 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Learning of Salient Object Detection, Depth Estimation and Contour Extraction
Mar 09, 2022




Benefiting from color independence, illumination invariance and location discrimination attributed by the depth map, it can provide important supplemental information for extracting salient objects in complex environments. However, high-quality depth sensors are expensive and can not be widely applied. While general depth sensors produce the noisy and sparse depth information, which brings the depth-based networks with irreversible interference. In this paper, we propose a novel multi-task and multi-modal filtered transformer (MMFT) network for RGB-D salient object detection (SOD). Specifically, we unify three complementary tasks: depth estimation, salient object detection and contour estimation. The multi-task mechanism promotes the model to learn the task-aware features from the auxiliary tasks. In this way, the depth information can be completed and purified. Moreover, we introduce a multi-modal filtered transformer (MFT) module, which equips with three modality-specific filters to generate the transformer-enhanced feature for each modality. The proposed model works in a depth-free style during the testing phase. Experiments show that it not only significantly surpasses the depth-based RGB-D SOD methods on multiple datasets, but also precisely predicts a high-quality depth map and salient contour at the same time. And, the resulted depth map can help existing RGB-D SOD methods obtain significant performance gain.
A Highly Adaptive Acoustic Model for Accurate Multi-Dialect Speech Recognition
May 06, 2022
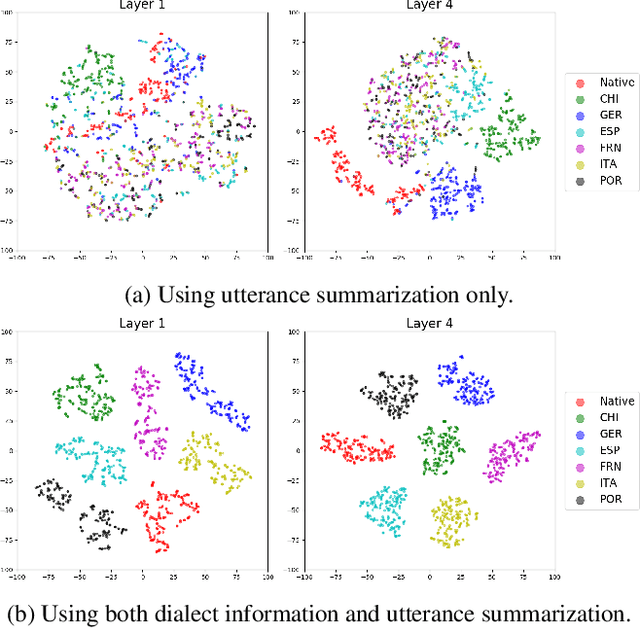
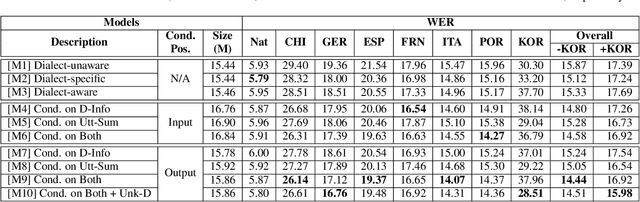
Despite the success of deep learning in speech recognition, multi-dialect speech recognition remains a difficult problem. Although dialect-specific acoustic models are known to perform well in general, they are not easy to maintain when dialect-specific data is scarce and the number of dialects for each language is large. Therefore, a single unified acoustic model (AM) that generalizes well for many dialects has been in demand. In this paper, we propose a novel acoustic modeling technique for accurate multi-dialect speech recognition with a single AM. Our proposed AM is dynamically adapted based on both dialect information and its internal representation, which results in a highly adaptive AM for handling multiple dialects simultaneously. We also propose a simple but effective training method to deal with unseen dialects. The experimental results on large scale speech datasets show that the proposed AM outperforms all the previous ones, reducing word error rates (WERs) by 8.11% relative compared to a single all-dialects AM and by 7.31% relative compared to dialect-specific AMs.
