 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explaining Classifiers by Constructing Familiar Concepts
Mar 07, 2022
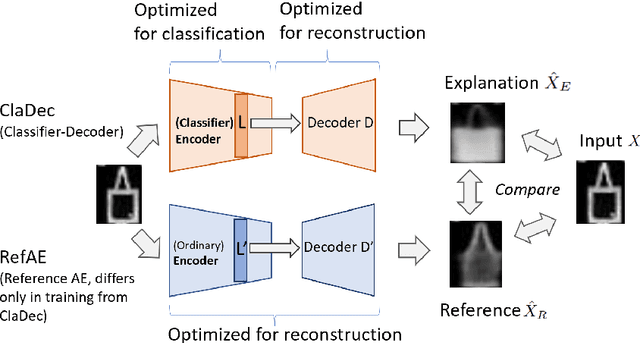
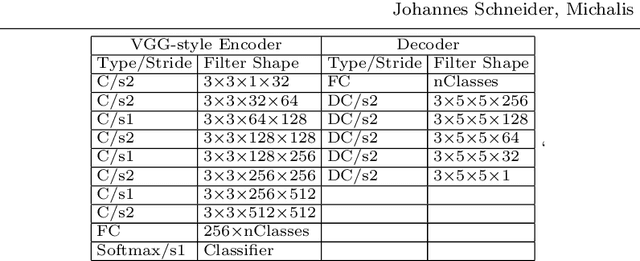
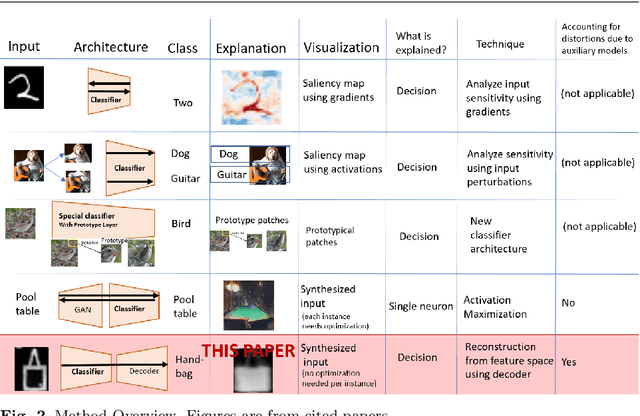
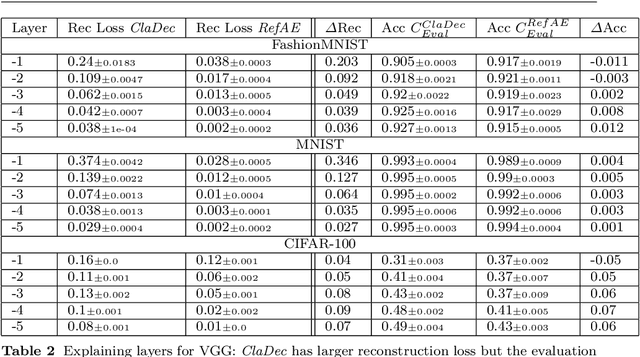
Interpreting a large number of neurons in deep learning is difficult. Our proposed `CLAssifier-DECoder' architecture (ClaDec) facilitates the understanding of the output of an arbitrary layer of neurons or subsets thereof. It uses a decoder that transforms the incomprehensible representation of the given neurons to a representation that is more similar to the domain a human is familiar with. In an image recognition problem, one can recognize what information (or concepts) a layer maintains by contrasting reconstructed images of ClaDec with those of a conventional auto-encoder(AE) serving as reference. An extension of ClaDec allows trading comprehensibility and fidelity. We evaluate our approach for image classification using convolutional neural networks. We show that reconstructed visualizations using encodings from a classifier capture more relevant classification information than conventional AEs. This holds although AEs contain more information on the original input. Our user study highlights that even non-experts can identify a diverse set of concepts contained in images that are relevant (or irrelevant) for the classifier. We also compare against saliency based methods that focus on pixel relevance rather than concepts. We show that ClaDec tends to highlight more relevant input areas to classification though outcomes depend on classifier architecture. Code is at \url{https://github.com/JohnTailor/ClaDec}
GDSRec: Graph-Based Decentralized Collaborative Filtering for Social Recommendation
May 20, 2022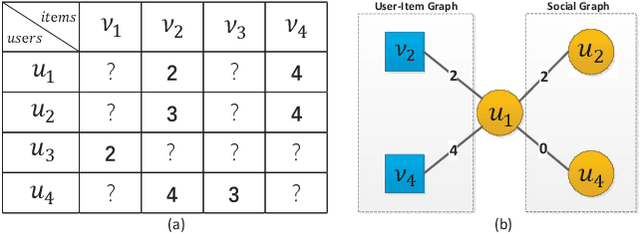
