 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comprehensive Survey of Few-shot Learning: Evolution, Applications, Challenges, and Opportunities
May 13, 2022

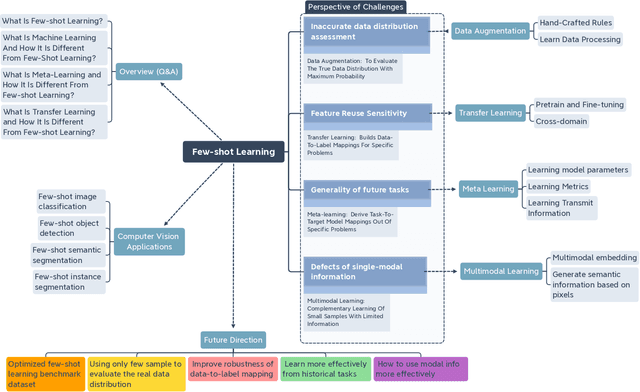
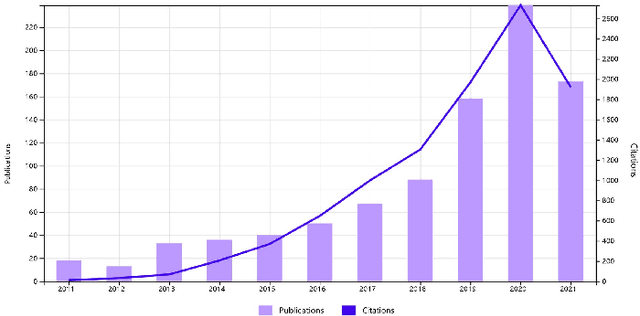
Few-shot learning (FSL) has emerged as an effective learning method and shows great potential. Despite the recent creative works in tackling FSL tasks, learning valid information rapidly from just a few or even zero samples still remains a serious challenge. In this context, we extensively investigated 200+ latest papers on FSL published in the past three years, aiming to present a timely and comprehensive overview of the most recent advances in FSL along with impartial comparisons of the strengths and weaknesses of the existing works. For the sake of avoiding conceptual confusion, we first elaborate and compare a set of similar concepts including few-shot learning, transfer learning, and meta-learning. Furthermore, we propose a novel taxonomy to classify the existing work according to the level of abstraction of knowledge in accordance with the challenges of FSL. To enrich this survey, in each subsection we provide in-depth analysis and insightful discussion about recent advances on these topics. Moreover, taking computer vision as an example, we highlight the important application of FSL, covering various research hotspots. Finally, we conclude the survey with unique insights into the technology evolution trends together with potential future research opportunities in the hope of providing guidance to follow-up research.
A Vision Inspired Neural Network for Unsupervised Anomaly Detection in Unordered Data
May 13, 2022
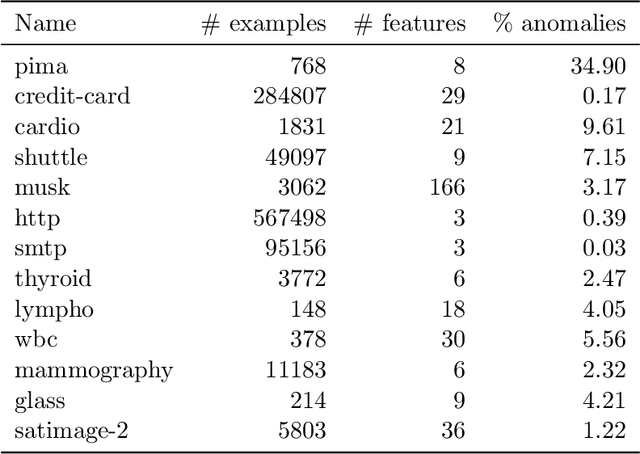
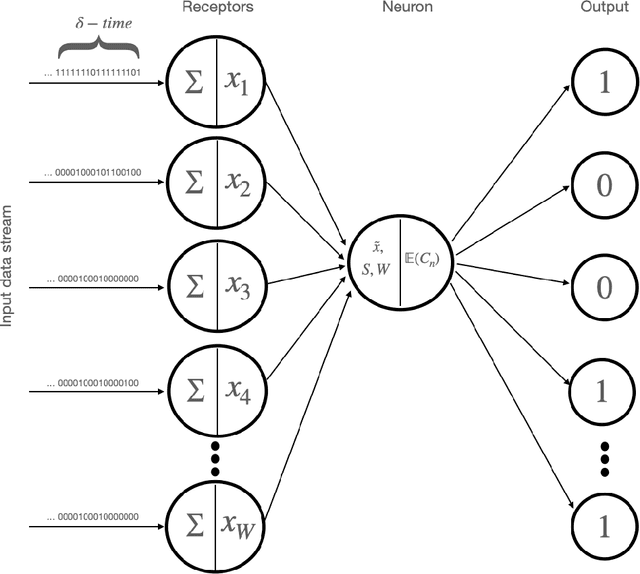
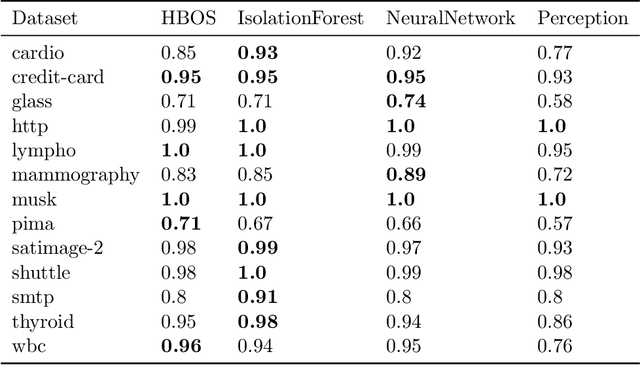
A fundamental problem in the field of unsupervised machine learning is the detection of anomalies corresponding to rare and unusual observations of interest; reasons include for their rejection, accommodation or further investigation. Anomalies are intuitively understood to be something unusual or inconsistent, whose occurrence sparks immediate attention. More