 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Mean-Reverting Time Series Prediction with Gaussian Processes: Functional and Augmented Data Structures in Financial Forecasting
Feb 23, 2024
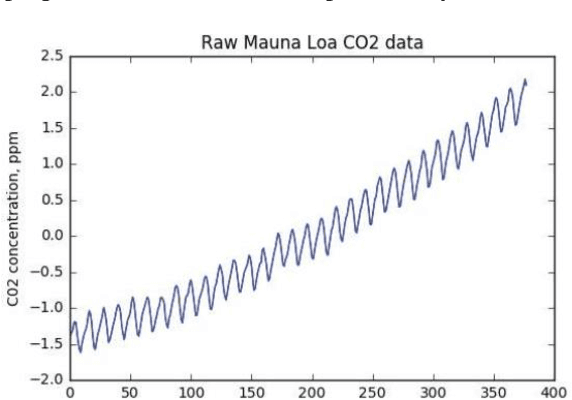
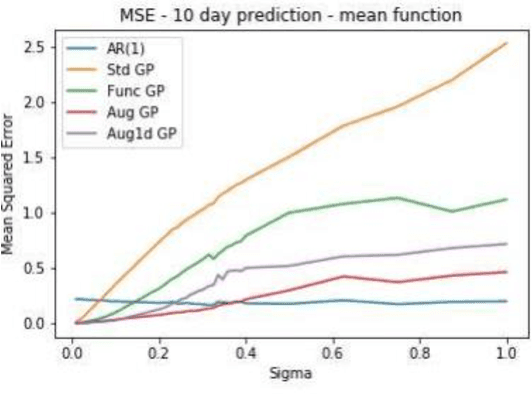
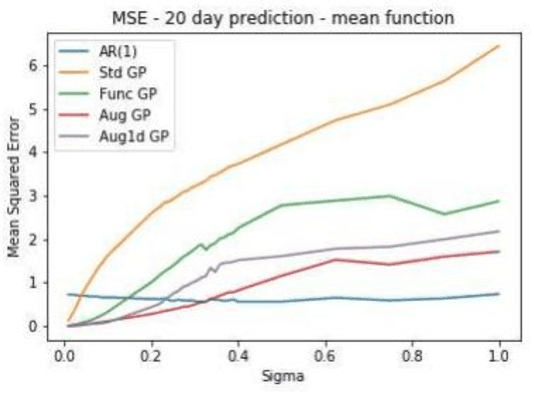
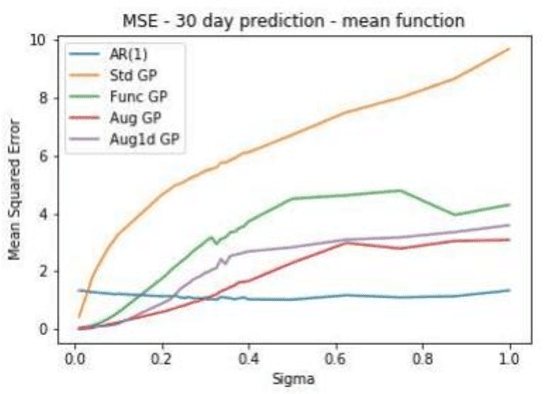
In this paper, we explore the application of Gaussian Processes (GPs) for predicting mean-reverting time series with an underlying structure, using relatively unexplored functional and augmented data structures. While many conventional forecasting methods concentrate on the short-term dynamics of time series data, GPs offer the potential to forecast not just the average prediction but the entire probability distribution over a future trajectory. This is particularly beneficial in financial contexts, where accurate predictions alone may not suffice if incorrect volatility assessments lead to capital losses. Moreover, in trade selection, GPs allow for the forecasting of multiple Sharpe ratios adjusted for transaction costs, aiding in decision-making. The functional data representation utilized in this study enables longer-term predictions by leveraging information from previous years, even as the forecast moves away from the current year's training data. Additionally, the augmented representation enriches the training set by incorporating multiple targets for future points in time, facilitating long-term predictions. Our implementation closely aligns with the methodology outlined in, which assessed effectiveness on commodity futures. However, our testing methodology differs. Instead of real data, we employ simulated data with similar characteristics. We construct a testing environment to evaluate both data representations and models under conditions of increasing noise, fat tails, and inappropriate kernels-conditions commonly encountered in practice. By simulating data, we can compare our forecast distribution over time against a full simulation of the actual distribution of our test set, thereby reducing the inherent uncertainty in testing time series models on real data. We enable feature prediction through augmentation and employ sub-sampling to ensure the feasibility of GPs.