DACSR: Dual-Aggregation End-to-End Calibrated Sequential Recommendation
Apr 29, 2022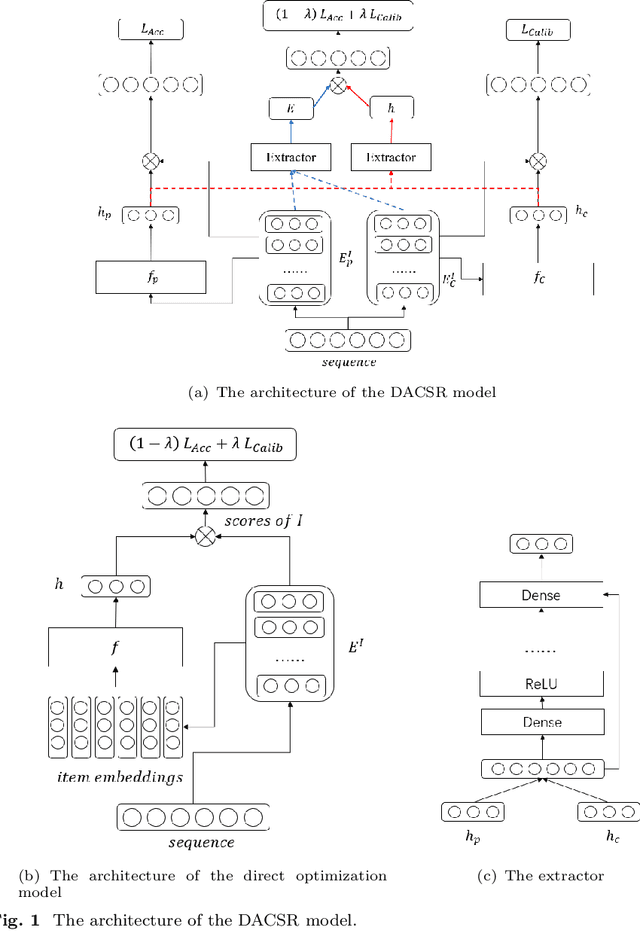
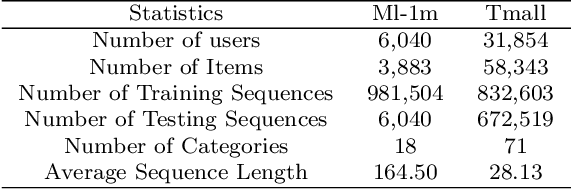
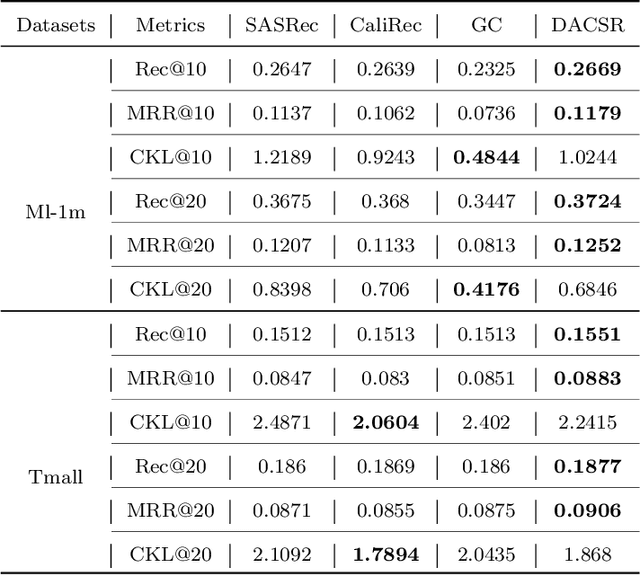
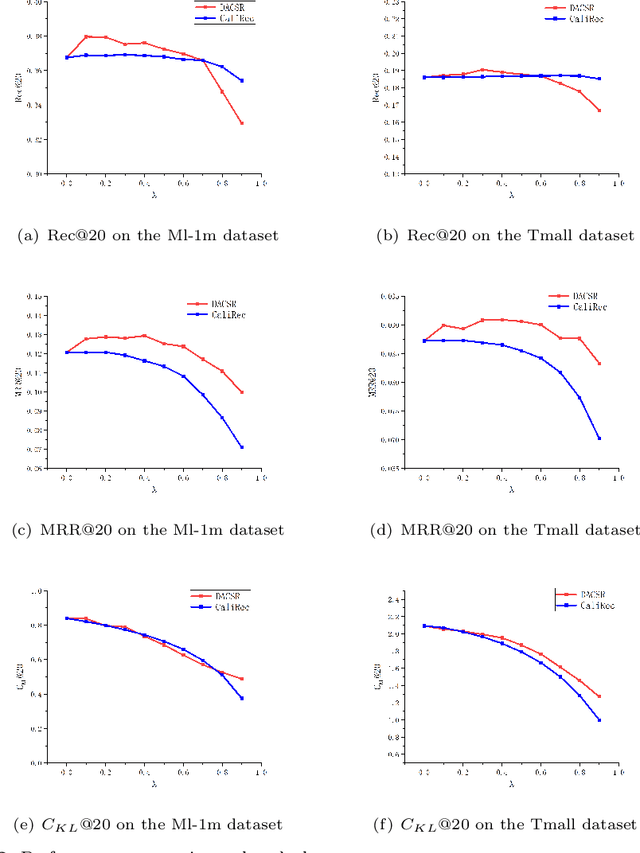
Recent years have witnessed the progress of sequential recommendation in accurately predicting users' future behaviors. However, only persuading accuracy leads to the risk of filter bubbles where recommenders only focus on users' main interest areas. Different from other studies which improve diversity or coverage, we investigate the calibration in sequential recommendation. However, existing calibrated methods followed a post-processing paradigm, which costs more computation time and sacrifices the recommendation accuracy. To this end, we propose an end-to-end framework to provide both accurate and calibrated recommendations. We propose a loss function to measure the divergence of distributions between recommendation lists and historical behaviors for sequential recommendation framework. In addition, we design a dual-aggregation model which extracts information from two individual sequence encoders with different objectives to further improve the recommendation. Experiments on two benchmark datasets demonstrate the effectiveness and efficiency of our model.
Gransformer: Transformer-based Graph Generation
Mar 25, 2022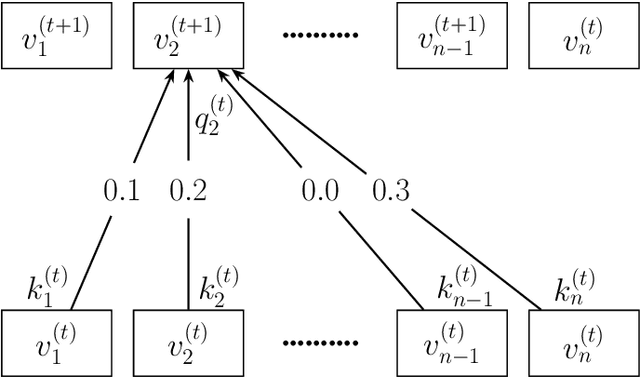
