 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving AMD diagnosis by the simultaneous identification of associated retinal lesions
May 22, 2022
Age-related Macular Degeneration (AMD) is the predominant cause of blindness in developed countries, specially in elderly people. Moreover, its prevalence is increasing due to the global population ageing. In this scenario, early detection is crucial to avert later vision impairment. Nonetheless, implementing large-scale screening programmes is usually not viable, since the population at-risk is large and the analysis must be performed by expert clinicians. Also, the diagnosis of AMD is considered to be particularly difficult, as it is characterized by many different lesions that, in many cases, resemble those of other macular diseases. To overcome these issues, several works have proposed automatic methods for the detection of AMD in retinography images, the most widely used modality for the screening of the disease. Nowadays, most of these works use Convolutional Neural Networks (CNNs) for the binary classification of images into AMD and non-AMD classes. In this work, we propose a novel approach based on CNNs that simultaneously performs AMD diagnosis and the classification of its potential lesions. This latter secondary task has not yet been addressed in this domain, and provides complementary useful information that improves the diagnosis performance and helps understanding the decision. A CNN model is trained using retinography images with image-level labels for both AMD and lesion presence, which are relatively easy to obtain. The experiments conducted in several public datasets show that the proposed approach improves the detection of AMD, while achieving satisfactory results in the identification of most lesions.
Multimodal learning-based inversion models for the space-time reconstruction of satellite-derived geophysical fields
Mar 20, 2022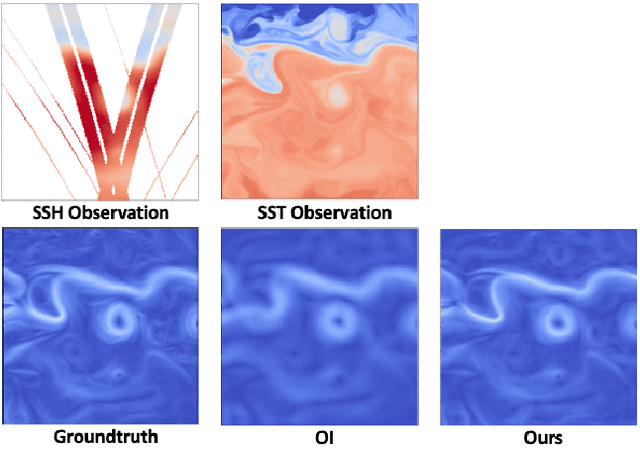
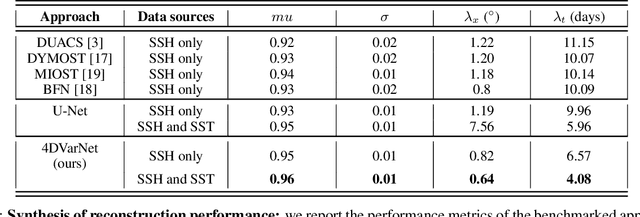

For numerous earth observation applications, one may benefit from various satellite sensors to address the reconstruction of some process or information of interest. A variety of satellite sensors deliver observation data with different sampling patterns due satellite orbits and/or their sensitivity to atmospheric conditions (e.g., clour cover, heavy rains,...). Beyond the ability to account for irregularly-sampled observations, the definition of model-driven inversion methods is often limited to specific case-studies where one can explicitly derive a physical model to relate the different observation sources. Here, we investigate how end-to-end learning schemes provide new means to address multimodal inversion problems. The proposed scheme combines a variational formulation with trainable observation operators, {\em a priori} terms and solvers. Through an application to space oceanography, we show how this scheme can successfully extract relevant information from satellite-derived sea surface temperature images and enhance the reconstruction of sea surface currents issued from satellite altimetry data.
