 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Collaborative Approach Using Neural Networks for BLE-RSS Lateration-Based Indoor Positioning
May 21, 2022
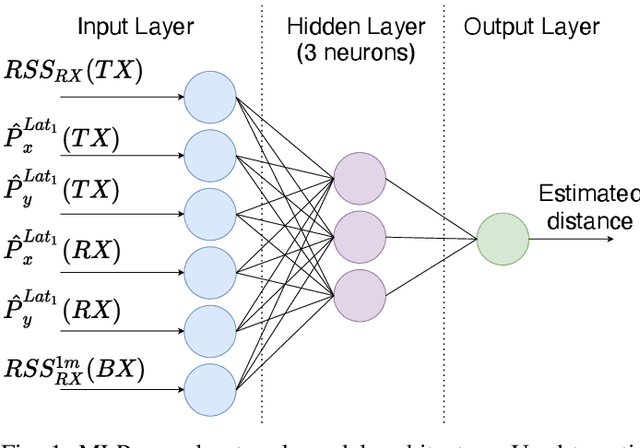
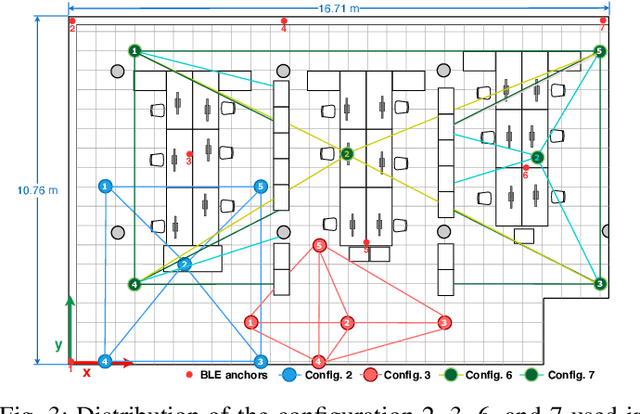
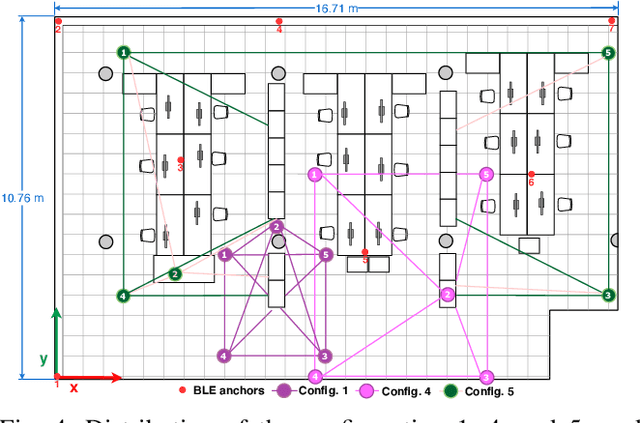
In daily life, mobile and wearable devices with high computing power, together with anchors deployed in indoor environments, form a common solution for the increasing demands for indoor location-based services. Within the technologies and methods currently in use for indoor localization, the approaches that rely on Bluetooth Low Energy (BLE) anchors, Received Signal Strength (RSS), and lateration are among the most popular, mainly because of their cheap and easy deployment and accessible infrastructure by a variety of devices. Nevertheless, such BLE- and RSS-based indoor positioning systems are prone to inaccuracies, mostly due to signal fluctuations, poor quantity of anchors deployed in the environment, and/or inappropriate anchor distributions, as well as mobile device hardware variability. In this paper, we address these issues by using a collaborative indoor positioning approach, which exploits neighboring devices as additional anchors in an extended positioning network. The collaborating devices' information (i.e., estimated positions and BLE-RSS) is processed using a multilayer perceptron (MLP) neural network by taking into account the device specificity in order to estimate the relative distances. After this, the lateration is applied to collaboratively estimate the device position. Finally, the stand-alone and collaborative position estimates are combined, providing the final position estimate for each device. The experimental results demonstrate that the proposed collaborative approach outperforms the stand-alone lateration method in terms of positioning accuracy.
