 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
COOPERNAUT: End-to-End Driving with Cooperative Perception for Networked Vehicles
May 04, 2022
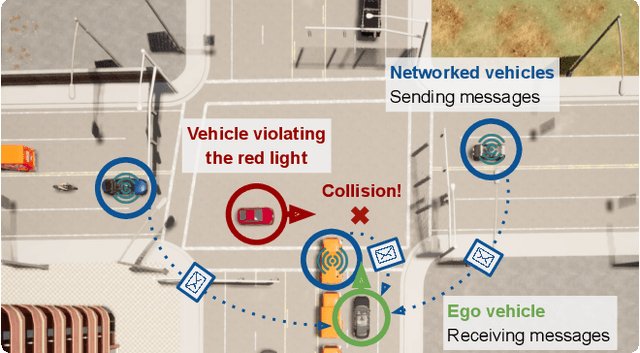

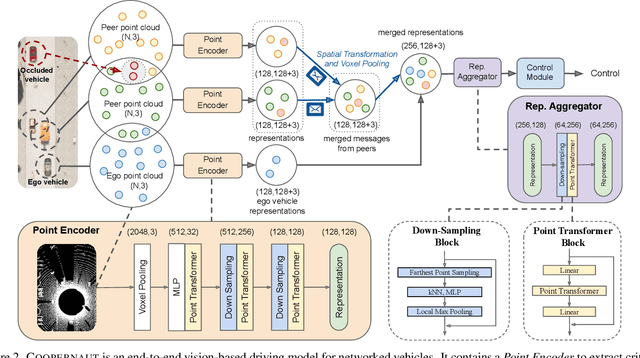

Optical sensors and learning algorithms for autonomous vehicles have dramatically advanced in the past few years. Nonetheless, the reliability of today's autonomous vehicles is hindered by the limited line-of-sight sensing capability and the brittleness of data-driven methods in handling extreme situations. With recent developments of telecommunication technologies, cooperative perception with vehicle-to-vehicle communications has become a promising paradigm to enhance autonomous driving in dangerous or emergency situations. We introduce COOPERNAUT, an end-to-end learning model that uses cross-vehicle perception for vision-based cooperative driving. Our model encodes LiDAR information into compact point-based representations that can be transmitted as messages between vehicles via realistic wireless channels. To evaluate our model, we develop AutoCastSim, a network-augmented driving simulation framework with example accident-prone scenarios. Our experiments on AutoCastSim suggest that our cooperative perception driving models lead to a 40% improvement in average success rate over egocentric driving models in these challenging driving situations and a 5 times smaller bandwidth requirement than prior work V2VNet. COOPERNAUT and AUTOCASTSIM are available at https://ut-austin-rpl.github.io/Coopernaut/.
Attention-based Multimodal Feature Representation Model for Micro-video Recommendation
May 18, 2022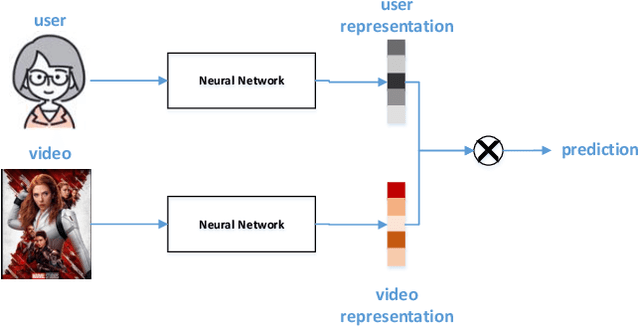
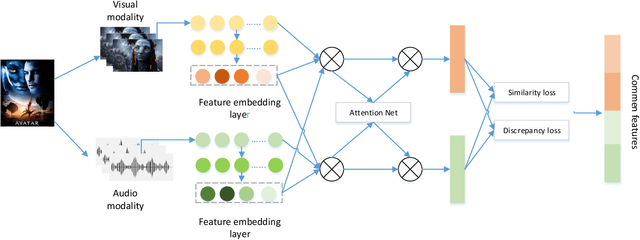
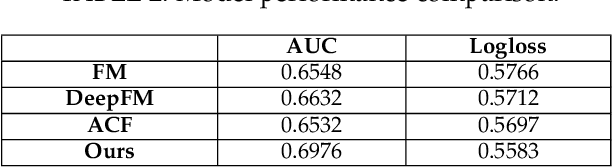
In recommender systems, models mostly use a combination of embedding layers and multilayer feedforward neural networks. The high-dimensional sparse original features are downscaled in the embedding layer and then fed into the fully connected network to obtain prediction results. However, the above methods have a rather obvious problem, that is, the features directly input are treated as independent individuals, and in fact there are internal correlations between features and features, and even different features have different importance in the recommendation. In this regard, this paper adopts a self-attentive mechanism to mine the internal correlations between features as well as their