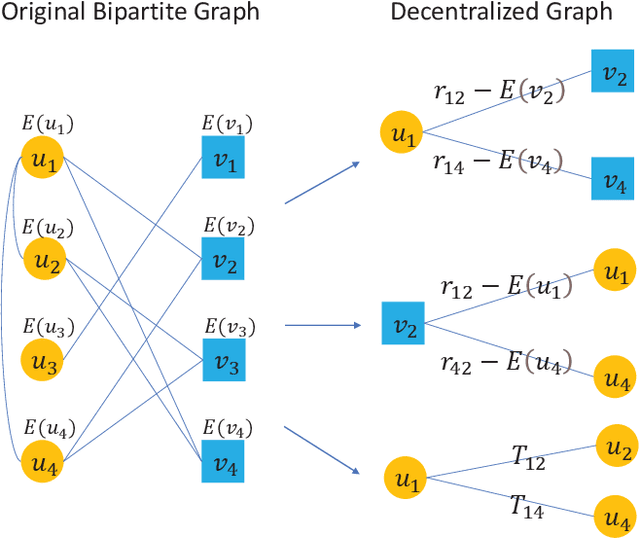
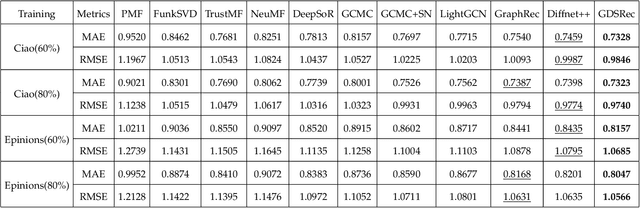
Generating recommendations based on user-item interactions and user-user social relations is a common use case in web-based systems. These connections can be naturally represented as graph-structured data and thus utilizing graph neural networks (GNNs) for social recommendation has become a promising research direction. However, existing graph-based methods fails to consider the bias offsets of users (items). For example, a low rating from a fastidious user may not imply a negative attitude toward this item because the user tends to assign low ratings in common cases. Such statistics should be considered into the graph modeling procedure. While some past work considers the biases, we argue that these proposed methods only treat them as scalars and can not capture the complete bias information hidden in data. Besides, social connections between users should also be differentiable so that users with similar item preference would have more influence on each other. To this end, we propose Graph-Based Decentralized Collaborative Filtering for Social Recommendation (GDSRec). GDSRec treats the biases as vectors and fuses them into the process of learning user and item representations. The statistical bias offsets are captured by decentralized neighborhood aggregation while the social connection strength is defined according to the preference similarity and then incorporated into the model design. We conduct extensive experiments on two benchmark datasets to verify the effectiveness of the proposed model. Experimental results show that the proposed GDSRec achieves superior performance compared with state-of-the-art related baselines. Our implementations are available in \url{https://github.com/MEICRS/GDSRec}.