Investigating Neural Architectures by Synthetic Dataset Design
Apr 23, 2022
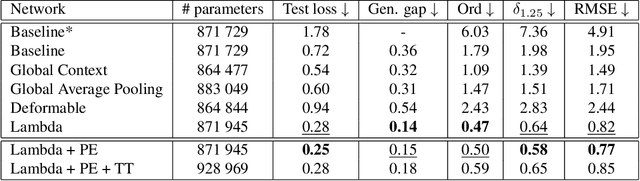

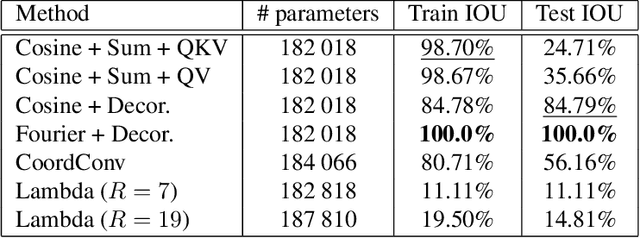
Recent years have seen the emergence of many new neural network structures (architectures and layers). To solve a given task, a network requires a certain set of abilities reflected in its structure. The required abilities depend on each task. There is so far no systematic study of the real capacities of the proposed neural structures. The question of what each structure can and cannot achieve is only partially answered by its performance on common benchmarks. Indeed, natural data contain complex unknown statistical cues. It is therefore impossible to know what cues a given neural structure is taking advantage of in such data. In this work, we sketch a methodology to measure the effect of each structure on a network's ability, by designing ad hoc synthetic datasets. Each dataset is tailored to assess a given ability and is reduced to its simplest form: each input contains exactly the amount of information needed to solve the task. We illustrate our methodology by building three datasets to evaluate each of the three following network properties: a) the ability to link local cues to distant inferences, b) the translation covariance and c) the ability to group pixels with the same characteristics and share information among them. Using a first simplified depth estimation dataset, we pinpoint a serious nonlocal deficit of the U-Net. We then evaluate how to resolve this limitation by embedding its structure with nonlocal layers, which allow computing complex features with long-range dependencies. Using a second dataset, we compare different positional encoding methods and use the results to further improve the U-Net on the depth estimation task. The third introduced dataset serves to demonstrate the need for self-attention-like mechanisms for resolving more realistic depth estimation tasks.
Learning Fair Representations via Rate-Distortion Maximization
Jan 31, 2022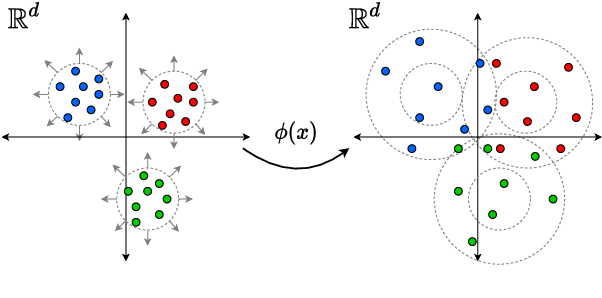
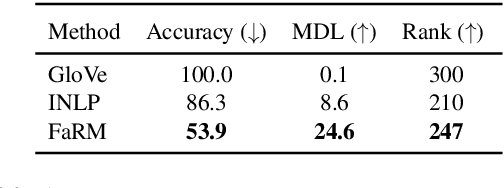
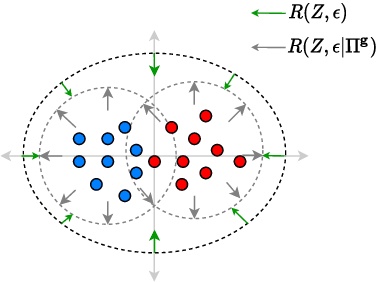
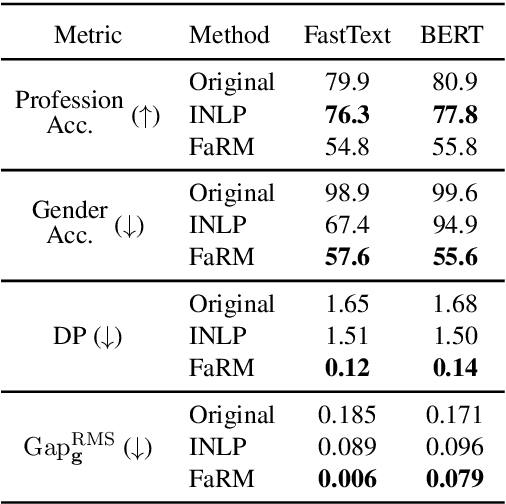
Text representations learned by machine learning models often encode undesirable demographic information of the user. Predictive models based on these representations can rely on such information resulting in biased decisions. We present a novel debiasing technique Fairness-aware Rate Maximization (FaRM), that removes demographic information by making representations of instances belonging to the same protected attribute class uncorrelated using the rate-distortion function. FaRM is able to debias representations with or without a target task at hand. FaRM can also be adapted to simultaneously remove information about multiple protected attributes. Empirical evaluations show that FaRM achieves state-of-the-art performance on several datasets, and learned representations leak significantly less protected attribute information against an attack by a non-linear probing network.
