 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross Cryptocurrency Relationship Mining for Bitcoin Price Prediction
Apr 28, 2022
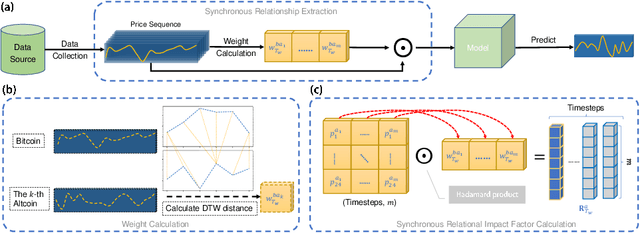
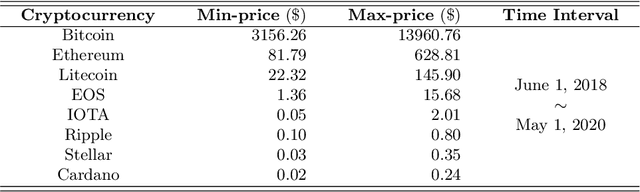
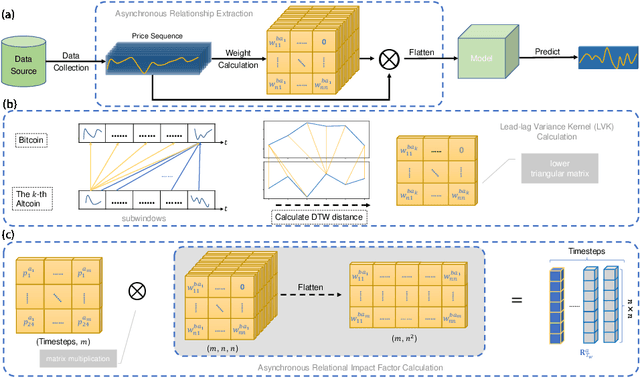
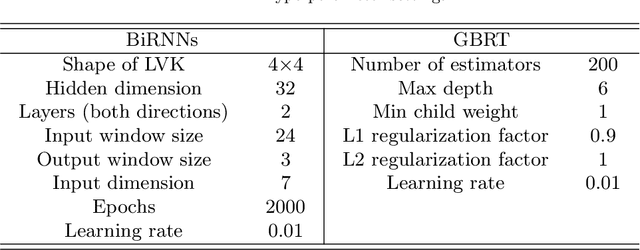
Blockchain finance has become a part of the world financial system, most typically manifested in the attention to the price of Bitcoin. However, a great deal of work is still limited to using technical indicators to capture Bitcoin price fluctuation, with little consideration of historical relationships and interactions between related cryptocurrencies. In this work, we propose a generic Cross-Cryptocurrency Relationship Mining module, named C2RM, which can effectively capture the synchronous and asynchronous impact factors between Bitcoin and related Altcoins. Specifically, we utilize the Dynamic Time Warping algorithm to extract the lead-lag relationship, yielding Lead-lag Variance Kernel, which will be used for aggregating the information of Altcoins to form relational impact factors. Comprehensive experimental results demonstrate that our C2RM can help existing price prediction methods achieve significant performance improvement, suggesting the effectiveness of Cross-Cryptocurrency interactions on benefitting Bitcoin price prediction.
