 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigating Neural Architectures by Synthetic Dataset Design
Apr 23, 2022

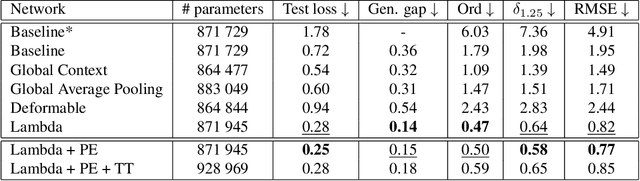

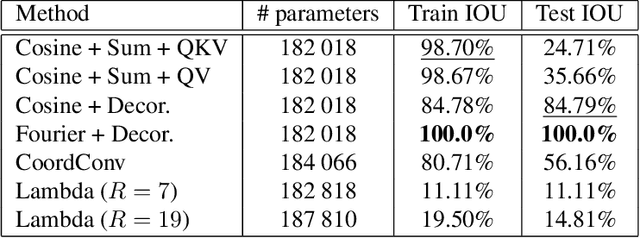
Recent years have seen the emergence of many new neural network structures (architectures and layers). To solve a given task, a network requires a certain set of abilities reflected in its structure. The required abilities depend on each task. There is so far no systematic study of the real capacities of the proposed neural structures. The question of what each structure can and cannot achieve is only partially answered by its performance on common benchmarks. Indeed, natural data contain complex unknown statistical cues. It is therefore impossible to know what cues a given neural structure is taking advantage of in such data. In this work, we sketch a methodology to measure the effect of each structure on a network's ability, by designing ad hoc synthetic datasets. Each dataset is tailored to assess a given ability and is reduced to its simplest form: each input contains exactly the amount of information needed to solve the task. We illustrate our methodology by building three datasets to evaluate each of the three following network properties: a) the ability to link local cues to distant inferences, b) the translation covariance and c) the ability to group pixels with the same characteristics and share information among them. Using a first simplified depth estimation dataset, we pinpoint a serious nonlocal deficit of the U-Net. We then evaluate how to resolve this limitation by embedding its structure with nonlocal layers, which allow computing complex features with long-range dependencies. Using a second dataset, we compare different positional encoding methods and use the results to further improve the U-Net on the depth estimation task. The third introduced dataset serves to demonstrate the need for self-attention-like mechanisms for resolving more realistic depth estimation tasks.
Coarse-to-Fine Feature Mining for Video Semantic Segmentation
Apr 07, 2022
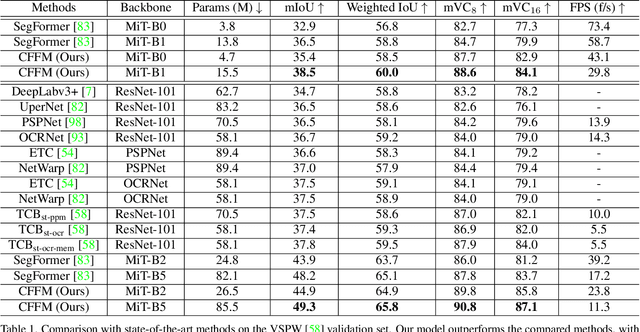