relative importance. In recent years, as a special form of attention mechanism, self-attention mechanism is favored by many researchers. The self-attentive mechanism captures the internal correlation of data or features by learning itself, thus reducing the dependence on external sources. Therefore, this paper adopts a multi-headed self-attentive mechanism to mine the internal correlations between features and thus learn the internal representation of features. At the same time, considering the rich information often hidden between features, the new feature representation obtained by crossover between the two is likely to imply the new description of the user likes the item. However, not all crossover features are meaningful, i.e., there is a problem of limited expression of feature combinations. Therefore, this paper adopts an attention-based approach to learn the external cross-representation of features.
ConvMAE: Masked Convolution Meets Masked Autoencoders
May 08, 2022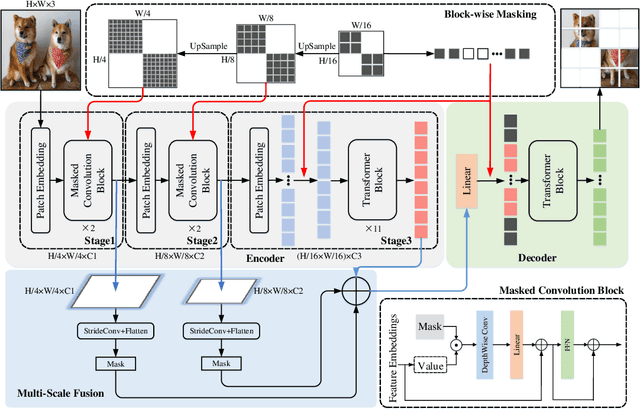
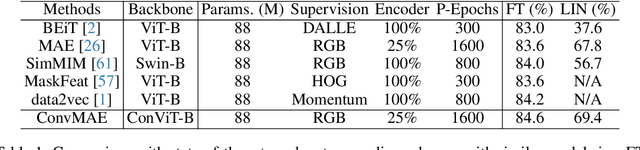
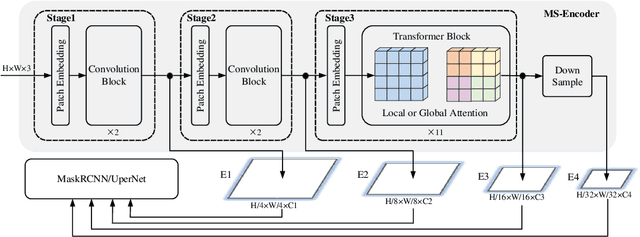
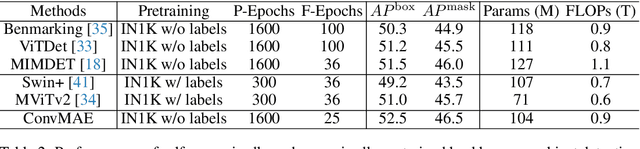
Vision Transformers (ViT) become widely-adopted architectures for various vision tasks. Masked auto-encoding for feature pretraining and multi-scale hybrid convolution-transformer architectures can further unleash the potentials of ViT, leading to state-of-the-art performances on image classification, detection and semantic segmentation. In this paper, our ConvMAE framework demonstrates that multi-scale hybrid convolution-transformer can learn more discriminative representations via the mask auto-encoding scheme. However, directly using the original masking strategy leads to the heavy computational cost and pretraining-finetuning discrepancy. To tackle the issue, we adopt the masked convolution to prevent information leakage in the convolution blocks. A simple block-wise masking strategy is proposed to ensure computational efficiency. We also propose to more directly supervise the multi-scale features of the encoder to boost multi-scale features. Based on our pretrained ConvMAE models, ConvMAE-Base improves ImageNet-1K finetuning accuracy by 1.4% compared with MAE-Base. On object detection, ConvMAE-Base finetuned for only 25 epochs surpasses MAE-Base fined-tuned for 100 epochs by 2.9% box AP and 2.2% mask AP respectively. Code and pretrained models are available at https://github.com/Alpha-VL/ConvMAE.