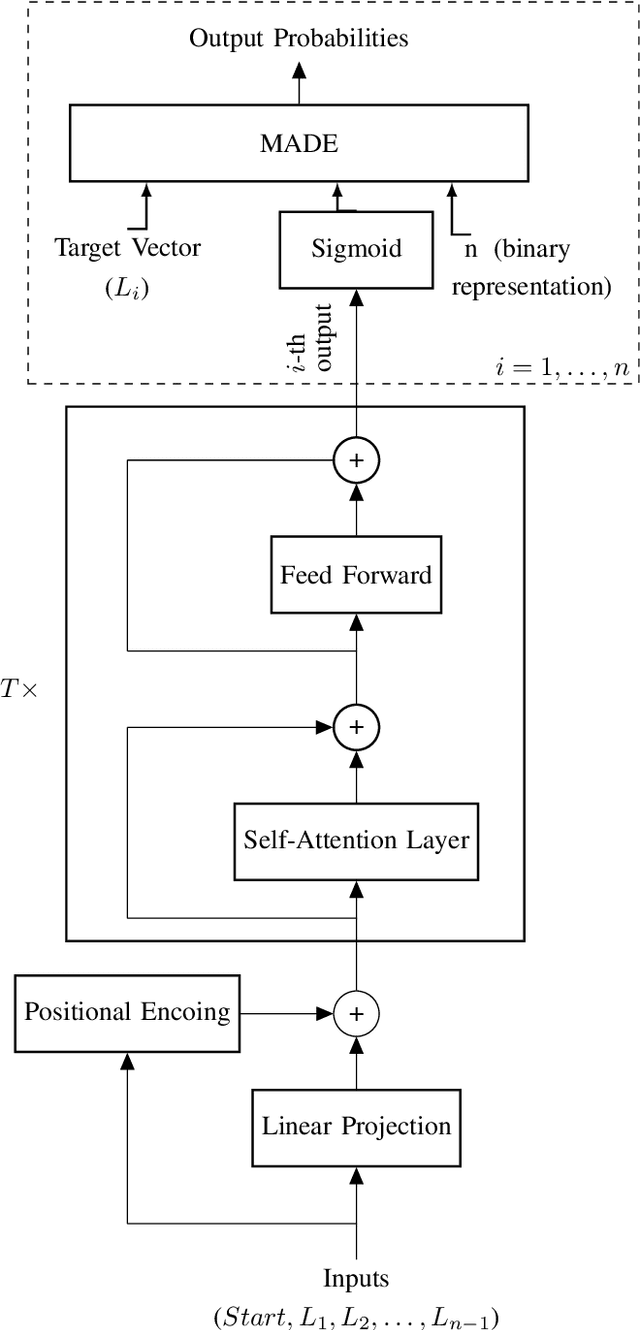
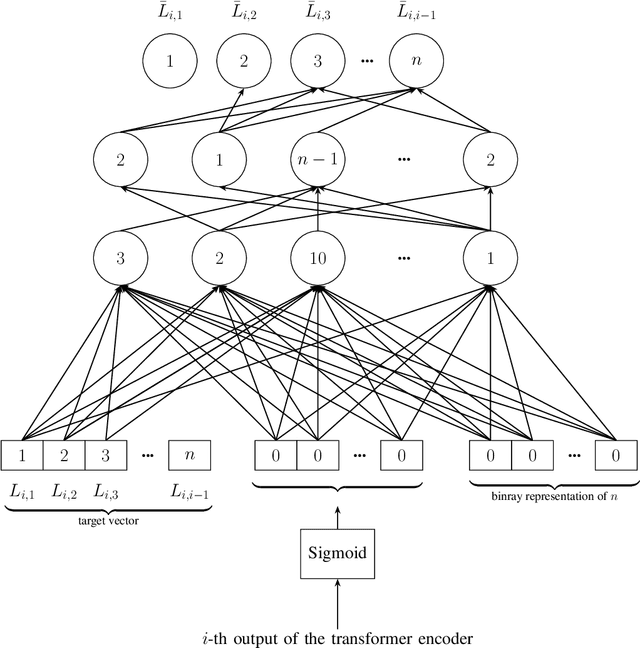

Transformers have become widely used in modern models for various tasks such as natural language processing and machine vision. This paper, proposes Gransformer, an algorithm for generating graphs that takes advantage of the transformer. We extend a simple autoregressive transformer encoder to exploit the structural information of the graph through efficient modifications. The attention mechanism is modified to consider the presence or absence of edges between each pair of nodes. We also introduce a graph-based familiarity measure that applies to both the attention and the positional coding. This autoregressive criterion, inspired by message passing algorithms, contains structural information about the graph. In the output layer, we also use a masked autoencoder for density estimation to efficiently model the generation of dependent edges. We also propose a technique to prevent the model from generating isolated nodes. We evaluate this method on two real-world datasets and compare it with some state-of-the-art autoregressive graph generation methods. Experimental results have shown that the proposed method performs comparative to these methods, including recurrent models and graph convolutional networks.
$G^2$: Enhance Knowledge Grounded Dialogue via Ground Graph
Apr 27, 2022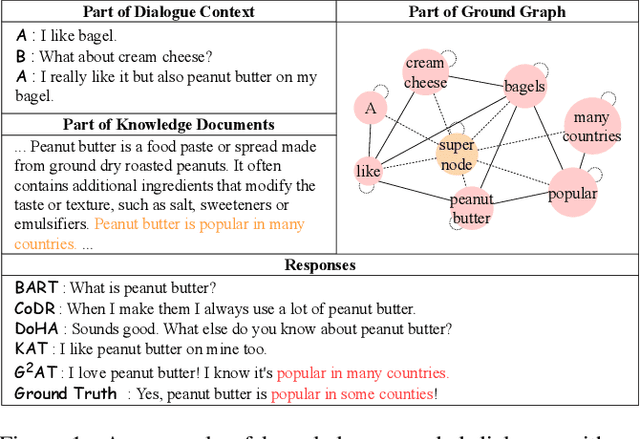
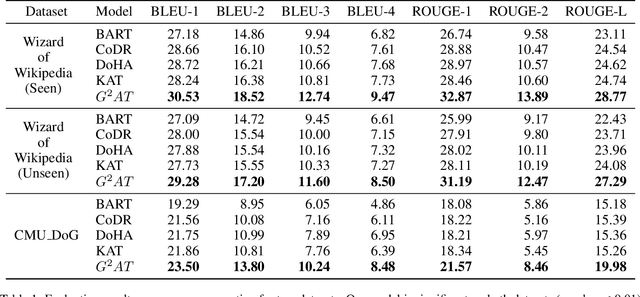