Semi-WTC: A Practical Semi-supervised Framework for Attack Categorization through Weight-Task Consistency
May 20, 2022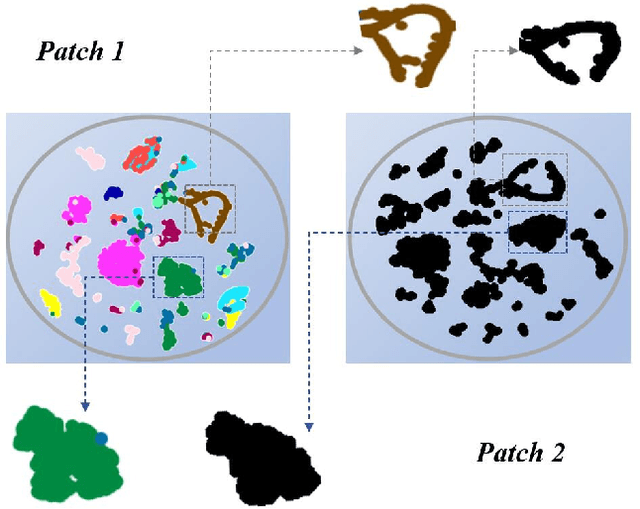

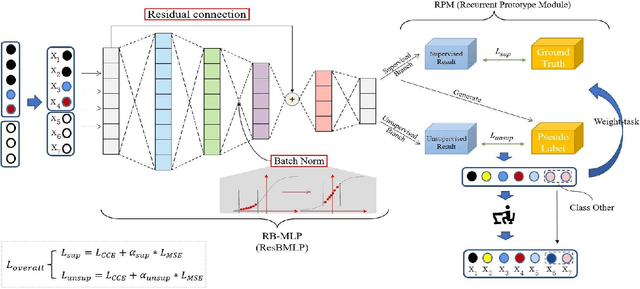
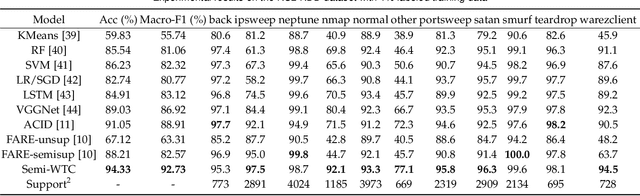
Supervised learning has been widely used for attack detection, which requires large amounts of high-quality data and labels. However, the data is often imbalanced and sufficient annotations are difficult to obtain. Moreover, these supervised models are subject to real-world deployment issues, such as defending against unseen artificial attacks. We propose a semi-supervised fine-grained attack categorization framework consisting of an encoder and a two-branch structure to integrate information from labeled and unlabeled data to tackle these practical challenges. This framework can be generalized to different supervised models. The multilayer perceptron with residual connection and batch normalization is used as the encoder to extract features and reduce the complexity. The Recurrent Prototype Module (RPM) is proposed to train the encoder effectively in a semi-supervised manner. To alleviate the problem of data imbalance, we introduce the Weight-Task Consistency (WTC) into the iterative process of RPM by assigning larger weights to classes with fewer samples in the loss function. In addition, to cope with new attacks in real-world deployment, we further propose an Active Adaption Resampling (AAR) method, which can better discover the distribution of the unseen sample data and adapt the parameters of the encoder. Experimental results show that our model outperforms the state-of-the-art semi-supervised attack detection methods with a general 5% improvement in classification accuracy and a 90% reduction in training time.