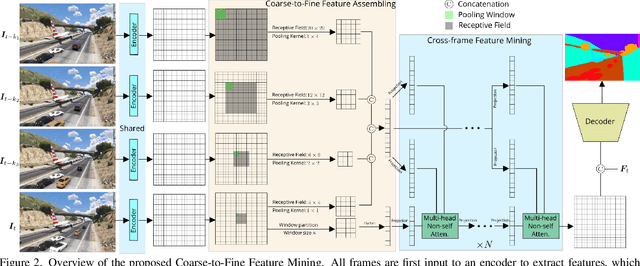
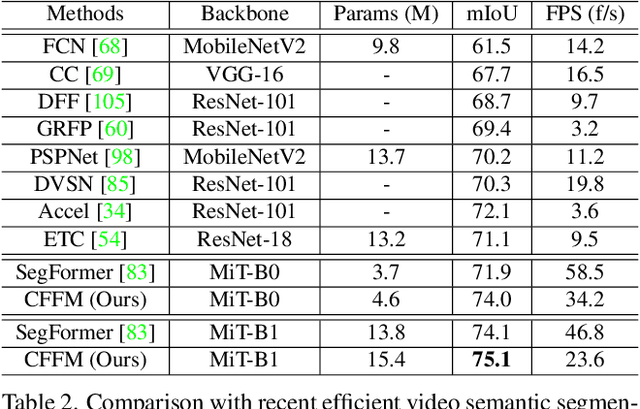
The contextual information plays a core role in semantic segmentation. As for video semantic segmentation, the contexts include static contexts and motional contexts, corresponding to static content and moving content in a video clip, respectively. The static contexts are well exploited in image semantic segmentation by learning multi-scale and global/long-range features. The motional contexts are studied in previous video semantic segmentation. However, there is no research about how to simultaneously learn static and motional contexts which are highly correlated and complementary to each other. To address this problem, we propose a Coarse-to-Fine Feature Mining (CFFM) technique to learn a unified presentation of static contexts and motional contexts. This technique consists of two parts: coarse-to-fine feature assembling and cross-frame feature mining. The former operation prepares data for further processing, enabling the subsequent joint learning of static and motional contexts. The latter operation mines useful information/contexts from the sequential frames to enhance the video contexts of the features of the target frame. The enhanced features can be directly applied for the final prediction. Experimental results on popular benchmarks demonstrate that the proposed CFFM performs favorably against state-of-the-art methods for video semantic segmentation. Our implementation is available at https://github.com/GuoleiSun/VSS-CFFM
TSAM: A Two-Stream Attention Model for Causal Emotion Entailment
Mar 02, 2022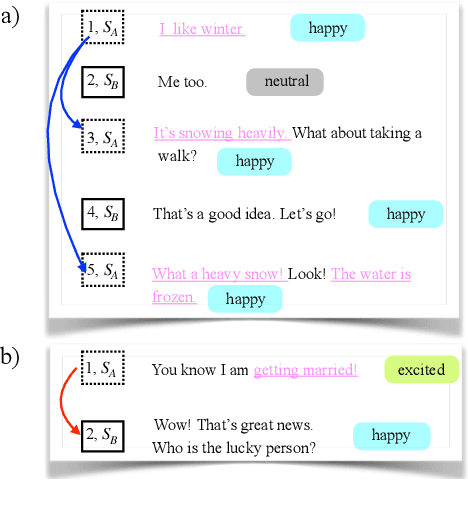
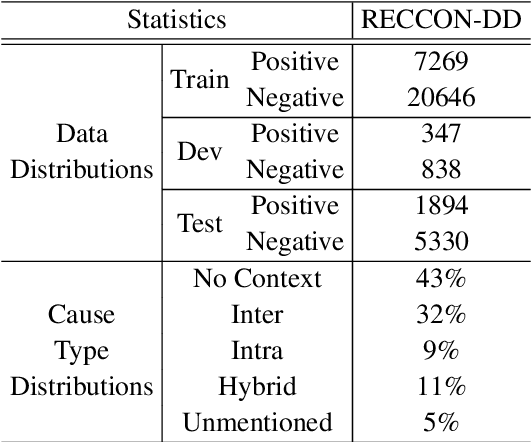
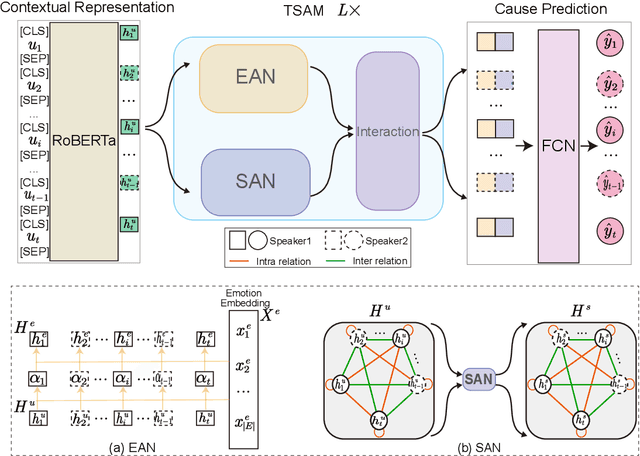
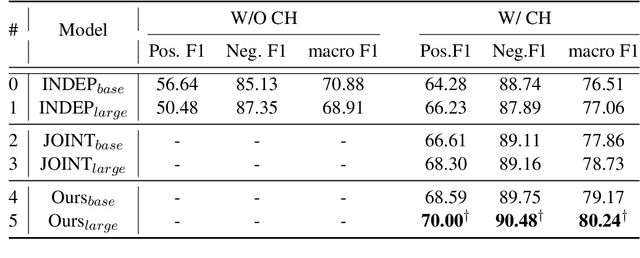
Causal Emotion Entailment (CEE) aims to discover the potential causes behind an emotion in a conversational utterance. Previous works formalize CEE as independent utterance pair classification problems, with emotion and speaker information neglected. From a new perspective, this paper considers CEE in a joint framework. We classify multiple utterances synchronously to