 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
Mar 30, 2022


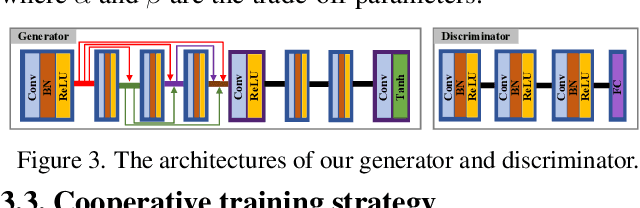

This study addresses the issue of fusing infrared and visible images that appear differently for object detection. Aiming at generating an image of high visual quality, previous approaches discover commons underlying the two modalities and fuse upon the common space either by iterative optimization or deep networks. These approaches neglect that modality differences implying the complementary information are extremely important for both fusion and subsequent detection task. This paper proposes a bilevel optimization formulation for the joint problem of fusion and detection, and then unrolls to a target-aware Dual Adversarial Learning (TarDAL) network for fusion and a commonly used detection network. The fusion network with one generator and dual discriminators seeks commons while learning from differences, which preserves structural information of targets from the infrared and textural details from the visible. Furthermore, we build a synchronized imaging system with calibrated infrared and optical sensors, and collect currently the most comprehensive benchmark covering a wide range of scenarios. Extensive experiments on several public datasets and our benchmark demonstrate that our method outputs not only visually appealing fusion but also higher detection mAP than the state-of-the-art approaches.
Medicinal Boxes Recognition on a Deep Transfer Learning Augmented Reality Mobile Application
Mar 26, 2022



Taking medicines is a fundamental aspect to cure illnesses. However, studies have shown that it can be hard for patients to remember the correct posology. More aggravating, a wrong dosage generally causes the disease to worsen. Although, all relevant instructions for a medicine are summarized in the corresponding patient information leaflet, the latter is generally difficult to navigate and understand. To address this problem and help patients with their medication, in this paper we introduce an augmented reality mobile application that can present to the user important details on the framed medicine. In particular, the app implements an inference engine based on a deep neural network, i.e., a densenet, fine-tuned to recognize a medicinal from its package. Subsequently, relevant information, such as posology or a simplified leaflet, is overlaid on the camera feed to help a patient when taking a medicine. Extensive experiments to select the best hyperparameters were performed on a dataset specifically collected to address this task; ultimately obtaining up to 91.30\% accuracy as well as real-time capabilities.
Submodular Combinatorial Information Measures with Applications in Machine Learning
Jun 27, 2020



Information-theoretic quantities like entropy and mutual information have found numerous uses in machine learning. It is well known that there is a strong connection between these entropic quantities and submodularity since entropy over a set of random variables is submodular. In this paper, we study combinatorial information measures that generalize independence, (conditional) entropy, (conditional) mutual information, and total correlation defined over sets of (not necessarily random) variables. These measures strictly generalize the corresponding entropic measures since they are all parameterized via submodular functions that themselves strictly generalize entropy. Critically, we show that, unlike entropic mutual information in general, the submodular mutual information is actually submodular in one argument, holding the other fixed, for a large class of submodular functions whose third-order partial derivatives satisfy a non-negativity property. This turns out to include a number of practically useful cases such as the facility location and set-cover functions. We study specific instantiations of the submodular information measures on these, as well as the probabilistic coverage, graph-cut, and saturated coverage functions, and see that they all have mathematically intuitive and practically useful expressions. Regarding applications, we connect the maximization of submodular (conditional) mutual information to problems such as mutual-information-based, query-based, and privacy-preserving summarization -- and we connect optimizing the multi-set submodular mutual information to clustering and robust partitioning.
