 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking
Apr 05, 2022
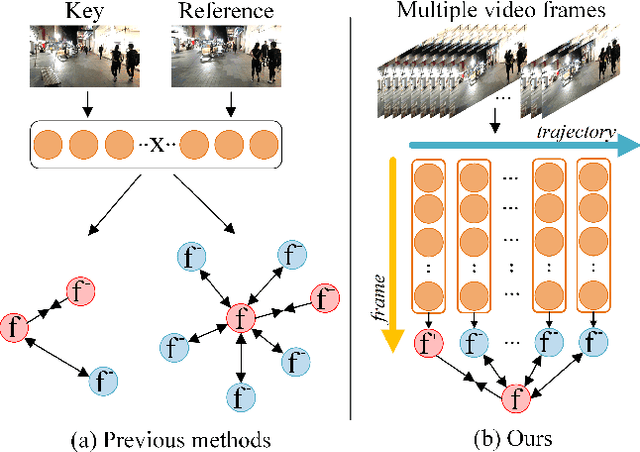
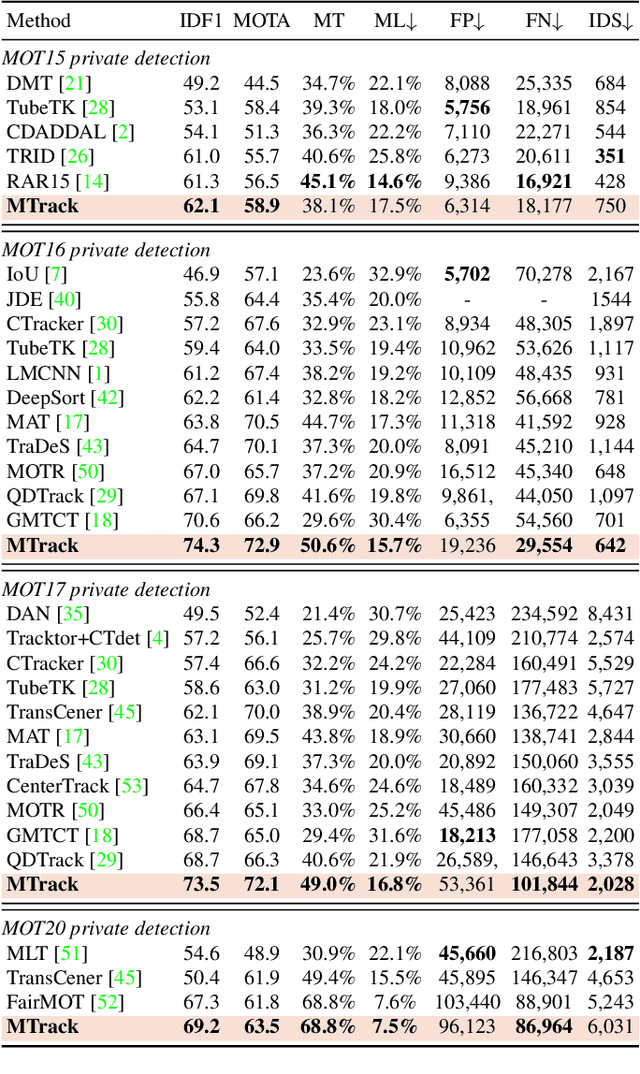
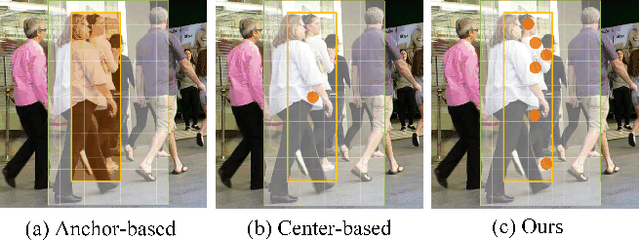
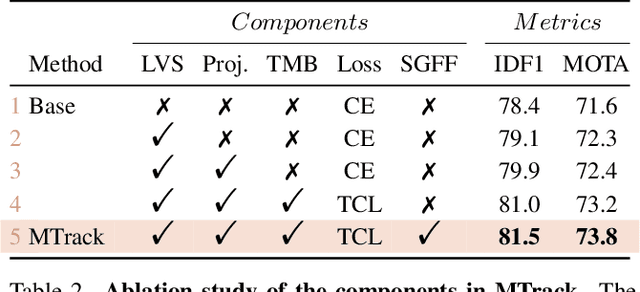
Discriminative representation is crucial for the association step in multi-object tracking. Recent work mainly utilizes features in single or neighboring frames for constructing metric loss and empowering networks to extract representation of targets. Although this strategy is effective, it fails to fully exploit the information contained in a whole trajectory. To this end, we propose a strategy, namely multi-view trajectory contrastive learning, in which each trajectory is represented as a center vector. By maintaining all the vectors in a dynamically updated memory bank, a trajectory-level contrastive loss is devised to explore the inter-frame information in the whole trajectories. Besides, in this strategy, each target is represented as multiple adaptively selected keypoints rather than a pre-defined anchor or center. This design allows the network to generate richer representation from multiple views of the same target, which can better characterize occluded objects. Additionally, in the inference stage, a similarity-guided feature fusion strategy is developed for further boosting the quality of the trajectory representation. Extensive experiments have been conducted on MOTChallenge to verify the effectiveness of the proposed techniques. The experimental results indicate that our method has surpassed preceding trackers and established new state-of-the-art performance.
