 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Statistical-Computational Trade-offs in Tensor PCA and Related Problems via Communication Complexity
Apr 15, 2022

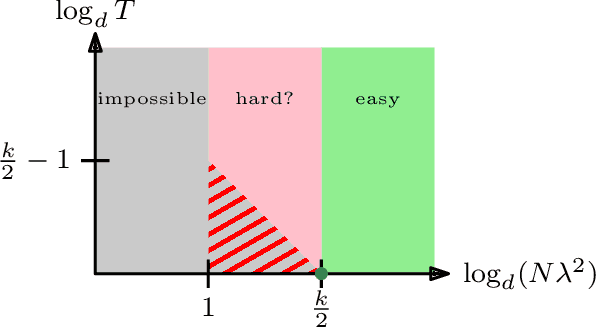
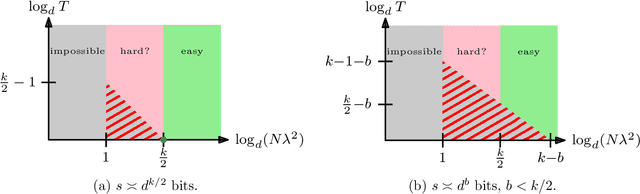

Tensor PCA is a stylized statistical inference problem introduced by Montanari and Richard to study the computational difficulty of estimating an unknown parameter from higher-order moment tensors. Unlike its matrix counterpart, Tensor PCA exhibits a statistical-computational gap, i.e., a sample size regime where the problem is information-theoretically solvable but conjectured to be computationally hard. This paper derives computational lower bounds on the run-time of memory bounded algorithms for Tensor PCA using communication complexity. These lower bounds specify a trade-off among the number of passes through the data sample, the sample size, and the memory required by any algorithm that successfully solves Tensor PCA. While the lower bounds do not rule out polynomial-time algorithms, they do imply that many commonly-used algorithms, such as gradient descent and power method, must have a higher iteration count when the sample size is not large enough. Similar lower bounds are obtained for Non-Gaussian Component Analysis, a family of statistical estimation problems in which low-order moment tensors carry no information about the unknown parameter. Finally, stronger lower bounds are obtained for an asymmetric variant of Tensor PCA and related statistical estimation problems. These results explain why many estimators for these problems use a memory state that is significantly larger than the effective dimensionality of the parameter of interest.
PromptDA: Label-guided Data Augmentation for Prompt-based Few Shot Learners
May 18, 2022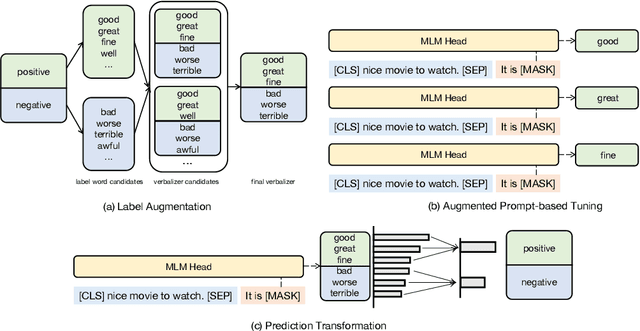
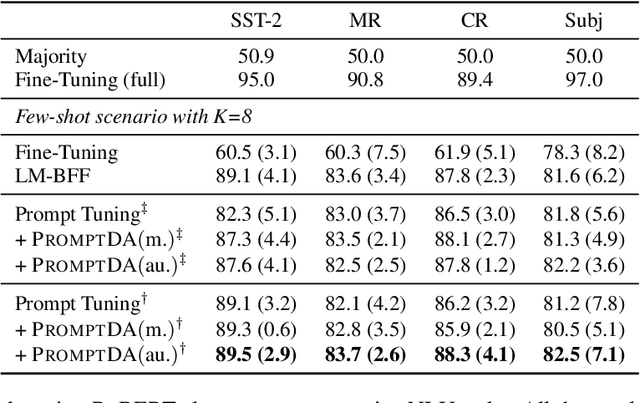

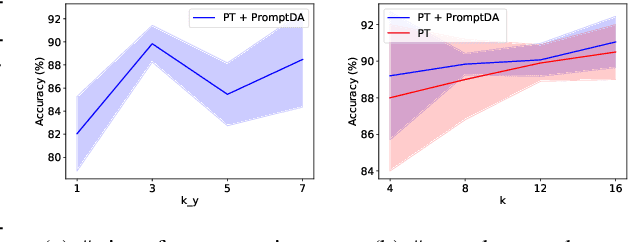
Recent advances on large pre-trained language models (PLMs) lead impressive gains on natural language understanding (NLU) tasks with task-specific fine-tuning. However, direct fine-tuning PLMs heavily relies on large amount of labeled instances, which are expensive and time-consuming to obtain. Prompt-based tuning on PLMs has proven valuable for few shot tasks. Existing works studying prompt-based tuning for few-shot NLU mainly focus on deriving proper label words with a verbalizer or generating prompt templates for eliciting semantics from PLMs. In addition, conventional data augmentation methods have also been verified useful