Exploiting Contextual Information with Deep Neural Networks
Jun 21, 2020
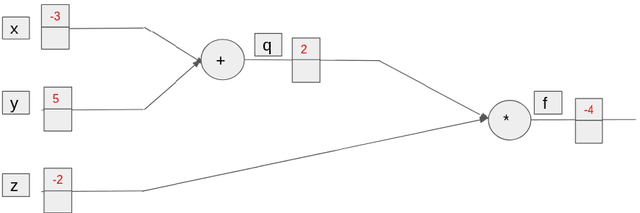
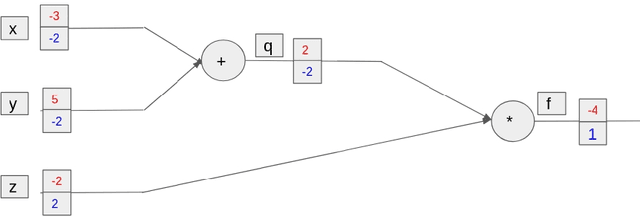
Context matters! Nevertheless, there has not been much research in exploiting contextual information in deep neural networks. For most part, the entire usage of contextual information has been limited to recurrent neural networks. Attention models and capsule networks are two recent ways of introducing contextual information in non-recurrent models, however both of these algorithms have been developed after this work has started. In this thesis, we show that contextual information can be exploited in 2 fundamentally different ways: implicitly and explicitly. In the DeepScore project, where the usage of context is very important for the recognition of many tiny objects, we show that by carefully crafting convolutional architectures, we can achieve state-of-the-art results, while also being able to implicitly correctly distinguish between objects which are virtually identical, but have different meanings based on their surrounding. In parallel, we show that by explicitly designing algorithms (motivated from graph theory and game theory) that take into considerations the entire structure of the dataset, we can achieve state-of-the-art results in different topics like semi-supervised learning and similarity learning. To the best of our knowledge, we are the first to integrate graph-theoretical modules, carefully crafted for the problem of similarity learning and that are designed to consider contextual information, not only outperforming the other models, but also gaining a speed improvement while using a smaller number of parameters.
Fundamental limitations on optimization in variational quantum algorithms
May 10, 2022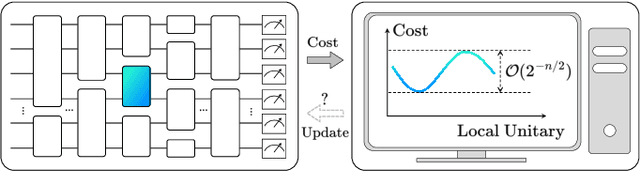
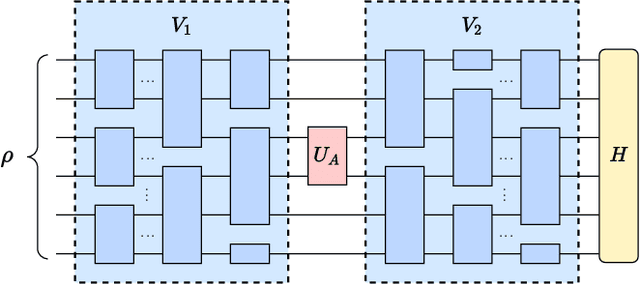
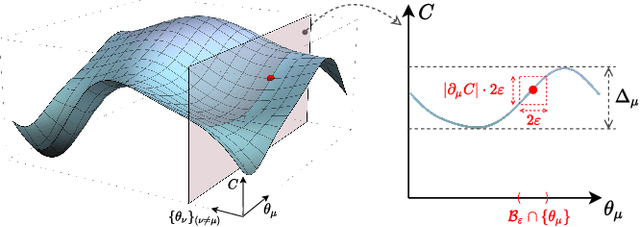

Exploring quantum applications of near-term quantum devices is a rapidly growing field of quantum information science with both theoretical and practical interests. A leading paradigm to establish such near-term quantum applications is variational quantum algorithms (VQAs). These algorithms use a classical optimizer to train a parameterized quantum circuit to accomplish certain tasks, where the circuits are usually randomly initialized. In this work, we prove that for a broad class of such random circuits, the variation range of the cost function via adjusting any local quantum gate within the circuit vanishes exponentially in the number of qubits with a high probability. This result can unify the restrictions on gradient-based and gradient-free optimizations in a natural manner and reveal extra harsh constraints on the training landscapes of VQAs. Hence a fundamental limitation on the trainability of VQAs is unraveled, indicating the essence of the optimization hardness in the Hilbert space with exponential dimension. We further showcase the validity of our results with numerical simulations of representative VQAs. We believe that these results would deepen our understanding of the scalability of VQAs and shed light on the search for near-term quantum applications with advantages.