Graph Adversarial Networks: Protecting Information against Adversarial Attacks
Oct 05, 2020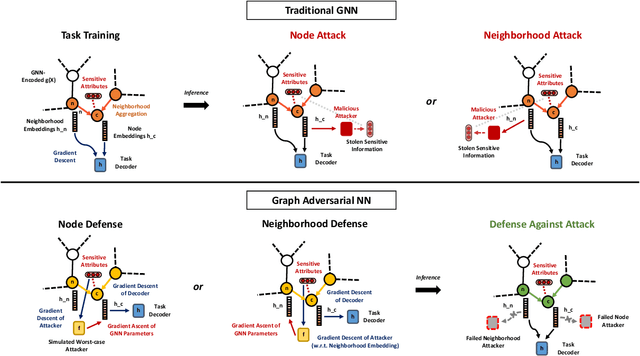
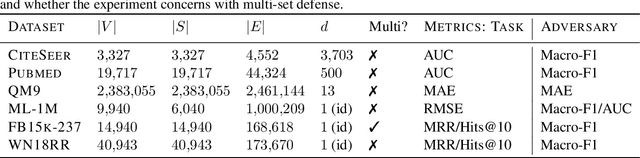
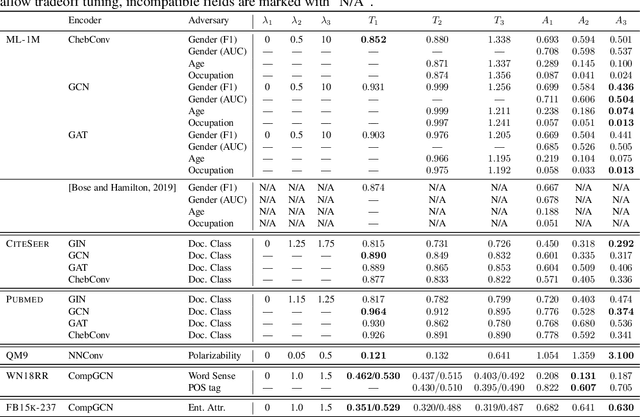
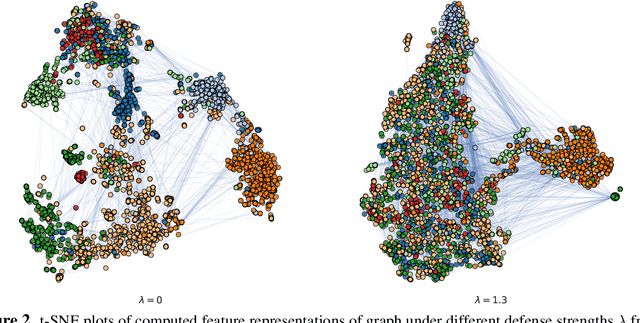
We study the problem of protecting information when learning with graph structured data. While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representational learning in many applications, the neighborhood aggregation paradigm exposes additional vulnerabilities to attackers seeking to extract node-level information about sensitive attributes. To counter this, we propose a minimax game between the desired GNN encoder and the worst-case attacker. The resulting adversarial training creates a strong defense against inference attacks, while only suffering small loss in task performance. We analyze the effectiveness of our framework against a worst-case adversary, and characterize the trade-off between predictive accuracy and adversarial defense. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders.
V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer
Mar 20, 2022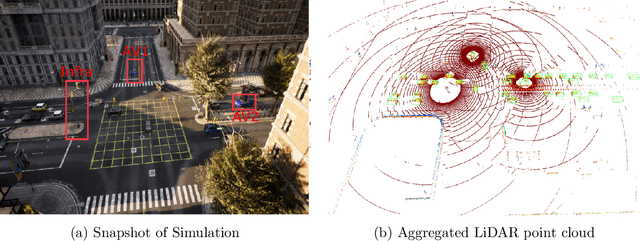
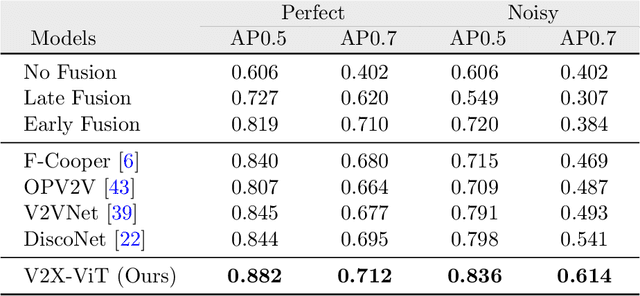
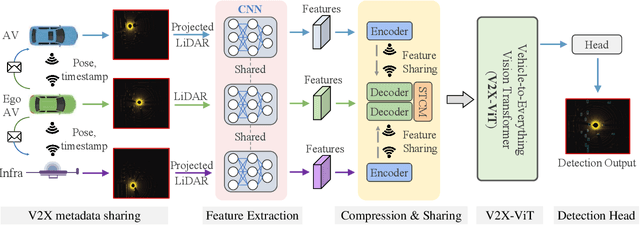
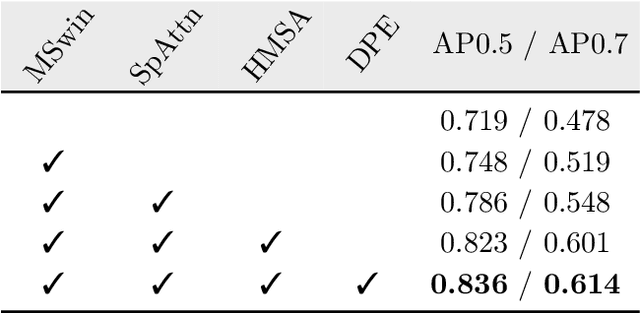
In this paper, we investigate the application of Vehicle-to-Everything (V2X) communication to improve the perception performance of autonomous vehicles. We present a robust cooperative perception framework with V2X communication using a novel vision Transformer. Specifically, we build a holistic attention model, namely V2X-ViT, to effectively fuse information across on-road agents (i.e., vehicles and infrastructure). V2X-ViT consists of alternating layers of heterogeneous multi-agent self-attention and