 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Measuring Vision-Language STEM Skills of Neural Models
Feb 27, 2024
We introduce a new challenge to test the STEM skills of neural models. The problems in the real world often require solutions, combining knowledge from STEM (science, technology, engineering, and math). Unlike existing datasets, our dataset requires the understanding of multimodal vision-language information of STEM. Our dataset features one of the largest and most comprehensive datasets for the challenge. It includes 448 skills and 1,073,146 questions spanning all STEM subjects. Compared to existing datasets that often focus on examining expert-level ability, our dataset includes fundamental skills and questions designed based on the K-12 curriculum. We also add state-of-the-art foundation models such as CLIP and GPT-3.5-Turbo to our benchmark. Results show that the recent model advances only help master a very limited number of lower grade-level skills (2.5% in the third grade) in our dataset. In fact, these models are still well below (averaging 54.7%) the performance of elementary students, not to mention near expert-level performance. To understand and increase the performance on our dataset, we teach the models on a training split of our dataset. Even though we observe improved performance, the model performance remains relatively low compared to average elementary students. To solve STEM problems, we will need novel algorithmic innovations from the community.
An Efficient MLP-based Point-guided Segmentation Network for Ore Images with Ambiguous Boundary
Feb 27, 2024The precise segmentation of ore images is critical to the successful execution of the beneficiation process. Due to the homogeneous appearance of the ores, which leads to low contrast and unclear boundaries, accurate segmentation becomes challenging, and recognition becomes problematic. This paper proposes a lightweight framework based on Multi-Layer Perceptron (MLP), which focuses on solving the problem of edge burring. Specifically, we introduce a lightweight backbone better suited for efficiently extracting low-level features. Besides, we design a feature pyramid network consisting of two MLP structures that balance local and global information thus enhancing detection accuracy. Furthermore, we propose a novel loss function that guides the prediction points to match the instance edge points to achieve clear object boundaries. We have conducted extensive experiments to validate the efficacy of our proposed method. Our approach achieves a remarkable processing speed of over 27 frames per second (FPS) with a model size of only 73 MB. Moreover, our method delivers a consistently high level of accuracy, with impressive performance scores of 60.4 and 48.9 in~$AP_{50}^{box}$ and~$AP_{50}^{mask}$ respectively, as compared to the currently available state-of-the-art techniques, when tested on the ore image dataset. The source code will be released at \url{https://github.com/MVME-HBUT/ORENEXT}.
Video as the New Language for Real-World Decision Making
Feb 27, 2024Both text and video data are abundant on the internet and support large-scale self-supervised learning through next token or frame prediction. However, they have not been equally leveraged: language models have had significant real-world impact, whereas video generation has remained largely limited to media entertainment. Yet video data captures important information about the physical world that is difficult to express in language. To address this gap, we discuss an under-appreciated opportunity to extend video generation to solve tasks in the real world. We observe how, akin to language, video can serve as a unified interface that can absorb internet knowledge and represent diverse tasks. Moreover, we demonstrate how, like language models, video generation can serve as planners, agents, compute engines, and environment simulators through techniques such as in-context learning, planning and reinforcement learning. We identify major impact opportunities in domains such as robotics, self-driving, and science, supported by recent work that demonstrates how such advanced capabilities in video generation are plausibly within reach. Lastly, we identify key challenges in video generation that mitigate progress. Addressing these challenges will enable video generation models to demonstrate unique value alongside language models in a wider array of AI applications.
CustomSketching: Sketch Concept Extraction for Sketch-based Image Synthesis and Editing
Feb 27, 2024Personalization techniques for large text-to-image (T2I) models allow users to incorporate new concepts from reference images. However, existing methods primarily rely on textual descriptions, leading to limited control over customized images and failing to support fine-grained and local editing (e.g., shape, pose, and details). In this paper, we identify sketches as an intuitive and versatile representation that can facilitate such control, e.g., contour lines capturing shape information and flow lines representing texture. This motivates us to explore a novel task of sketch concept extraction: given one or more sketch-image pairs, we aim to extract a special sketch concept that bridges the correspondence between the images and sketches, thus enabling sketch-based image synthesis and editing at a fine-grained level. To accomplish this, we introduce CustomSketching, a two-stage framework for extracting novel sketch concepts. Considering that an object can often be depicted by a contour for general shapes and additional strokes for internal details, we introduce a dual-sketch representation to reduce the inherent ambiguity in sketch depiction. We employ a shape loss and a regularization loss to balance fidelity and editability during optimization. Through extensive experiments, a user study, and several applications, we show our method is effective and superior to the adapted baselines.
