 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Worldwide city transport typology prediction with sentence-BERT based supervised learning via Wikipedia
Mar 29, 2022
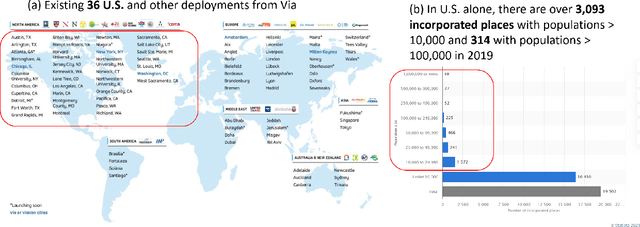
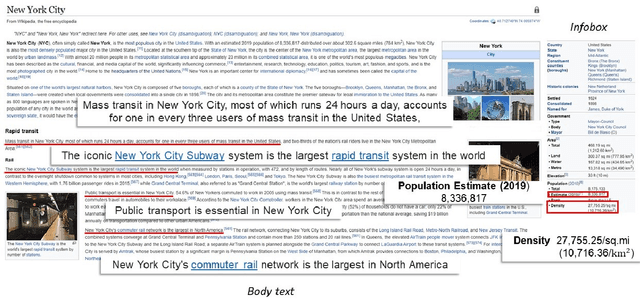
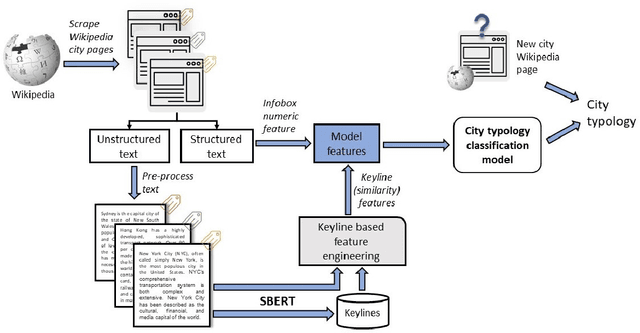
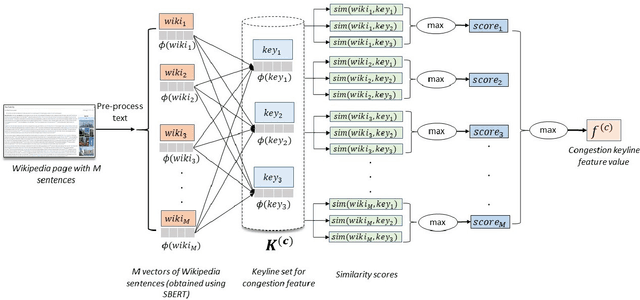
An overwhelming majority of the world's human population lives in urban areas and cities. Understanding a city's transportation typology is immensely valuable for planners and policy makers whose decisions can potentially impact millions of city residents. Despite the value of understanding a city's typology, labeled data (city and it's typology) is scarce, and spans at most a few hundred cities in the current transportation literature. To break this barrier, we propose a supervised machine learning approach to predict a city's typology given the information in its Wikipedia page. Our method leverages recent breakthroughs in natural language processing, namely sentence-BERT, and shows how the text-based information from Wikipedia can be effectively used as a data source for city typology prediction tasks that can be applied to over 2000 cities worldwide. We propose a novel method for low-dimensional city representation using a city's Wikipedia page, which makes supervised learning of city typology labels tractable even with a few hundred labeled samples. These features are used with labeled city samples to train binary classifiers (logistic regression) for four different city typologies: (i) congestion, (ii) auto-heavy, (iii) transit-heavy, and (iv) bike-friendly cities resulting in reasonably high AUC scores of 0.87, 0.86, 0.61 and 0.94 respectively. Our approach provides sufficient flexibility for incorporating additional variables in the city typology models and can be applied to study other city typologies as well. Our findings can assist a diverse group of stakeholders in transportation and urban planning fields, and opens up new opportunities for using text-based information from Wikipedia (or similar platforms) as data sources in such fields.