formally anomalies are those observations-under appropriate random variable modelling-whose expectation of occurrence with respect to a grouping of prior interest is less than one; such a definition and understanding has been used to develop the parameter-free perception anomaly detection algorithm. The present work seeks to establish important and practical connections between the approach used by the perception algorithm and prior decades of research in neurophysiology and computational neuroscience; particularly that of information processing in the retina and visual cortex. The algorithm is conceptualised as a neuron model which forms the kernel of an unsupervised neural network that learns to signal unexpected observations as anomalies. Both the network and neuron display properties observed in biological processes including: immediate intelligence; parallel processing; redundancy; global degradation; contrast invariance; parameter-free computation, dynamic thresholds and non-linear processing. A robust and accurate model for anomaly detection in univariate and multivariate data is built using this network as a concrete application.
Measuring Information Propagation in Literary Social Networks
Apr 29, 2020
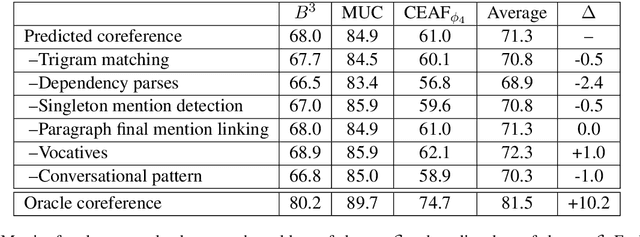
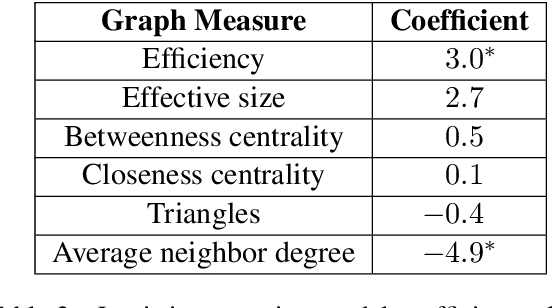
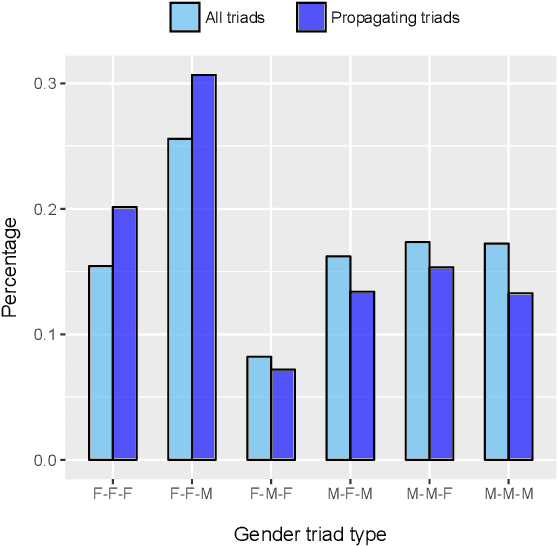
We present the task of modeling information propagation in literature, in which we seek to identify pieces of information passing from character A to character B to character C, only given a description of their activity in text. We describe a new pipeline for measuring information propagation in this domain and publish a new dataset for speaker attribution, enabling the evaluation of an important component of this pipeline on a wider range of literary texts than previously studied. Using this pipeline, we analyze the dynamics of information propagation in over 5,000 works of fiction, finding that information flows through characters that fill structural holes connecting different communities, and that characters who are women are depicted as filling this role much more frequently than characters who are men.
