 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 22, 2022
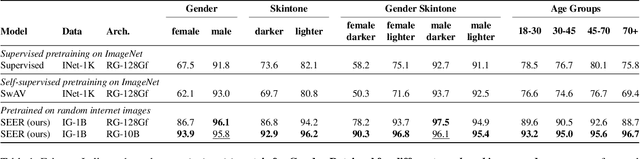
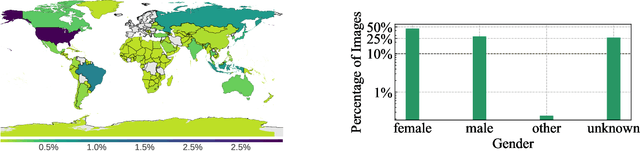
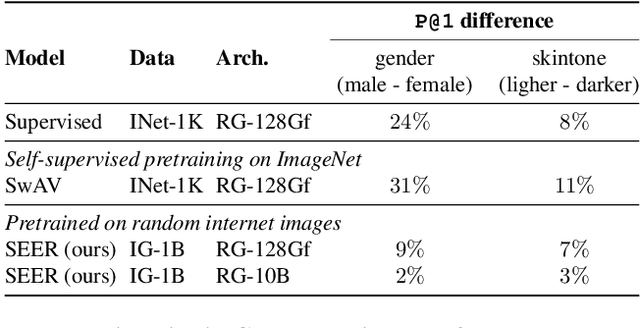
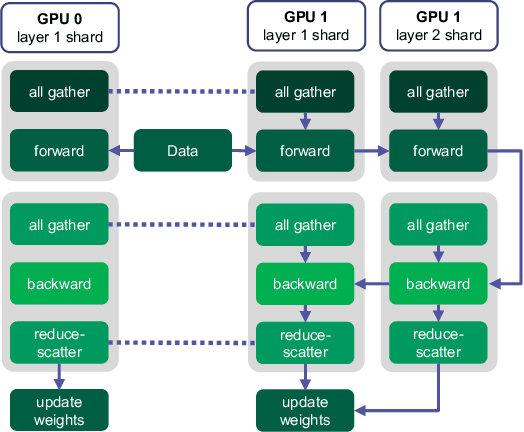
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.
GraphAD: A Graph Neural Network for Entity-Wise Multivariate Time-Series Anomaly Detection
May 23, 2022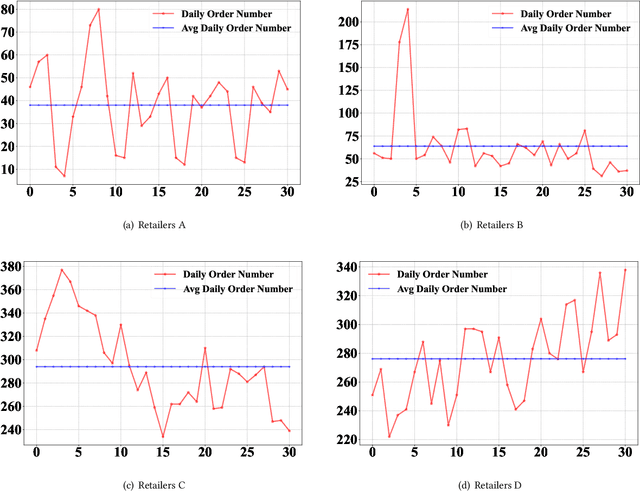
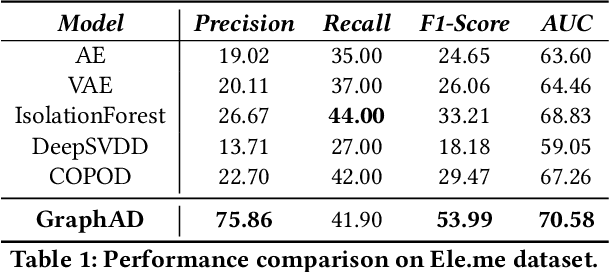
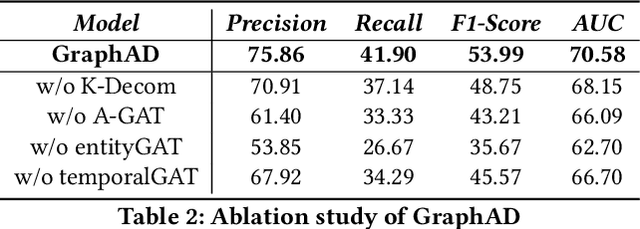
In recent years, the emergence and development of third-party platforms have greatly facilitated the growth of the Online to Offline (O2O) business. However, the large amount of transaction data raises new challenges for retailers, especially anomaly detection in operating conditions. Thus, platforms begin to develop intelligent business assistants with embedded anomaly detection methods to reduce the management burden on retailers. Traditional time-series anomaly detection methods capture underlying patterns from the perspectives of time and attributes, ignoring the difference between retailers in this scenario. Besides, similar transaction patterns extracted by the platforms can also provide guidance to individual retailers and enrich their available information without privacy issues. In this paper, we pose an entity-wise multivariate time-series anomaly detection problem that considers the time-series of each unique entity. To address this challenge, we propose GraphAD, a novel multivariate time-series anomaly detection model based on the graph neural network. GraphAD decomposes the Key Performance Indicator (KPI) into stable and volatility components and extracts their patterns in terms of attributes, entities and temporal perspectives via graph neural networks. We also construct a real-world entity-wise multivariate time-series dataset from the business data of Ele.me. The experimental results on this dataset show that GraphAD significantly outperforms existing anomaly detection methods.
