 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Personalized Federated Learning With Structure
Mar 08, 2022
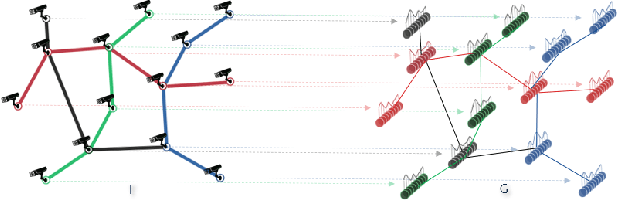

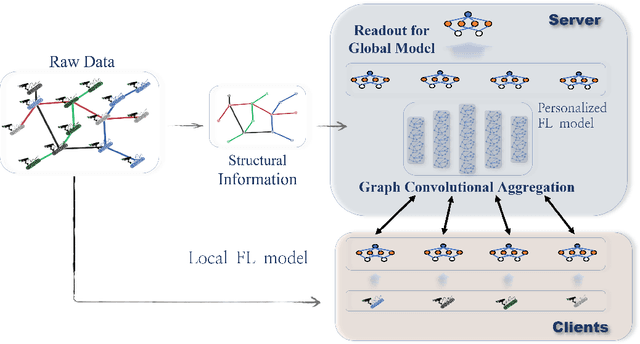
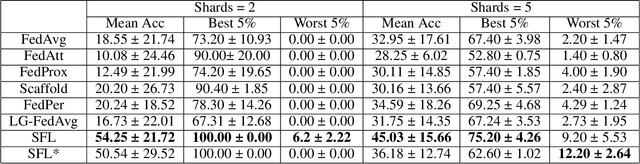
Knowledge sharing and model personalization are two key components to impact the performance of personalized federated learning (PFL). Existing PFL methods simply treat knowledge sharing as an aggregation of all clients regardless of the hidden relations among them. This paper is to enhance the knowledge-sharing process in PFL by leveraging the structural information among clients. We propose a novel structured federated learning(SFL) framework to simultaneously learn the global model and personalized model using each client's local relations with others and its private dataset. This proposed framework has been formulated to a new optimization problem to model the complex relationship among personalized models and structural topology information into a unified framework. Moreover, in contrast to a pre-defined structure, our framework could be further enhanced by adding a structure learning component to automatically learn the structure using the similarities between clients' models' parameters. By conducting extensive experiments, we first demonstrate how federated learning can be benefited by introducing structural information into the server aggregation process with a real-world dataset, and then the effectiveness of the proposed method has been demonstrated in varying degrees of data non-iid settings.
Computer Vision and Deep Learning for Fish Classification in Underwater Habitats: A Survey
Mar 15, 2022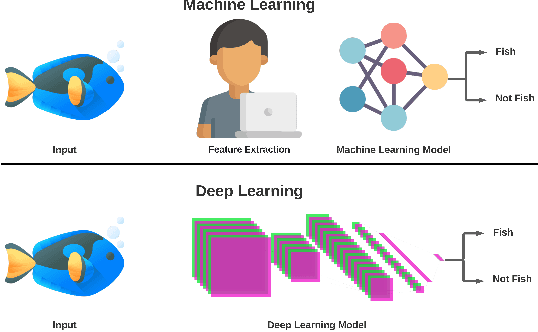
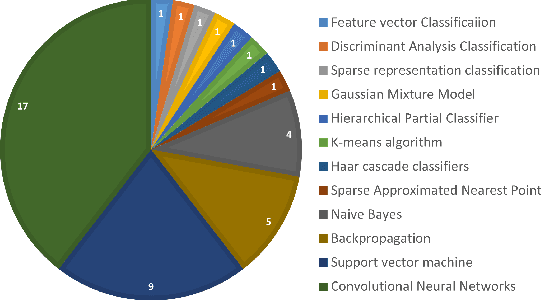
Marine scientists use remote underwater video recording to survey fish species in their natural habitats. This helps them understand and predict how fish respond to climate change, habitat degradation, and fishing pressure. This information is essential for developing sustainable fisheries for human consumption, and for preserving the environment. However, the enormous volume of collected videos makes extracting useful information a daunting and time-consuming task for a human. A promising method to address this problem is the cutting-edge Deep Learning (DL) technology.DL can help marine scientists parse large volumes of video promptly and efficiently, unlocking niche information that cannot be obtained using conventional manual monitoring methods. In this paper, we provide an overview of the key concepts of DL, while presenting a survey of literature on fish habitat monitoring with a focus on underwater fish classification. We also discuss the main challenges faced when developing DL for underwater image processing and propose approaches to address them. Finally, we provide insights into the marine habitat monitoring research domain and shed light on what the future of DL for underwater image processing may hold. This paper aims to inform a wide range of readers from marine scientists who would like to apply DL in their research to computer scientists who would like to survey state-of-the-art DL-based underwater fish habitat monitoring literature.
