 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving AMD diagnosis by the simultaneous identification of associated retinal lesions
May 22, 2022
Age-related Macular Degeneration (AMD) is the predominant cause of blindness in developed countries, specially in elderly people. Moreover, its prevalence is increasing due to the global population ageing. In this scenario, early detection is crucial to avert later vision impairment. Nonetheless, implementing large-scale screening programmes is usually not viable, since the population at-risk is large and the analysis must be performed by expert clinicians. Also, the diagnosis of AMD is considered to be particularly difficult, as it is characterized by many different lesions that, in many cases, resemble those of other macular diseases. To overcome these issues, several works have proposed automatic methods for the detection of AMD in retinography images, the most widely used modality for the screening of the disease. Nowadays, most of these works use Convolutional Neural Networks (CNNs) for the binary classification of images into AMD and non-AMD classes. In this work, we propose a novel approach based on CNNs that simultaneously performs AMD diagnosis and the classification of its potential lesions. This latter secondary task has not yet been addressed in this domain, and provides complementary useful information that improves the diagnosis performance and helps understanding the decision. A CNN model is trained using retinography images with image-level labels for both AMD and lesion presence, which are relatively easy to obtain. The experiments conducted in several public datasets show that the proposed approach improves the detection of AMD, while achieving satisfactory results in the identification of most lesions.
A Survey of Orthographic Information in Machine Translation
Aug 04, 2020Machine translation is one of the applications of natural language processing which has been explored in different languages. Recently researchers started paying attention towards machine translation for resource-poor languages and closely related languages. A widespread and underlying problem for these machine translation systems is the variation in orthographic conventions which causes many issues to traditional approaches. Two languages written in two different orthographies are not easily comparable, but orthographic information can also be used to improve the machine translation system. This article offers a survey of research regarding orthography's influence