Follow-the-Perturbed-Leader for Adversarial Markov Decision Processes with Bandit Feedback
May 26, 2022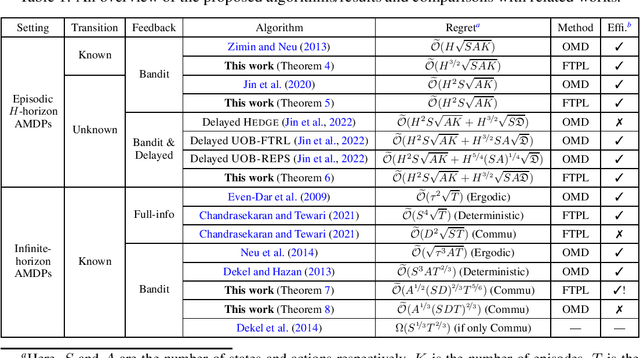
We consider regret minimization for Adversarial Markov Decision Processes (AMDPs), where the loss functions are changing over time and adversarially chosen, and the learner only observes the losses for the visited state-action pairs (i.e., bandit feedback). While there has been a surge of studies on this problem using Online-Mirror-Descent (OMD) methods, very little is known about the Follow-the-Perturbed-Leader (FTPL) methods, which are usually computationally more efficient and also easier to implement since it only requires solving an offline planning problem. Motivated by this, we take a closer look at FTPL for learning AMDPs, starting from the standard episodic finite-horizon setting. We find some unique and intriguing difficulties in the analysis and propose a workaround to eventually show that FTPL is also able to achieve near-optimal regret bounds in this case. More importantly, we then find two significant applications: First, the analysis of FTPL turns out to be readily generalizable to delayed bandit feedback with order-optimal regret, while OMD methods exhibit extra difficulties (Jin et al., 2022). Second, using FTPL, we also develop the first no-regret algorithm for learning communicating AMDPs in the infinite-horizon setting with bandit feedback and stochastic transitions. Our algorithm is efficient assuming access to an offline planning oracle, while even for the easier full-information setting, the only existing algorithm (Chandrasekaran and Tewari, 2021) is computationally inefficient.
