 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From MIM-Based GAN to Anomaly Detection:Event Probability Influence on Generative Adversarial Networks
Mar 25, 2022
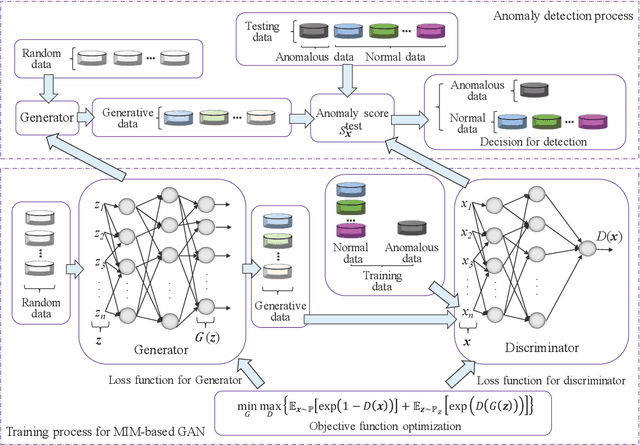
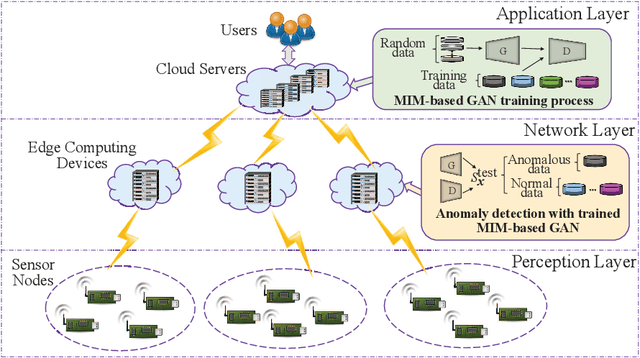
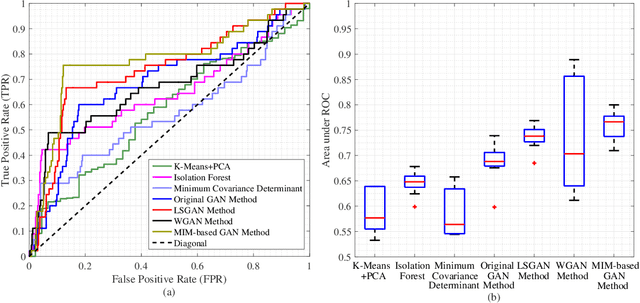
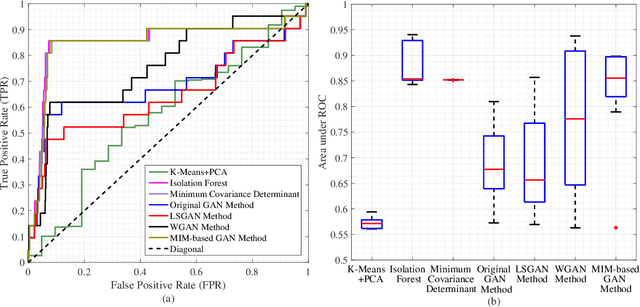
In order to introduce deep learning technologies into anomaly detection, Generative Adversarial Networks (GANs) are considered as important roles in the algorithm design and realistic applications. In terms of GANs, event probability reflected in the objective function, has an impact on the event generation which plays a crucial part in GAN-based anomaly detection. The information metric, e.g. Kullback-Leibler divergence in the original GAN, makes the objective function have different sensitivity on different event probability, which provides an opportunity to refine GAN-based anomaly detection by influencing data generation. In this paper, we introduce the exponential information metric into the GAN, referred to as MIM-based GAN, whose superior characteristics on data generation are discussed in theory. Furthermore, we propose an anomaly detection method with MIM-based GAN, as well as explain its principle for the unsupervised learning case from the viewpoint of probability event generation. Since this method is promising to detect anomalies in Internet of Things (IoT), such as environmental, medical and biochemical outliers, we make use of several datasets from the online ODDS repository to evaluate its performance and compare it with other methods.