on machine translation of under-resourced languages. It introduces under-resourced languages in terms of machine translation and how orthographic information can be utilised to improve machine translation. We describe previous work in this area, discussing what underlying assumptions were made, and showing how orthographic knowledge improves the performance of machine translation of under-resourced languages. We discuss different types of machine translation and demonstrate a recent trend that seeks to link orthographic information with well-established machine translation methods. Considerable attention is given to current efforts of cognates information at different levels of machine translation and the lessons that can be drawn from this. Additionally, multilingual neural machine translation of closely related languages is given a particular focus in this survey. This article ends with a discussion of the way forward in machine translation with orthographic information, focusing on multilingual settings and bilingual lexicon induction.
A Densely Connected Criss-Cross Attention Network for Document-level Relation Extraction
Mar 26, 2022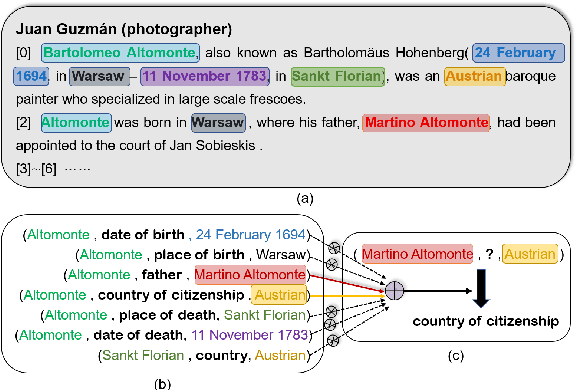
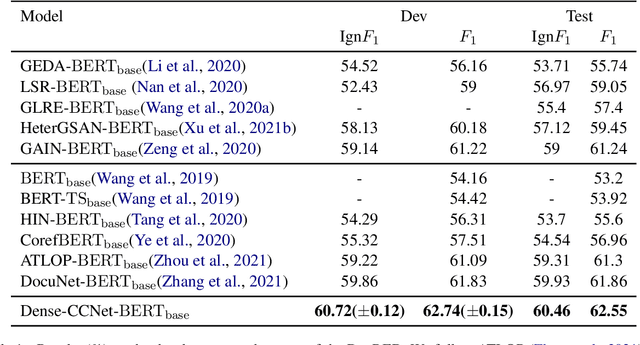
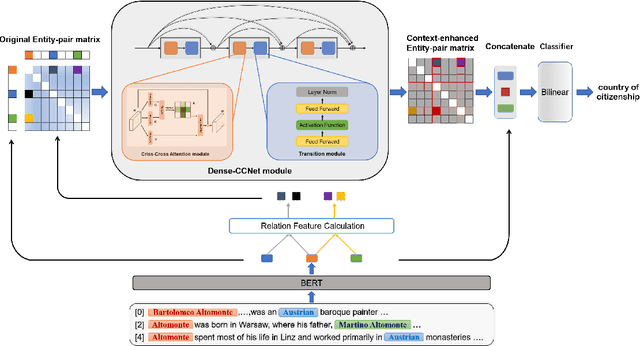
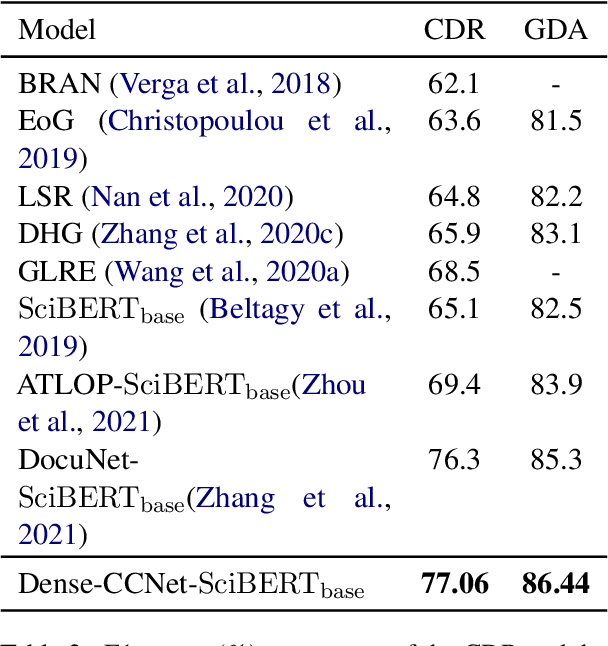
Document-level relation extraction (RE) aims to identify relations between two entities in a given document. Compared with its sentence-level counterpart, document-level RE requires complex reasoning. Previous research normally completed reasoning through information propagation on the mention-level or entity-level document-graph, but rarely considered reasoning at the entity-pair-level.In this paper, we propose a novel model, called Densely Connected Criss-Cross Attention Network (Dense-CCNet), for document-level RE, which can complete logical reasoning at the entity-pair-level. Specifically, the Dense-CCNet performs entity-pair-level logical reasoning through the Criss-Cross Attention (CCA), which can collect contextual information in horizontal and vertical directions on the entity-pair matrix to enhance the corresponding entity-pair representation. In addition, we densely connect multiple layers of the CCA to simultaneously capture the features of single-hop and multi-hop logical reasoning.We evaluate our Dense-CCNet model on three public document-level RE datasets, DocRED, CDR, and GDA. Experimental results demonstrate that our model achieves state-of-the-art performance on these three datasets.
