 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AI Annotated Recommendations in an Efficient Visual Learning Environment with Emphasis on YouTube (AI-EVL)
Mar 10, 2022
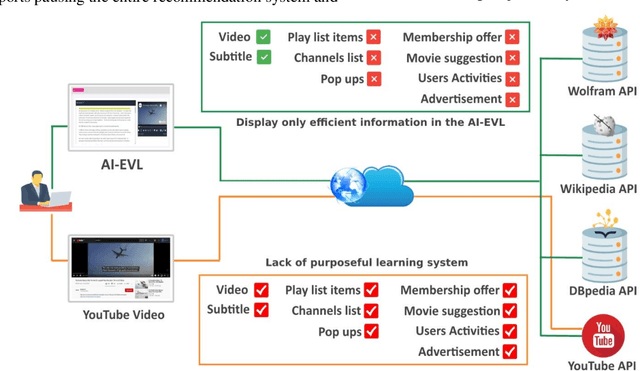
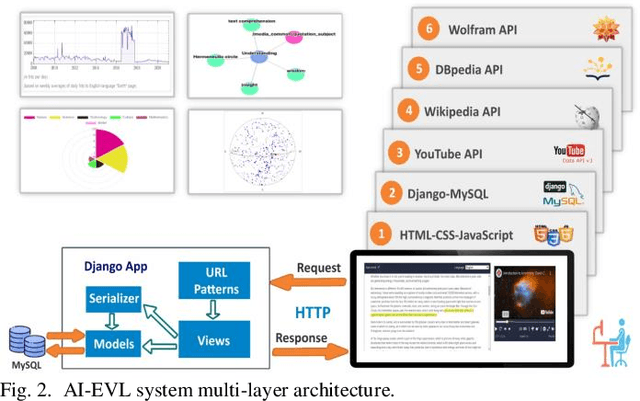
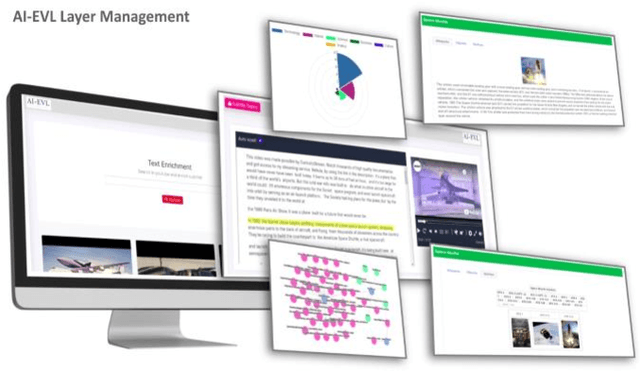
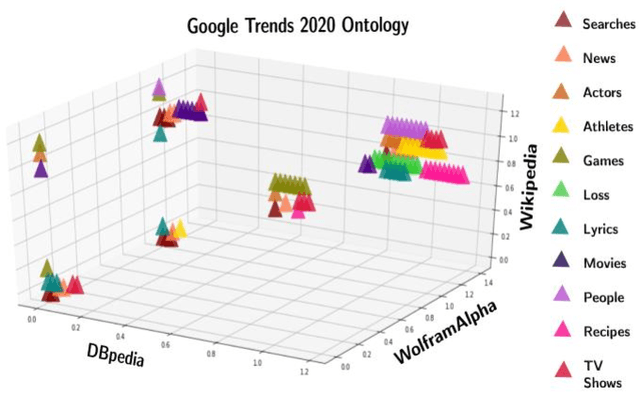
In this article, we create a system called AI-EVL. This is an annotated-based learning system. We extend AI to learning experience. If a user from the main YouTube page browses YouTube videos and a user from the AI-EVL system does the same, the amount of traffic used will be much less. It is due to ignoring unwanted contents which indicates a reduction in bandwidth usage too. This system is designed to be embedded with online learning tools and platforms to enrich their curriculum. In evaluating the system using Google 2020 trend data, we were able to extract rich ontological information for each data. Of the data collected, 34.86% belong to wolfram, 30.41% to DBpedia, and 34.73% to Wikipedia. The video subtitle information is displayed interactively and functionally to the user over time as the video is played. This effective visual learning system, due to the unique features, prevents the user's distraction and makes learning more focused. The information about the subtitle text is displayed in multiple layers including AI-annotated topics, Wikipedia/DBpedia, and Wolfram enriched texts via interactive and visual widgets.
