 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ingredient Extraction from Text in the Recipe Domain
Apr 18, 2022
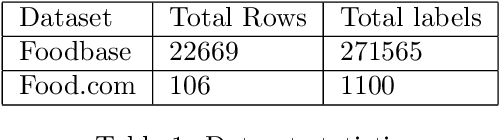
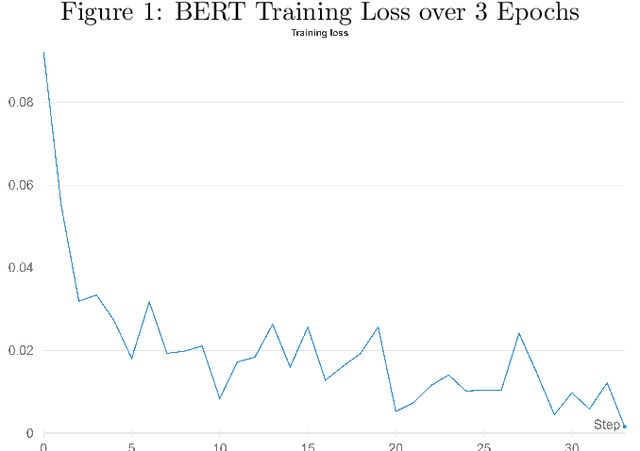
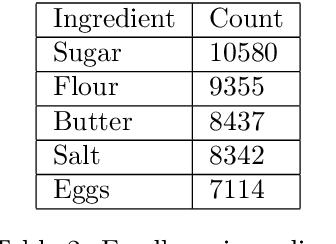
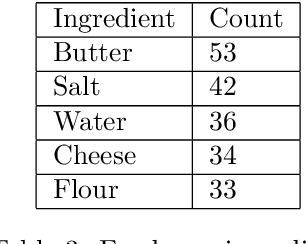
In recent years, there has been an increase in the number of devices with virtual assistants (e.g: Siri, Google Home, Alexa) in our living rooms and kitchens. As a result of this, these devices receive several queries about recipes. All these queries will contain terms relating to a "recipe-domain" i.e: they will contain dish-names, ingredients, cooking times, dietary preferences etc. Extracting these recipe-relevant aspects from the query thus becomes important when it comes to addressing the user's information need. Our project focuses on extracting ingredients from such plain-text user utterances. Our best performing model was a fine-tuned BERT which achieved an F1-score of $95.01$. We have released all our code in a GitHub repository.
Frontier-based Automatic-differentiable Information Gain Measure for Robotic Exploration of Unknown 3D Environments
Nov 10, 2020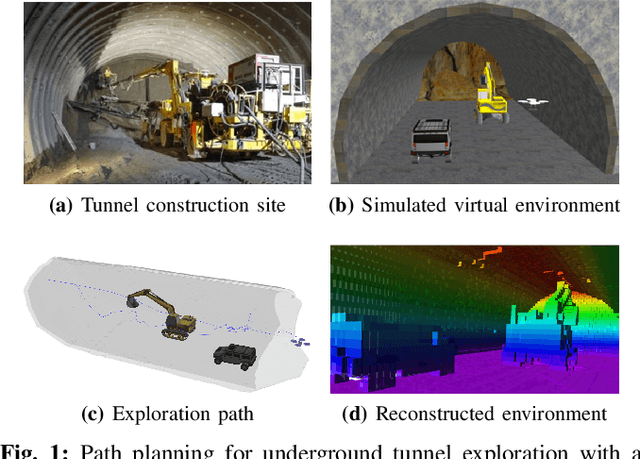



The path planning problem for autonomous exploration of an unknown region by a robotic agent typically employs frontier-based or information-theoretic heuristics. Frontier-based heuristics typically evaluate the information gain of a viewpoint by the number of visible frontier voxels, which is a discrete measure that can only be optimized by sampling. On the other hand, information-theoretic heuristics compute information gain as the mutual information between the map and the sensor's measurement. Although the gradient of such measures can be computed, the computation involves costly numerical differentiation. In this work, we add a novel fuzzy logic filter in the counting of visible frontier voxels surrounding a viewpoint, which allows the gradient of the information gain with respect to the viewpoint to be efficiently computed using automatic differentiation. This enables us to simultaneously optimize information gain with other differentiable quality measures such as path length. Using multiple simulation environments, we demonstrate that the proposed gradient-based optimization method consistently improves the information gain and other quality measures of exploration paths.
