 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast and Structured Block-Term Tensor Decomposition For Hyperspectral Unmixing
May 08, 2022
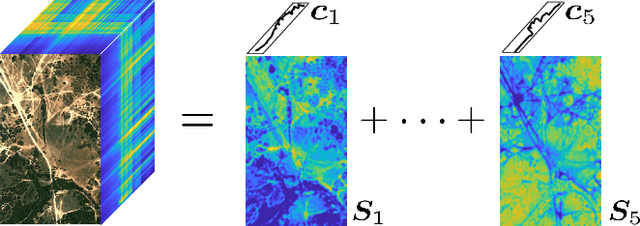
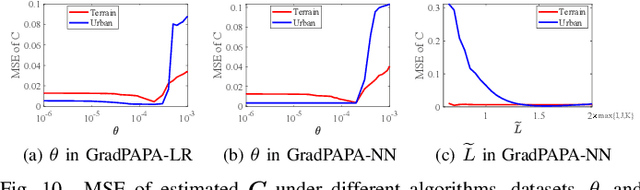
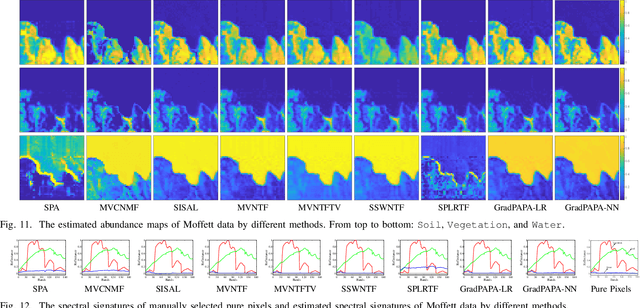
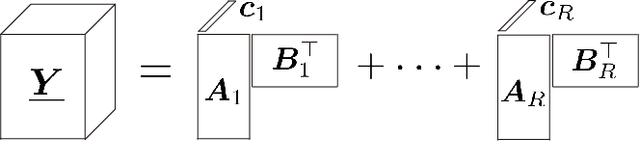
The block-term tensor decomposition model with multilinear rank-$(L_r,L_r,1)$ terms (or, the "LL1 tensor decomposition" in short) offers a valuable alternative for hyperspectral unmixing (HU) under the linear mixture model. Particularly, the LL1 decomposition ensures the endmember/abundance identifiability in scenarios where such guarantees are not supported by the classic matrix factorization (MF) approaches. However, existing LL1-based HU algorithms use a three-factor parameterization of the tensor (i.e., the hyperspectral image cube), which leads to a number of challenges including high per-iteration complexity, slow convergence, and difficulties in incorporating structural prior information. This work puts forth an LL1 tensor decomposition-based HU algorithm that uses a constrained two-factor re-parameterization of the tensor data. As a consequence, a two-block alternating gradient projection (GP)-based LL1 algorithm is proposed for HU. With carefully designed projection solvers, the GP algorithm enjoys a relatively low per-iteration complexity. Like in MF-based HU, the factors under our parameterization correspond to the endmembers and abundances. Thus, the proposed framework is natural to incorporate physics-motivated priors that arise in HU. The proposed algorithm often attains orders-of-magnitude speedup and substantial HU performance gains compared to the existing three-factor parameterization-based HU algorithms.