Denoising Diffusion Models for Inpainting of Healthy Brain Tissue
Feb 27, 2024This paper is a contribution to the "BraTS 2023 Local Synthesis of Healthy Brain Tissue via Inpainting Challenge". The task of this challenge is to transform tumor tissue into healthy tissue in brain magnetic resonance (MR) images. This idea originates from the problem that MR images can be evaluated using automatic processing tools, however, many of these tools are optimized for the analysis of healthy tissue. By solving the given inpainting task, we enable the automatic analysis of images featuring lesions, and further downstream tasks. Our approach builds on denoising diffusion probabilistic models. We use a 2D model that is trained using slices in which healthy tissue was cropped out and is learned to be inpainted again. This allows us to use the ground truth healthy tissue during training. In the sampling stage, we replace the slices containing diseased tissue in the original 3D volume with the slices containing the healthy tissue inpainting. With our approach, we achieve comparable results to the competing methods. On the validation set our model achieves a mean SSIM of 0.7804, a PSNR of 20.3525 and a MSE of 0.0113. In future we plan to extend our 2D model to a 3D model, allowing to inpaint the region of interest as a whole without losing context information of neighboring slices.
VoCo: A Simple-yet-Effective Volume Contrastive Learning Framework for 3D Medical Image Analysis
Feb 27, 2024Self-Supervised Learning (SSL) has demonstrated promising results in 3D medical image analysis. However, the lack of high-level semantics in pre-training still heavily hinders the performance of downstream tasks. We observe that 3D medical images contain relatively consistent contextual position information, i.e., consistent geometric relations between different organs, which leads to a potential way for us to learn consistent semantic representations in pre-training. In this paper, we propose a simple-yet-effective Volume Contrast (VoCo) framework to leverage the contextual position priors for pre-training. Specifically, we first generate a group of base crops from different regions while enforcing feature discrepancy among them, where we employ them as class assignments of different regions. Then, we randomly crop sub-volumes and predict them belonging to which class (located at which region) by contrasting their similarity to different base crops, which can be seen as predicting contextual positions of different sub-volumes. Through this pretext task, VoCo implicitly encodes the contextual position priors into model representations without the guidance of annotations, enabling us to effectively improve the performance of downstream tasks that require high-level semantics. Extensive experimental results on six downstream tasks demonstrate the superior effectiveness of VoCo. Code will be available at https://github.com/Luffy03/VoCo.
4CNet: A Confidence-Aware, Contrastive, Conditional, Consistency Model for Robot Map Prediction in Multi-Robot Environments
Feb 27, 2024Mobile robots in unknown cluttered environments with irregularly shaped obstacles often face sensing, energy, and communication challenges which directly affect their ability to explore these environments. In this paper, we introduce a novel deep learning method, Confidence-Aware Contrastive Conditional Consistency Model (4CNet), for mobile robot map prediction during resource-limited exploration in multi-robot environments. 4CNet uniquely incorporates: 1) a conditional consistency model for map prediction in irregularly shaped unknown regions, 2) a contrastive map-trajectory pretraining framework for a trajectory encoder that extracts spatial information from the trajectories of nearby robots during map prediction, and 3) a confidence network to measure the uncertainty of map prediction for effective exploration under resource constraints. We incorporate 4CNet within our proposed robot exploration with map prediction architecture, 4CNet-E. We then conduct extensive comparison studies with 4CNet-E and state-of-the-art heuristic and learning methods to investigate both map prediction and exploration performance in environments consisting of uneven terrain and irregularly shaped obstacles. Results showed that 4CNet-E obtained statistically significant higher prediction accuracy and area coverage with varying environment sizes, number of robots, energy budgets, and communication limitations. Real-world mobile robot experiments were performed and validated the feasibility and generalizability of 4CNet-E for mobile robot map prediction and exploration.