Decoupled Pyramid Correlation Network for Liver Tumor Segmentation from CT images
May 26, 2022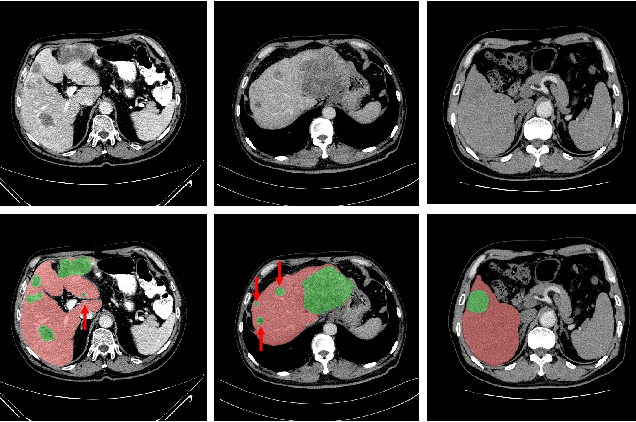
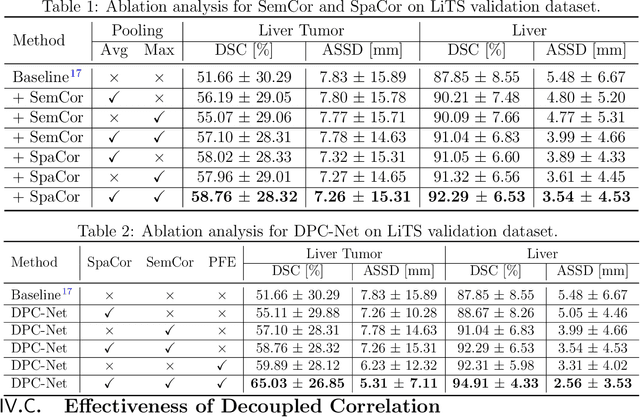
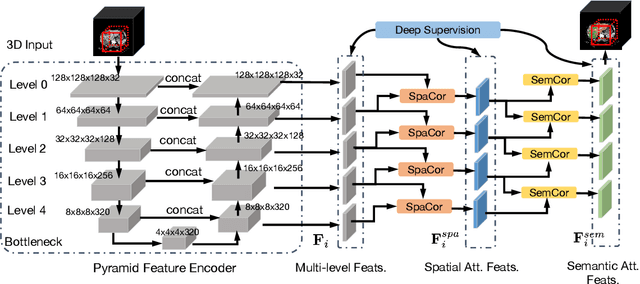
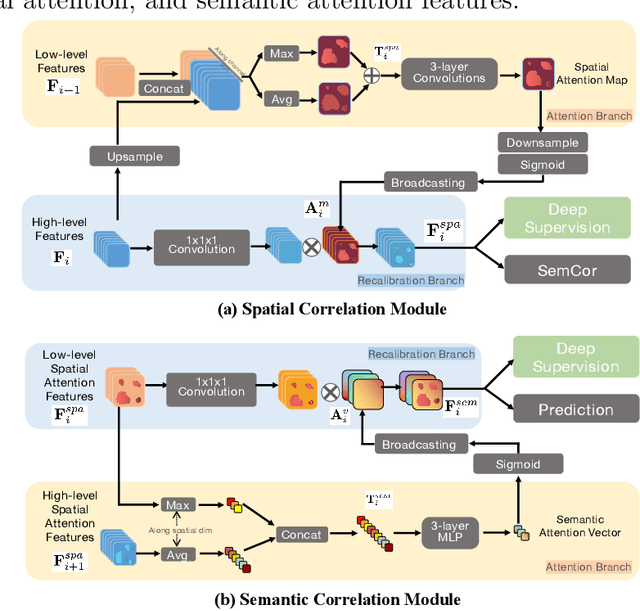
Purpose: Automated liver tumor segmentation from Computed Tomography (CT) images is a necessary prerequisite in the interventions of hepatic abnormalities and surgery planning. However, accurate liver tumor segmentation remains challenging due to the large variability of tumor sizes and inhomogeneous texture. Recent advances based on Fully Convolutional Network (FCN) for medical image segmentation drew on the success of learning discriminative pyramid features. In this paper, we propose a Decoupled Pyramid Correlation Network (DPC-Net) that exploits attention mechanisms to fully leverage both low- and high-level features embedded in FCN to segment liver tumor. Methods: We first design a powerful Pyramid Feature Encoder (PFE) to extract multi-level features from input images. Then we decouple the characteristics of features concerning spatial dimension (i.e., height, width, depth) and semantic dimension (i.e., channel). On top of that, we present two types of attention modules, Spatial Correlation (SpaCor) and Semantic Correlation (SemCor) modules, to recursively measure the correlation of multi-level features. The