 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-Driven Adaptive Sensing Based on Deep Reinforcement Learning
Oct 08, 2020
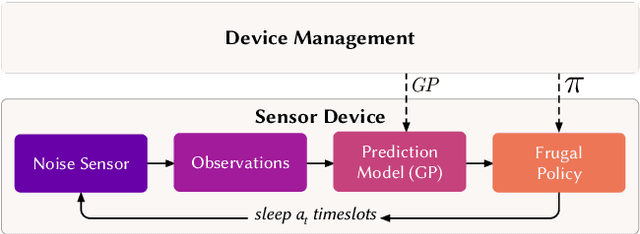
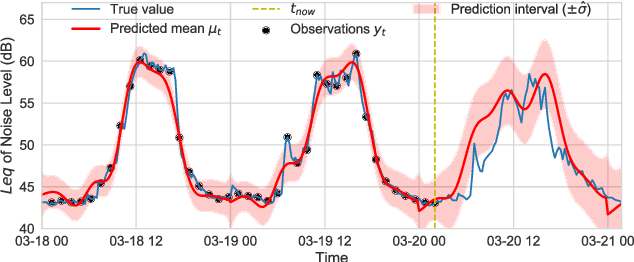
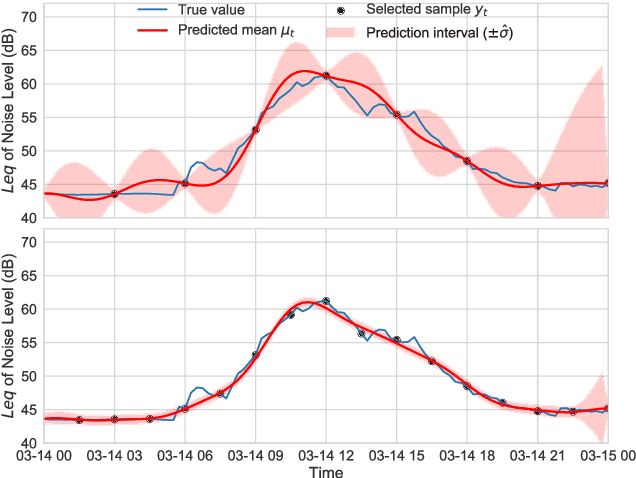
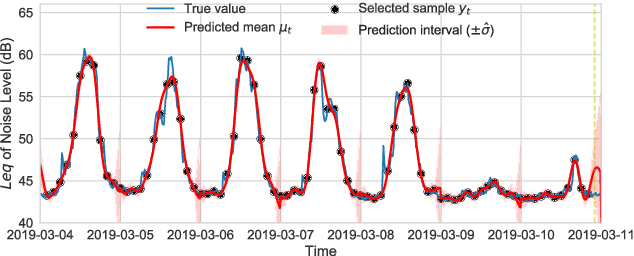
In order to make better use of deep reinforcement learning in the creation of sensing policies for resource-constrained IoT devices, we present and study a novel reward function based on the Fisher information value. This reward function enables IoT sensor devices to learn to spend available energy on measurements at otherwise unpredictable moments, while conserving energy at times when measurements would provide little new information. This is a highly general approach, which allows for a wide range of use cases without significant human design effort or hyper-parameter tuning. We illustrate the approach in a scenario of workplace noise monitoring, where results show that the learned behavior outperforms a uniform sampling strategy and comes close to a near-optimal oracle solution.
* 8 pages, 8 figures
Personalize Web Searching Strategies Classification and Comparison
Mar 25, 2022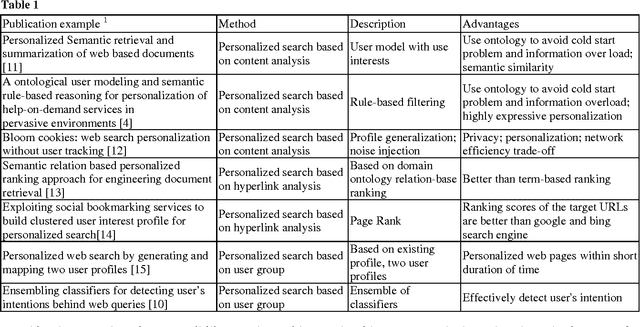
Personalization is becoming very important direction in semantic web search for the users that needs to find appropriate information. In this paper, a classification of web personalization is proposed and semantic web search tools are investigated. Building user interest profile is essential for personalizing. Nowadays, semantic web tools use ontologies for personalization because of their advantages. It is important to mention that most of the semantic web search tools use agent technologies for implementation.