Unifying Motion Deblurring and Frame Interpolation with Events
Mar 23, 2022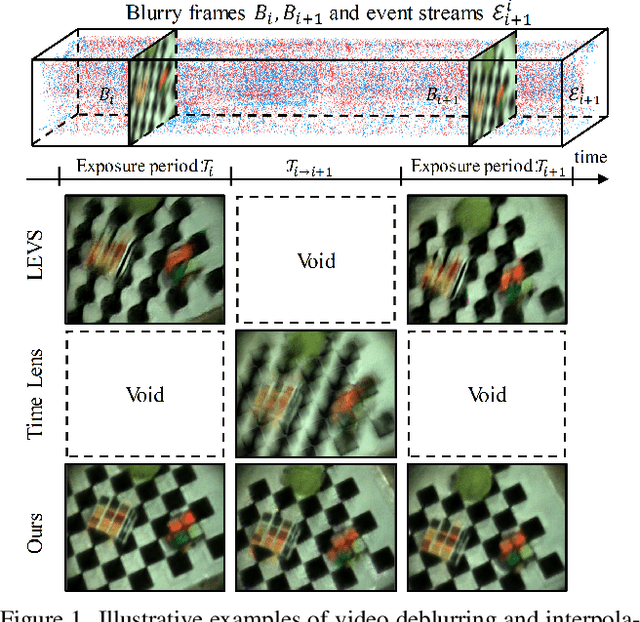
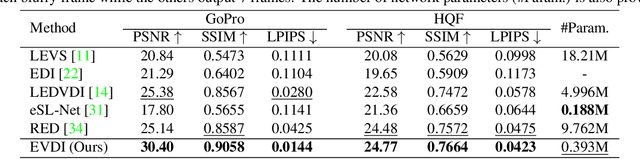
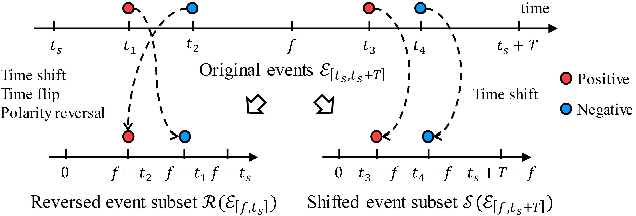
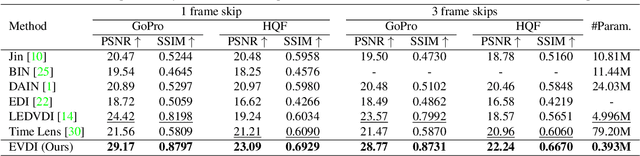
Slow shutter speed and long exposure time of frame-based cameras often cause visual blur and loss of inter-frame information, degenerating the overall quality of captured videos. To this end, we present a unified framework of event-based motion deblurring and frame interpolation for blurry video enhancement, where the extremely low latency of events is leveraged to alleviate motion blur and facilitate intermediate frame prediction. Specifically, the mapping relation between blurry frames and sharp latent images is first predicted by a learnable double integral network, and a fusion network is then proposed to refine the coarse results via utilizing the information from consecutive blurry inputs and the concurrent events. By exploring the mutual constraints among blurry frames, latent images, and event streams, we further propose a self-supervised learning framework to enable network training with real-world blurry videos and events. Extensive experiments demonstrate that our method compares favorably against the state-of-the-art approaches and achieves remarkable performance on both synthetic and real-world datasets.
Lightweight Hybrid CNN-ELM Model for Multi-building and Multi-floor Classification
Apr 21, 2022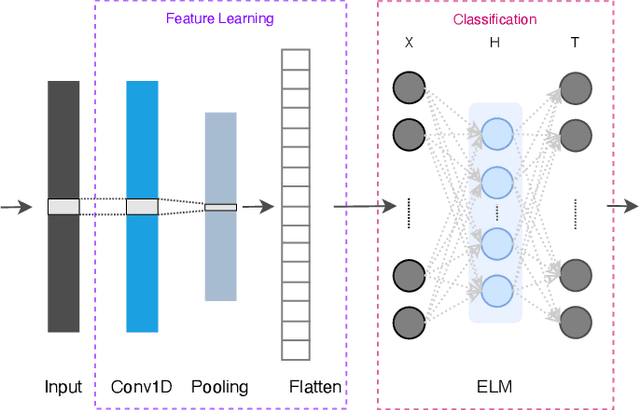
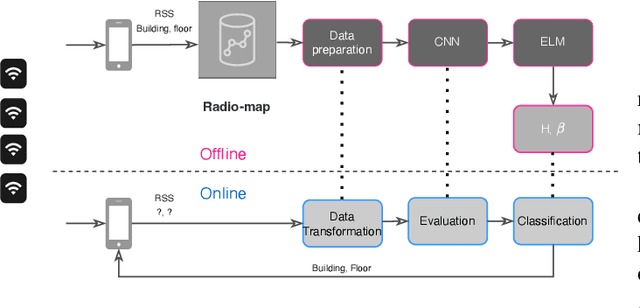
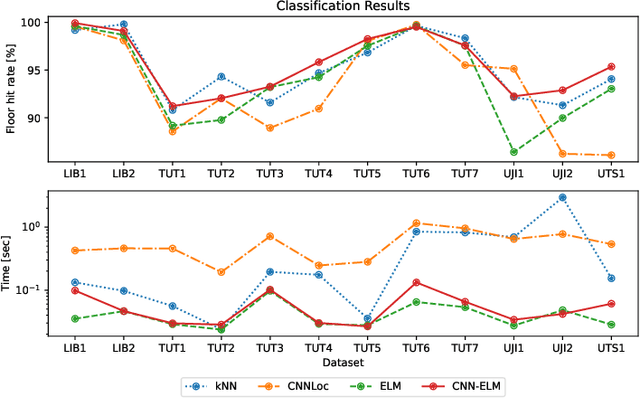
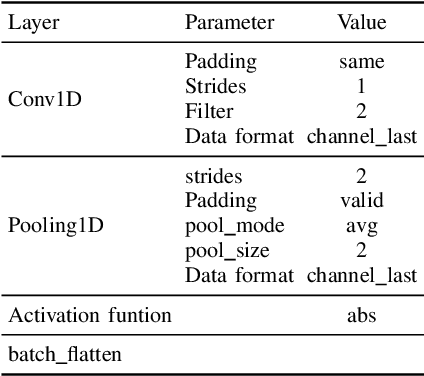