BEVerse: Unified Perception and Prediction in Birds-Eye-View for Vision-Centric Autonomous Driving
May 19, 2022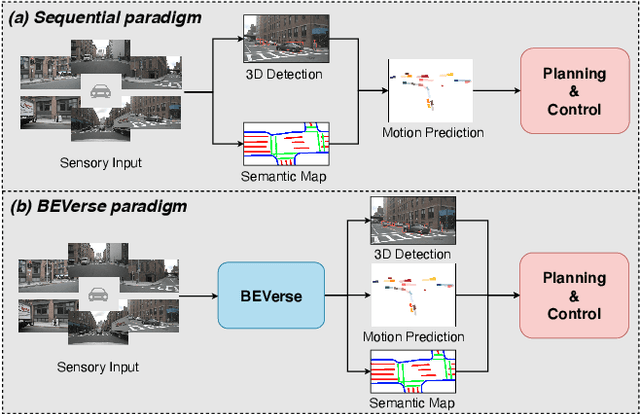

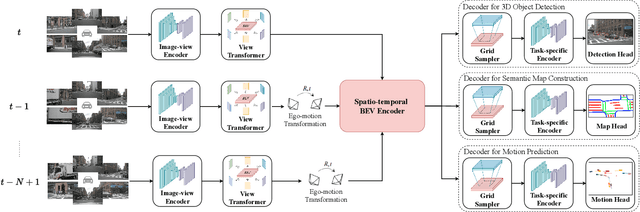

In this paper, we present BEVerse, a unified framework for 3D perception and prediction based on multi-camera systems. Unlike existing studies focusing on the improvement of single-task approaches, BEVerse features in producing spatio-temporal Birds-Eye-View (BEV) representations from multi-camera videos and jointly reasoning about multiple tasks for vision-centric autonomous driving. Specifically, BEVerse first performs shared feature extraction and lifting to generate 4D BEV representations from multi-timestamp and multi-view images. After the ego-motion alignment, the spatio-temporal encoder is utilized for further feature extraction in BEV. Finally, multiple task decoders are attached for joint reasoning and prediction. Within the decoders, we propose the grid sampler to generate BEV features with different ranges and granularities for different tasks. Also, we design the method of iterative flow for memory-efficient future prediction. We show that the temporal information improves 3D object detection and semantic map construction, while the multi-task learning can implicitly benefit motion prediction. With extensive experiments on the nuScenes dataset, we show that the multi-task BEVerse outperforms existing single-task methods on 3D object detection, semantic map construction, and motion prediction. Compared with the sequential paradigm, BEVerse also favors in significantly improved efficiency. The code and trained models will be released at https://github.com/zhangyp15/BEVerse.
Enhancing deep neural networks with morphological information
Nov 24, 2020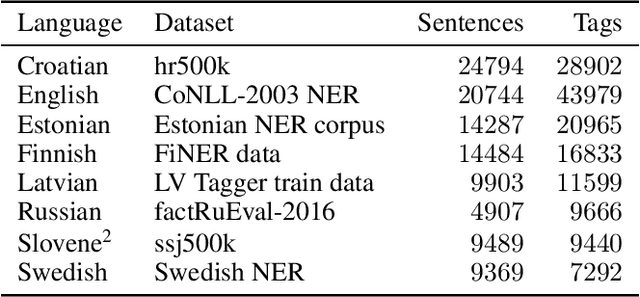
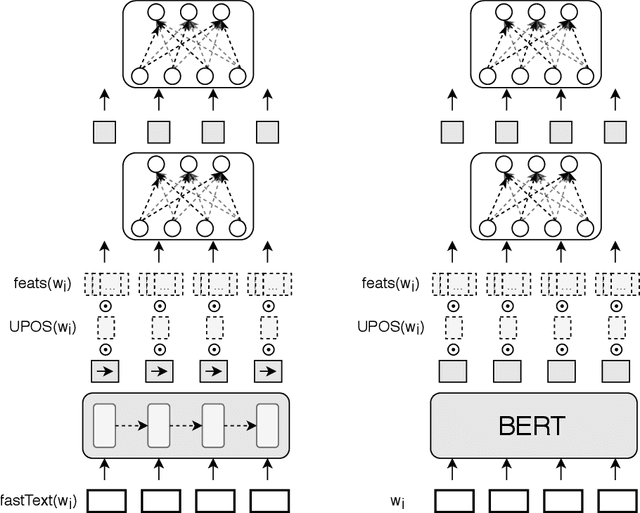
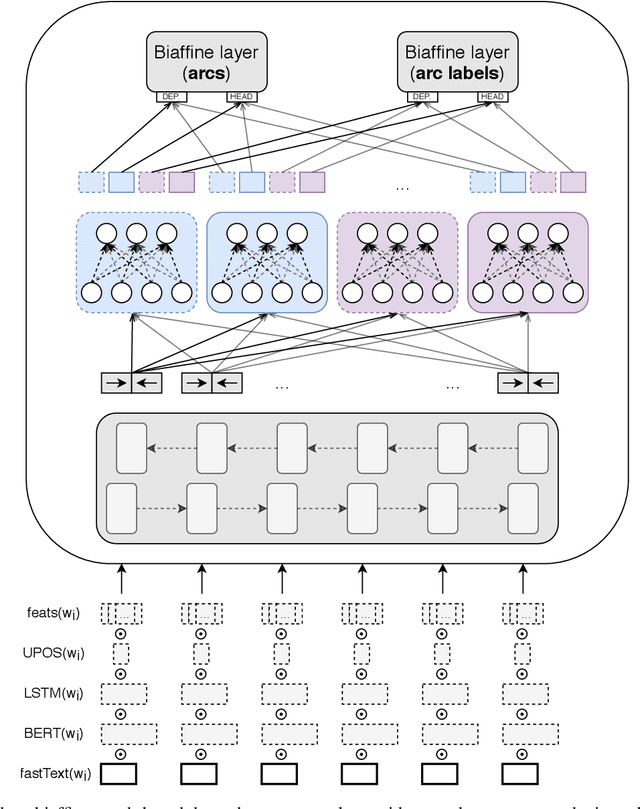