$G^2$: Enhance Knowledge Grounded Dialogue via Ground Graph
Apr 27, 2022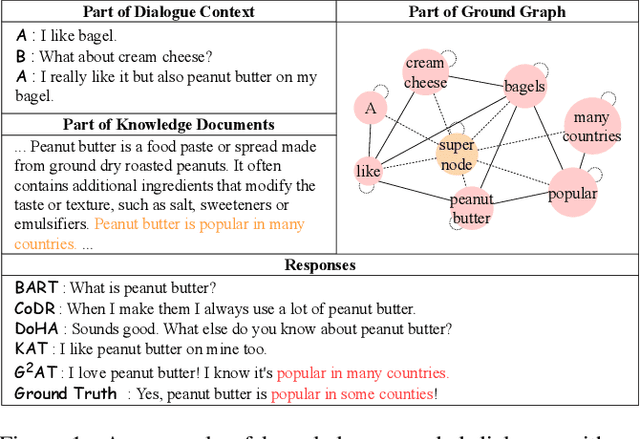
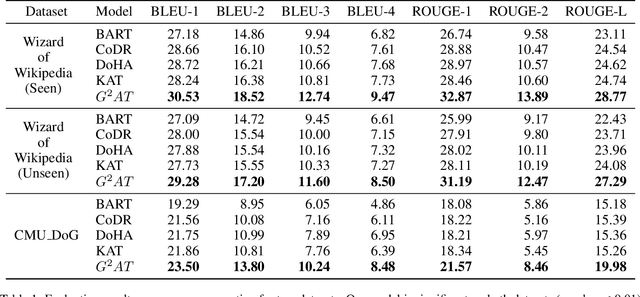
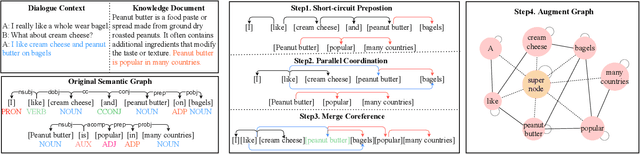
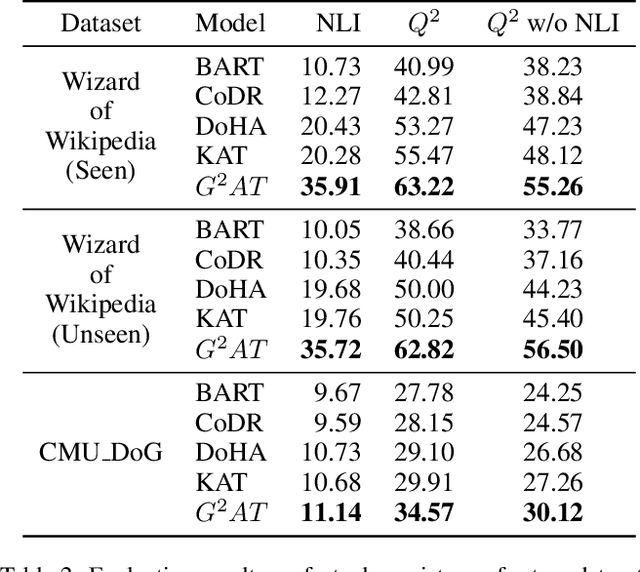
Knowledge grounded dialogue system is designed to generate responses that convey information from given knowledge documents. However, it's a challenge for the current Seq2Seq model to acquire knowledge from complex documents and integrate it to perform correct responses without the aid of an explicit semantic structure. To address these issues, we present a novel graph structure, Ground Graph ($G^2$), which models the semantic structure of both dialogue contexts and knowledge documents to facilitate knowledge selection and integration for the task. Besides, a Ground Graph Aware Transformer ($G^2AT$) is proposed to enhance knowledge grounded response generation. Empirical results show that our proposed model outperforms previous state-of-the-art methods with more than 10\% and 20\% gains on response generation and factual consistency. Furthermore, our structure-aware approach shows excellent generalization ability in resource-limited situations.
UniGDD: A Unified Generative Framework for Goal-Oriented Document-Grounded Dialogue
Apr 16, 2022



The goal-oriented document-grounded dialogue aims at responding to the user query based on the dialogue context and supporting document. Existing studies tackle this problem by decomposing it into two sub-tasks: knowledge identification and response generation. However, such pipeline methods would unavoidably suffer from the error propagation issue. This paper proposes to unify these two sub-tasks via sequentially generating the grounding knowledge and the response. We further develop a prompt-connected multi-task learning strategy to model the characteristics and connections of different tasks and introduce linear temperature scheduling to reduce the negative effect of irrelevant document information. Experimental results demonstrate the effectiveness of our framework.