OpenMatch: An Open-Source Package for Information Retrieval
Feb 04, 2021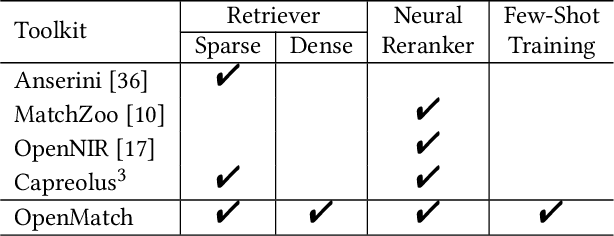
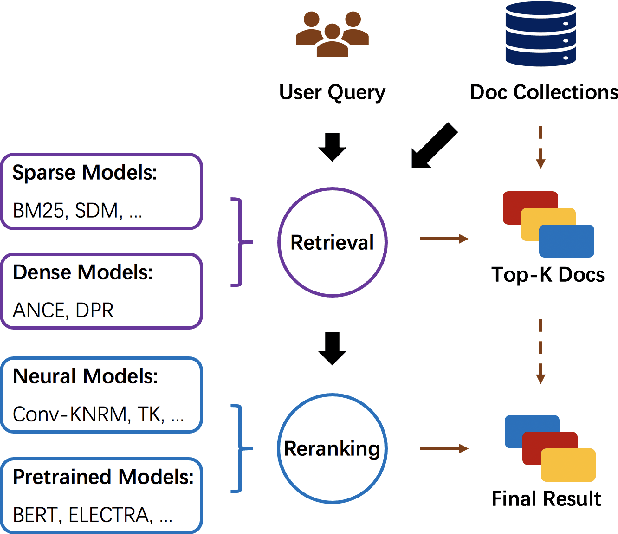
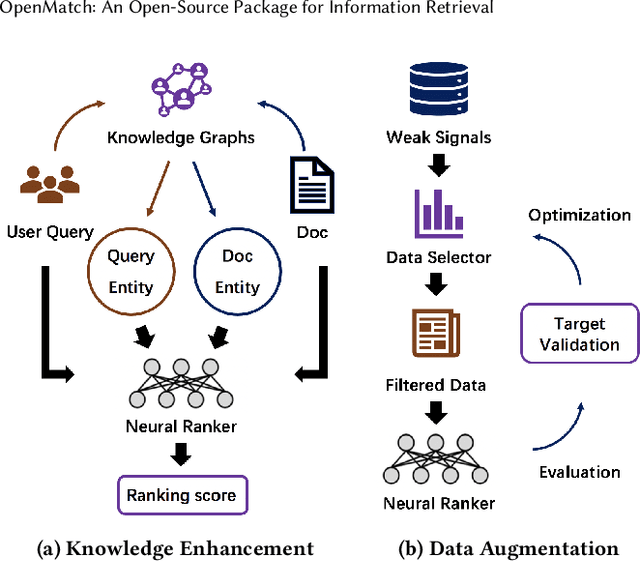
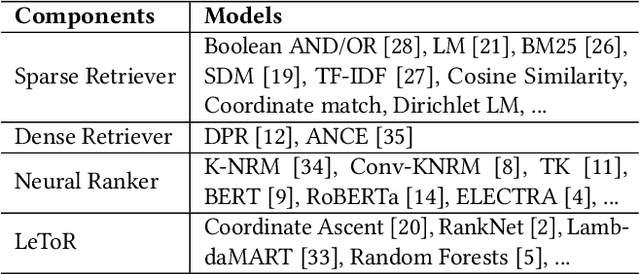
Information Retrieval (IR) is an important task and can be used in many applications. Neural IR (Neu-IR) models overcome the vocabulary mismatch problem of sparse retrievers and thrive on the ranking pipeline with semantic matching. Recent progress in IR mainly focuses on Neu-IR models, including efficient dense retrieval, advanced neural architectures and robustly training for few-shot IR that lacks training data. In order to integrate these advantages for researchers and engineers to utilize and develop, OpenMatch provides various functional neural modules based on PyTorch to maintain sufficient extensibility, making it easy to build customized and higher-capacity IR systems. Besides, OpenMatch consists of complicated optimization tricks, various sparse/dense retrieval methods, and advanced few-shot training methods, liberating users from surplus labor in baseline reimplementation and neural model finetuning. With OpenMatch, we achieve reasonable performance on various ranking