Fundamental limitations on optimization in variational quantum algorithms
May 10, 2022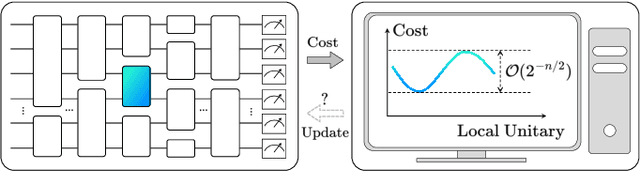
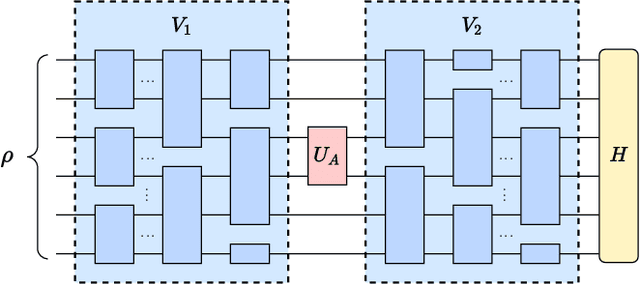
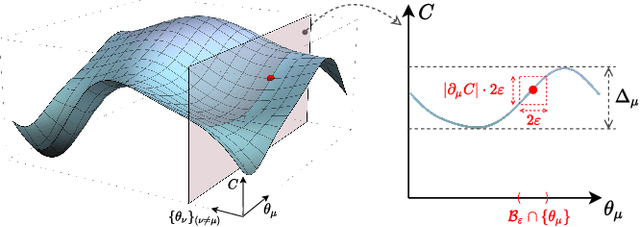

Exploring quantum applications of near-term quantum devices is a rapidly growing field of quantum information science with both theoretical and practical interests. A leading paradigm to establish such near-term quantum applications is variational quantum algorithms (VQAs). These algorithms use a classical optimizer to train a parameterized quantum circuit to accomplish certain tasks, where the circuits are usually randomly initialized. In this work, we prove that for a broad class of such random circuits, the variation range of the cost function via adjusting any local quantum gate within the circuit vanishes exponentially in the number of qubits with a high probability. This result can unify the restrictions on gradient-based and gradient-free optimizations in a natural manner and reveal extra harsh constraints on the training landscapes of VQAs. Hence a fundamental limitation on the trainability of VQAs is unraveled, indicating the essence of the optimization hardness in the Hilbert space with exponential dimension. We further showcase the validity of our results with numerical simulations of representative VQAs. We believe that these results would deepen our understanding of the scalability of VQAs and shed light on the search for near-term quantum applications with advantages.
C3KG: A Chinese Commonsense Conversation Knowledge Graph
Apr 06, 2022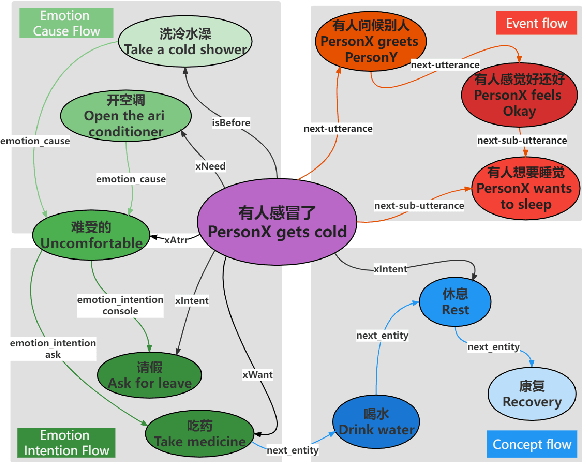

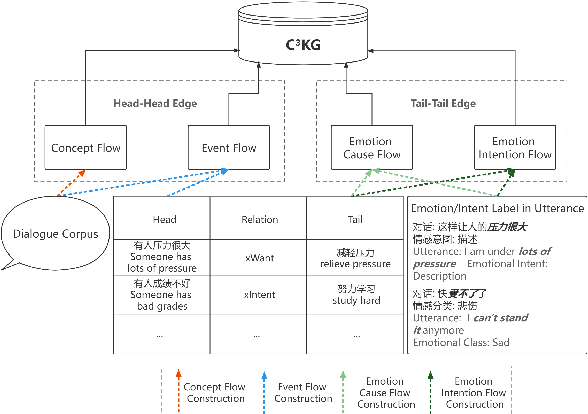

Existing commonsense knowledge bases often organize tuples in an isolated manner, which is deficient for commonsense conversational models to plan the next steps. To fill the gap, we curate a large-scale multi-turn human-written conversation corpus, and create the first Chinese commonsense conversation knowledge graph which incorporates both social commonsense knowledge and dialog flow information. To show the potential of our graph, we develop a graph-conversation matching approach, and benchmark two graph-grounded conversational tasks.
