 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Implicit Motion-Compensated Network for Unsupervised Video Object Segmentation
Apr 06, 2022
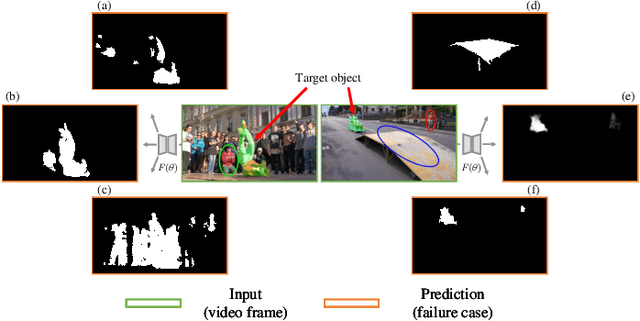



Unsupervised video object segmentation (UVOS) aims at automatically separating the primary foreground object(s) from the background in a video sequence. Existing UVOS methods either lack robustness when there are visually similar surroundings (appearance-based) or suffer from deterioration in the quality of their predictions because of dynamic background and inaccurate flow (flow-based). To overcome the limitations, we propose an implicit motion-compensated network (IMCNet) combining complementary cues ($\textit{i.e.}$, appearance and motion) with aligned motion information from the adjacent frames to the current frame at the feature level without estimating optical flows. The proposed IMCNet consists of an affinity computing module (ACM), an attention propagation module (APM), and a motion compensation module (MCM). The light-weight ACM extracts commonality between neighboring input frames based on appearance features. The APM then transmits global correlation in a top-down manner. Through coarse-to-fine iterative inspiring, the APM will refine object regions from multiple resolutions so as to efficiently avoid losing details. Finally, the MCM aligns motion information from temporally adjacent frames to the current frame which achieves implicit motion compensation at the feature level. We perform extensive experiments on $\textit{DAVIS}_{\textit{16}}$ and $\textit{YouTube-Objects}$. Our network achieves favorable performance while running at a faster speed compared to the state-of-the-art methods.