multi-scale window self-attention, which captures inter-agent interaction and per-agent spatial relationships. These key modules are designed in a unified Transformer architecture to handle common V2X challenges, including asynchronous information sharing, pose errors, and heterogeneity of V2X components. To validate our approach, we create a large-scale V2X perception dataset using CARLA and OpenCDA. Extensive experimental results demonstrate that V2X-ViT sets new state-of-the-art performance for 3D object detection and achieves robust performance even under harsh, noisy environments. The dataset, source code, and trained models will be open-sourced.
Selection of entropy based features for the analysis of the Archimedes' spiral applied to essential tremor
Mar 18, 2022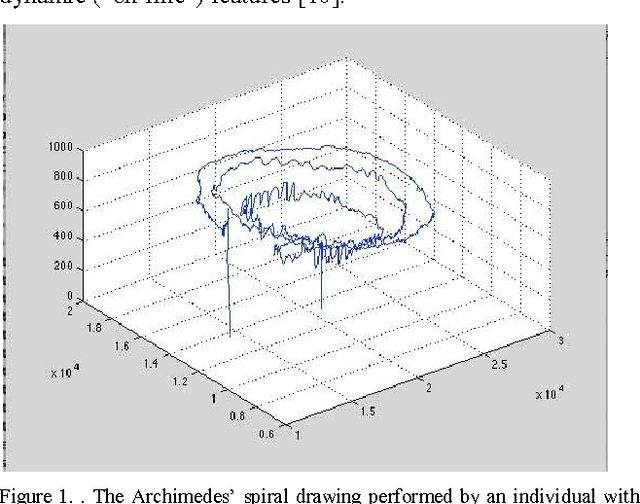
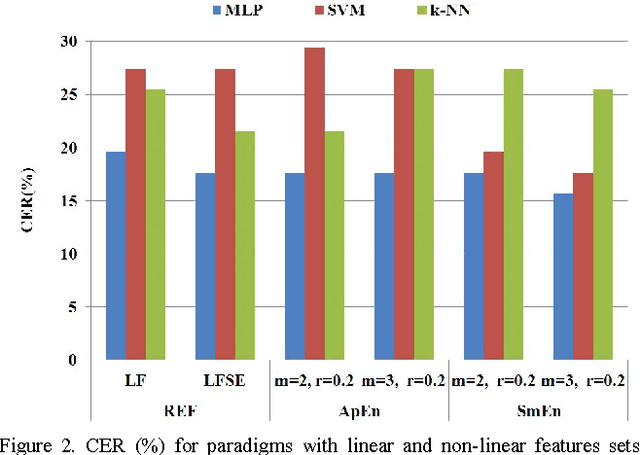
Biomedical systems are regulated by interacting mechanisms that operate across multiple spatial and temporal scales and produce biosignals with linear and non-linear information inside. In this sense entropy could provide a useful measure about disorder in the system, lack of information in time-series and/or irregularity of the signals. Essential tremor (ET) is the most common movement disorder, being 20 times more common than Parkinson's disease, and 50-70% of this disease cases are estimated to be genetic in origin. Archimedes spiral drawing is one of the most used standard tests for clinical diagnosis. This work, on selection of nonlinear biomarkers from drawings and handwriting, is part of a wide-ranging cross study for the diagnosis of essential tremor in BioDonostia Health Institute. Several entropy algorithms are used to generate nonlinear feayures. The automatic analysis system consists of several Machine Learning paradigms.
