 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CenGCN: Centralized Convolutional Networks with Vertex Imbalance for Scale-Free Graphs
Feb 16, 2022
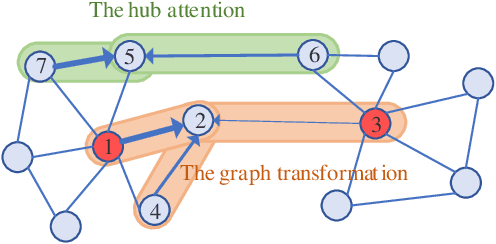
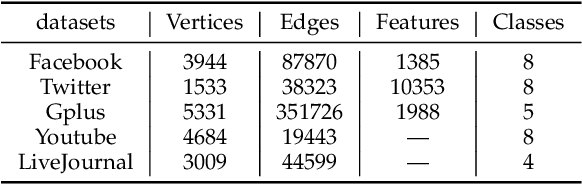
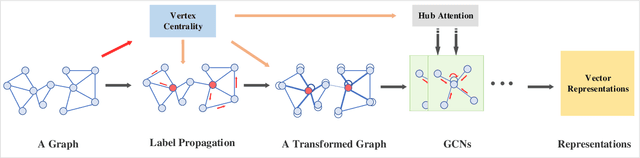
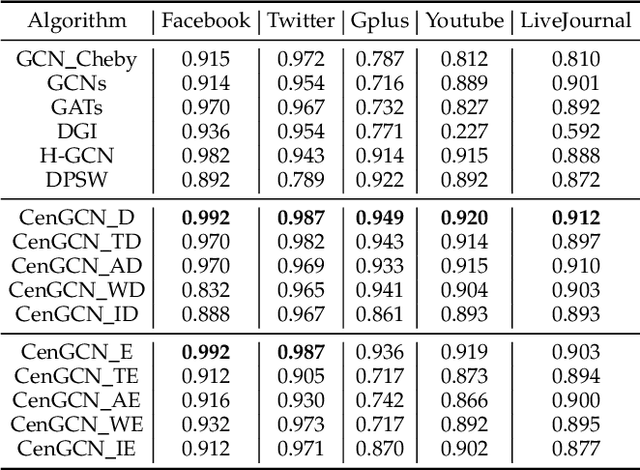
Graph Convolutional Networks (GCNs) have achieved impressive performance in a wide variety of areas, attracting considerable attention. The core step of GCNs is the information-passing framework that considers all information from neighbors to the central vertex to be equally important. Such equal importance, however, is inadequate for scale-free networks, where hub vertices propagate more dominant information due to vertex imbalance. In this paper, we propose a novel centrality-based framework named CenGCN to address the inequality of information. This framework first quantifies the similarity between hub vertices and their neighbors by label propagation with hub vertices. Based on this similarity and centrality indices, the framework transforms the graph by increasing or decreasing the weights of edges connecting hub vertices and adding self-connections to vertices. In each non-output layer of the GCN, this framework uses a hub attention mechanism to assign new weights to connected non-hub vertices based on their common information with hub vertices. We present two variants CenGCN\_D and CenGCN\_E, based on degree centrality and eigenvector centrality, respectively. We also conduct comprehensive experiments, including vertex classification, link prediction, vertex clustering, and network visualization. The results demonstrate that the two variants significantly outperform state-of-the-art baselines.