Masked Autoencoders for Point Cloud Self-supervised Learning
Mar 28, 2022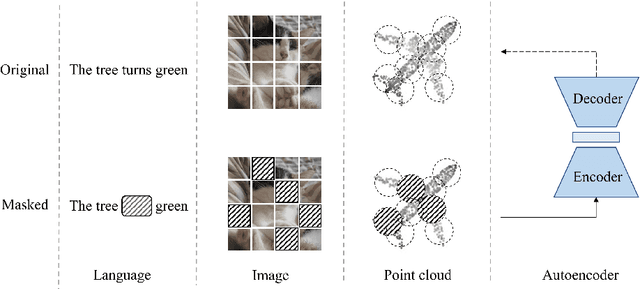
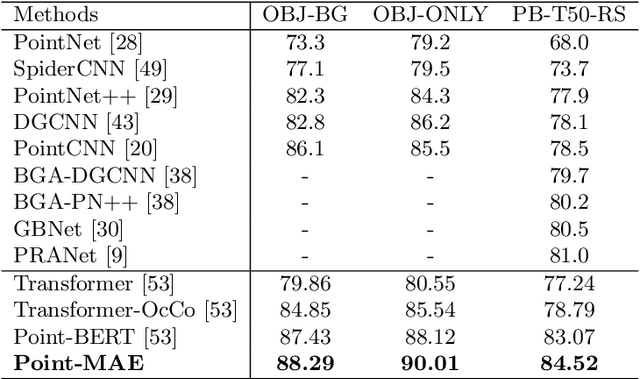
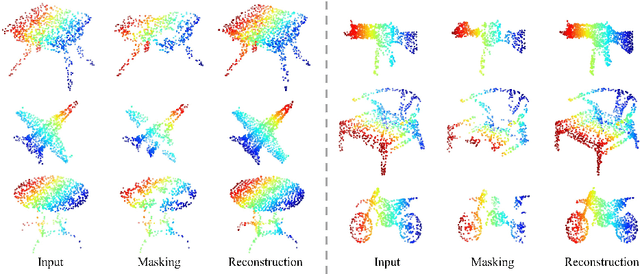
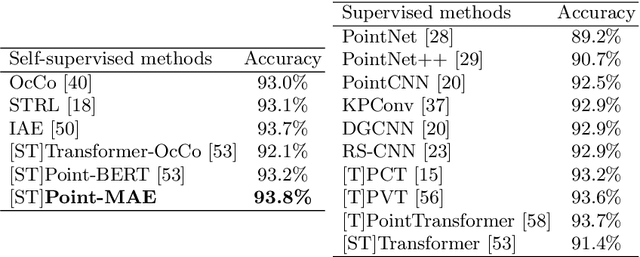
As a promising scheme of self-supervised learning, masked autoencoding has significantly advanced natural language processing and computer vision. Inspired by this, we propose a neat scheme of masked autoencoders for point cloud self-supervised learning, addressing the challenges posed by point cloud's properties, including leakage of location information and uneven information density. Concretely, we divide the input point cloud into irregular point patches and randomly mask them at a high ratio. Then, a standard Transformer based autoencoder, with an asymmetric design and a shifting mask tokens operation, learns high-level latent features from unmasked point patches, aiming to reconstruct the masked point patches. Extensive experiments show that our approach is efficient during pre-training and generalizes well on various downstream tasks. Specifically, our pre-trained models achieve 85.18% accuracy on ScanObjectNN and 94.04% accuracy on ModelNet40, outperforming all the other self-supervised learning methods. We show with our scheme, a simple architecture entirely based on standard Transformers can surpass dedicated Transformer models from supervised learning. Our approach also advances state-of-the-art accuracies by 1.5%-2.3% in the few-shot object classification. Furthermore, our work inspires the feasibility of applying unified architectures from languages and images to the point cloud.
