 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022

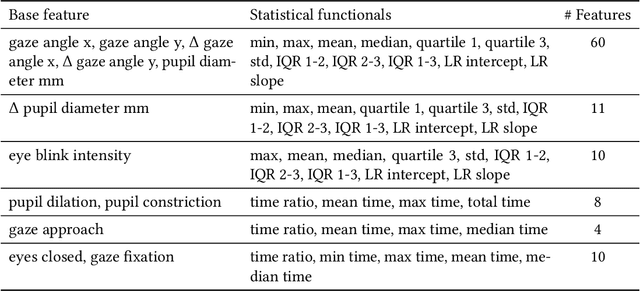

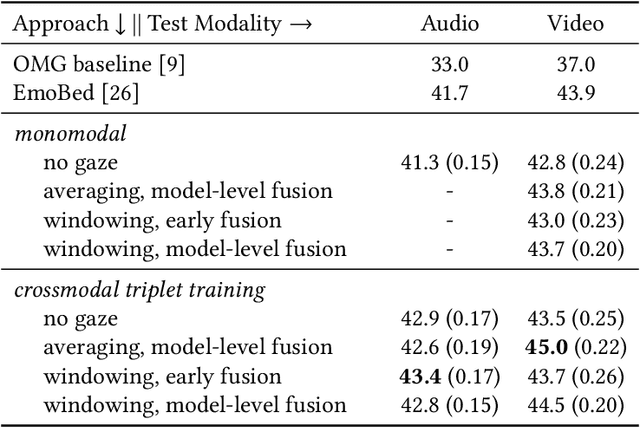
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.
Are Deep Neural Architectures Losing Information? Invertibility Is Indispensable
Sep 07, 2020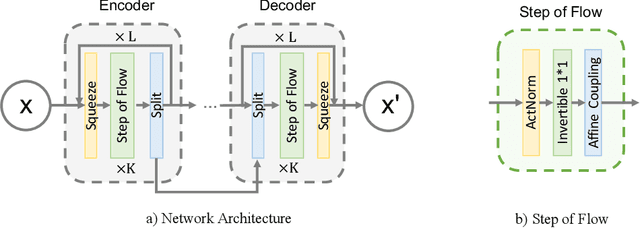
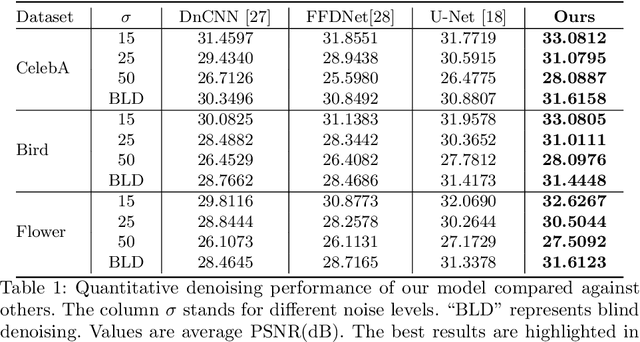

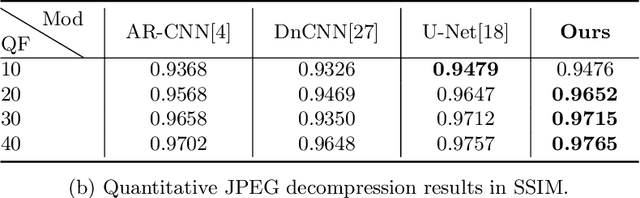
Ever since the advent of AlexNet, designing novel deep neural architectures for different tasks has consistently been a productive research direction. Despite the exceptional performance of various architectures in practice, we study a theoretical question: what is the condition for deep neural architectures to preserve all the information of the input data? Identifying the information lossless condition for deep neural architectures is important, because tasks such as image restoration require keep the detailed information of the input data as much as possible. Using the definition of mutual information, we show that: a deep neural architecture can preserve maximum details about the given data if and only if the architecture is invertible. We verify the advantages of our Invertible Restoring Autoencoder (IRAE) network by comparing it with competitive models on three perturbed image restoration tasks: image denoising, jpeg image decompression and image inpainting. Experimental results show that IRAE consistently outperforms non-invertible ones. Our model even contains far fewer parameters. Thus, it may be worthwhile to try replacing standard components of deep neural architectures, such as residual blocks and ReLU, with their invertible counterparts. We believe our work provides a unique perspective and direction for future deep learning research.