On the Capacity of Quantum Private Information Retrieval from MDS-Coded and Colluding Servers
Jun 29, 2021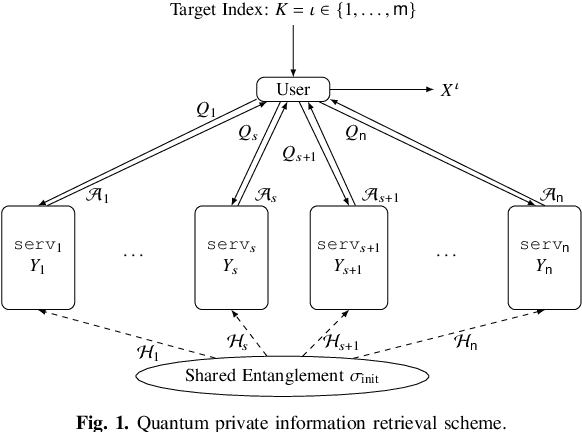
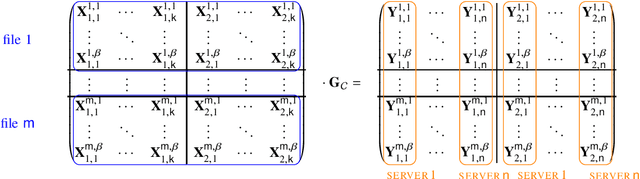


In quantum private information retrieval (QPIR), a user retrieves a classical file from multiple servers by downloading quantum systems without revealing the identity of the file. The QPIR capacity is the maximal achievable ratio of the retrieved file size to the total download size. In this paper, the capacity of QPIR from MDS-coded and colluding servers is studied. Two classes of QPIR, called stabilizer QPIR and dimension squared QPIR induced from classical strongly linear PIR are defined, and the related QPIR capacities are derived. For the non-colluding case, the general QPIR capacity is derived when the number of files goes to infinity. The capacities of symmetric and non-symmetric QPIR with coded and colluding servers are proved to coincide, being double to their classical counterparts. A general statement on the converse bound for QPIR with coded and colluding servers is derived showing that the capacities of stabilizer QPIR and dimension squared QPIR induced from any class of PIR are upper bounded by twice the classical capacity of the respective PIR class. The proposed capacity-achieving scheme combines the star-product scheme by Freij-Hollanti et al. and the stabilizer QPIR scheme by Song et al. by employing (weakly) self-dual Reed--Solomon codes.