capture the correlations between utterances in a global view and propose a Two-Stream Attention Model (TSAM) to effectively model the speaker's emotional influences in the conversational history. Specifically, the TSAM comprises three modules: Emotion Attention Network (EAN), Speaker Attention Network (SAN), and interaction module. The EAN and SAN incorporate emotion and speaker information in parallel, and the subsequent interaction module effectively interchanges relevant information between the EAN and SAN via a mutual BiAffine transformation. Experimental results on a benchmark dataset demonstrate that our model achieves new State-Of-The-Art (SOTA) performance and outperforms baselines remarkably.
Variance Reduction based Partial Trajectory Reuse to Accelerate Policy Gradient Optimization
May 06, 2022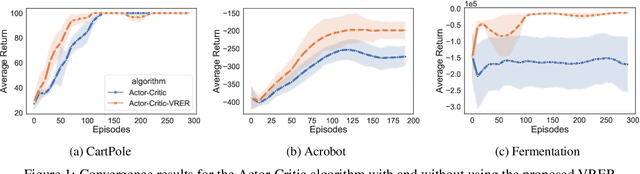
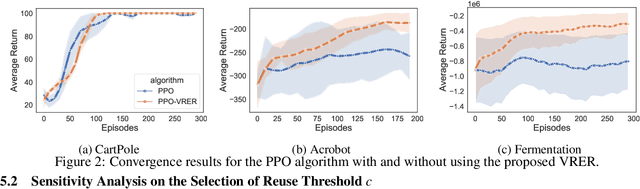
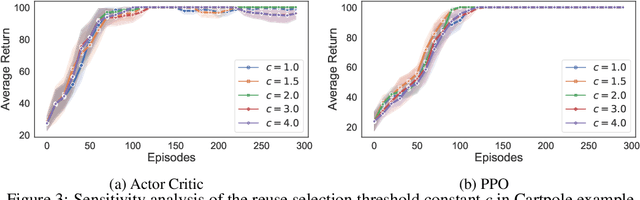
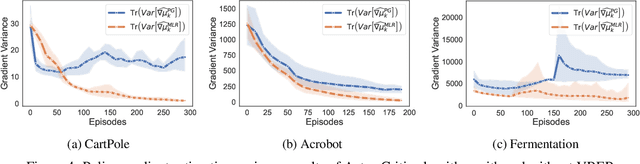
We extend the idea underlying the success of green simulation assisted policy gradient (GS-PG) to partial historical trajectory reuse for infinite-horizon Markov Decision Processes (MDP). The existing GS-PG method was designed to learn from complete episodes or process trajectories, which limits its applicability to low-data environment and online process control. In this paper, the mixture likelihood ratio (MLR) based policy gradient estimation is used to leverage the information from historical state decision transitions generated under different behavioral policies. We propose a variance reduction experience replay (VRER) approach that can intelligently select and reuse most relevant transition observations, improve the policy gradient estimation accuracy, and accelerate the learning of optimal policy. Then we create a process control strategy by incorporating VRER with the state-of-the-art step-based policy optimization approaches such as actor-critic method and proximal policy optimizations. The empirical study demonstrates that the proposed policy gradient methodology can significantly outperform the existing policy optimization approaches.