* 16 pages, 8 figures
TERMinator: A Neural Framework for Structure-Based Protein Design using Tertiary Repeating Motifs
Apr 27, 2022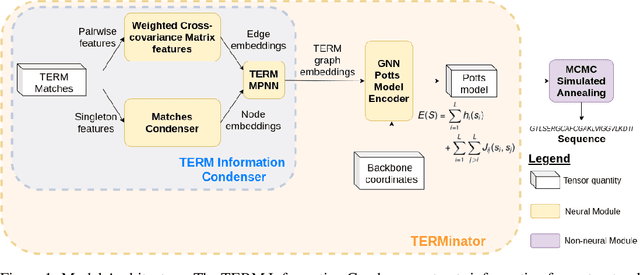
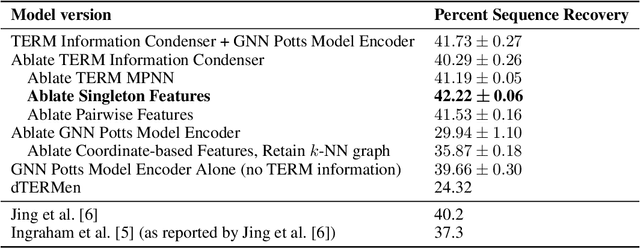
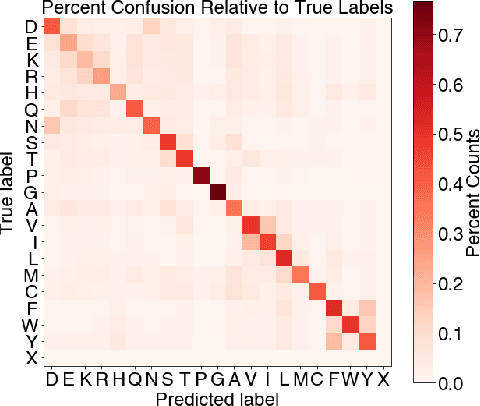

Computational protein design has the potential to deliver novel molecular structures, binders, and catalysts for myriad applications. Recent neural graph-based models that use backbone coordinate-derived features show exceptional performance on native sequence recovery tasks and are promising frameworks for design. A statistical framework for modeling protein sequence landscapes using Tertiary Motifs (TERMs), compact units of recurring structure in proteins, has also demonstrated good performance on protein design tasks. In this work, we investigate the use of TERM-derived data as features in neural protein design frameworks. Our graph-based architecture, TERMinator, incorporates TERM-based and coordinate-based information and outputs a Potts model over sequence space. TERMinator outperforms state-of-the-art models on native sequence recovery tasks, suggesting that utilizing TERM-based and coordinate-based features together is beneficial for protein design.
Learning Fair Representations via Rate-Distortion Maximization
Jan 31, 2022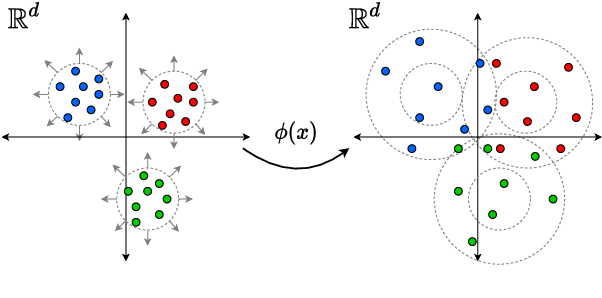
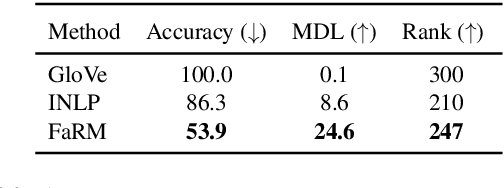
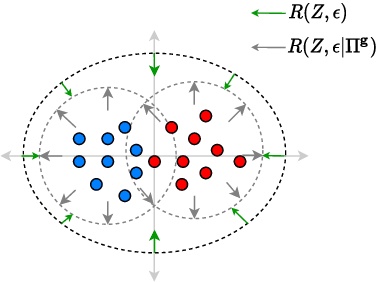
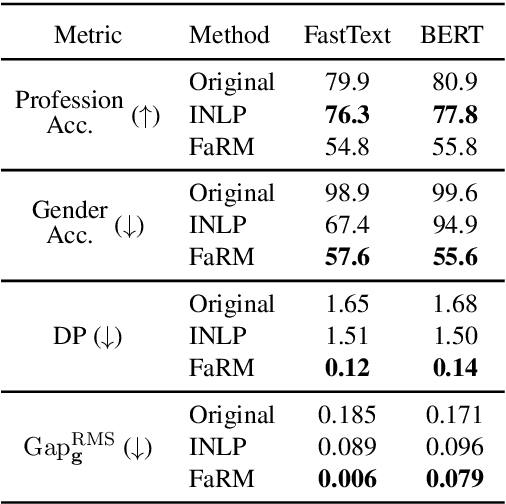
Text representations learned by machine learning models often encode undesirable demographic information of the user. Predictive models based on these representations can rely on such information resulting in biased decisions. We present a novel debiasing technique Fairness-aware Rate Maximization (FaRM), that removes demographic information by making representations of instances belonging to the same protected attribute class uncorrelated using the rate-distortion function. FaRM is able to debias representations with or without a target task at hand. FaRM can also be adapted to simultaneously remove information about multiple protected attributes. Empirical evaluations show that FaRM achieves state-of-the-art performance on several datasets, and learned representations leak significantly less protected attribute information against an attack by a non-linear probing network.