Quantum Image Processing
Mar 01, 2022
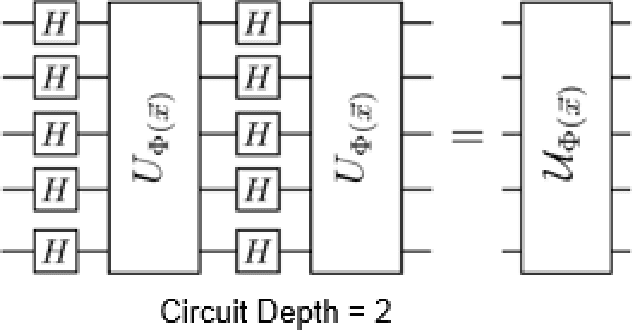
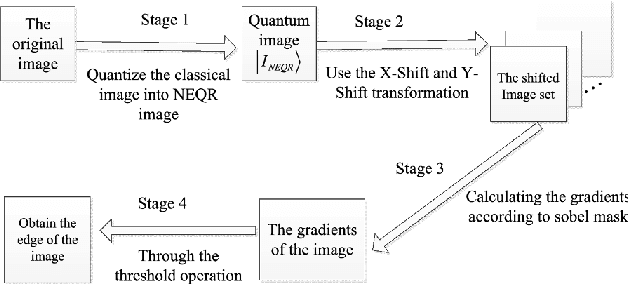
Image processing is popular in our daily life because of the need to extract essential information from our 3D world, including a variety of applications in widely separated fields like bio-medicine, economics, entertainment, and industry. The nature of visual information, algorithm complexity, and the representation of 3D scenes in 2D spaces are all popular research topics. In particular, the rapidly increasing volume of image data as well as increasingly challenging computational tasks have become important driving forces for further improving the efficiency of image processing and analysis. Since the concept of quantum computing was proposed by Feynman in 1982, many achievements have shown that quantum computing has dramatically improved computational efficiency [1]. Quantum information processing exploit quantum mechanical properties, such as quantum superposition, entanglement and parallelism, and effectively accelerate many classical problems like factoring large numbers, searching an unsorted database, Boson sampling, quantum simulation, solving linear systems of equations, and machine learning. These unique quantum properties may also be used to speed up signal and data processing. In quantum image processing, quantum image representation plays a key role, which substantively determines the kinds of processing tasks and how well they can be performed.
TransFusion: Multi-view Divergent Fusion for Medical Image Segmentation with Transformers
Mar 21, 2022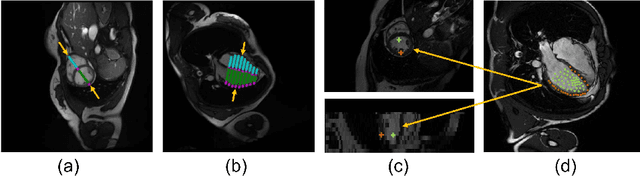
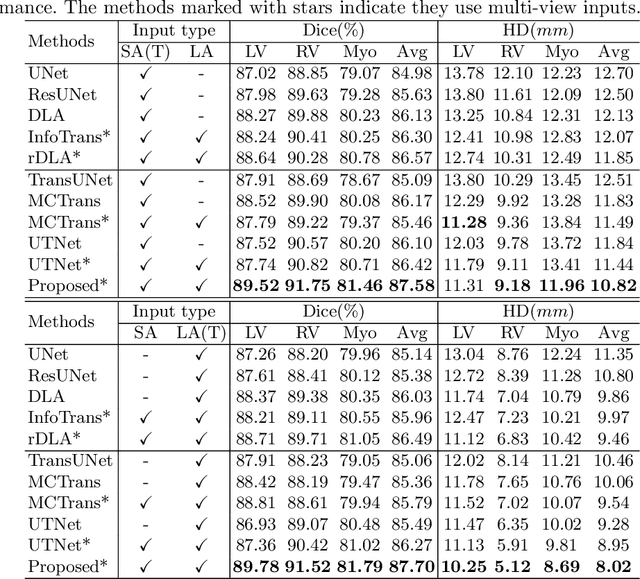
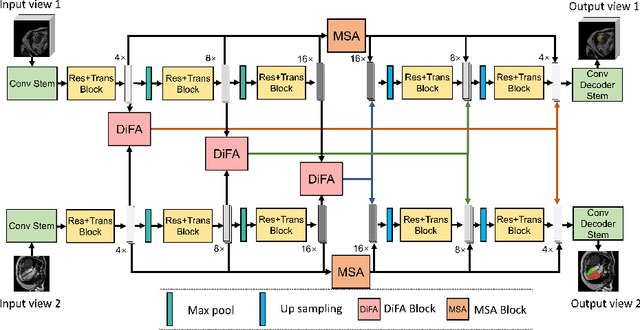
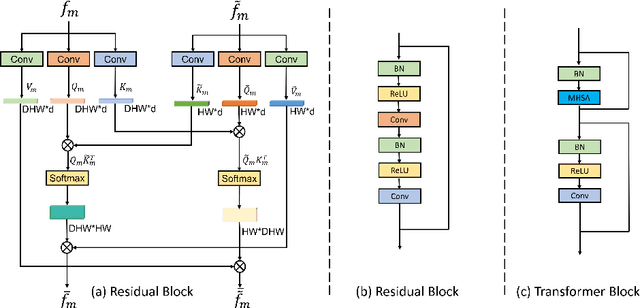