Multi-Agent Reinforcement Learning for Traffic Signal Control through Universal Communication Method
Apr 26, 2022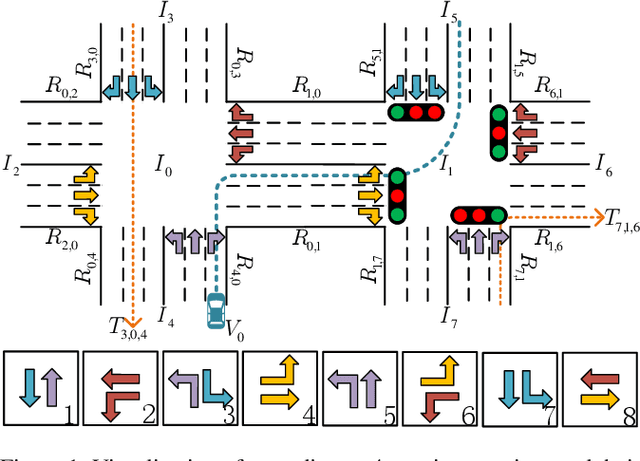
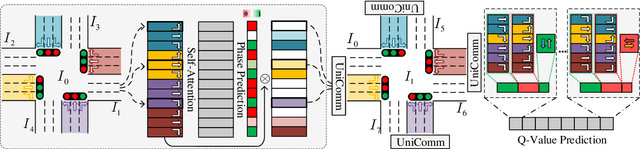
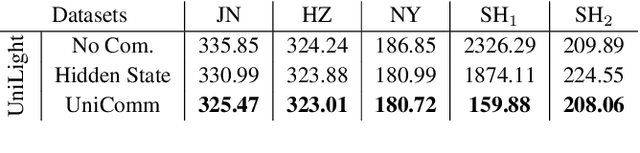
How to coordinate the communication among intersections effectively in real complex traffic scenarios with multi-intersection is challenging. Existing approaches only enable the communication in a heuristic manner without considering the content/importance of information to be shared. In this paper, we propose a universal communication form UniComm between intersections. UniComm embeds massive observations collected at one agent into crucial predictions of their impact on its neighbors, which improves the communication efficiency and is universal across existing methods. We also propose a concise network UniLight to make full use of communications enabled by UniComm. Experimental results on real datasets demonstrate that UniComm universally improves the performance of existing state-of-the-art methods, and UniLight significantly outperforms existing methods on a wide range of traffic situations.