Layer-wise Model Pruning based on Mutual Information
Aug 28, 2021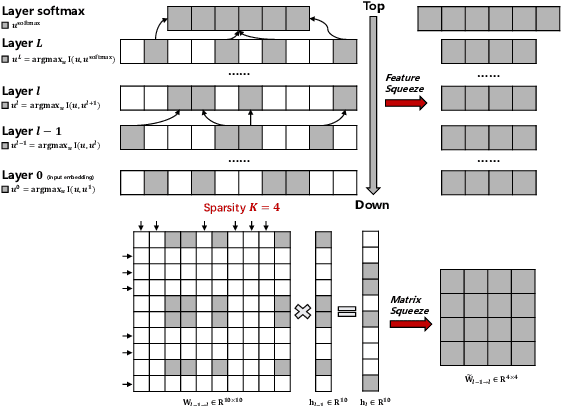
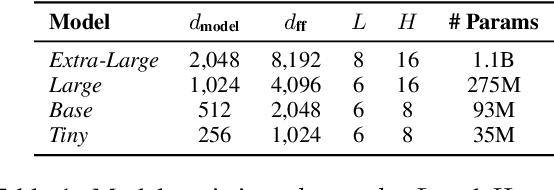
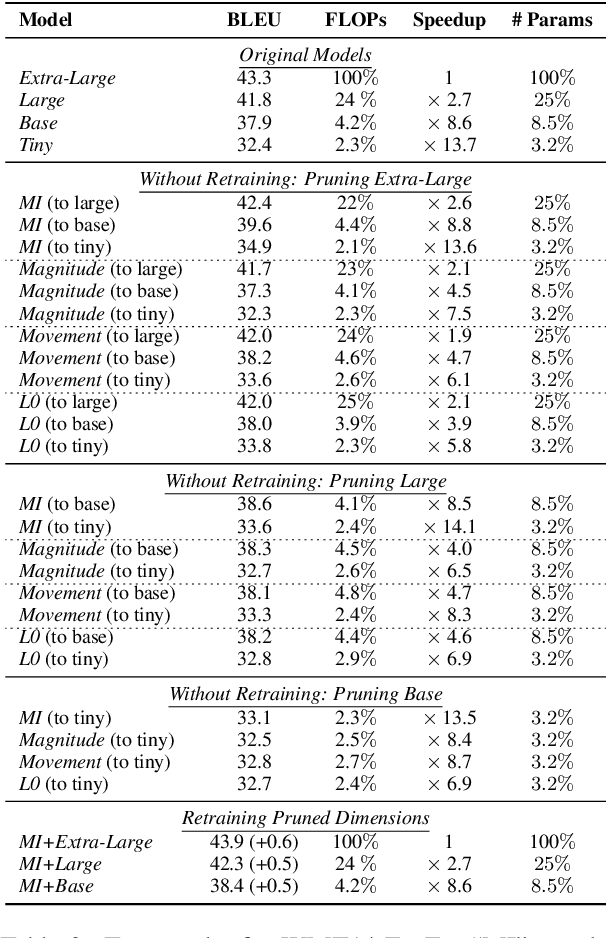
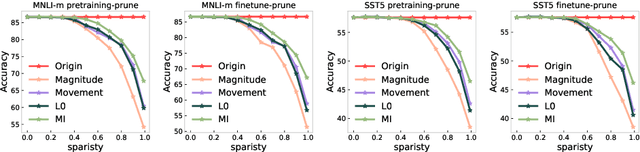
The proposed pruning strategy offers merits over weight-based pruning techniques: (1) it avoids irregular memory access since representations and matrices can be squeezed into their smaller but dense counterparts, leading to greater speedup; (2) in a manner of top-down pruning, the proposed method operates from a more global perspective based on training signals in the top layer, and prunes each layer by propagating the effect of global signals through layers, leading to better performances at the same sparsity level. Extensive experiments show that at the same sparsity level, the proposed strategy offers both greater speedup and higher performances than weight-based pruning methods (e.g., magnitude pruning, movement pruning).
Hyper Attention Recurrent Neural Network: Tackling Temporal Covariate Shift in Time Series Analysis
Feb 22, 2022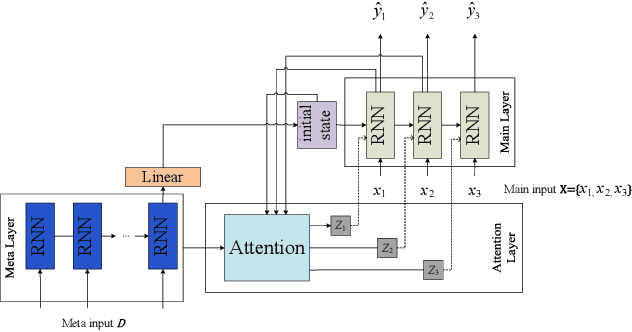
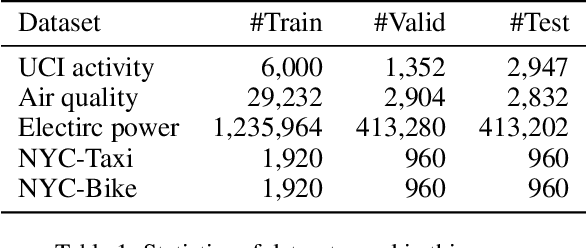
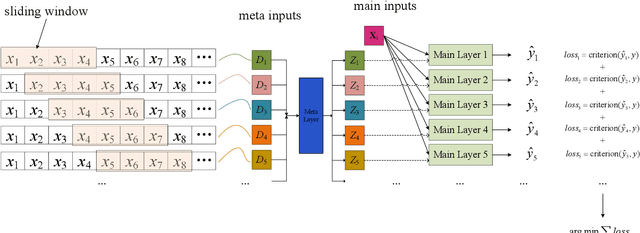
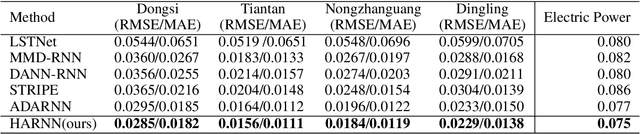
Analyzing long time series with RNNs often suffers from infeasible training. Segmentation is therefore commonly used in data pre-processing. However, in non-stationary time series, there exists often distribution shift among different segments. RNN is easily swamped in the dilemma of fitting bias in these segments due to the lack of global information, leading to poor generalization, known as Temporal