Combining information from multi-view images is crucial to improve the performance and robustness of automated methods for disease diagnosis. However, due to the non-alignment characteristics of multi-view images, building correlation and data fusion across views largely remain an open problem. In this study, we present TransFusion, a Transformer-based architecture to merge divergent multi-view imaging information using convolutional layers and powerful attention mechanisms. In particular, the Divergent Fusion Attention (DiFA) module is proposed for rich cross-view context modeling and semantic dependency mining, addressing the critical issue of capturing long-range correlations between unaligned data from different image views. We further propose the Multi-Scale Attention (MSA) to collect global correspondence of multi-scale feature representations. We evaluate TransFusion on the Multi-Disease, Multi-View \& Multi-Center Right Ventricular Segmentation in Cardiac MRI (M\&Ms-2) challenge cohort. TransFusion demonstrates leading performance against the state-of-the-art methods and opens up new perspectives for multi-view imaging integration towards robust medical image segmentation.
Exploring Dual Encoder Architectures for Question Answering
Apr 14, 2022
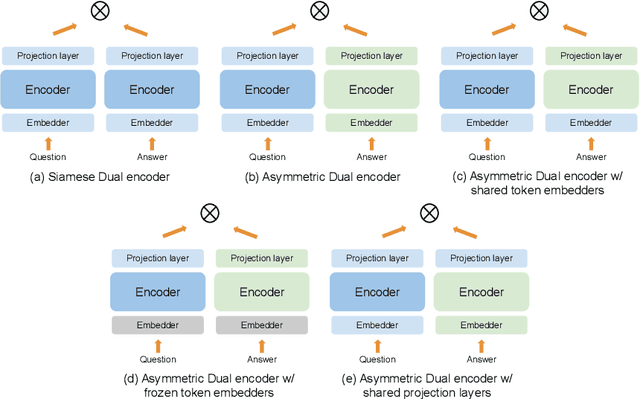
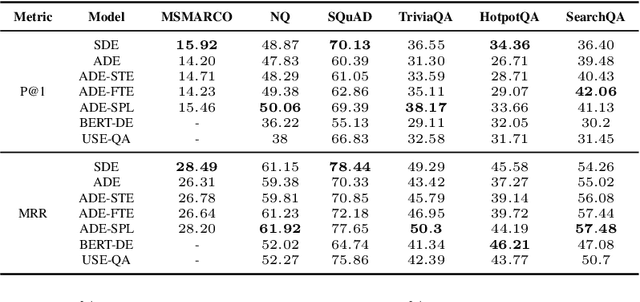

Dual encoders have been used for question-answering (QA) and information retrieval (IR) tasks with good results. There are two major types of dual encoders, Siamese Dual Encoders (SDE), with parameters shared across two encoders, and Asymmetric Dual Encoder (ADE), with two distinctly parameterized encoders. In this work, we explore the dual encoder architectures for QA retrieval tasks. By evaluating on MS MARCO and the MultiReQA benchmark, we show that SDE performs significantly better than ADE. We further propose three different improved versions of ADEs. Based on the evaluation of QA retrieval tasks and direct analysis of the embeddings, we demonstrate that sharing parameters in projection layers would enable ADEs to perform competitively with SDEs.