Multi-Layer Modeling of Dense Vegetation from Aerial LiDAR Scans
Apr 25, 2022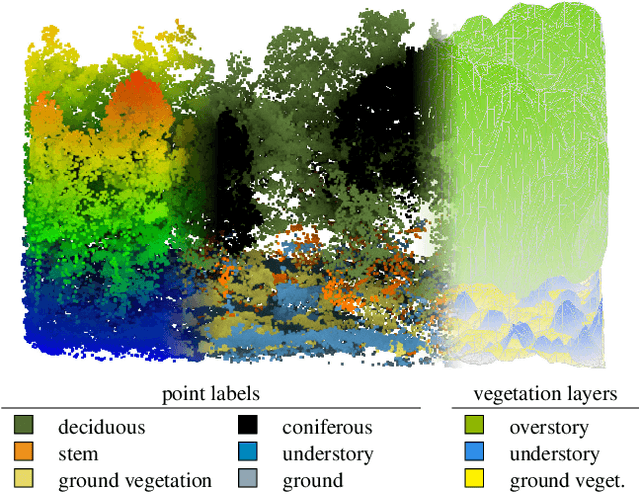

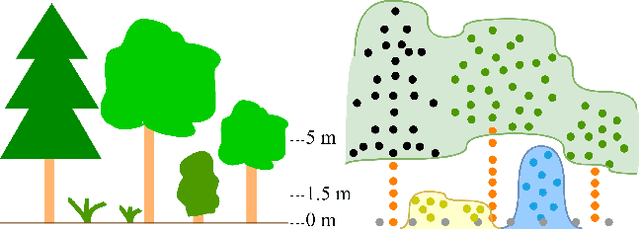
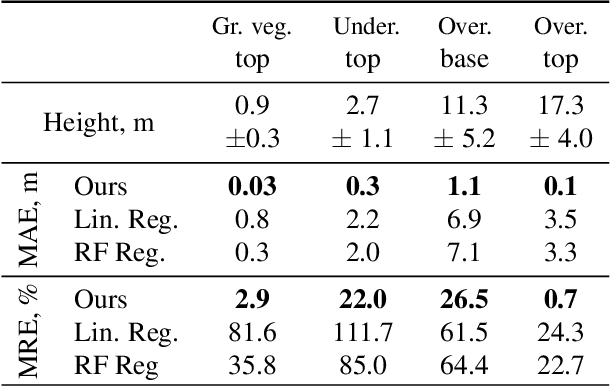
The analysis of the multi-layer structure of wild forests is an important challenge of automated large-scale forestry. While modern aerial LiDARs offer geometric information across all vegetation layers, most datasets and methods focus only on the segmentation and reconstruction of the top of canopy. We release WildForest3D, which consists of 29 study plots and over 2000 individual trees across 47 000m2 with dense 3D annotation, along with occupancy and height maps for 3 vegetation layers: ground vegetation, understory, and overstory. We propose a 3D deep network architecture predicting for the first time both 3D point-wise labels and high-resolution layer occupancy rasters simultaneously. This allows us to produce a precise estimation of the thickness of each vegetation layer as well as the corresponding watertight meshes, therefore meeting most forestry purposes. Both the dataset and the model are released in open access: https://github.com/ekalinicheva/multi_layer_vegetation.
Using Collocated Vision and Tactile Sensors for Visual Servoing and Localization
Apr 27, 2022
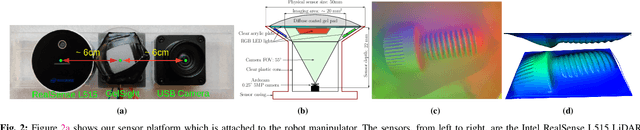


Coordinating proximity and tactile imaging by collocating cameras with tactile sensors can 1) provide useful information before contact such as object pose estimates and visually servo a robot to a target with reduced occlusion and higher resolution compared to head-mounted or external depth cameras, 2) simplify the contact point and pose estimation problems and help tactile sensing avoid erroneous matches when a surface does not have significant texture or has repetitive texture with many possible matches, and 3) use tactile imaging to further refine contact point and object pose estimation. We demonstrate our results with objects that have more surface texture than most objects in standard manipulation datasets. We learn that optic flow needs to be integrated over a substantial amount of camera travel to be useful in predicting movement direction. Most importantly, we also learn that state of the art vision algorithms do not do a good job localizing tactile images on object models, unless a reasonable prior can be provided from collocated cameras.