Reclaiming saliency: rhythmic precision-modulated action and perception
Mar 23, 2022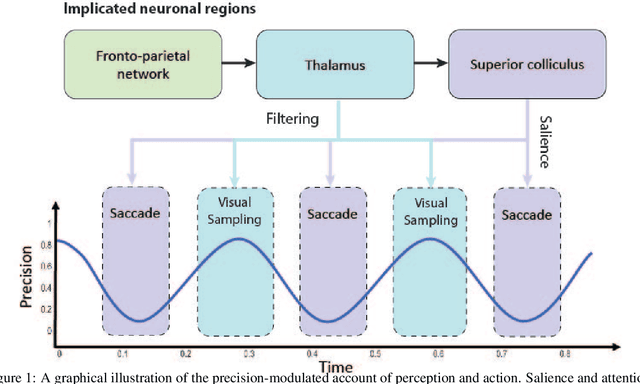
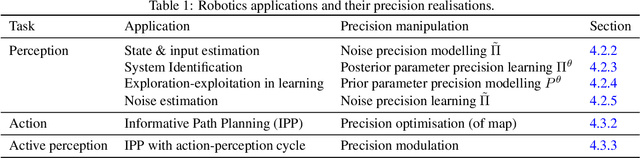

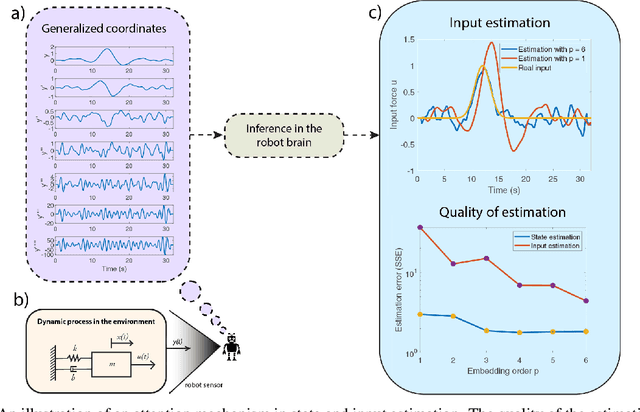
Computational models of visual attention in artificial intelligence and robotics have been inspired by the concept of a saliency map. These models account for the mutual information between the (current) visual information and its estimated causes. However, they fail to consider the circular causality between perception and action. In other words, they do not consider where to sample next, given current beliefs. Here, we reclaim salience as an active inference process that relies on two basic principles: uncertainty minimisation and rhythmic scheduling. For this, we make a distinction between attention and salience. Briefly, we associate attention with precision control, i.e., the confidence with which beliefs can be updated given sampled sensory data, and salience with uncertainty minimisation that underwrites the selection of future sensory data. Using this, we propose a new account of attention based on rhythmic precision-modulation and discuss its potential in robotics, providing numerical experiments that showcase advantages of precision-modulation for state and noise estimation, system identification and action selection for informative path planning.
Graph Auto-Encoders for Network Completion
Apr 25, 2022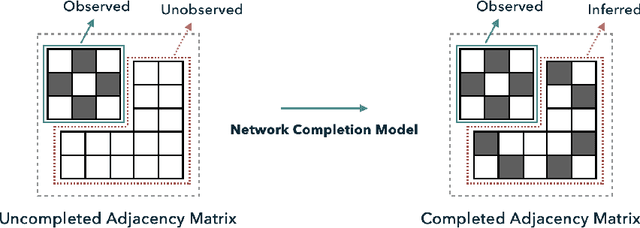
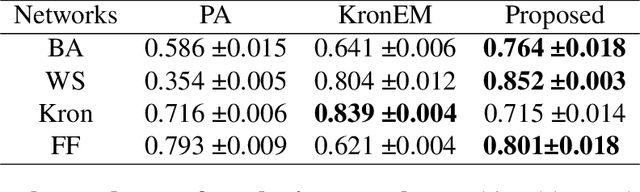
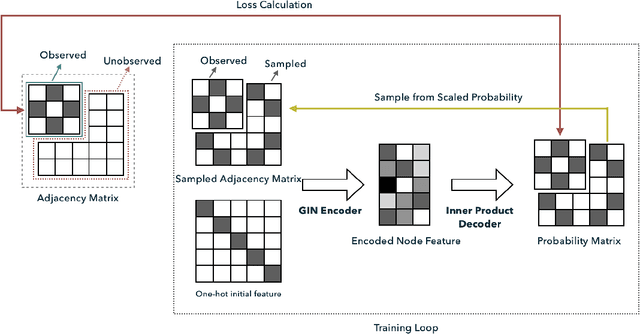
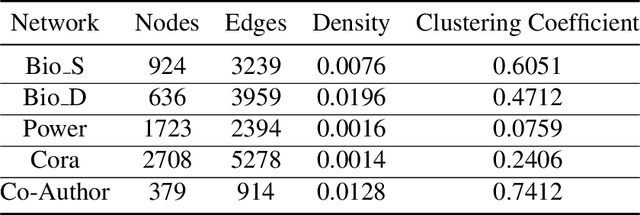
Completing a graph means inferring the missing nodes and edges from a partially observed network. Different methods have been proposed to solve this problem, but none of them employed the pattern similarity of parts of the graph. In this paper, we propose a model to use the learned pattern of connections from the observed part of the network based on the Graph Auto-Encoder technique and generalize these patterns to complete the whole graph. Our proposed model achieved competitive performance with less information needed. Empirical analysis of synthetic datasets and real-world datasets from different domains show that our model can complete the network with higher accuracy compared with baseline prediction models in most cases. Furthermore, we also studied the character of the model and found it is particularly suitable to complete a network that has more complex local connection patterns.
Learning-by-Narrating: Narrative Pre-Training for Zero-Shot Dialogue Comprehension
Mar 19, 2022

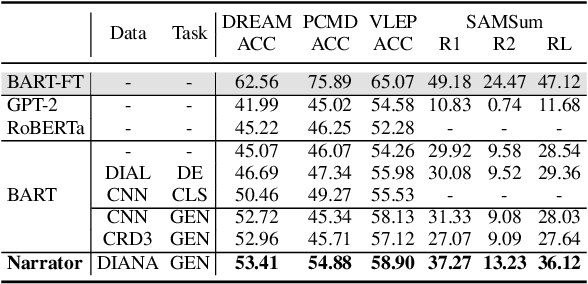
Comprehending a dialogue requires a model to capture diverse kinds of key information in the utterances, which are either scattered around or implicitly implied in different turns of conversations. Therefore, dialogue comprehension requires diverse capabilities such as paraphrasing, summarizing, and commonsense reasoning. Towards the objective of pre-training a zero-shot dialogue comprehension model, we develop a novel narrative-guided pre-training strategy that learns by narrating the key information from a dialogue input. However, the dialogue-narrative parallel corpus for such a pre-training strategy is currently unavailable. For this reason, we first construct a dialogue-narrative parallel corpus by automatically aligning movie subtitles and their synopses. We then pre-train a BART model on the data and evaluate its performance on four dialogue-based tasks that require comprehension. Experimental results show that our model not only achieves superior zero-shot performance but also exhibits stronger fine-grained dialogue comprehension capabilities. The data and code are available at https://github.com/zhaochaocs/Diana
Efficient Linear Attention for Fast and Accurate Keypoint Matching
Apr 22, 2022
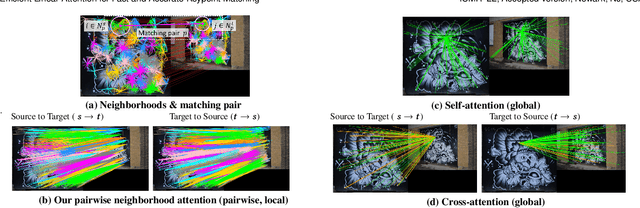
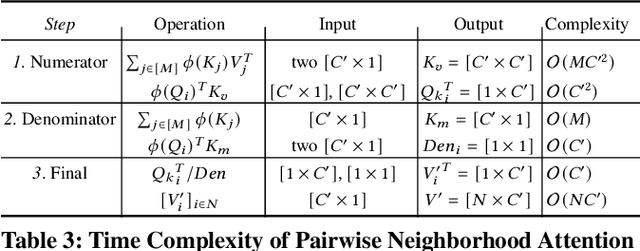
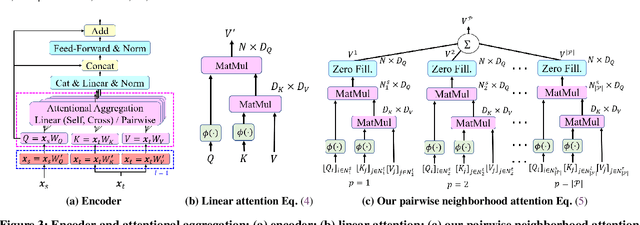