Machine learning models have become an essential tool in current indoor positioning solutions, given their high capabilities to extract meaningful information from the environment. Convolutional neural networks (CNNs) are one of the most used neural networks (NNs) due to that they are capable of learning complex patterns from the input data. Another model used in indoor positioning solutions is the Extreme Learning Machine (ELM), which provides an acceptable generalization performance as well as a fast speed of learning. In this paper, we offer a lightweight combination of CNN and ELM, which provides a quick and accurate classification of building and floor, suitable for power and resource-constrained devices. As a result, the proposed model is 58\% faster than the benchmark, with a slight improvement in the classification accuracy (by less than 1\%
BronchusNet: Region and Structure Prior Embedded Representation Learning for Bronchus Segmentation and Classification
May 14, 2022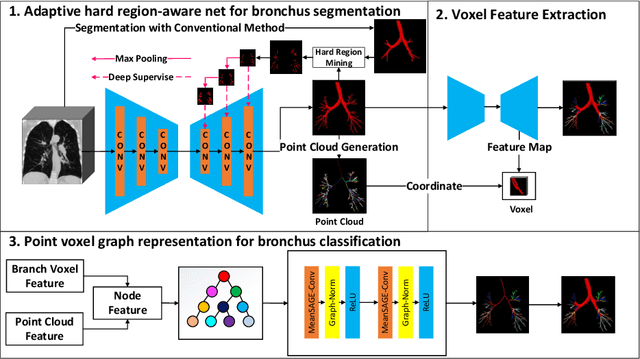


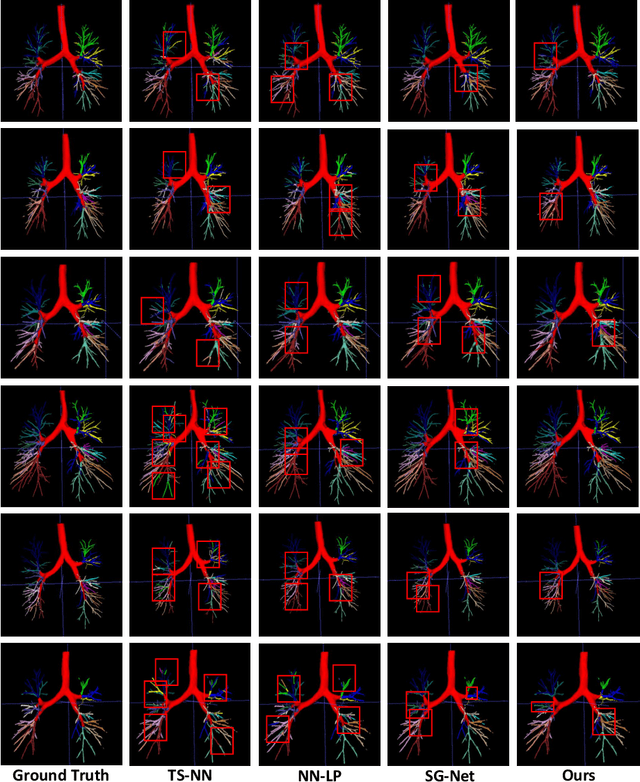
CT-based bronchial tree analysis plays an important role in the computer-aided diagnosis for respiratory diseases, as it could provide structured information for clinicians. The basis of airway analysis is bronchial tree reconstruction, which consists of bronchus segmentation and classification. However, there remains a challenge for accurate bronchial analysis due to the individual variations and the severe class imbalance. In this paper, we propose a region and structure prior embedded framework named BronchusNet to achieve accurate segmentation and classification of bronchial regions in CT images. For bronchus segmentation, we propose an adaptive hard region-aware UNet that incorporates multi-level prior guidance of hard pixel-wise samples in the general Unet segmentation network to achieve better hierarchical feature learning. For the classification of bronchial branches, we propose a hybrid point-voxel graph learning module to fully exploit bronchial structure priors and to support simultaneous feature interactions across