 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning from the Best: Rationalizing Prediction by Adversarial Information Calibration
Dec 18, 2020
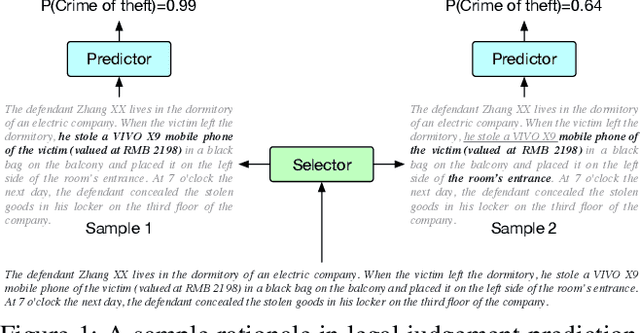
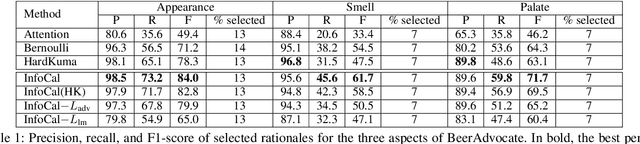

Explaining the predictions of AI models is paramount in safety-critical applications, such as in legal or medical domains. One form of explanation for a prediction is an extractive rationale, i.e., a subset of features of an instance that lead the model to give its prediction on the instance. Previous works on generating extractive rationales usually employ a two-phase model: a selector that selects the most important features (i.e., the rationale) followed by a predictor that makes the prediction based exclusively on the selected features. One disadvantage of these works is that the main signal for learning to select features comes from the comparison of the answers given by the predictor and the ground-truth answers. In this work, we propose to squeeze more information from the predictor via an information calibration method. More precisely, we train two models jointly: one is a typical neural model that solves the task at hand in an accurate but black-box manner, and the other is a selector-predictor model that additionally produces a rationale for its prediction. The first model is used as a guide to the second model. We use an adversarial-based technique to calibrate the information extracted by the two models such that the difference between them is an indicator of the missed or over-selected features. In addition, for natural language tasks, we propose to use a language-model-based regularizer to encourage the extraction of fluent rationales. Experimental results on a sentiment analysis task as well as on three tasks from the legal domain show the effectiveness of our approach to rationale extraction.
ACVNet: Attention Concatenation Volume for Accurate and Efficient Stereo Matching
Mar 19, 2022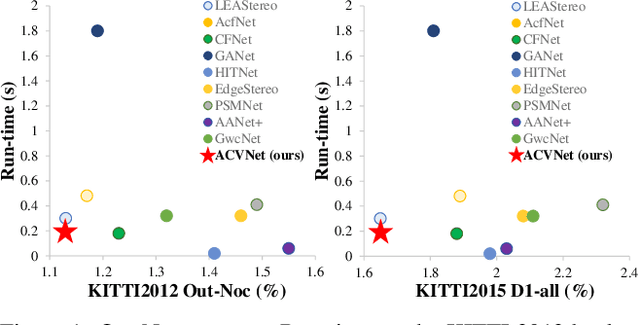
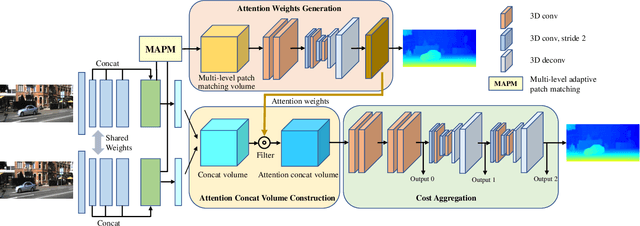
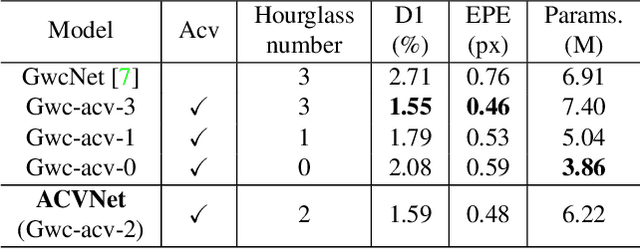
Stereo matching is a fundamental building block for many vision and robotics applications. An informative and concise cost volume representation is vital for stereo matching of high accuracy and efficiency. In this paper, we present a novel cost volume construction method which generates attention weights from correlation clues to suppress redundant information and enhance matching-related information in the concatenation volume. To generate reliable attention weights, we propose multi-level adaptive patch matching to improve the distinctiveness of the matching cost at different disparities even for textureless regions. The proposed cost volume is named attention concatenation volume (ACV) which can be seamlessly embedded into most stereo matching networks, the resulting networks can use a more lightweight aggregation network and meanwhile achieve higher accuracy, e.g. using only 1/25 parameters of the aggregation network can achieve higher accuracy for GwcNet. Furthermore, we design a highly accurate network (ACVNet) based on our ACV, which achieves state-of-the-art performance on several benchmarks.