X-Trans2Cap: Cross-Modal Knowledge Transfer using Transformer for 3D Dense Captioning
Apr 06, 2022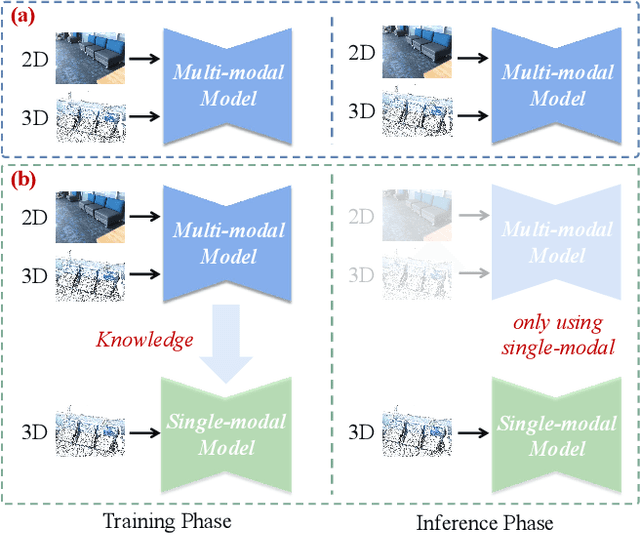
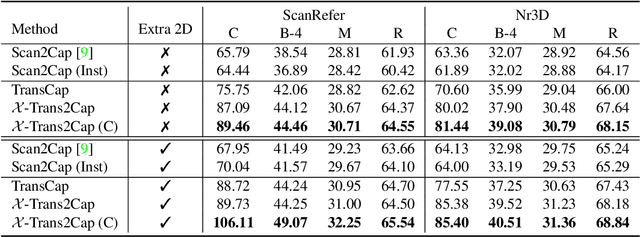
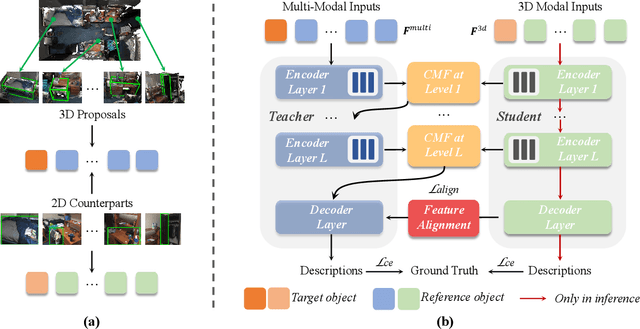

3D dense captioning aims to describe individual objects by natural language in 3D scenes, where 3D scenes are usually represented as RGB-D scans or point clouds. However, only exploiting single modal information, e.g., point cloud, previous approaches fail to produce faithful descriptions. Though aggregating 2D features into point clouds may be beneficial, it introduces an extra computational burden, especially in inference phases. In this study, we investigate a cross-modal knowledge transfer using Transformer for 3D dense captioning, X-Trans2Cap, to effectively boost the performance of single-modal 3D caption through knowledge distillation using a teacher-student framework. In practice, during the training phase, the teacher network exploits auxiliary 2D modality and guides the student network that only takes point clouds as input through the feature consistency constraints. Owing to the well-designed cross-modal feature fusion module and the feature alignment in the training phase, X-Trans2Cap acquires rich appearance information embedded in 2D images with ease. Thus, a more faithful caption can be generated only using point clouds during the inference. Qualitative and quantitative results confirm that X-Trans2Cap outperforms previous state-of-the-art by a large margin, i.e., about +21 and about +16 absolute CIDEr score on ScanRefer and Nr3D datasets, respectively.
ActorRL: A Novel Distributed Reinforcement Learning for Autonomous Intersection Management
May 05, 2022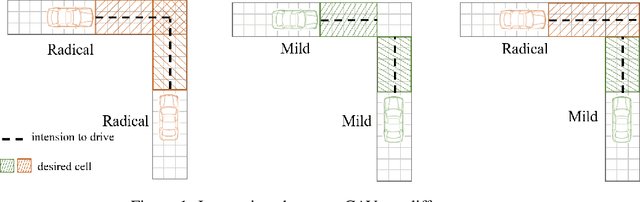

As an emerging tendency of future transportation, Connected Autonomous Vehicle (CAV) has the potential to improve traffic capacity and safety at intersections. In autonomous intersection management (AIM), distributed scheduling algorithm formulates the interactions among traffic participants as multi-agent problem with information exchange and behavioral cooperation. Deep Reinforcement Learning (DRL), as an approach obtaining satisfying performance in many domains, has been brought in AIM recently. Attempts to overcome the challenges of curse of dimensionality and instability in multi-agent DRL, we propose a novel DRL framework for AIM problem, ActorRL, where actor allocation mechanism attaches multiple roles with different personalities to CAVs under global observation, including radical actor, conservative actor, safety-first actor, etc. The actor shares behavioral policies with collective memories from CAVs it is assigned to, playing the role of "navigator" at AIM. In experiments, we compares the proposed method with several widely used scheduling methods and distributed DRL without actor allocation, the results shows better performance over benchmarks.