Covariate Shift (TCS) problem, which is only addressed by a recently proposed RNN-based model. One of the assumptions in TCS is that the distribution of all divided intervals under the same segment are identical. This assumption, however, may not be true on high-frequency time series, such as traffic flow, that also have large stochasticity. Besides, macro information across long periods isn't adequately considered in the latest RNN-based methods. To address the above issues, we propose Hyper Attention Recurrent Neural Network (HARNN) for the modeling of temporal patterns containing both micro and macro information. An HARNN consists of a meta layer for parameter generation and an attention-enabled main layer for inference. High-frequency segments are transformed into low-frequency segments and fed into the meta layers, while the first main layer consumes the same high-frequency segments as conventional methods. In this way, each low-frequency segment in the meta inputs generates a unique main layer, enabling the integration of both macro information and micro information for inference. This forces all main layers to predict the same target which fully harnesses the common knowledge in varied distributions when capturing temporal patterns. Evaluations on multiple benchmarks demonstrated that our model outperforms a couple of RNN-based methods on a federation of key metrics.
Dense residual Transformer for image denoising
May 14, 2022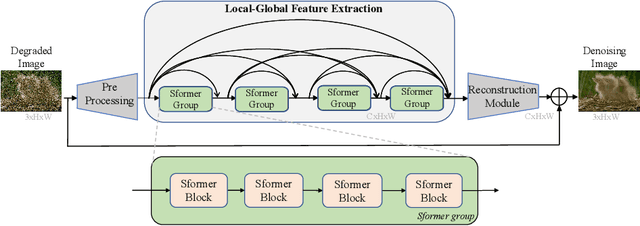
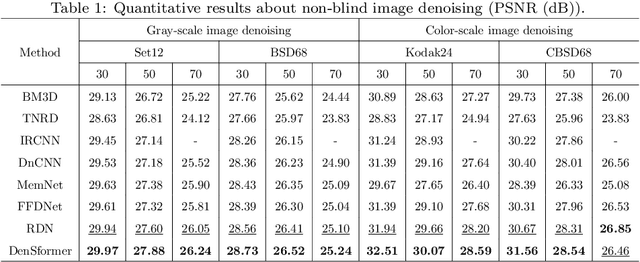
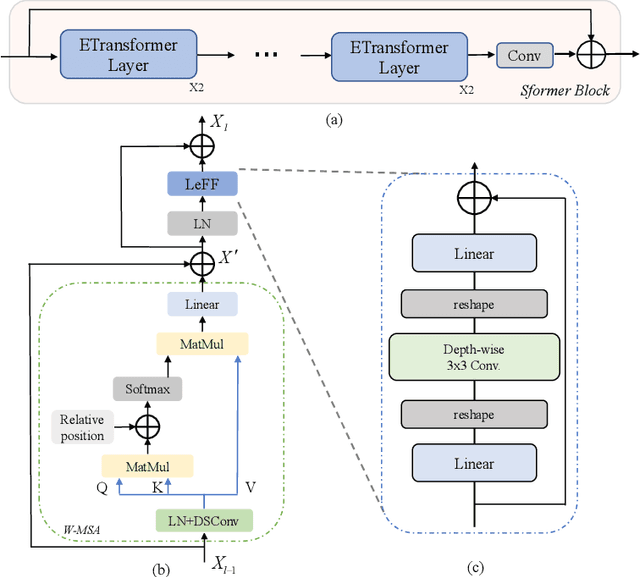
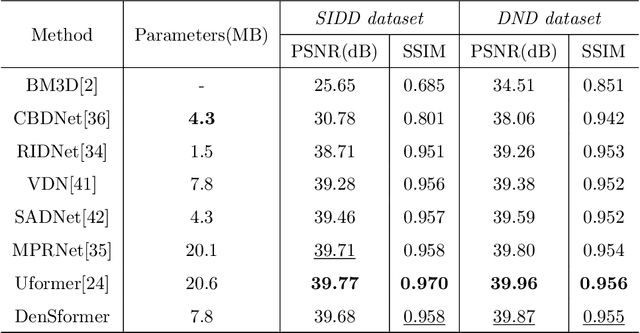
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.