Diverse Image Captioning with Grounded Style
May 03, 2022
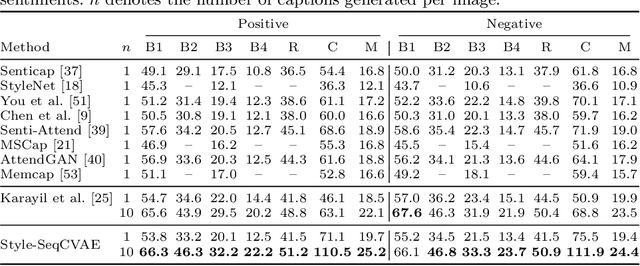
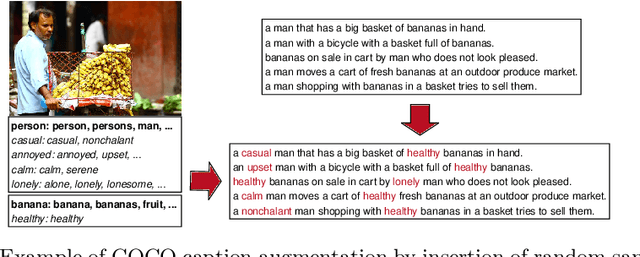
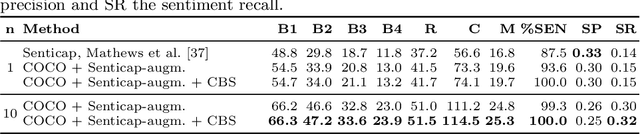
Stylized image captioning as presented in prior work aims to generate captions that reflect characteristics beyond a factual description of the scene composition, such as sentiments. Such prior work relies on given sentiment identifiers, which are used to express a certain global style in the caption, e.g. positive or negative, however without taking into account the stylistic content of the visual scene. To address this shortcoming, we first analyze the limitations of current stylized captioning datasets and propose COCO attribute-based augmentations to obtain varied stylized captions from COCO annotations. Furthermore, we encode the stylized information in the latent space of a Variational Autoencoder; specifically, we leverage extracted image attributes to explicitly structure its sequential latent space according to different localized style characteristics. Our experiments on the Senticap and COCO datasets show the ability of our approach to generate accurate captions with diversity in styles that are grounded in the image.