Modulation and Classification of Mixed Signals Based on Deep Learning
May 20, 2022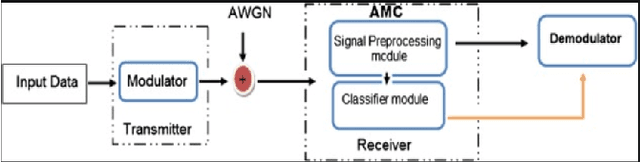
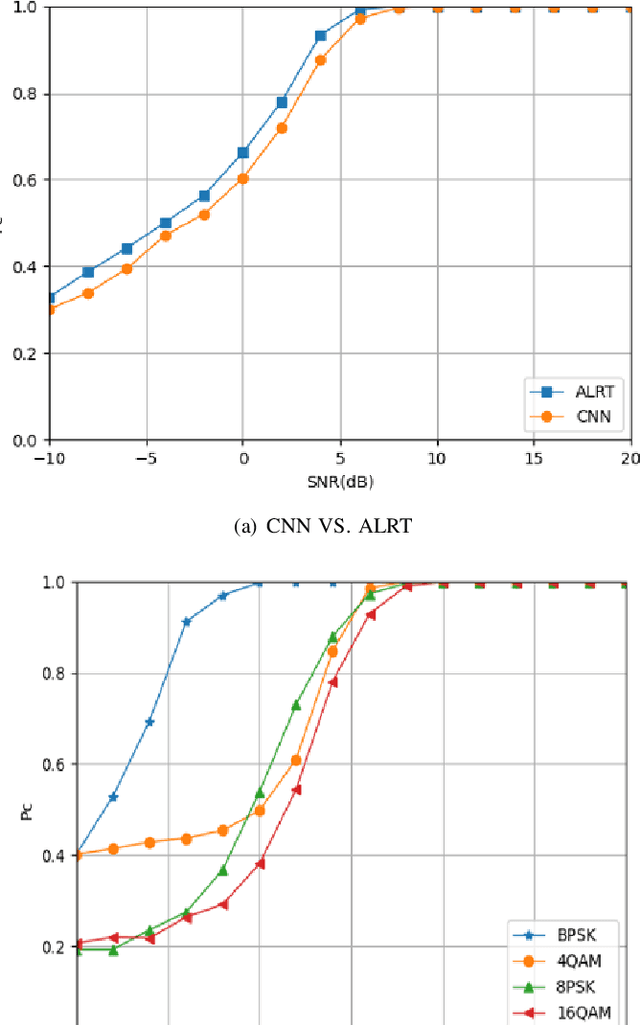
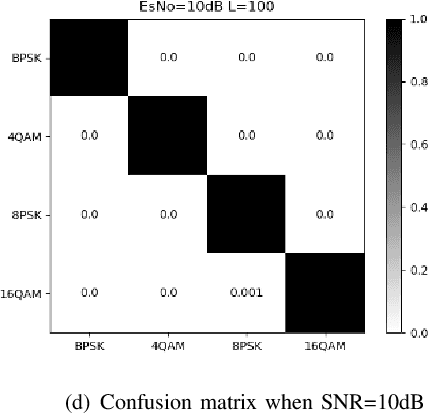
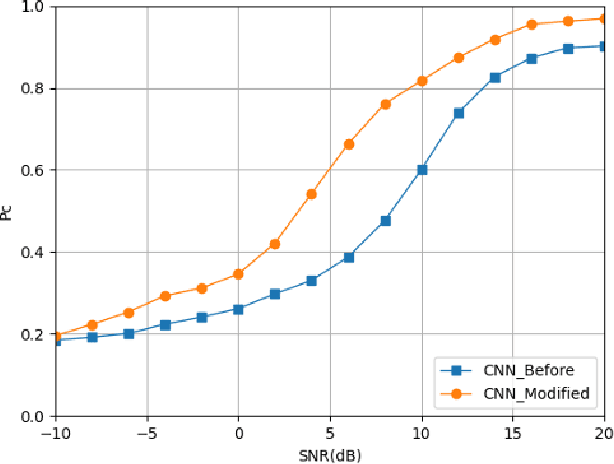
With the rapid development of information nowadays, spectrum resources are becoming more and more scarce, leading to a shift in the research direction from the modulation classification of a single signal to the modulation classification of multiple signals on the same channel. Therefore, the emergence of an effective mixed signals automatic modulation classification technology have important significance. Considering that NOMA technology has deeper requirements for the modulation classification of mixed signals under different power, this paper mainly introduces and uses a variety of deep learning networks to classify such mixed signals. First, the modulation classification of a single signal based on the existing CNN model is reproduced. We then develop new methods to improve the basic CNN structure and apply it to the modulation classification of mixed signals. Meanwhile, the effects of the number of training sets, the type of training sets and the training methods on the recognition accuracy of mixed signals are studied. Second, we investigate some deep learning models based on CNN (ResNet34, hierarchical structure) and other deep learning models (LSTM, CLDNN). It can be seen although the time and space complexity of these algorithms have increased, different deep learning models have different effects on the modulation classification problem of mixed signals at different power. Generally speaking, higher accuracy gains can be achieved.