UNet#: A UNet-like Redesigning Skip Connections for Medical Image Segmentation
May 24, 2022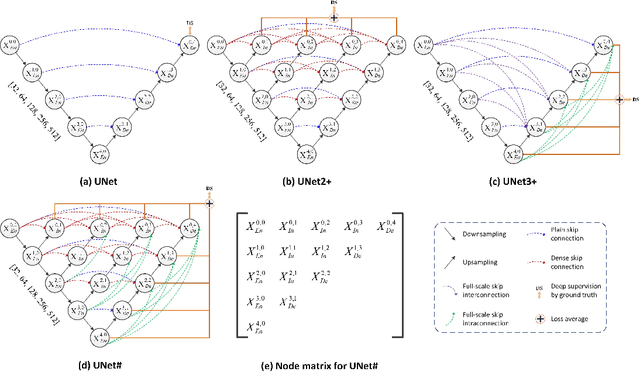
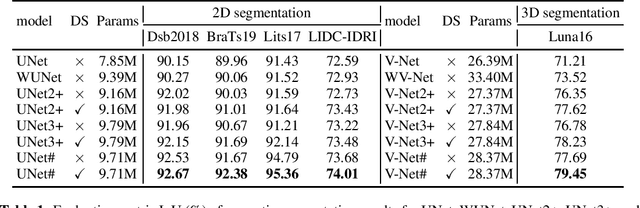
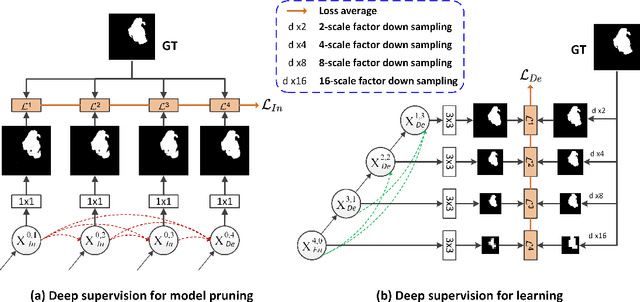
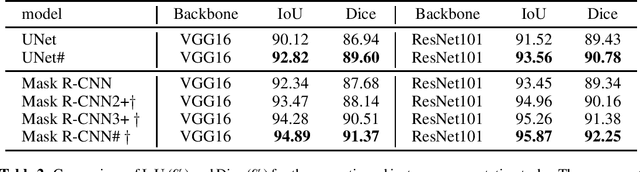
As an essential prerequisite for developing a medical intelligent assistant system, medical image segmentation has received extensive research and concentration from the neural network community. A series of UNet-like networks with encoder-decoder architecture has achieved extraordinary success, in which UNet2+ and UNet3+ redesign skip connections, respectively proposing dense skip connection and full-scale skip connection and dramatically improving compared with UNet in medical image segmentation. However, UNet2+ lacks sufficient information explored from the full scale, which will affect the learning of organs' location and boundary. Although UNet3+ can obtain the full-scale aggregation feature map, owing to the small number of neurons in the structure, it does not satisfy the segmentation of tiny objects when the number of samples is small. This paper proposes a novel network structure combining dense skip connections and full-scale skip connections, named UNet-sharp (UNet\#) for its shape similar to symbol \#. The proposed UNet\# can aggregate feature maps of different scales in the decoder sub-network and capture fine-grained details and coarse-grained semantics from the full scale, which benefits learning the exact location and accurately segmenting the boundary of organs or lesions. We perform deep supervision for model pruning to speed up testing and make it possible for the model to run on mobile devices; furthermore, designing two classification-guided modules to reduce false positives achieves more accurate segmentation results. Various experiments of semantic segmentation and instance segmentation on different modalities (EM, CT, MRI) and dimensions (2D, 3D) datasets, including the nuclei, brain tumor, liver, and lung, demonstrate that the proposed method outperforms state-of-the-art models.