Currently, deep learning approaches are superior in natural language processing due to their ability to extract informative features and patterns from languages. Two most successful neural architectures are LSTM and transformers, the latter mostly used in the form of large pretrained language models such as BERT. While cross-lingual approaches are on the rise, a vast majority of current natural language processing techniques is designed and applied to English, and less-resourced languages are lagging behind. In morphologically rich languages, plenty of information is conveyed through changes in morphology, e.g., through different prefixes and suffixes modifying stems of words. The existing neural approaches do not explicitly use the information on word morphology. We analyze the effect of adding morphological features to LSTM and BERT models. We use three tasks available in many less-resourced languages: named entity recognition (NER), dependency parsing (DP), and comment filtering (CF). We construct sensible baselines involving LSTM and BERT models, which we adjust by adding additional input in the form of part of speech (POS) tags and universal features. We compare the obtained models across subsets of eight languages. Our results suggest that adding morphological features has mixed effects depending on the quality of features and the task. The features improve the performance of LSTM-based models on the NER and DP tasks, while they do not benefit the performance on the CF task. For BERT-based models, the added morphological features only improve the performance on DP when they are of high quality, while they do not show any practical improvement when they are predicted. As in NER and CF datasets manually checked features are not available, we only experiment with the predicted morphological features and find that they do not cause any practical improvement in performance.