T-LEAP: occlusion-robust pose estimation of walking cows using temporal information
Apr 16, 2021


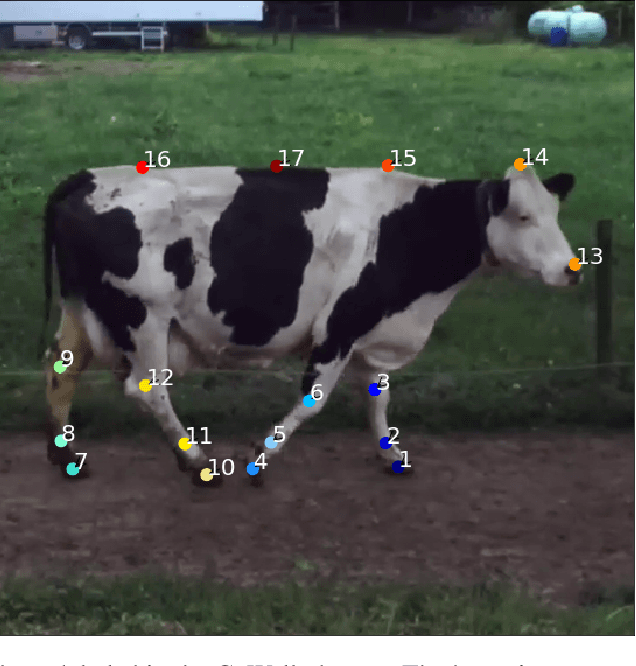
As herd size on dairy farms continue to increase, automatic health monitoring of cows has gained in interest. Lameness, a prevalent health disorder in dairy cows, is commonly detected by analyzing the gait of cows. A cow's gait can be tracked in videos using pose estimation models because models learn to automatically localize anatomical landmarks in images and videos. Most animal pose estimation models are static, that is, videos are processed frame by frame and do not use any temporal information. In this work, a static deep-learning model for animal-pose-estimation was extended to a temporal model that includes information from past frames. We compared the performance of the static and temporal pose estimation models. The data consisted of 1059 samples of 4 consecutive frames extracted from videos (30 fps) of 30 different dairy cows walking through an outdoor passageway. As farm environments are prone to occlusions, we tested the robustness of the static and temporal models by adding artificial occlusions to the videos. The experiments showed that, on non-occluded data, both static and temporal approaches achieved a Percentage of Correct Keypoints (PCKh@0.2) of 99%. On occluded data, our temporal approach outperformed the static one by up to 32.9%, suggesting that using temporal data is beneficial for pose estimation in environments prone to occlusions, such as dairy farms. The generalization capabilities of the temporal model was evaluated by testing it on data containing unknown cows (cows not present in the training set). The results showed that the average detection rate (PCKh@0.2) was of 93.8% on known cows and 87.6% on unknown cows, indicating that the model is capable of generalizing well to new cows and that they could be easily fine-tuned to new herds. Finally, we showed that with harder tasks, such as occlusions and unknown cows, a deeper architecture was more beneficial.