Attention-based Multimodal Feature Representation Model for Micro-video Recommendation
May 18, 2022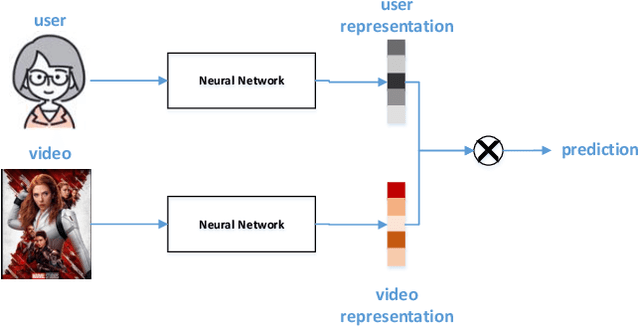
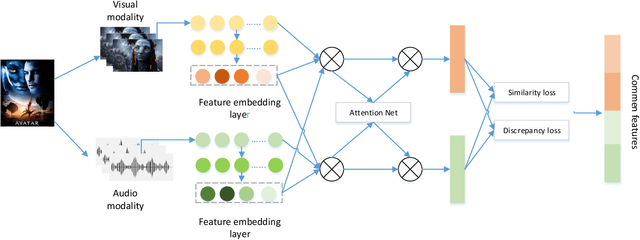
In recommender systems, models mostly use a combination of embedding layers and multilayer feedforward neural networks. The high-dimensional sparse original features are downscaled in the embedding layer and then fed into the fully connected network to obtain prediction results. However, the above methods have a rather obvious problem, that is, the features directly input are treated as independent individuals, and in fact there are internal correlations between features and features, and even different features have different importance in the recommendation. In this regard, this paper adopts a self-attentive mechanism to mine the internal correlations between features as well as their relative importance. In recent years, as a special form of attention mechanism, self-attention mechanism is favored by many researchers. The self-attentive mechanism captures the internal correlation of data or features by learning itself, thus reducing the dependence on external sources. Therefore, this paper adopts a multi-headed self-attentive mechanism to mine the internal correlations between features and thus learn the internal representation of features. At the same time, considering the rich information often hidden between features, the new feature representation obtained by crossover between the two is likely to imply the new description of the user likes the item. However, not all crossover features are meaningful, i.e., there is a problem of limited expression of feature combinations. Therefore, this paper adopts an attention-based approach to learn the external cross-representation of features.