* This archival version of the manuscript is significantly different in content from the reviewed and published version. The published version can be accessed here: https://ieeexplore.ieee.org/document/9699405. Supplementary materials can be accessed here: https://arkadeepnc.github.io/projects/collocated_vision_touch/index.html
Scene Graph Expansion for Semantics-Guided Image Outpainting
May 05, 2022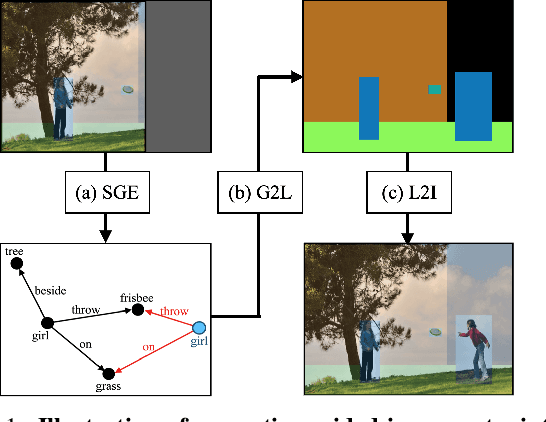
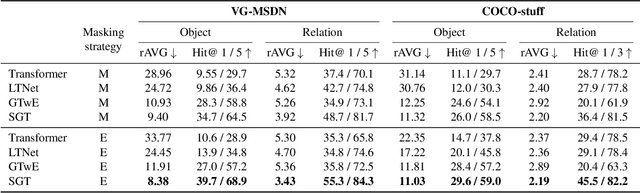
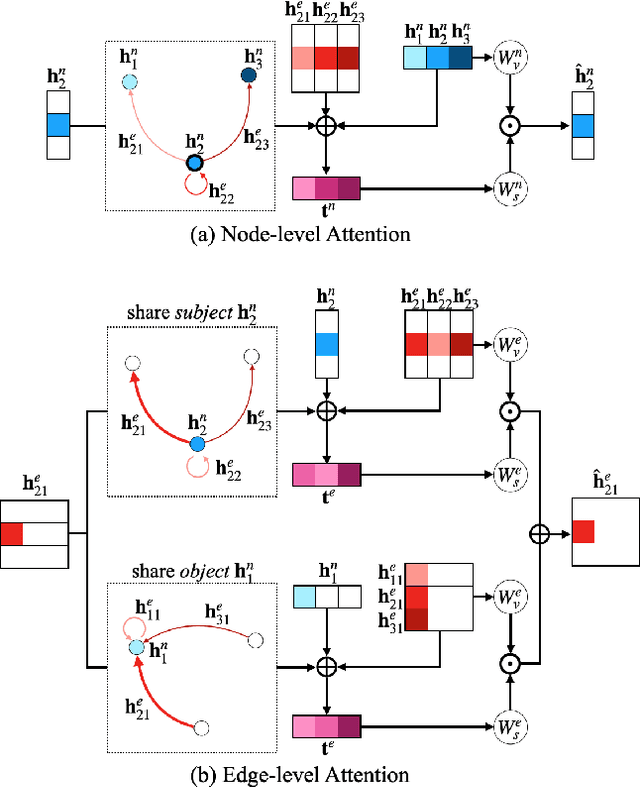

In this paper, we address the task of semantics-guided image outpainting, which is to complete an image by generating semantically practical content. Different from most existing image outpainting works, we approach the above task by understanding and completing image semantics at the scene graph level. In particular, we propose a novel network of Scene Graph Transformer (SGT), which is designed to take node and edge features as inputs for modeling the associated structural information. To better understand and process graph-based inputs, our SGT uniquely performs feature attention at both node and edge levels. While the former views edges as relationship regularization, the latter observes the co-occurrence of nodes for guiding the attention process. We demonstrate that, given a partial input image with its layout and scene graph, our SGT can be applied for scene graph expansion and its conversion to a complete layout. Following state-of-the-art layout-to-image conversions works, the task of image outpainting can be completed with sufficient and practical semantics introduced. Extensive experiments are conducted on the datasets of MS-COCO and Visual Genome, which quantitatively and qualitatively confirm the effectiveness of our proposed SGT and outpainting frameworks.