former selectively emphasizes global semantic information in low-level features with the guidance of high-level ones. The latter adaptively enhance spatial details in high-level features with the guidance of low-level ones. Results: We evaluate the DPC-Net on MICCAI 2017 LiTS Liver Tumor Segmentation (LiTS) challenge dataset. Dice Similarity Coefficient (DSC) and Average Symmetric Surface Distance (ASSD) are employed for evaluation. The proposed method obtains a DSC of 76.4% and an ASSD of 0.838 mm for liver tumor segmentation, outperforming the state-of-the-art methods. It also achieves a competitive results with a DSC of 96.0% and an ASSD of 1.636 mm for liver segmentation.
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints
May 10, 2022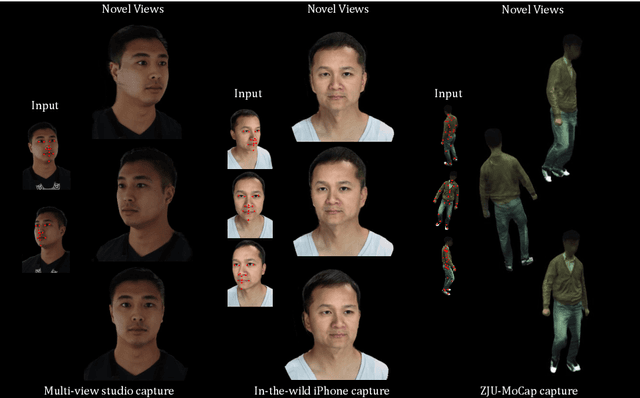

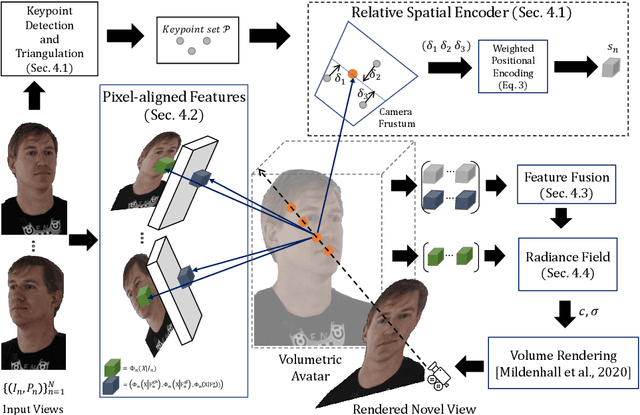
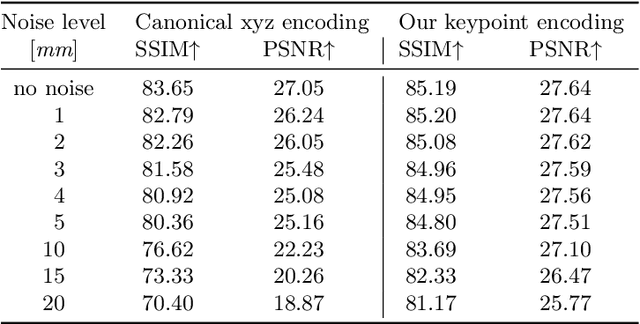
Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior work that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling. https://markomih.github.io/KeypointNeRF
BinsFormer: Revisiting Adaptive Bins for Monocular Depth Estimation
Apr 03, 2022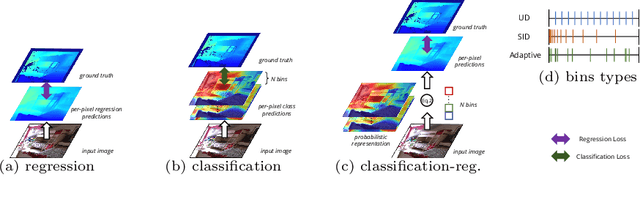
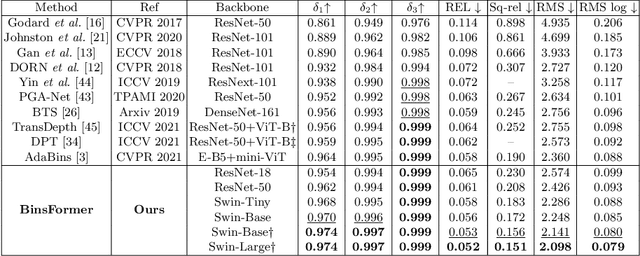
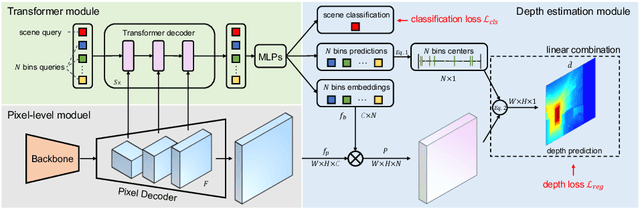
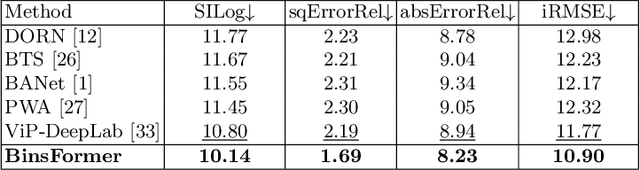
Monocular depth estimation is a fundamental task in computer vision and has drawn increasing attention. Recently, some methods reformulate it as a classification-regression task to boost the model performance, where continuous depth is estimated via a linear combination of predicted probability distributions and discrete bins. In this paper, we present a novel framework called BinsFormer, tailored for the classification-regression-based depth estimation. It mainly focuses on two crucial components in the specific task: 1) proper generation of adaptive bins and 2) sufficient interaction between probability distribution and bins predictions. To specify, we employ the Transformer decoder to generate bins, novelly viewing it as a direct set-to-set prediction problem. We further integrate a multi-scale decoder structure to achieve a comprehensive understanding of spatial geometry information and estimate depth maps in a coarse-to-fine manner. Moreover, an extra scene understanding query is proposed to improve the estimation accuracy, which turns out that models can implicitly learn useful information from an auxiliary environment classification task. Extensive experiments on the KITTI, NYU, and SUN RGB-D datasets demonstrate that BinsFormer surpasses state-of-the-art monocular depth estimation methods with prominent margins. Code and pretrained models will be made publicly available at \url{https://github.com/zhyever/Monocular-Depth-Estimation-Toolbox}.