for few-shot tasks. However, there currently are few data augmentation methods designed for the prompt-based tuning paradigm. Therefore, we study a new problem of data augmentation for prompt-based few shot learners. Since label semantics are helpful in prompt-based tuning, we propose a novel label-guided data augmentation method PromptDA which exploits the enriched label semantic information for data augmentation. Experimental results on several few shot text classification tasks show that our proposed framework achieves superior performance by effectively leveraging label semantics and data augmentation in language understanding.
Sensing Time Effectiveness for Fitness to Drive Evaluation in Neurological Patients
May 31, 2022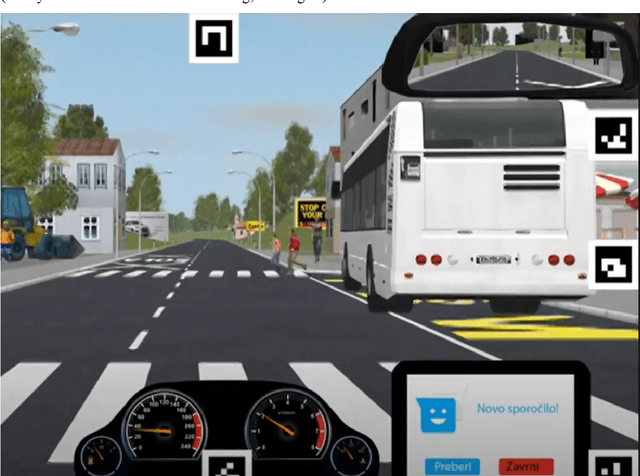
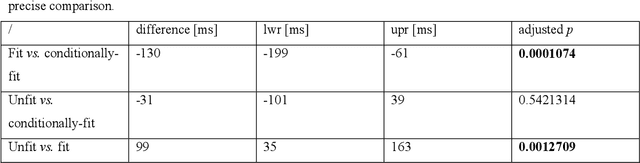
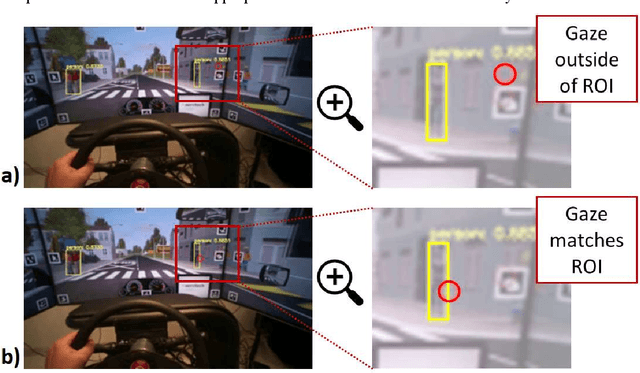
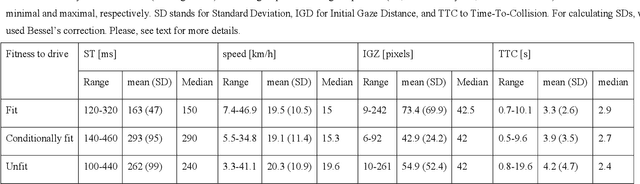
We present a method to automatically calculate sensing time (ST) from the eye tracker data in subjects with neurological impairment using a driving simulator. ST presents the time interval for a person to notice the stimulus from its first occurrence. Precisely, we measured the time since the children started to cross the street until the drivers directed their look to the children. In comparison to the commonly used reaction time, ST does not require additional neuro-muscular responses such as braking and presents unique information on the sensory function. From 108 neurological patients recruited for the study, the analysis of ST was performed in overall 56 patients to assess fit-, unfit-, and conditionally-fit-to-drive patients. The results showed that the proposed method based on the YOLO (You Only Look Once) object detector is efficient for computing STs from the eye tracker data in neurological patients. We obtained discriminative results for fit-to-drive patients by application of Tukey's Honest Significant Difference post hoc test (p < 0.01), while no difference was observed between conditionally-fit and unfit-to-drive groups (p = 0.542). Moreover, we show that time-to-collision (TTC), initial gaze distance (IGD) from pedestrians, and speed at the hazard onset did not influence the result, while the only significant interaction is among fitness, IGD, and TTC on ST. Although the proposed method can be applied to assess fitness to drive, we provide directions for future driving simulation-based evaluation and propose processing workflow to secure reliable ST calculation in other domains such as psychology, neuroscience, marketing, etc.