Progressive Multi-scale Consistent Network for Multi-class Fundus Lesion Segmentation
May 31, 2022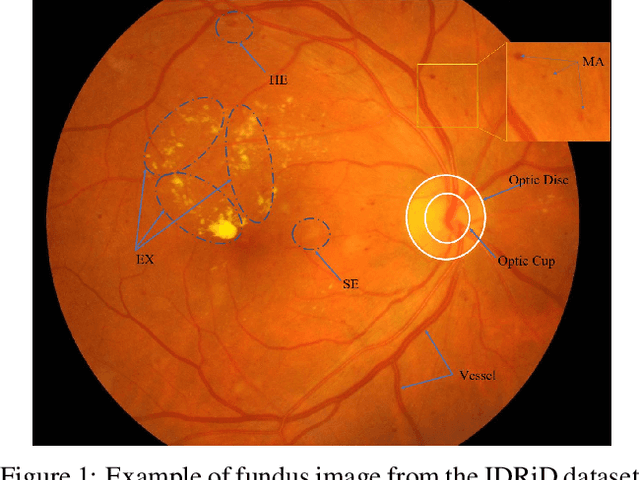
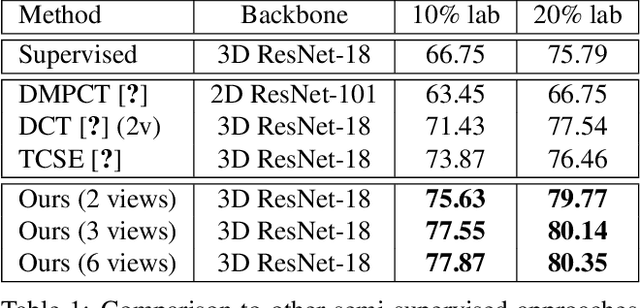
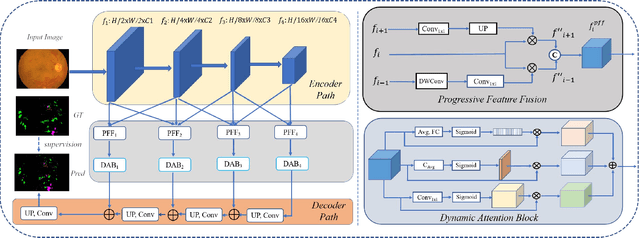
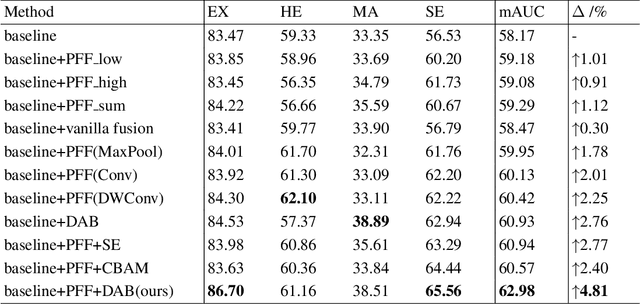
Effectively integrating multi-scale information is of considerable significance for the challenging multi-class segmentation of fundus lesions because different lesions vary significantly in scales and shapes. Several methods have been proposed to successfully handle the multi-scale object segmentation. However, two issues are not considered in previous studies. The first is the lack of interaction between adjacent feature levels, and this will lead to the deviation of high-level features from low-level features and the loss of detailed cues. The second is the conflict between the low-level and high-level features, this occurs because they learn different scales of features, thereby confusing the model and decreasing the accuracy of the final prediction. In this paper, we propose a progressive multi-scale consistent network (PMCNet) that integrates the proposed progressive feature fusion (PFF) block and dynamic attention block (DAB) to address the aforementioned issues. Specifically, PFF block progressively integrates multi-scale features from adjacent encoding layers, facilitating feature learning of each layer by aggregating fine-grained details and high-level semantics. As features at different scales should be consistent, DAB is designed to dynamically learn the attentive cues from the fused features at different scales, thus aiming to smooth the essential conflicts existing in multi-scale features. The two proposed PFF and DAB blocks can be integrated with the off-the-shelf backbone networks to address the two issues of multi-scale and feature inconsistency in the multi-class segmentation of fundus lesions, which will produce better feature representation in the feature space. Experimental results on three public datasets indicate that the proposed method is more effective than recent state-of-the-art methods.
Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
May 19, 2022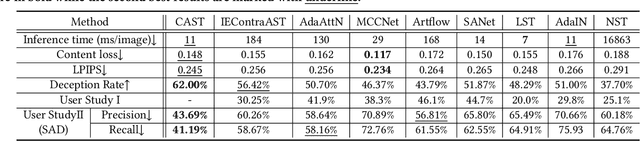

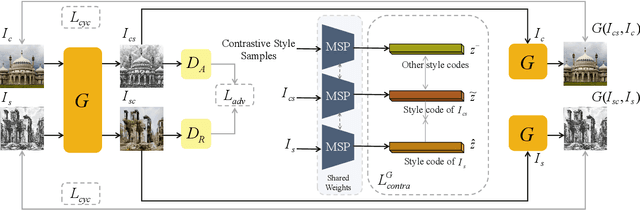
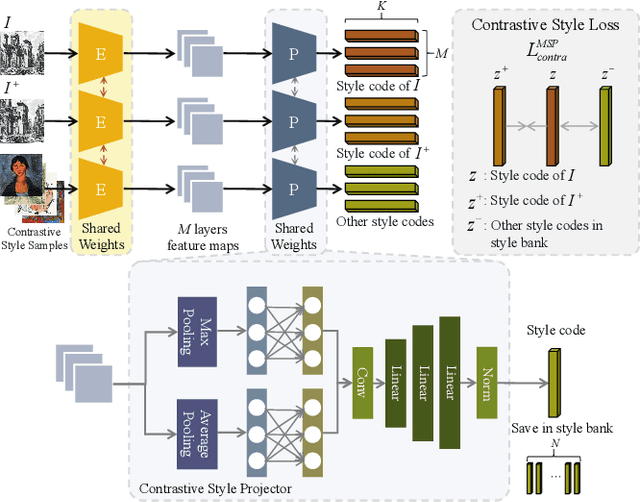
In this work, we tackle the challenging problem of arbitrary image style transfer using a novel style feature representation learning method. A suitable style representation, as a key component in image stylization tasks, is essential to achieve satisfactory results. Existing deep neural network based approaches achieve reasonable results with the guidance from second-order statistics such as Gram matrix of content features. However, they do not leverage sufficient style information, which results in artifacts such as local distortions and style inconsistency. To address these issues, we propose to learn style representation directly from image features instead of their second-order statistics, by analyzing the similarities and differences between multiple styles and considering the style distribution. Specifically, we present Contrastive Arbitrary Style Transfer (CAST), which is a new style representation learning and style transfer method via contrastive learning. Our framework consists of three key components, i.e., a multi-layer style projector for style code encoding, a domain enhancement module for effective learning of style distribution, and a generative network for image style transfer. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results compared to those obtained via state-of-the-art methods. Code and models are available at https://github.com/zyxElsa/CAST_pytorch
EnK: Encoding time-information in convolution
Jun 07, 2020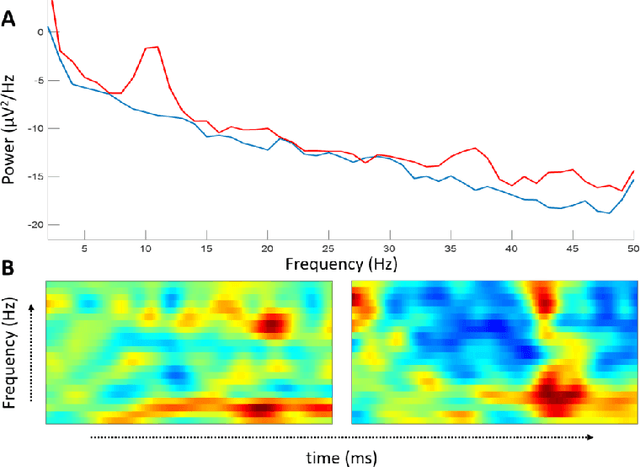

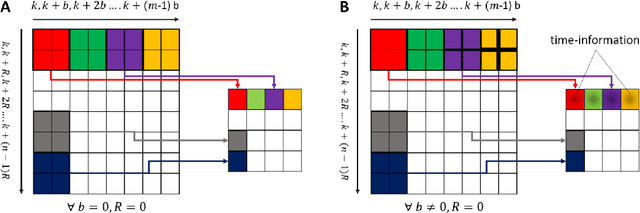
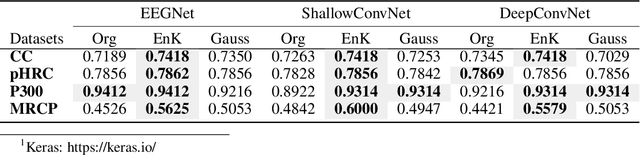
Recent development in deep learning techniques has attracted attention in decoding and classification in EEG signals. Despite several efforts utilizing different features of EEG signals, a significant research challenge is to use time-dependent features in combination with local and global features. There have been several efforts to remodel the deep learning convolution neural networks (CNNs) to capture time-dependency information by incorporating hand-crafted features, slicing the input data in a smaller time-windows, and recurrent convolution. However, these approaches partially solve the problem, but simultaneously hinder the CNN's capability to learn from unknown information that might be present in the data. To solve this, we have proposed a novel time encoding kernel (EnK) approach, which introduces the increasing time information during convolution operation in CNN. The encoded information by EnK lets CNN learn time-dependent features in-addition to local and global features. We performed extensive experiments on several EEG datasets: cognitive conflict (CC), physical-human robot collaboration (pHRC), P300 visual-evoked potentials, movement-related cortical potentials (MRCP). EnK outperforms the state-of-art by 12\% (F1 score). Moreover, the EnK approach required only one additional parameter to learn and can be applied to a virtually any CNN architectures with minimal efforts. These results support our methodology and show high potential to improve CNN performance in the context of time-series data in general.
Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation
Mar 19, 2022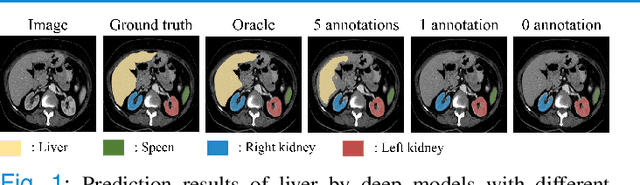
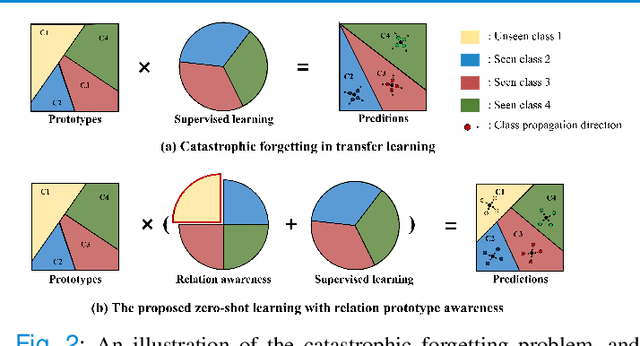
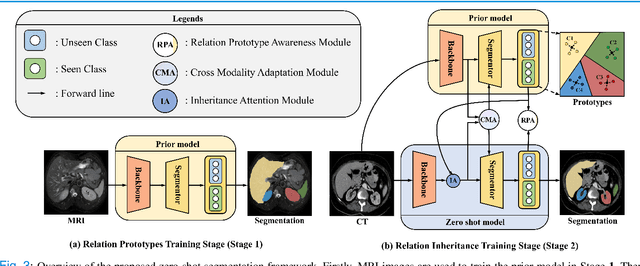
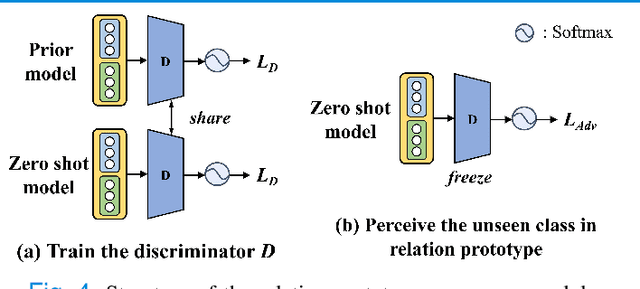
Due to the lack of properly annotated medical data, exploring the generalization capability of the deep model is becoming a public concern. Zero-shot learning (ZSL) has emerged in recent years to equip the deep model with the ability to recognize unseen classes. However, existing studies mainly focus on natural images, which utilize linguistic models to extract auxiliary information for ZSL. It is impractical to apply the natural image ZSL solutions directly to medical images, since the medical terminology is very domain-specific, and it is not easy to acquire linguistic models for the medical terminology. In this work, we propose a new paradigm of ZSL specifically for medical images utilizing cross-modality information. We make three main contributions with the proposed paradigm. First, we extract the prior knowledge about the segmentation targets, called relation prototypes, from the prior model and then propose a cross-modality adaptation module to inherit the prototypes to the zero-shot model. Second, we propose a relation prototype awareness module to make the zero-shot model aware of information contained in the prototypes. Last but not least, we develop an inheritance attention module to recalibrate the relation prototypes to enhance the inheritance process. The proposed framework is evaluated on two public cross-modality datasets including a cardiac dataset and an abdominal dataset. Extensive experiments show that the proposed framework significantly outperforms the state of the arts.