Active Privacy-Utility Trade-off Against Inference in Time-Series Data Sharing
Feb 11, 2022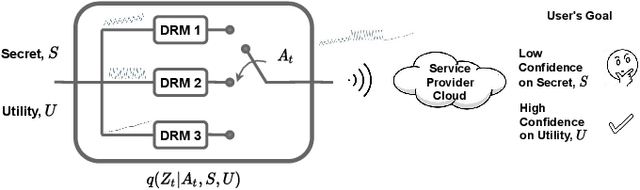
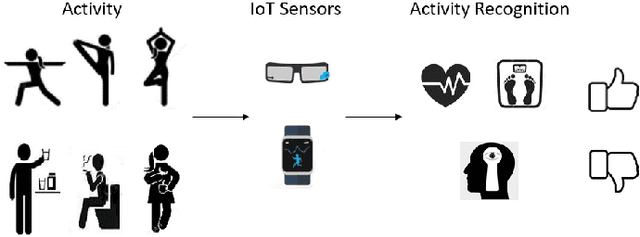
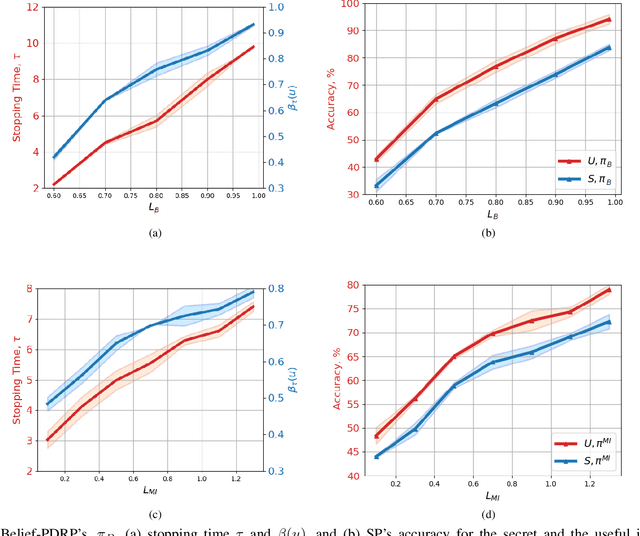
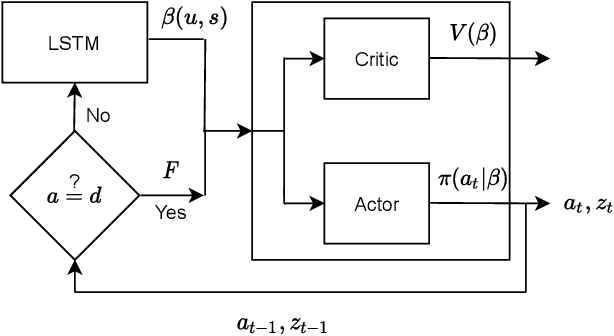
Internet of things (IoT) devices, such as smart meters, smart speakers and activity monitors, have become highly popular thanks to the services they offer. However, in addition to their many benefits, they raise privacy concerns since they share fine-grained time-series user data with untrusted third parties. In this work, we consider a user releasing her data containing personal information in return of a service from an honest-but-curious service provider (SP). We model user's personal information as two correlated random variables (r.v.'s), one of them, called the secret variable, is to be kept private, while the other, called the useful variable, is to be disclosed for utility. We consider active sequential data release, where at each time step the user chooses from among a finite set of release mechanisms, each revealing some information about the user's personal information, i.e., the true values of the r.v.'s, albeit with different statistics. The user manages data release in an online fashion such that the maximum amount of information is revealed about the latent useful variable as quickly as possible, while the confidence for the sensitive variable is kept below a predefined level. For privacy measure, we consider both the probability of correctly detecting the true value of the secret and the mutual information (MI) between the secret and the released data. We formulate both problems as partially observable Markov decision processes (POMDPs), and numerically solve them by advantage actor-critic (A2C) deep reinforcement learning (DRL). We evaluate the privacy-utility trade-off (PUT) of the proposed policies on both the synthetic data and smoking activity dataset, and show their validity by testing the activity detection accuracy of the SP modeled by a long short-term memory (LSTM) neural network.