Multi-modality Associative Bridging through Memory: Speech Sound Recollected from Face Video
Apr 04, 2022
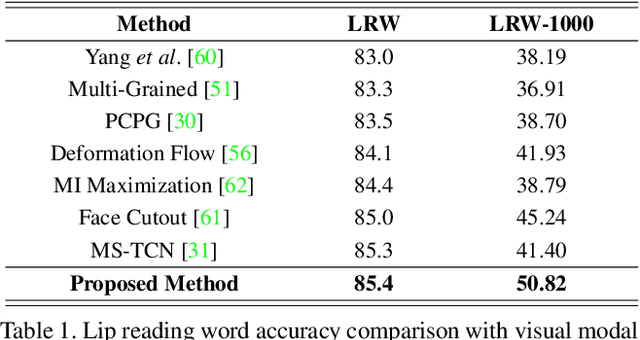
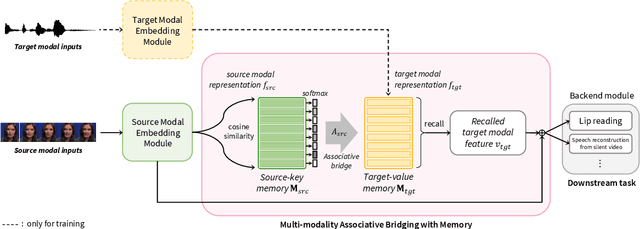
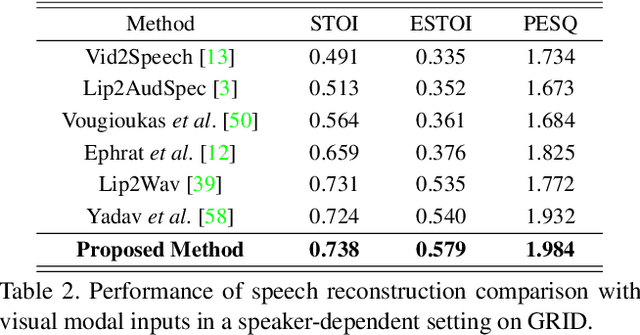
In this paper, we introduce a novel audio-visual multi-modal bridging framework that can utilize both audio and visual information, even with uni-modal inputs. We exploit a memory network that stores source (i.e., visual) and target (i.e., audio) modal representations, where source modal representation is what we are given, and target modal representations are what we want to obtain from the memory network. We then construct an associative bridge between source and target memories that considers the interrelationship between the two memories. By learning the interrelationship through the associative bridge, the proposed bridging framework is able to obtain the target modal representations inside the memory network, even with the source modal input only, and it provides rich information for its downstream tasks. We apply the proposed framework to two tasks: lip reading and speech reconstruction from silent video. Through the proposed associative bridge and modality-specific memories, each task knowledge is enriched with the recalled audio context, achieving state-of-the-art performance. We also verify that the associative bridge properly relates the source and target memories.