Introduction of a tree-based technique for efficient and real-time label retrieval in the object tracking system
May 31, 2022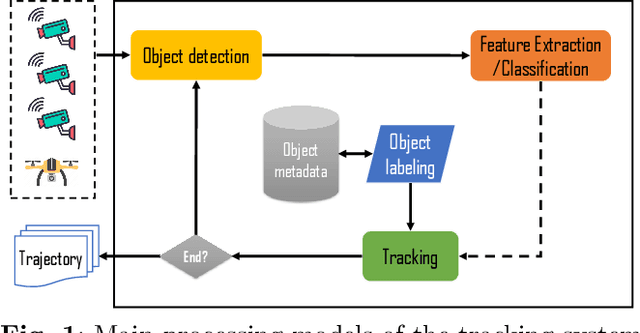
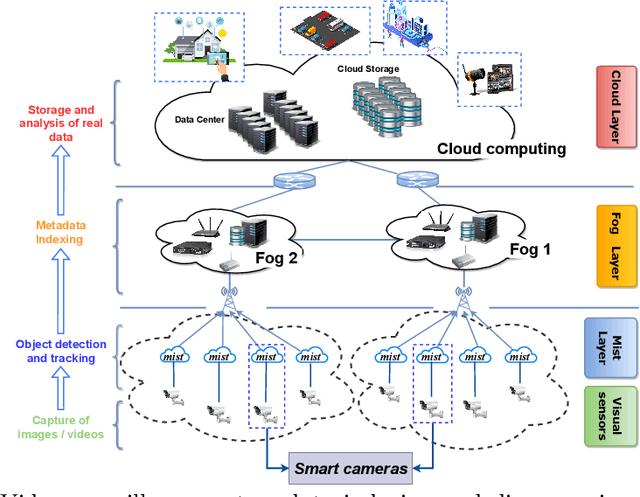
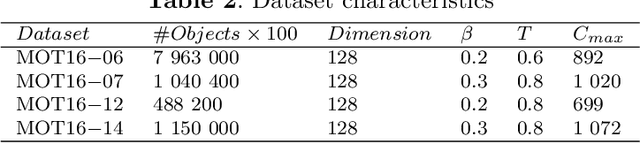
This paper addresses the issue of the real-time tracking quality of moving objects in large-scale video surveillance systems. During the tracking process, the system assigns an identifier or label to each tracked object to distinguish it from other objects. In such a mission, it is essential to keep this identifier for the same objects, whatever the area, the time of their appearance, or the detecting camera. This is to conserve as much information about the tracking object as possible, decrease the number of ID switching (ID-Sw), and increase the quality of object tracking. To accomplish object labeling, a massive amount of data collected by the cameras must be searched to retrieve the most similar (nearest neighbor) object identifier. Although this task is simple, it becomes very complex in large-scale video surveillance networks, where the data becomes very large. In this case, the label retrieval time increases significantly with this increase, which negatively affects the performance of the real-time tracking system. To avoid such problems, we propose a new solution to automatically label multiple objects for efficient real-time tracking using the indexing mechanism. This mechanism organizes the metadata of the objects extracted during the detection and tracking phase in an Adaptive BCCF-tree. The main advantage of this structure is: its ability to index massive metadata generated by multi-cameras, its logarithmic search complexity, which implicitly reduces the search response time, and its quality of research results, which ensure coherent labeling of the tracked objects. The system load is distributed through a new Internet of Video Things infrastructure-based architecture to improve data processing and real-time object tracking performance. The experimental evaluation was conducted on a publicly available dataset generated by multi-camera containing different crowd activities.