Local Hypergraph-based Nested Named Entity Recognition as Query-based Sequence Labeling
May 04, 2022

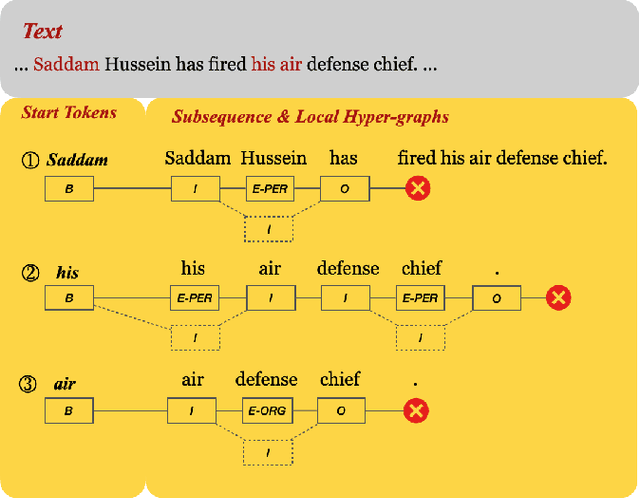
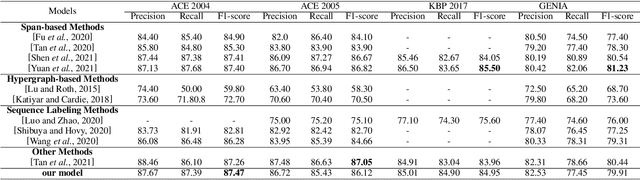
There has been a growing academic interest in the recognition of nested named entities in many domains. We tackle the task with a novel local hypergraph-based method: We first propose start token candidates and generate corresponding queries with their surrounding context, then use a query-based sequence labeling module to form a local hypergraph for each candidate. An end token estimator is used to correct the hypergraphs and get the final predictions. Compared to span-based approaches, our method is free of the high computation cost of span sampling and the risk of losing long entities. Sequential prediction makes it easier to leverage information in word order inside nested structures, and richer representations are built with a local hypergraph. Experiments show that our proposed method outperforms all the previous hypergraph-based and sequence labeling approaches with large margins on all four nested datasets. It achieves a new state-of-the-art F1 score on the ACE 2004 dataset and competitive F1 scores with previous state-of-the-art methods on three other nested NER datasets: ACE 2005, GENIA, and KBP 2017.
Reclaiming saliency: rhythmic precision-modulated action and perception
Mar 23, 2022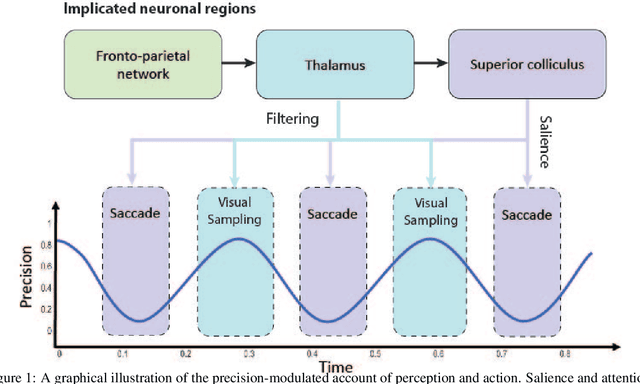
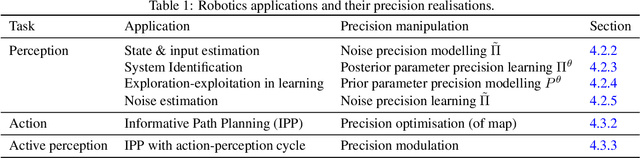

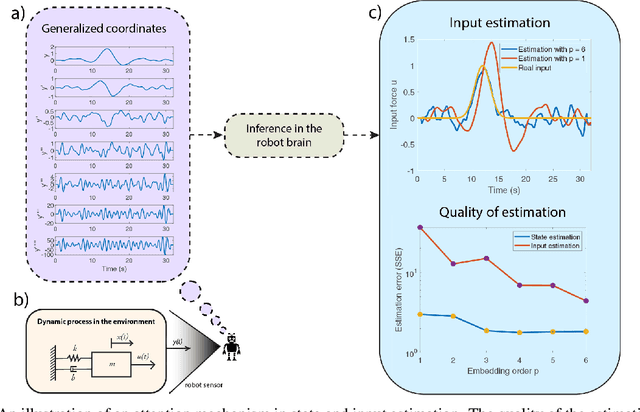
Computational models of visual attention in artificial intelligence and robotics have been inspired by the concept of a saliency map. These models account for the mutual information between the (current) visual information and its estimated causes. However, they fail to consider the circular causality between perception and action. In other words, they do not consider where to sample next, given current beliefs. Here, we reclaim salience as an active inference process that relies on two basic principles: uncertainty minimisation and rhythmic scheduling. For this, we make a distinction between attention and salience. Briefly, we associate attention with precision control, i.e., the confidence with which beliefs can be updated given sampled sensory data, and salience with uncertainty minimisation that underwrites the selection of future sensory data. Using this, we propose a new account of attention based on rhythmic precision-modulation and discuss its potential in robotics, providing numerical experiments that showcase advantages of precision-modulation for state and noise estimation, system identification and action selection for informative path planning.