A Survey on Hyperspectral Image Restoration: From the View of Low-Rank Tensor Approximation
May 18, 2022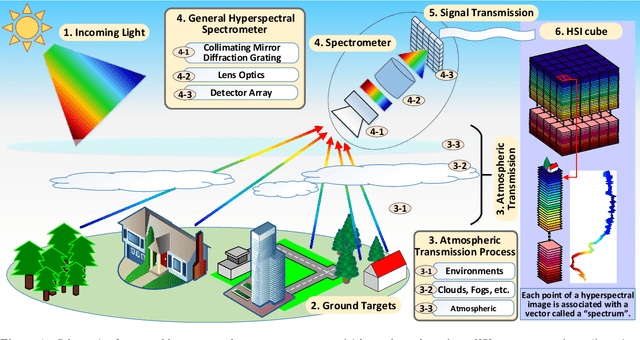
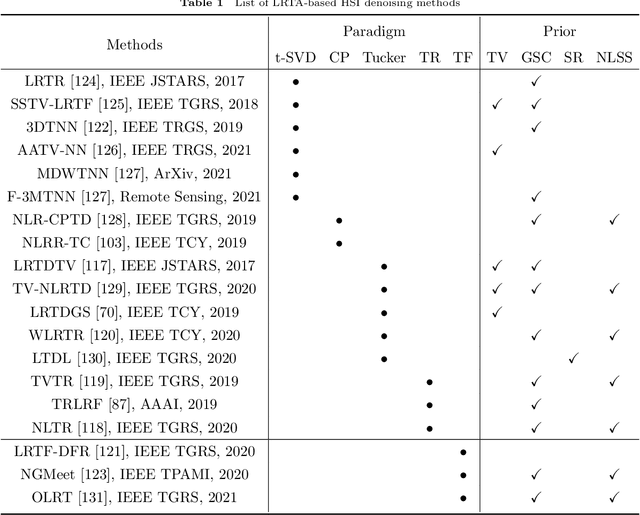
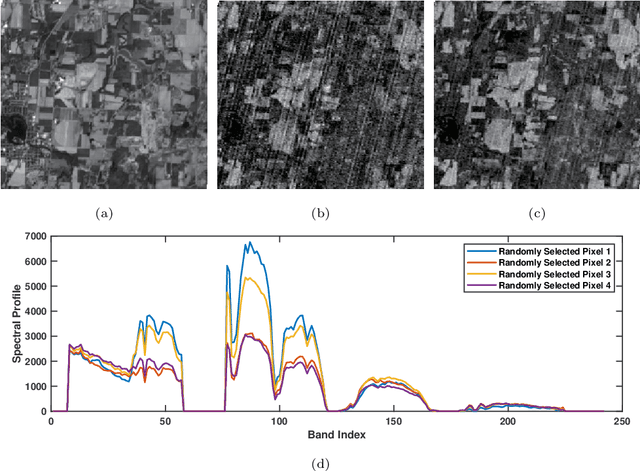
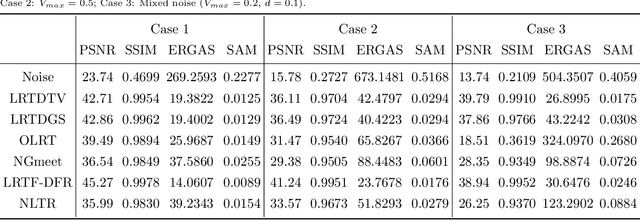
The ability of capturing fine spectral discriminative information enables hyperspectral images (HSIs) to observe, detect and identify objects with subtle spectral discrepancy. However, the captured HSIs may not represent true distribution of ground objects and the received reflectance at imaging instruments may be degraded, owing to environmental disturbances, atmospheric effects and sensors' hardware limitations. These degradations include but are not limited to: complex noise (i.e., Gaussian noise, impulse noise, sparse stripes, and their mixtures), heavy stripes, deadlines, cloud and shadow occlusion, blurring and spatial-resolution degradation and spectral absorption, etc. These degradations dramatically reduce the quality and usefulness of HSIs. Low-rank tensor approximation (LRTA) is such an emerging technique, having gained much attention in HSI restoration community, with ever-growing theoretical foundation and pivotal technological innovation. Compared to low-rank matrix approximation (LRMA), LRTA is capable of characterizing more complex intrinsic structure of high-order data and owns more efficient learning abilities, being established to address convex and non-convex inverse optimization problems induced by HSI restoration. This survey mainly attempts to present a sophisticated, cutting-edge, and comprehensive technical survey of LRTA toward HSI restoration, specifically focusing on the following six topics: Denoising, Destriping, Inpainting, Deblurring, Super--resolution and