Inductive Mutual Information Estimation: A Convex Maximum-Entropy Copula Approach
Feb 25, 2021
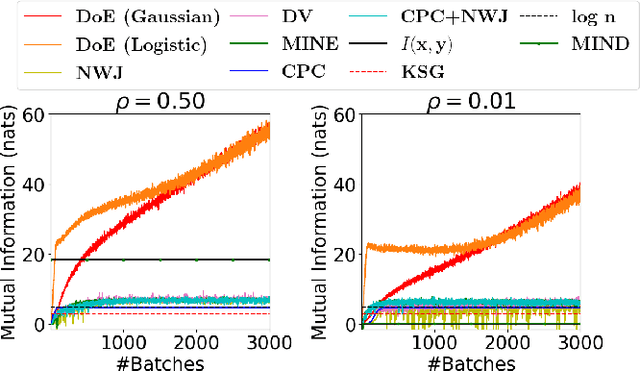

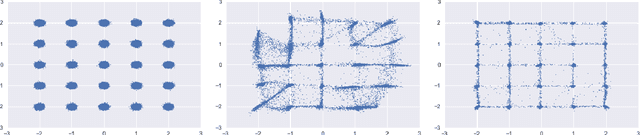
We propose a novel estimator of the mutual information between two ordinal vectors $x$ and $y$. Our approach is inductive (as opposed to deductive) in that it depends on the data generating distribution solely through some nonparametric properties revealing associations in the data, and does not require having enough data to fully characterize the true joint distributions $P_{x, y}$. Specifically, our approach consists of (i) noting that $I\left(y; x\right) = I\left(u_y; u_x\right)$ where $u_y$ and $u_x$ are the \emph{copula-uniform dual representations} of $y$ and $x$ (i.e. their images under the probability integral transform), and (ii) estimating the copula entropies $h\left(u_y\right)$, $h\left(u_x\right)$ and $h\left(u_y, u_x\right)$ by solving a maximum-entropy problem over the space of copula densities under a constraint of the type $\alpha_m = E\left[\phi_m(u_y, u_x)\right]$. We prove that, so long as the constraint is feasible, this problem admits a unique solution, it is in the exponential family, and it can be learned by solving a convex optimization problem. The resulting estimator, which we denote MIND, is marginal-invariant, always non-negative, unbounded for any sample size $n$, consistent, has MSE rate $O(1/n)$, and is more data-efficient than competing approaches. Beyond mutual information estimation, we illustrate that our approach may be used to mitigate mode collapse in GANs by maximizing the entropy of the copula of fake samples, a model we refer to as Copula Entropy Regularized GAN (CER-GAN).
A Dirichlet Process Mixture of Robust Task Models for Scalable Lifelong Reinforcement Learning
May 22, 2022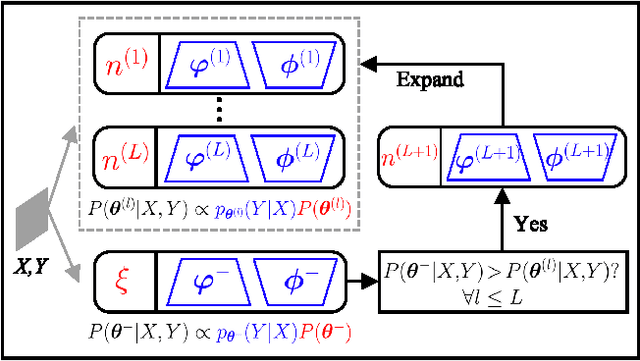
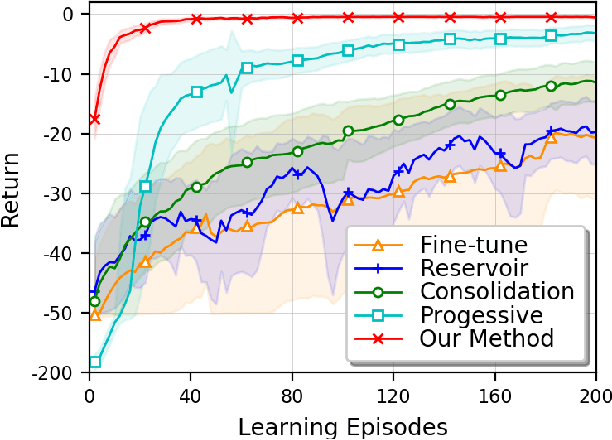
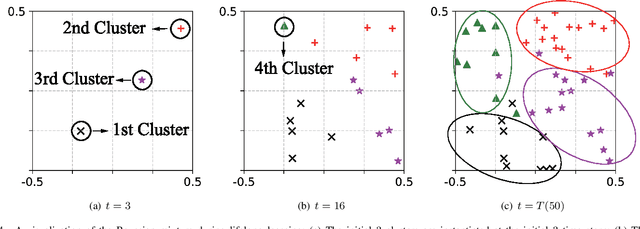