datasets, rank first of the automatic group in TREC COVID (Round 2) and rank top on the MS MARCO Document Ranking leaderboard. The library, experimental methodologies and results of OpenMatch are all publicly available at https://github.com/thunlp/OpenMatch.
Layer-wise Model Pruning based on Mutual Information
Aug 28, 2021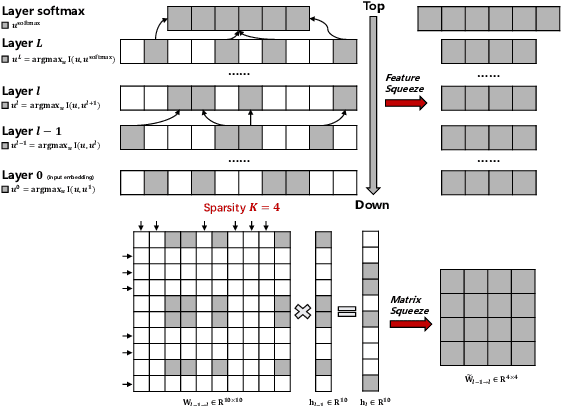
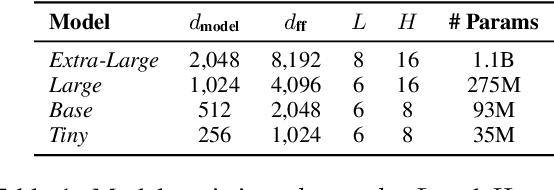
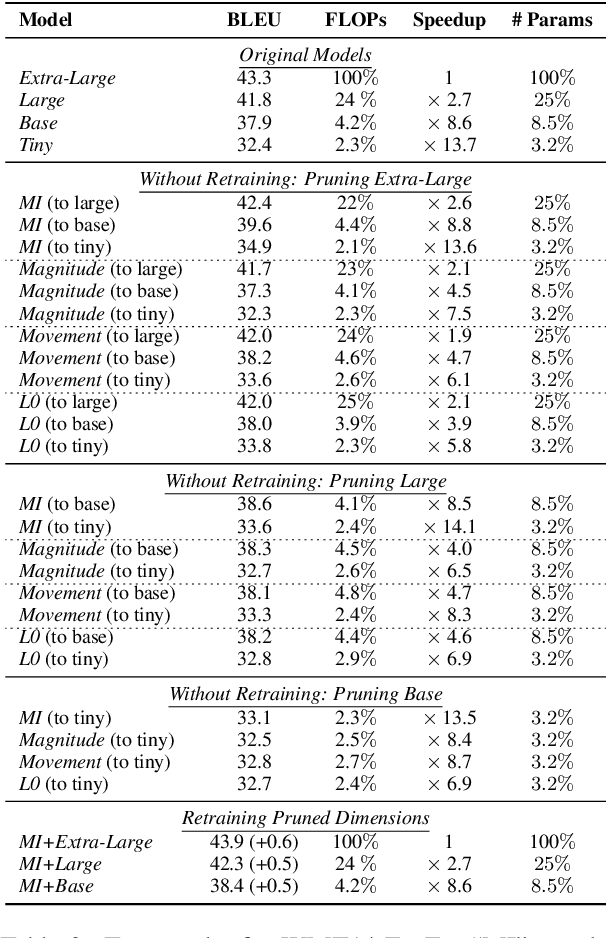
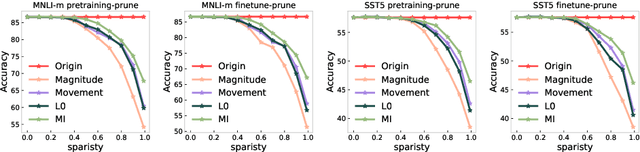
The proposed pruning strategy offers merits over weight-based pruning techniques: (1) it avoids irregular memory access since representations and matrices can be squeezed into their smaller but dense counterparts, leading to greater speedup; (2) in a manner of top-down pruning, the proposed method operates from a more global perspective based on training signals in the top layer, and prunes each layer by propagating the effect of global signals through layers, leading to better performances at the same sparsity level. Extensive experiments show that at the same sparsity level, the proposed strategy offers both greater speedup and higher performances than weight-based pruning methods (e.g., magnitude pruning, movement pruning).