* In the 43rd DAGM German Conference on Pattern Recognition (GCPR) 2021
Multi-Agent Reinforcement Learning for Traffic Signal Control through Universal Communication Method
Apr 26, 2022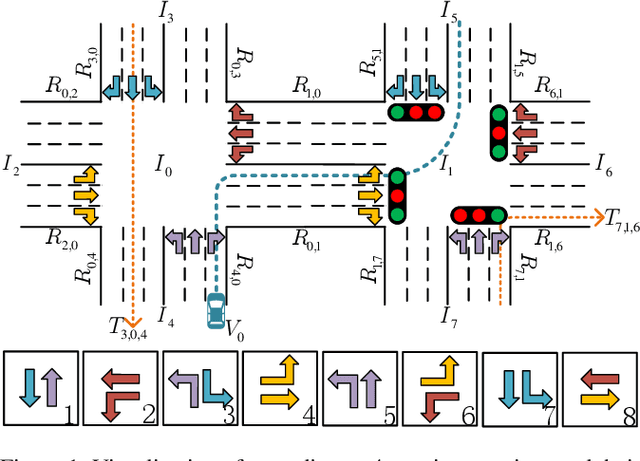
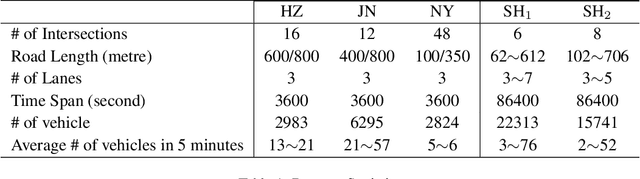
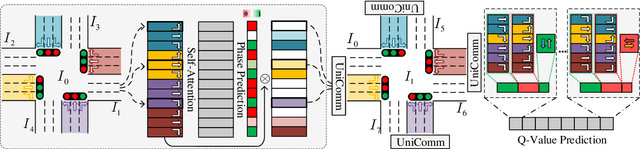
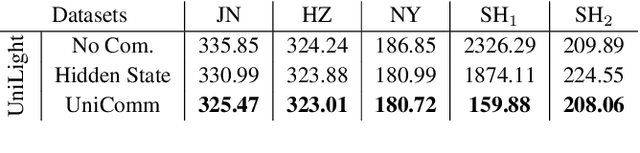
How to coordinate the communication among intersections effectively in real complex traffic scenarios with multi-intersection is challenging. Existing approaches only enable the communication in a heuristic manner without considering the content/importance of information to be shared. In this paper, we propose a universal communication form UniComm between intersections. UniComm embeds massive observations collected at one agent into crucial predictions of their impact on its neighbors, which improves the communication efficiency and is universal across existing methods. We also propose a concise network UniLight to make full use of communications enabled by UniComm. Experimental results on real datasets demonstrate that UniComm universally improves the performance of existing state-of-the-art methods, and UniLight significantly outperforms existing methods on a wide range of traffic situations.
GAC: A Deep Reinforcement Learning Model Toward User Incentivization in Unknown Social Networks
Mar 17, 2022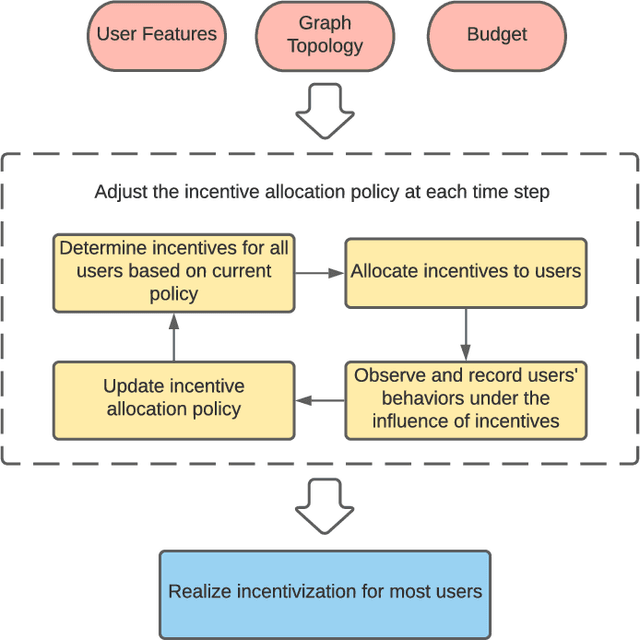

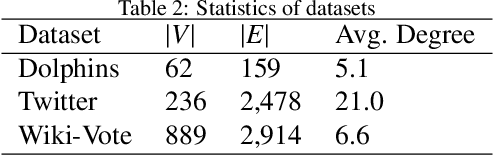
In recent years, providing incentives to human users for attracting their attention and engagement has been widely adopted in many applications. To effectively incentivize users, most incentive mechanisms determine incentive values based on users' individual attributes, such as preferences. These approaches could be ineffective when such information is unavailable. Meanwhile, due to the budget limitation, the number of users who can be incentivized is also restricted. In this light, we intend to utilize social influence among users to maximize the incentivization. By directly incentivizing influential users in the social network, their followers and friends could be indirectly incentivized with fewer incentives or no incentive. However, it is difficult to identify influential users beforehand in the social network, as the influence strength between each pair of users is typically unknown. In this work, we propose an end-to-end reinforcement learning-based framework, named Geometric Actor-Critic (GAC), to discover effective incentive allocation policies under limited budgets. More specifically, the proposed approach can extract information from a high-level network representation for learning effective incentive allocation policies. The proposed GAC only requires the topology of the social network and does not rely on any prior information about users' attributes. We use three real-world social network datasets to evaluate the performance of the proposed GAC. The experimental results demonstrate the effectiveness of the proposed approach.