Rate of Prefix-free Codes in LQG Control Systems with Side Information
Feb 08, 2021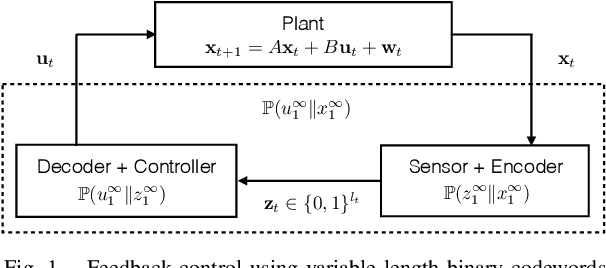
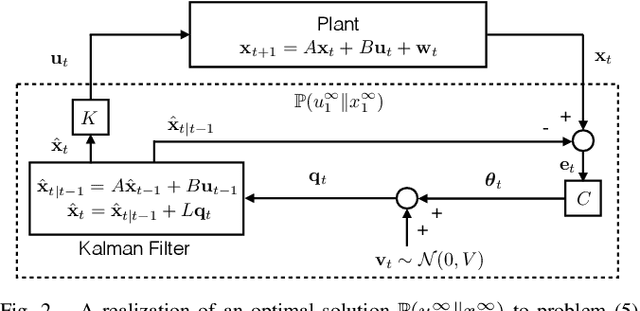
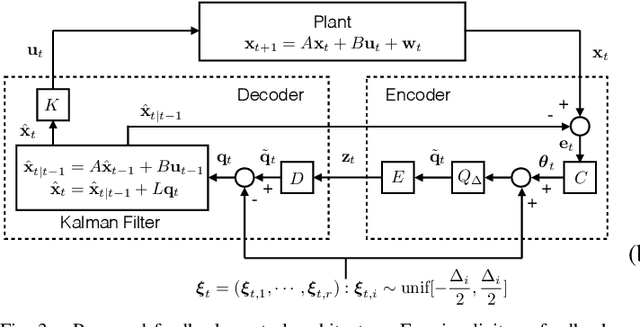
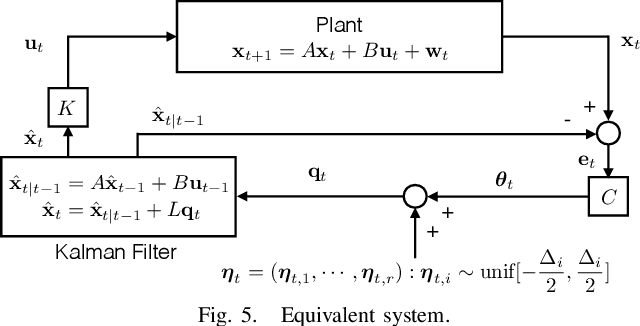
In this work, we study an LQG control system where one of two feedback channels is discrete and incurs a communication cost. We assume that a decoder (co-located with the controller) can make noiseless measurements of a subset of the state vector (referred to as side information) meanwhile a remote encoder (co-located with a sensor) can make arbitrary measurements of the entire state vector, but must convey its measurements to the decoder over a noiseless binary channel. Use of the channel incurs a communication cost, quantified as the time-averaged expected length of prefix-free binary codeword. We study the tradeoff between the communication cost and control performance. The formulation motivates a constrained directed information minimization problem, which can be solved via convex optimization. Using the optimization, we propose a quantizer design and a subsequent achievability result.