Diffuse Map Guiding Unsupervised Generative Adversarial Network for SVBRDF Estimation
May 25, 2022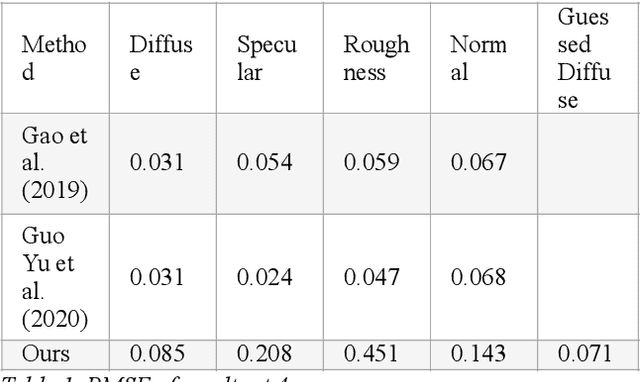
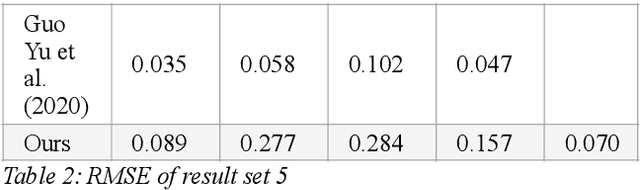
Reconstructing materials in the real world has always been a difficult problem in computer graphics. Accurately reconstructing the material in the real world is critical in the field of realistic rendering. Traditionally, materials in computer graphics are mapped by an artist, then mapped onto a geometric model by coordinate transformation, and finally rendered with a rendering engine to get realistic materials. For opaque objects, the industry commonly uses physical-based bidirectional reflectance distribution function (BRDF) rendering models for material modeling. The commonly used physical-based rendering models are Cook-Torrance BRDF, Disney BRDF. In this paper, we use the Cook-Torrance model to reconstruct the materials. The SVBRDF material parameters include Normal, Diffuse, Specular and Roughness. This paper presents a Diffuse map guiding material estimation method based on the Generative Adversarial Network(GAN). This method can predict plausible SVBRDF maps with global features using only a few pictures taken by the mobile phone. The main contributions of this paper are: 1) We preprocess a small number of input pictures to produce a large number of non-repeating pictures for training to reduce over-fitting. 2) We use a novel method to directly obtain the guessed diffuse map with global characteristics, which provides more prior information for the training process. 3) We improve the network architecture of the generator so that it can generate fine details of normal maps and reduce the possibility to generate over-flat normal maps. The method used in this paper can obtain prior knowledge without using dataset training, which greatly reduces the difficulty of material reconstruction and saves a lot of time to generate and calibrate datasets.