* 5 pages
Towards Bundle Adjustment for Satellite Imaging via Quantum Machine Learning
Apr 23, 2022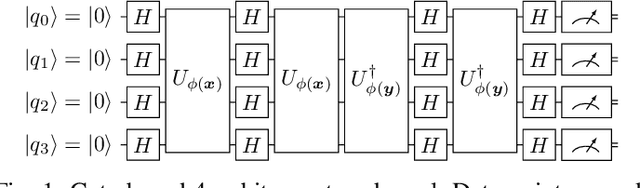
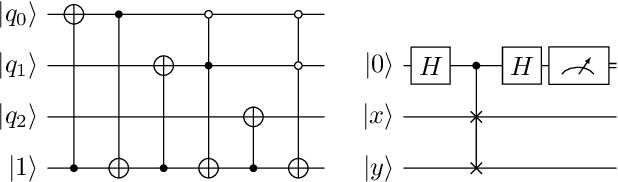


Given is a set of images, where all images show views of the same area at different points in time and from different viewpoints. The task is the alignment of all images such that relevant information, e.g., poses, changes, and terrain, can be extracted from the fused image. In this work, we focus on quantum methods for keypoint extraction and feature matching, due to the demanding computational complexity of these sub-tasks. To this end, k-medoids clustering, kernel density clustering, nearest neighbor search, and kernel methods are investigated and it is explained how these methods can be re-formulated for quantum annealers and gate-based quantum computers. Experimental results obtained on digital quantum emulation hardware, quantum annealers, and quantum gate computers show that classical systems still deliver superior results. However, the proposed methods are ready for the current and upcoming generations of quantum computing devices which have the potential to outperform classical systems in the near future.
Obfuscation via Information Density Estimation
Oct 17, 2019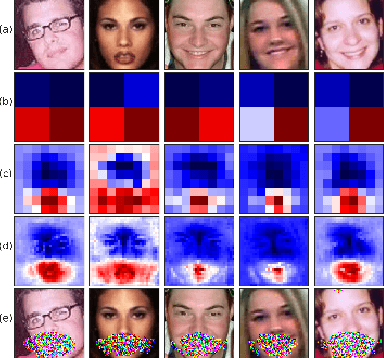
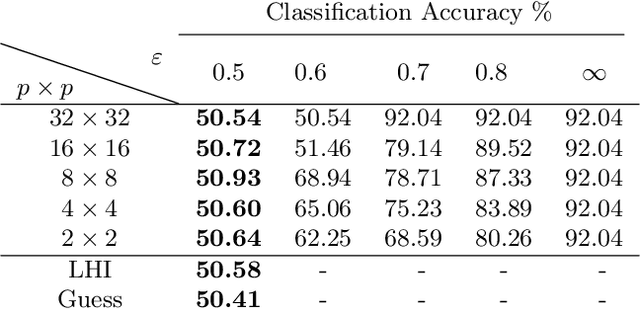
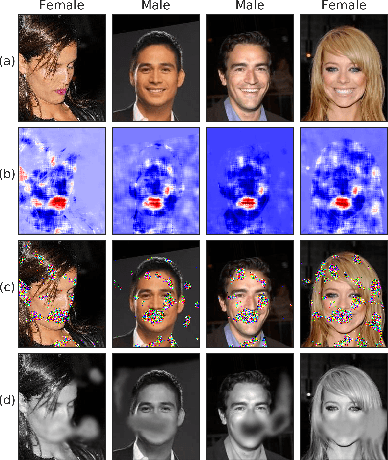
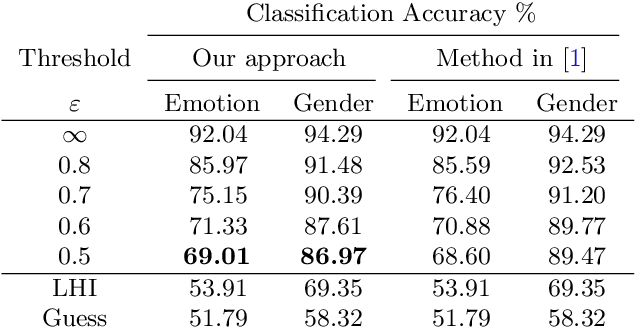
Identifying features that leak information about sensitive attributes is a key challenge in the design of information obfuscation mechanisms. In this paper, we propose a framework to identify information-leaking features via information density estimation. Here, features whose information densities exceed a pre-defined threshold are deemed information-leaking features. Once these features are identified, we sequentially pass them through a targeted obfuscation mechanism with a provable leakage guarantee in terms of $\mathsf{E}_\gamma$-divergence. The core of this mechanism relies on a data-driven estimate of the trimmed information density for which we propose a novel estimator, named the trimmed information density estimator (TIDE). We then use TIDE to implement our mechanism on three real-world datasets. Our approach can be used as a data-driven pipeline for designing obfuscation mechanisms targeting specific features.