Hybrid Active and Passive Sensing for SLAM in Wireless Communication Systems
Mar 19, 2022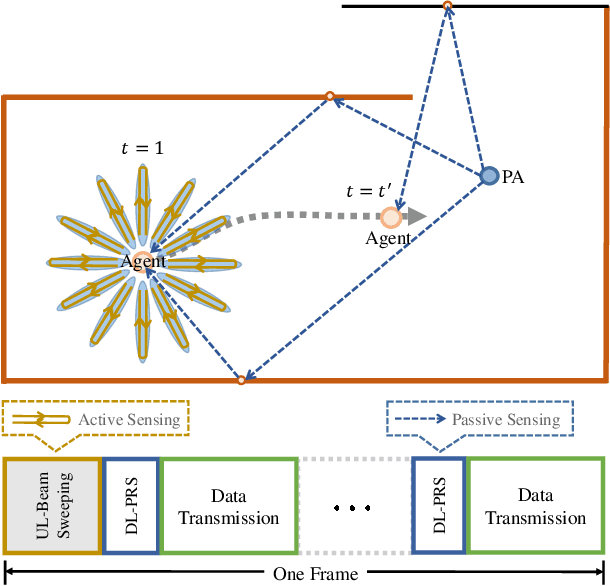
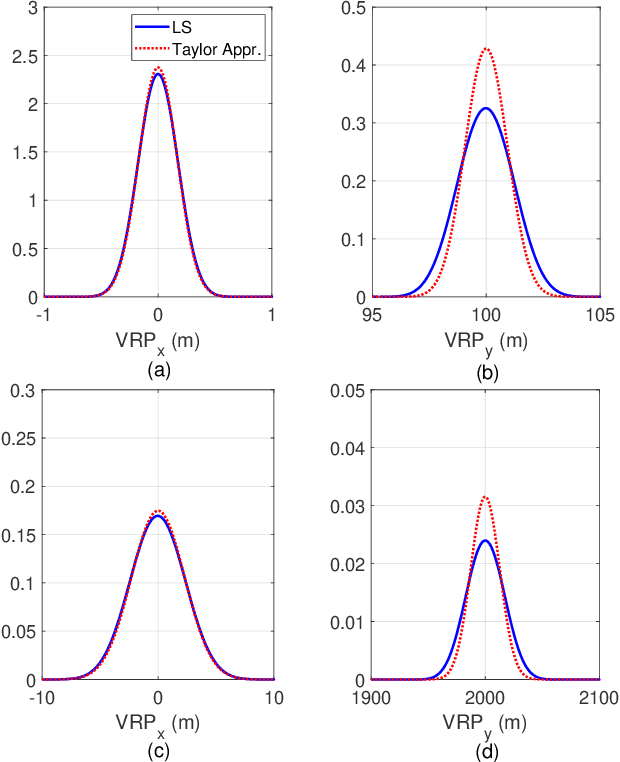
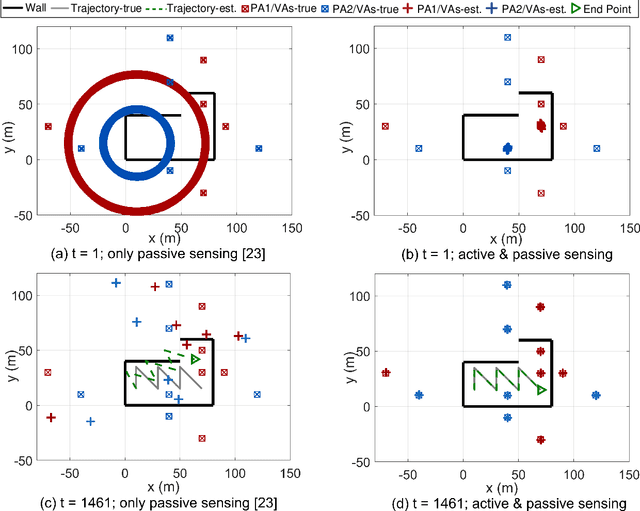
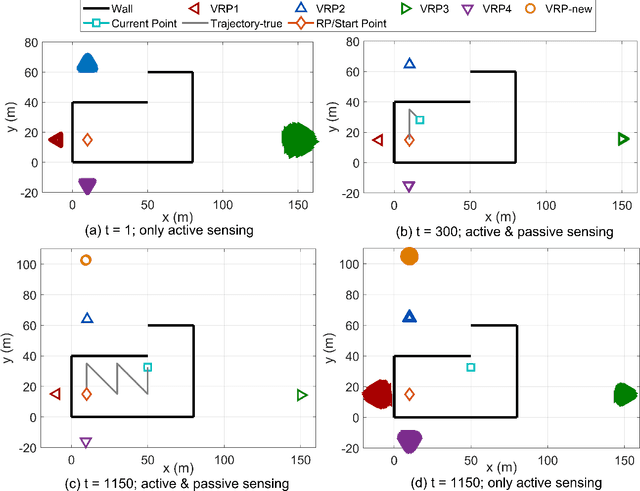
Integrating sensing functions into future mobile equipment has become an important trend. Realizing different types of sensing and achieving mutual enhancement under the existing communication hardware architecture is a crucial challenge in realizing the deep integration of sensing and communication. In the 5G New Radio context, active sensing can be performed through uplink beam sweeping on the user equipment (UE) side to observe the surrounding environment. In addition, the UE can perform passive sensing through downlink channel estimation to measure the multipath component (MPC) information. This study is the first to develop a hybrid simultaneous localization and mapping (SLAM) mechanism that combines active and passive sensing, in which mutual enhancement between the two sensing modes is realized in communication systems. Specifically, we first establish a common feature associated with the reflective surface to bridge active and passive sensing, thus enabling information fusion. Based on the common feature, we can attain physical anchor initialization through MPC with the assistance of active sensing. Then, we extend the classic probabilistic data association SLAM mechanism to achieve UE localization and continuously refine the physical anchor and target reflections through the subsequent passive sensing. Numerical results show that the proposed hybrid active and passive sensing-based SLAM mechanism can work successfully in tricky scenarios without any prior information on the floor plan, anchors, or agents. Moreover, the proposed algorithm demonstrates significant performance gains compared with active or passive sensing only mechanisms.