EnK: Encoding time-information in convolution
Jun 07, 2020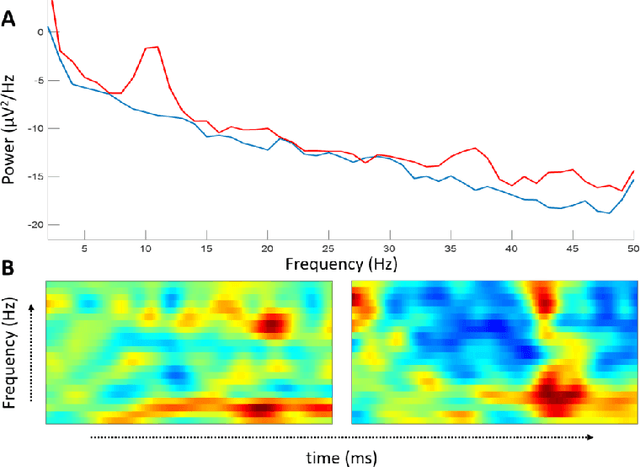

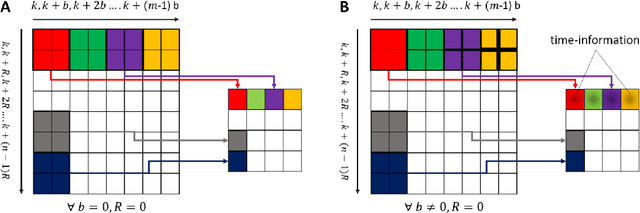
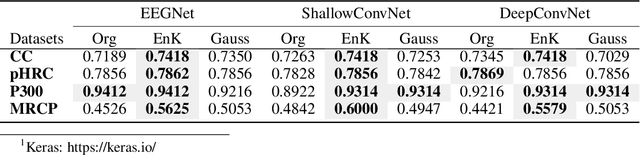
Recent development in deep learning techniques has attracted attention in decoding and classification in EEG signals. Despite several efforts utilizing different features of EEG signals, a significant research challenge is to use time-dependent features in combination with local and global features. There have been several efforts to remodel the deep learning convolution neural networks (CNNs) to capture time-dependency information by incorporating hand-crafted features, slicing the input data in a smaller time-windows, and recurrent convolution. However, these approaches partially solve the problem, but simultaneously hinder the CNN's capability to learn from unknown information that might be present in the data. To solve this, we have proposed a novel time encoding kernel (EnK) approach, which introduces the increasing time information during convolution operation in CNN. The encoded information by EnK lets CNN learn time-dependent features in-addition to local and global features. We performed extensive experiments on several EEG datasets: cognitive conflict (CC), physical-human robot collaboration (pHRC), P300 visual-evoked potentials, movement-related cortical potentials (MRCP). EnK outperforms the state-of-art by 12\% (F1 score). Moreover, the EnK approach required only one additional parameter to learn and can be applied to a virtually any CNN architectures with minimal efforts. These results support our methodology and show high potential to improve CNN performance in the context of time-series data in general.