Comparison research on binary relations based on transitive degrees and cluster degrees
Jan 25, 2022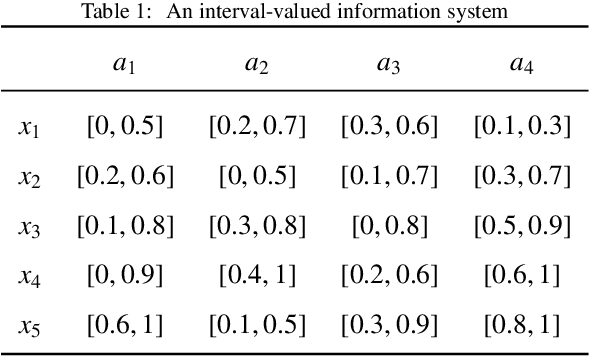
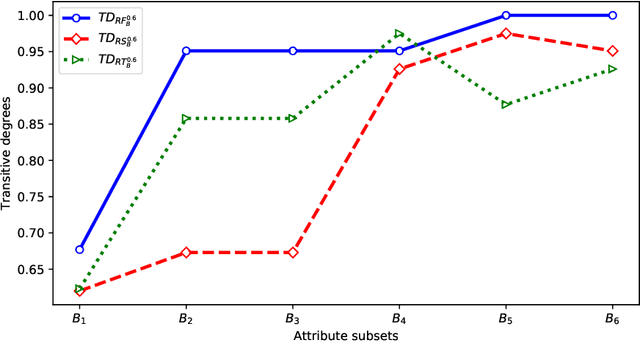
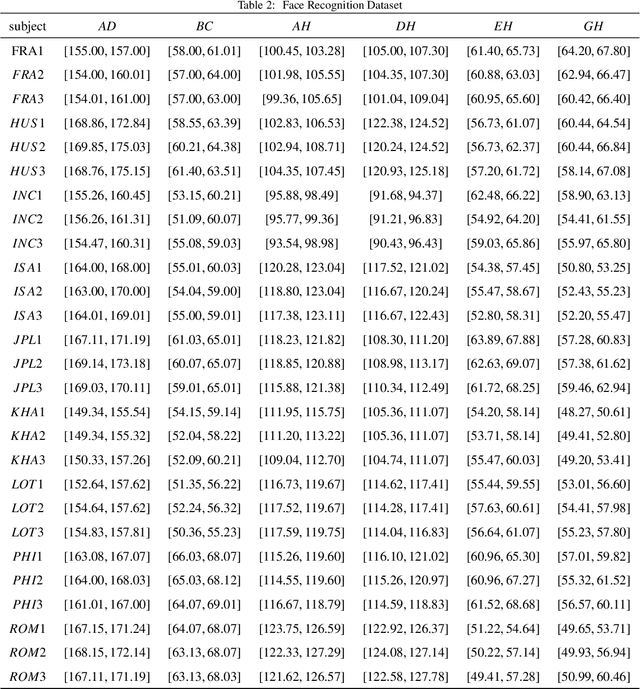
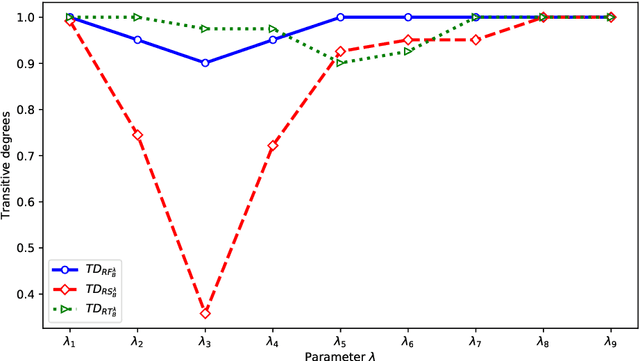
Interval-valued information systems are generalized models of single-valued information systems. By rough set approach, interval-valued information systems have been extensively studied. Authors could establish many binary relations from the same interval-valued information system. In this paper, we do some researches on comparing these binary relations so as to provide numerical scales for choosing suitable relations in dealing with interval-valued information systems. Firstly, based on similarity degrees, we compare the most common three binary relations induced from the same interval-valued information system. Secondly, we propose the concepts of transitive degree and cluster degree, and investigate their properties. Finally, we provide some methods to compare binary relations by means of the transitive degree and the cluster degree. Furthermore, we use these methods to analyze the most common three relations induced from Face Recognition Dataset, and obtain that $RF_{B} ^{\lambda}$ is a good choice when we deal with an interval-valued information system by means of rough set approach.
Mind The Gap: Alleviating Local Imbalance for Unsupervised Cross-Modality Medical Image Segmentation
May 24, 2022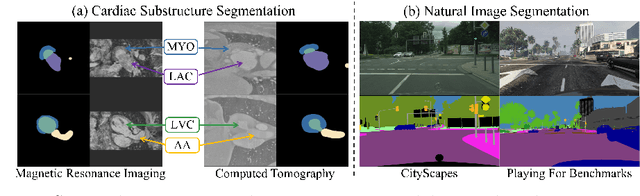
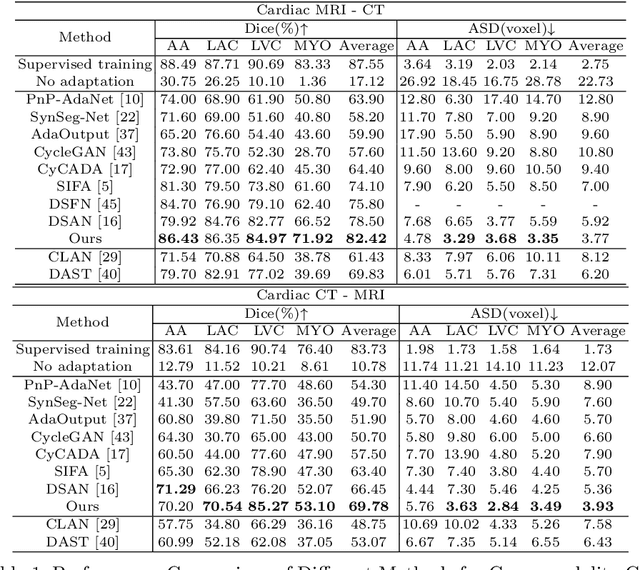

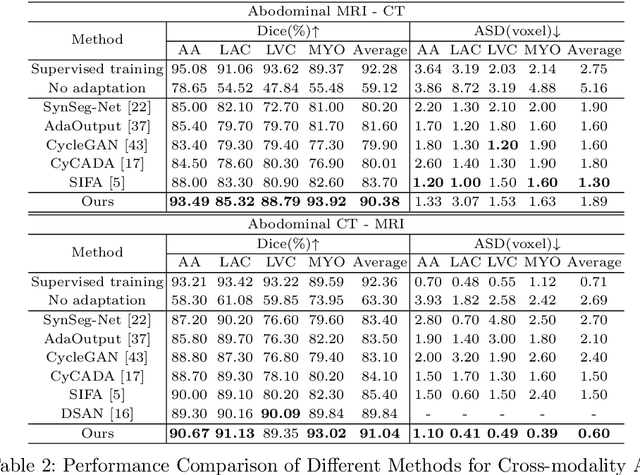
Unsupervised cross-modality medical image adaptation aims to alleviate the severe domain gap between different imaging modalities without using the target domain label. A key in this campaign relies upon aligning the distributions of source and target domain. One common attempt is to enforce the global alignment between two domains, which, however, ignores the fatal local-imbalance domain gap problem, i.e., some local features with larger domain gap are harder to transfer. Recently, some methods conduct alignment focusing on local regions to improve the efficiency of model learning. While this operation may cause a deficiency of critical information from contexts. To tackle this limitation, we propose a novel strategy to alleviate the domain gap imbalance considering the characteristics of medical images, namely Global-Local Union Alignment. Specifically, a feature-disentanglement style-transfer module first synthesizes the target-like source-content images to reduce the global domain gap. Then, a local feature mask is integrated to reduce the 'inter-gap' for local features by prioritizing those discriminative features with larger domain gap. This combination of global and local alignment can precisely localize the crucial regions in segmentation target while preserving the overall semantic consistency. We conduct a series of experiments with two cross-modality adaptation tasks, i,e. cardiac substructure and abdominal multi-organ segmentation. Experimental results indicate that our method exceeds the SOTA methods by 3.92% Dice score in MRI-CT cardiac segmentation and 3.33% in the reverse direction.