Blind Goal-Oriented Massive Access for Future Wireless Networks
May 14, 2022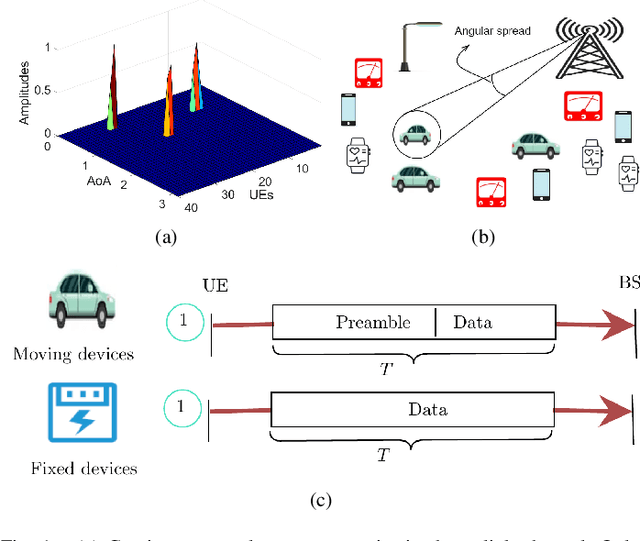
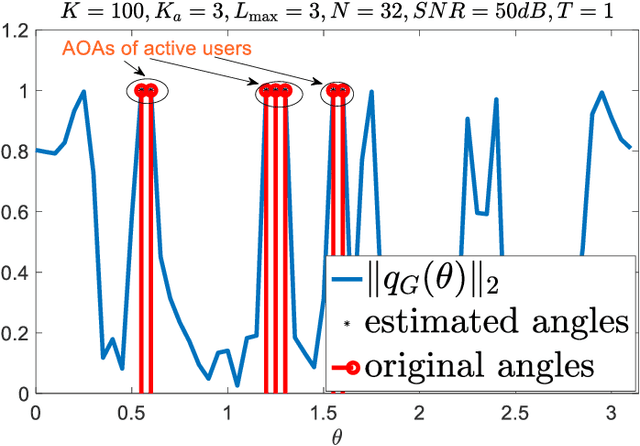
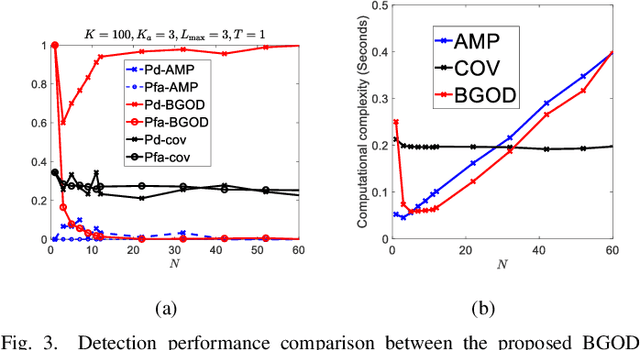
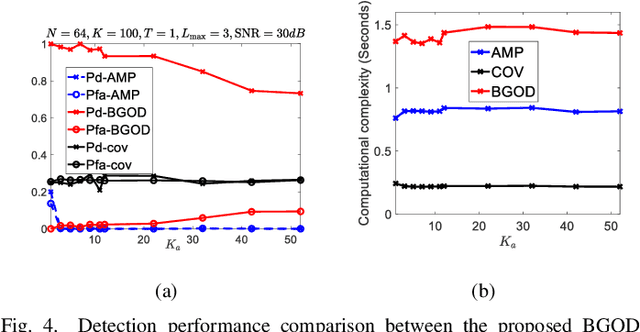
Emerging communication networks are envisioned to support massive wireless connectivity of heterogeneous devices with sporadic traffic and diverse requirements in terms of latency, reliability, and bandwidth. Providing multiple access to an increasing number of uncoordinated users and sharing the limited resources become essential in this context. In this work, we revisit the random access (RA) problem and exploit the continuous angular group sparsity feature of wireless channels to propose a novel RA strategy that provides low latency, high reliability, and massive access with limited bandwidth resources in an all-in-one package. To this end, we first design a reconstruction-free goal-oriented optimization problem, which only preserves the angular information required to identify the active devices. To solve this, we propose an alternating direction method of multipliers (ADMM) and derive closed-form expressions for each ADMM step. Then, we design a clustering algorithm that assigns the users in specific groups from which we can identify active stationary devices by their angles. For mobile devices, we propose an alternating minimization algorithm to recover their data and their channel gains simultaneously, which allows us to identify active mobile users. Simulation results show significant performance gains in terms of active user detection and false alarm probabilities as compared to state-of-the-art RA schemes, even with limited number of preambles. Moreover, unlike prior work, the performance of the proposed blind goal-oriented massive access does not depend on the number of devices.