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints
May 10, 2022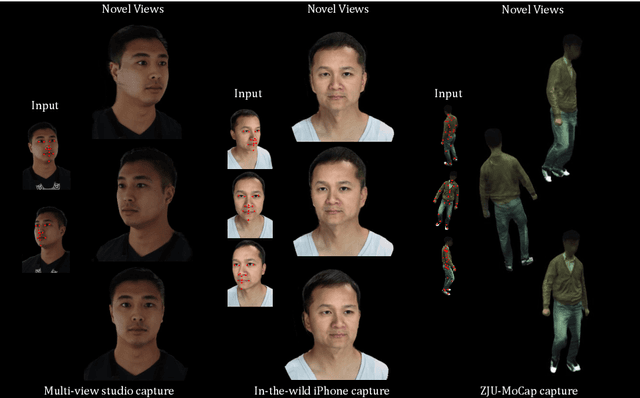

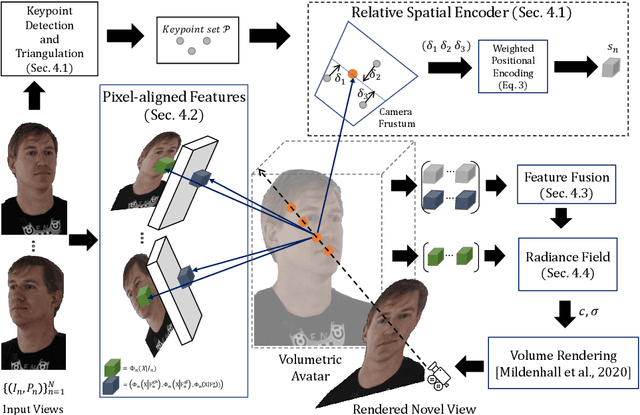
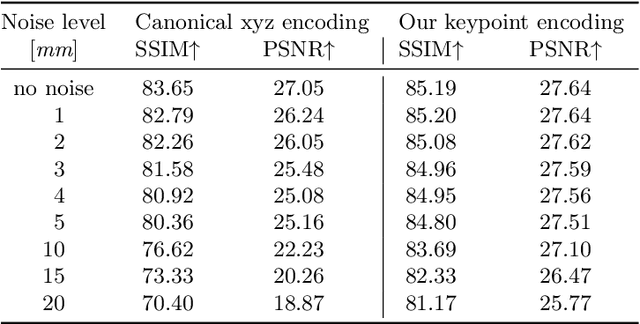
Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior work that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling. https://markomih.github.io/KeypointNeRF
What can we Learn Even From the Weakest? Learning Sketches for Programmatic Strategies
Mar 22, 2022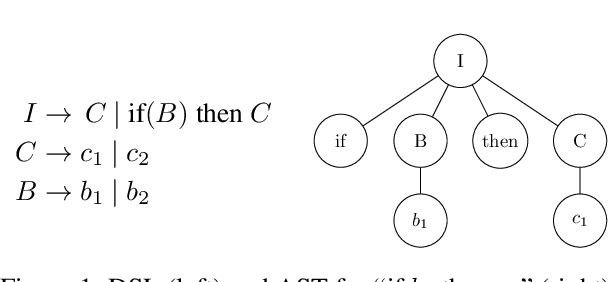

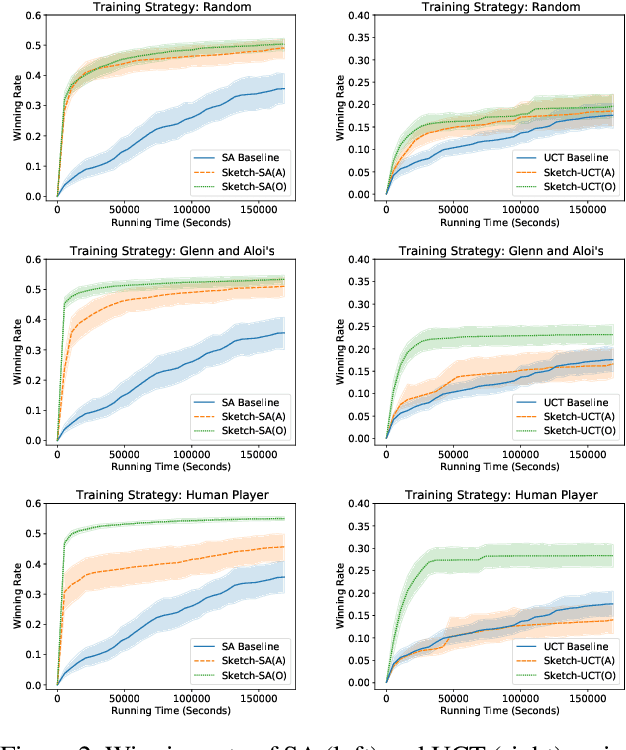
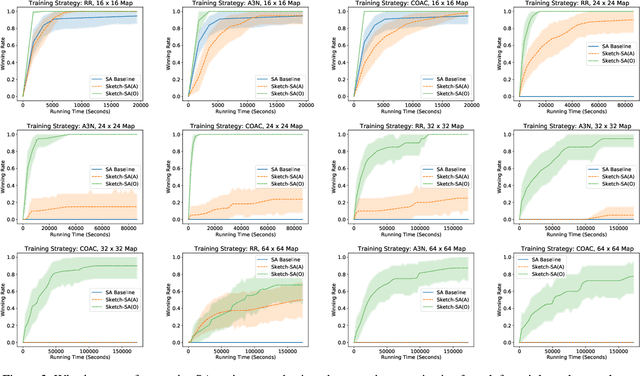
In this paper we show that behavioral cloning can be used to learn effective sketches of programmatic strategies. We show that even the sketches learned by cloning the behavior of weak players can help the synthesis of programmatic strategies. This is because even weak players can provide helpful information, e.g., that a player must choose an action in their turn of the game. If behavioral cloning is not employed, the synthesizer needs to learn even the most basic information by playing the game, which can be computationally expensive. We demonstrate empirically the advantages of our sketch-learning approach with simulated annealing and UCT synthesizers. We evaluate our synthesizers in the games of Can't Stop and MicroRTS. The sketch-based synthesizers are able to learn stronger programmatic strategies than their original counterparts. Our synthesizers generate strategies of Can't Stop that defeat a traditional programmatic strategy for the game. They also synthesize strategies that defeat the best performing method from the latest MicroRTS competition.
Exploiting Contextual Information with Deep Neural Networks