NeuralTree: A 256-Channel 0.227uJ/class Versatile Neural Activity Classification and Closed-Loop Neuromodulation SoC
May 21, 2022



Closed-loop neural interfaces with on-chip machine learning can detect and suppress disease symptoms in neurological disorders or restore lost functions in paralyzed patients. While high-density neural recording can provide rich neural activity information for accurate disease-state detection, existing systems have low channel count and poor scalability, which could limit their therapeutic efficacy. This work presents a highly scalable and versatile closed-loop neural interface SoC that can overcome these limitations. A 256-channel time-division multiplexed (TDM) front-end with a two-step fast-settling mixed-signal DC servo loop (DSL) is proposed to record high-spatial-resolution neural activity and perform channel-selective brain-state inference. A tree-structured neural network (NeuralTree) classification processor extracts a rich set of neural biomarkers in a patient- and disease-specific manner. Trained with an energy-aware learning algorithm, the NeuralTree classifier detects the symptoms of underlying disorders (e.g., epilepsy and movement disorders) at an optimal energy-accuracy trade-off. A 16-channel high-voltage (HV) compliant neurostimulator closes the therapeutic loop by delivering charge-balanced biphasic current pulses to the brain. The proposed SoC was fabricated in 65nm CMOS and achieved a 0.227uJ/class energy efficiency in a compact area of 0.014mm^2/channel. The SoC was extensively verified on human electroencephalography (EEG) and intracranial EEG (iEEG) epilepsy datasets, obtaining 95.6%/94% sensitivity and 96.8%/96.9% specificity, respectively. In-vivo neural recordings using soft uECoG arrays and multi-domain biomarker extraction were further performed on a rat model of epilepsy. In addition, for the first time in literature, on-chip classification of rest-state tremor in Parkinson's disease from human local field potentials (LFPs) was demonstrated.
DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised Learning
Feb 22, 2022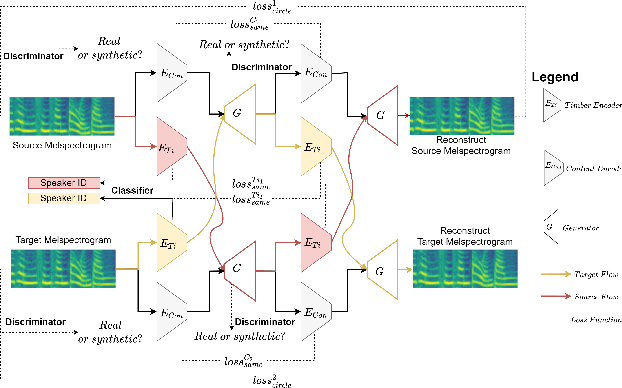
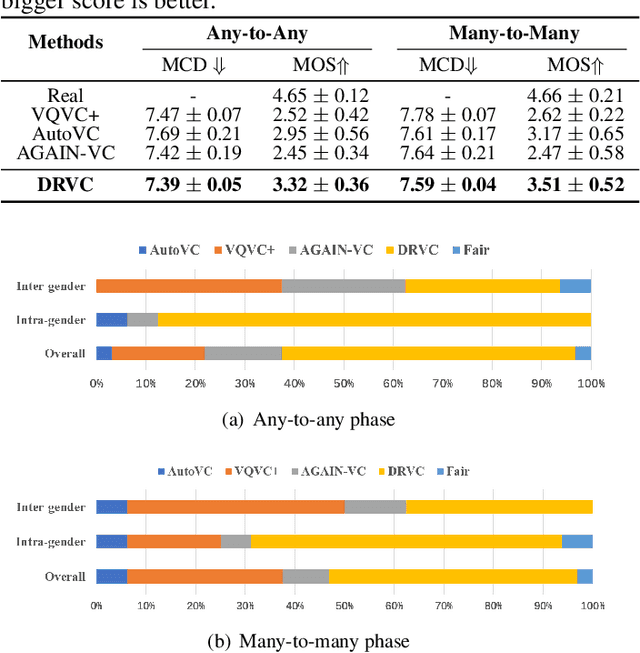

Any-to-any voice conversion problem aims to convert voices for source and target speakers, which are out of the training data. Previous works wildly utilize the disentangle-based models. The disentangle-based model assumes the speech consists of content and speaker style information and aims to untangle them to change the style information for conversion. Previous works focus on reducing the dimension of speech to get the content information. But the size is hard to determine to lead to the untangle overlapping problem. We propose the Disentangled Representation Voice Conversion (DRVC) model to address the issue. DRVC model is an end-to-end self-supervised model consisting of the content encoder, timbre encoder, and generator. Instead of the previous work for reducing speech size to get content, we propose a cycle for restricting the disentanglement by the Cycle Reconstruct Loss and Same Loss. The experiments show there is an improvement for converted speech on quality and voice similarity.