Dynamic Focus-aware Positional Queries for Semantic Segmentation
Apr 04, 2022
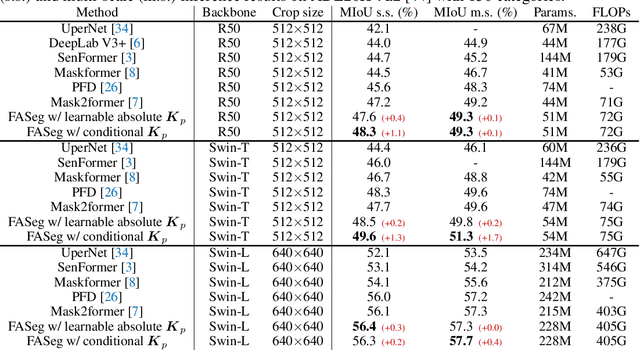
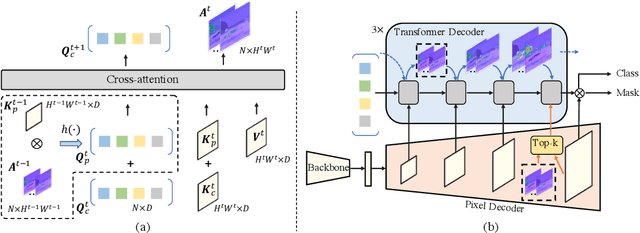
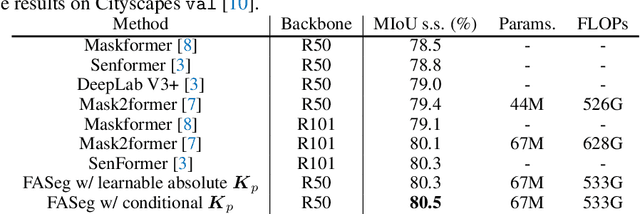
Most of the latest top semantic segmentation approaches are based on vision Transformers, particularly DETR-like frameworks, which employ a set of queries in the Transformer decoder. Each query is composed of a content query that preserves semantic information and a positional query that provides positional guidance for aggregating the query-specific context. However, the positional queries in the Transformer decoder layers are typically represented as fixed learnable weights, which often encode dataset statistics for segments and can be inaccurate for individual samples. Therefore, in this paper, we propose to generate positional queries dynamically conditioned on the cross-attention scores and the localization information of the preceding layer. By doing so, each query is aware of its previous focus, thus providing more accurate positional guidance and encouraging the cross-attention consistency across the decoder layers. In addition, we also propose an efficient way to deal with high-resolution cross-attention by dynamically determining the contextual tokens based on the low-resolution cross-attention maps to perform local relation aggregation. Our overall framework termed FASeg (Focus-Aware semantic Segmentation) provides a simple yet effective solution for semantic segmentation. Extensive experiments on ADE20K and Cityscapes show that our FASeg achieves state-of-the-art performance, e.g., obtaining 48.3% and 49.6% mIoU respectively for single-scale inference on ADE20K validation set with ResNet-50 and Swin-T backbones, and barely increases the computation consumption from Mask2former. Source code will be made publicly available at https://github.com/zip-group/FASeg.