Visual Knowledge Discovery with Artificial Intelligence: Challenges and Future Directions
May 04, 2022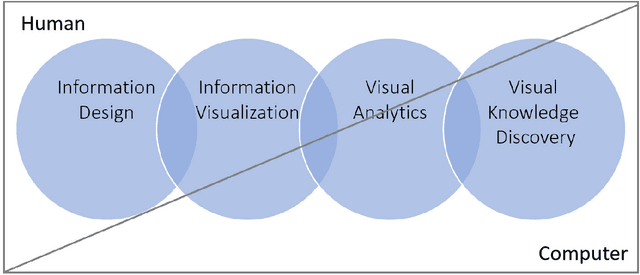
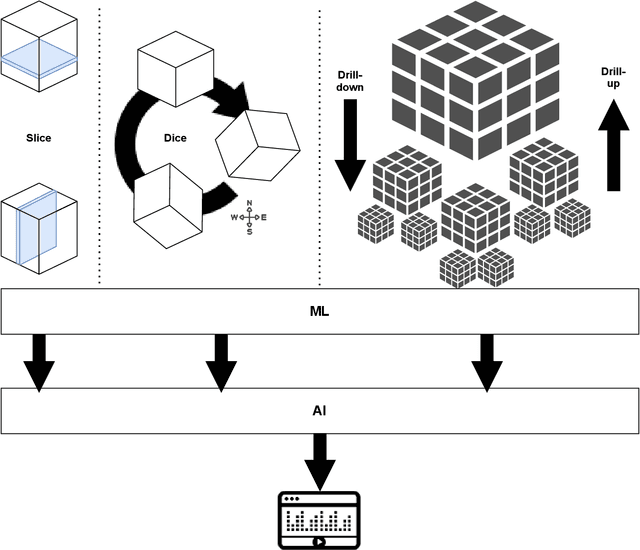
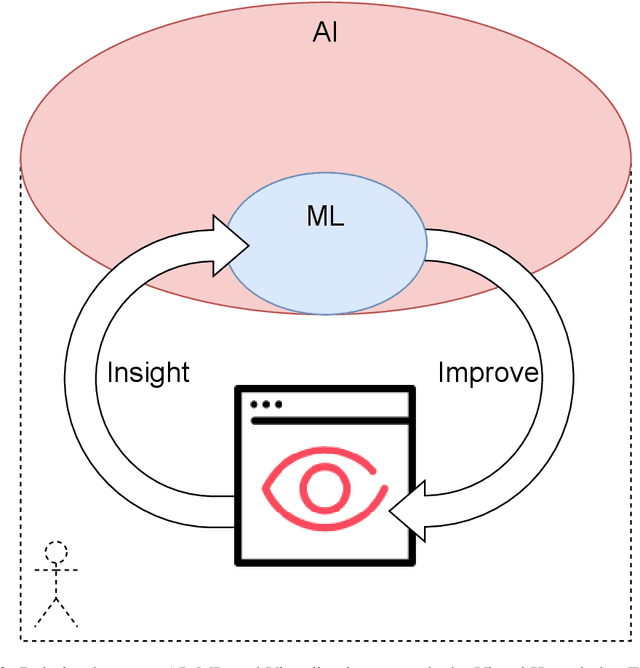
This volume is devoted to the emerging field of Integrated Visual Knowledge Discovery that combines advances in Artificial Intelligence/Machine Learning (AI/ML) and Visualization/Visual Analytics. Chapters included are extended versions of the selected AI and Visual Analytics papers and related symposia at the recent International Information Visualization Conferences (IV2019 and IV2020). AI/ML face a long-standing challenge of explaining models to humans. Models explanation is fundamentally human activity, not only an algorithmic one. In this chapter we aim to present challenges and future directions within the field of Visual Analytics, Visual Knowledge Discovery and AI/ML, and to discuss the role of visualization in visual AI/ML. In addition, we describe progress in emerging Full 2D ML, natural language processing, and AI/ML in multidimensional data aided by visual means.