On the efficiency of Stochastic Quasi-Newton Methods for Deep Learning
May 18, 2022

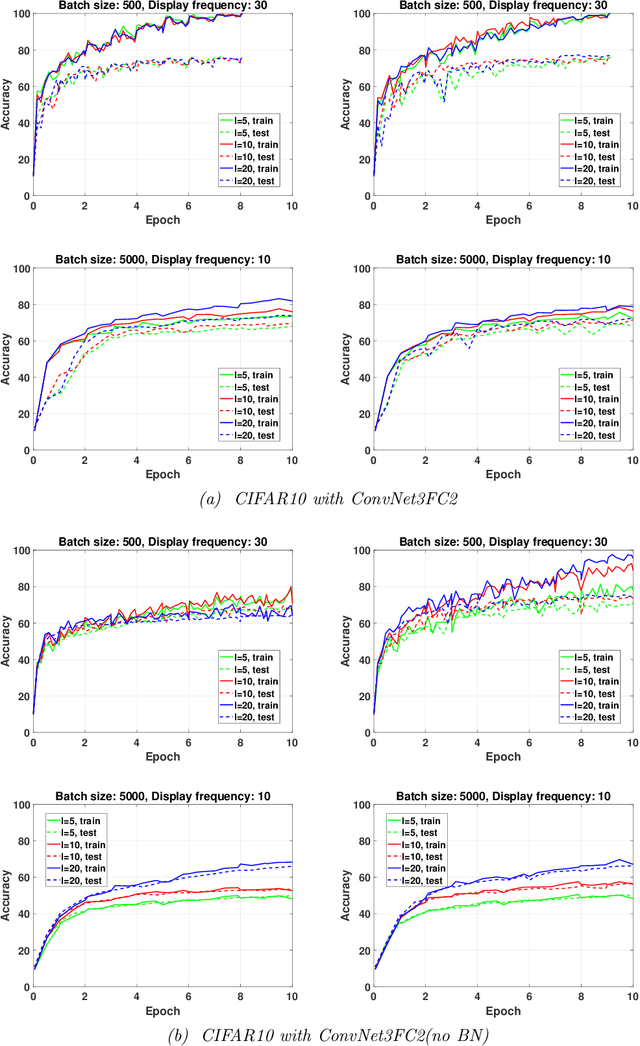
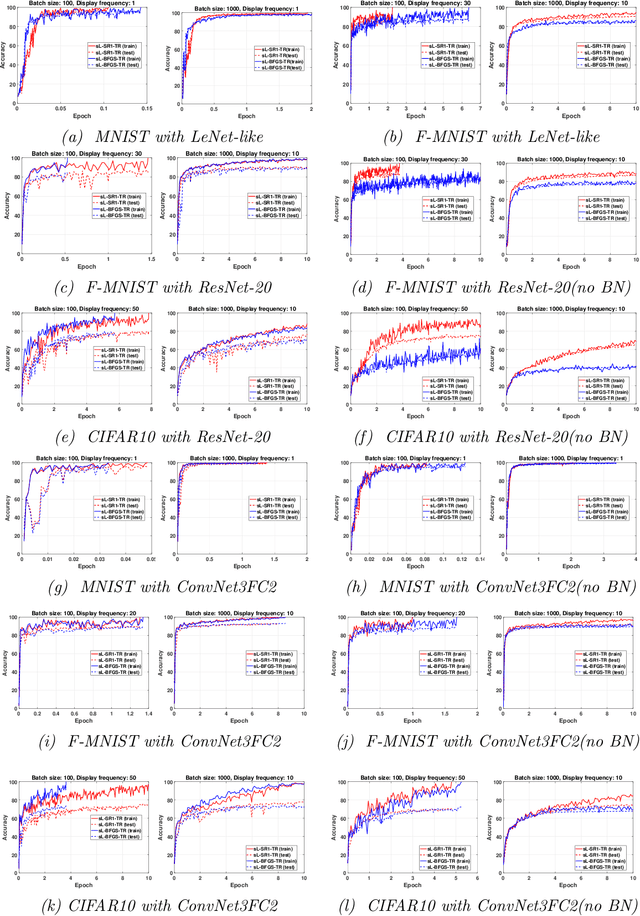
While first-order methods are popular for solving optimization problems that arise in large-scale deep learning problems, they come with some acute deficiencies. To diminish such shortcomings, there has been recent interest in applying second-order methods such as quasi-Newton based methods which construct Hessians approximations using only gradient information. The main focus of our work is to study the behaviour of stochastic quasi-Newton algorithms for training deep neural networks. We have analyzed the performance of two well-known quasi-Newton updates, the limited memory Broyden-Fletcher-Goldfarb-Shanno (BFGS) and the Symmetric Rank One (SR1). This study fills a gap concerning the real performance of both updates and analyzes whether more efficient training is obtained when using the more robust BFGS update or the cheaper SR1 formula which allows for indefinite Hessian approximations and thus can potentially help to better navigate the pathological saddle points present in the non-convex loss functions found in deep learning. We present and discuss the results of an extensive experimental study which includes the effect of batch normalization and network's architecture, the limited memory parameter, the batch size and the type of sampling strategy. we show that stochastic quasi-Newton optimizers are efficient and able to outperform in some instances the well-known first-order Adam optimizer run with the optimal combination of its numerous hyperparameters.