Non-parametric Depth Distribution Modelling based Depth Inference for Multi-view Stereo
May 08, 2022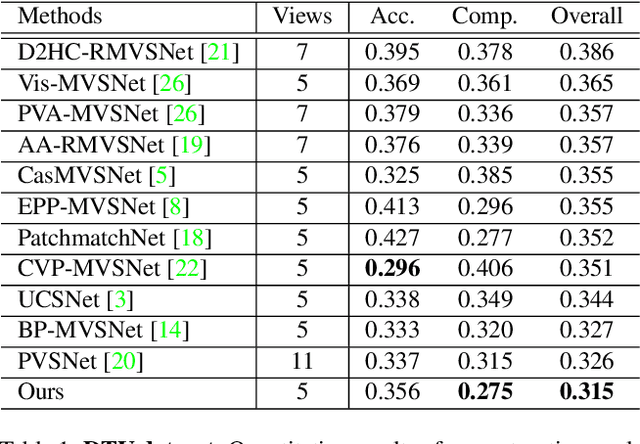
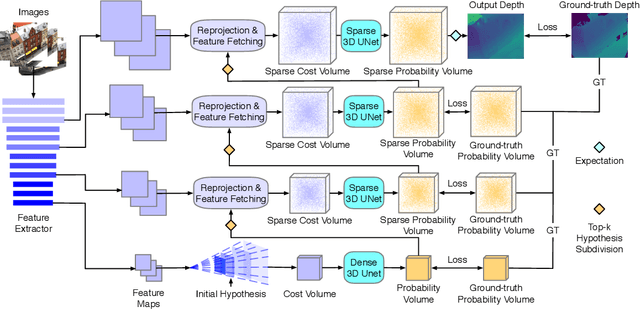
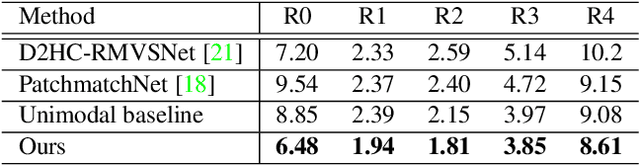
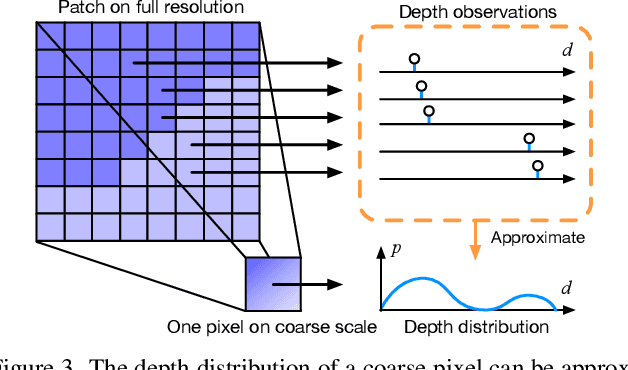
Recent cost volume pyramid based deep neural networks have unlocked the potential of efficiently leveraging high-resolution images for depth inference from multi-view stereo. In general, those approaches assume that the depth of each pixel follows a unimodal distribution. Boundary pixels usually follow a multi-modal distribution as they represent different depths; Therefore, the assumption results in an erroneous depth prediction at the coarser level of the cost volume pyramid and can not be corrected in the refinement levels leading to wrong depth predictions. In contrast, we propose constructing the cost volume by non-parametric depth distribution modeling to handle pixels with unimodal and multi-modal distributions. Our approach outputs multiple depth hypotheses at the coarser level to avoid errors in the early stage. As we perform local search around these multiple hypotheses in subsequent levels, our approach does not maintain the rigid depth spatial ordering and, therefore, we introduce a sparse cost aggregation network to derive information within each volume. We evaluate our approach extensively on two benchmark datasets: DTU and Tanks & Temples. Our experimental results show that our model outperforms existing methods by a large margin and achieves superior performance on boundary regions. Code is available at https://github.com/NVlabs/NP-CVP-MVSNet
Where and What: Driver Attention-based Object Detection
Apr 26, 2022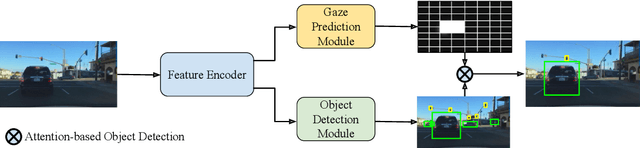

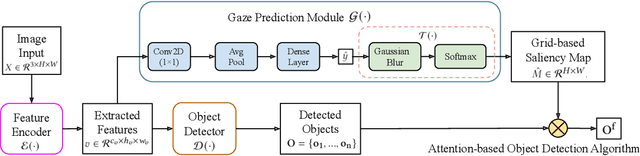

Human drivers use their attentional mechanisms to focus on critical objects and make decisions while driving. As human attention can be revealed from gaze data, capturing and analyzing gaze information has emerged in recent years to benefit autonomous driving technology. Previous works in this context have primarily aimed at predicting "where" human drivers look at and lack knowledge of "what" objects drivers focus on. Our work bridges the gap between pixel-level and object-level attention prediction. Specifically, we propose to integrate an attention prediction module into a pretrained object detection framework and predict the attention in a grid-based style. Furthermore, critical objects are recognized based on predicted attended-to areas. We evaluate our proposed method on two driver attention datasets, BDD-A and DR(eye)VE. Our framework achieves competitive state-of-the-art performance in the attention prediction on both pixel-level and object-level but is far more efficient (75.3 GFLOPs less) in computation.