Sparse Compressed Spiking Neural Network Accelerator for Object Detection
May 02, 2022
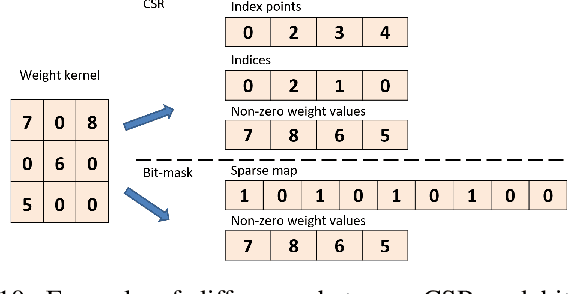
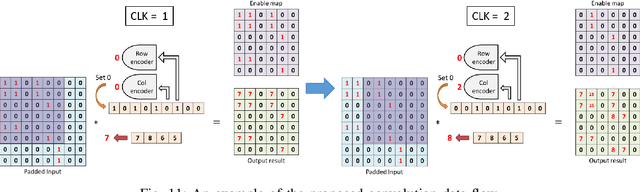
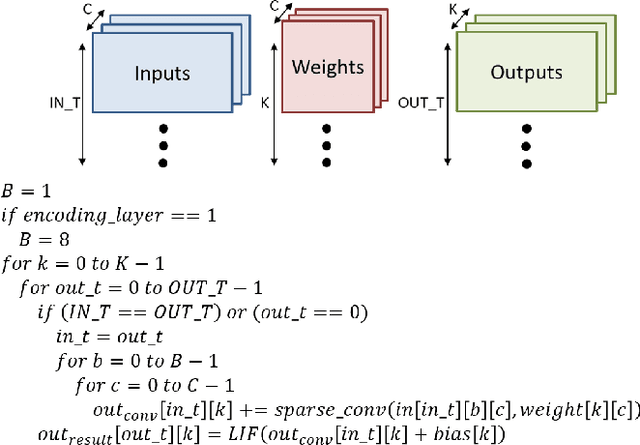
Spiking neural networks (SNNs), which are inspired by the human brain, have recently gained popularity due to their relatively simple and low-power hardware for transmitting binary spikes and highly sparse activation maps. However, because SNNs contain extra time dimension information, the SNN accelerator will require more buffers and take longer to infer, especially for the more difficult high-resolution object detection task. As a result, this paper proposes a sparse compressed spiking neural network accelerator that takes advantage of the high sparsity of activation maps and weights by utilizing the proposed gated one-to-all product for low power and highly parallel model execution. The experimental result of the neural network shows 71.5$\%$ mAP with mixed (1,3) time steps on the IVS 3cls dataset. The accelerator with the TSMC 28nm CMOS process can achieve 1024$\times$576@29 frames per second processing when running at 500MHz with 35.88TOPS/W energy efficiency and 1.05mJ energy consumption per frame.
Far from Asymptopia
May 06, 2022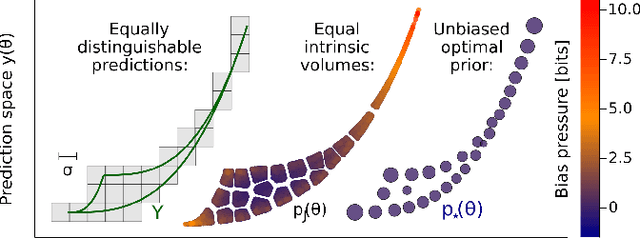