Selectively Contextual Bandits
May 09, 2022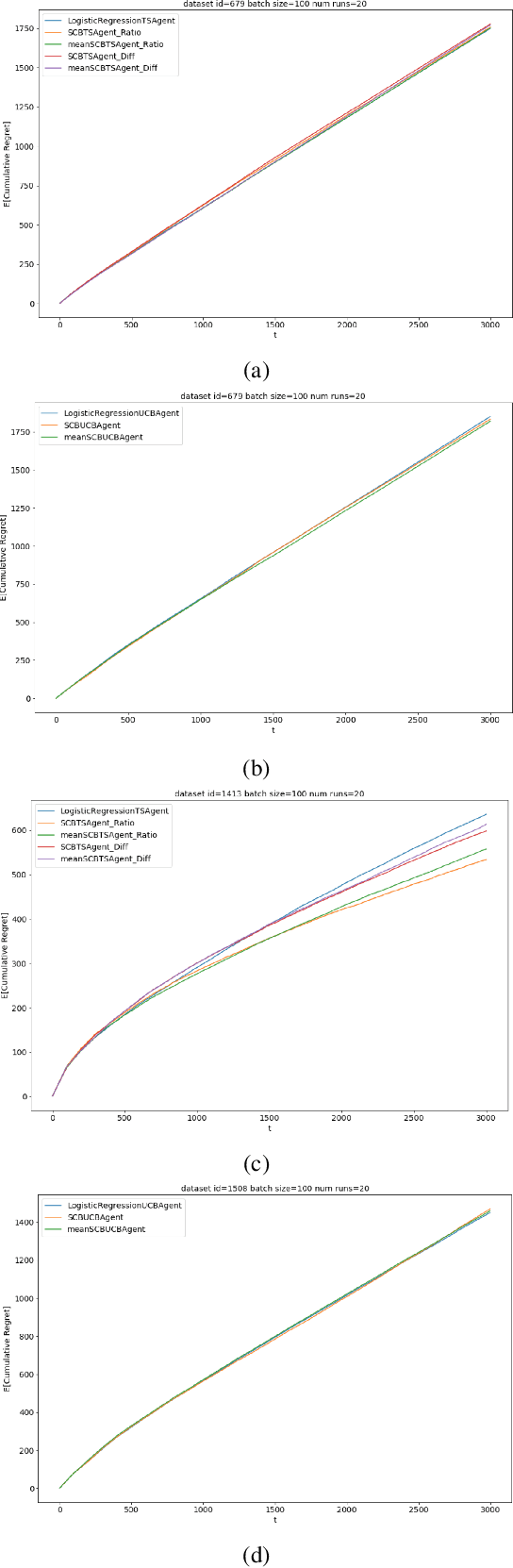
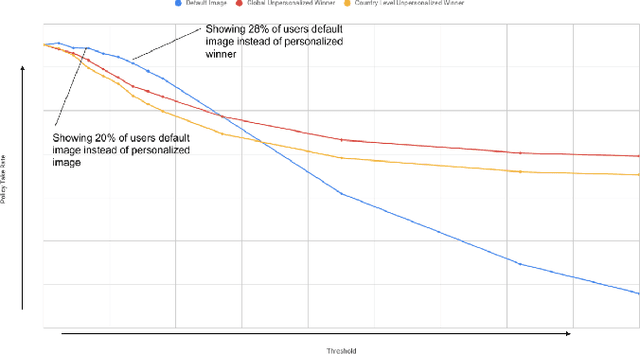
Contextual bandits are widely used in industrial personalization systems. These online learning frameworks learn a treatment assignment policy in the presence of treatment effects that vary with the observed contextual features of the users. While personalization creates a rich user experience that reflect individual interests, there are benefits of a shared experience across a community that enable participation in the zeitgeist. Such benefits are emergent through network effects and are not captured in regret metrics typically employed in evaluating bandits. To balance these needs, we propose a new online learning algorithm that preserves benefits of personalization while increasing the commonality in treatments across users. Our approach selectively interpolates between a contextual bandit algorithm and a context-free multi-arm bandit and leverages the contextual information for a treatment decision only if it promises significant gains. Apart from helping users of personalization systems balance their experience between the individualized and shared, simplifying the treatment assignment policy by making it selectively reliant on the context can help improve the rate of learning in some cases. We evaluate our approach in a classification setting using public datasets and show the benefits of the hybrid policy.