Multilingual and Multimodal Abuse Detection
Apr 03, 2022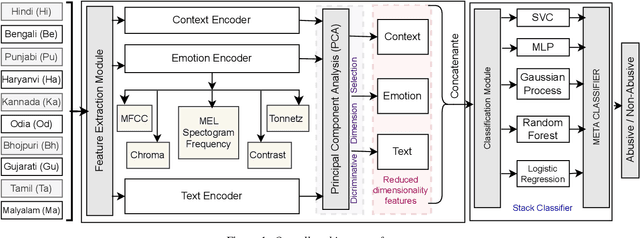
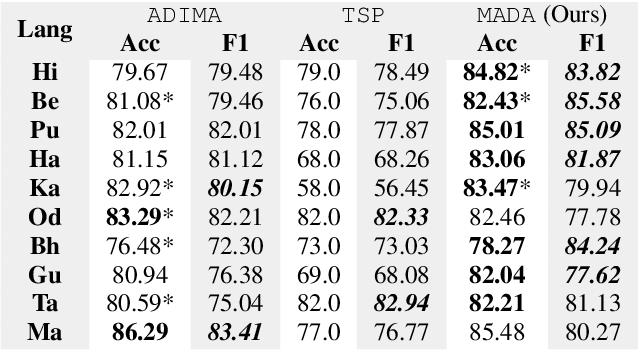
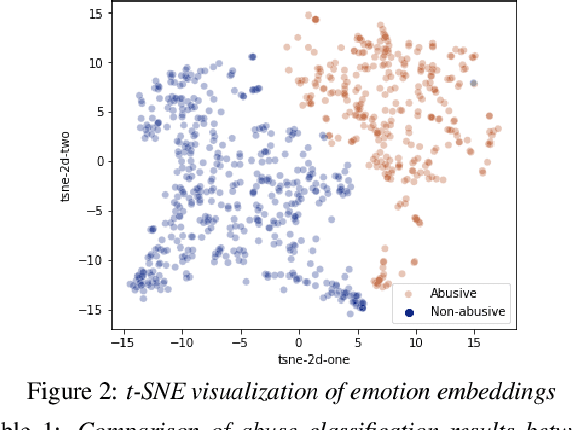
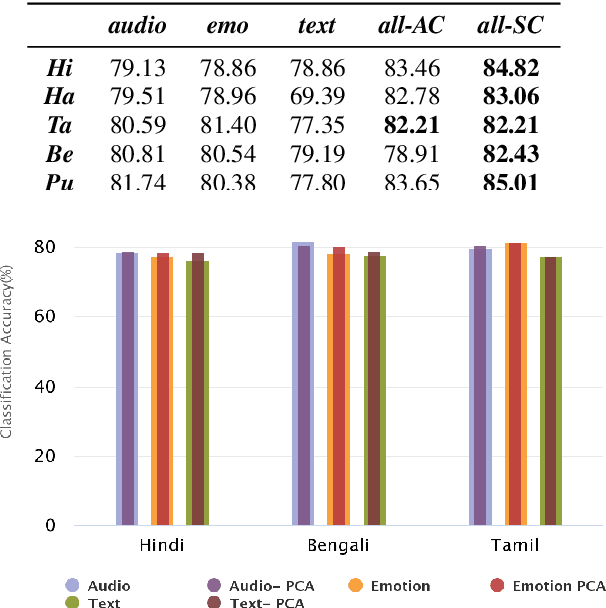
The presence of abusive content on social media platforms is undesirable as it severely impedes healthy and safe social media interactions. While automatic abuse detection has been widely explored in textual domain, audio abuse detection still remains unexplored. In this paper, we attempt abuse detection in conversational audio from a multimodal perspective in a multilingual social media setting. Our key hypothesis is that along with the modelling of audio, incorporating discriminative information from other modalities can be highly beneficial for this task. Our proposed method, MADA, explicitly focuses on two modalities other than the audio itself, namely, the underlying emotions expressed in the abusive audio and the semantic information encapsulated in the corresponding textual form. Observations prove that MADA demonstrates gains over audio-only approaches on the ADIMA dataset. We test the proposed approach on 10 different languages and observe consistent gains in the range 0.6%-5.2% by leveraging multiple modalities. We also perform extensive ablation experiments for studying the contributions of every modality and observe the best results while leveraging all the modalities together. Additionally, we perform experiments to empirically confirm that there is a strong correlation between underlying emotions and abusive behaviour.