A Few Brief Notes on DeepImpact, COIL, and a Conceptual Framework for Information Retrieval Techniques
Jun 28, 2021
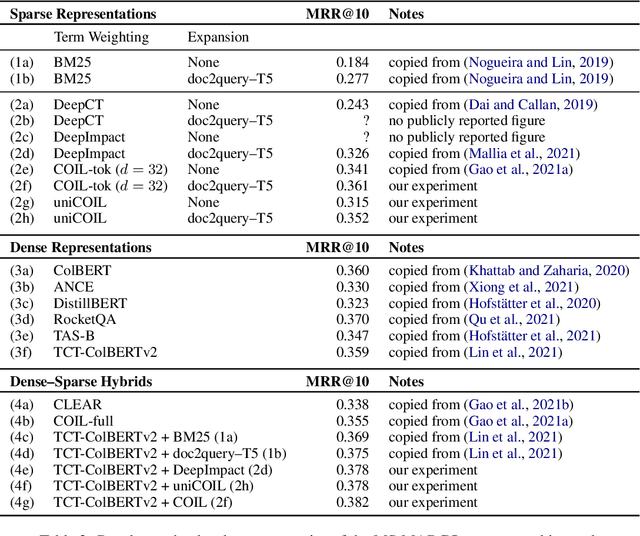
Recent developments in representational learning for information retrieval can be organized in a conceptual framework that establishes two pairs of contrasts: sparse vs. dense representations and unsupervised vs. learned representations. Sparse learned representations can further be decomposed into expansion and term weighting components. This framework allows us to understand the relationship between recently proposed techniques such as DPR, ANCE, DeepCT, DeepImpact, and COIL, and furthermore, gaps revealed by our analysis point to "low hanging fruit" in terms of techniques that have yet to be explored. We present a novel technique dubbed "uniCOIL", a simple extension of COIL that achieves to our knowledge the current state-of-the-art in sparse retrieval on the popular MS MARCO passage ranking dataset. Our implementation using the Anserini IR toolkit is built on the Lucene search library and thus fully compatible with standard inverted indexes.
End-to-End Zero-Shot Voice Style Transfer with Location-Variable Convolutions
May 19, 2022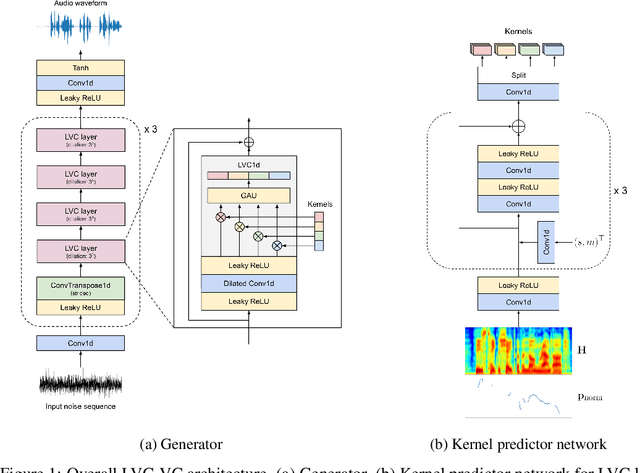
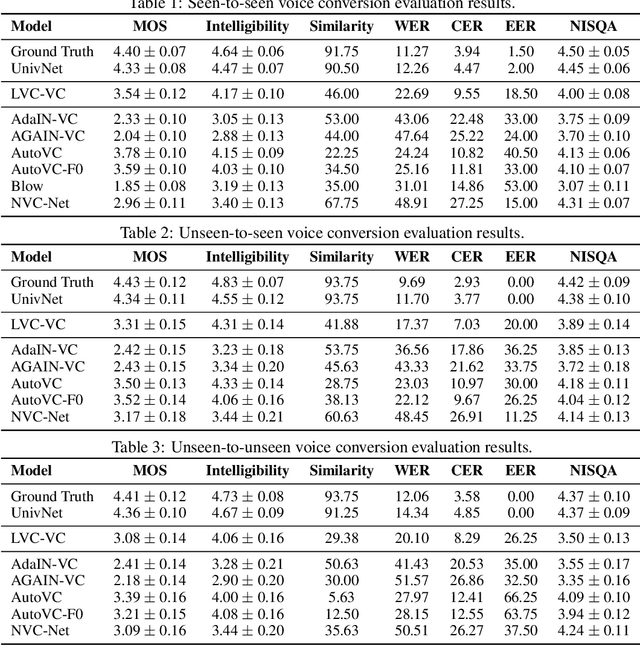

Zero-shot voice conversion is becoming an increasingly popular research direction, as it promises the ability to transform speech to match the voice style of any speaker. However, little work has been done on end-to-end methods for this task, which are appealing because they remove the need for a separate vocoder to generate audio from intermediate features. In this work, we propose Location-Variable Convolution-based Voice Conversion (LVC-VC), a model for performing end-to-end zero-shot voice conversion that is based on a neural vocoder. LVC-VC utilizes carefully designed input features that have disentangled content and speaker style information, and the vocoder-like architecture learns to combine them to simultaneously perform voice conversion while synthesizing audio. To the best of our knowledge, LVC-VC is one of the first models to be proposed that can perform zero-shot voice conversion in an end-to-end manner, and it is the first to do so using a vocoder-like neural framework. Experiments show that our model achieves competitive or better voice style transfer performance compared to several baselines while maintaining the intelligibility of transformed speech much better.