Jun 27, 2020
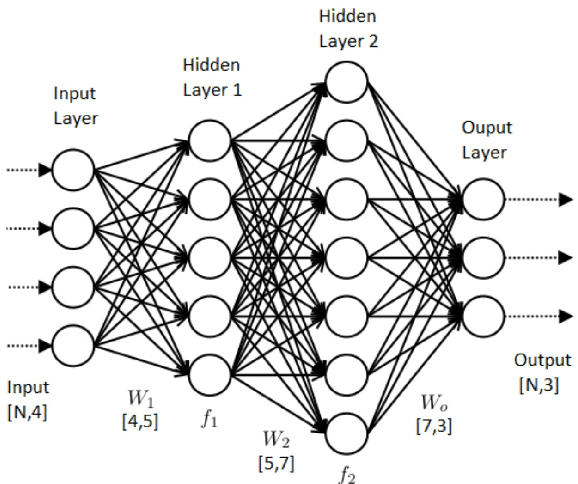
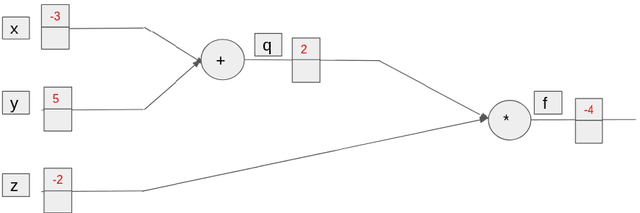
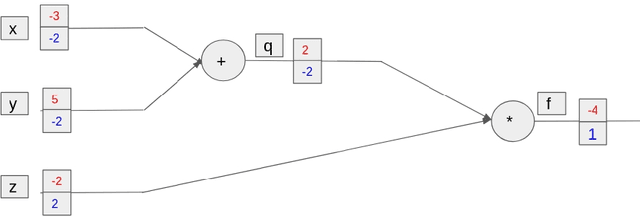
Context matters! Nevertheless, there has not been much research in exploiting contextual information in deep neural networks. For most part, the entire usage of contextual information has been limited to recurrent neural networks. Attention models and capsule networks are two recent ways of introducing contextual information in non-recurrent models, however both of these algorithms have been developed after this work has started. In this thesis, we show that contextual information can be exploited in 2 fundamentally different ways: implicitly and explicitly. In the DeepScore project, where the usage of context is very important for the recognition of many tiny objects, we show that by carefully crafting convolutional architectures, we can achieve state-of-the-art results, while also being able to implicitly correctly distinguish between objects which are virtually identical, but have different meanings based on their surrounding. In parallel, we show that by explicitly designing algorithms (motivated from graph theory and game theory) that take into considerations the entire structure of the dataset, we can achieve state-of-the-art results in different topics like semi-supervised learning and similarity learning. To the best of our knowledge, we are the first to integrate graph-theoretical modules, carefully crafted for the problem of similarity learning and that are designed to consider contextual information, not only outperforming the other models, but also gaining a speed improvement while using a smaller number of parameters.