Rethinking Bayesian Learning for Data Analysis: The Art of Prior and Inference in Sparsity-Aware Modeling
May 28, 2022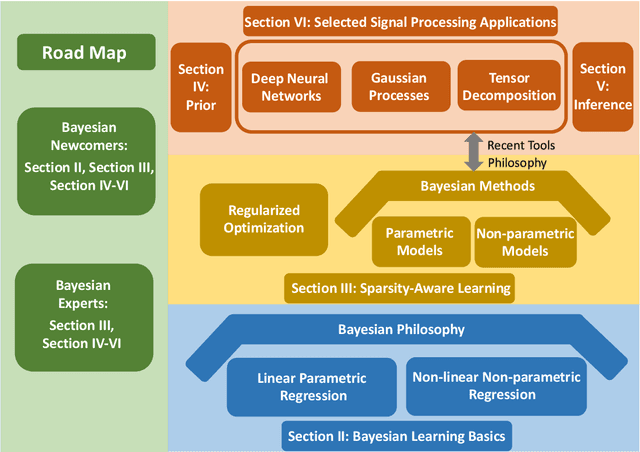
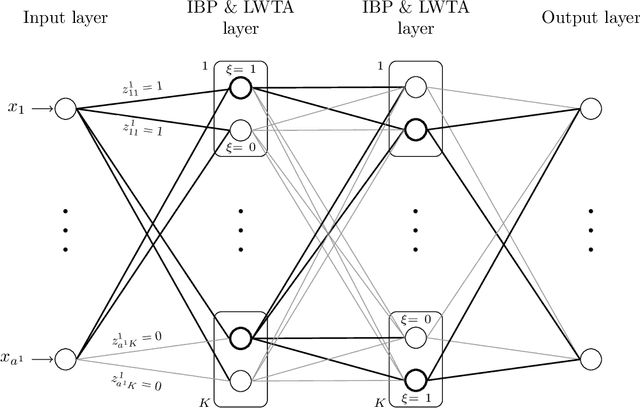
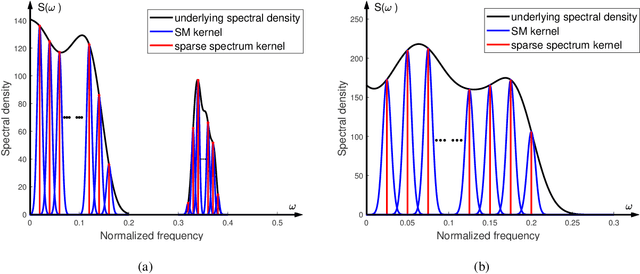
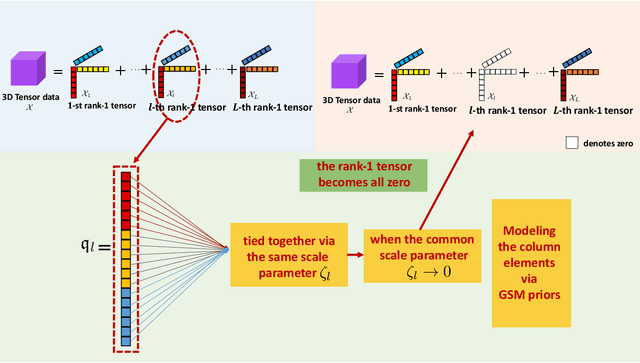
Sparse modeling for signal processing and machine learning has been at the focus of scientific research for over two decades. Among others, supervised sparsity-aware learning comprises two major paths paved by: a) discriminative methods and b) generative methods. The latter, more widely known as Bayesian methods, enable uncertainty evaluation w.r.t. the performed predictions. Furthermore, they can better exploit related prior information and naturally introduce robustness into the model, due to their unique capacity to marginalize out uncertainties related to the parameter estimates. Moreover, hyper-parameters associated with the adopted priors can be learnt via the training data. To implement sparsity-aware learning, the crucial point lies in the choice of the function regularizer for discriminative methods and the choice of the prior distribution for Bayesian learning. Over the last decade or so, due to the intense research on deep learning, emphasis has been put on discriminative techniques. However, a come back of Bayesian methods is taking place that sheds new light on the design of deep neural networks, which also establish firm links with Bayesian models and inspire new paths for unsupervised learning, such as Bayesian tensor decomposition. The goal of this article is two-fold. First, to review, in a unified way, some recent advances in incorporating sparsity-promoting priors into three highly popular data modeling tools, namely deep neural networks, Gaussian processes, and tensor decomposition. Second, to review their associated inference techniques from different aspects, including: evidence maximization via optimization and variational inference methods. Challenges such as small data dilemma, automatic model structure search, and natural prediction uncertainty evaluation are also discussed. Typical signal processing and machine learning tasks are demonstrated.