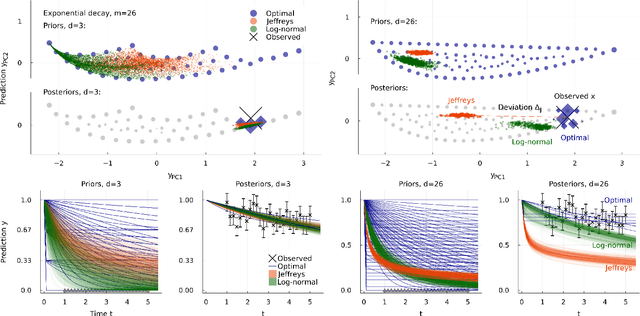
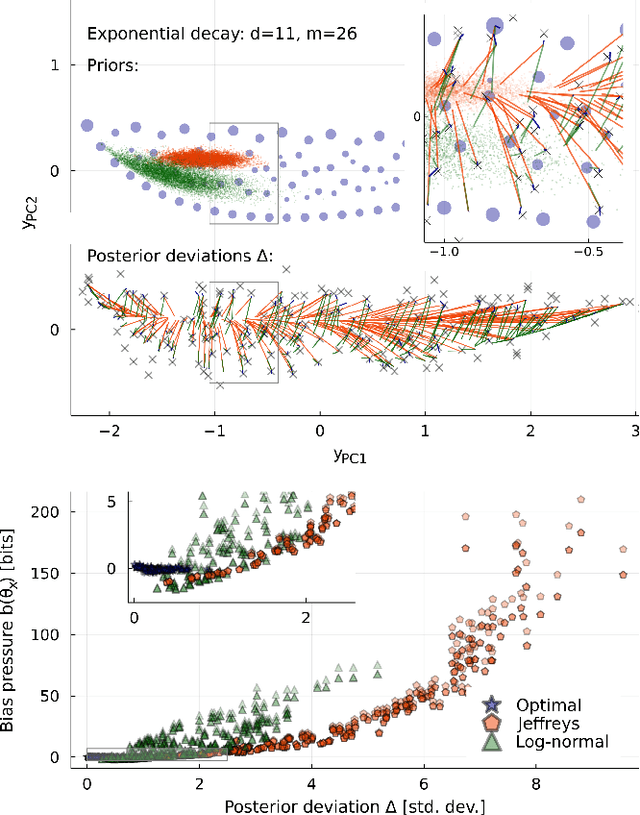
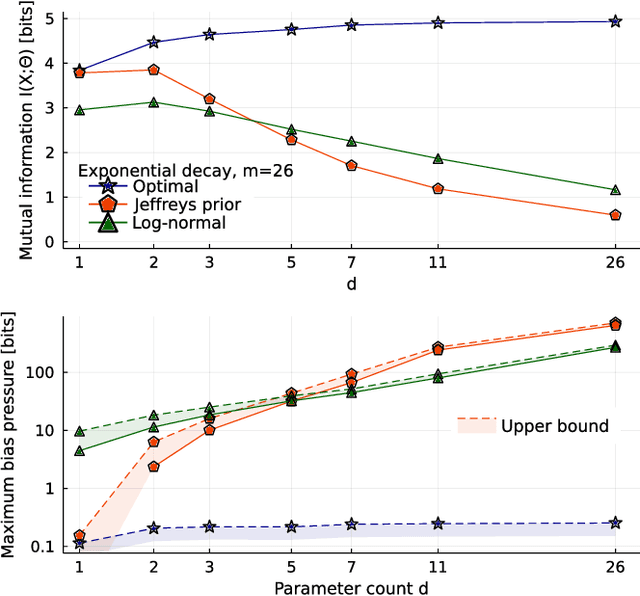
Inference from limited data requires a notion of measure on parameter space, which is most explicit in the Bayesian framework as a prior distribution. Jeffreys prior is the best-known uninformative choice, the invariant volume element from information geometry, but we demonstrate here that this leads to enormous bias in typical high-dimensional models. This is because models found in science typically have an effective dimensionality of accessible behaviours much smaller than the number of microscopic parameters. Any measure which treats all of these parameters equally is far from uniform when projected onto the sub-space of relevant parameters, due to variations in the local co-volume of irrelevant directions. We present results on a principled choice of measure which avoids this issue, and leads to unbiased posteriors, by focusing on relevant parameters. This optimal prior depends on the quantity of data to be gathered, and approaches Jeffreys prior in the asymptotic limit. But for typical models this limit cannot be justified without an impossibly large increase in the quantity of data, exponential in the number of microscopic parameters.