AI Annotated Recommendations in an Efficient Visual Learning Environment with Emphasis on YouTube (AI-EVL)
Mar 10, 2022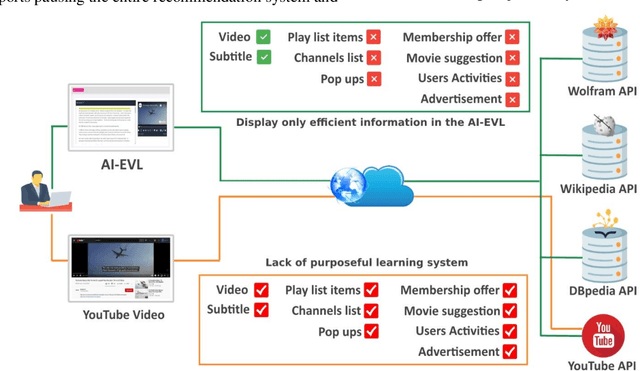
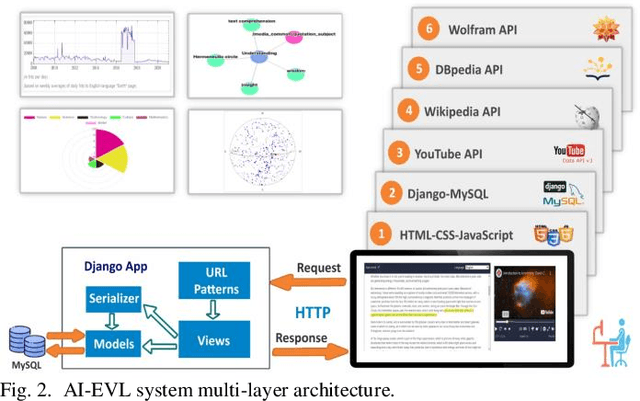
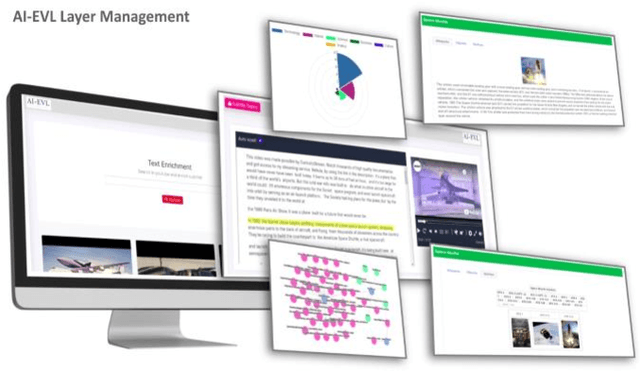
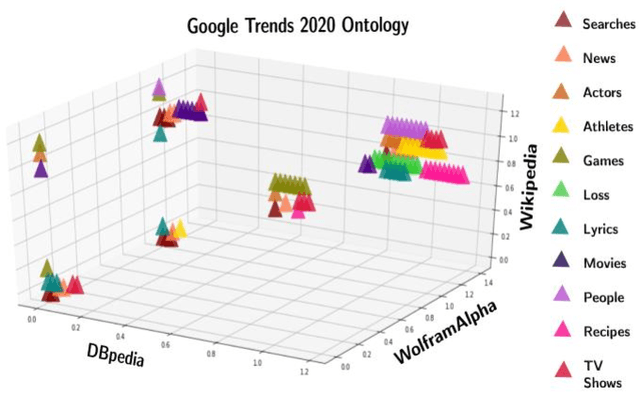
In this article, we create a system called AI-EVL. This is an annotated-based learning system. We extend AI to learning experience. If a user from the main YouTube page browses YouTube videos and a user from the AI-EVL system does the same, the amount of traffic used will be much less. It is due to ignoring unwanted contents which indicates a reduction in bandwidth usage too. This system is designed to be embedded with online learning tools and platforms to enrich their curriculum. In evaluating the system using Google 2020 trend data, we were able to extract rich ontological information for each data. Of the data collected, 34.86% belong to wolfram, 30.41% to DBpedia, and 34.73% to Wikipedia. The video subtitle information is displayed interactively and functionally to the user over time as the video is played. This effective visual learning system, due to the unique features, prevents the user's distraction and makes learning more focused. The information about the subtitle text is displayed in multiple layers including AI-annotated topics, Wikipedia/DBpedia, and Wolfram enriched texts via interactive and visual widgets.