PreRoutGNN for Timing Prediction with Order Preserving Partition: Global Circuit Pre-training, Local Delay Learning and Attentional Cell Modeling
Feb 27, 2024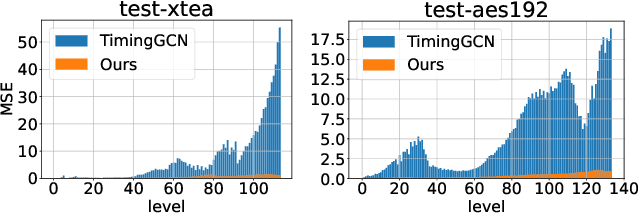
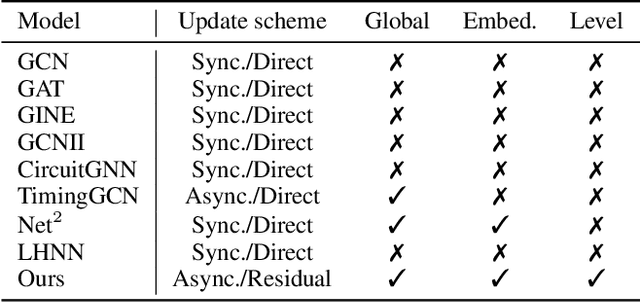

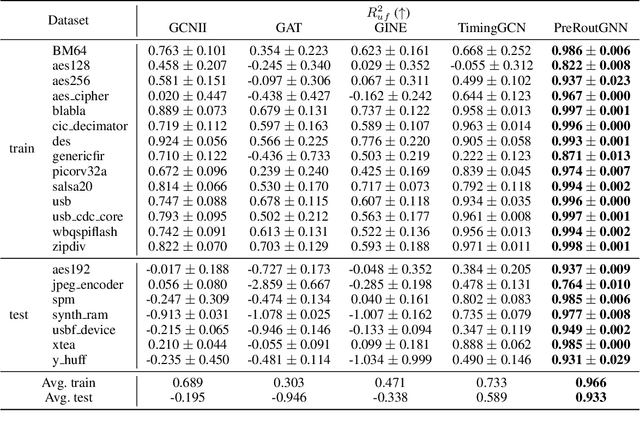
Pre-routing timing prediction has been recently studied for evaluating the quality of a candidate cell placement in chip design. It involves directly estimating the timing metrics for both pin-level (slack, slew) and edge-level (net delay, cell delay), without time-consuming routing. However, it often suffers from signal decay and error accumulation due to the long timing paths in large-scale industrial circuits. To address these challenges, we propose a two-stage approach. First, we propose global circuit training to pre-train a graph auto-encoder that learns the global graph embedding from circuit netlist. Second, we use a novel node updating scheme for message passing on GCN, following the topological sorting sequence of the learned graph embedding and circuit graph. This scheme residually models the local time delay between two adjacent pins in the updating sequence, and extracts the lookup table information inside each cell via a new attention mechanism. To handle large-scale circuits efficiently, we introduce an order preserving partition scheme that reduces memory consumption while maintaining the topological dependencies. Experiments on 21 real world circuits achieve a new SOTA R2 of 0.93 for slack prediction, which is significantly surpasses 0.59 by previous SOTA method. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI.
MemoryPrompt: A Light Wrapper to Improve Context Tracking in Pre-trained Language Models
Feb 23, 2024Transformer-based language models (LMs) track contextual information through large, hard-coded input windows. We introduce MemoryPrompt, a leaner approach in which the LM is complemented by a small auxiliary recurrent network that passes information to the LM by prefixing its regular input with a sequence of vectors, akin to soft prompts, without requiring LM finetuning. Tested on a task designed to probe a LM's ability to keep track of multiple fact updates, a MemoryPrompt-augmented LM outperforms much larger LMs that have access to the full input history. We also test MemoryPrompt on a long-distance dialogue dataset, where its performance is comparable to that of a model conditioned on the entire conversation history. In both experiments we also observe that, unlike full-finetuning approaches, MemoryPrompt does not suffer from catastrophic forgetting when adapted to new tasks, thus not disrupting the generalist capabilities of the underlying LM.
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering
Feb 26, 2024Advances towards more faithful and traceable answers of Large Language Models (LLMs) are crucial for various research and practical endeavors. One avenue in reaching this goal is basing the answers on reliable sources. However, this Evidence-Based QA has proven to work insufficiently with LLMs in terms of citing the correct sources (source quality) and truthfully representing the information within sources (answer attributability). In this work, we systematically investigate how to robustly fine-tune LLMs for better source quality and answer attributability. Specifically, we introduce a data generation pipeline with automated data quality filters, which can synthesize diversified high-quality training and testing data at scale. We further introduce four test sets to benchmark the robustness of fine-tuned specialist models. Extensive evaluation shows that fine-tuning on synthetic data improves performance on both in- and out-of-distribution. Furthermore, we show that data quality, which can be drastically improved by proposed quality filters, matters more than quantity in improving Evidence-Based QA.