A Pattern-mining Driven Study on Differences of Newspapers in Expressing Temporal Information
Nov 24, 2020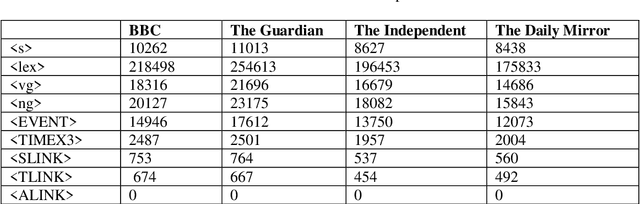

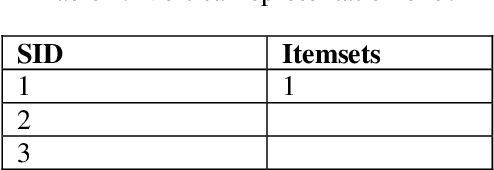
This paper studies the differences between different types of newspapers in expressing temporal information, which is a topic that has not received much attention. Techniques from the fields of temporal processing and pattern mining are employed to investigate this topic. First, a corpus annotated with temporal information is created by the author. Then, sequences of temporal information tags mixed with part-of-speech tags are extracted from the corpus. The TKS algorithm is used to mine skip-gram patterns from the sequences. With these patterns, the signatures of the four newspapers are obtained. In order to make the signatures uniquely characterize the newspapers, we revise the signatures by removing reference patterns. Through examining the number of patterns in the signatures and revised signatures, the proportion of patterns containing temporal information tags and the specific patterns containing temporal information tags, it is found that newspapers differ in ways of expressing temporal information.
* 19 pages
Task2Dial: A Novel Task and Dataset for Commonsense enhanced Task-based Dialogue Grounded in Documents
Apr 03, 2022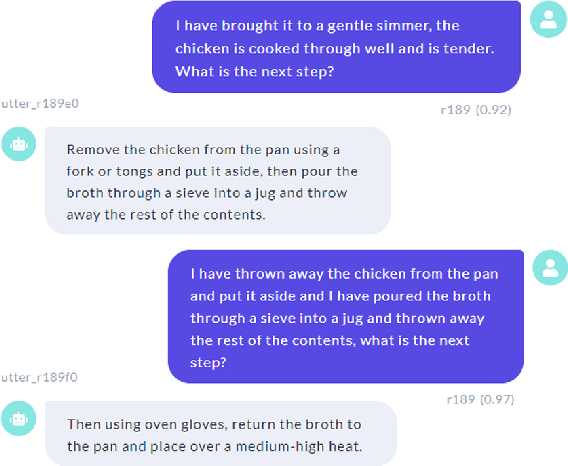

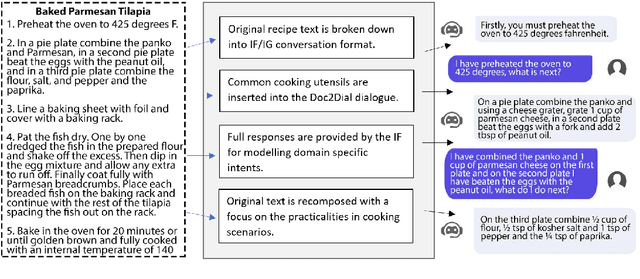
This paper proposes a novel task on commonsense-enhanced task-based dialogue grounded in documents and describes the Task2Dial dataset, a novel dataset of document-grounded task-based dialogues, where an Information Giver (IG) provides instructions (by consulting a document) to an Information Follower (IF), so that the latter can successfully complete the task. In this unique setting, the IF can ask clarification questions which may not be grounded in the underlying document and require commonsense knowledge to be answered. The Task2Dial dataset poses new challenges: (1) its human reference texts show more lexical richness and variation than other document-grounded dialogue datasets; (2) generating from this set requires paraphrasing as instructional responses might have been modified from the underlying document; (3) requires commonsense knowledge, since questions might not necessarily be grounded in the document; (4) generating requires planning based on context, as task steps need to be provided in order. The Task2Dial dataset contains dialogues with an average $18.15$ number of turns and 19.79 tokens per turn, as compared to 12.94 and 12 respectively in existing datasets. As such, learning from this dataset promises more natural, varied and less template-like system utterances.