Submodular Combinatorial Information Measures with Applications in Machine Learning
Jun 27, 2020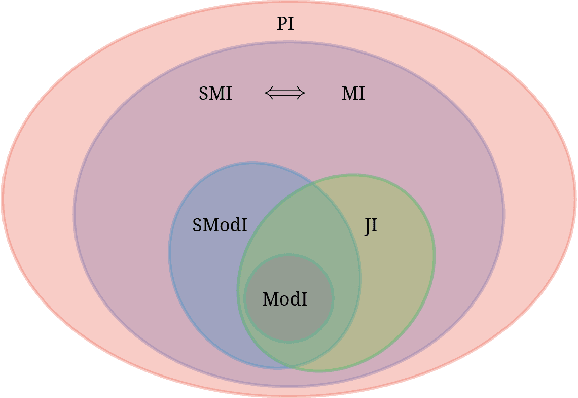



Information-theoretic quantities like entropy and mutual information have found numerous uses in machine learning. It is well known that there is a strong connection between these entropic quantities and submodularity since entropy over a set of random variables is submodular. In this paper, we study combinatorial information measures that generalize independence, (conditional) entropy, (conditional) mutual information, and total correlation defined over sets of (not necessarily random) variables. These measures strictly generalize the corresponding entropic measures since they are all parameterized via submodular functions that themselves strictly generalize entropy. Critically, we show that, unlike entropic mutual information in general, the submodular mutual information is actually submodular in one argument, holding the other fixed, for a large class of submodular functions whose third-order partial derivatives satisfy a non-negativity property. This turns out to include a number of practically useful cases such as the facility location and set-cover functions. We study specific instantiations of the submodular information measures on these, as well as the probabilistic coverage, graph-cut, and saturated coverage functions, and see that they all have mathematically intuitive and practically useful expressions. Regarding applications, we connect the maximization of submodular (conditional) mutual information to problems such as mutual-information-based, query-based, and privacy-preserving summarization -- and we connect optimizing the multi-set submodular mutual information to clustering and robust partitioning.