CABACE: Injecting Character Sequence Information and Domain Knowledge for Enhanced Acronym and Long-Form Extraction
Dec 25, 2021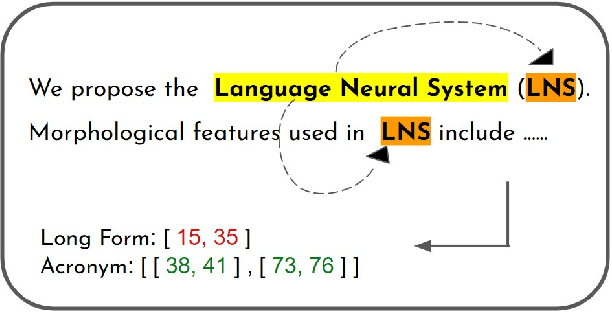
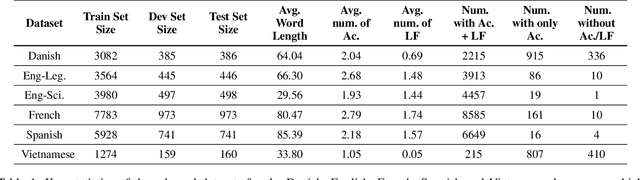
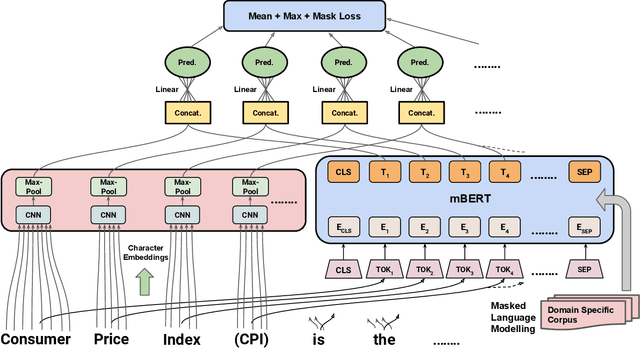
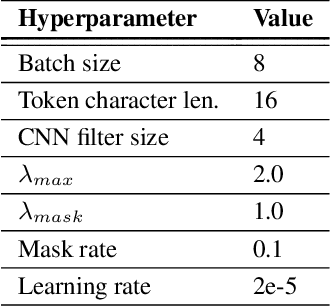
Acronyms and long-forms are commonly found in research documents, more so in documents from scientific and legal domains. Many acronyms used in such documents are domain-specific and are very rarely found in normal text corpora. Owing to this, transformer-based NLP models often detect OOV (Out of Vocabulary) for acronym tokens, especially for non-English languages, and their performance suffers while linking acronyms to their long forms during extraction. Moreover, pretrained transformer models like BERT are not specialized to handle scientific and legal documents. With these points being the overarching motivation behind this work, we propose a novel framework CABACE: Character-Aware BERT for ACronym Extraction, which takes into account character sequences in text and is adapted to scientific and legal domains by masked language modelling. We further use an objective with an augmented loss function, adding the max loss and mask loss terms to the standard cross-entropy loss for training CABACE. We further leverage pseudo labelling and adversarial data generation to improve the generalizability of the framework. Experimental results prove the superiority of the proposed framework in comparison to various baselines. Additionally, we show that the proposed framework is better suited than baseline models for zero-shot generalization to non-English languages, thus reinforcing the effectiveness of our approach. Our team BacKGProp secured the highest scores on the French dataset, second-highest on Danish and Vietnamese, and third-highest in the English-Legal dataset on the global leaderboard for the acronym extraction (AE) shared task at SDU AAAI-22.