Gradient-based Bayesian Experimental Design for Implicit Models using Mutual Information Lower Bounds
May 10, 2021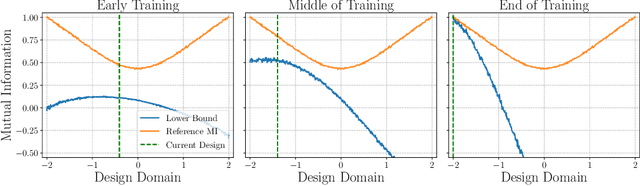
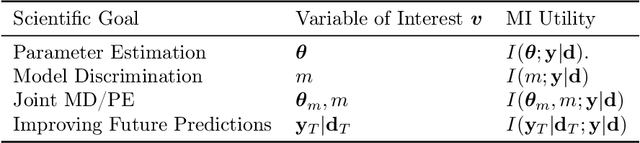
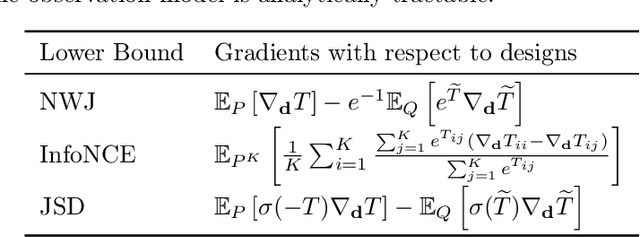
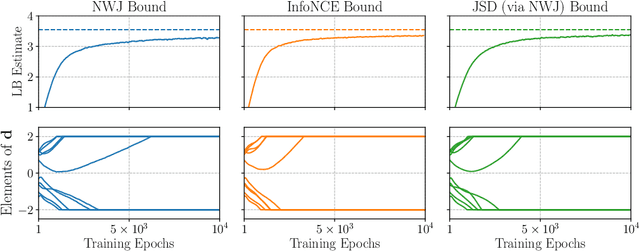
We introduce a framework for Bayesian experimental design (BED) with implicit models, where the data-generating distribution is intractable but sampling from it is still possible. In order to find optimal experimental designs for such models, our approach maximises mutual information lower bounds that are parametrised by neural networks. By training a neural network on sampled data, we simultaneously update network parameters and designs using stochastic gradient-ascent. The framework enables experimental design with a variety of prominent lower bounds and can be applied to a wide range of scientific tasks, such as parameter estimation, model discrimination and improving future predictions. Using a set of intractable toy models, we provide a comprehensive empirical comparison of prominent lower bounds applied to the aforementioned tasks. We further validate our framework on a challenging system of stochastic differential equations from epidemiology.