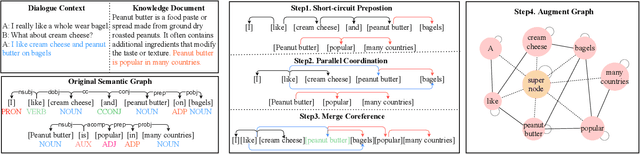
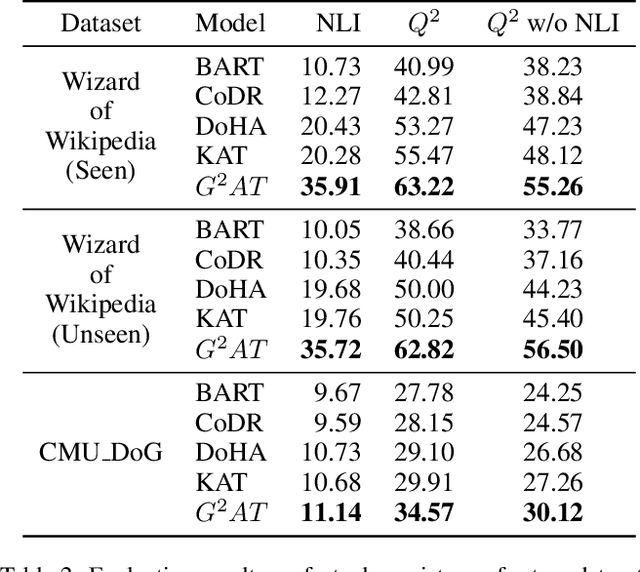
Knowledge grounded dialogue system is designed to generate responses that convey information from given knowledge documents. However, it's a challenge for the current Seq2Seq model to acquire knowledge from complex documents and integrate it to perform correct responses without the aid of an explicit semantic structure. To address these issues, we present a novel graph structure, Ground Graph ($G^2$), which models the semantic structure of both dialogue contexts and knowledge documents to facilitate knowledge selection and integration for the task. Besides, a Ground Graph Aware Transformer ($G^2AT$) is proposed to enhance knowledge grounded response generation. Empirical results show that our proposed model outperforms previous state-of-the-art methods with more than 10\% and 20\% gains on response generation and factual consistency. Furthermore, our structure-aware approach shows excellent generalization ability in resource-limited situations.
Actively Tracking the Optimal Arm in Non-Stationary Environments with Mandatory Probing
May 20, 2022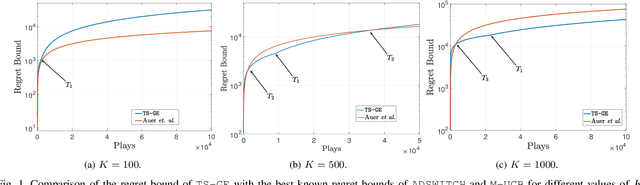
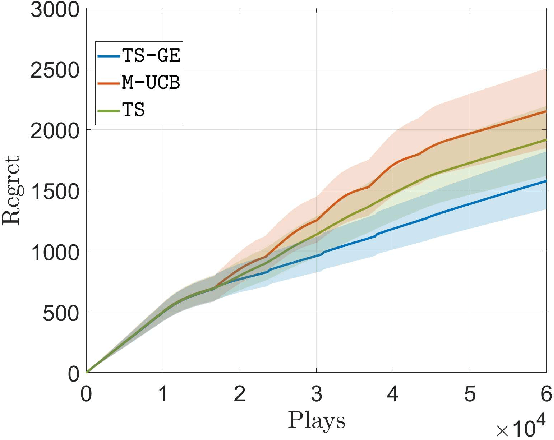
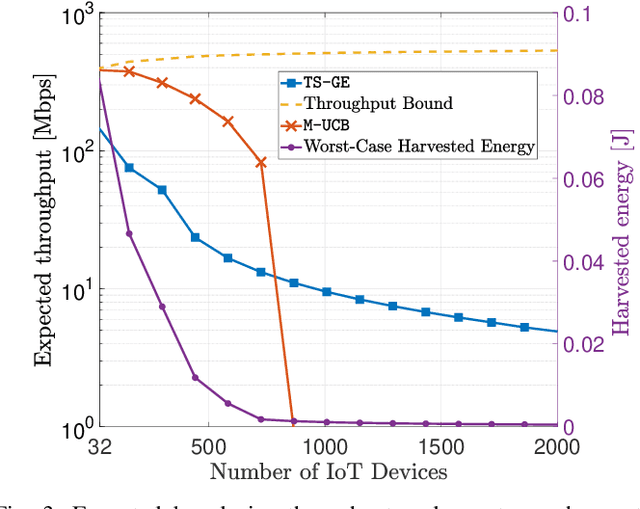