* 22 pages
Application of machine learning methods to detect and classify Core images using GAN and texture recognition
Apr 21, 2022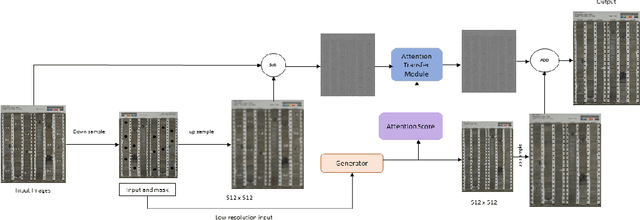

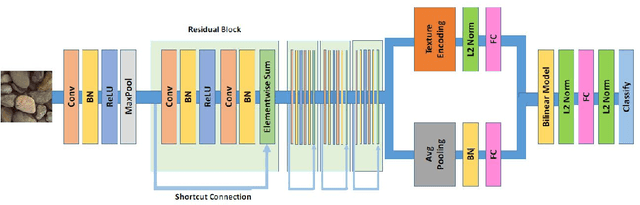
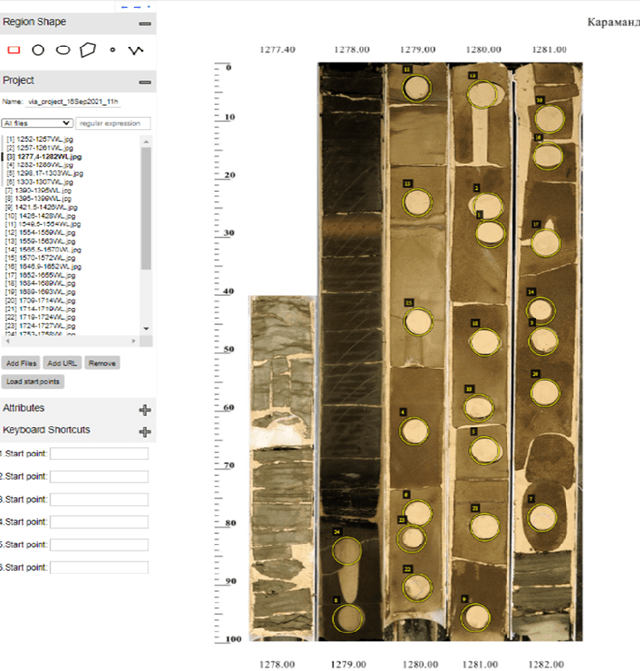
During exploration campaigns, oil companies rely heavily on drill core samples as they provide valuable geological information that helps them find important oil deposits. Traditional core logging techniques are laborious and subjective. Core imaging, a new technique in the oil industry, is used to supplement analysis by rapidly characterising large quantities of drill cores in a nondestructive and noninvasive manner. In this paper, we will present the problem of core detection and classification. The first problem is detecting the cores and segmenting the holes in images by using Faster RCNN and Mask RCNN models respectively. The second problem is filling the hole in the core image by applying the Generative adversarial network(GAN) technique and using Contextual Residual Aggregation(CRA) which creates high frequency residual for missing contents in images. And finally applying Texture recognition models for the classification of core images.