MSTRIQ: No Reference Image Quality Assessment Based on Swin Transformer with Multi-Stage Fusion
May 23, 2022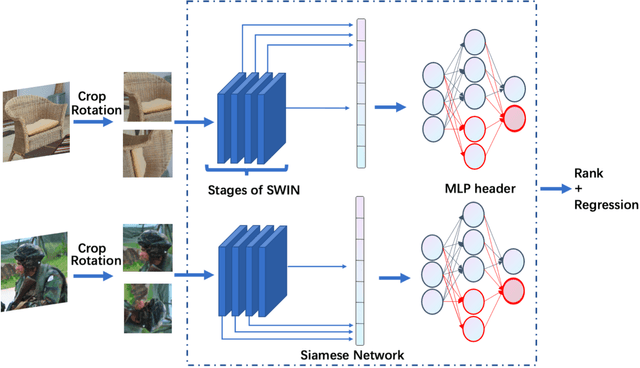
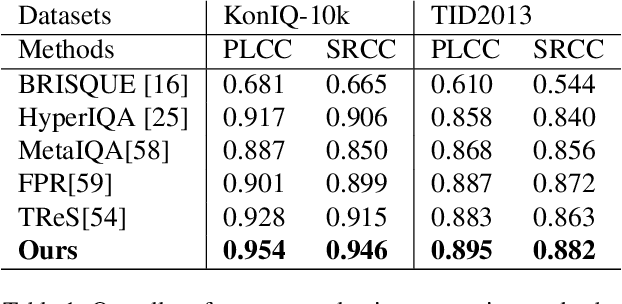
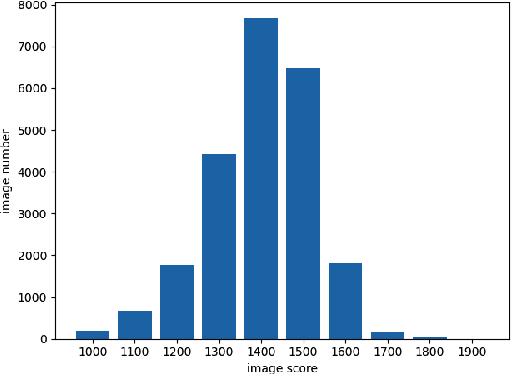
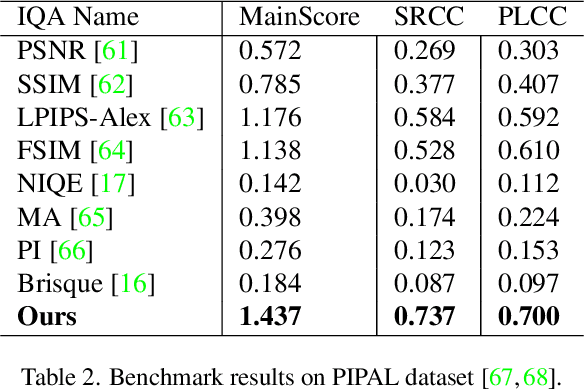
Measuring the perceptual quality of images automatically is an essential task in the area of computer vision, as degradations on image quality can exist in many processes from image acquisition, transmission to enhancing. Many Image Quality Assessment(IQA) algorithms have been designed to tackle this problem. However, it still remains un settled due to the various types of image distortions and the lack of large-scale human-rated datasets. In this paper, we propose a novel algorithm based on the Swin Transformer [31] with fused features from multiple stages, which aggregates information from both local and global features to better predict the quality. To address the issues of small-scale datasets, relative rankings of images have been taken into account together with regression loss to simultaneously optimize the model. Furthermore, effective data augmentation strategies are also used to improve the performance. In comparisons with previous works, experiments are carried out on two standard IQA datasets and a challenge dataset. The results demonstrate the effectiveness of our work. The proposed method outperforms other methods on standard datasets and ranks 2nd in the no-reference track of NTIRE 2022 Perceptual Image Quality Assessment Challenge [53]. It verifies that our method is promising in solving diverse IQA problems and thus can be used to real-word applications.