Graph Adversarial Networks: Protecting Information against Adversarial Attacks
Sep 28, 2020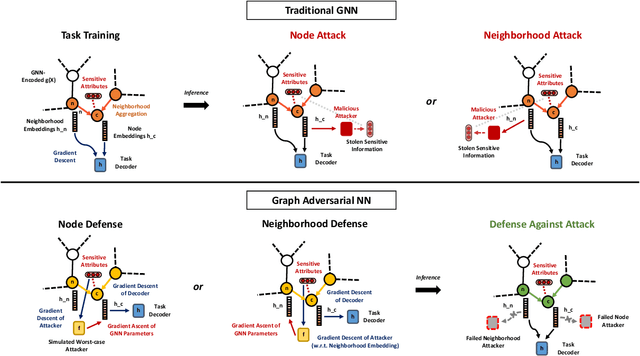
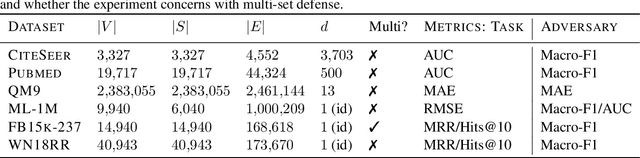
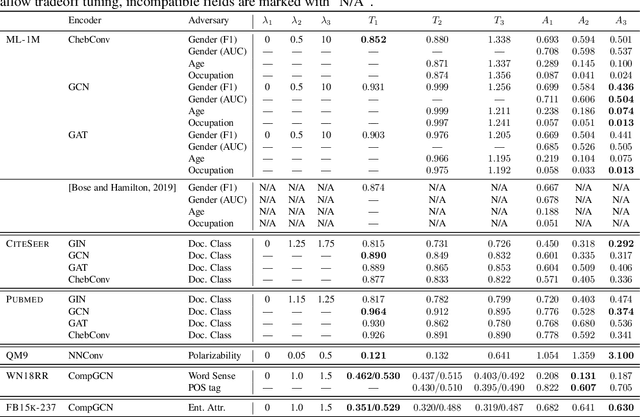
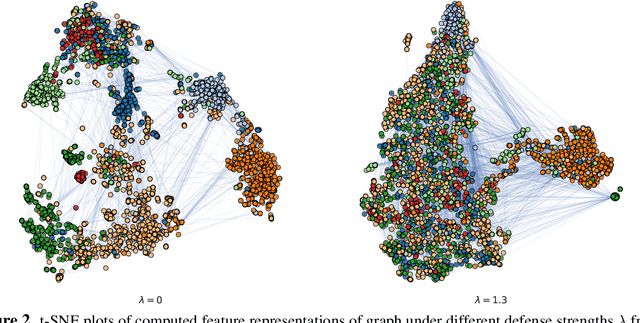
We explore the problem of protecting information when learning with graph-structured data. While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representational learning in many applications, the neighborhood aggregation paradigm exposes additional vulnerabilities to attackers seeking to extract node-level information about sensitive attributes. To counter this, we propose a minimax game between the desired GNN encoder and the worst-case attacker. The resulting adversarial training creates a strong defense against inference attacks, while only suffering small loss in task performance. We analyze the effectiveness of our framework against a worst-case adversary, and characterize the trade-off between predictive accuracy and adversarial defense. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders.
Balancing Fairness and Accuracy in Sentiment Detection using Multiple Black Box Models
Apr 22, 2022

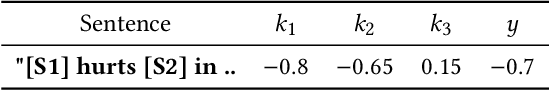
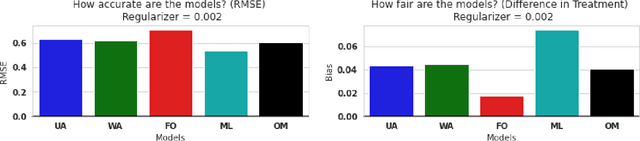
Sentiment detection is an important building block for multiple information retrieval tasks such as product recommendation, cyberbullying detection, and misinformation detection. Unsurprisingly, multiple commercial APIs, each with different levels of accuracy and fairness, are now available for sentiment detection. While combining inputs from multiple modalities or black-box models for increasing accuracy is commonly studied in multimedia computing literature, there has been little work on combining different modalities for increasing fairness of the resulting decision. In this work, we audit multiple commercial sentiment detection APIs for the gender bias in two actor news headlines settings and report on the level of bias observed. Next, we propose a "Flexible Fair Regression" approach, which ensures satisfactory accuracy and fairness by jointly learning from multiple black-box models. The results pave way for fair yet accurate sentiment detectors for multiple applications.