Recently Transformers have provided state-of-the-art performance in sparse matching, crucial to realize high-performance 3D vision applications. Yet, these Transformers lack efficiency due to the quadratic computational complexity of their attention mechanism. To solve this problem, we employ an efficient linear attention for the linear computational complexity. Then, we propose a new attentional aggregation that achieves high accuracy by aggregating both the global and local information from sparse keypoints. To further improve the efficiency, we propose the joint learning of feature matching and description. Our learning enables simpler and faster matching than Sinkhorn, often used in matching the learned descriptors from Transformers. Our method achieves competitive performance with only 0.84M learnable parameters against the bigger SOTAs, SuperGlue (12M parameters) and SGMNet (30M parameters), on three benchmarks, HPatch, ETH, and Aachen Day-Night.
Who's the Expert? On Multi-source Belief Change
Apr 29, 2022Consider the following belief change/merging scenario. A group of information sources gives a sequence of reports about the state of the world at various instances (e.g. different points in time). The true states at these instances are unknown to us. The sources have varying levels of expertise, also unknown to us, and may be knowledgeable on some topics but not others. This may cause sources to report false statements in areas they lack expertise. What should we believe on the basis of these reports? We provide a framework in which to explore this problem, based on an extension of propositional logic with expertise formulas. This extended language allows us to express beliefs about the state of the world at each instance, as well as beliefs about the expertise of each source. We propose several postulates, provide a couple of families of concrete operators, and analyse these operators with respect to the postulates.
Evaluation of Automatic Text Summarization using Synthetic Facts
Apr 11, 2022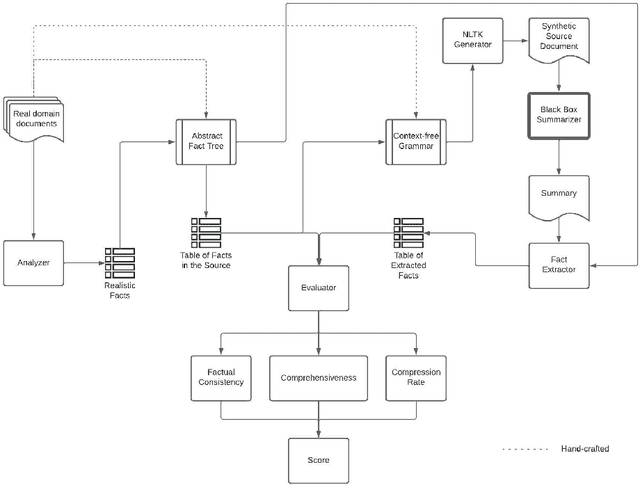
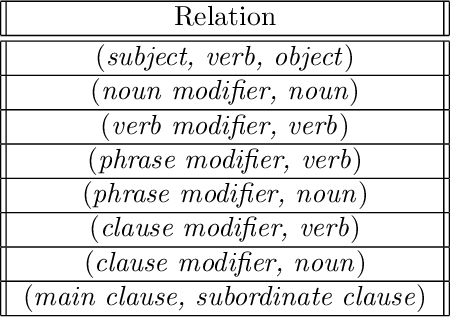
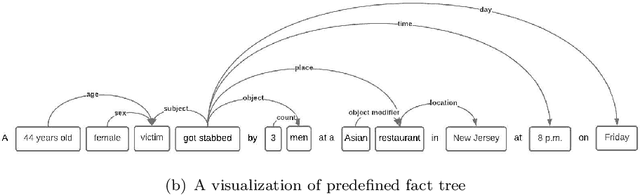
Despite some recent advances, automatic text summarization remains unreliable, elusive, and of limited practical use in applications. Two main problems with current summarization methods are well known: evaluation and factual consistency. To address these issues, we propose a new automatic reference-less text summarization evaluation system that can measure the quality of any text summarization model with a set of generated facts based on factual consistency, comprehensiveness, and compression rate. As far as we know, our evaluation system is the first system that measures the overarching quality of the text summarization models based on factuality, information coverage, and compression rate.