Semi-WTC: A Practical Semi-supervised Framework for Attack Categorization through Weight-Task Consistency
May 19, 2022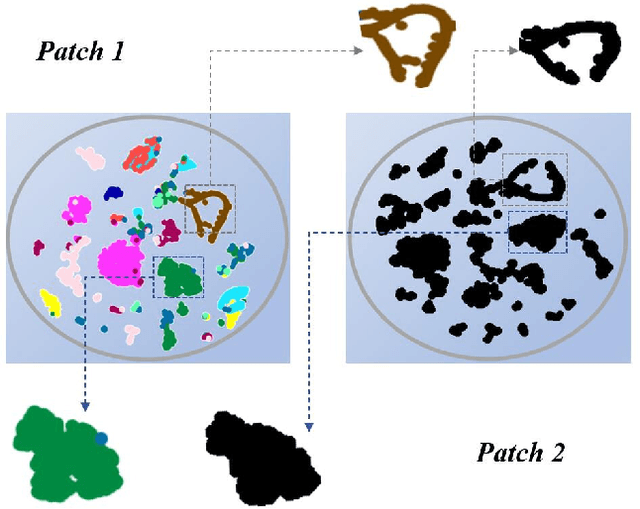

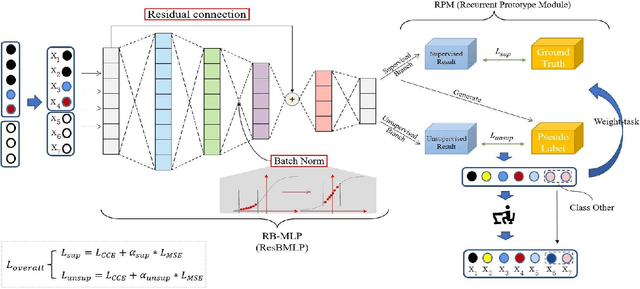
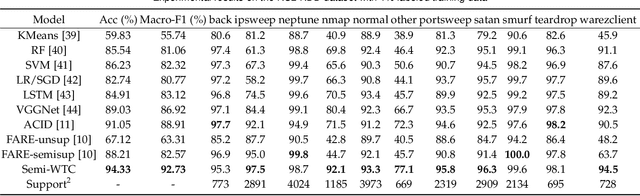
Supervised learning has been widely used for attack detection, which requires large amounts of high-quality data and labels. However, the data is often imbalanced and sufficient annotations are difficult to obtain. Moreover, these supervised models are subject to real-world deployment issues, such as defending against unseen artificial attacks. We propose a semi-supervised fine-grained attack categorization framework consisting of an encoder and a two-branch structure to integrate information from labeled and unlabeled data to tackle these practical challenges. This framework can be generalized to different supervised models. The multilayer perceptron with residual connection and batch normalization is used as the encoder to extract features and reduce the complexity. The Recurrent Prototype Module (RPM) is proposed to train the encoder effectively in a semi-supervised manner. To alleviate the problem of data imbalance, we introduce the Weight-Task Consistency (WTC) into the iterative process of RPM by assigning larger weights to classes with fewer samples in the loss function. In addition, to cope with new attacks in real-world deployment, we further propose an Active Adaption Resampling (AAR) method, which can better discover the distribution of the unseen sample data and adapt the parameters of the encoder. Experimental results show that our model outperforms the state-of-the-art semi-supervised attack detection methods with a general 5% improvement in classification accuracy and a 90% reduction in training time.