* 5 pages, published in 2015 4th International Work Conference on Bioinspired Intelligence ,IWOBI, 2015, pp. 157-162
Self-Attention for Incomplete Utterance Rewriting
Feb 26, 2022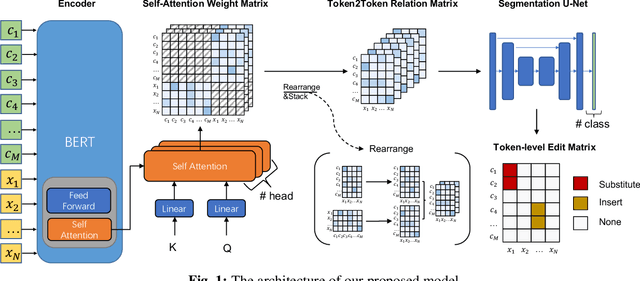
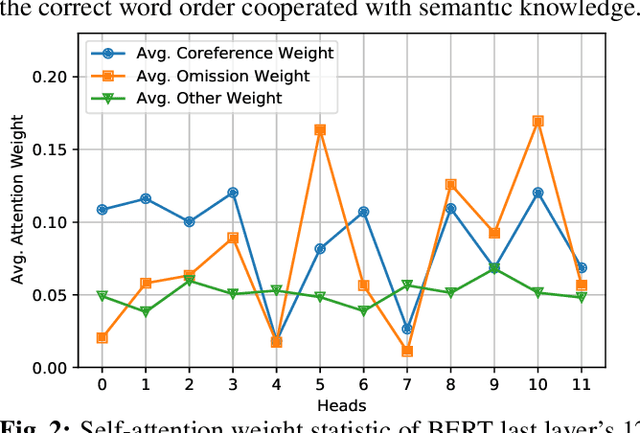
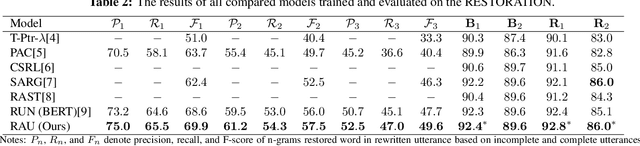
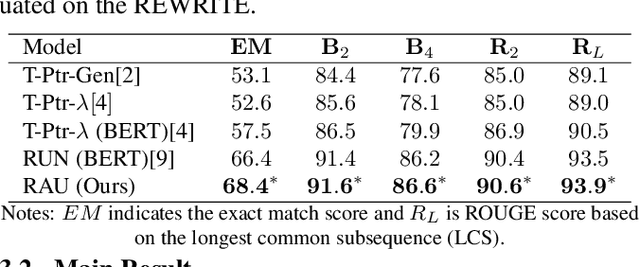
Incomplete utterance rewriting (IUR) has recently become an essential task in NLP, aiming to complement the incomplete utterance with sufficient context information for comprehension. In this paper, we propose a novel method by directly extracting the coreference and omission relationship from the self-attention weight matrix of the transformer instead of word embeddings and edit the original text accordingly to generate the complete utterance. Benefiting from the rich information in the self-attention weight matrix, our method achieved competitive results on public IUR datasets.