DACSR: Dual-Aggregation End-to-End Calibrated Sequential Recommendation
Apr 29, 2022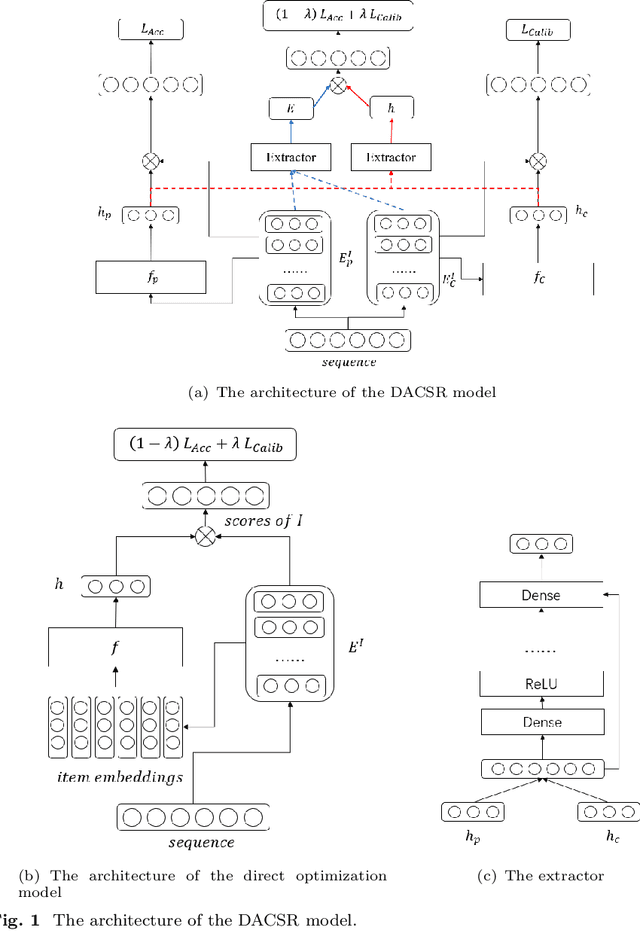
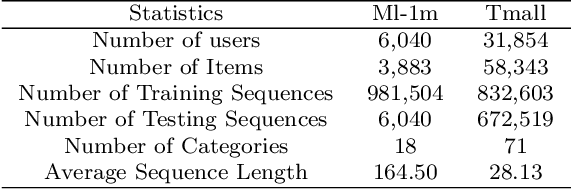
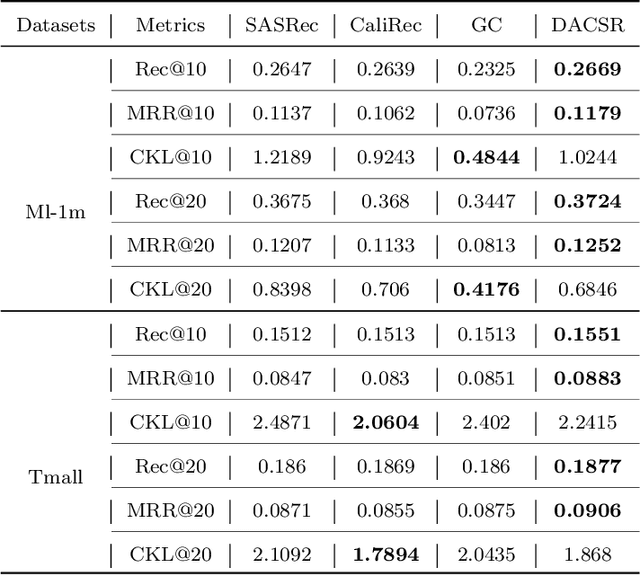
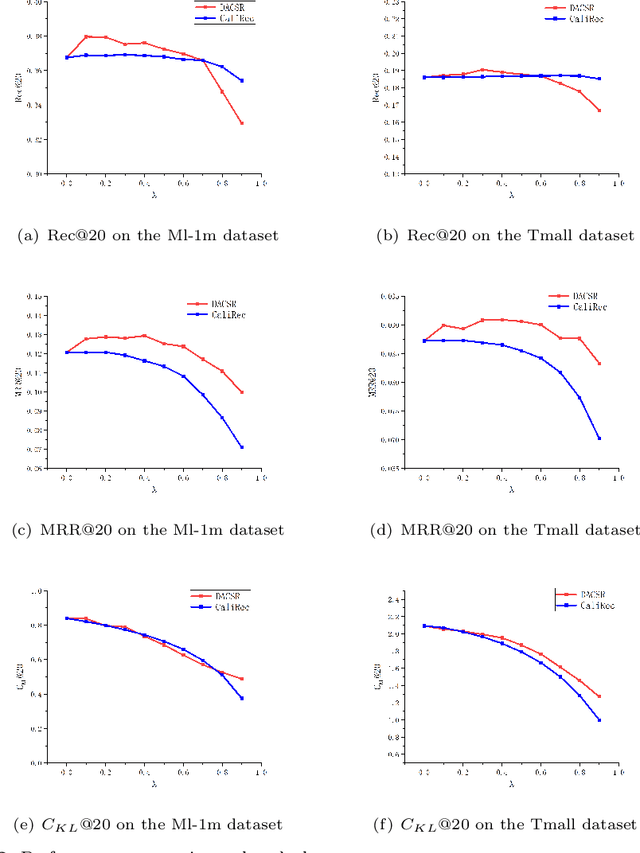
Recent years have witnessed the progress of sequential recommendation in accurately predicting users' future behaviors. However, only persuading accuracy leads to the risk of filter bubbles where recommenders only focus on users' main interest areas. Different from other studies which improve diversity or coverage, we investigate the calibration in sequential recommendation. However, existing calibrated methods followed a post-processing paradigm, which costs more computation time and sacrifices the recommendation accuracy. To this end, we propose an end-to-end framework to provide both accurate and calibrated recommendations. We propose a loss function to measure the divergence of distributions between recommendation lists and historical behaviors for sequential recommendation framework. In addition, we design a dual-aggregation model which extracts information from two individual sequence encoders with different objectives to further improve the recommendation. Experiments on two benchmark datasets demonstrate the effectiveness and efficiency of our model.
Implicit Motion-Compensated Network for Unsupervised Video Object Segmentation
Apr 06, 2022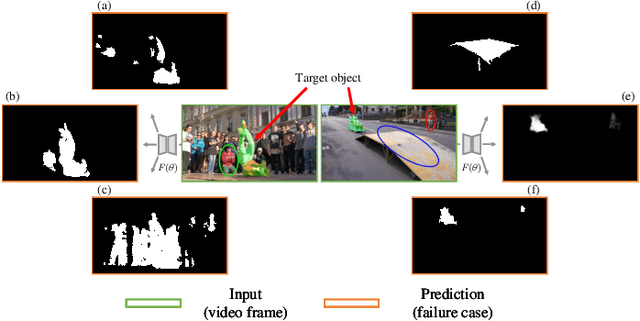



Unsupervised video object segmentation (UVOS) aims at automatically separating the primary foreground object(s) from the background in a video sequence. Existing UVOS methods either lack robustness when there are visually similar surroundings (appearance-based) or suffer from deterioration in the quality of their predictions because of dynamic background and inaccurate flow (flow-based). To overcome the limitations, we propose an implicit motion-compensated network (IMCNet) combining complementary cues ($\textit{i.e.}$, appearance and motion) with aligned motion information from the adjacent frames to the current frame at the feature level without estimating optical flows. The proposed IMCNet consists of an affinity computing module (ACM), an attention propagation module (APM), and a motion compensation module (MCM). The light-weight ACM extracts commonality between neighboring input frames based on appearance features. The APM then transmits global correlation in a top-down manner. Through coarse-to-fine iterative inspiring, the APM will refine object regions from multiple resolutions so as to efficiently avoid losing details. Finally, the MCM aligns motion information from temporally adjacent frames to the current frame which achieves implicit motion compensation at the feature level. We perform extensive experiments on $\textit{DAVIS}_{\textit{16}}$ and $\textit{YouTube-Objects}$. Our network achieves favorable performance while running at a faster speed compared to the state-of-the-art methods.