Information Leakage in Embedding Models
Mar 31, 2020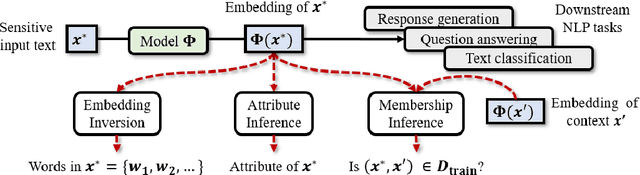
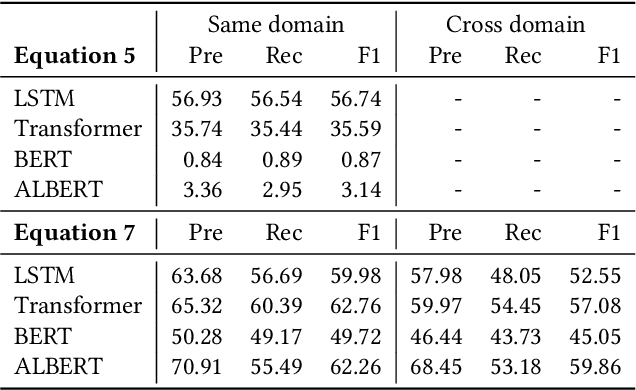
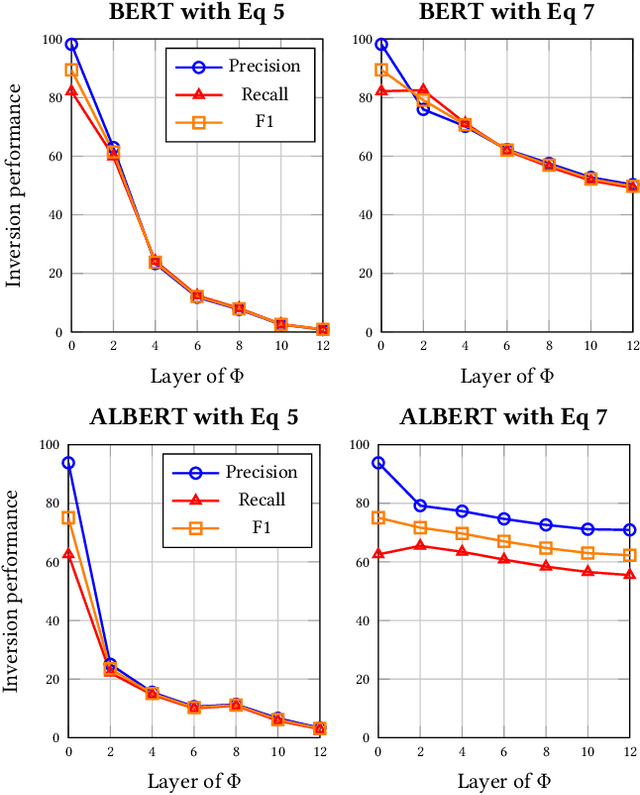
Embeddings are functions that map raw input data to low-dimensional vector representations, while preserving important semantic information about the inputs. Pre-training embeddings on a large amount of unlabeled data and fine-tuning them for downstream tasks is now a de facto standard in achieving state of the art learning in many domains. We demonstrate that embeddings, in addition to encoding generic semantics, often also present a vector that leaks sensitive information about the input data. We develop three classes of attacks to systematically study information that might be leaked by embeddings. First, embedding vectors can be inverted to partially recover some of the input data. As an example, we show that our attacks on popular sentence embeddings recover between 50\%--70\% of the input words (F1 scores of 0.5--0.7). Second, embeddings may reveal sensitive attributes inherent in inputs and independent of the underlying semantic task at hand. Attributes such as authorship of text can be easily extracted by training an inference model on just a handful of labeled embedding vectors. Third, embedding models leak moderate amount of membership information for infrequent training data inputs. We extensively evaluate our attacks on various state-of-the-art embedding models in the text domain. We also propose and evaluate defenses that can prevent the leakage to some extent at a minor cost in utility.
Lattices from Linear Codes: Source and Channel Networks
Feb 23, 2022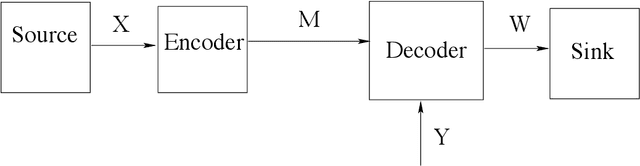
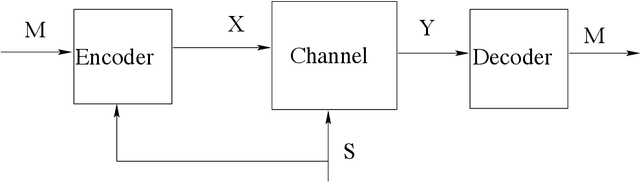
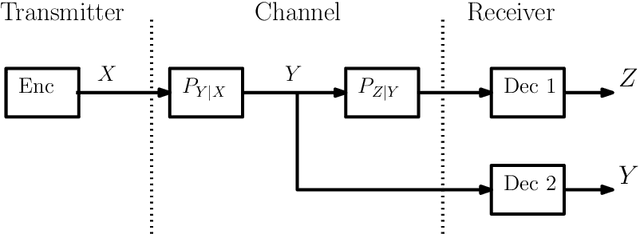
In this paper, we consider the information-theoretic characterization of the set of achievable rates and distortions in a broad class of multiterminal communication scenarios with general continuous-valued sources and channels. A framework is presented which involves fine discretization of the source and channel variables followed by communication over the resulting discretized network. In order to evaluate fundamental performance limits, convergence results for information measures are provided under the proposed discretization process. Using this framework, we consider point-to-point source coding and channel coding with side-information, distributed source coding with distortion constraints, the function reconstruction problems (two-help-one), computation over multiple access channel, the interference channel, and the multiple-descriptions source coding problem. We construct lattice-like codes for general sources and channels, and derive inner-bounds to set of achievable rates and distortions in these communication scenarios.