Augmenting Neural Networks with Priors on Function Values
Feb 21, 2022



The need for function estimation in label-limited settings is common in the natural sciences. At the same time, prior knowledge of function values is often available in these domains. For example, data-free biophysics-based models can be informative on protein properties, while quantum-based computations can be informative on small molecule properties. How can we coherently leverage such prior knowledge to help improve a neural network model that is quite accurate in some regions of input space -- typically near the training data -- but wildly wrong in other regions? Bayesian neural networks (BNN) enable the user to specify prior information only on the neural network weights, not directly on the function values. Moreover, there is in general no clear mapping between these. Herein, we tackle this problem by developing an approach to augment BNNs with prior information on the function values themselves. Our probabilistic approach yields predictions that rely more heavily on the prior information when the epistemic uncertainty is large, and more heavily on the neural network when the epistemic uncertainty is small.
Restoring Vision through Retinal Implants -- A Systematic Literature Review
Apr 04, 2022
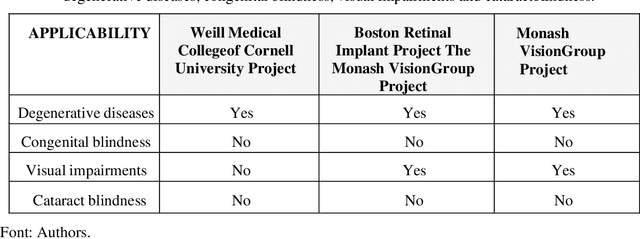
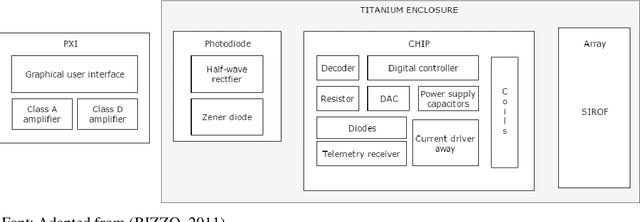
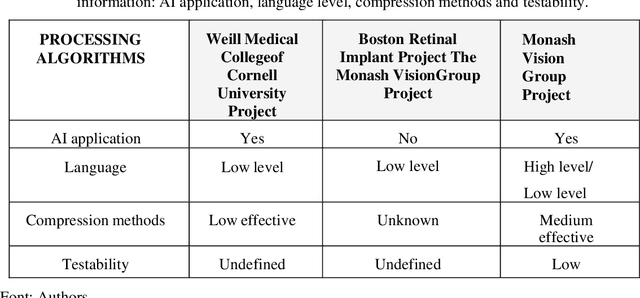
This work presents a bunched of promising technologies to treat blind people: the bionic eyes. The strategy is to combine a retina implant with software capable to interpret the information received. Along this line of thinking, projects such as Retinal Prosthetic Strategy with the Capacity to Restore Normal Vision from Weill Medical College of Cornell University Project, Update on Retinal Prosthetic Research from The Boston Retinal Implant Project, and Restoration of Vision Using Wireless Cortical Implants from Monash Vision Group Project, have shown in a different context the use of technologies that commits to bring the vision through its use.
Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction
May 20, 2022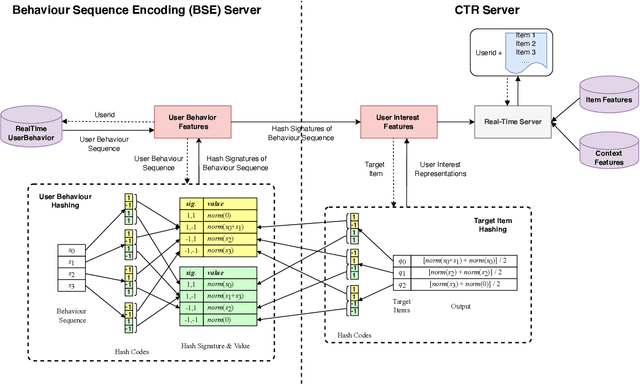

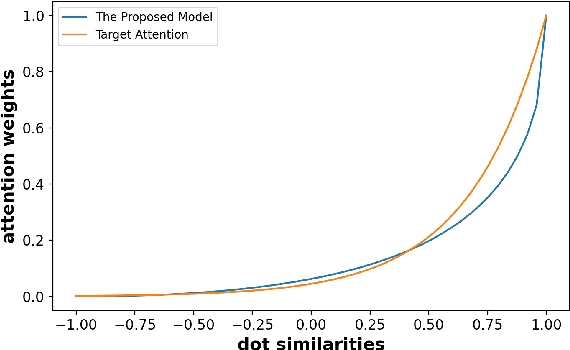
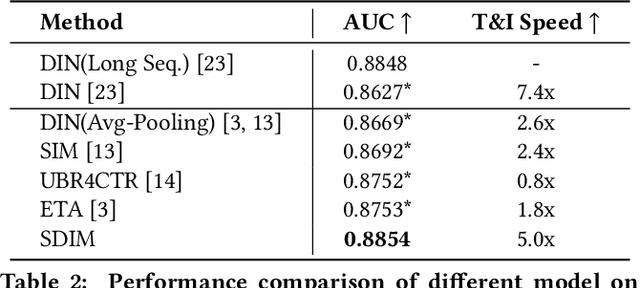
Rich user behavior data has been proven to be of great value for Click-Through Rate (CTR) prediction applications, especially in industrial recommender, search, or advertising systems. However, it's non-trivial for real-world systems to make full use of long-term user behaviors due to the strict requirements of online serving time. Most previous works adopt the retrieval-based strategy, where a small number of user behaviors are retrieved first for subsequent attention. However, the retrieval-based methods are sub-optimal and would cause more or less information losses, and it's difficult to balance the effectiveness and efficiency of the retrieval algorithm. In this paper, we propose \textbf{SDIM} (\textbf{S}ampling-based \textbf{D}eep \textbf{I}nterest \textbf{M}odeling), a simple yet effective sampling-based end-to-end approach for modeling long-term user behaviors. We sample from multiple hash functions to generate hash signatures of the candidate item and each item in the user behavior sequence, and obtain the user interest by directly gathering behavior items associated with the candidate item with the same hash signature. We show theoretically and experimentally that the proposed method performs on par with standard attention-based models on modeling long-term user behaviors, while being sizable times faster. We also introduce the deployment of SDIM in our system. Specifically, we decouple the behavior sequence hashing, which is the most time-consuming part, from the CTR model by designing a separate module named BSE (behavior Sequence Encoding). BSE is latency-free for the CTR server, enabling us to model extremely long user behaviors. Both offline and online experiments are conducted to demonstrate the effectiveness of SDIM. SDIM now has been deployed online in the search system of Meituan APP.
Beyond Visual Image: Automated Diagnosis of Pigmented Skin Lesions Combining Clinical Image Features with Patient Data
Jan 25, 2022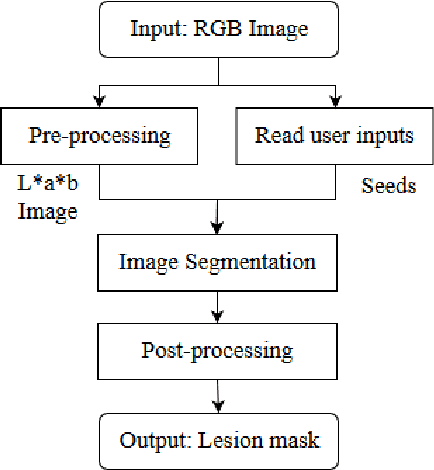

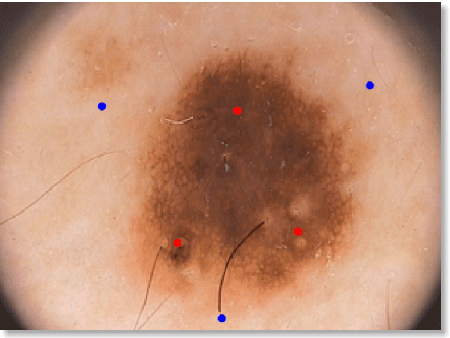

kin cancer is considered one of the most common type of cancer in several countries. Due to the difficulty and subjectivity in the clinical diagnosis of skin lesions, Computer-Aided Diagnosis systems are being developed for assist experts to perform more reliable diagnosis. The clinical analysis and diagnosis of skin lesions relies not only on the visual information but also on the context information provided by the patient. This work addresses the problem of pigmented skin lesions detection from smartphones captured images. In addition to the features extracted from images, patient context information was collected to provide a more accurate diagnosis. The experiments showed that the combination of visual features with context information improved final results. Experimental results are very promising and comparable to experts.