Learning Infomax and Domain-Independent Representations for Causal Effect Inference with Real-World Data
Feb 22, 2022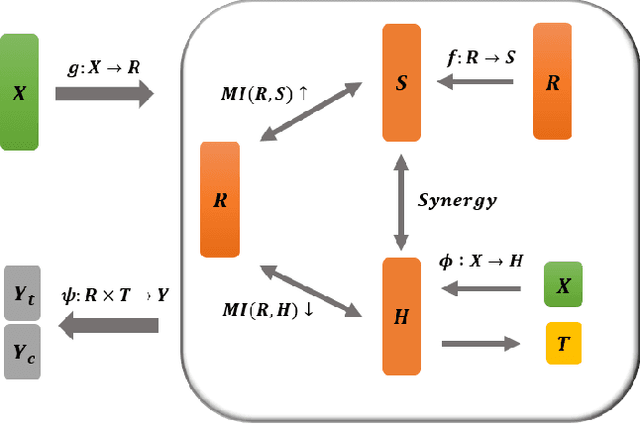
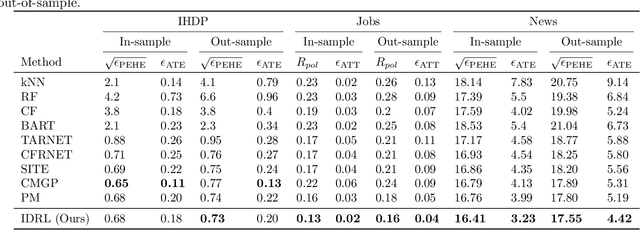
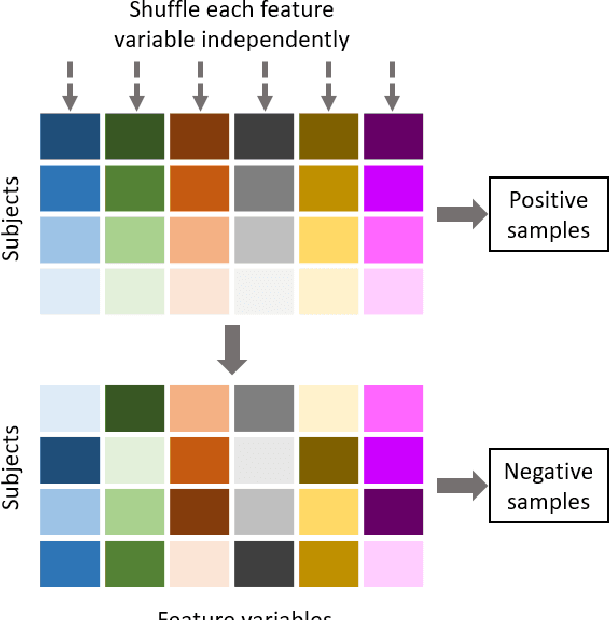
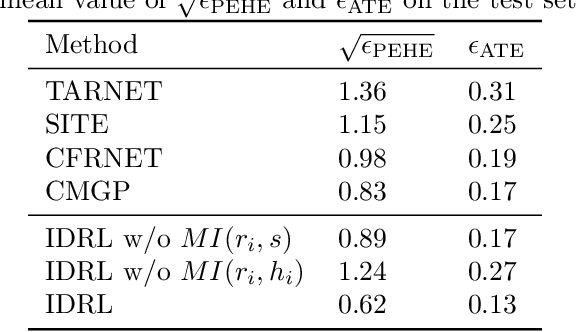
The foremost challenge to causal inference with real-world data is to handle the imbalance in the covariates with respect to different treatment options, caused by treatment selection bias. To address this issue, recent literature has explored domain-invariant representation learning based on different domain divergence metrics (e.g., Wasserstein distance, maximum mean discrepancy, position-dependent metric, and domain overlap). In this paper, we reveal the weaknesses of these strategies, i.e., they lead to the loss of predictive information when enforcing the domain invariance; and the treatment effect estimation performance is unstable, which heavily relies on the characteristics of the domain distributions and the choice of domain divergence metrics. Motivated by information theory, we propose to learn the Infomax and Domain-Independent Representations to solve the above puzzles. Our method utilizes the mutual information between the global feature representations and individual feature representations, and the mutual information between feature representations and treatment assignment predictions, in order to maximally capture the common predictive information for both treatment and control groups. Moreover, our method filters out the influence of instrumental and irrelevant variables, and thus it effectively increases the predictive ability of potential outcomes. Experimental results on both the synthetic and real-world datasets show that our method achieves state-of-the-art performance on causal effect inference. Moreover, our method exhibits reliable prediction performances when facing data with different characteristics of data distributions, complicated variable types, and severe covariate imbalance.
