 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Tip of the Tongue: Analyzing Conceptual Representation in Large Language Models with Reverse-Dictionary Probe
Feb 26, 2024
Probing and enhancing large language models' reasoning capacity remains a crucial open question. Here we re-purpose the reverse dictionary task as a case study to probe LLMs' capacity for conceptual inference. We use in-context learning to guide the models to generate the term for an object concept implied in a linguistic description. Models robustly achieve high accuracy in this task, and their representation space encodes information about object categories and fine-grained features. Further experiments suggest that the conceptual inference ability as probed by the reverse-dictionary task predicts model's general reasoning performance across multiple benchmarks, despite similar syntactic generalization behaviors across models. Explorative analyses suggest that prompting LLMs with description$\Rightarrow$word examples may induce generalization beyond surface-level differences in task construals and facilitate models on broader commonsense reasoning problems.
One-Shot Graph Representation Learning Using Hyperdimensional Computing
Feb 26, 2024We present a novel, simple, fast, and efficient approach for semi-supervised learning on graphs. The proposed approach takes advantage of hyper-dimensional computing which encodes data samples using random projections into a high dimensional space (HD space for short). Specifically, we propose a Hyper-dimensional Graph Learning (HDGL) algorithm that leverages the injectivity property of the node representations of a family of graph neural networks. HDGL maps node features to the HD space and then uses HD operators such as bundling and binding to aggregate information from the local neighborhood of each node. Results of experiments with widely used benchmark data sets show that HDGL achieves predictive performance that is competitive with the state-of-the-art deep learning methods, without the need for computationally expensive training.
Flexible Robust Beamforming for Multibeam Satellite Downlink using Reinforcement Learning
Feb 26, 2024Low Earth Orbit (LEO) satellite-to-handheld connections herald a new era in satellite communications. Space-Division Multiple Access (SDMA) precoding is a method that mitigates interference among satellite beams, boosting spectral efficiency. While optimal SDMA precoding solutions have been proposed for ideal channel knowledge in various scenarios, addressing robust precoding with imperfect channel information has primarily been limited to simplified models. However, these models might not capture the complexity of LEO satellite applications. We use the Soft Actor-Critic (SAC) deep Reinforcement Learning (RL) method to learn robust precoding strategies without the need for explicit insights into the system conditions and imperfections. Our results show flexibility to adapt to arbitrary system configurations while performing strongly in terms of achievable rate and robustness to disruptive influences compared to analytical benchmark precoders.
Retrieval Augmented Generation Systems: Automatic Dataset Creation, Evaluation and Boolean Agent Setup
Feb 26, 2024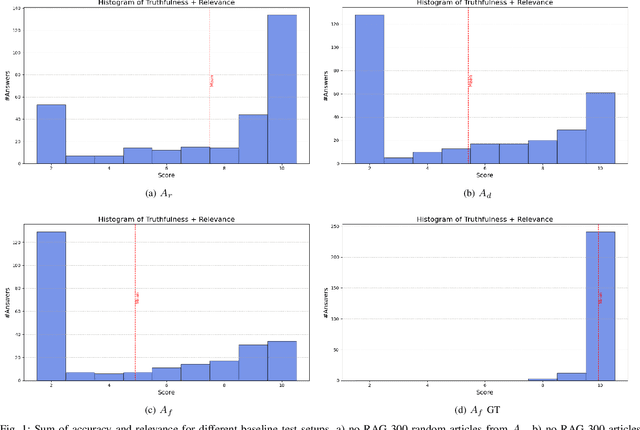
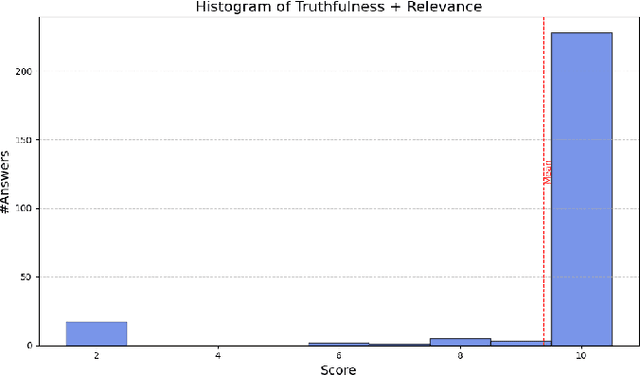
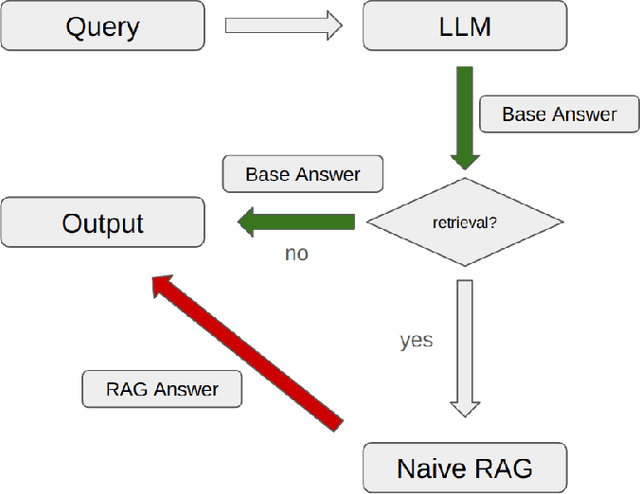
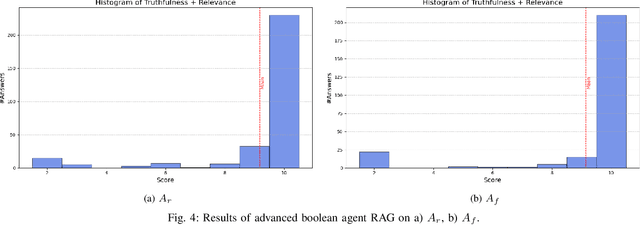