Unsupervised Extractive Opinion Summarization Using Sparse Coding
Mar 15, 2022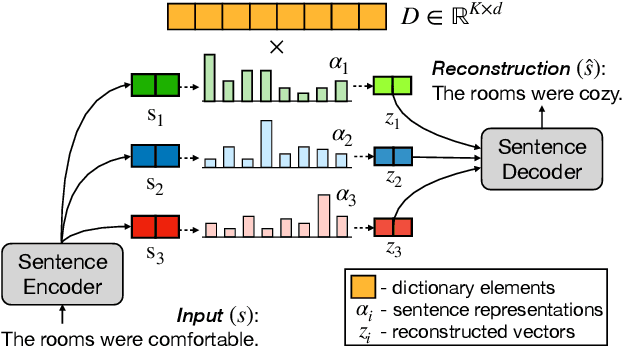
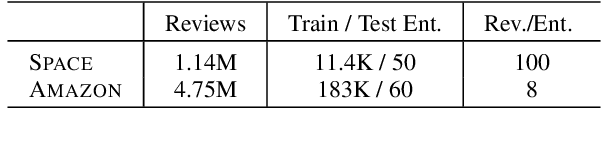
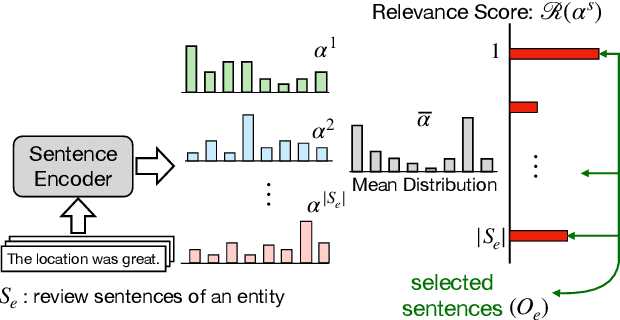
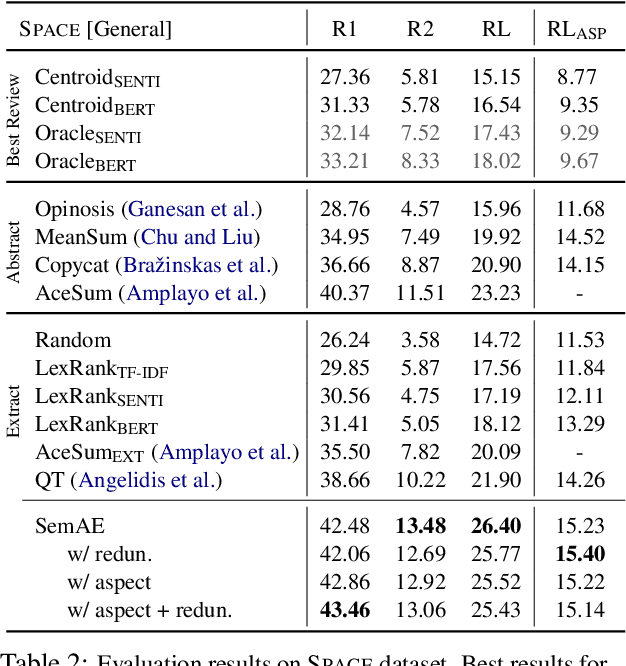
Opinion summarization is the task of automatically generating summaries that encapsulate information from multiple user reviews. We present Semantic Autoencoder (SemAE) to perform extractive opinion summarization in an unsupervised manner. SemAE uses dictionary learning to implicitly capture semantic information from the review and learns a latent representation of each sentence over semantic units. A semantic unit is supposed to capture an abstract semantic concept. Our extractive summarization algorithm leverages the representations to identify representative opinions among hundreds of reviews. SemAE is also able to perform controllable summarization to generate aspect-specific summaries. We report strong performance on SPACE and AMAZON datasets, and perform experiments to investigate the functioning of our model. Our code is publicly available at https://github.com/brcsomnath/SemAE.