Distilling Privileged Multimodal Information for Expression Recognition using Optimal Transport
Jan 27, 2024Multimodal affect recognition models have reached remarkable performance in the lab environment due to their ability to model complementary and redundant semantic information. However, these models struggle in the wild, mainly because of the unavailability or quality of modalities used for training. In practice, only a subset of the training-time modalities may be available at test time. Learning with privileged information (PI) enables deep learning models (DL) to exploit data from additional modalities only available during training. State-of-the-art knowledge distillation (KD) methods have been proposed to distill multiple teacher models (each trained on a modality) to a common student model. These privileged KD methods typically utilize point-to-point matching and have no explicit mechanism to capture the structural information in the teacher representation space formed by introducing the privileged modality. We argue that encoding this same structure in the student space may lead to enhanced student performance. This paper introduces a new structural KD mechanism based on optimal transport (OT), where entropy-regularized OT distills the structural dark knowledge. Privileged KD with OT (PKDOT) method captures the local structures in the multimodal teacher representation by calculating a cosine similarity matrix and selects the top-k anchors to allow for sparse OT solutions, resulting in a more stable distillation process. Experiments were performed on two different problems: pain estimation on the Biovid dataset (ordinal classification) and arousal-valance prediction on the Affwild2 dataset (regression). Results show that the proposed method can outperform state-of-the-art privileged KD methods on these problems. The diversity of different modalities and fusion architectures indicates that the proposed PKDOT method is modality and model-agnostic.
CODIS: Benchmarking Context-Dependent Visual Comprehension for Multimodal Large Language Models
Feb 21, 2024Multimodal large language models (MLLMs) have demonstrated promising results in a variety of tasks that combine vision and language. As these models become more integral to research and applications, conducting comprehensive evaluations of their capabilities has grown increasingly important. However, most existing benchmarks fail to consider that, in certain situations, images need to be interpreted within a broader context. In this work, we introduce a new benchmark, named as CODIS, designed to assess the ability of models to use context provided in free-form text to enhance visual comprehension. Our findings indicate that MLLMs consistently fall short of human performance on this benchmark. Further analysis confirms that these models struggle to effectively extract and utilize contextual information to improve their understanding of images. This underscores the pressing need to enhance the ability of MLLMs to comprehend visuals in a context-dependent manner. View our project website at https://thunlp-mt.github.io/CODIS.
Bangla AI: A Framework for Machine Translation Utilizing Large Language Models for Ethnic Media
Feb 21, 2024Ethnic media, which caters to diaspora communities in host nations, serves as a vital platform for these communities to both produce content and access information. Rather than utilizing the language of the host nation, ethnic media delivers news in the language of the immigrant community. For instance, in the USA, Bangla ethnic media presents news in Bangla rather than English. This research delves into the prospective integration of large language models (LLM) and multi-lingual machine translations (MMT) within the ethnic media industry. It centers on the transformative potential of using LLM in MMT in various facets of news translation, searching, and categorization. The paper outlines a theoretical framework elucidating the integration of LLM and MMT into the news searching and translation processes for ethnic media. Additionally, it briefly addresses the potential ethical challenges associated with the incorporation of LLM and MMT in news translation procedures.
2D Matryoshka Sentence Embeddings
Feb 22, 2024Common approaches rely on fixed-length embedding vectors from language models as sentence embeddings for downstream tasks such as semantic textual similarity (STS). Such methods are limited in their flexibility due to unknown computational constraints and budgets across various applications. Matryoshka Representation Learning (MRL) (Kusupati et al., 2022) encodes information at finer granularities, i.e., with lower embedding dimensions, to adaptively accommodate ad hoc tasks. Similar accuracy can be achieved with a smaller embedding size, leading to speedups in downstream tasks. Despite its improved efficiency, MRL still requires traversing all Transformer layers before obtaining the embedding, which remains the dominant factor in time and memory consumption. This prompts consideration of whether the fixed number of Transformer layers affects representation quality and whether using intermediate layers for sentence representation is feasible. In this paper, we introduce a novel sentence embedding model called Two-dimensional Matryoshka Sentence Embedding (2DMSE). It supports elastic settings for both embedding sizes and Transformer layers, offering greater flexibility and efficiency than MRL. We conduct extensive experiments on STS tasks and downstream applications. The experimental results demonstrate the effectiveness of our proposed model in dynamically supporting different embedding sizes and Transformer layers, allowing it to be highly adaptable to various scenarios.
ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs
Feb 22, 2024Safety is critical to the usage of large language models (LLMs). Multiple techniques such as data filtering and supervised fine-tuning have been developed to strengthen LLM safety. However, currently known techniques presume that corpora used for safety alignment of LLMs are solely interpreted by semantics. This assumption, however, does not hold in real-world applications, which leads to severe vulnerabilities in LLMs. For example, users of forums often use ASCII art, a form of text-based art, to convey image information. In this paper, we propose a novel ASCII art-based jailbreak attack and introduce a comprehensive benchmark Vision-in-Text Challenge (ViTC) to evaluate the capabilities of LLMs in recognizing prompts that cannot be solely interpreted by semantics. We show that five SOTA LLMs (GPT-3.5, GPT-4, Gemini, Claude, and Llama2) struggle to recognize prompts provided in the form of ASCII art. Based on this observation, we develop the jailbreak attack ArtPrompt, which leverages the poor performance of LLMs in recognizing ASCII art to bypass safety measures and elicit undesired behaviors from LLMs. ArtPrompt only requires black-box access to the victim LLMs, making it a practical attack. We evaluate ArtPrompt on five SOTA LLMs, and show that ArtPrompt can effectively and efficiently induce undesired behaviors from all five LLMs.