Retrieval Augmented Generation (RAG) systems have seen huge popularity in augmenting Large-Language Model (LLM) outputs with domain specific and time sensitive data. Very recently a shift is happening from simple RAG setups that query a vector database for additional information with every user input to more sophisticated forms of RAG. However, different concrete approaches compete on mostly anecdotal evidence at the moment. In this paper we present a rigorous dataset creation and evaluation workflow to quantitatively compare different RAG strategies. We use a dataset created this way for the development and evaluation of a boolean agent RAG setup: A system in which a LLM can decide whether to query a vector database or not, thus saving tokens on questions that can be answered with internal knowledge. We publish our code and generated dataset online.
Enhancing Roadway Safety: LiDAR-based Tree Clearance Analysis
Feb 28, 2024In the efforts for safer roads, ensuring adequate vertical clearance above roadways is of great importance. Frequently, trees or other vegetation is growing above the roads, blocking the sight of traffic signs and lights and posing danger to traffic participants. Accurately estimating this space from simple images proves challenging due to a lack of depth information. This is where LiDAR technology comes into play, a laser scanning sensor that reveals a three-dimensional perspective. Thus far, LiDAR point clouds at the street level have mainly been used for applications in the field of autonomous driving. These scans, however, also open up possibilities in urban management. In this paper, we present a new point cloud algorithm that can automatically detect those parts of the trees that grow over the street and need to be trimmed. Our system uses semantic segmentation to filter relevant points and downstream processing steps to create the required volume to be kept clear above the road. Challenges include obscured stretches of road, the noisy unstructured nature of LiDAR point clouds, and the assessment of the road shape. The identified points of non-compliant trees can be projected from the point cloud onto images, providing municipalities with a visual aid for dealing with such occurrences. By automating this process, municipalities can address potential road space constraints, enhancing safety for all. They may also save valuable time by carrying out the inspections more systematically. Our open-source code gives communities inspiration on how to automate the process themselves.
Passive Snapshot Coded Aperture Dual-Pixel RGB-D Imaging
Feb 28, 2024Passive, compact, single-shot 3D sensing is useful in many application areas such as microscopy, medical imaging, surgical navigation, and autonomous driving where form factor, time, and power constraints can exist. Obtaining RGB-D scene information over a short imaging distance, in an ultra-compact form factor, and in a passive, snapshot manner is challenging. Dual-pixel (DP) sensors are a potential solution to achieve the same. DP sensors collect light rays from two different halves of the lens in two interleaved pixel arrays, thus capturing two slightly different views of the scene, like a stereo camera system. However, imaging with a DP sensor implies that the defocus blur size is directly proportional to the disparity seen between the views. This creates a trade-off between disparity estimation vs. deblurring accuracy. To improve this trade-off effect, we propose CADS (Coded Aperture Dual-Pixel Sensing), in which we use a coded aperture in the imaging lens along with a DP sensor. In our approach, we jointly learn an optimal coded pattern and the reconstruction algorithm in an end-to-end optimization setting. Our resulting CADS imaging system demonstrates improvement of $>$1.5dB PSNR in all-in-focus (AIF) estimates and 5-6% in depth estimation quality over naive DP sensing for a wide range of aperture settings. Furthermore, we build the proposed CADS prototypes for DSLR photography settings and in an endoscope and a dermoscope form factor. Our novel coded dual-pixel sensing approach demonstrates accurate RGB-D reconstruction results in simulations and real-world experiments in a passive, snapshot, and compact manner.