Offline Retrieval Evaluation Without Evaluation Metrics
Apr 25, 2022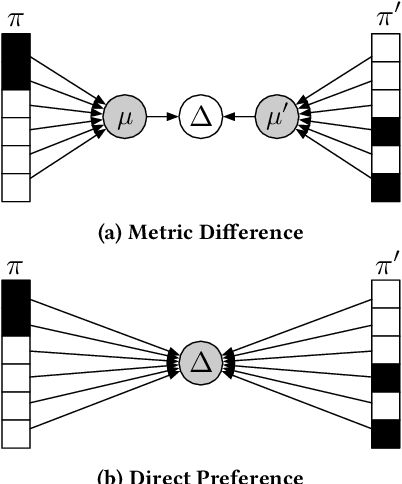
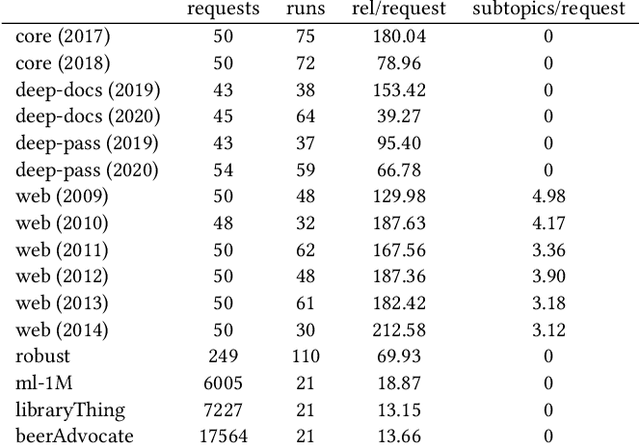
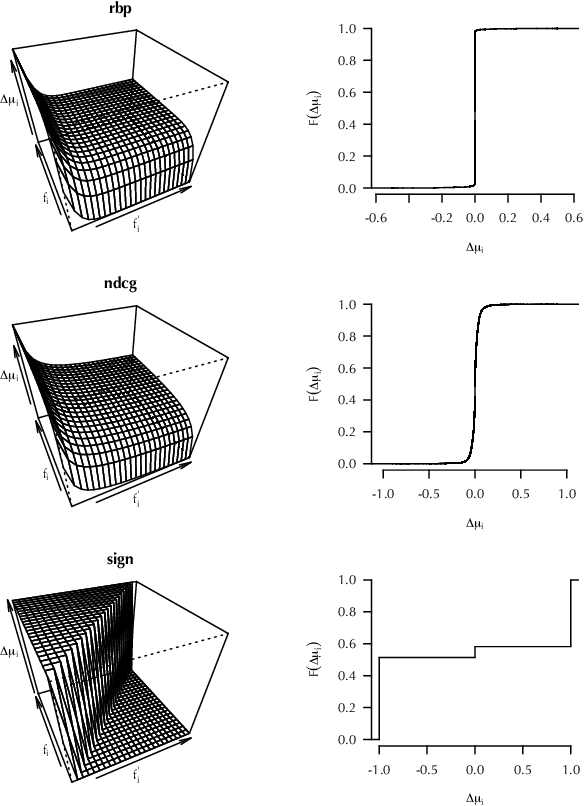
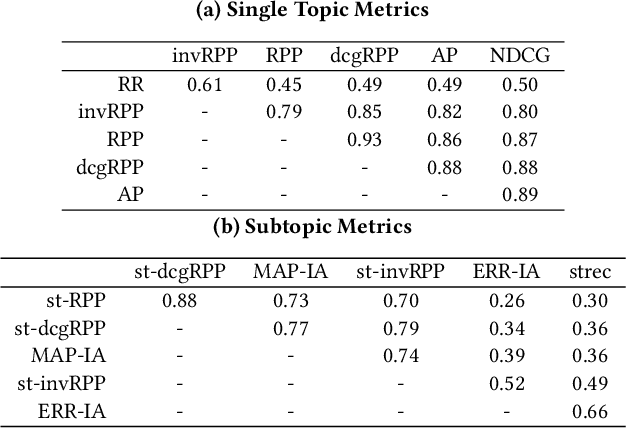
Offline evaluation of information retrieval and recommendation has traditionally focused on distilling the quality of a ranking into a scalar metric such as average precision or normalized discounted cumulative gain. We can use this metric to compare the performance of multiple systems for the same request. Although evaluation metrics provide a convenient summary of system performance, they also collapse subtle differences across users into a single number and can carry assumptions about user behavior and utility not supported across retrieval scenarios. We propose recall-paired preference (RPP), a metric-free evaluation method based on directly computing a preference between ranked lists. RPP simulates multiple user subpopulations per query and compares systems across these pseudo-populations. Our results across multiple search and recommendation tasks demonstrate that RPP substantially improves discriminative power while correlating well with existing metrics and being equally robust to incomplete data.
CARNet: A Dynamic Autoencoder for Learning Latent Dynamics in Autonomous Driving Tasks
May 18, 2022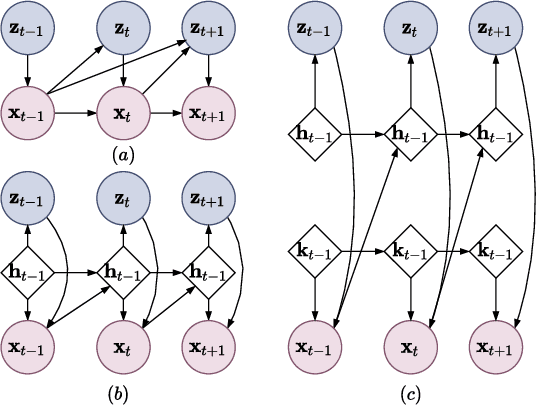
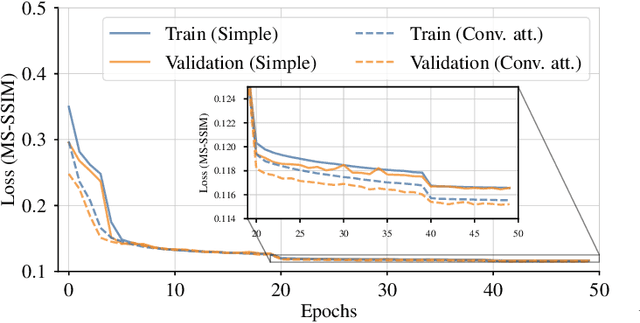


Autonomous driving has received a lot of attention in the automotive industry and is often seen as the future of transportation. Passenger vehicles equipped with a wide array of sensors (e.g., cameras, front-facing radars, LiDARs, and IMUs) capable of continuous perception of the environment are becoming increasingly prevalent. These sensors provide a stream of high-dimensional, temporally correlated data that is essential for reliable autonomous driving. An autonomous driving system should effectively use the information collected from the various sensors in order to form an abstract description of the world and maintain situational awareness. Deep learning models, such as autoencoders, can be used for that purpose, as they can learn compact latent representations from a stream of incoming data. However, most autoencoder models process the data independently, without assuming any temporal interdependencies. Thus, there is a need for deep learning models that explicitly consider the temporal dependence of the data in their architecture. This work proposes CARNet, a Combined dynAmic autoencodeR NETwork architecture that utilizes an autoencoder combined with a recurrent neural network to learn the current latent representation and, in addition, also predict future latent representations in the context of autonomous driving. We demonstrate the efficacy of the proposed model in both imitation and reinforcement learning settings using both simulated and real datasets. Our results show that the proposed model outperforms the baseline state-of-the-art model, while having significantly fewer trainable parameters.