Phase-Aware Spoof Speech Detection Based on Res2Net with Phase Network
Mar 21, 2022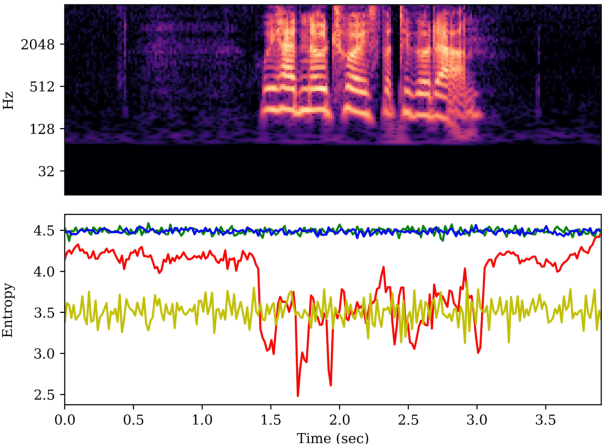
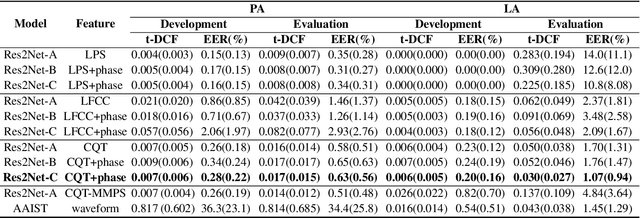
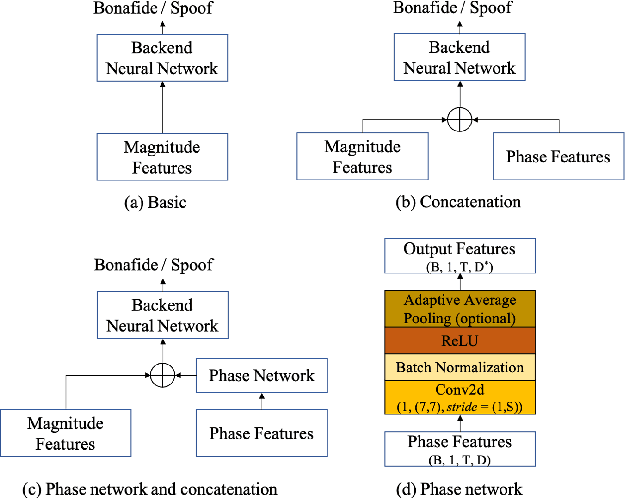

The spoof speech detection (SSD) is the essential countermeasure for automatic speaker verification systems. Although SSD with magnitude features in the frequency domain has shown promising results, the phase information also can be important to capture the artefacts of certain types of spoofing attacks. Thus, both magnitude and phase features must be considered to ensure the generalization ability to diverse types of spoofing attacks. In this paper, we investigate the failure reason of feature-level fusion of the previous works through the entropy analysis from which we found that the randomness difference between magnitude and phase features is large, which can interrupt the feature-level fusion via backend neural network; thus, we propose a phase network to reduce that difference. Our SSD system: phase network equipped Res2Net achieved significant performance improvement, specifically in the spoofing attack for which the phase information is considered to be important. Also, we demonstrate our SSD system in both known- and unknown-kind SSD scenarios for practical applications.