Towards Robotic Laboratory Automation Plug & Play: Teaching-free Robot Integration with the LAPP Digital Twin
May 17, 2022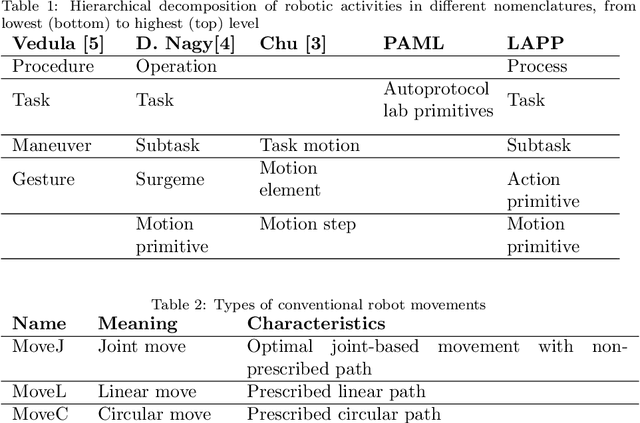
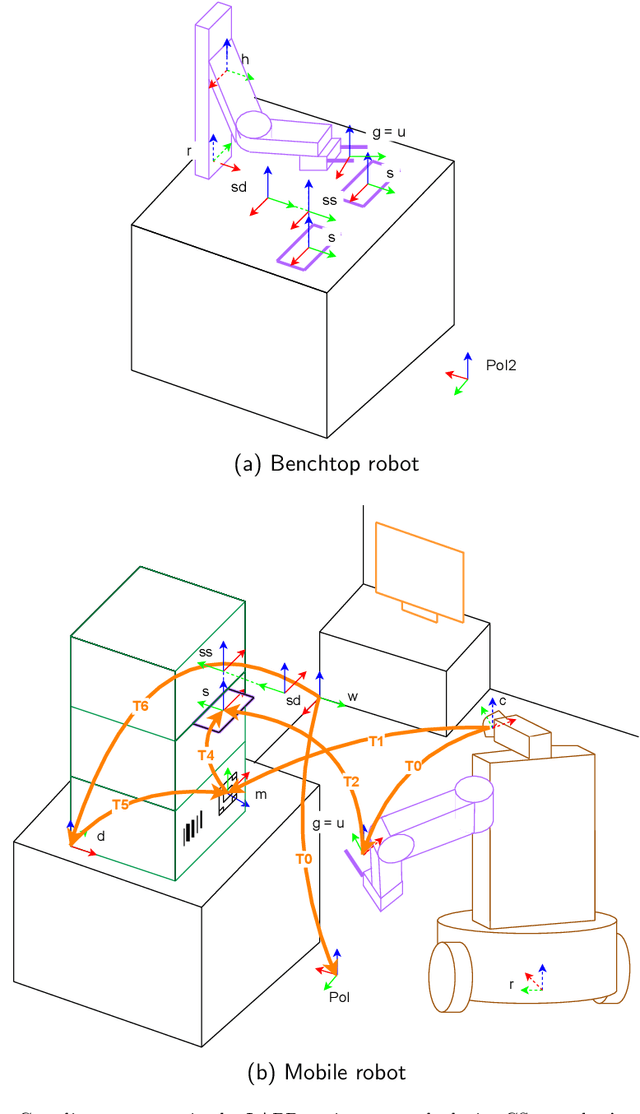
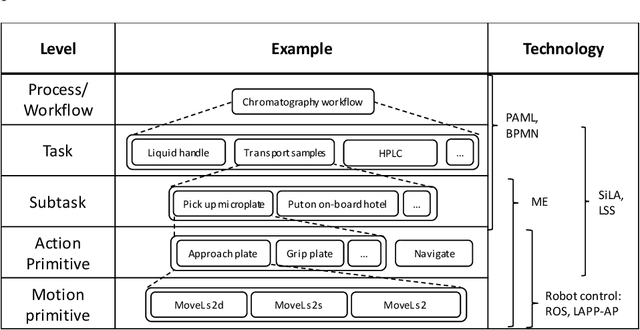
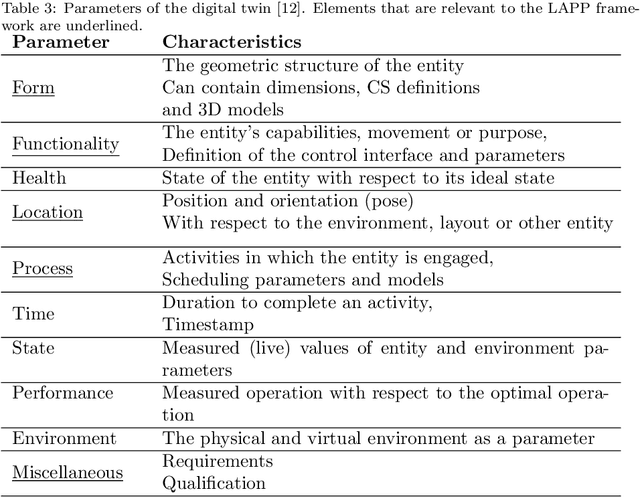
The Laboratory Automation Plug & Play (LAPP) framework is a high-level abstraction layer that makes the autonomous operation of life science laboratory robots possible. The plug & play nature lies in the fact that the manual teaching and configuration of robots is not required. A digital twin (DT) based concept is proposed that outlines the types of information that has to be provided for each relevant component of the system. In particular, for the devices that the robot interfaces with, the robot positions have to be defined beforehand in a device-attached coordinate system (CS) by the vendor. This CS has to be detectable by the vision system of the robot by means of optical markers placed on the front side of the device. With that, the robot is capable of tending the machine by performing the pick-and-place type transportation of standard sample carriers. This basic use case is the primary scope of the LAPP-DT framework. The hardware scope is limited to simple benchtop and mobile manipulators with parallel grippers at this stage. This paper first provides an overview of relevant literature and state-of-the-art solutions, after which it outlines the framework on the conceptual level, followed by the specification of the relevant DT parameters for the robot, for the devices and for the facility. Finally, appropriate technologies and strategies are identified for the implementation.
How to Minimize the Weighted Sum AoI in Two-Source Status Update Systems: OMA or NOMA?
May 06, 2022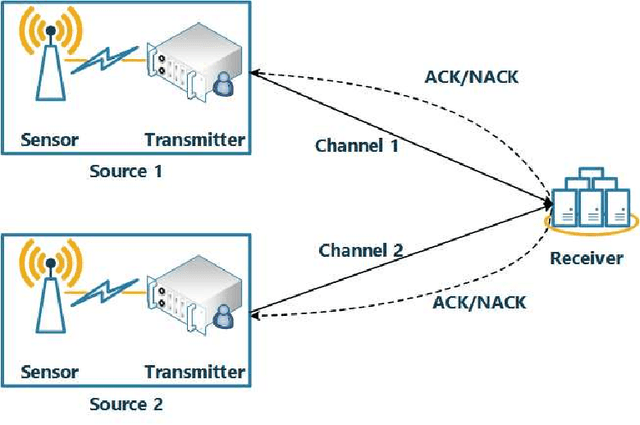
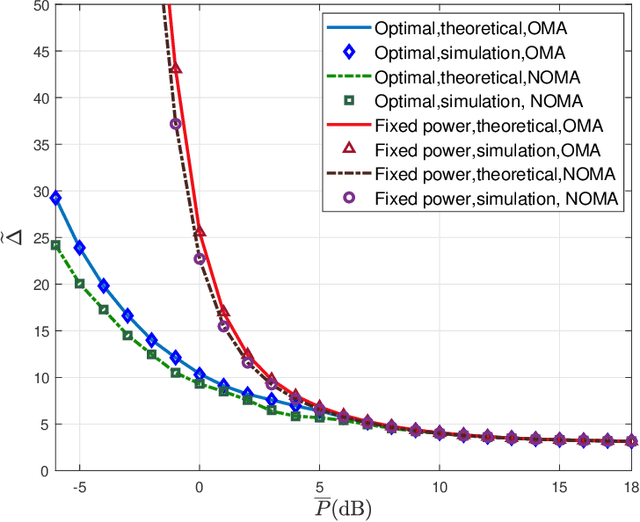
In this paper, the minimization of the weighted sum average age of information (AoI) in a two-source status update communication system is studied. Two independent sources send update packets to a common destination node in a time-slotted manner under the limit of maximum retransmission rounds. Different multiple access schemes, i.e., orthogonal multiple access (OMA) and non-orthogonal multiple access (NOMA) are exploited here over a block-fading multiple access channel (MAC). Constrained Markov decision process (CMDP) problems are formulated to describe the AoI minimization problems considering both transmission schemes. The Lagrangian method is utilised to convert CMDP problems to unconstraint Markov decision process (MDP) problems and corresponding algorithms to derive the power allocation policies are obtained. On the other hand, for the case of unknown environments, two online reinforcement learning approaches considering both multiple access schemes are proposed to achieve near-optimal age performance. Numerical simulations validate the improvement of the proposed policy in terms of weighted sum AoI compared to the fixed power transmission policy, and illustrate that NOMA is more favorable in case of larger packet size.
Continual learning on 3D point clouds with random compressed rehearsal
May 20, 2022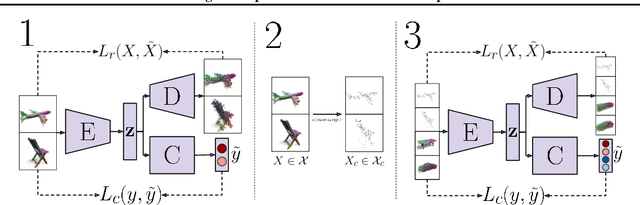

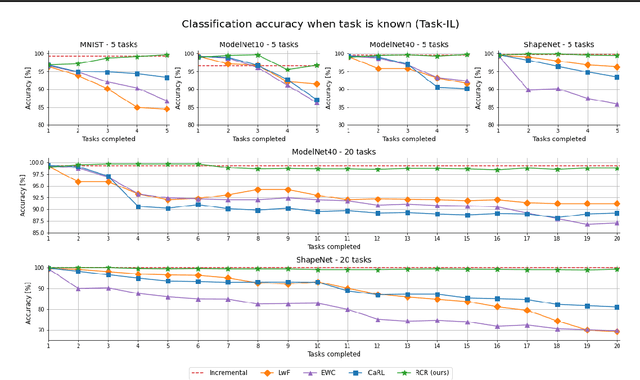
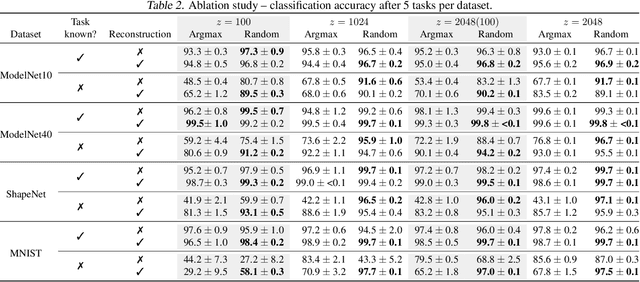
Contemporary deep neural networks offer state-of-the-art results when applied to visual reasoning, e.g., in the context of 3D point cloud data. Point clouds are important datatype for precise modeling of three-dimensional environments, but effective processing of this type of data proves to be challenging. In the world of large, heavily-parameterized network architectures and continuously-streamed data, there is an increasing need for machine learning models that can be trained on additional data. Unfortunately, currently available models cannot fully leverage training on additional data without losing their past knowledge. Combating this phenomenon, called catastrophic forgetting, is one of the main objectives of continual learning. Continual learning for deep neural networks has been an active field of research, primarily in 2D computer vision, natural language processing, reinforcement learning, and robotics. However, in 3D computer vision, there are hardly any continual learning solutions specifically designed to take advantage of point cloud structure. This work proposes a novel neural network architecture capable of continual learning on 3D point cloud data. We utilize point cloud structure properties for preserving a heavily compressed set of past data. By using rehearsal and reconstruction as regularization methods of the learning process, our approach achieves a significant decrease of catastrophic forgetting compared to the existing solutions on several most popular point cloud datasets considering two continual learning settings: when a task is known beforehand, and in the challenging scenario of when task information is unknown to the model.
Graph Neural Network Enhanced Language Models for Efficient Multilingual Text Classification
Mar 06, 2022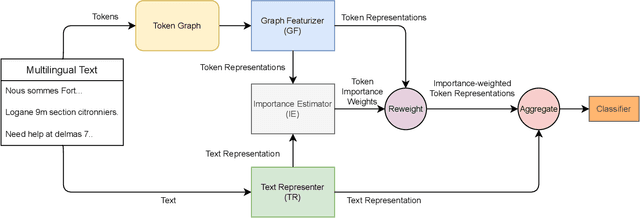

Online social media works as a source of various valuable and actionable information during disasters. These information might be available in multiple languages due to the nature of user generated content. An effective system to automatically identify and categorize these actionable information should be capable to handle multiple languages and under limited supervision. However, existing works mostly focus on English language only with the assumption that sufficient labeled data is available. To overcome these challenges, we propose a multilingual disaster related text classification system which is capable to work under \{mono, cross and multi\} lingual scenarios and under limited supervision. Our end-to-end trainable framework combines the versatility of graph neural networks, by applying over the corpus, with the power of transformer based large language models, over examples, with the help of cross-attention between the two. We evaluate our framework over total nine English, Non-English and monolingual datasets in \{mono, cross and multi\} lingual classification scenarios. Our framework outperforms state-of-the-art models in disaster domain and multilingual BERT baseline in terms of Weighted F$_1$ score. We also show the generalizability of the proposed model under limited supervision.
A Method of Query Graph Reranking for Knowledge Base Question Answering
Apr 27, 2022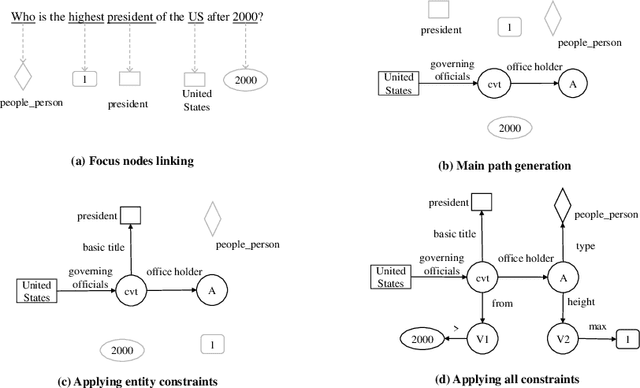

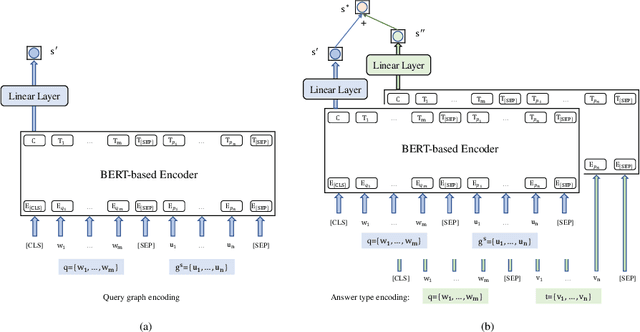
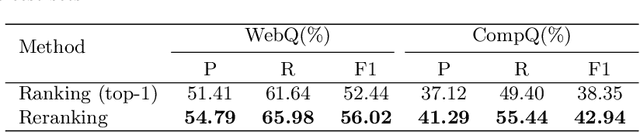
This paper presents a novel reranking method to better choose the optimal query graph, a sub-graph of knowledge graph, to retrieve the answer for an input question in Knowledge Base Question Answering (KBQA). Existing methods suffer from a severe problem that there is a significant gap between top-1 performance and the oracle score of top-n results. To address this problem, our method divides the choosing procedure into two steps: query graph ranking and query graph reranking. In the first step, we provide top-n query graphs for each question. Then we propose to rerank the top-n query graphs by combining with the information of answer type. Experimental results on two widely used datasets show that our proposed method achieves the best results on the WebQuestions dataset and the second best on the ComplexQuestions dataset.