A Probabilistic Representation of Deep Learning for Improving The Information Theoretic Interpretability
Oct 27, 2020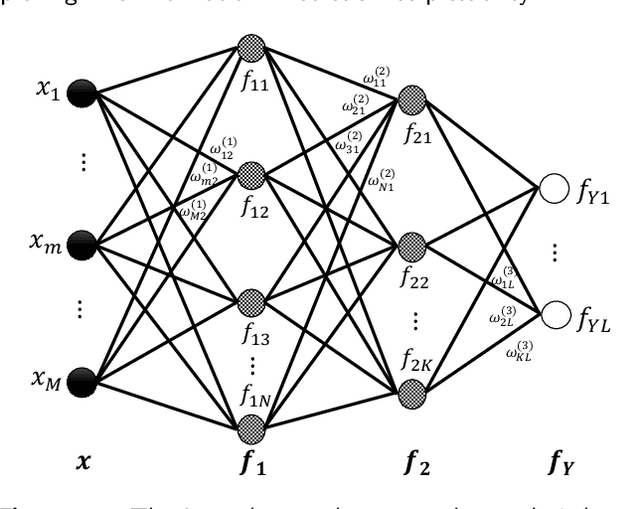
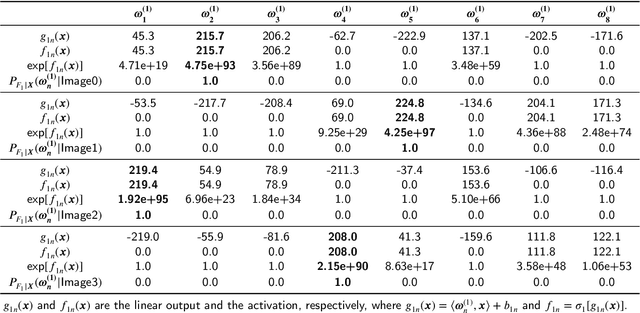
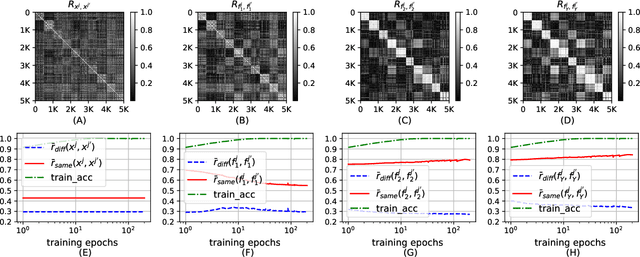
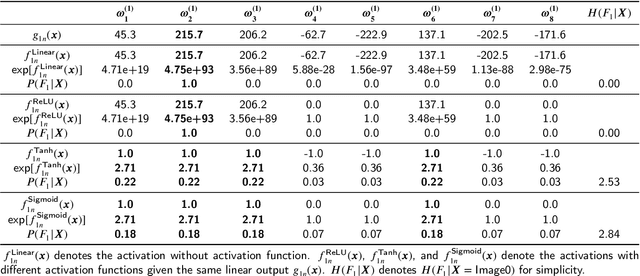
In this paper, we propose a probabilistic representation of MultiLayer Perceptrons (MLPs) to improve the information-theoretic interpretability. Above all, we demonstrate that the activations being i.i.d. is not valid for all the hidden layers of MLPs, thus the existing mutual information estimators based on non-parametric inference methods, e.g., empirical distributions and Kernel Density Estimate (KDE), are invalid for measuring the information flow in MLPs. Moreover, we introduce explicit probabilistic explanations for MLPs: (i) we define the probability space (Omega_F, t, P_F) for a fully connected layer f and demonstrate the great effect of an activation function on the probability measure P_F ; (ii) we prove the entire architecture of MLPs as a Gibbs distribution P; and (iii) the back-propagation aims to optimize the sample space Omega_F of all the fully connected layers of MLPs for learning an optimal Gibbs distribution P* to express the statistical connection between the input and the label. Based on the probabilistic explanations for MLPs, we improve the information-theoretic interpretability of MLPs in three aspects: (i) the random variable of f is discrete and the corresponding entropy is finite; (ii) the information bottleneck theory cannot correctly explain the information flow in MLPs if we take into account the back-propagation; and (iii) we propose novel information-theoretic explanations for the generalization of MLPs. Finally, we demonstrate the proposed probabilistic representation and information-theoretic explanations for MLPs in a synthetic dataset and benchmark datasets.