Masked Summarization to Generate Factually Inconsistent Summaries for Improved Factual Consistency Checking
May 04, 2022
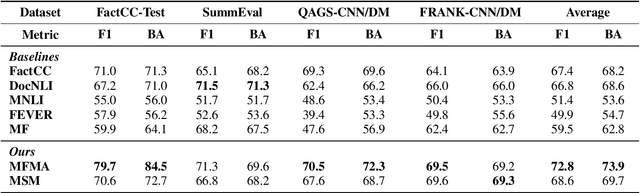
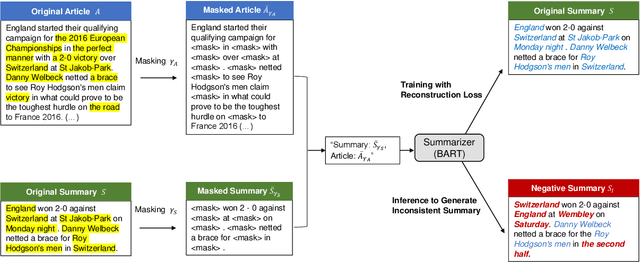
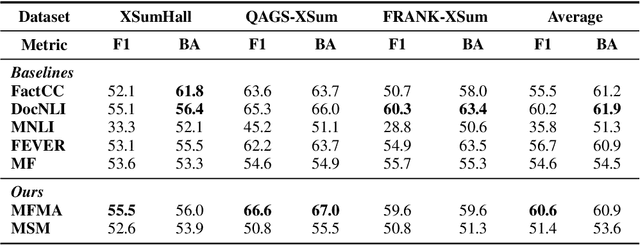
Despite the recent advances in abstractive summarization systems, it is still difficult to determine whether a generated summary is factual consistent with the source text. To this end, the latest approach is to train a factual consistency classifier on factually consistent and inconsistent summaries. Luckily, the former is readily available as reference summaries in existing summarization datasets. However, generating the latter remains a challenge, as they need to be factually inconsistent, yet closely relevant to the source text to be effective. In this paper, we propose to generate factually inconsistent summaries using source texts and reference summaries with key information masked. Experiments on seven benchmark datasets demonstrate that factual consistency classifiers trained on summaries generated using our method generally outperform existing models and show a competitive correlation with human judgments. We also analyze the characteristics of the summaries generated using our method. We will release the pre-trained model and the code at https://github.com/hwanheelee1993/MFMA.
Estimating informativeness of samples with Smooth Unique Information
Jan 17, 2021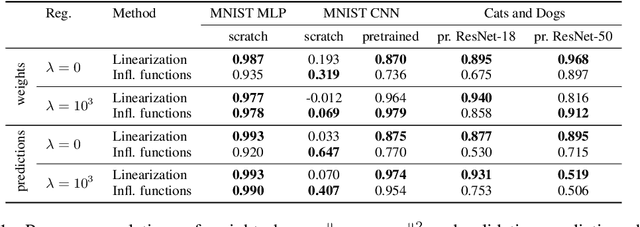

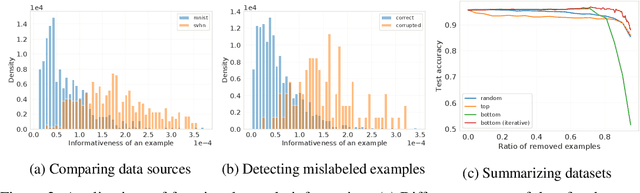
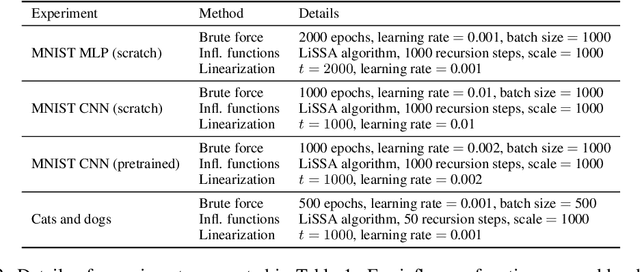
We define a notion of information that an individual sample provides to the training of a neural network, and we specialize it to measure both how much a sample informs the final weights and how much it informs the function computed by the weights. Though related, we show that these quantities have a qualitatively different behavior. We give efficient approximations of these quantities using a linearized network and demonstrate empirically that the approximation is accurate for real-world architectures, such as pre-trained ResNets. We apply these measures to several problems, such as dataset summarization, analysis of under-sampled classes, comparison of informativeness of different data sources, and detection of adversarial and corrupted examples. Our work generalizes existing frameworks but enjoys better computational properties for heavily over-parametrized models, which makes it possible to apply it to real-world networks.