Learning to generate line drawings that convey geometry and semantics
Mar 29, 2022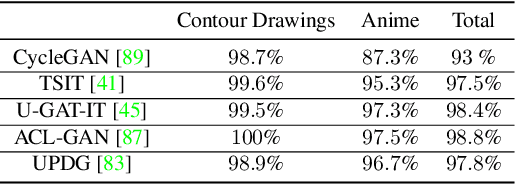
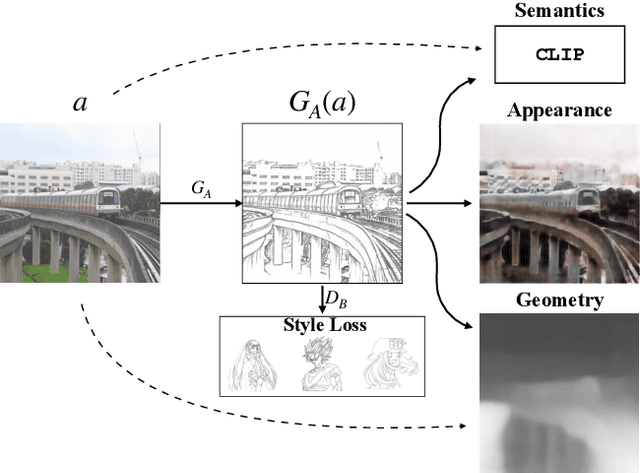
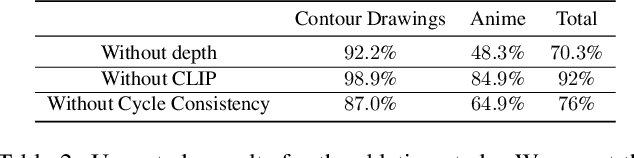

This paper presents an unpaired method for creating line drawings from photographs. Current methods often rely on high quality paired datasets to generate line drawings. However, these datasets often have limitations due to the subjects of the drawings belonging to a specific domain, or in the amount of data collected. Although recent work in unsupervised image-to-image translation has shown much progress, the latest methods still struggle to generate compelling line drawings. We observe that line drawings are encodings of scene information and seek to convey 3D shape and semantic meaning. We build these observations into a set of objectives and train an image translation to map photographs into line drawings. We introduce a geometry loss which predicts depth information from the image features of a line drawing, and a semantic loss which matches the CLIP features of a line drawing with its corresponding photograph. Our approach outperforms state-of-the-art unpaired image translation and line drawing generation methods on creating line drawings from arbitrary photographs. For code and demo visit our webpage carolineec.github.io/informative_drawings
Masked Summarization to Generate Factually Inconsistent Summaries for Improved Factual Consistency Checking
May 04, 2022
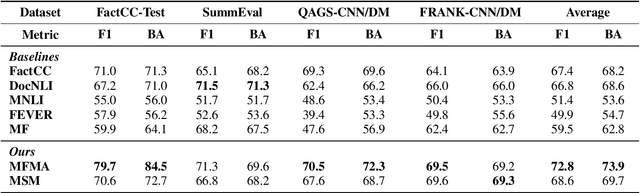
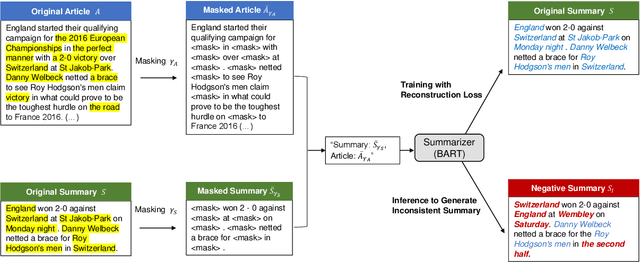
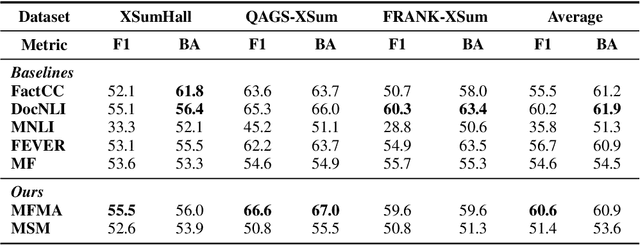
Despite the recent advances in abstractive summarization systems, it is still difficult to determine whether a generated summary is factual consistent with the source text. To this end, the latest approach is to train a factual consistency classifier on factually consistent and inconsistent summaries. Luckily, the former is readily available as reference summaries in existing summarization datasets. However, generating the latter remains a challenge, as they need to be factually inconsistent, yet closely relevant to the source text to be effective. In this paper, we propose to generate factually inconsistent summaries using source texts and reference summaries with key information masked. Experiments on seven benchmark datasets demonstrate that factual consistency classifiers trained on summaries generated using our method generally outperform existing models and show a competitive correlation with human judgments. We also analyze the characteristics of the summaries generated using our method. We will release the pre-trained model and the code at https://github.com/hwanheelee1993/MFMA.