We study a novel multi-armed bandit (MAB) setting which mandates the agent to probe all the arms periodically in a non-stationary environment. In particular, we develop \texttt{TS-GE} that balances the regret guarantees of classical Thompson sampling (TS) with the broadcast probing (BP) of all the arms simultaneously in order to actively detect a change in the reward distributions. Once a system-level change is detected, the changed arm is identified by an optional subroutine called group exploration (GE) which scales as $\log_2(K)$ for a $K-$armed bandit setting. We characterize the probability of missed detection and the probability of false-alarm in terms of the environment parameters. The latency of change-detection is upper bounded by $\sqrt{T}$ while within a period of $\sqrt{T}$, all the arms are probed at least once. We highlight the conditions in which the regret guarantee of \texttt{TS-GE} outperforms that of the state-of-the-art algorithms, in particular, \texttt{ADSWITCH} and \texttt{M-UCB}. Furthermore, unlike the existing bandit algorithms, \texttt{TS-GE} can be deployed for applications such as timely status updates, critical control, and wireless energy transfer, which are essential features of next-generation wireless communication networks. We demonstrate the efficacy of \texttt{TS-GE} by employing it in a n industrial internet-of-things (IIoT) network designed for simultaneous wireless information and power transfer (SWIPT).
A Comprehensive Survey of Few-shot Learning: Evolution, Applications, Challenges, and Opportunities
May 13, 2022
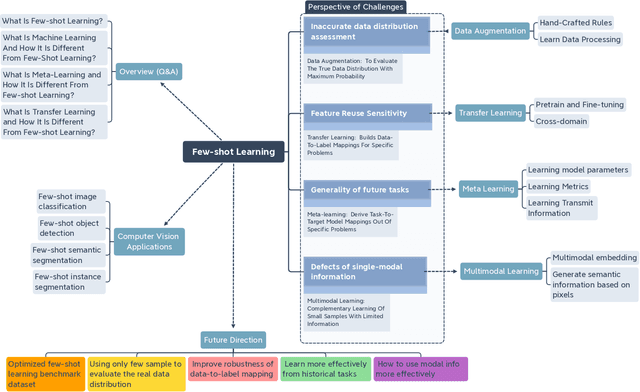