Efficient Classification of Long Documents Using Transformers
Mar 21, 2022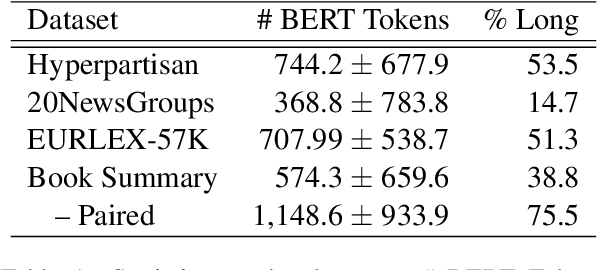
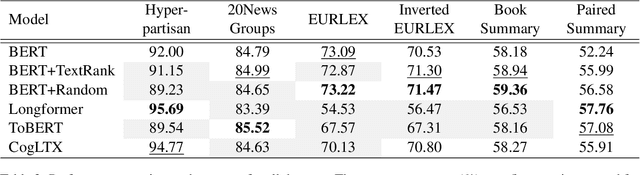
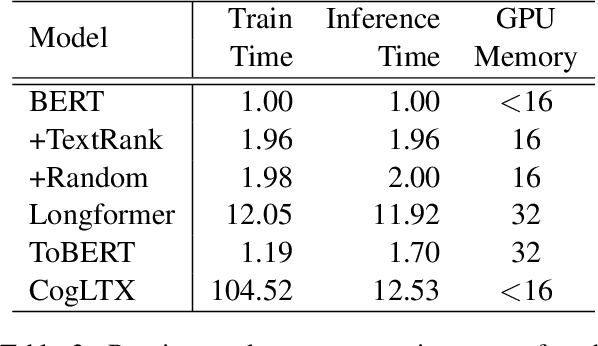
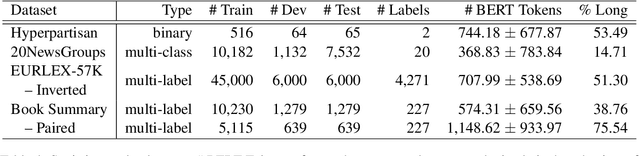
Several methods have been proposed for classifying long textual documents using Transformers. However, there is a lack of consensus on a benchmark to enable a fair comparison among different approaches. In this paper, we provide a comprehensive evaluation of the relative efficacy measured against various baselines and diverse datasets -- both in terms of accuracy as well as time and space overheads. Our datasets cover binary, multi-class, and multi-label classification tasks and represent various ways information is organized in a long text (e.g. information that is critical to making the classification decision is at the beginning or towards the end of the document). Our results show that more complex models often fail to outperform simple baselines and yield inconsistent performance across datasets. These findings emphasize the need for future studies to consider comprehensive baselines and datasets that better represent the task of long document classification to develop robust models.
Measuring Information Propagation in Literary Social Networks
Apr 29, 2020
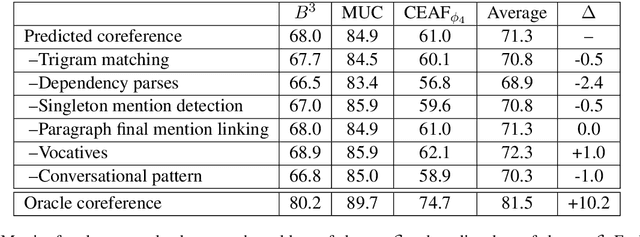
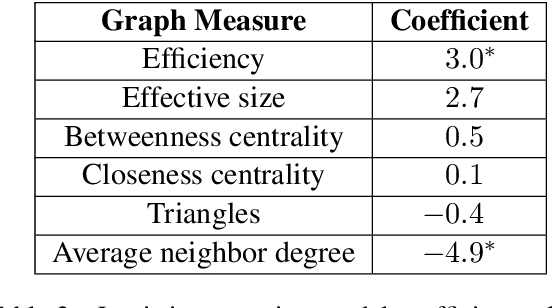
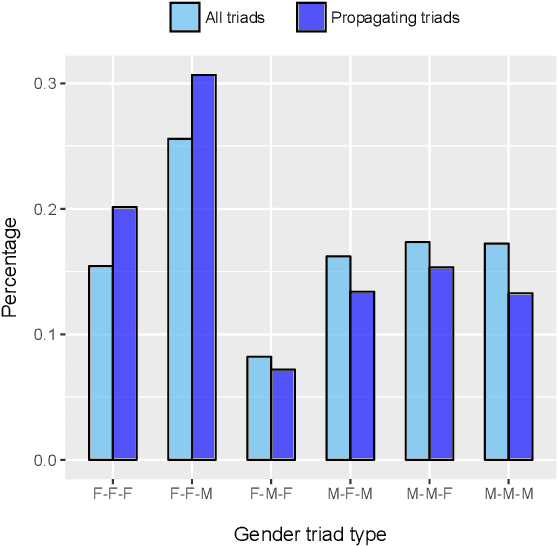
We present the task of modeling information propagation in literature, in which we seek to identify pieces of information passing from character A to character B to character C, only given a description of their activity in text. We describe a new pipeline for measuring information propagation in this domain and publish a new dataset for speaker attribution, enabling the evaluation of an important component of this pipeline on a wider range of literary texts than previously studied. Using this pipeline, we analyze the dynamics of information propagation in over 5,000 works of fiction, finding that information flows through characters that fill structural holes connecting different communities, and that characters who are women are depicted as filling this role much more frequently than characters who are men.