MAP-Gen: An Automated 3D-Box Annotation Flow with Multimodal Attention Point Generator
Mar 29, 2022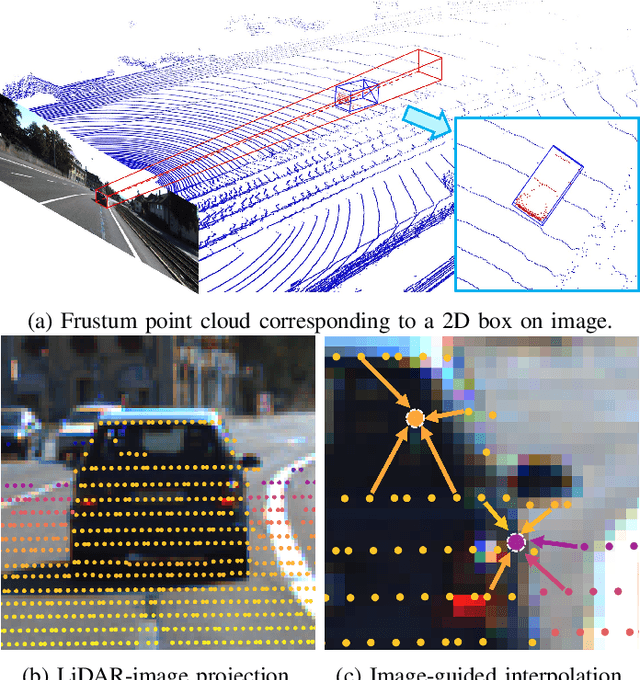
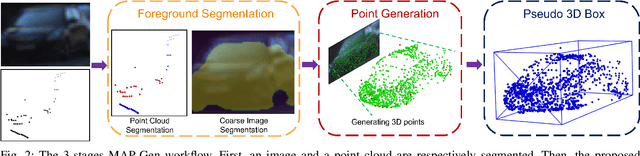
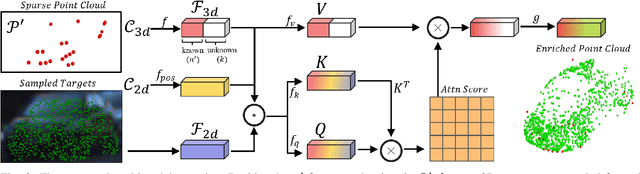
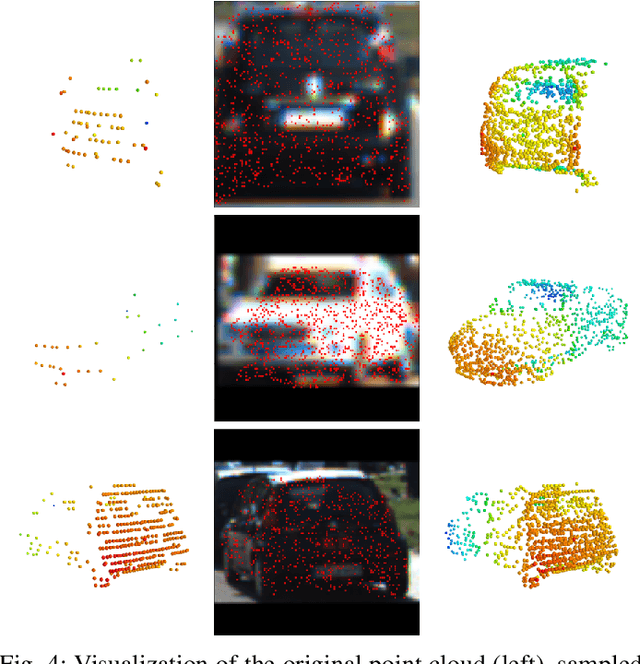
Manually annotating 3D point clouds is laborious and costly, limiting the training data preparation for deep learning in real-world object detection. While a few previous studies tried to automatically generate 3D bounding boxes from weak labels such as 2D boxes, the quality is sub-optimal compared to human annotators. This work proposes a novel autolabeler, called multimodal attention point generator (MAP-Gen), that generates high-quality 3D labels from weak 2D boxes. It leverages dense image information to tackle the sparsity issue of 3D point clouds, thus improving label quality. For each 2D pixel, MAP-Gen predicts its corresponding 3D coordinates by referencing context points based on their 2D semantic or geometric relationships. The generated 3D points densify the original sparse point clouds, followed by an encoder to regress 3D bounding boxes. Using MAP-Gen, object detection networks that are weakly supervised by 2D boxes can achieve 94~99% performance of those fully supervised by 3D annotations. It is hopeful this newly proposed MAP-Gen autolabeling flow can shed new light on utilizing multimodal information for enriching sparse point clouds.