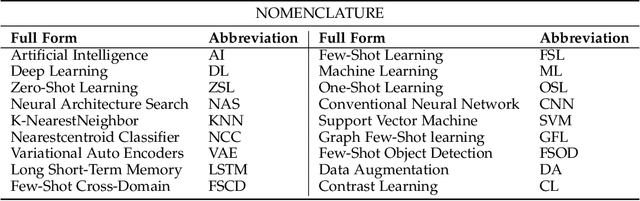
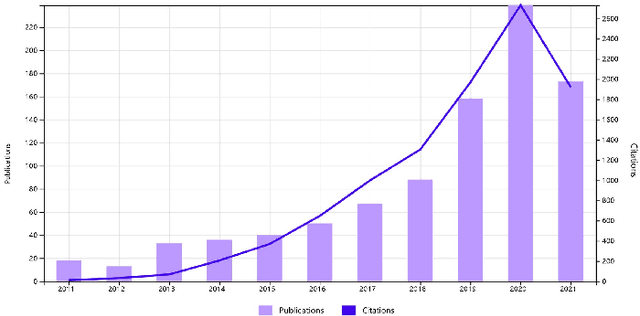
Few-shot learning (FSL) has emerged as an effective learning method and shows great potential. Despite the recent creative works in tackling FSL tasks, learning valid information rapidly from just a few or even zero samples still remains a serious challenge. In this context, we extensively investigated 200+ latest papers on FSL published in the past three years, aiming to present a timely and comprehensive overview of the most recent advances in FSL along with impartial comparisons of the strengths and weaknesses of the existing works. For the sake of avoiding conceptual confusion, we first elaborate and compare a set of similar concepts including few-shot learning, transfer learning, and meta-learning. Furthermore, we propose a novel taxonomy to classify the existing work according to the level of abstraction of knowledge in accordance with the challenges of FSL. To enrich this survey, in each subsection we provide in-depth analysis and insightful discussion about recent advances on these topics. Moreover, taking computer vision as an example, we highlight the important application of FSL, covering various research hotspots. Finally, we conclude the survey with unique insights into the technology evolution trends together with potential future research opportunities in the hope of providing guidance to follow-up research.