While reinforcement learning (RL) algorithms are achieving state-of-the-art performance in various challenging tasks, they can easily encounter catastrophic forgetting or interference when faced with lifelong streaming information. In the paper, we propose a scalable lifelong RL method that dynamically expands the network capacity to accommodate new knowledge while preventing past memories from being perturbed. We use a Dirichlet process mixture to model the non-stationary task distribution, which captures task relatedness by estimating the likelihood of task-to-cluster assignments and clusters the task models in a latent space. We formulate the prior distribution of the mixture as a Chinese restaurant process (CRP) that instantiates new mixture components as needed. The update and expansion of the mixture are governed by the Bayesian non-parametric framework with an expectation maximization (EM) procedure, which dynamically adapts the model complexity without explicit task boundaries or heuristics. Moreover, we use the domain randomization technique to train robust prior parameters for the initialization of each task model in the mixture, thus the resulting model can better generalize and adapt to unseen tasks. With extensive experiments conducted on robot navigation and locomotion domains, we show that our method successfully facilitates scalable lifelong RL and outperforms relevant existing methods.
Mutual Information in Community Detection with Covariate Information and Correlated Networks
Dec 11, 2019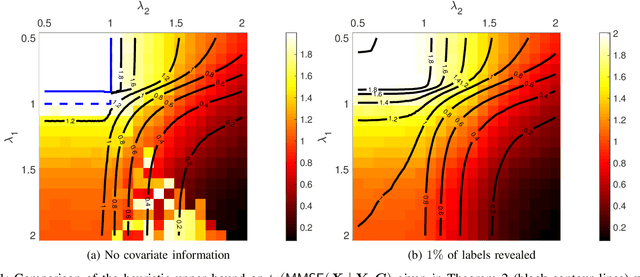
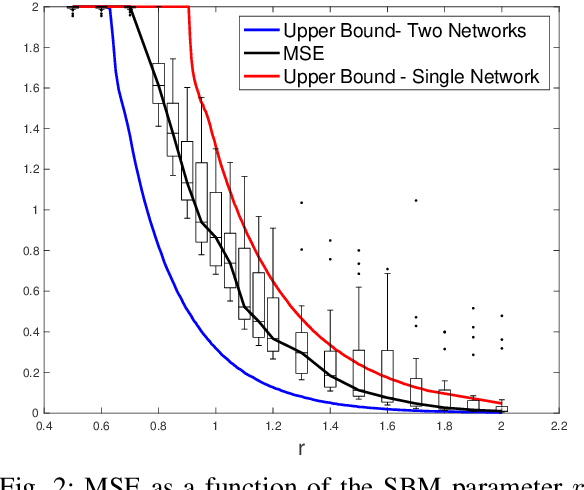
We study the problem of community detection when there is covariate information about the node labels and one observes multiple correlated networks. We provide an asymptotic upper bound on the per-node mutual information as well as a heuristic analysis of a multivariate performance measure called the MMSE matrix. These results show that the combined effects of seemingly very different types of information can be characterized explicitly in terms of formulas involving low-dimensional estimation problems in additive Gaussian noise. Our analysis is supported by numerical simulations.