Continual learning on 3D point clouds with random compressed rehearsal
May 20, 2022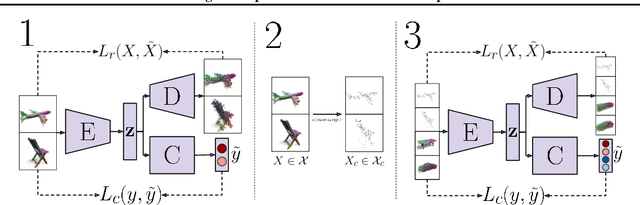

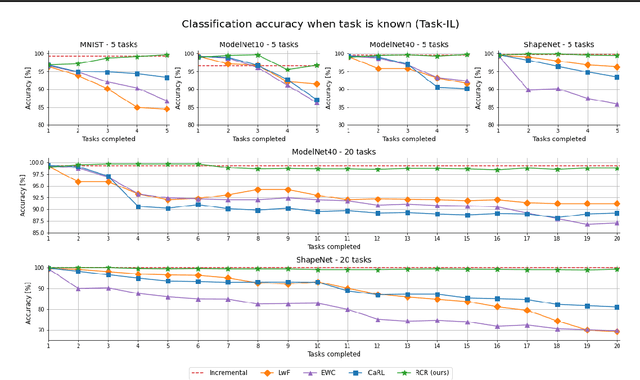
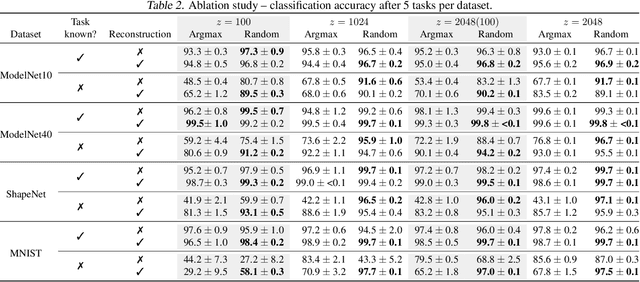
Contemporary deep neural networks offer state-of-the-art results when applied to visual reasoning, e.g., in the context of 3D point cloud data. Point clouds are important datatype for precise modeling of three-dimensional environments, but effective processing of this type of data proves to be challenging. In the world of large, heavily-parameterized network architectures and continuously-streamed data, there is an increasing need for machine learning models that can be trained on additional data. Unfortunately, currently available models cannot fully leverage training on additional data without losing their past knowledge. Combating this phenomenon, called catastrophic forgetting, is one of the main objectives of continual learning. Continual learning for deep neural networks has been an active field of research, primarily in 2D computer vision, natural language processing, reinforcement learning, and robotics. However, in 3D computer vision, there are hardly any continual learning solutions specifically designed to take advantage of point cloud structure. This work proposes a novel neural network architecture capable of continual learning on 3D point cloud data. We utilize point cloud structure properties for preserving a heavily compressed set of past data. By using rehearsal and reconstruction as regularization methods of the learning process, our approach achieves a significant decrease of catastrophic forgetting compared to the existing solutions on several most popular point cloud datasets considering two continual learning settings: when a task is known beforehand, and in the challenging scenario of when task information is unknown to the model.
Context-Preserving Instance-Level Augmentation and Deformable Convolution Networks for SAR Ship Detection
Feb 14, 2022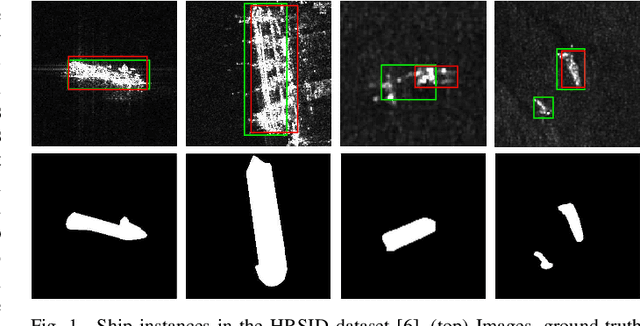

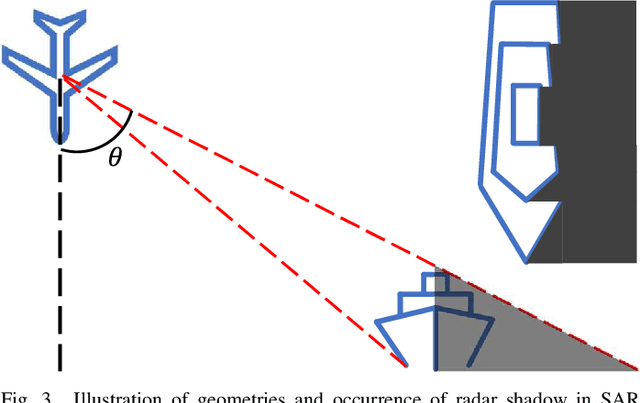

Shape deformation of targets in SAR image due to random orientation and partial information loss caused by occlusion of the radar signal, is an essential challenge in SAR ship detection. In this paper, we propose a data augmentation method to train a deep network that is robust to partial information loss within the targets. Taking advantage of ground-truth annotations for bounding box and instance segmentation mask, we present a simple and effective pipeline to simulate information loss on targets in instance-level, while preserving contextual information. Furthermore, we adopt deformable convolutional network to adaptively extract shape-invariant deep features from geometrically translated targets. By learning sampling offset to the grid of standard convolution, the network can robustly extract the features from targets with shape variations for SAR ship detection. Experiments on the HRSID dataset including comparisons with other deep networks and augmentation methods, as well as ablation study, demonstrate the effectiveness of our proposed method.