* Accepted for publication at CISS 2021
TransGeo: Transformer Is All You Need for Cross-view Image Geo-localization
Mar 31, 2022

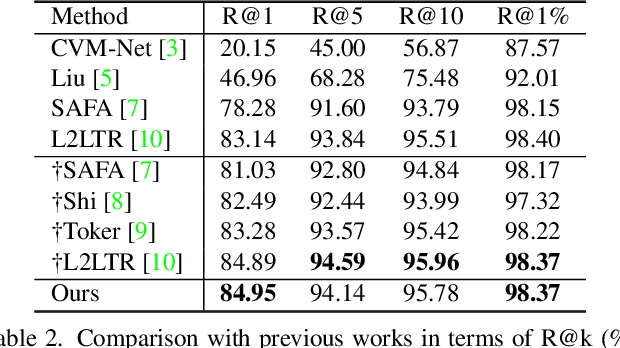
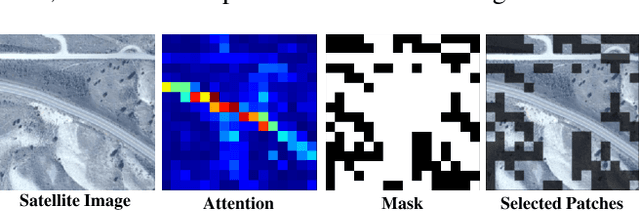
The dominant CNN-based methods for cross-view image geo-localization rely on polar transform and fail to model global correlation. We propose a pure transformer-based approach (TransGeo) to address these limitations from a different perspective. TransGeo takes full advantage of the strengths of transformer related to global information modeling and explicit position information encoding. We further leverage the flexibility of transformer input and propose an attention-guided non-uniform cropping method, so that uninformative image patches are removed with negligible drop on performance to reduce computation cost. The saved computation can be reallocated to increase resolution only for informative patches, resulting in performance improvement with no additional computation cost. This "attend and zoom-in" strategy is highly similar to human behavior when observing images. Remarkably, TransGeo achieves state-of-the-art results on both urban and rural datasets, with significantly less computation cost than CNN-based methods. It does not rely on polar transform and infers faster than CNN-based methods. Code is available at https://github.com/Jeff-Zilence/TransGeo2022.
Incorporating Prior Knowledge into Neural Networks through an Implicit Composite Kernel
May 15, 2022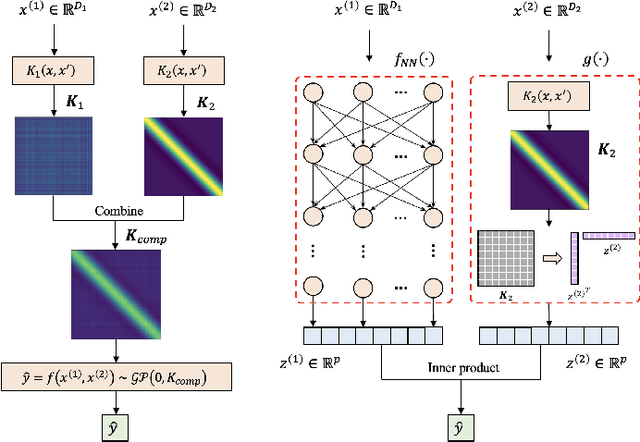

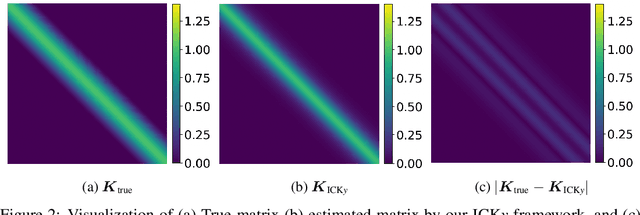
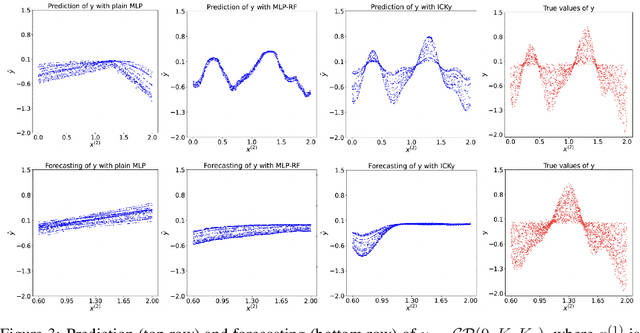
It is challenging to guide neural network (NN) learning with prior knowledge. In contrast, many known properties, such as spatial smoothness or seasonality, are straightforward to model by choosing an appropriate kernel in a Gaussian process (GP). Many deep learning applications could be enhanced by modeling such known properties. For example, convolutional neural networks (CNNs) are frequently used in remote sensing, which is subject to strong seasonal effects. We propose to blend the strengths of deep learning and the clear modeling capabilities of GPs by using a composite kernel that combines a kernel implicitly defined by a neural network with a second kernel function chosen to model known properties (e.g., seasonality). Then, we approximate the resultant GP by combining a deep network and an efficient mapping based on the Nystrom approximation, which we call Implicit Composite Kernel (ICK). ICK is flexible and can be used to include prior information in neural networks in many applications. We demonstrate the strength of our framework by showing its superior performance and flexibility on both synthetic and real-world data sets. The code is available at: https://anonymous.4open.science/r/ICK_NNGP-17C5/.