Information Theoretic Counterfactual Learning from Missing-Not-At-Random Feedback
Sep 06, 2020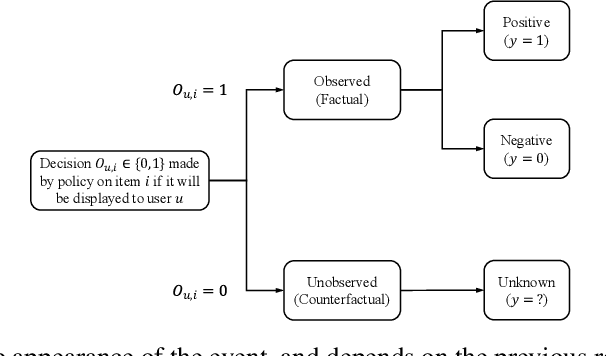
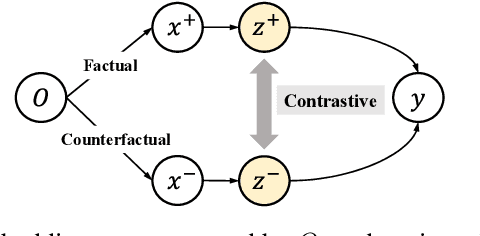
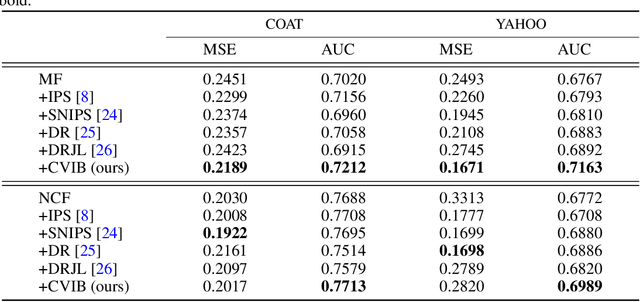
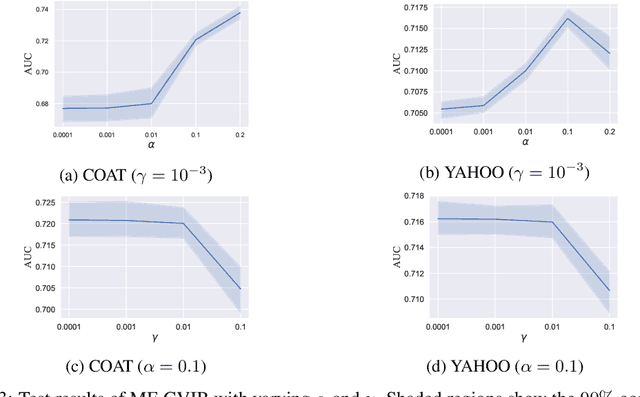
Counterfactual learning for dealing with missing-not-at-random data (MNAR) is an intriguing topic in the recommendation literature, since MNAR data are ubiquitous in modern recommender systems. Missing-at-random (MAR) data, namely randomized controlled trials (RCTs), are usually required by most previous counterfactual learning methods. However, the execution of RCTs is extraordinarily expensive in practice. To circumvent the use of RCTs, we build an information theoretic counterfactual variational information bottleneck (CVIB), as an alternative for debiasing learning without RCTs. By separating the task-aware mutual information term in the original information bottleneck Lagrangian into factual and counterfactual parts, we derive a contrastive information loss and an additional output confidence penalty, which facilitates balanced learning between the factual and counterfactual domains. Empirical evaluation on real-world datasets shows that our CVIB significantly enhances both shallow and deep models, which sheds light on counterfactual learning in recommendation that goes beyond RCTs.
Improving AMD diagnosis by the simultaneous identification of associated retinal lesions
May 22, 2022Age-related Macular Degeneration (AMD) is the predominant cause of blindness in developed countries, specially in elderly people. Moreover, its prevalence is increasing due to the global population ageing. In this scenario, early detection is crucial to avert later vision impairment. Nonetheless, implementing large-scale screening programmes is usually not viable, since the population at-risk is large and the analysis must be performed by expert clinicians. Also, the diagnosis of AMD is considered to be particularly difficult, as it is characterized by many different lesions that, in many cases, resemble those of other macular diseases. To overcome these issues, several works have proposed automatic methods for the detection of AMD in retinography images, the most widely used modality for the screening of the disease. Nowadays, most of these works use Convolutional Neural Networks (CNNs) for the binary classification of images into AMD and non-AMD classes. In this work, we propose a novel approach based on CNNs that simultaneously performs AMD diagnosis and the classification of its potential lesions. This latter secondary task has not yet been addressed in this domain, and provides complementary useful information that improves the diagnosis performance and helps understanding the decision. A CNN model is trained using retinography images with image-level labels for both AMD and lesion presence, which are relatively easy to obtain. The experiments conducted in several public datasets show that the proposed approach improves the detection of AMD, while achieving satisfactory results in the identification of most lesions.