different branches. To facilitate the study of bronchial analysis, we contribute~\textbf{BRSC}: an open-access benchmark of \textbf{BR}onchus imaging analysis with high-quality pixel-wise \textbf{S}egmentation masks and the \textbf{C}lass of bronchial segments. Experimental results on BRSC show that our proposed method not only achieves the state-of-the-art performance for binary segmentation of bronchial region but also exceeds the best existing method on bronchial branches classification by 6.9\%.
Improved Orientation Estimation and Detection with Hybrid Object Detection Networks for Automotive Radar
May 03, 2022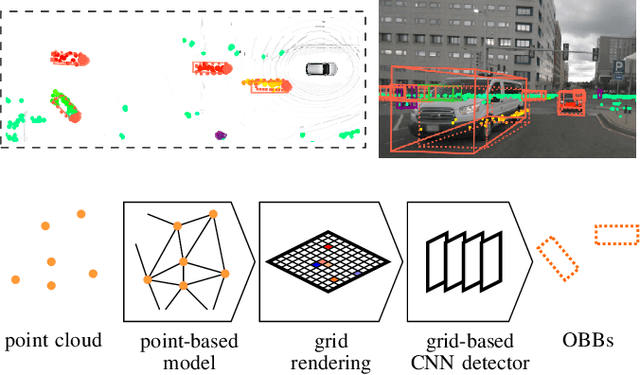


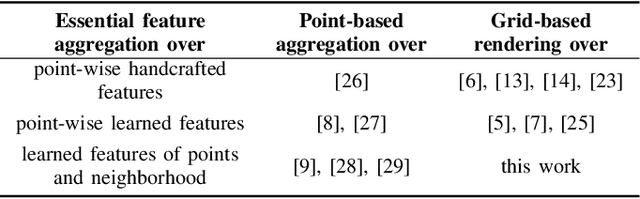
This paper presents novel hybrid architectures that combine grid- and point-based processing to improve the detection performance and orientation estimation of radar-based object detection networks. Purely grid-based detection models operate on a bird's-eye-view (BEV) projection of the input point cloud. These approaches suffer from a loss of detailed information through the discrete grid resolution. This applies in particular to radar object detection, where relatively coarse grid resolutions are commonly used to account for the sparsity of radar point clouds. In contrast, point-based models are not affected by this problem as they continuously process point clouds. However, they generally exhibit worse detection performances than grid-based methods. We show that a point-based model can extract neighborhood features, leveraging the exact relative positions of points, before grid rendering. This has significant benefits for a following convolutional detection backbone. In experiments on the public nuScenes dataset our hybrid architecture achieves improvements in terms of detection performance and orientation estimates over networks from previous literature.