Semi-WTC: A Practical Semi-supervised Framework for Attack Categorization through Weight-Task Consistency
May 19, 2022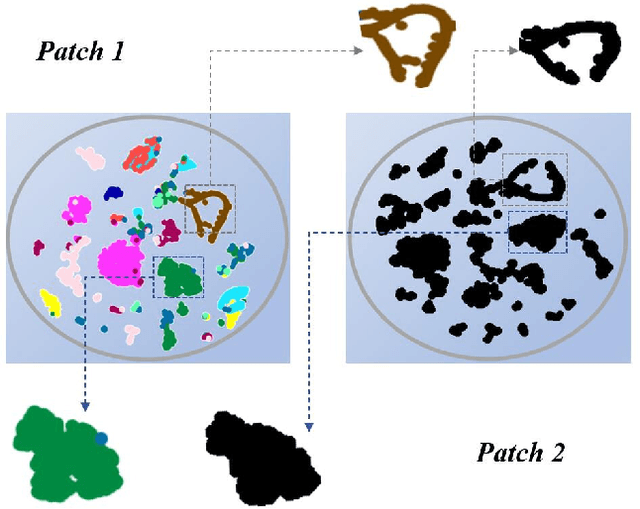

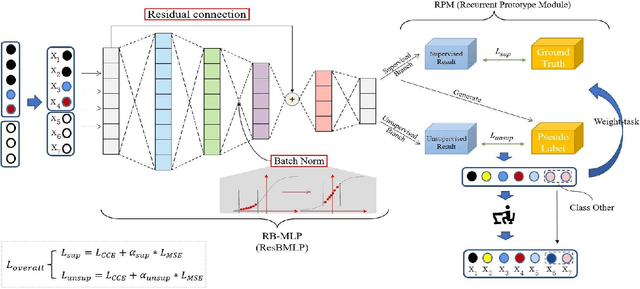
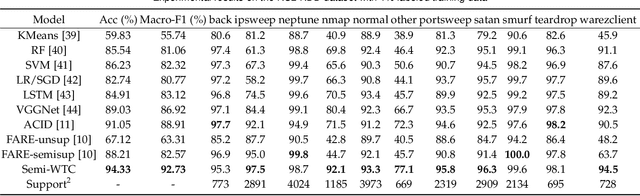
Supervised learning has been widely used for attack detection, which requires large amounts of high-quality data and labels. However, the data is often imbalanced and sufficient annotations are difficult to obtain. Moreover, these supervised models are subject to real-world deployment issues, such as defending against unseen artificial attacks. We propose a semi-supervised fine-grained attack categorization framework consisting of an encoder and a two-branch structure to integrate information from labeled and unlabeled data to tackle these practical challenges. This framework can be generalized to different supervised models. The multilayer perceptron with residual connection and batch normalization is used as the encoder to extract features and reduce the complexity. The Recurrent Prototype Module (RPM) is proposed to train the encoder effectively in a semi-supervised manner. To alleviate the problem of data imbalance, we introduce the Weight-Task Consistency (WTC) into the iterative process of RPM by assigning larger weights to classes with fewer samples in the loss function. In addition, to cope with new attacks in real-world deployment, we further propose an Active Adaption Resampling (AAR) method, which can better discover the distribution of the unseen sample data and adapt the parameters of the encoder. Experimental results show that our model outperforms the state-of-the-art semi-supervised attack detection methods with a general 5% improvement in classification accuracy and a 90% reduction in training time.
Email Summarization to Assist Users in Phishing Identification
Mar 24, 2022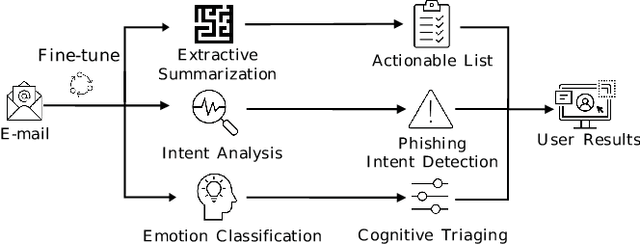

Cyber-phishing attacks recently became more precise, targeted, and tailored by training data to activate only in the presence of specific information or cues. They are adaptable to a much greater extent than traditional phishing detection. Hence, automated detection systems cannot always be 100% accurate, increasing the uncertainty around expected behavior when faced with a potential phishing email. On the other hand, human-centric defence approaches focus extensively on user training but face the difficulty of keeping users up to date with continuously emerging patterns. Therefore, advances in analyzing the content of an email in novel ways along with summarizing the most pertinent content to the recipients of emails is a prospective gateway to furthering how to combat these threats. Addressing this gap, this work leverages transformer-based machine learning to (i) analyze prospective psychological triggers, to (ii) detect possible malicious intent, and (iii) create representative summaries of emails. We then amalgamate this information and present it to the user to allow them to (i) easily decide whether the email is "phishy" and (ii) self-learn advanced malicious patterns.