EqVIO: An Equivariant Filter for Visual Inertial Odometry
May 04, 2022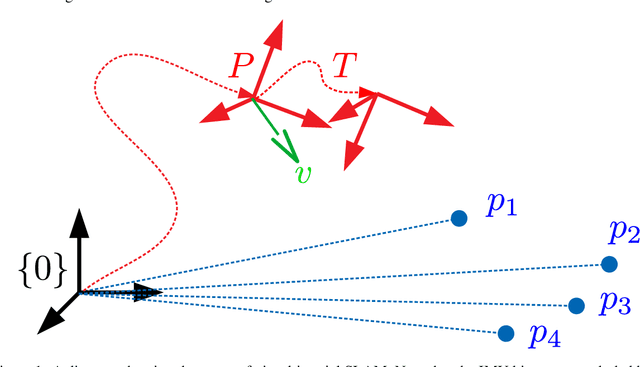
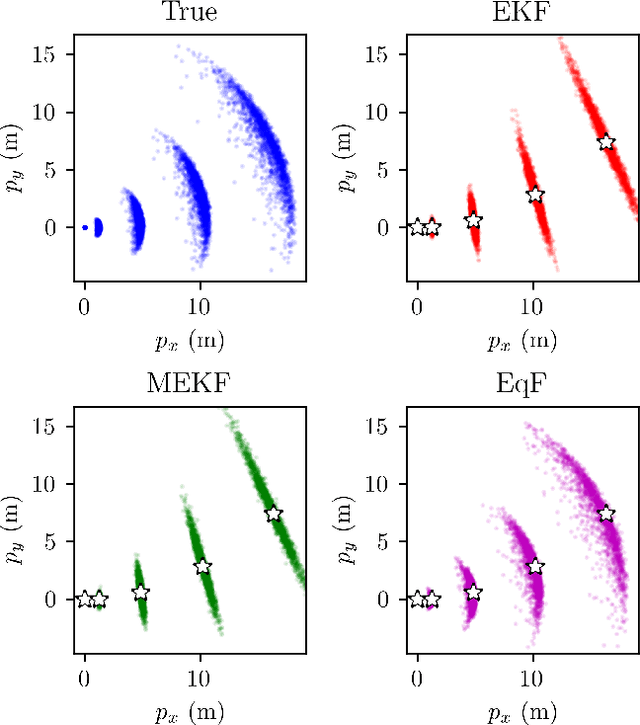
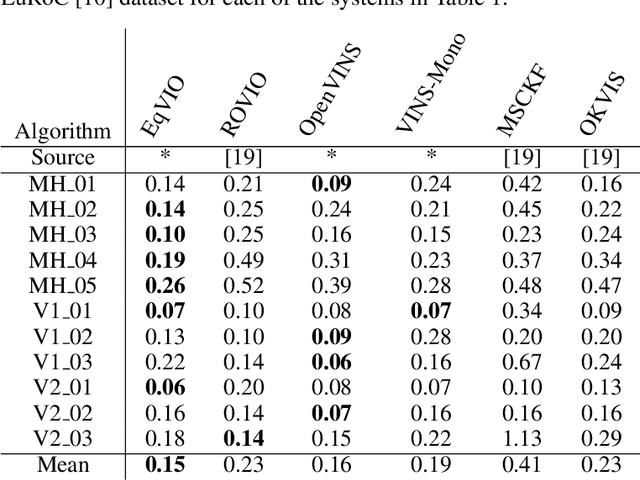
Visual Inertial Odometry (VIO) is the problem of estimating a robot's trajectory by combining information from an inertial measurement unit (IMU) and a camera, and is of great interest to the robotics community. This paper develops a novel Lie group symmetry for the VIO problem and applies the recently proposed equivariant filter. The symmetry is shown to be compatible with the invariance of the VIO reference frame, lead to exact linearisation of bias-free IMU dynamics, and provide equivariance of the visual measurement function. As a result, the equivariant filter (EqF) based on this Lie group is a consistent estimator for VIO with lower linearisation error in the propagation of state dynamics and a higher order equivariant output approximation than standard formulations. Experimental results on the popular EuRoC and UZH-FPV datasets demonstrate that the proposed system outperforms other state-of-the-art VIO algorithms in terms of both speed and accuracy.