Deep learning with photosensor timing information as a background rejection method for the Cherenkov Telescope Array
Mar 10, 2021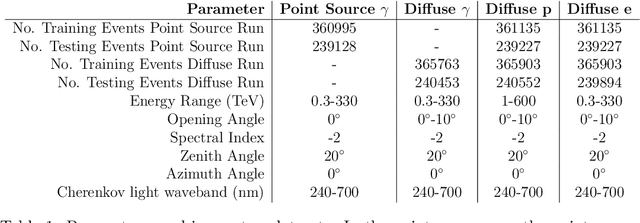
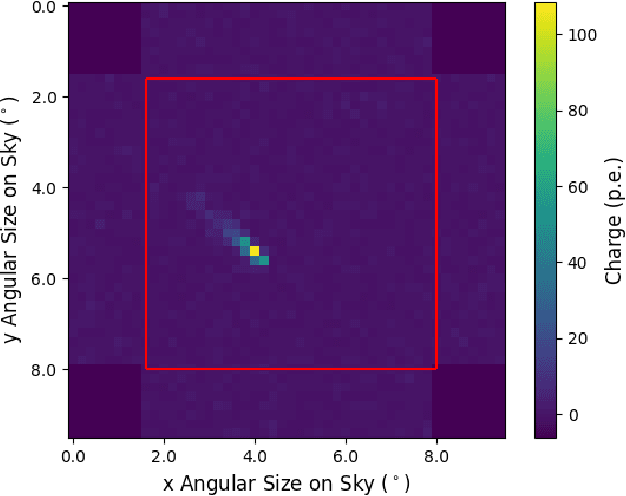
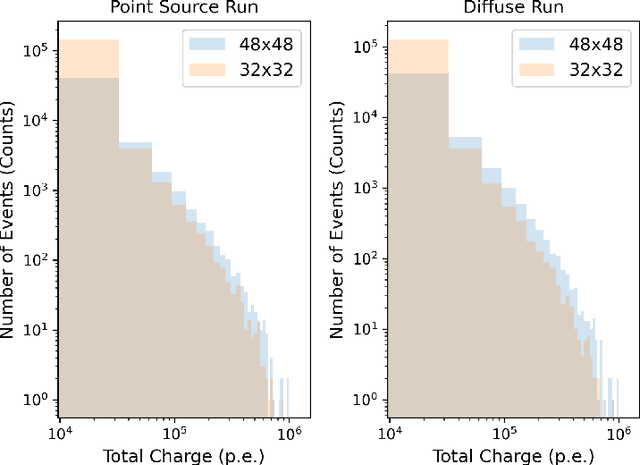

New deep learning techniques present promising new analysis methods for Imaging Atmospheric Cherenkov Telescopes (IACTs) such as the upcoming Cherenkov Telescope Array (CTA). In particular, the use of Convolutional Neural Networks (CNNs) could provide a direct event classification method that uses the entire information contained within the Cherenkov shower image, bypassing the need to Hillas parameterise the image and allowing fast processing of the data. Existing work in this field has utilised images of the integrated charge from IACT camera photomultipliers, however the majority of current and upcoming generation IACT cameras have the capacity to read out the entire photosensor waveform following a trigger. As the arrival times of Cherenkov photons from Extensive Air Showers (EAS) at the camera plane are dependent upon the altitude of their emission and the impact distance from the telescope, these waveforms contain information potentially useful for IACT event classification. In this test-of-concept simulation study, we investigate the potential for using these camera pixel waveforms with new deep learning techniques as a background rejection method, against both proton and electron induced EAS. We find that a means of utilising their information is to create a set of seven additional 2-dimensional pixel maps of waveform parameters, to be fed into the machine learning algorithm along with the integrated charge image. Whilst we ultimately find that the only classification power against electrons is based upon event direction, methods based upon timing information appear to out-perform similar charge based methods for gamma/hadron separation. We also review existing methods of event classifications using a combination of deep learning and timing information in other astroparticle physics experiments.