Fusion. The theoretical development and variants of LRTA techniques are also elaborated. For each topic, the state-of-the-art restoration methods are compared by assessing their performance both quantitatively and visually. Open issues and challenges are also presented, including model formulation, algorithm design, prior exploration and application concerning the interpretation requirements.
Accelerated Continuous-Time Approximate Dynamic Programming via Data-Assisted Hybrid Control
Apr 27, 2022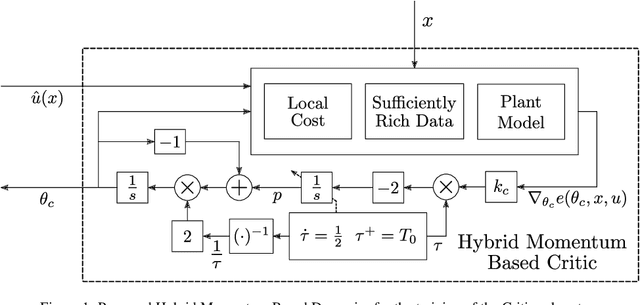
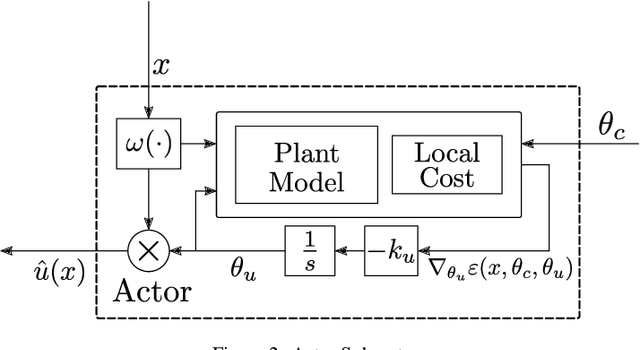
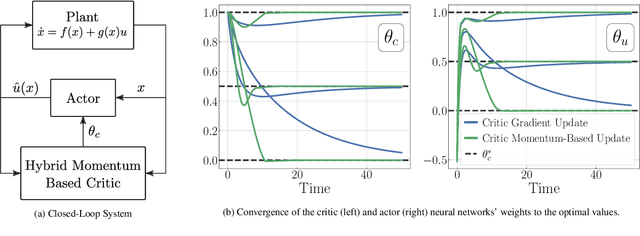
We introduce a new closed-loop architecture for the online solution of approximate optimal control problems in the context of continuous-time systems. Specifically, we introduce the first algorithm that incorporates dynamic momentum in actor-critic structures to control continuous-time dynamic plants with an affine structure in the input. By incorporating dynamic momentum in our algorithm, we are able to accelerate the convergence properties of the closed-loop system, achieving superior transient performance compared to traditional gradient-descent based techniques. In addition, by leveraging the existence of past recorded data with sufficiently rich information properties, we dispense with the persistence of excitation condition traditionally imposed on the regressors of the critic and the actor. Given that our continuous-time momentum-based dynamics also incorporate periodic discrete-time resets that emulate restarting techniques used in the machine learning literature, we leverage tools from hybrid dynamical systems theory to establish asymptotic stability properties for the closed-loop system. We illustrate our results with a numerical example.