Unified Interactive Image Matting
May 17, 2022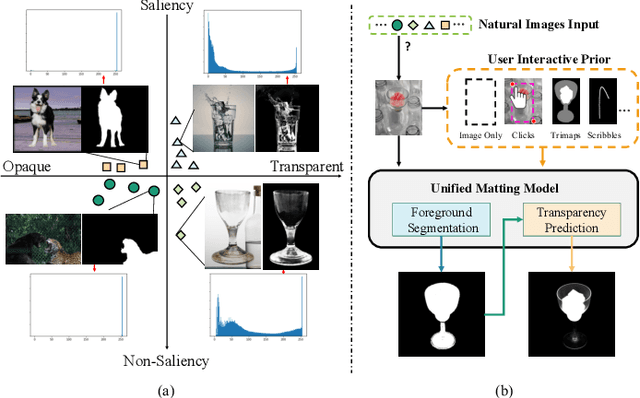

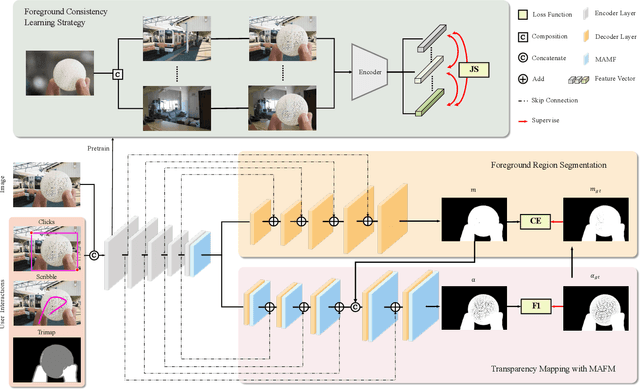
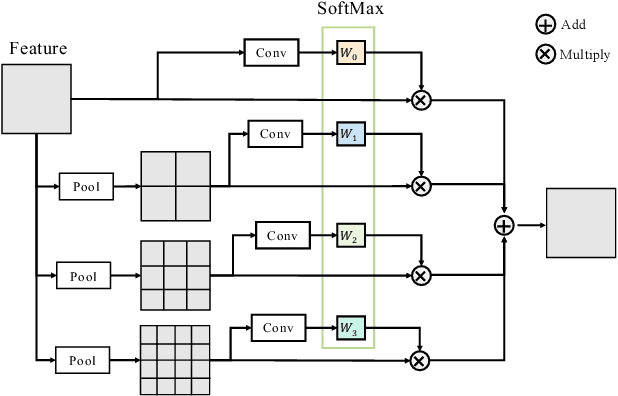
Recent image matting studies are developing towards proposing trimap-free or interactive methods for complete complex image matting tasks. Although avoiding the extensive labors of trimap annotation, existing methods still suffer from two limitations: (1) For the single image with multiple objects, it is essential to provide extra interaction information to help determining the matting target; (2) For transparent objects, the accurate regression of alpha matte from RGB image is much more difficult compared with the opaque ones. In this work, we propose a Unified Interactive image Matting method, named UIM, which solves the limitations and achieves satisfying matting results for any scenario. Specifically, UIM leverages multiple types of user interaction to avoid the ambiguity of multiple matting targets, and we compare the pros and cons of different annotation types in detail. To unify the matting performance for transparent and opaque objects, we decouple image matting into two stages, i.e., foreground segmentation and transparency prediction. Moreover, we design a multi-scale attentive fusion module to alleviate the vagueness in the boundary region. Experimental results demonstrate that UIM achieves state-of-the-art performance on the Composition-1K test set and a synthetic unified dataset. Our code and models will be released soon.