Is Information Theory Inherently a Theory of Causation?
Oct 19, 2020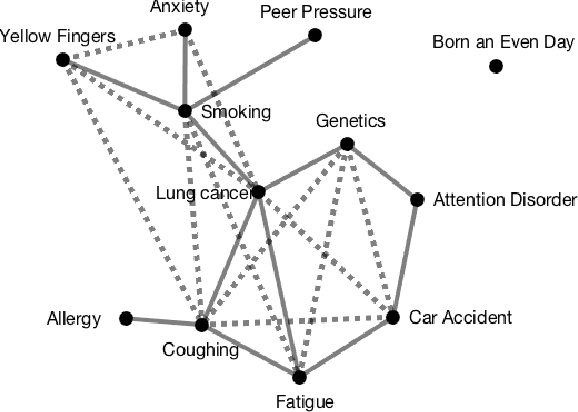
Information theory gives rise to a novel method for causal skeleton discovery by expressing associations between variables as tensors. This tensor-based approach reduces the dimensionality of the data needed to test for conditional independence. For systems comprising three variables, this means that the causal skeleton can be determined using the tensors of the pair-wise associations.
Graph Adversarial Networks: Protecting Information against Adversarial Attacks
Oct 07, 2020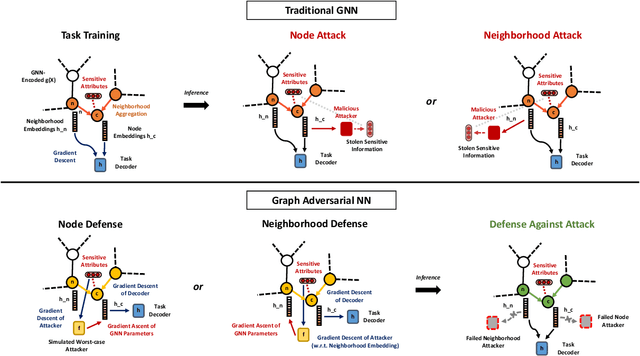
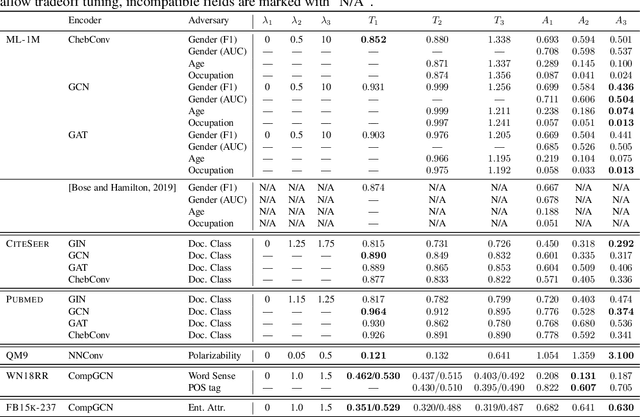
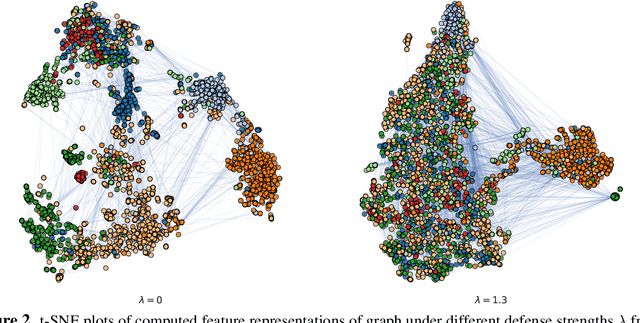
We study the problem of protecting information when learning with graph-structured data. While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representational learning in many applications, the neighborhood aggregation paradigm exposes additional vulnerabilities to attackers seeking to extract node-level information about sensitive attributes. To counter this, we propose a minimax game between the desired GNN encoder and the worst-case attacker. The resulting adversarial training creates a strong defense against inference attacks, while only suffering a small loss in task performance. We analyze the effectiveness of our framework against a worst-case adversary, and characterize the trade-off between predictive accuracy and adversarial defense. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders. Our code is available at https://github.com/liaopeiyuan/GAL.
