selector-predictor model that additionally produces a rationale for its prediction. The first model is used as a guide to the second model. We use an adversarial-based technique to calibrate the information extracted by the two models such that the difference between them is an indicator of the missed or over-selected features. In addition, for natural language tasks, we propose to use a language-model-based regularizer to encourage the extraction of fluent rationales. Experimental results on a sentiment analysis task as well as on three tasks from the legal domain show the effectiveness of our approach to rationale extraction.
TabLeX: A Benchmark Dataset for Structure and Content Information Extraction from Scientific Tables
May 12, 2021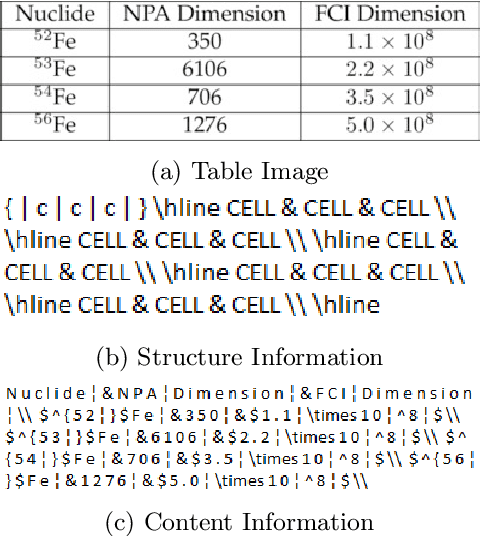
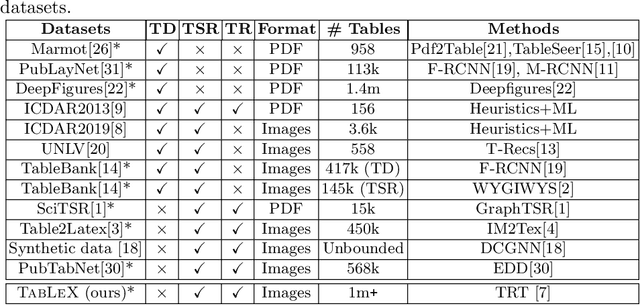
Information Extraction (IE) from the tables present in scientific articles is challenging due to complicated tabular representations and complex embedded text. This paper presents TabLeX, a large-scale benchmark dataset comprising table images generated from scientific articles. TabLeX consists of two subsets, one for table structure extraction and the other for table content extraction. Each table image is accompanied by its corresponding LATEX source code. To facilitate the development of robust table IE tools, TabLeX contains images in different aspect ratios and in a variety of fonts. Our analysis sheds light on the shortcomings of current state-of-the-art table extraction models and shows that they fail on even simple table images. Towards the end, we experiment with a transformer-based existing baseline to report performance scores. In contrast to the static benchmarks, we plan to augment this dataset with more complex and diverse tables at regular intervals.
Bayesian Convolutional Neural Networks for Limited Data Hyperspectral Remote Sensing Image Classification
May 19, 2022

Employing deep neural networks for Hyper-spectral remote sensing (HSRS) image classification is a challenging task. HSRS images have high dimensionality and a large number of channels with substantial redundancy between channels. In addition, the training data for classifying HSRS images is limited and the amount of available training data is much smaller compared to other classification tasks. These factors complicate the training process of deep neural networks with many parameters and cause them to not perform well even compared to conventional models. Moreover, convolutional neural networks produce over-confident predictions, which is highly undesirable considering the aforementioned problem. In this work, we use a special class of deep neural networks, namely Bayesian neural network, to classify HSRS images. To the extent of our knowledge, this is the first time that this class of neural networks has been used in HSRS image classification. Bayesian neural networks provide an inherent tool for measuring uncertainty. We show that a Bayesian network can outperform a similarly-constructed non-Bayesian convolutional neural network (CNN) and an off-the-shelf Random Forest (RF). Moreover, experimental results for the Pavia Centre, Salinas, and Botswana datasets show that the Bayesian network is more stable and robust to model pruning. Furthermore, we analyze the prediction uncertainty of the Bayesian model and show that the prediction uncertainty metric can provide information about the model predictions and has a positive correlation with the prediction error.