A Vision Inspired Neural Network for Unsupervised Anomaly Detection in Unordered Data
May 13, 2022
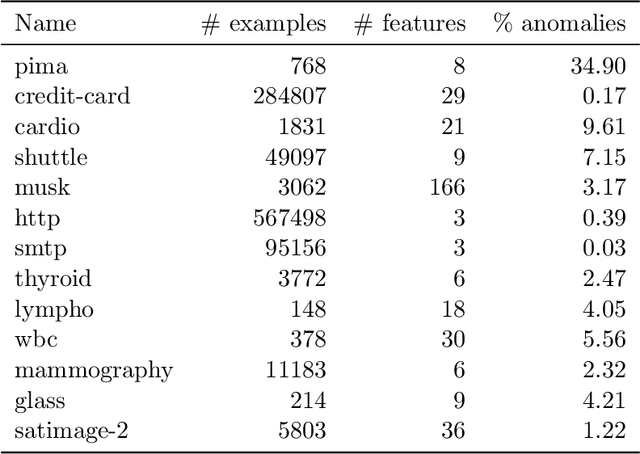
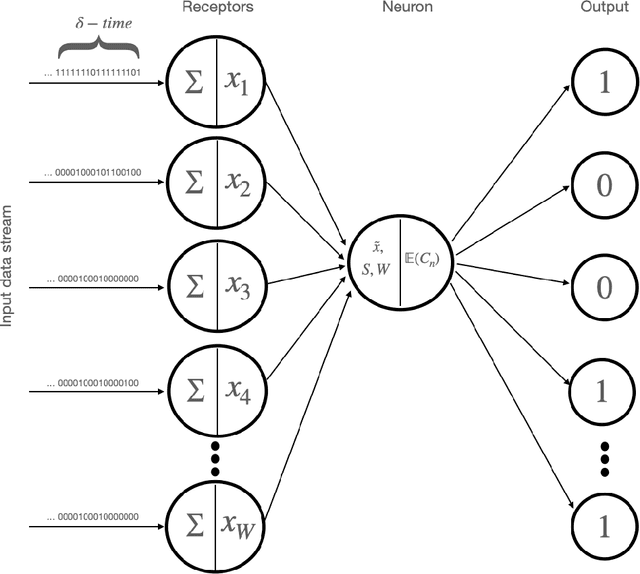
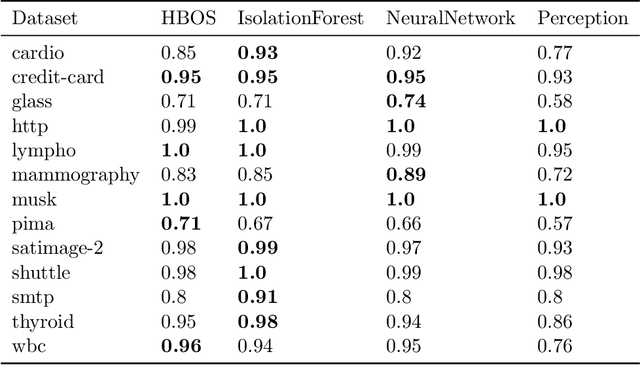
A fundamental problem in the field of unsupervised machine learning is the detection of anomalies corresponding to rare and unusual observations of interest; reasons include for their rejection, accommodation or further investigation. Anomalies are intuitively understood to be something unusual or inconsistent, whose occurrence sparks immediate attention. More formally anomalies are those observations-under appropriate random variable modelling-whose expectation of occurrence with respect to a grouping of prior interest is less than one; such a definition and understanding has been used to develop the parameter-free perception anomaly detection algorithm. The present work seeks to establish important and practical connections between the approach used by the perception algorithm and prior decades of research in neurophysiology and computational neuroscience; particularly that of information processing in the retina and visual cortex. The algorithm is conceptualised as a neuron model which forms the kernel of an unsupervised neural network that learns to signal unexpected observations as anomalies. Both the network and neuron display properties observed in biological processes including: immediate intelligence; parallel processing; redundancy; global degradation; contrast invariance; parameter-free computation, dynamic thresholds and non-linear processing. A robust and accurate model for anomaly detection in univariate and multivariate data is built using this network as a concrete application.