DDXPlus: A new Dataset for Medical Automatic Diagnosis
May 18, 2022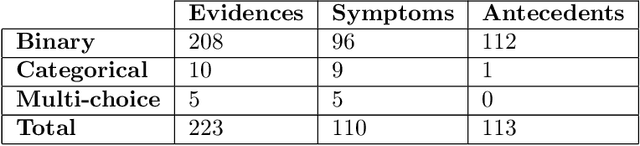
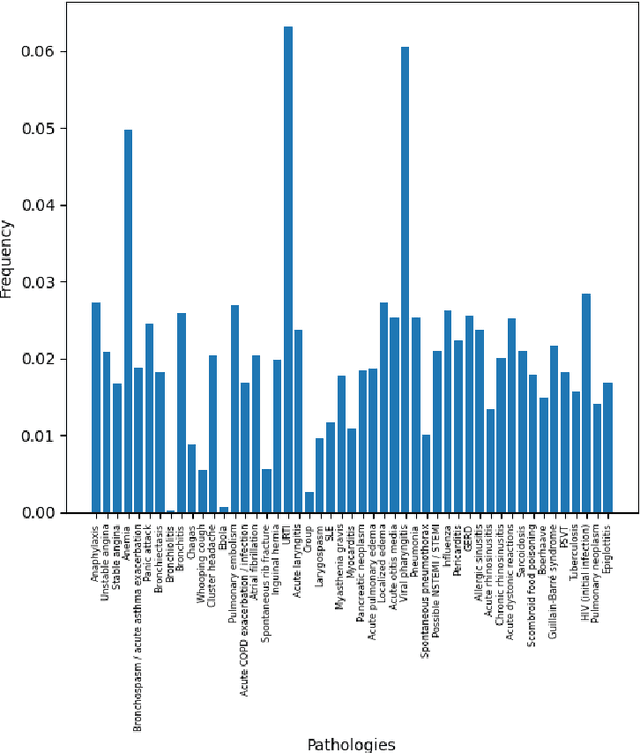
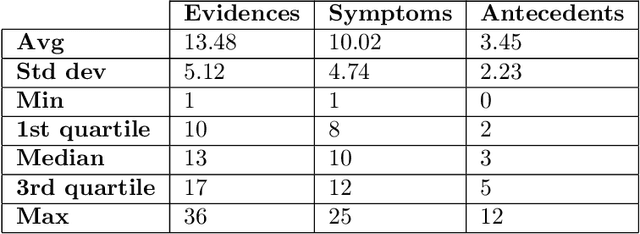
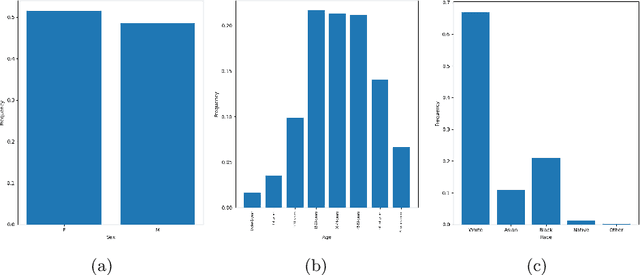
There has been rapidly growing interests in Automatic Diagnosis (AD) and Automatic Symptom Detection (ASD) systems in the machine learning research literature, aiming to assist doctors in telemedicine services. These systems are designed to interact with patients, collect evidence relevant to their concerns, and make predictions about the underlying diseases. Doctors would review the interaction, including the evidence and the predictions, before making their final decisions. Despite the recent progress, an important piece of doctors' interactions with patients is missing in the design of AD and ASD systems, namely the differential diagnosis. Its absence is largely due to the lack of datasets that include such information for models to train on. In this work, we present a large-scale synthetic dataset that includes a differential diagnosis, along with the ground truth pathology, for each patient. In addition, this dataset includes more pathologies, as well as types of symtoms and antecedents. As a proof-of-concept, we extend several existing AD and ASD systems to incorporate differential diagnosis, and provide empirical evidence that using differentials in training signals is essential for such systems to learn to predict differentials. Dataset available at https://github.com/bruzwen/ddxplus