Differentiable Zooming for Multiple Instance Learning on Whole-Slide Images
Apr 26, 2022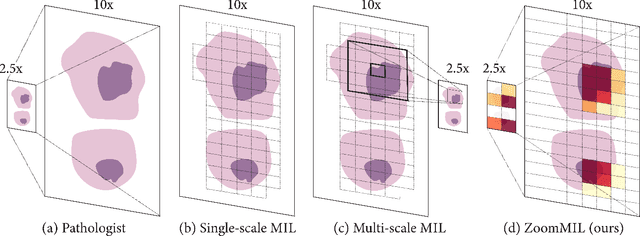
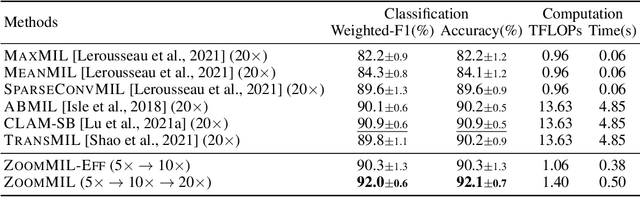
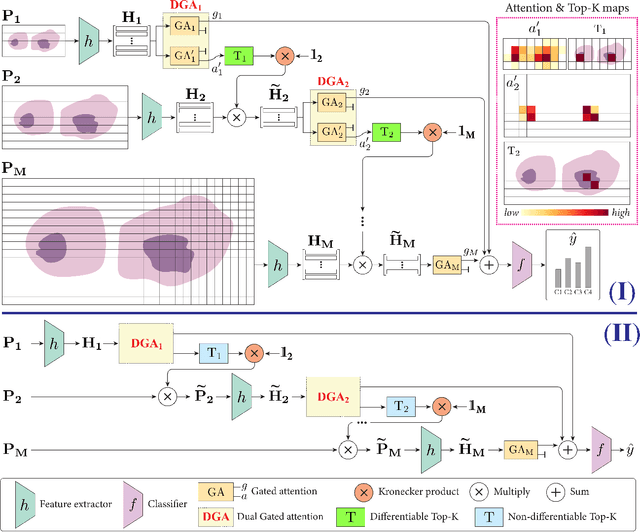
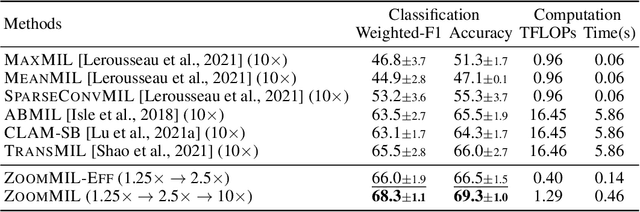
Multiple Instance Learning (MIL) methods have become increasingly popular for classifying giga-pixel sized Whole-Slide Images (WSIs) in digital pathology. Most MIL methods operate at a single WSI magnification, by processing all the tissue patches. Such a formulation induces high computational requirements, and constrains the contextualization of the WSI-level representation to a single scale. A few MIL methods extend to multiple scales, but are computationally more demanding. In this paper, inspired by the pathological diagnostic process, we propose ZoomMIL, a method that learns to perform multi-level zooming in an end-to-end manner. ZoomMIL builds WSI representations by aggregating tissue-context information from multiple magnifications. The proposed method outperforms the state-of-the-art MIL methods in WSI classification on two large datasets, while significantly reducing the computational demands with regard to Floating-Point Operations (FLOPs) and processing time by up to 40x.
BiCo-Net: Regress Globally, Match Locally for Robust 6D Pose Estimation
May 07, 2022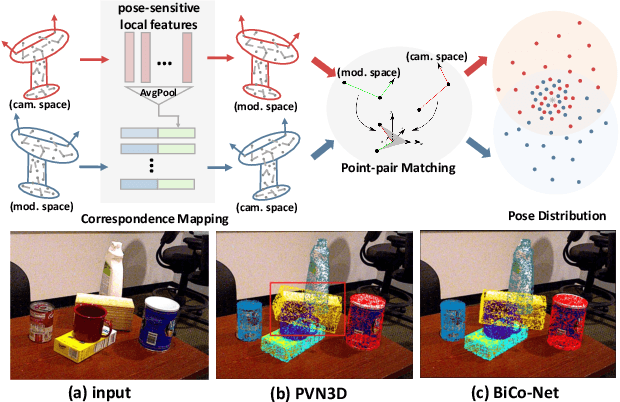
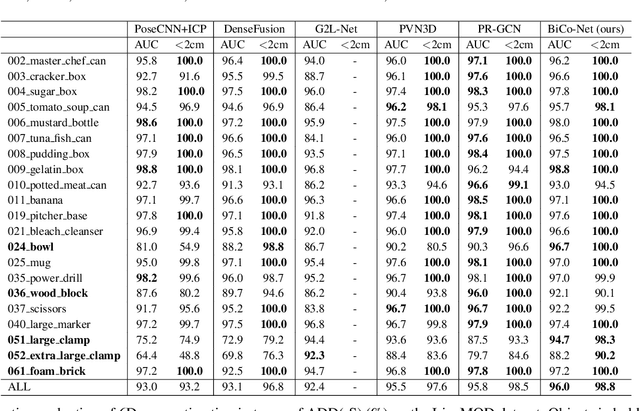
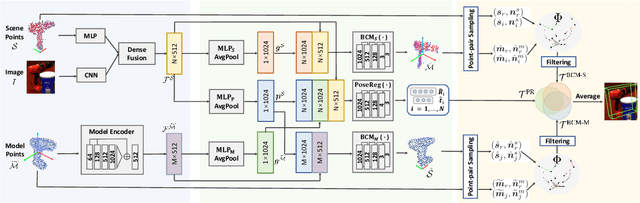

The challenges of learning a robust 6D pose function lie in 1) severe occlusion and 2) systematic noises in depth images. Inspired by the success of point-pair features, the goal of this paper is to recover the 6D pose of an object instance segmented from RGB-D images by locally matching pairs of oriented points between the model and camera space. To this end, we propose a novel Bi-directional Correspondence Mapping Network (BiCo-Net) to first generate point clouds guided by a typical pose regression, which can thus incorporate pose-sensitive information to optimize generation of local coordinates and their normal vectors. As pose predictions via geometric computation