Intelligent Reflecting Surfaces and Next Generation Wireless Systems
Feb 27, 2024Intelligent reflecting surface (IRS) is a potential candidate for massive multiple-input multiple-output (MIMO) 2.0 technology due to its low cost, ease of deployment, energy efficiency and extended coverage. This chapter investigates the slot-by-slot IRS reflection pattern design and two-timescale reflection pattern design schemes, respectively. For the slot-by-slot reflection optimization, we propose exploiting an IRS to improve the propagation channel rank in mmWave massive MIMO systems without need to increase the transmit power budget. Then, we analyze the impact of the distributed IRS on the channel rank. To further reduce the heavy overhead of channel training, channel state information (CSI) estimation, and feedback in time-varying MIMO channels, we present a two-timescale reflection optimization scheme, where the IRS is configured relatively infrequently based on statistical CSI (S-CSI) and the active beamformers and power allocation are updated based on quickly outdated instantaneous CSI (I-CSI) per slot. The achievable average sum-rate (AASR) of the system is maximized without excessive overhead of cascaded channel estimation. A recursive sampling particle swarm optimization (PSO) algorithm is developed to optimize the large-timescale IRS reflection pattern efficiently with reduced samplings of channel samples.
LinkNER: Linking Local Named Entity Recognition Models to Large Language Models using Uncertainty
Feb 27, 2024Named Entity Recognition (NER) serves as a fundamental task in natural language understanding, bearing direct implications for web content analysis, search engines, and information retrieval systems. Fine-tuned NER models exhibit satisfactory performance on standard NER benchmarks. However, due to limited fine-tuning data and lack of knowledge, it performs poorly on unseen entity recognition. As a result, the usability and reliability of NER models in web-related applications are compromised. Instead, Large Language Models (LLMs) like GPT-4 possess extensive external knowledge, but research indicates that they lack specialty for NER tasks. Furthermore, non-public and large-scale weights make tuning LLMs difficult. To address these challenges, we propose a framework that combines small fine-tuned models with LLMs (LinkNER) and an uncertainty-based linking strategy called RDC that enables fine-tuned models to complement black-box LLMs, achieving better performance. We experiment with both standard NER test sets and noisy social media datasets. LinkNER enhances NER task performance, notably surpassing SOTA models in robustness tests. We also quantitatively analyze the influence of key components like uncertainty estimation methods, LLMs, and in-context learning on diverse NER tasks, offering specific web-related recommendations.
CGGM: A conditional graph generation model with adaptive sparsity for node anomaly detection in IoT networks
Feb 27, 2024Dynamic graphs are extensively employed for detecting anomalous behavior in nodes within the Internet of Things (IoT). Generative models are often used to address the issue of imbalanced node categories in dynamic graphs. Nevertheless, the constraints it faces include the monotonicity of adjacency relationships, the difficulty in constructing multi-dimensional features for nodes, and the lack of a method for end-to-end generation of multiple categories of nodes. This paper presents a novel graph generation model, called CGGM, designed specifically to generate a larger number of nodes belonging to the minority class. The mechanism for generating an adjacency matrix, through adaptive sparsity, enhances flexibility in its structure. The feature generation module, called multidimensional features generator (MFG) to generate node features along with topological information. Labels are transformed into embedding vectors, serving as conditional constraints to control the generation of synthetic data across multiple categories. Using a multi-stage loss, the distribution of synthetic data is adjusted to closely resemble that of real data. In extensive experiments, we show that CGGM's synthetic data outperforms state-of-the-art methods across various metrics. Our results demonstrate efficient generation of diverse data categories, robustly enhancing multi-category classification model performance.
Reinforced In-Context Black-Box Optimization
Feb 27, 2024Black-Box Optimization (BBO) has found successful applications in many fields of science and engineering. Recently, there has been a growing interest in meta-learning particular components of BBO algorithms to speed up optimization and get rid of tedious hand-crafted heuristics. As an extension, learning the entire algorithm from data requires the least labor from experts and can provide the most flexibility. In this paper, we propose RIBBO, a method to reinforce-learn a BBO algorithm from offline data in an end-to-end fashion. RIBBO employs expressive sequence models to learn the optimization histories produced by multiple behavior algorithms and tasks, leveraging the in-context learning ability of large models to extract task information and make decisions accordingly. Central to our method is to augment the optimization histories with regret-to-go tokens, which are designed to represent the performance of an algorithm based on cumulative regret of the histories. The integration of regret-to-go tokens enables RIBBO to automatically generate sequences of query points that satisfy the user-desired regret, which is verified by its universally good empirical performance on diverse problems, including BBOB functions, hyper-parameter optimization and robot control problems.