Low Resolution Information Also Matters: Learning Multi-Resolution Representations for Person Re-Identification
May 26, 2021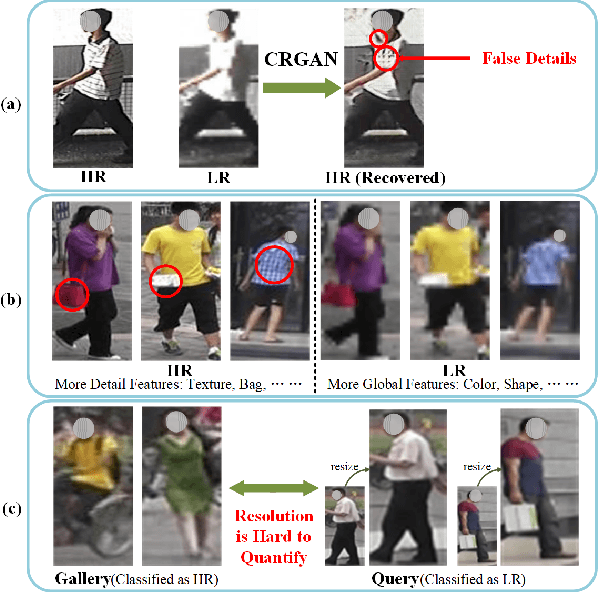
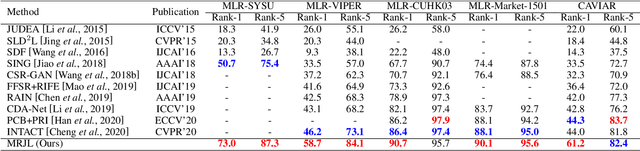
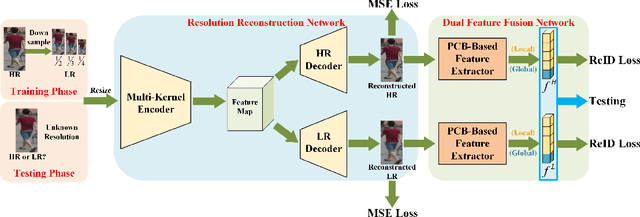
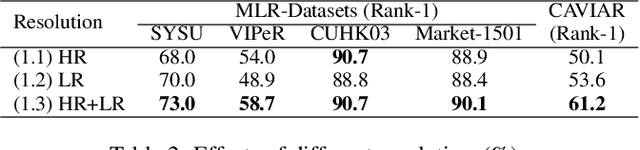
As a prevailing task in video surveillance and forensics field, person re-identification (re-ID) aims to match person images captured from non-overlapped cameras. In unconstrained scenarios, person images often suffer from the resolution mismatch problem, i.e., \emph{Cross-Resolution Person Re-ID}. To overcome this problem, most existing methods restore low resolution (LR) images to high resolution (HR) by super-resolution (SR). However, they only focus on the HR feature extraction and ignore the valid information from original LR images. In this work, we explore the influence of resolutions on feature extraction and develop a novel method for cross-resolution person re-ID called \emph{\textbf{M}ulti-Resolution \textbf{R}epresentations \textbf{J}oint \textbf{L}earning} (\textbf{MRJL}). Our method consists of a Resolution Reconstruction Network (RRN) and a Dual Feature Fusion Network (DFFN). The RRN uses an input image to construct a HR version and a LR version with an encoder and two decoders, while the DFFN adopts a dual-branch structure to generate person representations from multi-resolution images. Comprehensive experiments on five benchmarks verify the superiority of the proposed MRJL over the relevent state-of-the-art methods.