Analysis of OODA Loop based on Adversarial for Complex Game Environments
Mar 25, 2022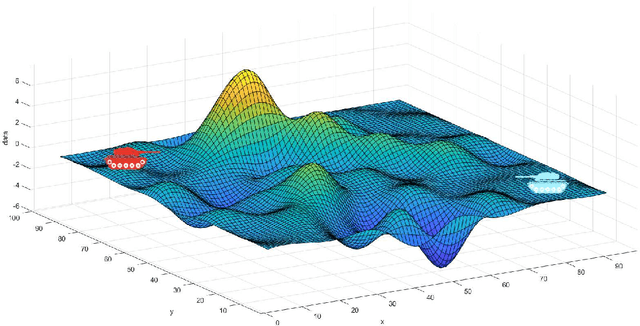
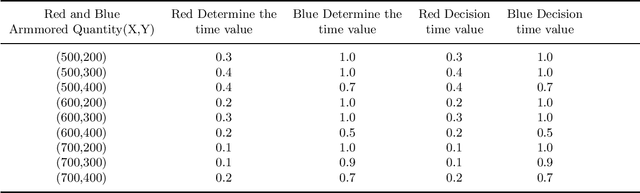
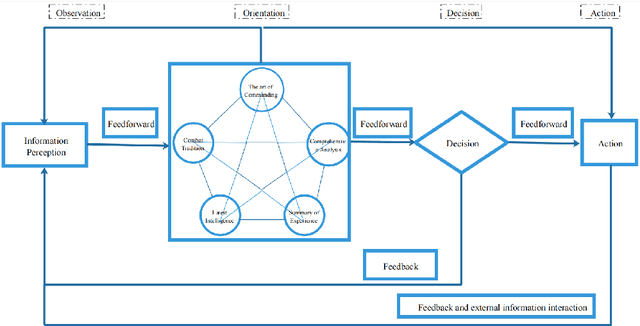
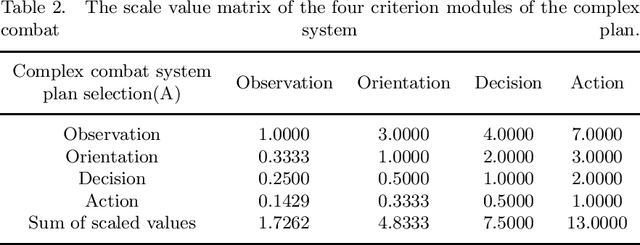
To address the problem of imperfect confrontation strategy caused by the lack of information of game environment in the simulation of non-complete information dynamic countermeasure modeling for intelligent game, the hierarchical analysis game strategy of confrontation model based on OODA ring (Observation, Orientation, Decision, Action) theory is proposed. At the same time, taking into account the trend of unmanned future warfare, NetLogo software simulation is used to construct a dynamic derivation of the confrontation between two tanks. In the validation process, the OODA loop theory is used to describe the operation process of the complex system between red and blue sides, and the four-step cycle of observation, judgment, decision and execution is carried out according to the number of armor of both sides, and then the OODA loop system adjusts the judgment and decision time coefficients for the next confrontation cycle according to the results of the first cycle. Compared with traditional simulation methods that consider objective factors such as loss rate and support rate, the OODA-loop-based hierarchical game analysis can analyze the confrontation situation more comprehensively.
End-to-end model for named entity recognition from speech without paired training data
Apr 02, 2022


Recent works showed that end-to-end neural approaches tend to become very popular for spoken language understanding (SLU). Through the term end-to-end, one considers the use of a single model optimized to extract semantic information directly from the speech signal. A major issue for such models is the lack of paired audio and textual data with semantic annotation. In this paper, we propose an approach to build an end-to-end neural model to extract semantic information in a scenario in which zero paired audio data is available. Our approach is based on the use of an external model trained to generate a sequence of vectorial representations from text. These representations mimic the hidden representations that could be generated inside an end-to-end automatic speech recognition (ASR) model by processing a speech signal. An SLU neural module is then trained using these representations as input and the annotated text as output. Last, the SLU module replaces the top layers of the ASR model to achieve the construction of the end-to-end model. Our experiments on named entity recognition, carried out on the QUAERO corpus, show that this approach is very promising, getting better results than a comparable cascade approach or than the use of synthetic voices.