only rely on one single pair of local oriented points, our BiCo-Net can achieve robustness against sparse and occluded point clouds. An ensemble of redundant pose predictions from locally matching and direct pose regression further refines final pose output against noisy observations. Experimental results on three popularly benchmarking datasets can verify that our method can achieve state-of-the-art performance, especially for the more challenging severe occluded scenes. Source codes are available at https://github.com/Gorilla-Lab-SCUT/BiCo-Net.
HRel: Filter Pruning based on High Relevance between Activation Maps and Class Labels
Feb 22, 2022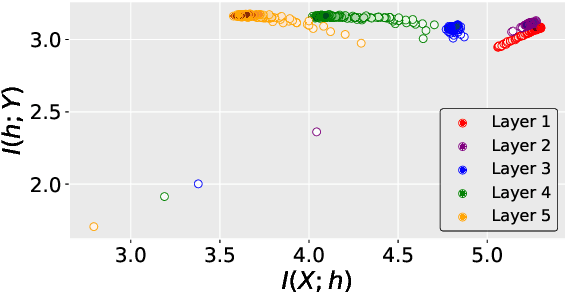
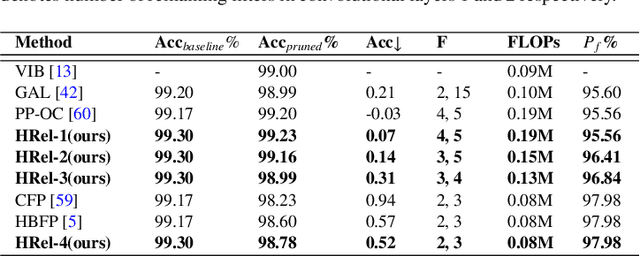
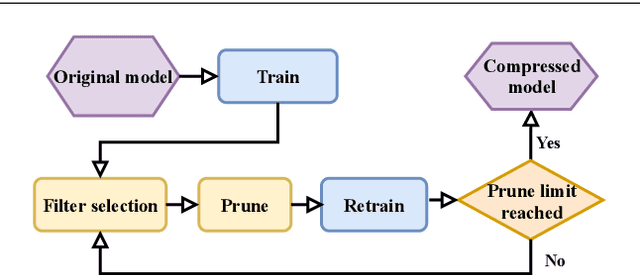
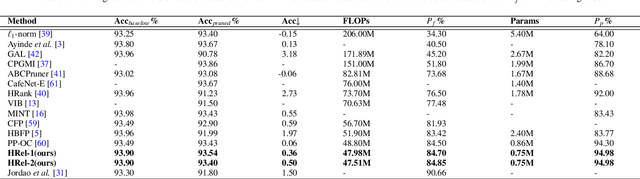
This paper proposes an Information Bottleneck theory based filter pruning method that uses a statistical measure called Mutual Information (MI). The MI between filters and class labels, also called \textit{Relevance}, is computed using the filter's activation maps and the annotations. The filters having High Relevance (HRel) are considered to be more important. Consequently, the least important filters, which have lower Mutual Information with the class labels, are pruned. Unlike the existing MI based pruning methods, the proposed method determines the significance of the filters purely based on their corresponding activation map's relationship with the class labels. Architectures such as LeNet-5, VGG-16, ResNet-56\textcolor{myblue}{, ResNet-110 and ResNet-50 are utilized to demonstrate the efficacy of the proposed pruning method over MNIST, CIFAR-10 and ImageNet datasets. The proposed method shows the state-of-the-art pruning results for LeNet-5, VGG-16, ResNet-56, ResNet-110 and ResNet-50 architectures. In the experiments, we prune 97.98 \%, 84.85 \%, 76.89\%, 76.95\%, and 63.99\% of Floating Point Operation (FLOP)s from LeNet-5, VGG-16, ResNet-56, ResNet-110, and ResNet-50 respectively.