Generalizable Person Re-Identification via Self-Supervised Batch Norm Test-Time Adaption
Mar 28, 2022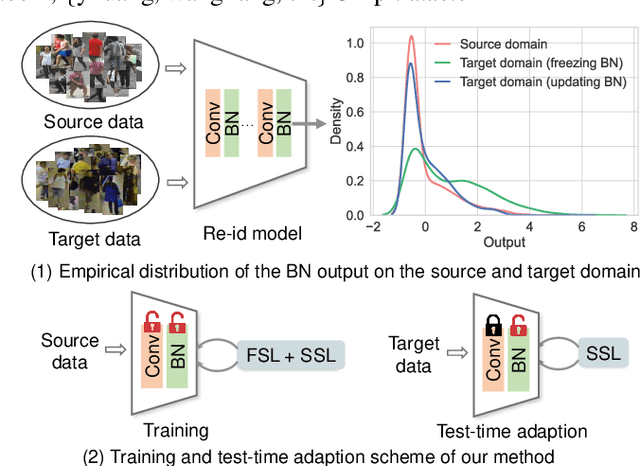
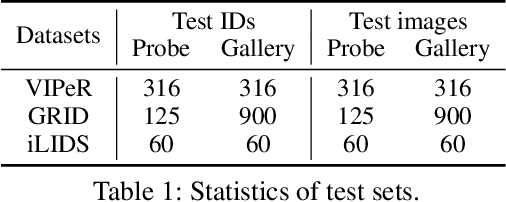
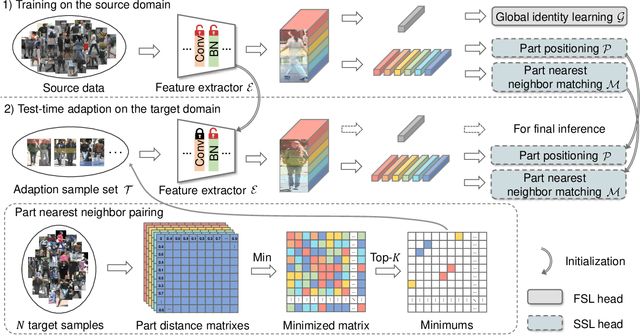
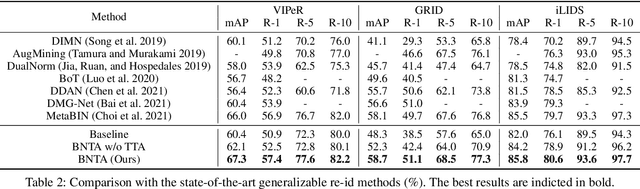
In this paper, we investigate the generalization problem of person re-identification (re-id), whose major challenge is the distribution shift on an unseen domain. As an important tool of regularizing the distribution, batch normalization (BN) has been widely used in existing methods. However, they neglect that BN is severely biased to the training domain and inevitably suffers the performance drop if directly generalized without being updated. To tackle this issue, we propose Batch Norm Test-time Adaption (BNTA), a novel re-id framework that applies the self-supervised strategy to update BN parameters adaptively. Specifically, BNTA quickly explores the domain-aware information within unlabeled target data before inference, and accordingly modulates the feature distribution normalized by BN to adapt to the target domain. This is accomplished by two designed self-supervised auxiliary tasks, namely part positioning and part nearest neighbor matching, which help the model mine the domain-aware information with respect to the structure and identity of body parts, respectively. To demonstrate the effectiveness of our method, we conduct extensive experiments on three re-id datasets and confirm the superior performance to the state-of-the-art methods.