UNet#: A UNet-like Redesigning Skip Connections for Medical Image Segmentation
May 24, 2022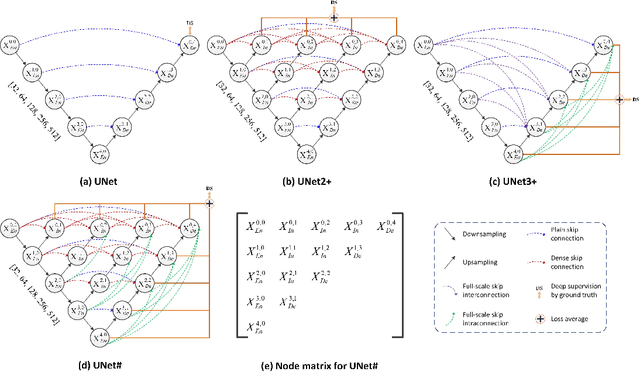
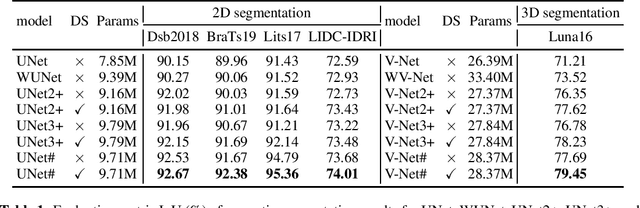
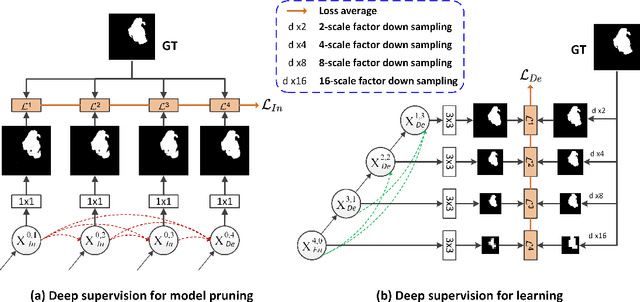
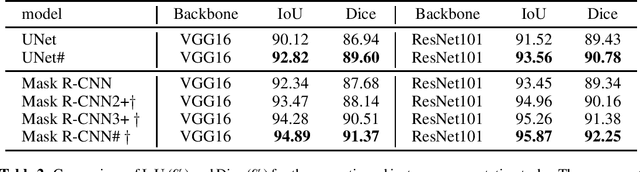
As an essential prerequisite for developing a medical intelligent assistant system, medical image segmentation has received extensive research and concentration from the neural network community. A series of UNet-like networks with encoder-decoder architecture has achieved extraordinary success, in which UNet2+ and UNet3+ redesign skip connections, respectively proposing dense skip connection and full-scale skip connection and dramatically improving compared with UNet in medical image segmentation. However, UNet2+ lacks sufficient information explored from the full scale, which will affect the learning of organs' location and boundary. Although UNet3+ can obtain the full-scale aggregation feature map, owing to the small number of neurons in the structure, it does not satisfy the segmentation of tiny objects when the number of samples is small. This paper proposes a novel network structure combining dense skip connections and full-scale skip connections, named UNet-sharp (UNet\#) for its shape similar to symbol \#. The proposed UNet\# can aggregate feature maps of different scales in the decoder sub-network and capture fine-grained details and coarse-grained semantics from the full scale, which benefits learning the exact location and accurately segmenting the boundary of organs or lesions. We perform deep supervision for model pruning to speed up testing and make it possible for the model to run on mobile devices; furthermore, designing two classification-guided modules to reduce false positives achieves more accurate segmentation results. Various experiments of semantic segmentation and instance segmentation on different modalities (EM, CT, MRI) and dimensions (2D, 3D) datasets, including the nuclei, brain tumor, liver, and lung, demonstrate that the proposed method outperforms state-of-the-art models.