} The proposed HRel pruning method outperforms recent state-of-the-art filter pruning methods. Even after pruning the filters from convolutional layers of LeNet-5 drastically (i.e. from 20, 50 to 2, 3, respectively), only a small accuracy drop of 0.52\% is observed. Notably, for VGG-16, 94.98\% parameters are reduced, only with a drop of 0.36\% in top-1 accuracy. \textcolor{myblue}{ResNet-50 has shown a 1.17\% drop in the top-5 accuracy after pruning 66.42\% of the FLOPs.} In addition to pruning, the Information Plane dynamics of Information Bottleneck theory is analyzed for various Convolutional Neural Network architectures with the effect of pruning.
Are Deep Neural Architectures Losing Information? Invertibility Is Indispensable
Sep 07, 2020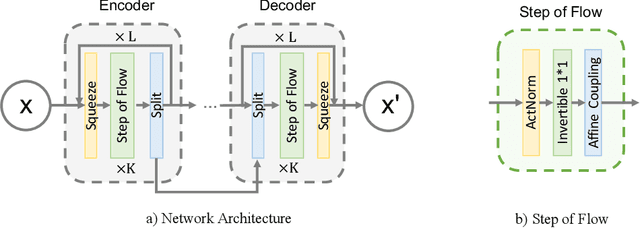
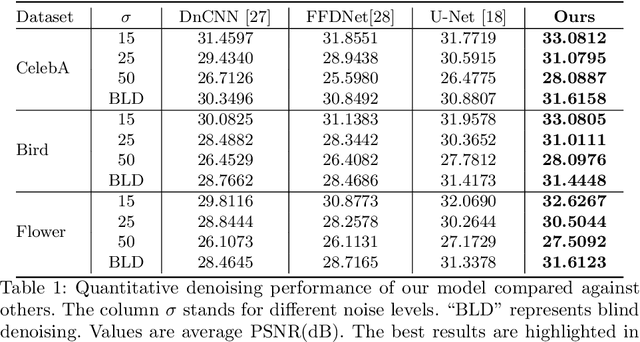

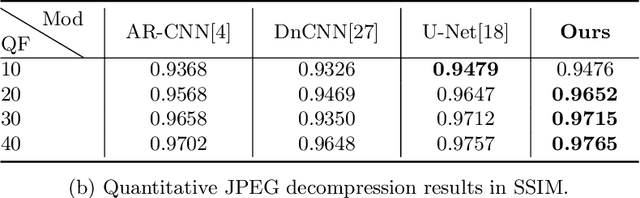
Ever since the advent of AlexNet, designing novel deep neural architectures for different tasks has consistently been a productive research direction. Despite the exceptional performance of various architectures in practice, we study a theoretical question: what is the condition for deep neural architectures to preserve all the information of the input data? Identifying the information lossless condition for deep neural architectures is important, because tasks such as image restoration require keep the detailed information of the input data as much as possible. Using the definition of mutual information, we show that: a deep neural architecture can preserve maximum details about the given data if and only if the architecture is invertible. We verify the advantages of our Invertible Restoring Autoencoder (IRAE) network by comparing it with competitive models on three perturbed image restoration tasks: image denoising, jpeg image decompression and image inpainting. Experimental results show that IRAE consistently outperforms non-invertible ones. Our model even contains far fewer parameters. Thus, it may be worthwhile to try replacing standard components of deep neural architectures, such as residual blocks and ReLU, with their invertible counterparts. We believe our work provides a unique perspective and direction for future deep learning research.