Adversarial Training Reduces Information and Improves Transferability
Jul 23, 2020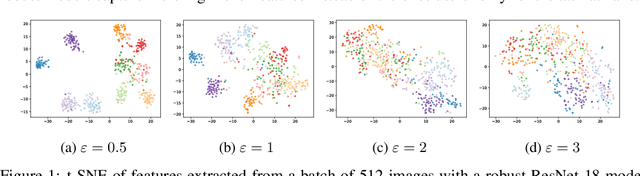
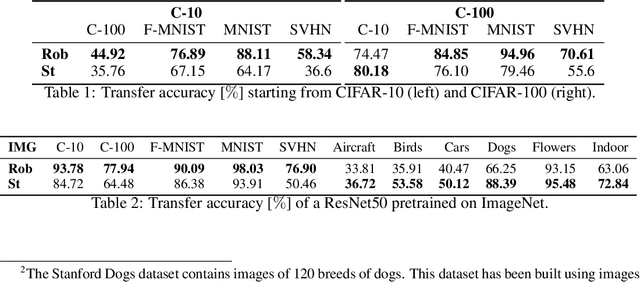
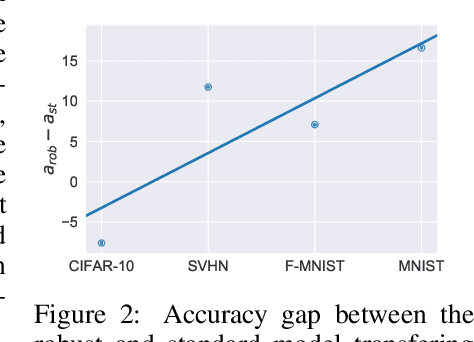
Recent results show that features of adversarially trained networks for classification, in addition to being robust, enable desirable properties such as invertibility. The latter property may seem counter-intuitive as it is widely accepted by the community that classification models should only capture the minimal information (features) required for the task. Motivated by this discrepancy, we investigate the dual relationship between Adversarial Training and Information Theory. We show that the Adversarial Training can improve linear transferability to new tasks, from which arises a new trade-off between transferability of representations and accuracy on the source task. We validate our results employing robust networks trained on CIFAR-10, CIFAR-100 and ImageNet on several datasets. Moreover, we show that Adversarial Training reduces Fisher information of representations about the input and of the weights about the task, and we provide a theoretical argument which explains the invertibility of deterministic networks without violating the principle of minimality. Finally, we leverage our theoretical insights to remarkably improve the quality of reconstructed images through inversion.
Rethinking Position Bias Modeling with Knowledge Distillation for CTR Prediction
Apr 01, 2022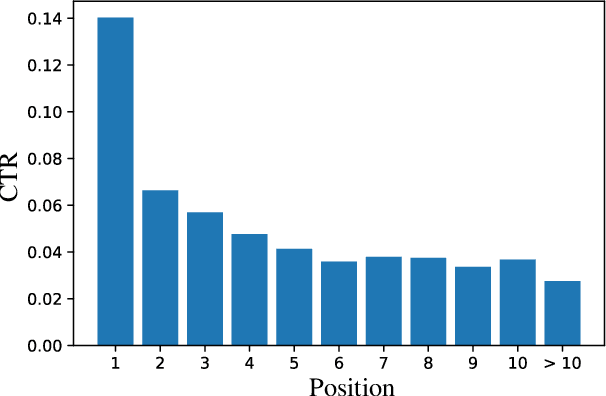
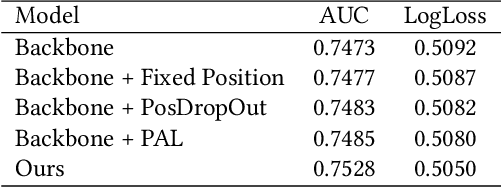
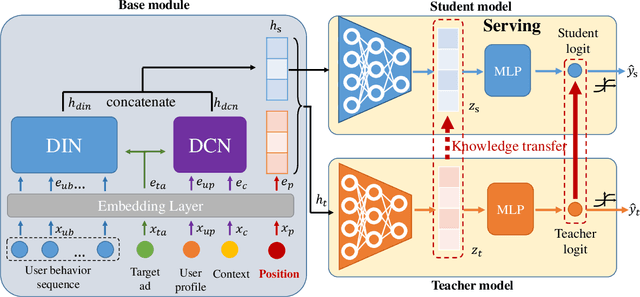
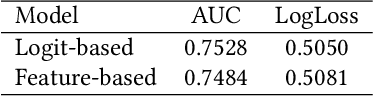
Click-through rate (CTR) Prediction is of great importance in real-world online ads systems. One challenge for the CTR prediction task is to capture the real interest of users from their clicked items, which is inherently biased by presented positions of items, i.e., more front positions tend to obtain higher CTR values. A popular line of existing works focuses on explicitly estimating position bias by result randomization which is expensive and inefficient, or by inverse propensity