BodyMap: Learning Full-Body Dense Correspondence Map
May 18, 2022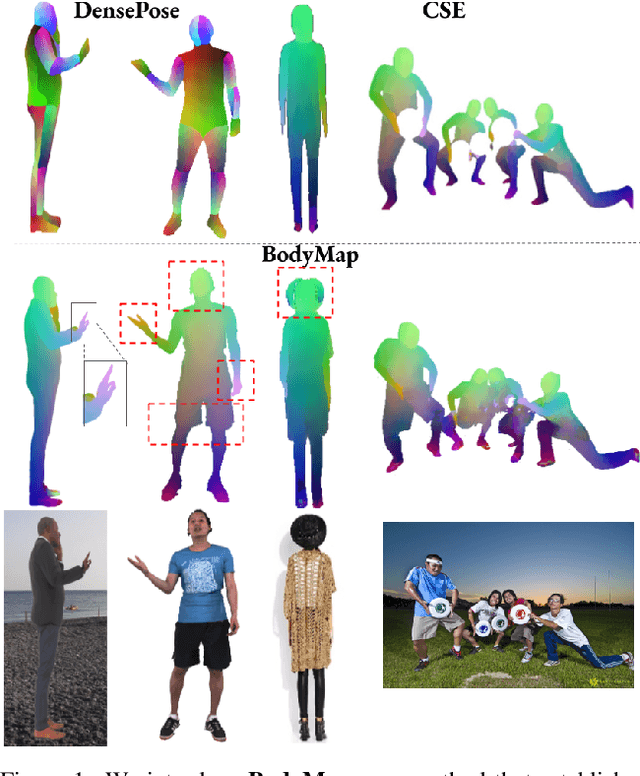
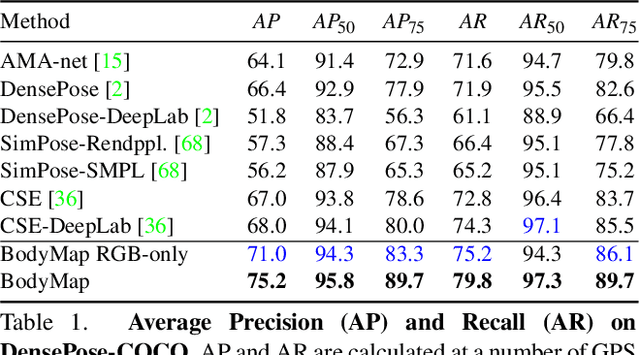
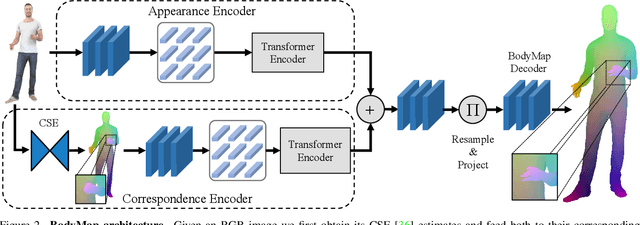
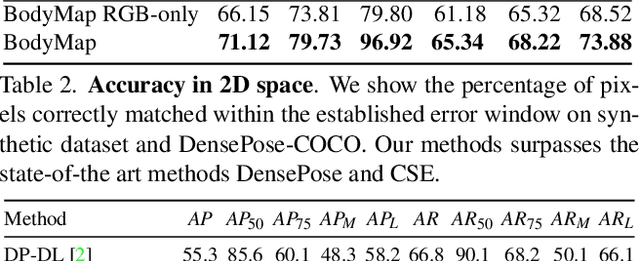
Dense correspondence between humans carries powerful semantic information that can be utilized to solve fundamental problems for full-body understanding such as in-the-wild surface matching, tracking and reconstruction. In this paper we present BodyMap, a new framework for obtaining high-definition full-body and continuous dense correspondence between in-the-wild images of clothed humans and the surface of a 3D template model. The correspondences cover fine details such as hands and hair, while capturing regions far from the body surface, such as loose clothing. Prior methods for estimating such dense surface correspondence i) cut a 3D body into parts which are unwrapped to a 2D UV space, producing discontinuities along part seams, or ii) use a single surface for representing the whole body, but none handled body details. Here, we introduce a novel network architecture with Vision Transformers that learn fine-level features on a continuous body surface. BodyMap outperforms prior work on various metrics and datasets, including DensePose-COCO by a large margin. Furthermore, we show various applications ranging from multi-layer dense cloth correspondence, neural rendering with novel-view synthesis and appearance swapping.