Discrete models of continuous behavior of collective adaptive systems
Apr 26, 2022
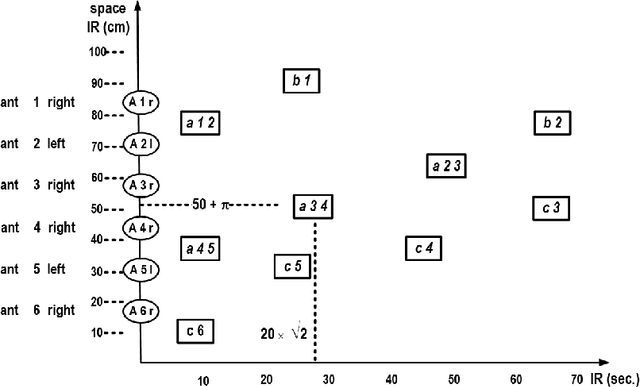
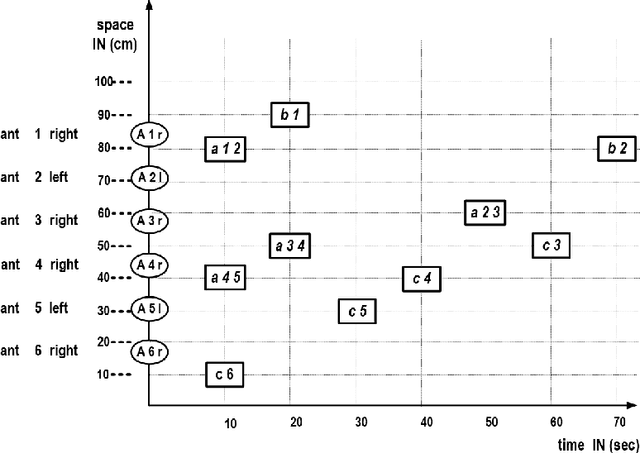
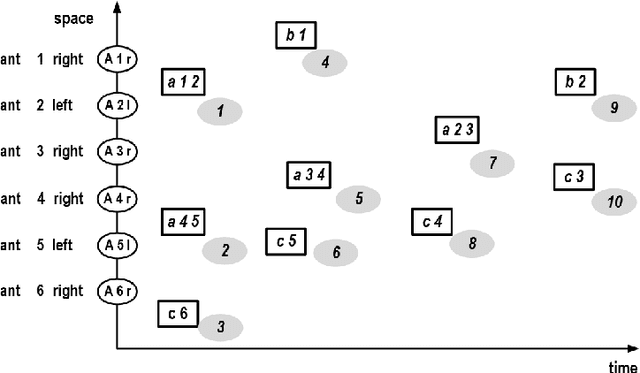
Artificial ants are "small" units, moving autonomously around on a shared, dynamically changing "space", directly or indirectly exchanging some kind of information. Artificial ants are frequently conceived as a paradigm for collective adaptive systems. In this paper, we discuss means to represent continuous moves of "ants" in discrete models. More generally, we challenge the role of the notion of "time" in artificial ant systems and models. We suggest a modeling framework that structures behavior along causal dependencies, and not along temporal relations. We present all arguments by help of a simple example. As a modeling framework we employ Heraklit; an emerging framework that already has proven its worth in many contexts.
Obsolete Personal Information Update System for the Prevention of Falls among Elderly Patients
Jan 20, 2021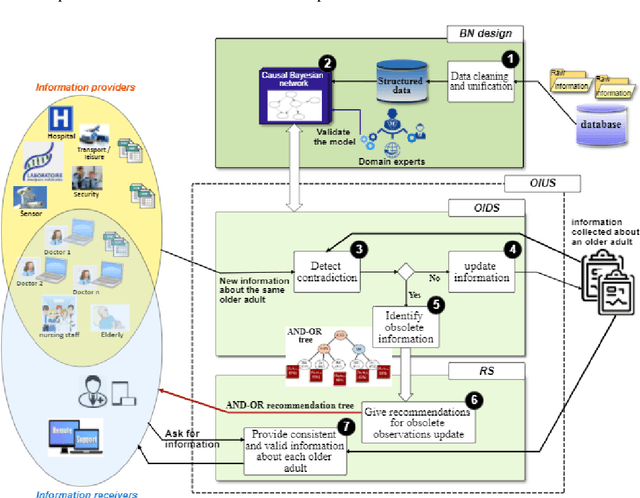
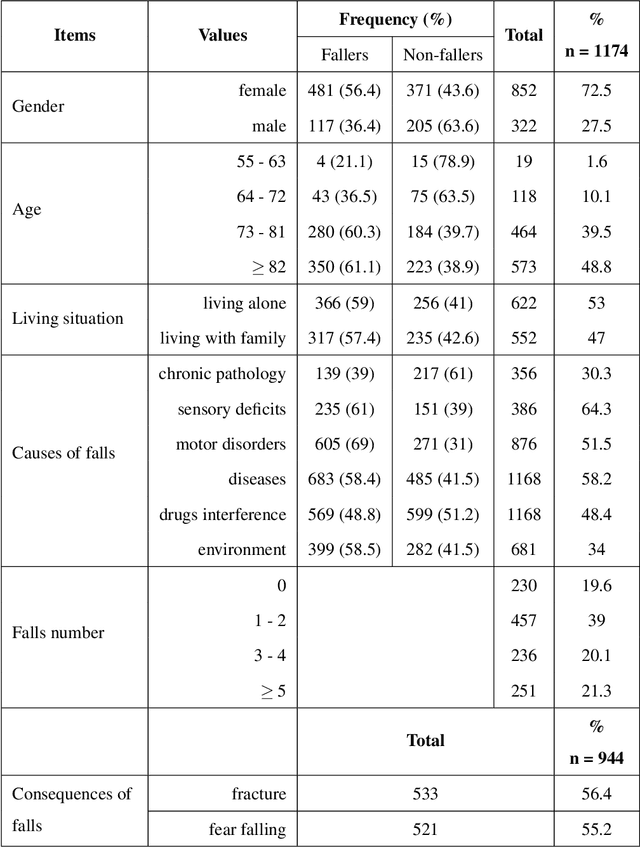
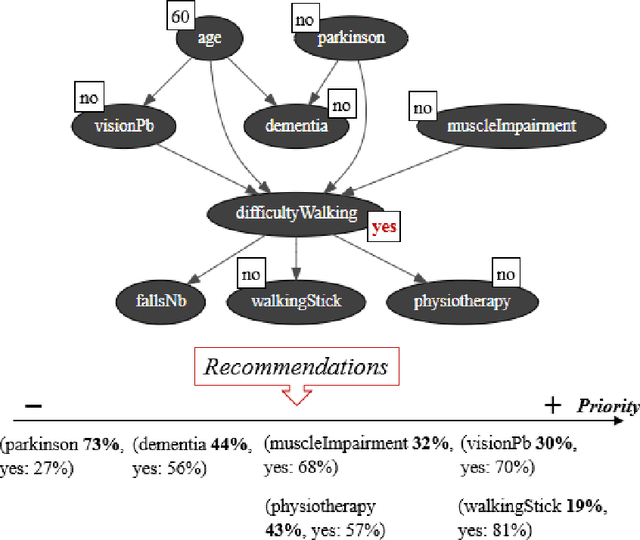
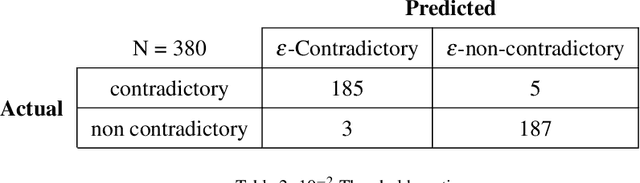
Falls are a common problem affecting the older adults and a major public health issue. Centers for Disease Control and Prevention, and World Health Organization report that one in three adults over the age of 65 and half of the adults over 80 fall each year. In recent years, an ever-increasing range of applications have been developed to help deliver more effective falls prevention interventions. All these applications rely on a huge elderly personal database collected from hospitals, mutual health, and other organizations in caring for elderly. The information describing an elderly is continually evolving and may become obsolete at a given moment and contradict what we already know on the same person. So, it needs to be continuously checked and updated in order to restore the database consistency and then provide better service. This paper provides an outline of an Obsolete personal Information Update System (OIUS) designed in the context of the elderly-fall prevention project. Our OIUS aims to control and update in real-time the information acquired about each older adult, provide on-demand consistent information and supply tailored interventions to caregivers and fall-risk patients. The approach outlined for this purpose is based on a polynomial-time algorithm build on top of a causal Bayesian network representing the elderly data. The result is given as a recommendation tree with some accuracy level. We conduct a thorough empirical study for such a model on an elderly personal information base. Experiments confirm the viability and effectiveness of our OIUS.