weighting (IPW) which relies heavily on the quality of the propensity estimation. Another common solution is modeling position as features during offline training and simply adopting fixed value or dropout tricks when serving. However, training-inference inconsistency can lead to sub-optimal performance. Furthermore, post-click information such as position values is informative while less exploited in CTR prediction. This work proposes a simple yet efficient knowledge distillation framework to alleviate the impact of position bias and leverage position information to improve CTR prediction. We demonstrate the performance of our proposed method on a real-world production dataset and online A/B tests, achieving significant improvements over competing baseline models. The proposed method has been deployed in the real world online ads systems, serving main traffic on one of the world's largest e-commercial platforms.
EEG-ITNet: An Explainable Inception Temporal Convolutional Network for Motor Imagery Classification
Apr 14, 2022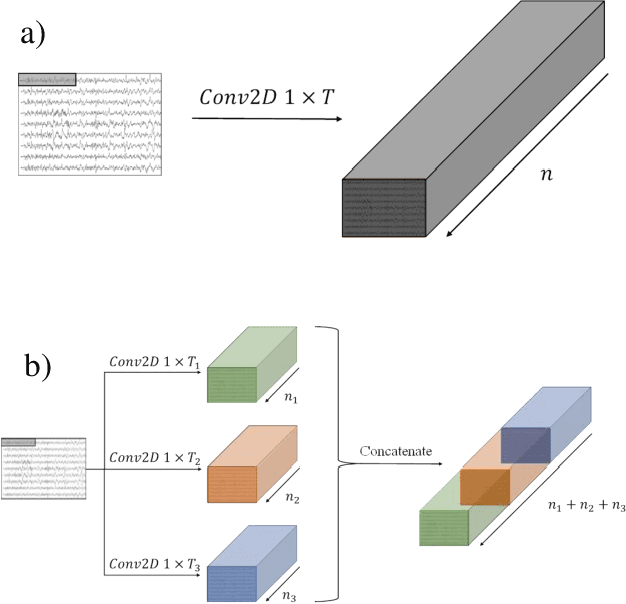
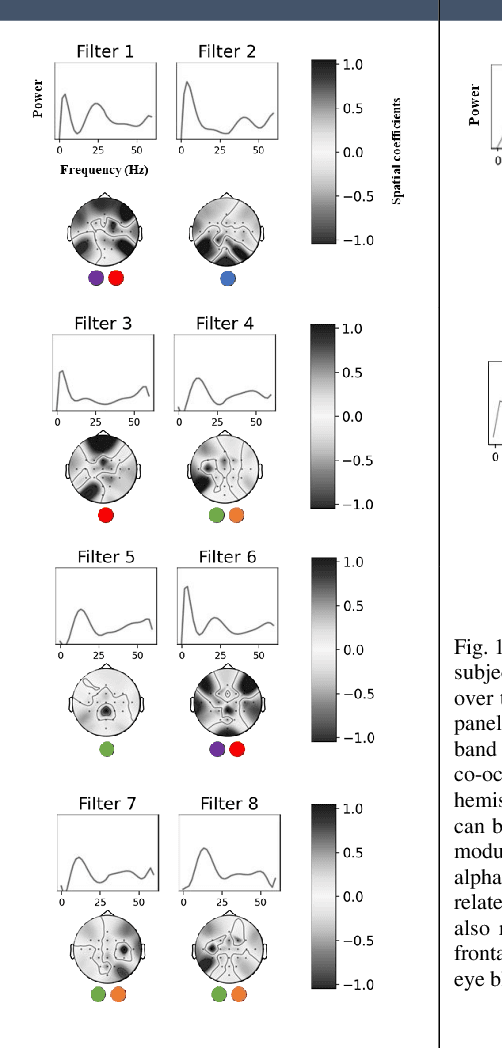
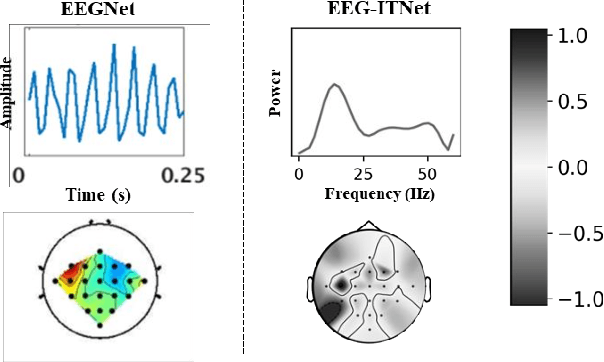
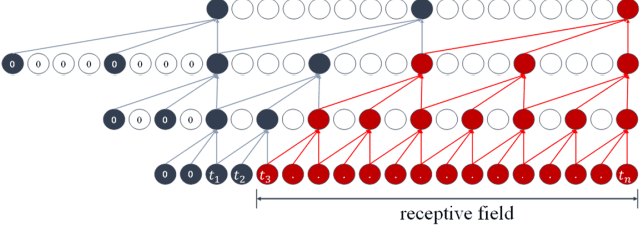
In recent years, neural networks and especially deep architectures have received substantial attention for EEG signal analysis in the field of brain-computer interfaces (BCIs). In this ongoing research area, the end-to-end models are more favoured than traditional approaches requiring signal transformation pre-classification. They can eliminate the need for prior information from experts and the extraction of handcrafted features. However, although several deep learning algorithms have been already proposed in the literature, achieving high accuracies for classifying motor movements or mental tasks, they often face a lack of interpretability and therefore are not quite favoured by the neuroscience community. The reasons behind this issue can be the high number of parameters and the sensitivity of deep neural networks to capture tiny yet unrelated discriminative features. We propose an end-to-end deep learning architecture called EEG-ITNet