TruthBot: An Automated Conversational Tool for Intent Learning, Curated Information Presenting, and Fake News Alerting
Jan 31, 2021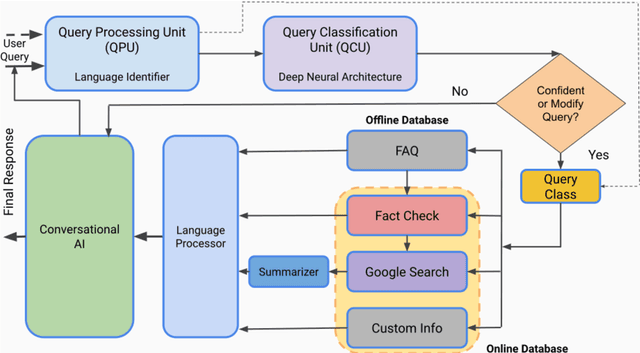
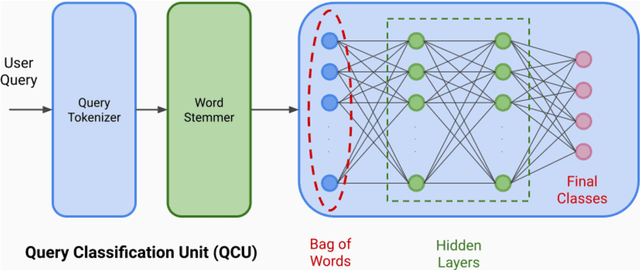
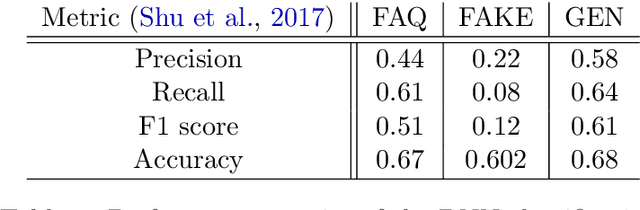

We present TruthBot, an all-in-one multilingual conversational chatbot designed for seeking truth (trustworthy and verified information) on specific topics. It helps users to obtain information specific to certain topics, fact-check information, and get recent news. The chatbot learns the intent of a query by training a deep neural network from the data of the previous intents and responds appropriately when it classifies the intent in one of the classes above. Each class is implemented as a separate module that uses either its own curated knowledge-base or searches the web to obtain the correct information. The topic of the chatbot is currently set to COVID-19. However, the bot can be easily customized to any topic-specific responses. Our experimental results show that each module performs significantly better than its closest competitor, which is verified both quantitatively and through several user-based surveys in multiple languages. TruthBot has been deployed in June 2020 and is currently running.