What Do Adversarially trained Neural Networks Focus: A Fourier Domain-based Study
Mar 16, 2022
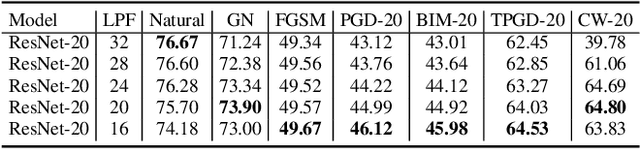
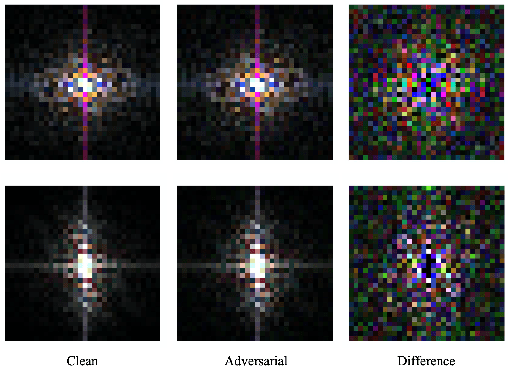
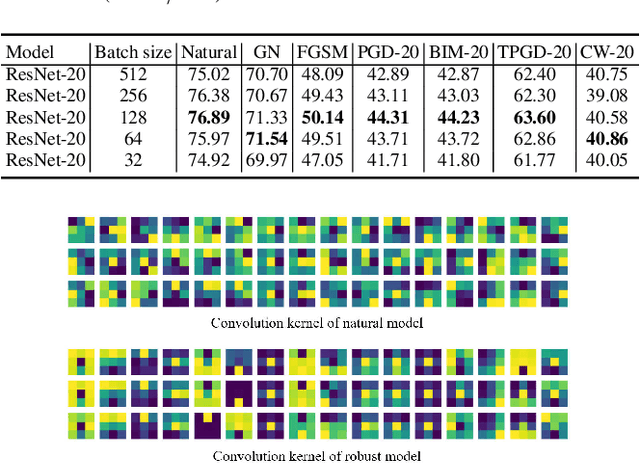
Although many fields have witnessed the superior performance brought about by deep learning, the robustness of neural networks remains an open issue. Specifically, a small adversarial perturbation on the input may cause the model to produce a completely different output. Such poor robustness implies many potential hazards, especially in security-critical applications, e.g., autonomous driving and mobile robotics. This work studies what information the adversarially trained model focuses on. Empirically, we notice that the differences between the clean and adversarial data are mainly distributed in the low-frequency region. We then find that an adversarially-trained model is more robust than its naturally-trained counterpart due to the reason that the former pays more attention to learning the dominant information in low-frequency components. In addition, we consider two common ways to improve model robustness, namely, by data augmentation and by using stronger network architectures, and understand these techniques from a frequency-domain perspective. We are hopeful this work can shed light on the design of more robust neural networks.