Monant Medical Misinformation Dataset: Mapping Articles to Fact-Checked Claims
Apr 26, 2022
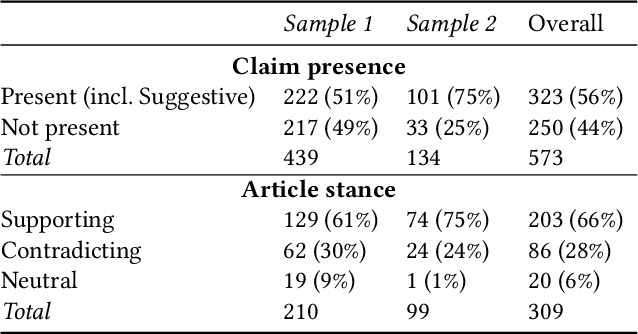

False information has a significant negative influence on individuals as well as on the whole society. Especially in the current COVID-19 era, we witness an unprecedented growth of medical misinformation. To help tackle this problem with machine learning approaches, we are publishing a feature-rich dataset of approx. 317k medical news articles/blogs and 3.5k fact-checked claims. It also contains 573 manually and more than 51k automatically labelled mappings between claims and articles. Mappings consist of claim presence, i.e., whether a claim is contained in a given article, and article stance towards the claim. We provide several baselines for these two tasks and evaluate them on the manually labelled part of the dataset. The dataset enables a number of additional tasks related to medical misinformation, such as misinformation characterisation studies or studies of misinformation diffusion between sources.
* 11 pages, 4 figures, SIGIR 2022 Resource paper track
WDV: A Broad Data Verbalisation Dataset Built from Wikidata
May 05, 2022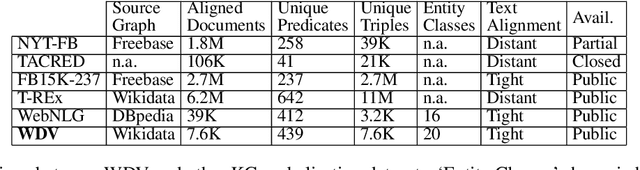
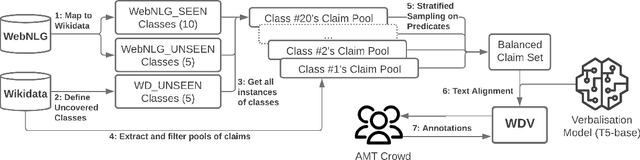
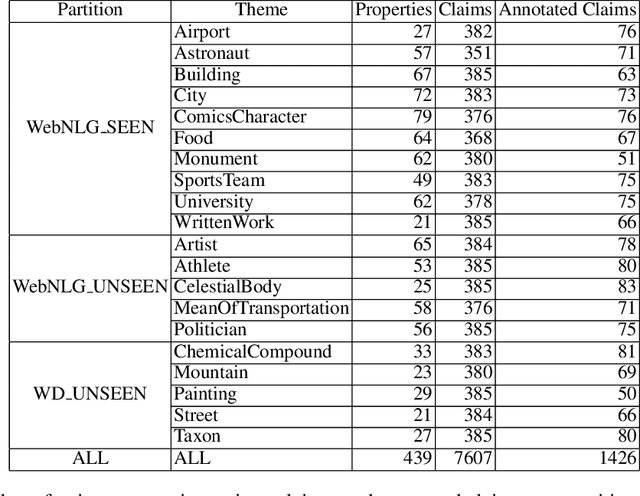
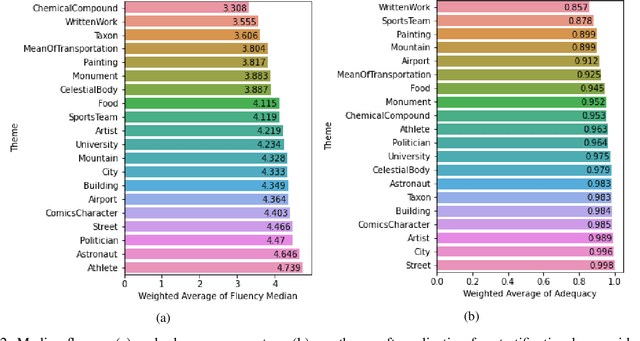
Data verbalisation is a task of great importance in the current field of natural language processing, as there is great benefit in the transformation of our abundant structured and semi-structured data into human-readable formats. Verbalising Knowledge Graph (KG) data focuses on converting interconnected triple-based claims, formed of subject, predicate, and object, into text. Although KG verbalisation datasets exist for some KGs, there are still gaps in their fitness for use in many scenarios. This is especially true for Wikidata, where available datasets either loosely couple claim sets with textual information or heavily focus on predicates around biographies, cities, and countries. To address these gaps, we propose WDV, a large KG claim verbalisation dataset built from Wikidata, with a tight coupling between triples and text, covering a wide variety of entities and predicates. We also evaluate the quality of our verbalisations through a reusable workflow for measuring human-centred fluency and adequacy scores. Our data and code are openly available in the hopes of furthering research towards KG verbalisation.