Optimizing Rescoring Rules with Interpretable Representations of Long-Term Information
Apr 28, 2021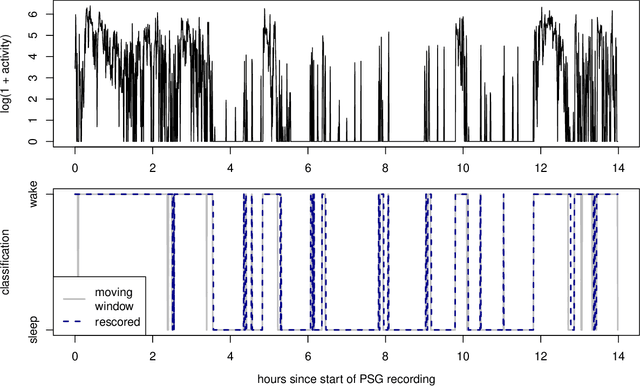
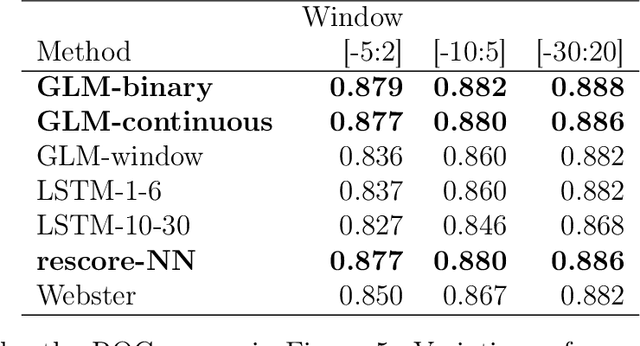
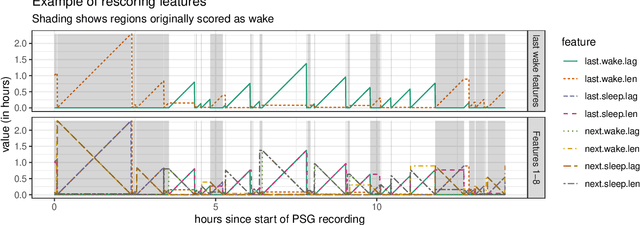
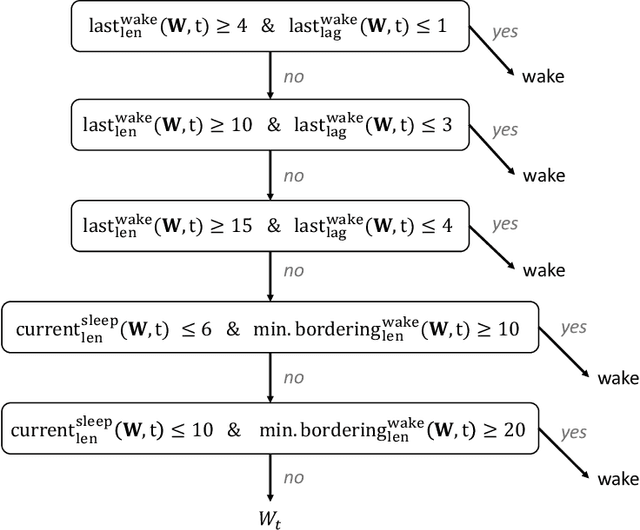
Analyzing temporal data (e.g., wearable device data) requires a decision about how to combine information from the recent and distant past. In the context of classifying sleep status from actigraphy, Webster's rescoring rules offer one popular solution based on the long-term patterns in the output of a moving-window model. Unfortunately, the question of how to optimize rescoring rules for any given setting has remained unsolved. To address this problem and expand the possible use cases of rescoring rules, we propose rephrasing these rules in terms of epoch-specific features. Our features take two general forms: (1) the time lag between now and the most recent [or closest upcoming] bout of time spent in a given state, and (2) the length of the most recent [or closest upcoming] bout of time spent in a given state. Given any initial moving window model, these features can be defined recursively, allowing for straightforward optimization of rescoring rules. Joint optimization of the moving window model and the subsequent rescoring rules can also be implemented using gradient-based optimization software, such as Tensorflow. Beyond binary classification problems (e.g., sleep-wake), the same approach can be applied to summarize long-term patterns for multi-state classification problems (e.g., sitting, walking, or stair climbing). We find that optimized rescoring rules improve the performance of sleep-wake classifiers, achieving accuracy comparable to that of certain neural network architectures.
Exploiting Contextual Information with Deep Neural Networks
Jun 21, 2020
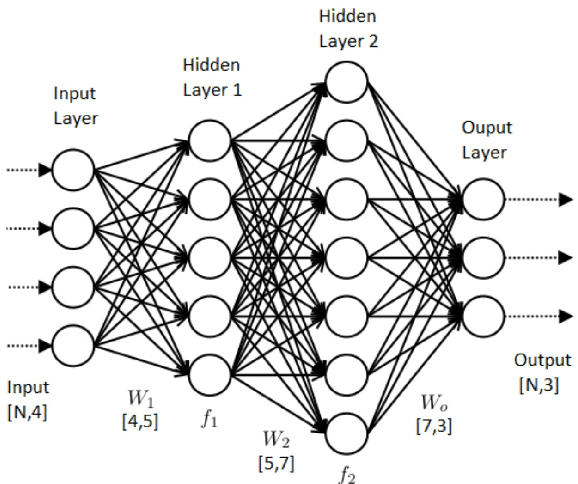
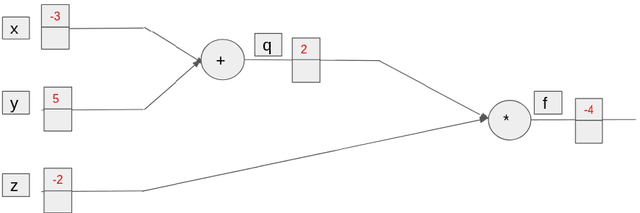
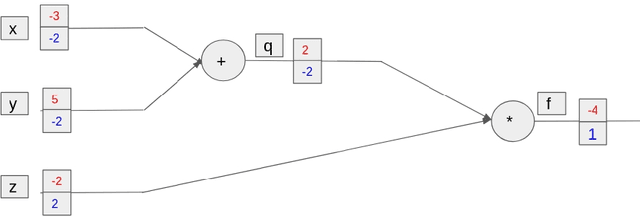
Context matters! Nevertheless, there has not been much research in exploiting contextual information in deep neural networks. For most part, the entire usage of contextual information has been limited to recurrent neural networks. Attention models and capsule networks are two recent ways of introducing contextual information in non-recurrent models, however both of these algorithms have been developed after this work has started. In this thesis, we show that contextual information can be exploited in 2 fundamentally different ways: implicitly and explicitly. In the DeepScore project, where the usage of context is very important for the recognition of many tiny objects, we show that by carefully crafting convolutional architectures, we can achieve state-of-the-art results, while also being able to implicitly correctly distinguish between objects which are virtually identical, but have different meanings based on their surrounding. In parallel, we show that by explicitly designing algorithms (motivated from graph theory and game theory) that take into considerations the entire structure of the dataset, we can achieve state-of-the-art results in different topics like semi-supervised learning and similarity learning. To the best of our knowledge, we are the first to integrate graph-theoretical modules, carefully crafted for the problem of similarity learning and that are designed to consider contextual information, not only outperforming the other models, but also gaining a speed improvement while using a smaller number of parameters.
Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
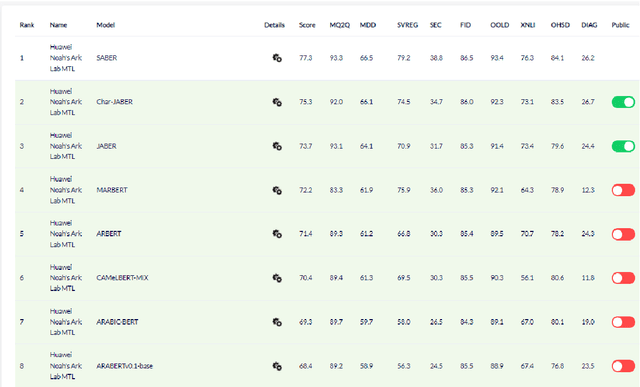
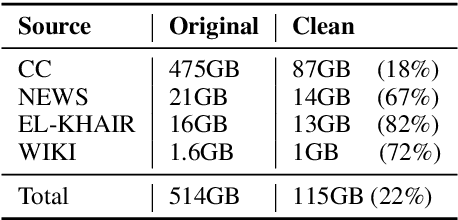
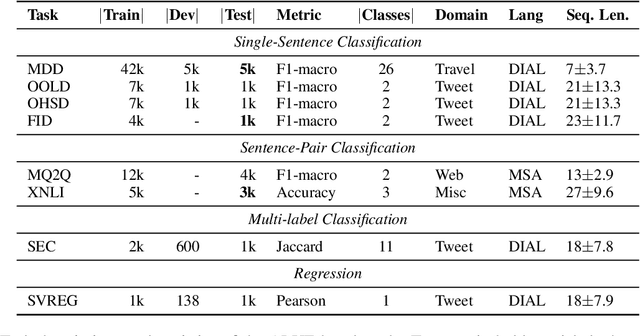
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
Decomposing neural networks as mappings of correlation functions
Feb 10, 2022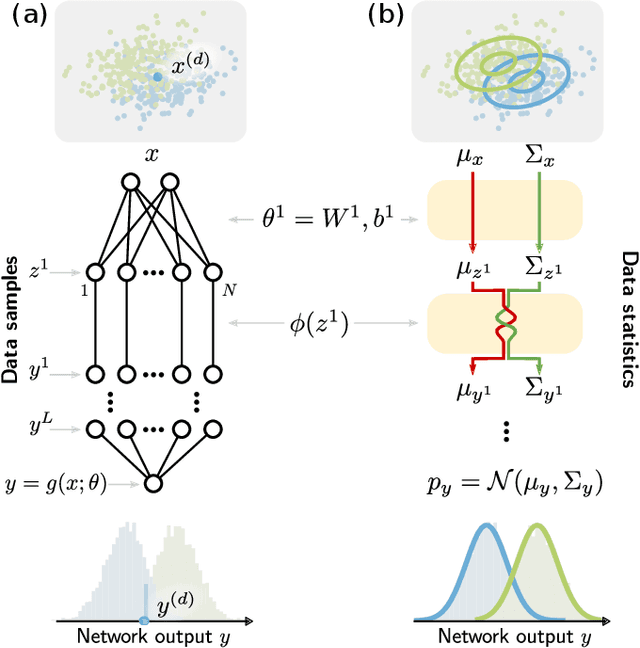
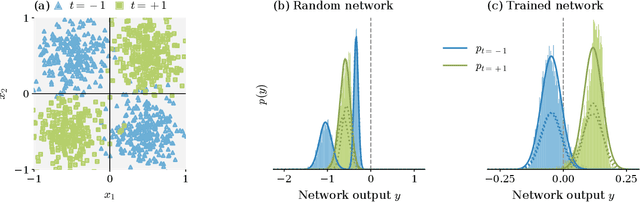
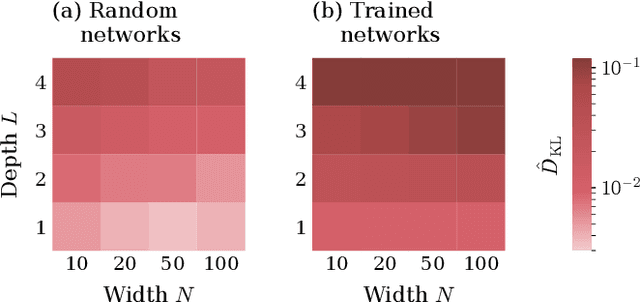
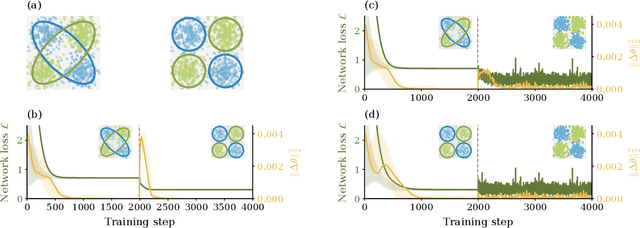
Understanding the functional principles of information processing in deep neural networks continues to be a challenge, in particular for networks with trained and thus non-random weights. To address this issue, we study the mapping between probability distributions implemented by a deep feed-forward network. We characterize this mapping as an iterated transformation of distributions, where the non-linearity in each layer transfers information between different orders of correlation functions. This allows us to identify essential statistics in the data, as well as different information representations that can be used by neural networks. Applied to an XOR task and to MNIST, we show that correlations up to second order predominantly capture the information processing in the internal layers, while the input layer also extracts higher-order correlations from the data. This analysis provides a quantitative and explainable perspective on classification.
DFTR: Depth-supervised Fusion Transformer for Salient Object Detection
Apr 11, 2022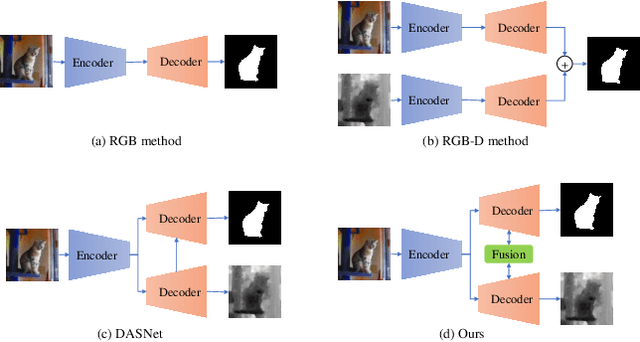
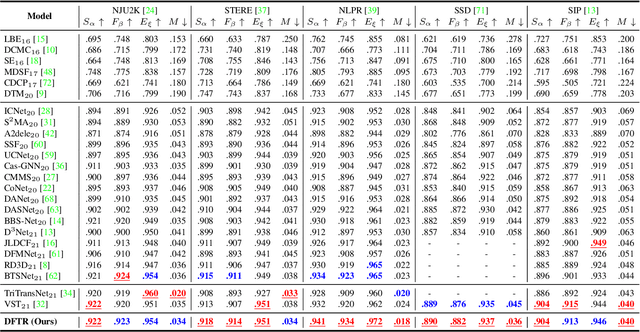
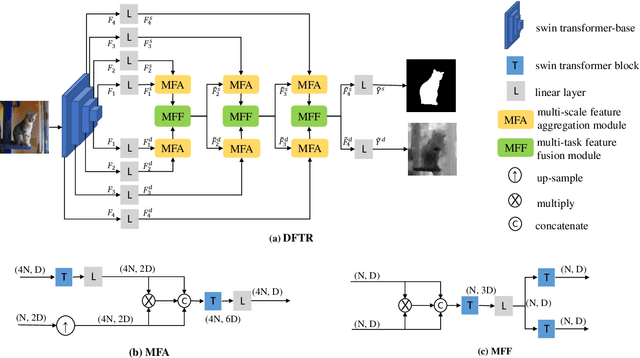
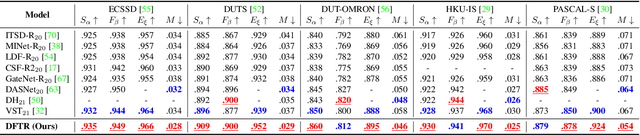
Automated salient object detection (SOD) plays an increasingly crucial role in many computer vision applications. By reformulating the depth information as supervision rather than as input, depth-supervised convolutional neural networks (CNN) have achieved promising results on both RGB and RGB-D SOD scenarios with the merits of no requirements for extra depth networks and depth inputs in the inference stage. This paper, for the first time, seeks to expand the applicability of depth supervision to the Transformer architecture. Specifically, we develop a Depth-supervised Fusion TRansformer (DFTR), to further improve the accuracy of both RGB and RGB-D SOD. The proposed DFTR involves three primary features: 1) DFTR, to the best of our knowledge, is the first pure Transformer-based model for depth-supervised SOD; 2) A multi-scale feature aggregation (MFA) module is proposed to fully exploit the multi-scale features encoded by the Swin Transformer in a coarse-to-fine manner; 3) To enable bidirectional information flow across different streams of features, a novel multi-stage feature fusion (MFF) module is further integrated into our DFTR with the emphasis on salient regions at different network learning stages. We extensively evaluate the proposed DFTR on ten benchmarking datasets. Experimental results show that our DFTR consistently outperforms the existing state-of-the-art methods for both RGB and RGB-D SOD tasks. The code and model will be made publicly available.