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022
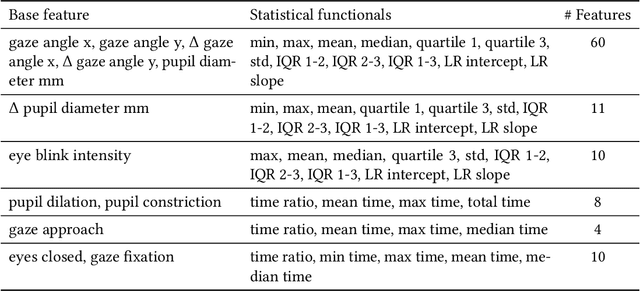

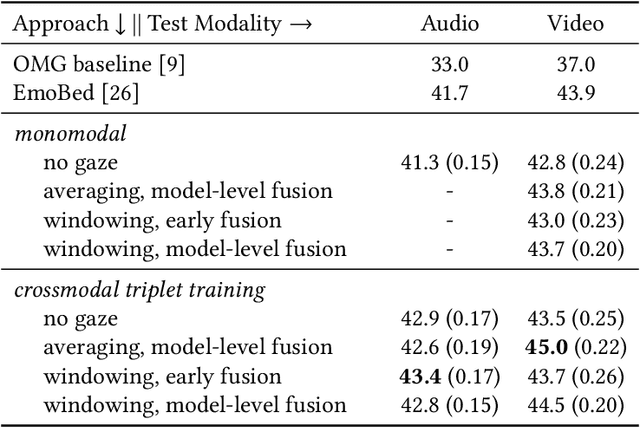
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.
Learning-by-Narrating: Narrative Pre-Training for Zero-Shot Dialogue Comprehension
Mar 19, 2022

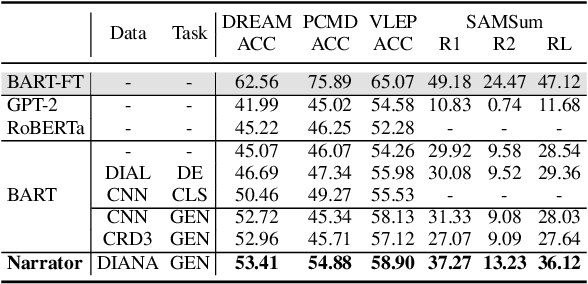
Comprehending a dialogue requires a model to capture diverse kinds of key information in the utterances, which are either scattered around or implicitly implied in different turns of conversations. Therefore, dialogue comprehension requires diverse capabilities such as paraphrasing, summarizing, and commonsense reasoning. Towards the objective of pre-training a zero-shot dialogue comprehension model, we develop a novel narrative-guided pre-training strategy that learns by narrating the key information from a dialogue input. However, the dialogue-narrative parallel corpus for such a pre-training strategy is currently unavailable. For this reason, we first construct a dialogue-narrative parallel corpus by automatically aligning movie subtitles and their synopses. We then pre-train a BART model on the data and evaluate its performance on four dialogue-based tasks that require comprehension. Experimental results show that our model not only achieves superior zero-shot performance but also exhibits stronger fine-grained dialogue comprehension capabilities. The data and code are available at https://github.com/zhaochaocs/Diana
Graph Auto-Encoders for Network Completion
Apr 25, 2022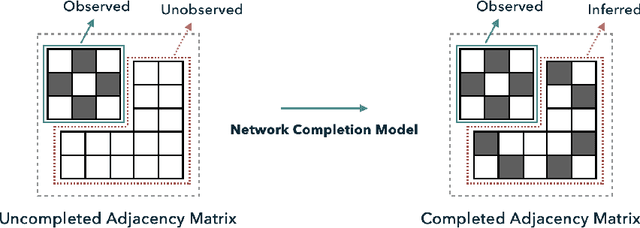
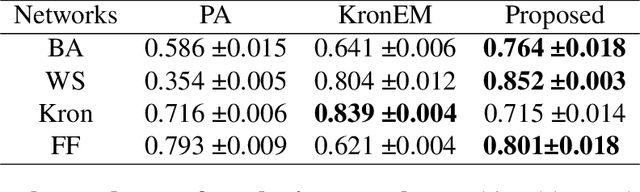
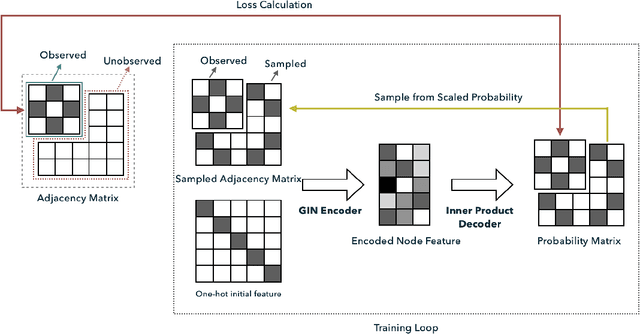
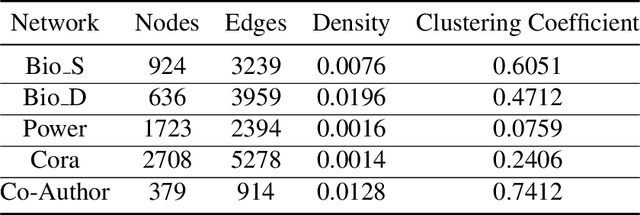