Long Time No See! Open-Domain Conversation with Long-Term Persona Memory
Mar 14, 2022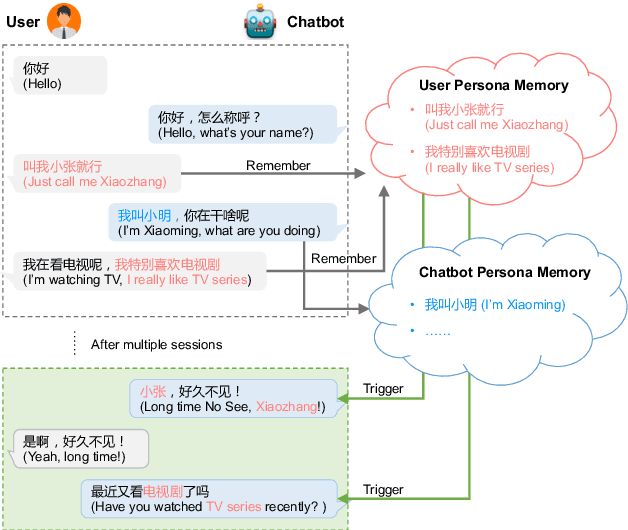
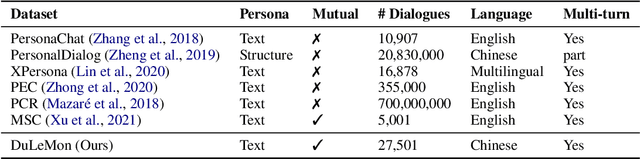
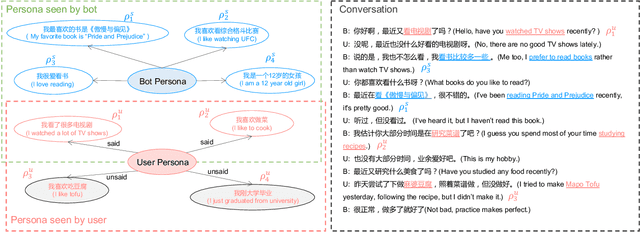
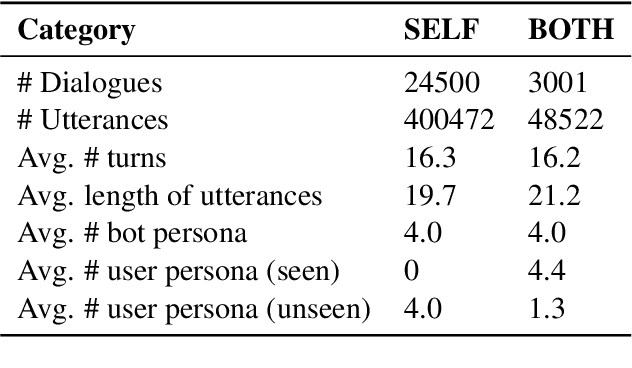
Most of the open-domain dialogue models tend to perform poorly in the setting of long-term human-bot conversations. The possible reason is that they lack the capability of understanding and memorizing long-term dialogue history information. To address this issue, we present a novel task of Long-term Memory Conversation (LeMon) and then build a new dialogue dataset DuLeMon and a dialogue generation framework with Long-Term Memory (LTM) mechanism (called PLATO-LTM). This LTM mechanism enables our system to accurately extract and continuously update long-term persona memory without requiring multiple-session dialogue datasets for model training. To our knowledge, this is the first attempt to conduct real-time dynamic management of persona information of both parties, including the user and the bot. Results on DuLeMon indicate that PLATO-LTM can significantly outperform baselines in terms of long-term dialogue consistency, leading to better dialogue engagingness.
Deep Reinforcement Learning Using a Low-Dimensional Observation Filter for Visual Complex Video Game Playing
Apr 24, 2022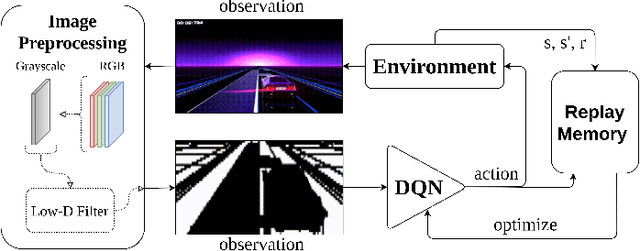
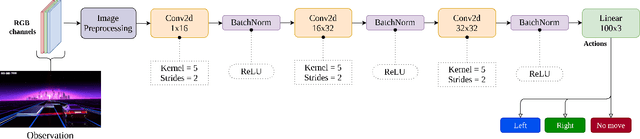
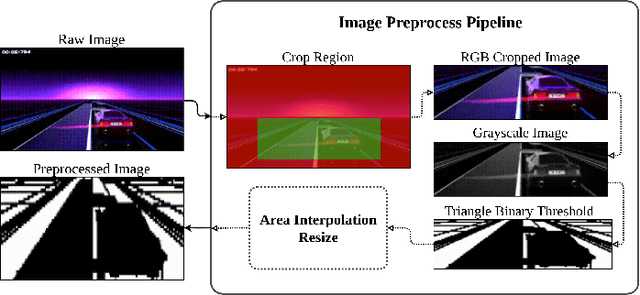
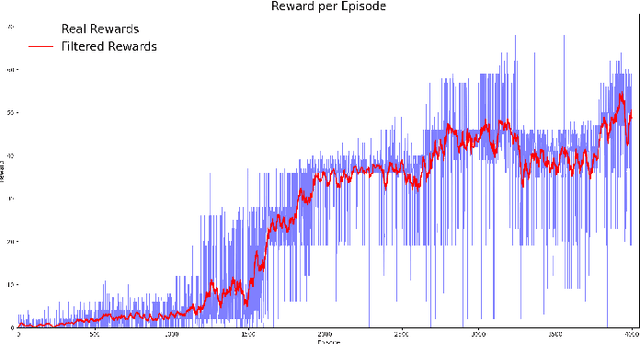
Deep Reinforcement Learning (DRL) has produced great achievements since it was proposed, including the possibility of processing raw vision input data. However, training an agent to perform tasks based on image feedback remains a challenge. It requires the processing of large amounts of data from high-dimensional observation spaces, frame by frame, and the agent's actions are computed according to deep neural network policies, end-to-end. Image pre-processing is an effective way of reducing these high dimensional spaces, eliminating unnecessary information present in the scene, supporting the extraction of features and their representations in the agent's neural network. Modern video-games are examples of this type of challenge for DRL algorithms because of their visual complexity. In this paper, we propose a low-dimensional observation filter that allows a deep Q-network agent to successfully play in a visually complex and modern video-game, called Neon Drive.
Attention based Memory video portrait matting
Mar 21, 2022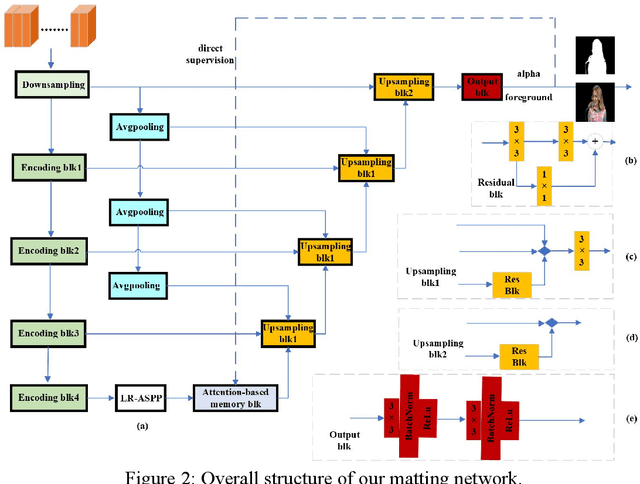

We proposed a novel trimap free video matting method based on the attention mechanism. By the nature of the problem, most existing approaches use either multiple computational expansive modules or complex algorithms to exploit temporal information fully. We designed a temporal aggregation module to compute the temporal coherence between the current frame and its two previous frames.
Exploring Neural Entity Representations for Semantic Information
Nov 17, 2020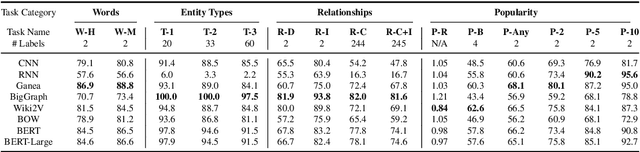
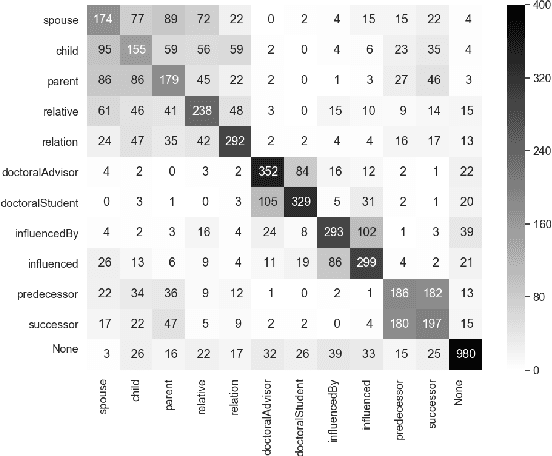
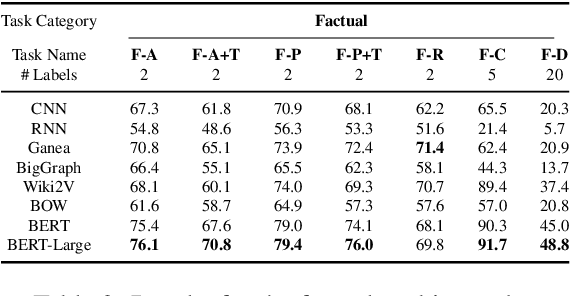
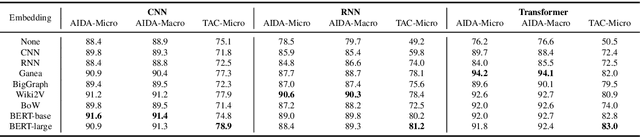
Neural methods for embedding entities are typically extrinsically evaluated on downstream tasks and, more recently, intrinsically using probing tasks. Downstream task-based comparisons are often difficult to interpret due to differences in task structure, while probing task evaluations often look at only a few attributes and models. We address both of these issues by evaluating a diverse set of eight neural entity embedding methods on a set of simple probing tasks, demonstrating which methods are able to remember words used to describe entities, learn type, relationship and factual information, and identify how frequently an entity is mentioned. We also compare these methods in a unified framework on two entity linking tasks and discuss how they generalize to different model architectures and datasets.
* 9 pages, 1 figure