Network Traffic Anomaly Detection Method Based on Multi scale Residual Feature
May 08, 2022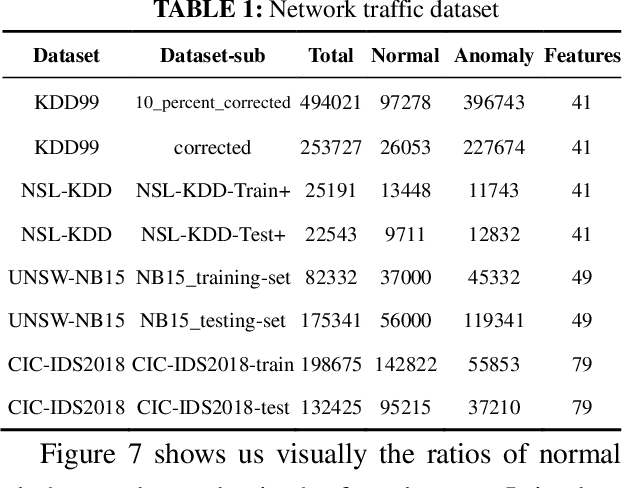
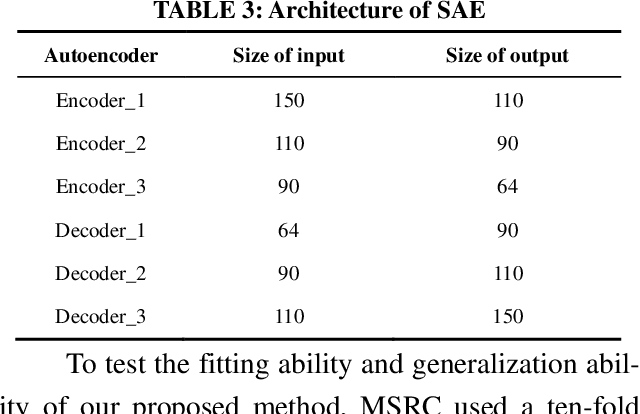
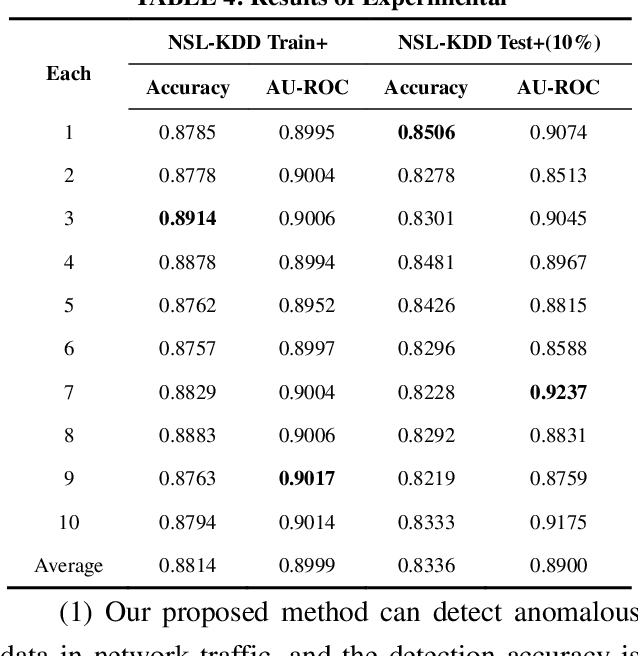
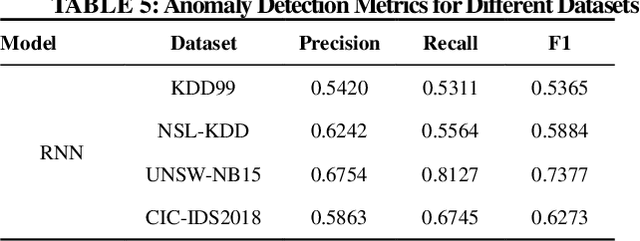
To address the problem that traditional network traffic anomaly detection algorithms do not suffi-ciently mine potential features in long time domain, an anomaly detection method based on mul-ti-scale residual features of network traffic is proposed. The original traffic is divided into subse-quences of different time spans using sliding windows, and each subsequence is decomposed and reconstructed into data sequences of different levels using wavelet transform technique; the stacked autoencoder (SAE) constructs similar feature space using normal network traffic, and gen-erates reconstructed error vector using the difference between reconstructed samples and input samples in the similar feature space; the multi-path residual group is used to learn reconstructed error The traffic classification is completed by a lightweight classifier. The experimental results show that the detection performance of the proposed method for anomalous network traffic is sig-nificantly improved compared with traditional methods; it confirms that the longer time span and more S transformation scales have positive effects on discovering potential diversity information in the original network traffic.