Completing a graph means inferring the missing nodes and edges from a partially observed network. Different methods have been proposed to solve this problem, but none of them employed the pattern similarity of parts of the graph. In this paper, we propose a model to use the learned pattern of connections from the observed part of the network based on the Graph Auto-Encoder technique and generalize these patterns to complete the whole graph. Our proposed model achieved competitive performance with less information needed. Empirical analysis of synthetic datasets and real-world datasets from different domains show that our model can complete the network with higher accuracy compared with baseline prediction models in most cases. Furthermore, we also studied the character of the model and found it is particularly suitable to complete a network that has more complex local connection patterns.
Efficient Linear Attention for Fast and Accurate Keypoint Matching
Apr 22, 2022
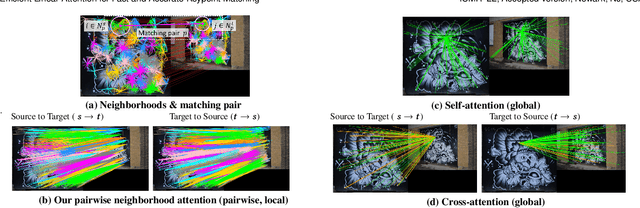
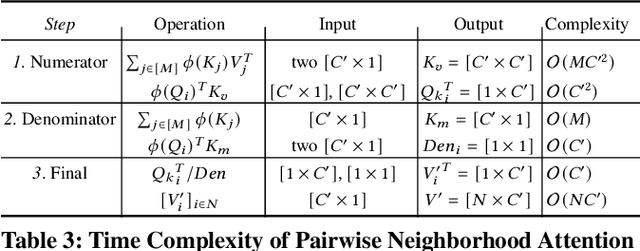
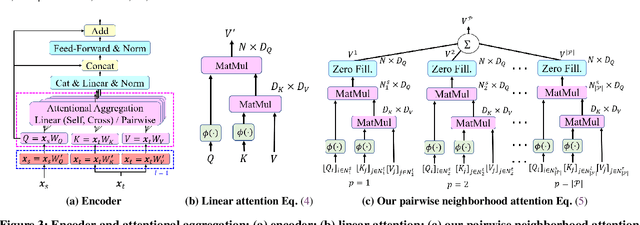
Recently Transformers have provided state-of-the-art performance in sparse matching, crucial to realize high-performance 3D vision applications. Yet, these Transformers lack efficiency due to the quadratic computational complexity of their attention mechanism. To solve this problem, we employ an efficient linear attention for the linear computational complexity. Then, we propose a new attentional aggregation that achieves high accuracy by aggregating both the global and local information from sparse keypoints. To further improve the efficiency, we propose the joint learning of feature matching and description. Our learning enables simpler and faster matching than Sinkhorn, often used in matching the learned descriptors from Transformers. Our method achieves competitive performance with only 0.84M learnable parameters against the bigger SOTAs, SuperGlue (12M parameters) and SGMNet (30M parameters), on three benchmarks, HPatch, ETH, and Aachen Day-Night.