Closed-Form Bounds for DP-SGD against Record-level Inference
Feb 22, 2024Machine learning models trained with differentially-private (DP) algorithms such as DP-SGD enjoy resilience against a wide range of privacy attacks. Although it is possible to derive bounds for some attacks based solely on an $(\varepsilon,\delta)$-DP guarantee, meaningful bounds require a small enough privacy budget (i.e., injecting a large amount of noise), which results in a large loss in utility. This paper presents a new approach to evaluate the privacy of machine learning models against specific record-level threats, such as membership and attribute inference, without the indirection through DP. We focus on the popular DP-SGD algorithm, and derive simple closed-form bounds. Our proofs model DP-SGD as an information theoretic channel whose inputs are the secrets that an attacker wants to infer (e.g., membership of a data record) and whose outputs are the intermediate model parameters produced by iterative optimization. We obtain bounds for membership inference that match state-of-the-art techniques, whilst being orders of magnitude faster to compute. Additionally, we present a novel data-dependent bound against attribute inference. Our results provide a direct, interpretable, and practical way to evaluate the privacy of trained models against specific inference threats without sacrificing utility.
Contrastive Learning of Shared Spatiotemporal EEG Representations Across Individuals for Naturalistic Neuroscience
Feb 22, 2024Neural representations induced by naturalistic stimuli offer insights into how humans respond to peripheral stimuli in daily life. The key to understanding the general neural mechanisms underlying naturalistic stimuli processing involves aligning neural activities across individuals and extracting inter-subject shared neural representations. Targeting the Electroencephalogram (EEG) technique, known for its rich spatial and temporal information, this study presents a general framework for Contrastive Learning of Shared SpatioTemporal EEG Representations across individuals (CL-SSTER). Harnessing the representational capabilities of contrastive learning, CL-SSTER utilizes a neural network to maximize the similarity of EEG representations across individuals for identical stimuli, contrasting with those for varied stimuli. The network employed spatial and temporal convolutions to simultaneously learn the spatial and temporal patterns inherent in EEG. The versatility of CL-SSTER was demonstrated on three EEG datasets, including a synthetic dataset, a speech audio EEG dataset, and an emotional video EEG dataset. CL-SSTER attained the highest inter-subject correlation (ISC) values compared to the state-of-the-art ISC methods. The latent representations generated by CL-SSTER exhibited reliable spatiotemporal EEG patterns, which can be explained by specific aspects of the stimuli. CL-SSTER serves as an interpretable and scalable foundational framework for the identification of inter-subject shared neural representations in the realm of naturalistic neuroscience.
Quantum $X$-Secure $B$-Byzantine $T$-Colluding Private Information Retrieval
Jan 30, 2024We consider the problems arising from the presence of Byzantine servers in a quantum private information retrieval (QPIR) setting. This is the first work to precisely define what the capabilities of Byzantine servers could be in a QPIR context. We show that quantum Byzantine servers have more capabilities than their classical counterparts due to the possibilities created by the quantum encoding procedure. We focus on quantum Byzantine servers that can apply any reversible operations on their individual qudits. In this case, the Byzantine servers can generate any error, i.e., this covers \emph{all} possible single qudit operations that can be done by the Byzantine servers on their qudits. We design a scheme that is resilient to these kinds of manipulations. We show that the scheme designed achieves superdense coding gain in all cases, i.e., $R_Q= \max \left\{0,\min\left\{1,2\left(1-\frac{X+T+2B}{N}\right)\right\}\right\}$.
A Condensed Transition Graph Framework for Zero-shot Link Prediction with Large Language Models
Feb 16, 2024Zero-shot link prediction (ZSLP) on knowledge graphs aims at automatically identifying relations between given entities. Existing methods primarily employ auxiliary information to predict tail entity given head entity and its relation, yet face challenges due to the occasional unavailability of such detailed information and the inherent simplicity of predicting tail entities based on semantic similarities. Even though Large Language Models (LLMs) offer a promising solution to predict unobserved relations between the head and tail entity in a zero-shot manner, their performance is still restricted due to the inability to leverage all the (exponentially many) paths' information between two entities, which are critical in collectively indicating their relation types. To address this, in this work, we introduce a Condensed Transition Graph Framework for Zero-Shot Link Prediction (CTLP), which encodes all the paths' information in linear time complexity to predict unseen relations between entities, attaining both efficiency and information preservation. Specifically, we design a condensed transition graph encoder with theoretical guarantees on its coverage, expressiveness, and efficiency. It is learned by a transition graph contrastive learning strategy. Subsequently, we design a soft instruction tuning to learn and map the all-path embedding to the input of LLMs. Experimental results show that our proposed CTLP method achieves state-of-the-art performance on three standard ZSLP datasets