and a more comprehensible method to visualise the network learned patterns. Using inception modules and causal convolutions with dilation, our model can extract rich spectral, spatial, and temporal information from multi-channel EEG signals with less complexity (in terms of the number of trainable parameters) than other existing end-to-end architectures, such as EEG-Inception and EEG-TCNet. By an exhaustive evaluation on dataset 2a from BCI competition IV and OpenBMI motor imagery dataset, EEG-ITNet shows up to 5.9\% improvement in the classification accuracy in different scenarios with statistical significance compared to its competitors. We also comprehensively explain and support the validity of network illustration from a neuroscientific perspective. We have also made our code open at https://github.com/AbbasSalami/EEG-ITNet
Local Hypergraph-based Nested Named Entity Recognition as Query-based Sequence Labeling
May 04, 2022

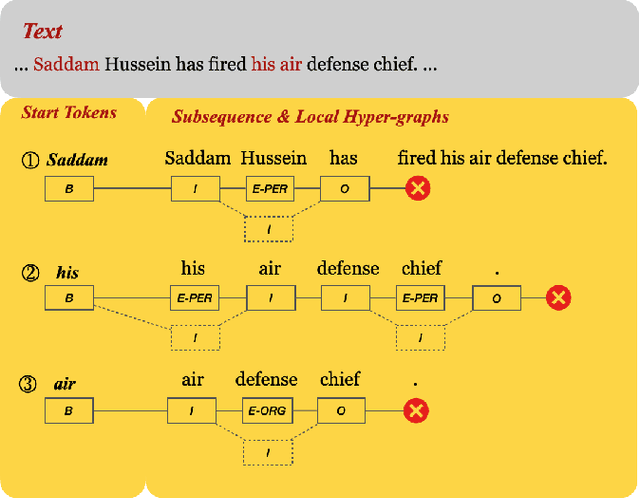
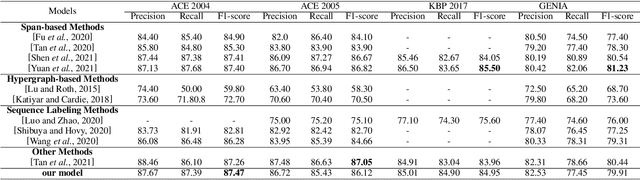
There has been a growing academic interest in the recognition of nested named entities in many domains. We tackle the task with a novel local hypergraph-based method: We first propose start token candidates and generate corresponding queries with their surrounding context, then use a query-based sequence labeling module to form a local hypergraph for each candidate. An end token estimator is used to correct the hypergraphs and get the final predictions. Compared to span-based approaches, our method is free of the high computation cost of span sampling and the risk of losing long entities. Sequential prediction makes it easier to leverage information in word order inside nested structures, and richer representations are built with a local hypergraph. Experiments show that our proposed method outperforms all the previous hypergraph-based and sequence labeling approaches with large margins on all four nested datasets. It achieves a new state-of-the-art F1 score on the ACE 2004 dataset and competitive F1 scores with previous state-of-the-art methods on three other nested NER datasets: ACE 2005, GENIA, and KBP 2017.