Collaborative likelihood-ratio estimation over graphs
May 28, 2022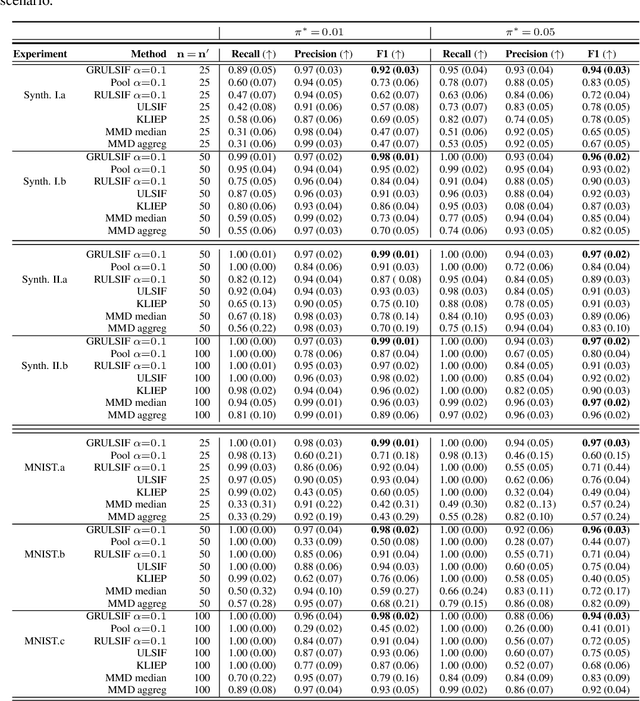
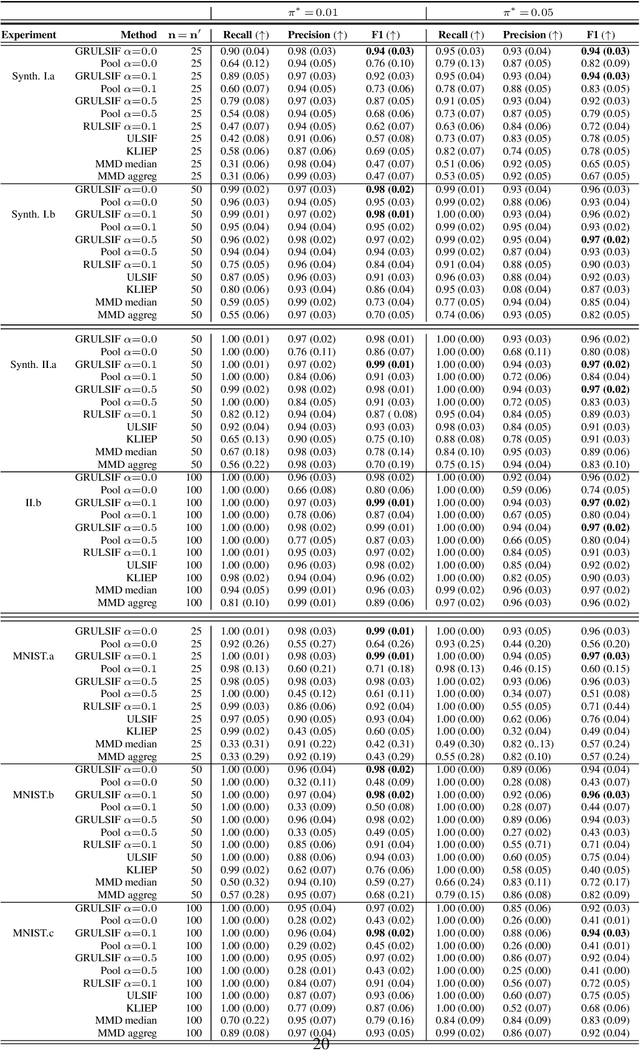
Assuming we have i.i.d observations from two unknown probability density functions (pdfs), $p$ and $p'$, the likelihood-ratio estimation (LRE) is an elegant approach to compare the two pdfs just by relying on the available data, and without knowing the pdfs explicitly. In this paper we introduce a graph-based extension of this problem: Suppose each node $v$ of a fixed graph has access to observations coming from two unknown node-specific pdfs, $p_v$ and $p'_v$; the goal is then to compare the respective $p_v$ and $p'_v$ of each node by also integrating information provided by the graph structure. This setting is interesting when the graph conveys some sort of `similarity' between the node-wise estimation tasks, which suggests that the nodes can collaborate to solve more efficiently their individual tasks, while on the other hand trying to limit the data sharing among them. Our main contribution is a distributed non-parametric framework for graph-based LRE, called GRULSIF, that incorporates in a novel way elements from f-divengence functionals, Kernel methods, and Multitask Learning. Among the several applications of LRE, we choose the two-sample hypothesis testing to develop a proof of concept for our graph-based learning framework. Our experiments compare favorably the performance of our approach against state-of-the-art non-parametric statistical tests that apply at each node independently, and thus disregard the graph structure.