 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AggPose: Deep Aggregation Vision Transformer for Infant Pose Estimation
May 11, 2022
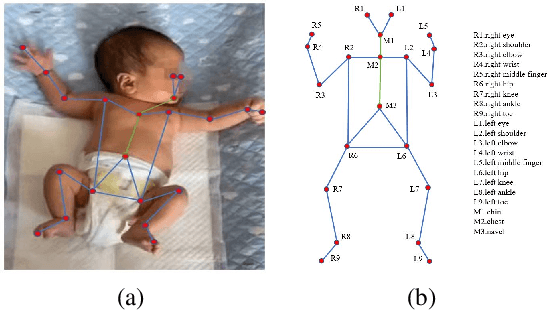

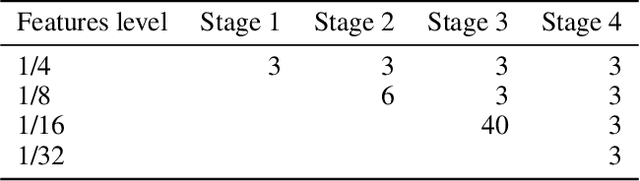
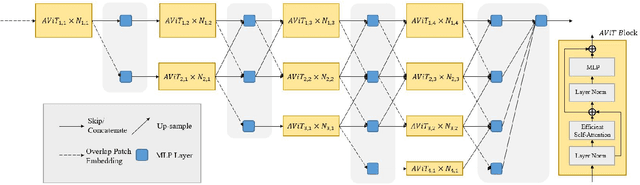
Movement and pose assessment of newborns lets experienced pediatricians predict neurodevelopmental disorders, allowing early intervention for related diseases. However, most of the newest AI approaches for human pose estimation methods focus on adults, lacking publicly benchmark for infant pose estimation. In this paper, we fill this gap by proposing infant pose dataset and Deep Aggregation Vision Transformer for human pose estimation, which introduces a fast trained full transformer framework without using convolution operations to extract features in the early stages. It generalizes Transformer + MLP to high-resolution deep layer aggregation within feature maps, thus enabling information fusion between different vision levels. We pre-train AggPose on COCO pose dataset and apply it on our newly released large-scale infant pose estimation dataset. The results show that AggPose could effectively learn the multi-scale features among different resolutions and significantly improve the performance of infant pose estimation. We show that AggPose outperforms hybrid model HRFormer and TokenPose in the infant pose estimation dataset. Moreover, our AggPose outperforms HRFormer by 0.7% AP on COCO val pose estimation on average. Our code is available at github.com/SZAR-LAB/AggPose.
Intelligent Reflecting Surface Configurations for Smart Radio Using Deep Reinforcement Learning
May 11, 2022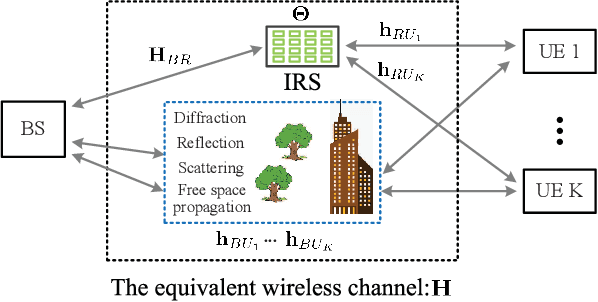
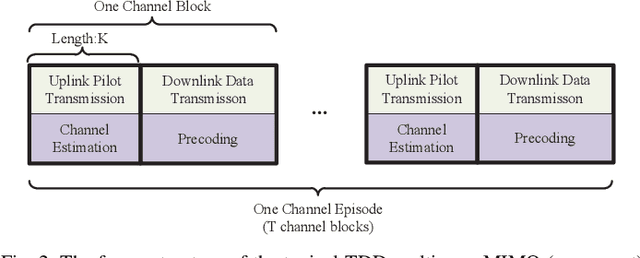

Intelligent reflecting surface (IRS) is envisioned to change the paradigm of wireless communications from "adapting to wireless channels" to "changing wireless channels". However, current IRS configuration schemes, consisting of sub-channel estimation and passive beamforming in sequence, conform to the conventional model-based design philosophies and are difficult to be realized practically in the complex radio environment. To create the smart radio environment, we propose a model-free design of IRS control that is independent of the sub-channel channel state information (CSI) and requires the minimum interaction between IRS and the wireless communication system. We firstly model the control of IRS as a Markov decision process (MDP) and apply deep reinforcement learning (DRL) to perform real-time coarse phase control of IRS. Then, we apply extremum seeking control (ESC) as the fine phase control of IRS. Finally, by updating the frame structure, we integrate DRL and ESC in the model-free control of IRS to improve its adaptivity to different channel dynamics. Numerical results show the superiority of our proposed joint DRL and ESC scheme and verify its effectiveness in model-free IRS control without sub-channel CSI.
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective
Oct 05, 2020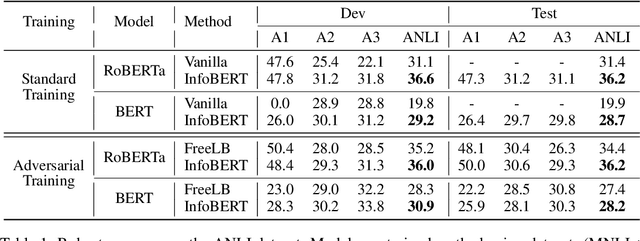
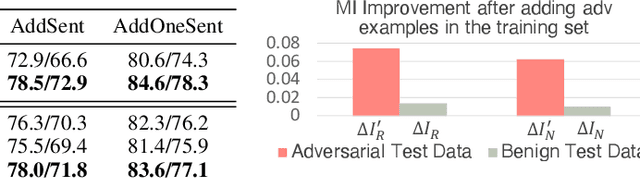
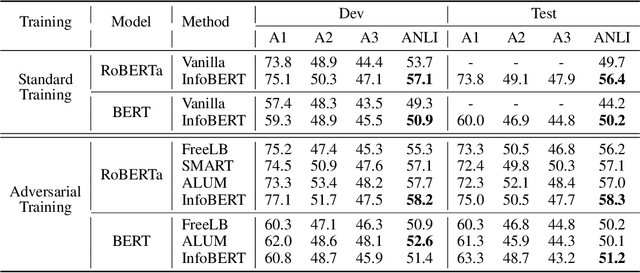
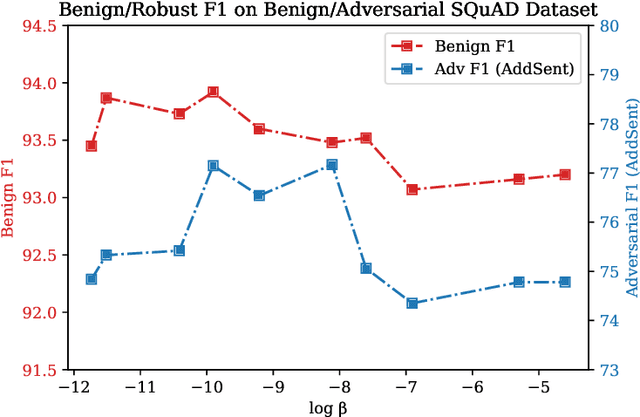
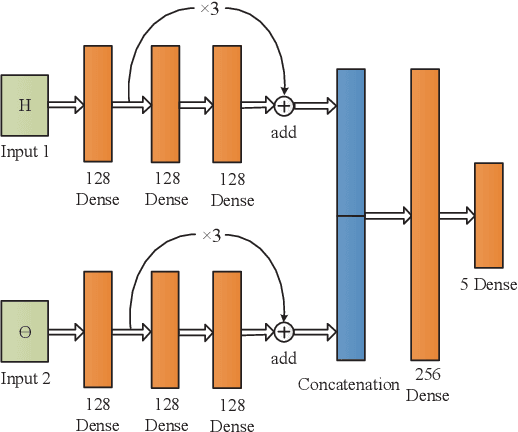
Large-scale language models such as BERT have achieved state-of-the-art performance across a wide range of NLP tasks. Recent studies, however, show that such BERT-based models are vulnerable facing the threats of textual adversarial attacks. We aim to address this problem from an information-theoretic perspective, and propose InfoBERT, a novel learning framework for robust fine-tuning of pre-trained language models. InfoBERT contains two mutual-information-based regularizers for model training: (i) an Information Bottleneck regularizer, which suppresses noisy mutual information between the input and the feature representation; and (ii) a Robust Feature regularizer, which increases the mutual information between local robust features and global features. We provide a principled way to theoretically analyze and improve the robustness of representation learning for language models in both standard and adversarial training. Extensive experiments demonstrate that InfoBERT achieves state-of-the-art robust accuracy over several adversarial datasets on Natural Language Inference (NLI) and Question Answering (QA) tasks.
Cross Cryptocurrency Relationship Mining for Bitcoin Price Prediction
Apr 28, 2022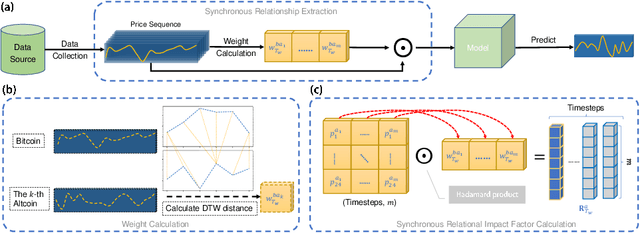
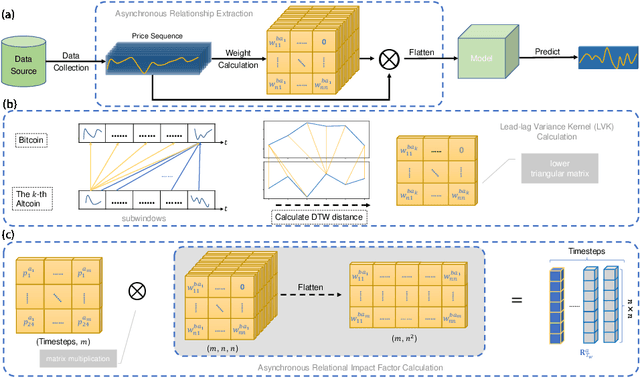
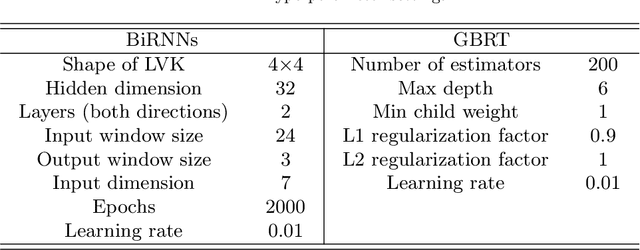
Blockchain finance has become a part of the world financial system, most typically manifested in the attention to the price of Bitcoin. However, a great deal of work is still limited to using technical indicators to capture Bitcoin price fluctuation, with little consideration of historical relationships and interactions between related cryptocurrencies. In this work, we propose a generic Cross-Cryptocurrency Relationship Mining module, named C2RM, which can effectively capture the synchronous and asynchronous impact factors between Bitcoin and related Altcoins. Specifically, we utilize the Dynamic Time Warping algorithm to extract the lead-lag relationship, yielding Lead-lag Variance Kernel, which will be used for aggregating the information of Altcoins to form relational impact factors. Comprehensive experimental results demonstrate that our C2RM can help existing price prediction methods achieve significant performance improvement, suggesting the effectiveness of Cross-Cryptocurrency interactions on benefitting Bitcoin price prediction.
STDC-MA Network for Semantic Segmentation
May 11, 2022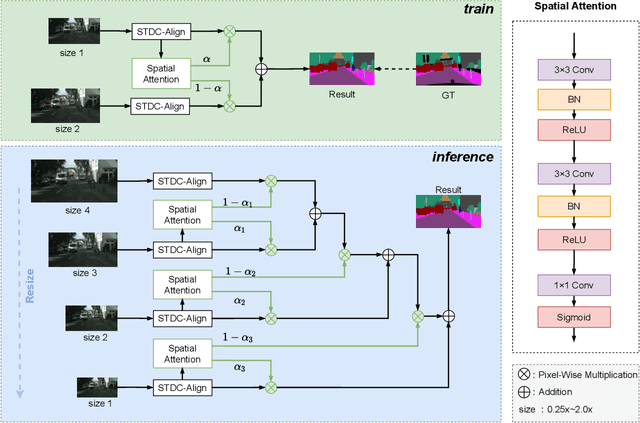

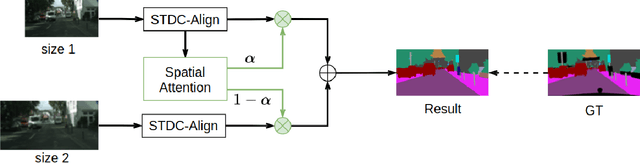
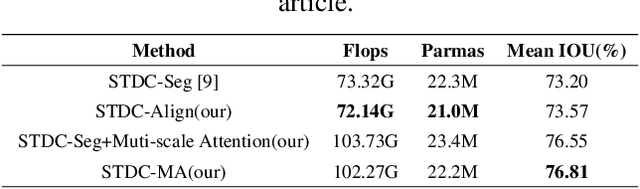
Semantic segmentation is applied extensively in autonomous driving and intelligent transportation with methods that highly demand spatial and semantic information. Here, an STDC-MA network is proposed to meet these demands. First, the STDC-Seg structure is employed in STDC-MA to ensure a lightweight and efficient structure. Subsequently, the feature alignment module (FAM) is applied to understand the offset between high-level and low-level features, solving the problem of pixel offset related to upsampling on the high-level feature map. Our approach implements the effective fusion between high-level features and low-level features. A hierarchical multiscale attention mechanism is adopted to reveal the relationship among attention regions from two different input sizes of one image. Through this relationship, regions receiving much attention are integrated into the segmentation results, thereby reducing the unfocused regions of the input image and improving the effective utilization of multiscale features. STDC- MA maintains the segmentation speed as an STDC-Seg network while improving the segmentation accuracy of small objects. STDC-MA was verified on the verification set of Cityscapes. The segmentation result of STDC-MA attained 76.81% mIOU with the input of 0.5x scale, 3.61% higher than STDC-Seg.
Gated Domain-Invariant Feature Disentanglement for Domain Generalizable Object Detection
Mar 22, 2022
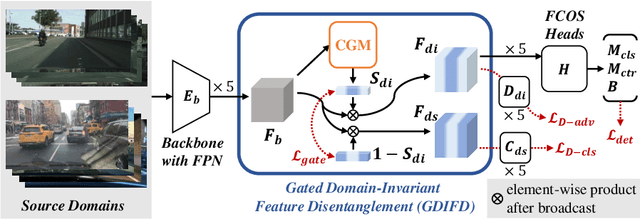

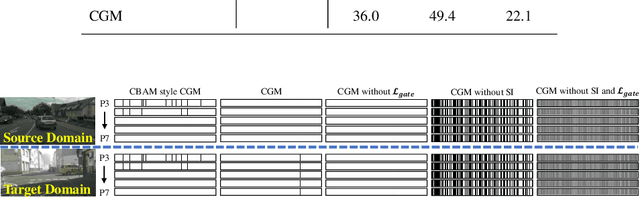
For Domain Generalizable Object Detection (DGOD), Disentangled Representation Learning (DRL) helps a lot by explicitly disentangling Domain-Invariant Representations (DIR) from Domain-Specific Representations (DSR). Considering the domain category is an attribute of input data, it should be feasible for networks to fit a specific mapping which projects DSR into feature channels exclusive to domain-specific information, and thus much cleaner disentanglement of DIR from DSR can be achieved simply on channel dimension. Inspired by this idea, we propose a novel DRL method for DGOD, which is termed Gated Domain-Invariant Feature Disentanglement (GDIFD). In GDIFD, a Channel Gate Module (CGM) learns to output channel gate signals close to either 0 or 1, which can mask out the channels exclusive to domain-specific information helpful for domain recognition. With the proposed GDIFD, the backbone in our framework can fit the desired mapping easily, which enables the channel-wise disentanglement. In experiments, we demonstrate that our approach is highly effective and achieves state-of-the-art DGOD performance.
Deep Directed Information-Based Learning for Privacy-Preserving Smart Meter Data Release
Nov 20, 2020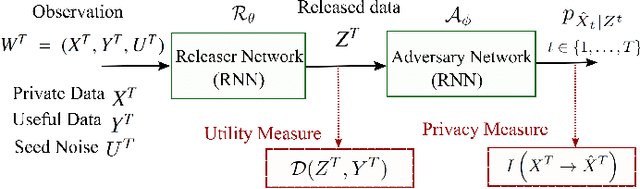
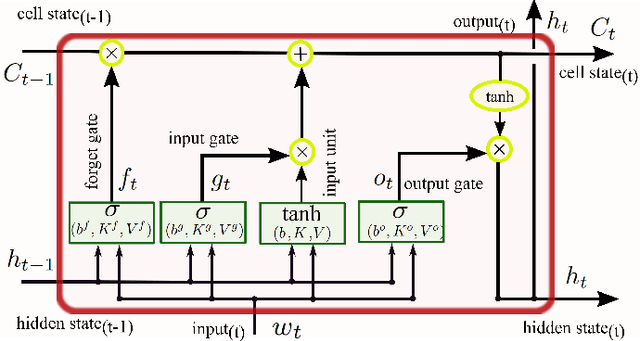
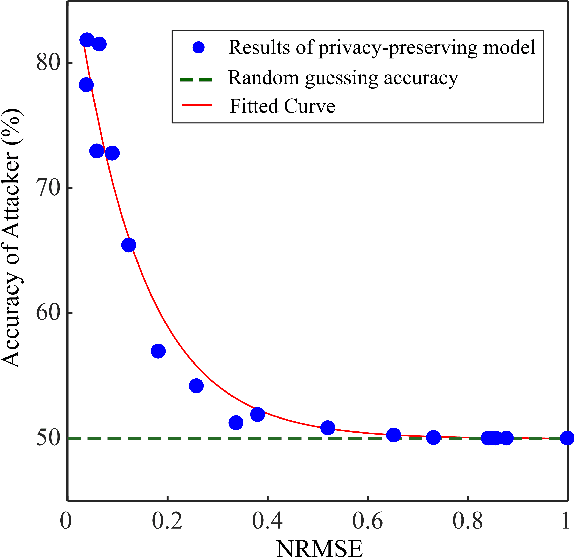
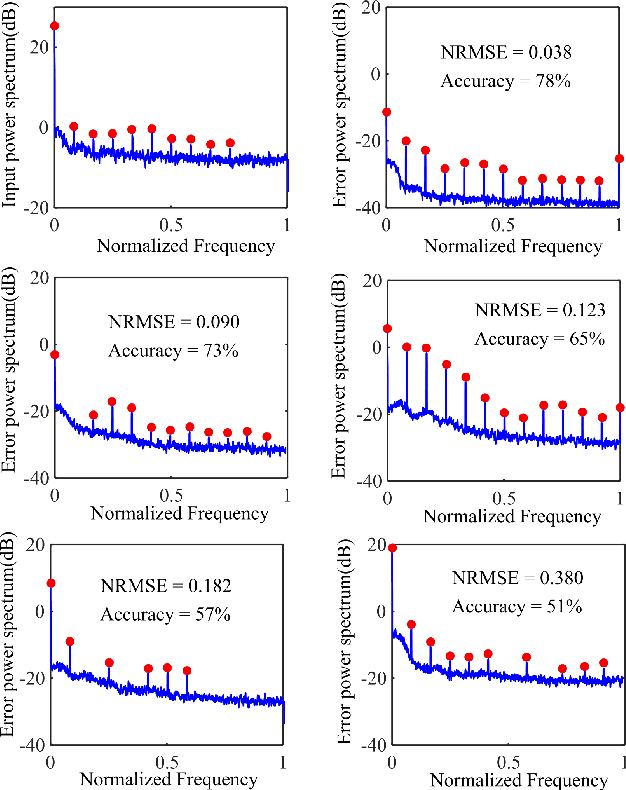
The explosion of data collection has raised serious privacy concerns in users due to the possibility that sharing data may also reveal sensitive information. The main goal of a privacy-preserving mechanism is to prevent a malicious third party from inferring sensitive information while keeping the shared data useful. In this paper, we study this problem in the context of time series data and smart meters (SMs) power consumption measurements in particular. Although Mutual Information (MI) between private and released variables has been used as a common information-theoretic privacy measure, it fails to capture the causal time dependencies present in the power consumption time series data. To overcome this limitation, we introduce the Directed Information (DI) as a more meaningful measure of privacy in the considered setting and propose a novel loss function. The optimization is then performed using an adversarial framework where two Recurrent Neural Networks (RNNs), referred to as the releaser and the adversary, are trained with opposite goals. Our empirical studies on real-world data sets from SMs measurements in the worst-case scenario where an attacker has access to all the training data set used by the releaser, validate the proposed method and show the existing trade-offs between privacy and utility.
Deep Transfer Learning & Beyond: Transformer Language Models in Information Systems Research
Oct 23, 2021
AI is widely thought to be poised to transform business, yet current perceptions of the scope of this transformation may be myopic. Recent progress in natural language processing involving transformer language models (TLMs) offers a potential avenue for AI-driven business and societal transformation that is beyond the scope of what most currently foresee. We review this recent progress as well as recent literature utilizing text mining in top IS journals to develop an outline for how future IS research can benefit from these new techniques. Our review of existing IS literature reveals that suboptimal text mining techniques are prevalent and that the more advanced TLMs could be applied to enhance and increase IS research involving text data, and to enable new IS research topics, thus creating more value for the research community. This is possible because these techniques make it easier to develop very powerful custom systems and their performance is superior to existing methods for a wide range of tasks and applications. Further, multilingual language models make possible higher quality text analytics for research in multiple languages. We also identify new avenues for IS research, like language user interfaces, that may offer even greater potential for future IS research.
ProxyMix: Proxy-based Mixup Training with Label Refinery for Source-Free Domain Adaptation
May 29, 2022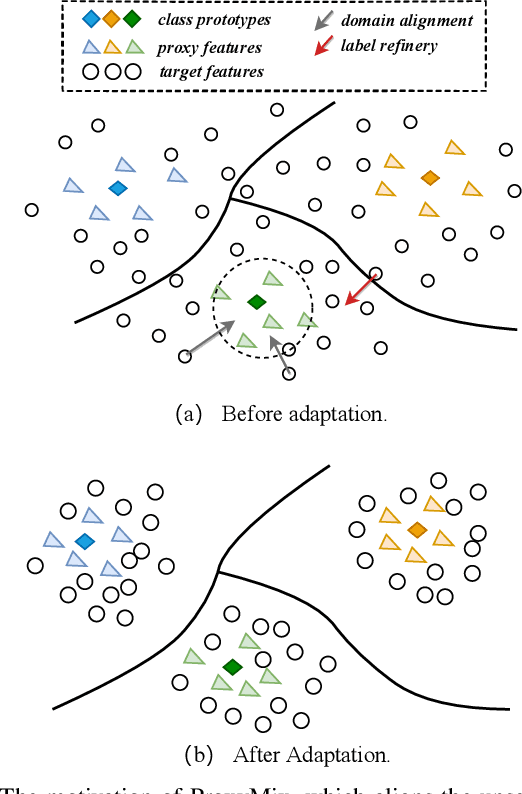
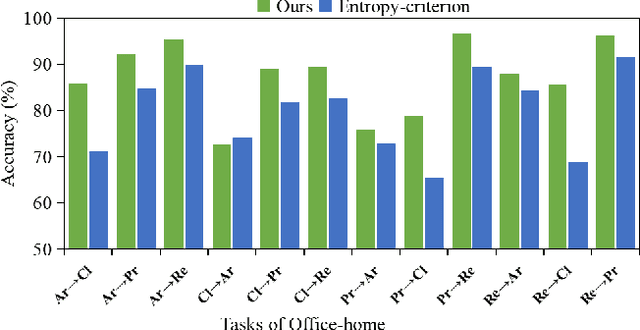
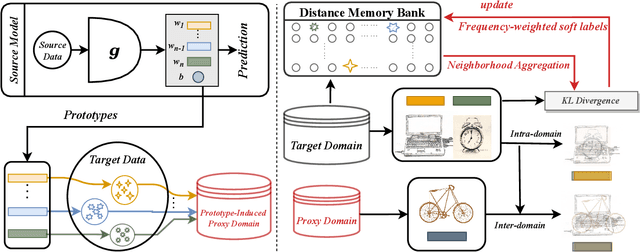
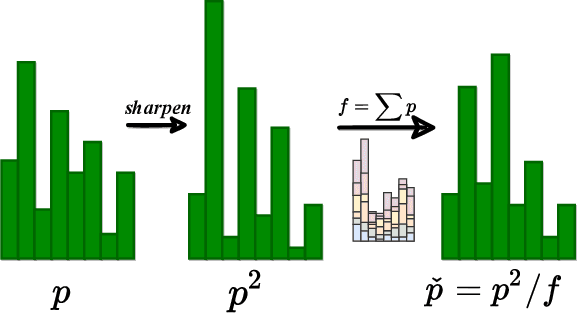
Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. Owing to privacy concerns and heavy data transmission, source-free UDA, exploiting the pre-trained source models instead of the raw source data for target learning, has been gaining popularity in recent years. Some works attempt to recover unseen source domains with generative models, however introducing additional network parameters. Other works propose to fine-tune the source model by pseudo labels, while noisy pseudo labels may misguide the decision boundary, leading to unsatisfied results. To tackle these issues, we propose an effective method named Proxy-based Mixup training with label refinery (ProxyMix). First of all, to avoid additional parameters and explore the information in the source model, ProxyMix defines the weights of the classifier as the class prototypes and then constructs a class-balanced proxy source domain by the nearest neighbors of the prototypes to bridge the unseen source domain and the target domain. To improve the reliability of pseudo labels, we further propose the frequency-weighted aggregation strategy to generate soft pseudo labels for unlabeled target data. The proposed strategy exploits the internal structure of target features, pulls target features to their semantic neighbors, and increases the weights of low-frequency classes samples during gradient updating. With the proxy domain and the reliable pseudo labels, we employ two kinds of mixup regularization, i.e., inter- and intra-domain mixup, in our framework, to align the proxy and the target domain, enforcing the consistency of predictions, thereby further mitigating the negative impacts of noisy labels. Experiments on three 2D image and one 3D point cloud object recognition benchmarks demonstrate that ProxyMix yields state-of-the-art performance for source-free UDA tasks.
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
Mar 30, 2022

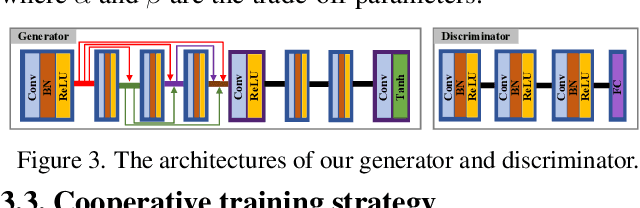

This study addresses the issue of fusing infrared and visible images that appear differently for object detection. Aiming at generating an image of high visual quality, previous approaches discover commons underlying the two modalities and fuse upon the common space either by iterative optimization or deep networks. These approaches neglect that modality differences implying the complementary information are extremely important for both fusion and subsequent detection task. This paper proposes a bilevel optimization formulation for the joint problem of fusion and detection, and then unrolls to a target-aware Dual Adversarial Learning (TarDAL) network for fusion and a commonly used detection network. The fusion network with one generator and dual discriminators seeks commons while learning from differences, which preserves structural information of targets from the infrared and textural details from the visible. Furthermore, we build a synchronized imaging system with calibrated infrared and optical sensors, and collect currently the most comprehensive benchmark covering a wide range of scenarios. Extensive experiments on several public datasets and our benchmark demonstrate that our method outputs not only visually appealing fusion but also higher detection mAP than the state-of-the-art approaches.