Graph Adversarial Networks: Protecting Information against Adversarial Attacks
Oct 05, 2020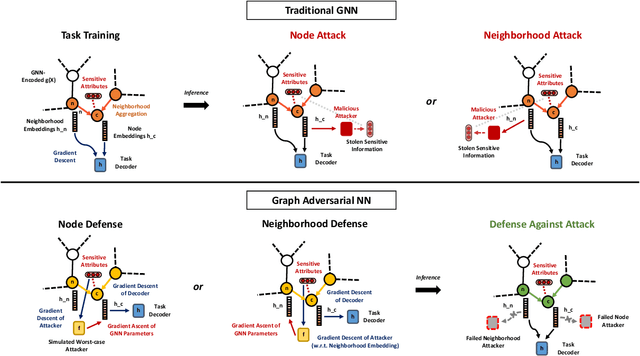
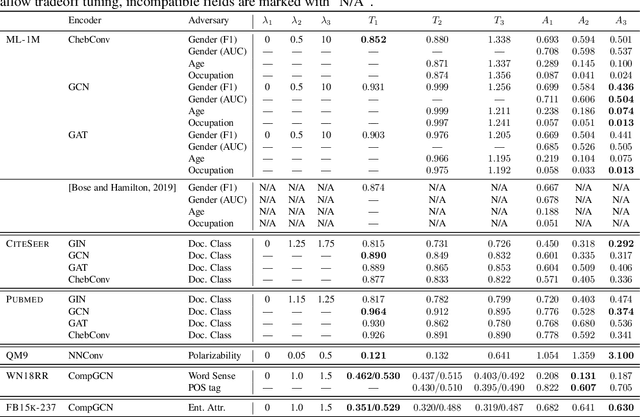
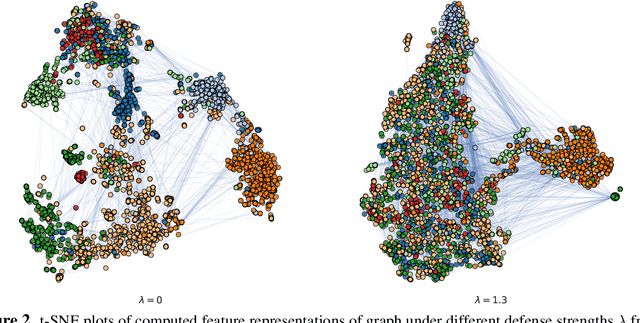
We study the problem of protecting information when learning with graph structured data. While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representational learning in many applications, the neighborhood aggregation paradigm exposes additional vulnerabilities to attackers seeking to extract node-level information about sensitive attributes. To counter this, we propose a minimax game between the desired GNN encoder and the worst-case attacker. The resulting adversarial training creates a strong defense against inference attacks, while only suffering small loss in task performance. We analyze the effectiveness of our framework against a worst-case adversary, and characterize the trade-off between predictive accuracy and adversarial defense. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders.