 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
STDC-MA Network for Semantic Segmentation
May 11, 2022
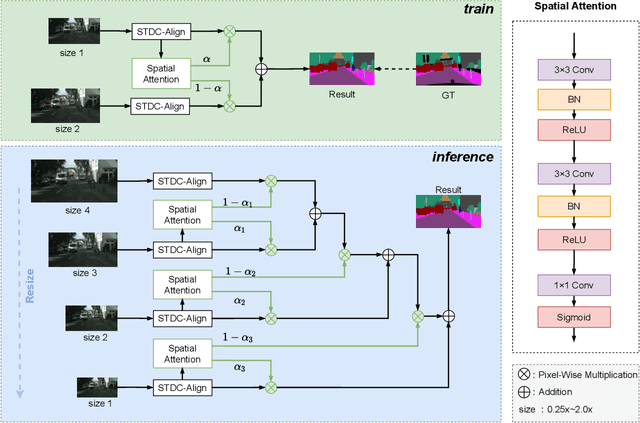

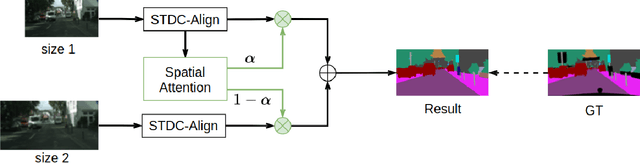
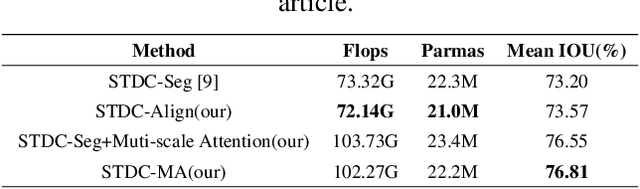
Semantic segmentation is applied extensively in autonomous driving and intelligent transportation with methods that highly demand spatial and semantic information. Here, an STDC-MA network is proposed to meet these demands. First, the STDC-Seg structure is employed in STDC-MA to ensure a lightweight and efficient structure. Subsequently, the feature alignment module (FAM) is applied to understand the offset between high-level and low-level features, solving the problem of pixel offset related to upsampling on the high-level feature map. Our approach implements the effective fusion between high-level features and low-level features. A hierarchical multiscale attention mechanism is adopted to reveal the relationship among attention regions from two different input sizes of one image. Through this relationship, regions receiving much attention are integrated into the segmentation results, thereby reducing the unfocused regions of the input image and improving the effective utilization of multiscale features. STDC- MA maintains the segmentation speed as an STDC-Seg network while improving the segmentation accuracy of small objects. STDC-MA was verified on the verification set of Cityscapes. The segmentation result of STDC-MA attained 76.81% mIOU with the input of 0.5x scale, 3.61% higher than STDC-Seg.
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Mar 31, 2022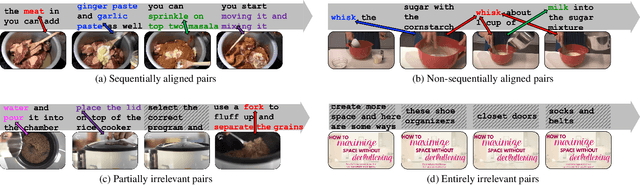
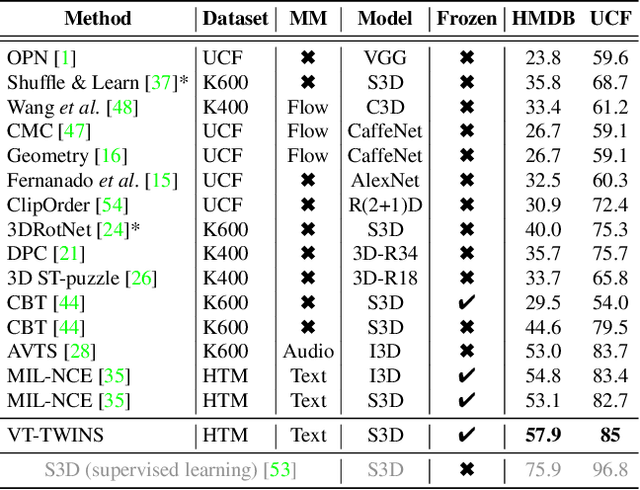
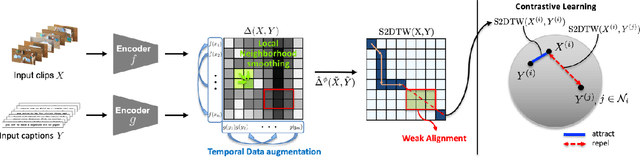
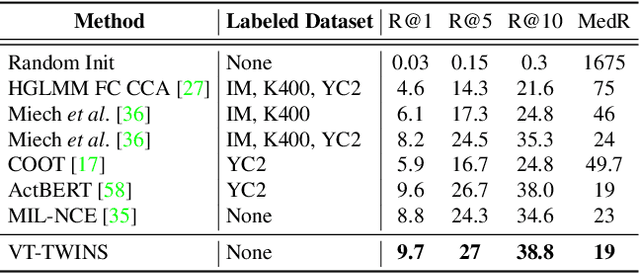
Learning generic joint representations for video and text by a supervised method requires a prohibitively substantial amount of manually annotated video datasets. As a practical alternative, a large-scale but uncurated and narrated video dataset, HowTo100M, has recently been introduced. But it is still challenging to learn joint embeddings of video and text in a self-supervised manner, due to its ambiguity and non-sequential alignment. In this paper, we propose a novel multi-modal self-supervised framework Video-Text Temporally Weak Alignment-based Contrastive Learning (VT-TWINS) to capture significant information from noisy and weakly correlated data using a variant of Dynamic Time Warping (DTW). We observe that the standard DTW inherently cannot handle weakly correlated data and only considers the globally optimal alignment path. To address these problems, we develop a differentiable DTW which also reflects local information with weak temporal alignment. Moreover, our proposed model applies a contrastive learning scheme to learn feature representations on weakly correlated data. Our extensive experiments demonstrate that VT-TWINS attains significant improvements in multi-modal representation learning and outperforms various challenging downstream tasks. Code is available at https://github.com/mlvlab/VT-TWINS.
C3KG: A Chinese Commonsense Conversation Knowledge Graph
Apr 06, 2022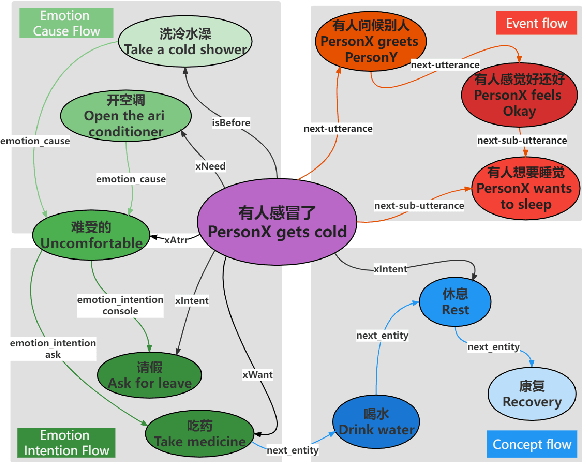

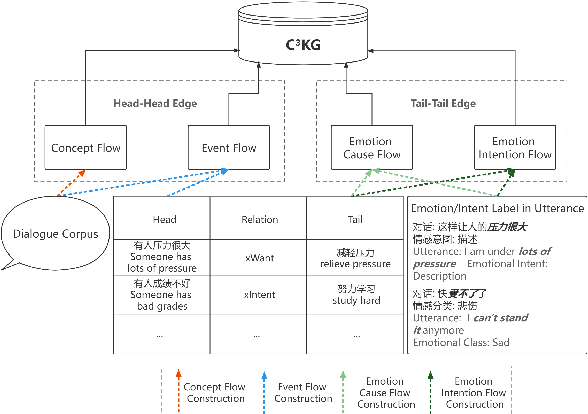

Existing commonsense knowledge bases often organize tuples in an isolated manner, which is deficient for commonsense conversational models to plan the next steps. To fill the gap, we curate a large-scale multi-turn human-written conversation corpus, and create the first Chinese commonsense conversation knowledge graph which incorporates both social commonsense knowledge and dialog flow information. To show the potential of our graph, we develop a graph-conversation matching approach, and benchmark two graph-grounded conversational tasks.
What can we Learn Even From the Weakest? Learning Sketches for Programmatic Strategies
Mar 22, 2022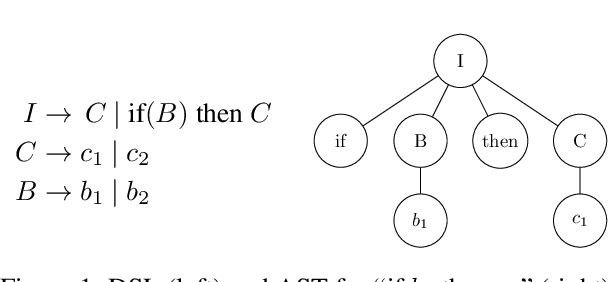

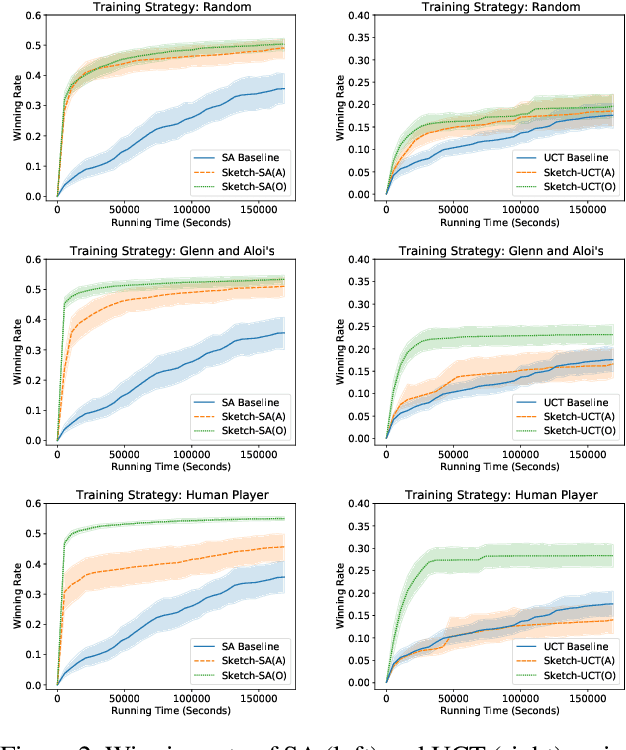
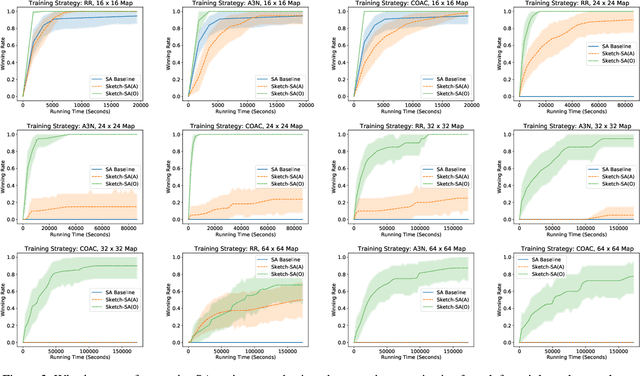
In this paper we show that behavioral cloning can be used to learn effective sketches of programmatic strategies. We show that even the sketches learned by cloning the behavior of weak players can help the synthesis of programmatic strategies. This is because even weak players can provide helpful information, e.g., that a player must choose an action in their turn of the game. If behavioral cloning is not employed, the synthesizer needs to learn even the most basic information by playing the game, which can be computationally expensive. We demonstrate empirically the advantages of our sketch-learning approach with simulated annealing and UCT synthesizers. We evaluate our synthesizers in the games of Can't Stop and MicroRTS. The sketch-based synthesizers are able to learn stronger programmatic strategies than their original counterparts. Our synthesizers generate strategies of Can't Stop that defeat a traditional programmatic strategy for the game. They also synthesize strategies that defeat the best performing method from the latest MicroRTS competition.
Cross Cryptocurrency Relationship Mining for Bitcoin Price Prediction
Apr 28, 2022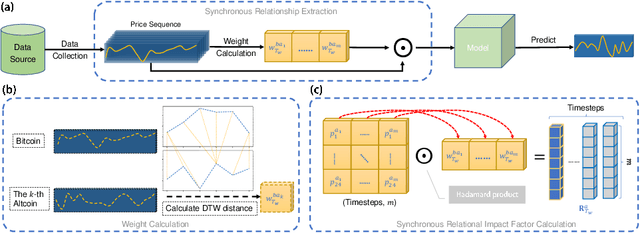
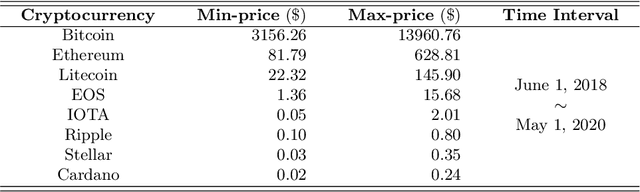
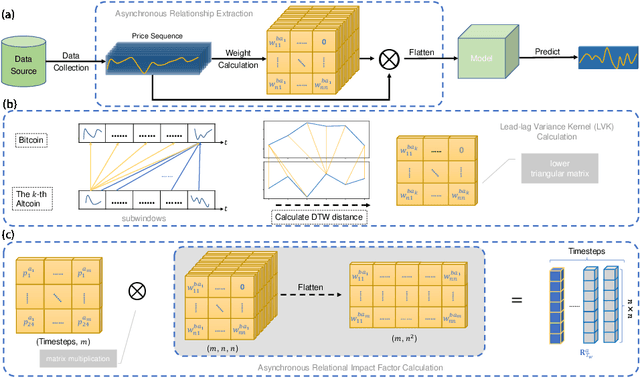
Blockchain finance has become a part of the world financial system, most typically manifested in the attention to the price of Bitcoin. However, a great deal of work is still limited to using technical indicators to capture Bitcoin price fluctuation, with little consideration of historical relationships and interactions between related cryptocurrencies. In this work, we propose a generic Cross-Cryptocurrency Relationship Mining module, named C2RM, which can effectively capture the synchronous and asynchronous impact factors between Bitcoin and related Altcoins. Specifically, we utilize the Dynamic Time Warping algorithm to extract the lead-lag relationship, yielding Lead-lag Variance Kernel, which will be used for aggregating the information of Altcoins to form relational impact factors. Comprehensive experimental results demonstrate that our C2RM can help existing price prediction methods achieve significant performance improvement, suggesting the effectiveness of Cross-Cryptocurrency interactions on benefitting Bitcoin price prediction.
Leveraging Meta-path Contexts for Classification in Heterogeneous Information Networks
Dec 18, 2020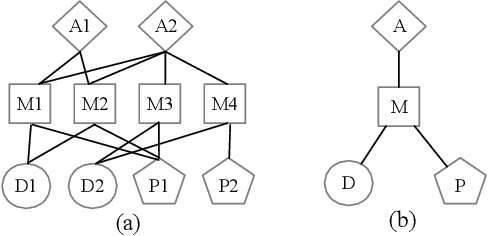
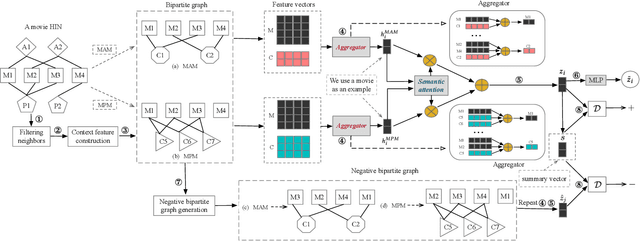
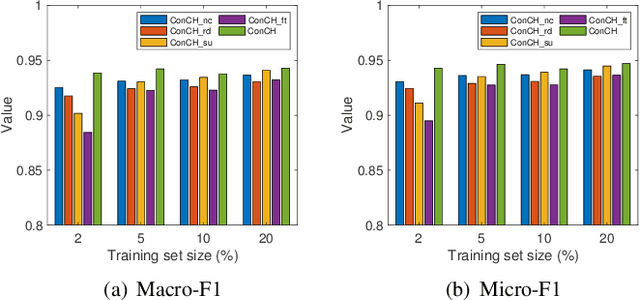
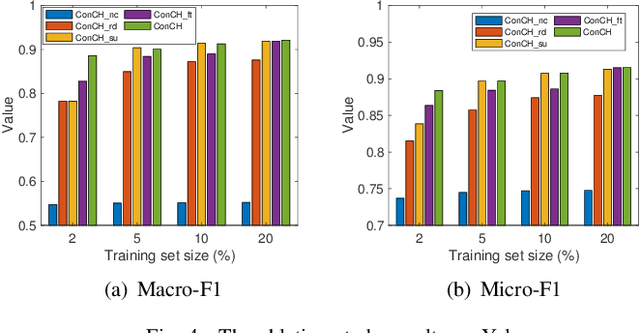
A heterogeneous information network (HIN) has as vertices objects of different types and as edges the relations between objects, which are also of various types. We study the problem of classifying objects in HINs. Most existing methods perform poorly when given scarce labeled objects as training sets, and methods that improve classification accuracy under such scenarios are often computationally expensive. To address these problems, we propose ConCH, a graph neural network model. ConCH formulates the classification problem as a multi-task learning problem that combines semi-supervised learning with self-supervised learning to learn from both labeled and unlabeled data. ConCH employs meta-paths, which are sequences of object types that capture semantic relationships between objects. Based on meta-paths, it considers two sources of information for an object x: (1) Meta-path-based neighbors of x are retrieved and ranked, and the top-k neighbors are retained. (2) The meta-path instances of x to its selected neighbors are used to derive meta-path-based contexts. ConCH utilizes the above information to co-derive object embeddings and context embeddings via graph convolution. It also uses the attention mechanism to fuse the embeddings of x generated from various meta-paths to obtain x's final embedding. We conduct extensive experiments to evaluate the performance of ConCH against other 14 classification methods. Our results show that ConCH is an effective and efficient method for HIN classification.
Decoupled Pyramid Correlation Network for Liver Tumor Segmentation from CT images
May 26, 2022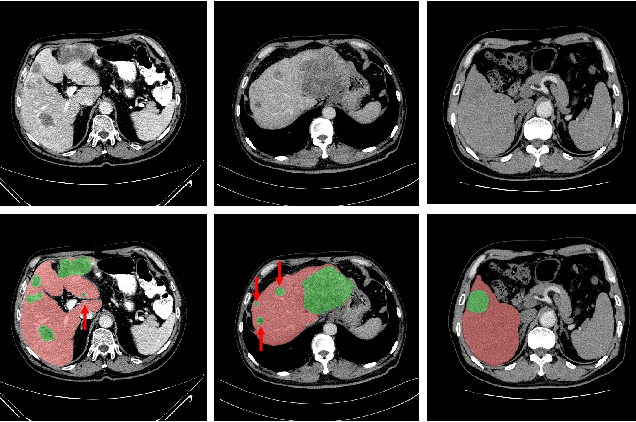
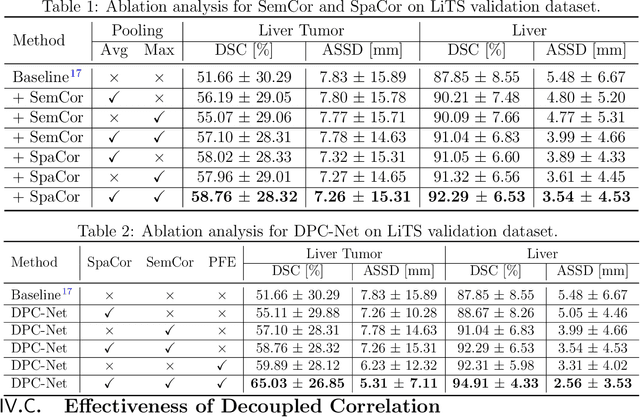
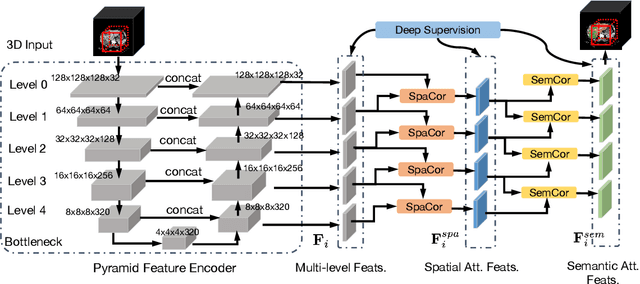
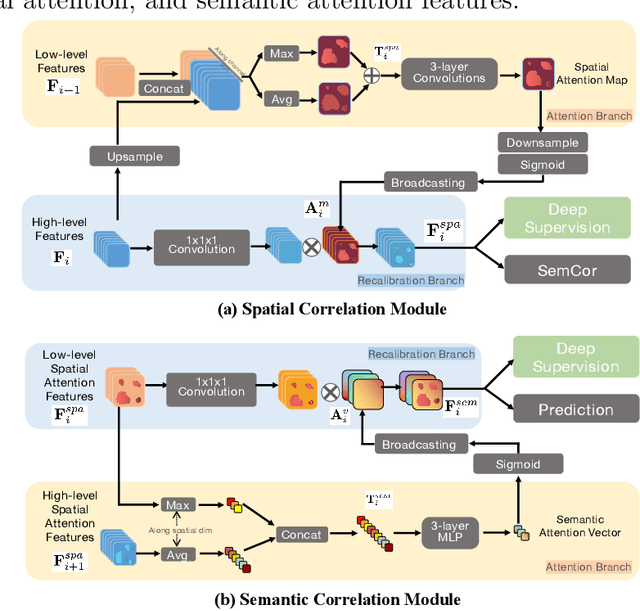
Purpose: Automated liver tumor segmentation from Computed Tomography (CT) images is a necessary prerequisite in the interventions of hepatic abnormalities and surgery planning. However, accurate liver tumor segmentation remains challenging due to the large variability of tumor sizes and inhomogeneous texture. Recent advances based on Fully Convolutional Network (FCN) for medical image segmentation drew on the success of learning discriminative pyramid features. In this paper, we propose a Decoupled Pyramid Correlation Network (DPC-Net) that exploits attention mechanisms to fully leverage both low- and high-level features embedded in FCN to segment liver tumor. Methods: We first design a powerful Pyramid Feature Encoder (PFE) to extract multi-level features from input images. Then we decouple the characteristics of features concerning spatial dimension (i.e., height, width, depth) and semantic dimension (i.e., channel). On top of that, we present two types of attention modules, Spatial Correlation (SpaCor) and Semantic Correlation (SemCor) modules, to recursively measure the correlation of multi-level features. The former selectively emphasizes global semantic information in low-level features with the guidance of high-level ones. The latter adaptively enhance spatial details in high-level features with the guidance of low-level ones. Results: We evaluate the DPC-Net on MICCAI 2017 LiTS Liver Tumor Segmentation (LiTS) challenge dataset. Dice Similarity Coefficient (DSC) and Average Symmetric Surface Distance (ASSD) are employed for evaluation. The proposed method obtains a DSC of 76.4% and an ASSD of 0.838 mm for liver tumor segmentation, outperforming the state-of-the-art methods. It also achieves a competitive results with a DSC of 96.0% and an ASSD of 1.636 mm for liver segmentation.
Extracting Latent Steering Vectors from Pretrained Language Models
May 10, 2022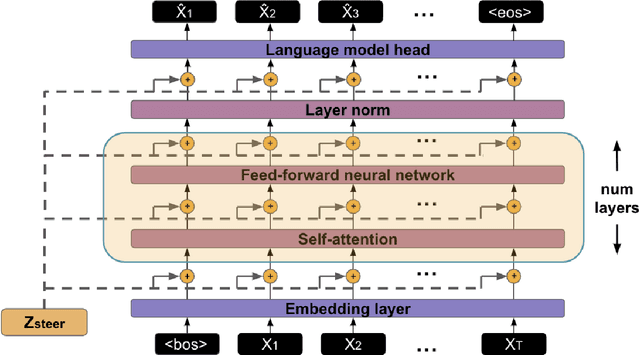


Prior work on controllable text generation has focused on learning how to control language models through trainable decoding, smart-prompt design, or fine-tuning based on a desired objective. We hypothesize that the information needed to steer the model to generate a target sentence is already encoded within the model. Accordingly, we explore a different approach altogether: extracting latent vectors directly from pretrained language model decoders without fine-tuning. Experiments show that there exist steering vectors, which, when added to the hidden states of the language model, generate a target sentence nearly perfectly (> 99 BLEU) for English sentences from a variety of domains. We show that vector arithmetic can be used for unsupervised sentiment transfer on the Yelp sentiment benchmark, with performance comparable to models tailored to this task. We find that distances between steering vectors reflect sentence similarity when evaluated on a textual similarity benchmark (STS-B), outperforming pooled hidden states of models. Finally, we present an analysis of the intrinsic properties of the steering vectors. Taken together, our results suggest that frozen LMs can be effectively controlled through their latent steering space.
A Computationally Efficient Approach to Non-cooperative Target Detection and Tracking with Almost No A-priori Information
Apr 20, 2021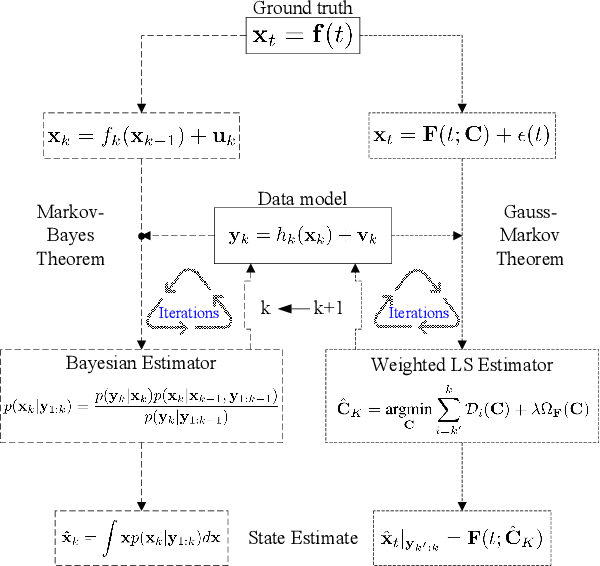
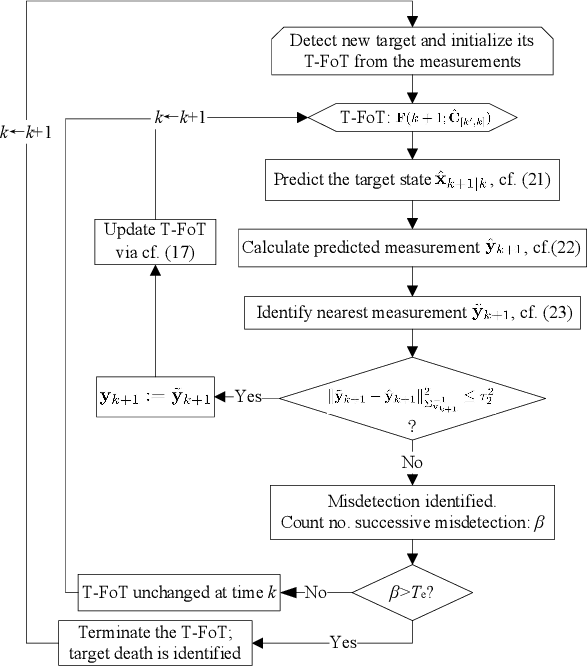
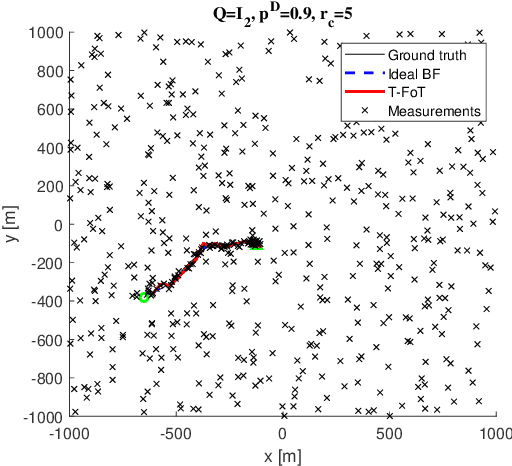
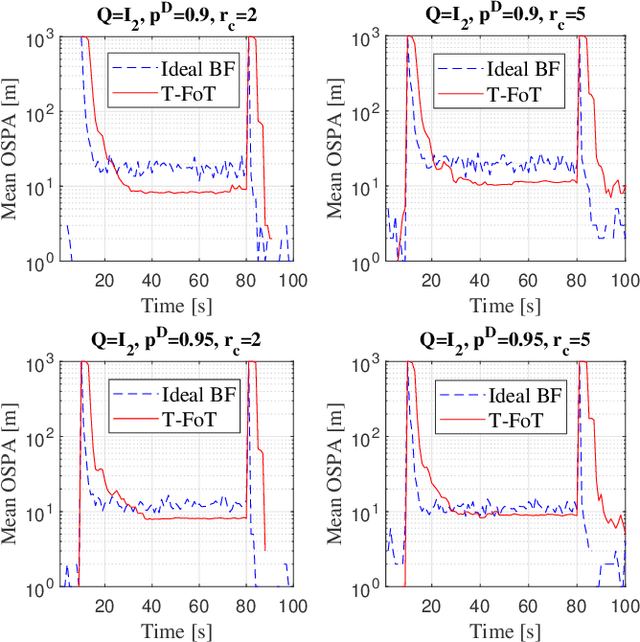
This paper addresses the problem of real-time detection and tracking of a non-cooperative target in the challenging scenario with almost no a-priori information about target birth, death, dynamics and detection probability. Furthermore, there are false and missing data at unknown yet low rates in the measurements. The only information given in advance is about the target-measurement model and the constraint that there is no more than one target in the scenario. To solve these challenges, we model the movement of the target by using a trajectory function of time (T-FoT). Data-driven T-FoT initiation and termination strategies are proposed for identifying the (re-)appearance and disappearance of the target. During the existence of the target, real target measurements are distinguished from clutter if the target indeed exists and is detected, in order to update the T-FoT at each scan for which we design a least-squares estimator. Simulations using either linear or nonlinear systems are conducted to demonstrate the effectiveness of our approach in comparison with the Bayes optimal Bernoulli filters. The results show that our approach is comparable to the perfectly-modeled filters, even outperforms them in some cases while requiring much less a-prior information and computing much faster.
Decomposing neural networks as mappings of correlation functions
Feb 10, 2022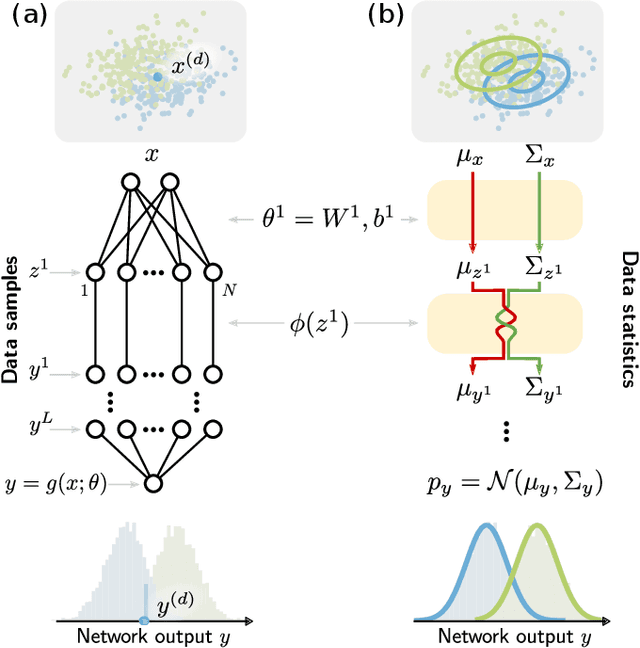
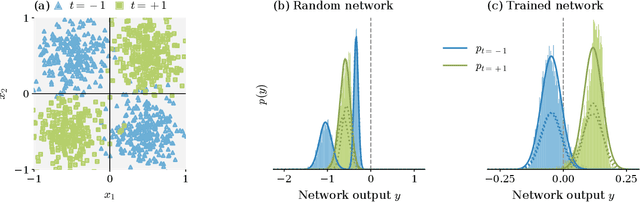
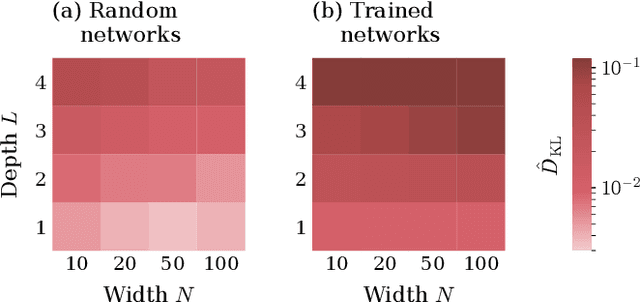
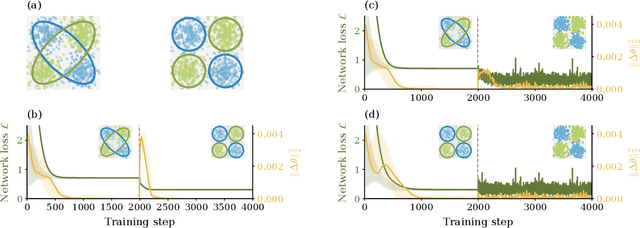
Understanding the functional principles of information processing in deep neural networks continues to be a challenge, in particular for networks with trained and thus non-random weights. To address this issue, we study the mapping between probability distributions implemented by a deep feed-forward network. We characterize this mapping as an iterated transformation of distributions, where the non-linearity in each layer transfers information between different orders of correlation functions. This allows us to identify essential statistics in the data, as well as different information representations that can be used by neural networks. Applied to an XOR task and to MNIST, we show that correlations up to second order predominantly capture the information processing in the internal layers, while the input layer also extracts higher-order correlations from the data. This analysis provides a quantitative and explainable perspective on classification.