Comparison research on binary relations based on transitive degrees and cluster degrees
Jan 25, 2022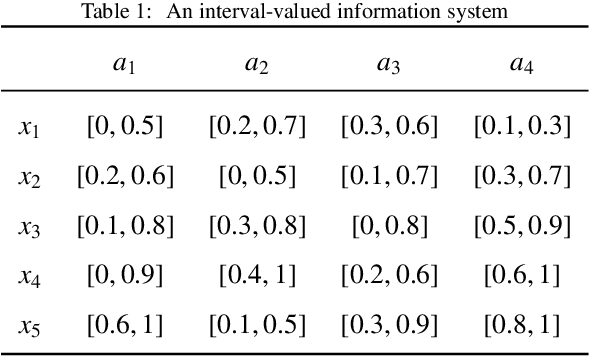
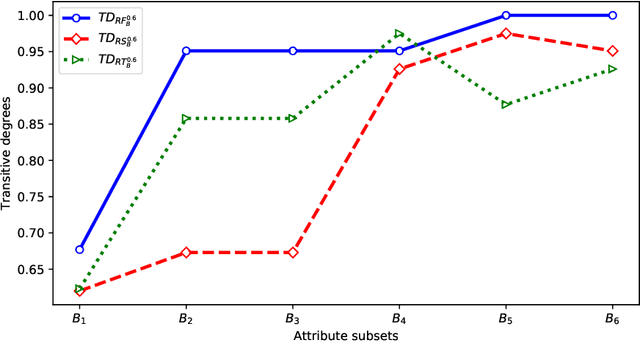
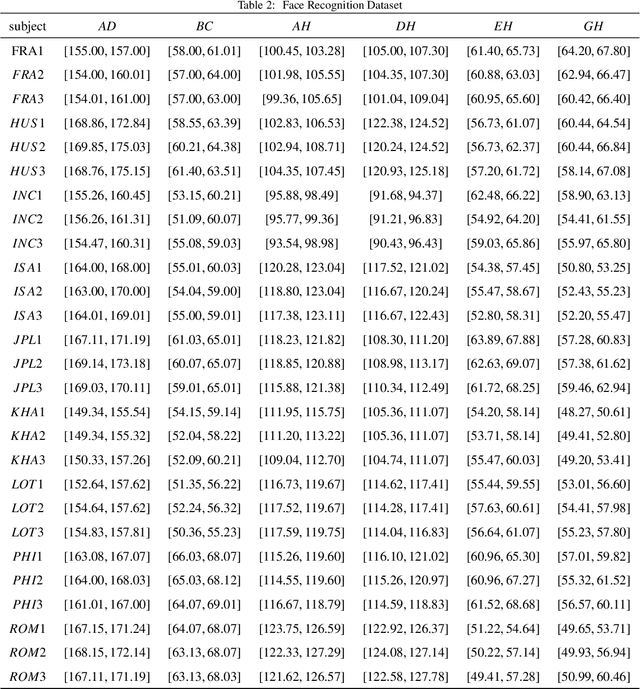
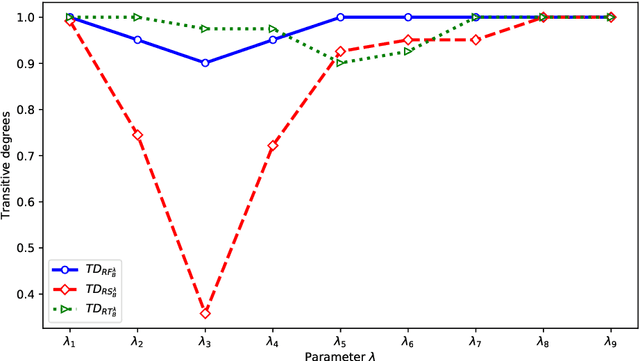
Interval-valued information systems are generalized models of single-valued information systems. By rough set approach, interval-valued information systems have been extensively studied. Authors could establish many binary relations from the same interval-valued information system. In this paper, we do some researches on comparing these binary relations so as to provide numerical scales for choosing suitable relations in dealing with interval-valued information systems. Firstly, based on similarity degrees, we compare the most common three binary relations induced from the same interval-valued information system. Secondly, we propose the concepts of transitive degree and cluster degree, and investigate their properties. Finally, we provide some methods to compare binary relations by means of the transitive degree and the cluster degree. Furthermore, we use these methods to analyze the most common three relations induced from Face Recognition Dataset, and obtain that $RF_{B} ^{\lambda}$ is a good choice when we deal with an interval-valued information system by means of rough set approach.