Beyond Bounding Box: Multimodal Knowledge Learning for Object Detection
May 09, 2022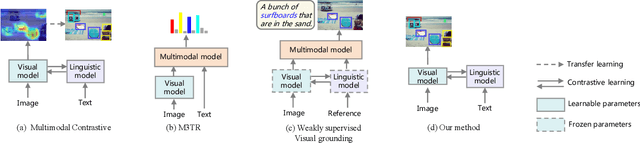
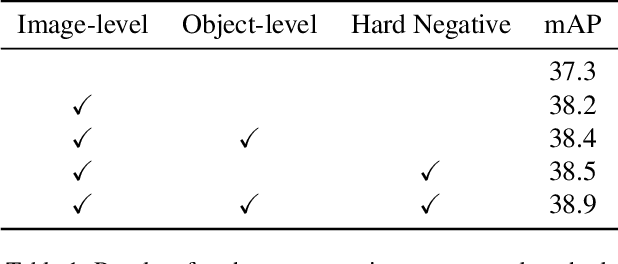
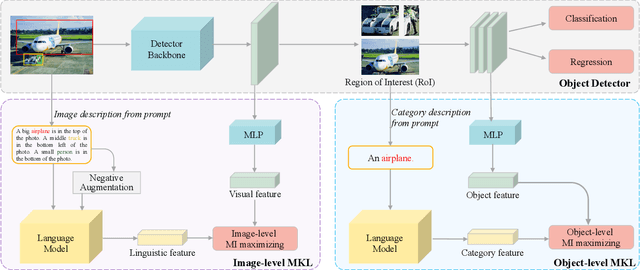
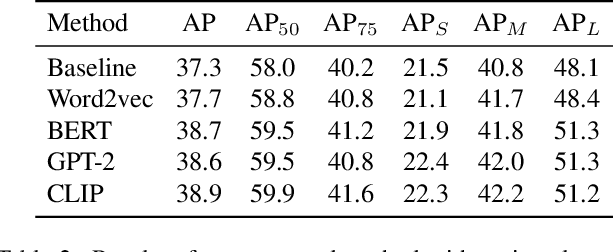
Multimodal supervision has achieved promising results in many visual language understanding tasks, where the language plays an essential role as a hint or context for recognizing and locating instances. However, due to the defects of the human-annotated language corpus, multimodal supervision remains unexplored in fully supervised object detection scenarios. In this paper, we take advantage of language prompt to introduce effective and unbiased linguistic supervision into object detection, and propose a new mechanism called multimodal knowledge learning (\textbf{MKL}), which is required to learn knowledge from language supervision. Specifically, we design prompts and fill them with the bounding box annotations to generate descriptions containing extensive hints and context for instances recognition and localization. The knowledge from language is then distilled into the detection model via maximizing cross-modal mutual information in both image- and object-level. Moreover, the generated descriptions are manipulated to produce hard negatives to further boost the detector performance. Extensive experiments demonstrate that the proposed method yields a consistent performance gain by 1.6\% $\sim$ 2.1\% and achieves state-of-the-art on MS-COCO and OpenImages datasets.
COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List
Apr 15, 2021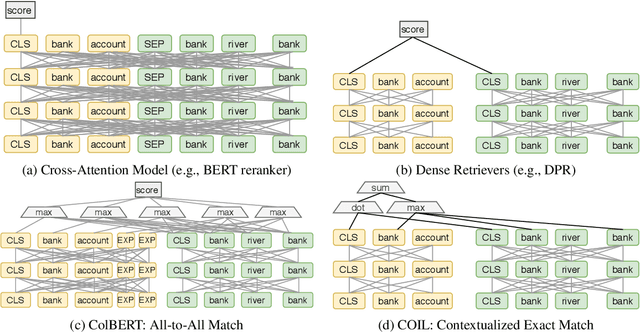
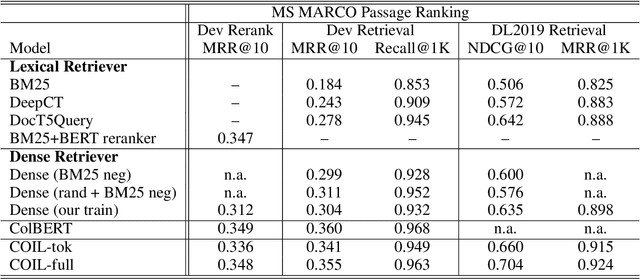
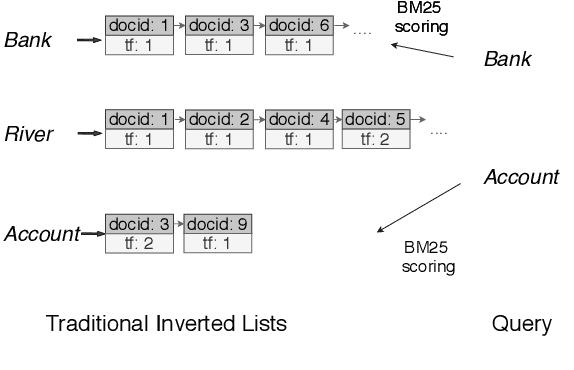
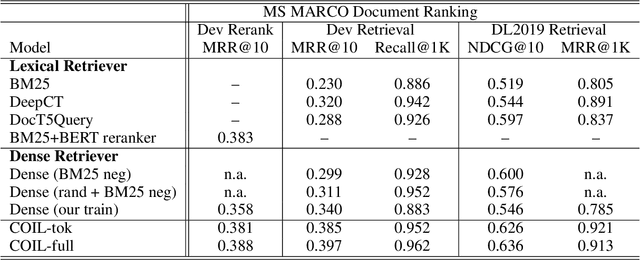
Classical information retrieval systems such as BM25 rely on exact lexical match and carry out search efficiently with inverted list index. Recent neural IR models shifts towards soft semantic matching all query document terms, but they lose the computation efficiency of exact match systems. This paper presents COIL, a contextualized exact match retrieval architecture that brings semantic lexical matching. COIL scoring is based on overlapping query document tokens' contextualized representations. The new architecture stores contextualized token representations in inverted lists, bringing together the efficiency of exact match and the representation power of deep language models. Our experimental results show COIL outperforms classical lexical retrievers and state-of-the-art deep LM retrievers with similar or smaller latency.
Visualization of Decision Trees based on General Line Coordinates to Support Explainable Models
May 09, 2022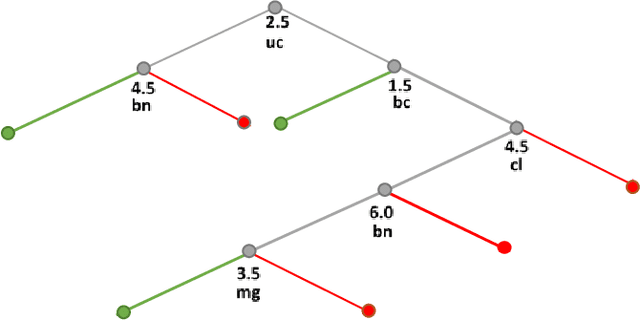
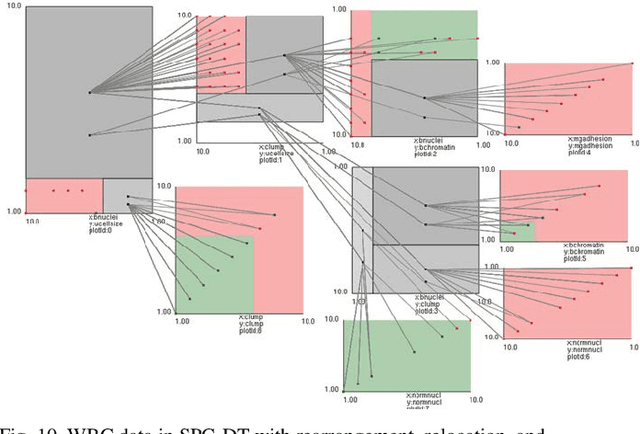

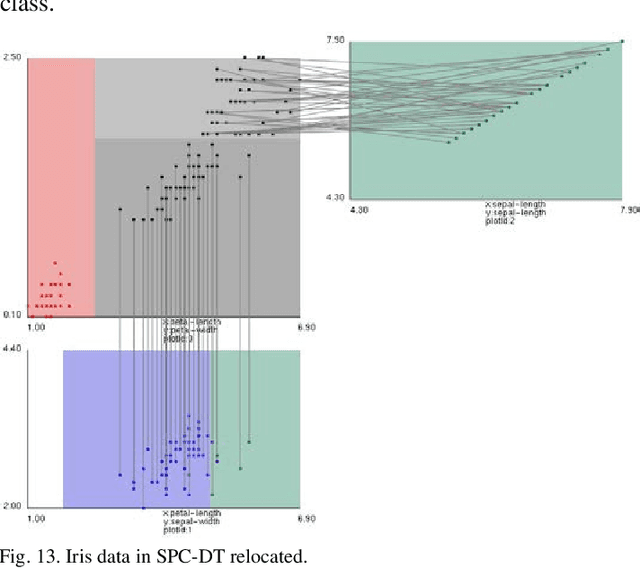
Visualization of Machine Learning (ML) models is an important part of the ML process to enhance the interpretability and prediction accuracy of the ML models. This paper proposes a new method SPC-DT to visualize the Decision Tree (DT) as interpretable models. These methods use a version of General Line Coordinates called Shifted Paired Coordinates (SPC). In SPC, each n-D point is visualized in a set of shifted pairs of 2-D Cartesian coordinates as a directed graph. The new method expands and complements the capabilities of existing methods, to visualize DT models. It shows: (1) relations between attributes, (2) individual cases relative to the DT structure, (3) data flow in the DT, (4) how tight each split is to thresholds in the DT nodes, and (5) the density of cases in parts of the n-D space. This information is important for domain experts for evaluating and improving the DT models, including avoiding overgeneralization and overfitting of models, along with their performance. The benefits of the methods are demonstrated in the case studies, using three real datasets.
EnK: Encoding time-information in convolution
Jun 07, 2020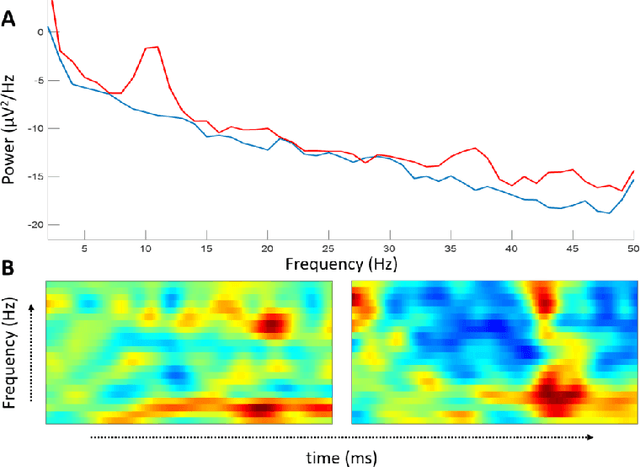

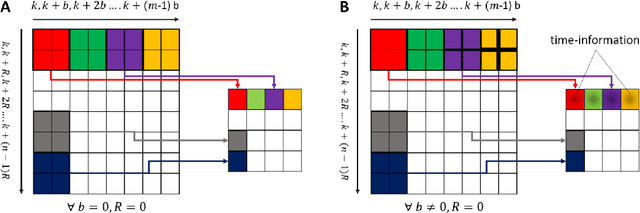
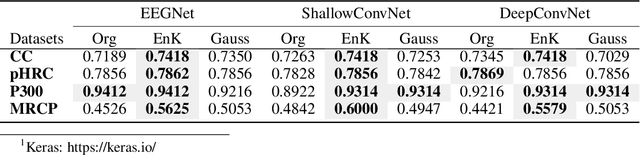
Recent development in deep learning techniques has attracted attention in decoding and classification in EEG signals. Despite several efforts utilizing different features of EEG signals, a significant research challenge is to use time-dependent features in combination with local and global features. There have been several efforts to remodel the deep learning convolution neural networks (CNNs) to capture time-dependency information by incorporating hand-crafted features, slicing the input data in a smaller time-windows, and recurrent convolution. However, these approaches partially solve the problem, but simultaneously hinder the CNN's capability to learn from unknown information that might be present in the data. To solve this, we have proposed a novel time encoding kernel (EnK) approach, which introduces the increasing time information during convolution operation in CNN. The encoded information by EnK lets CNN learn time-dependent features in-addition to local and global features. We performed extensive experiments on several EEG datasets: cognitive conflict (CC), physical-human robot collaboration (pHRC), P300 visual-evoked potentials, movement-related cortical potentials (MRCP). EnK outperforms the state-of-art by 12\% (F1 score). Moreover, the EnK approach required only one additional parameter to learn and can be applied to a virtually any CNN architectures with minimal efforts. These results support our methodology and show high potential to improve CNN performance in the context of time-series data in general.