Infographics Wizard: Flexible Infographics Authoring and Design Exploration
Apr 21, 2022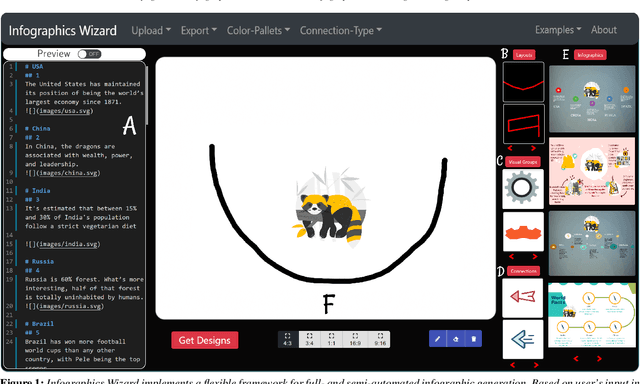
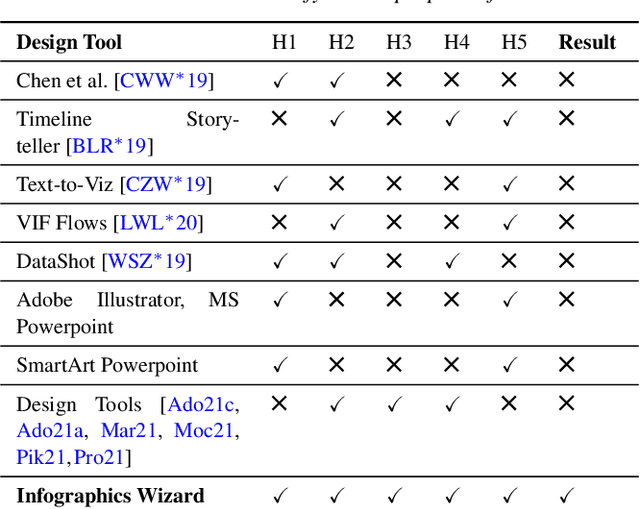
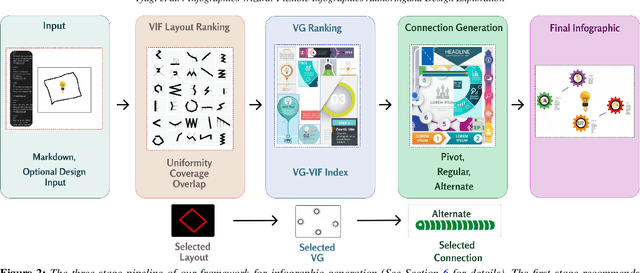
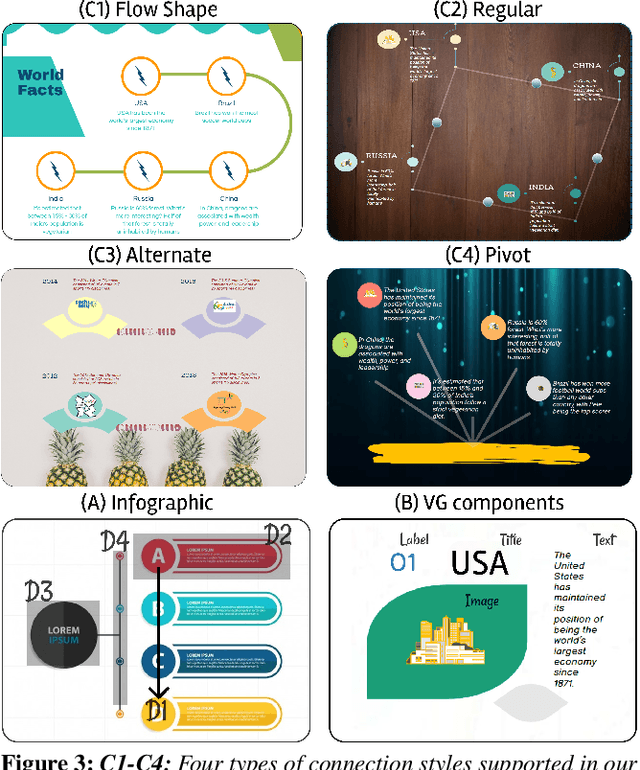
Infographics are an aesthetic visual representation of information following specific design principles of human perception. Designing infographics can be a tedious process for non-experts and time-consuming, even for professional designers. With the help of designers, we propose a semi-automated infographic framework for general structured and flow-based infographic design generation. For novice designers, our framework automatically creates and ranks infographic designs for a user-provided text with no requirement for design input. However, expert designers can still provide custom design inputs to customize the infographics. We will also contribute an individual visual group (VG) designs dataset (in SVG), along with a 1k complete infographic image dataset with segmented VGs in this work. Evaluation results confirm that by using our framework, designers from all expertise levels can generate generic infographic designs faster than existing methods while maintaining the same quality as hand-designed infographics templates.