Online Learning for Traffic Routing under Unknown Preferences
Mar 31, 2022
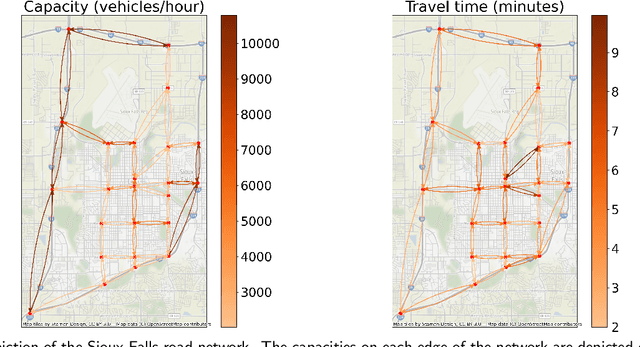
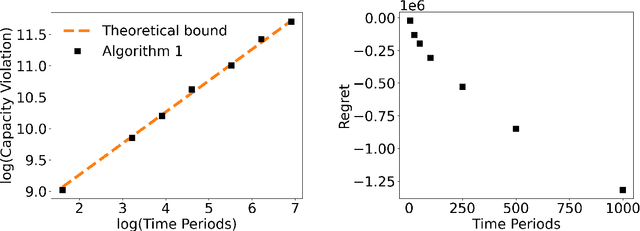
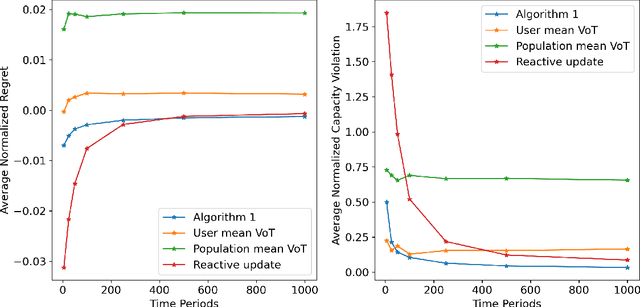
In transportation networks, users typically choose routes in a decentralized and self-interested manner to minimize their individual travel costs, which, in practice, often results in inefficient overall outcomes for society. As a result, there has been a growing interest in designing road tolling schemes to cope with these efficiency losses and steer users toward a system-efficient traffic pattern. However, the efficacy of road tolling schemes often relies on having access to complete information on users' trip attributes, such as their origin-destination (O-D) travel information and their values of time, which may not be available in practice. Motivated by this practical consideration, we propose an online learning approach to set tolls in a traffic network to drive heterogeneous users with different values of time toward a system-efficient traffic pattern. In particular, we develop a simple yet effective algorithm that adjusts tolls at each time period solely based on the observed aggregate flows on the roads of the network without relying on any additional trip attributes of users, thereby preserving user privacy. In the setting where the O-D pairs and values of time of users are drawn i.i.d. at each period, we show that our approach obtains an expected regret and road capacity violation of $O(\sqrt{T})$, where $T$ is the number of periods over which tolls are updated. Our regret guarantee is relative to an offline oracle that has complete information on users' trip attributes. We further establish a $\Omega(\sqrt{T})$ lower bound on the regret of any algorithm, which establishes that our algorithm is optimal up to constants. Finally, we demonstrate the superior performance of our approach relative to several benchmarks on a real-world transportation network, thereby highlighting its practical applicability.