 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal Context Matters: Enhancing Single Image Prediction with Disease Progression Representations
Mar 31, 2022
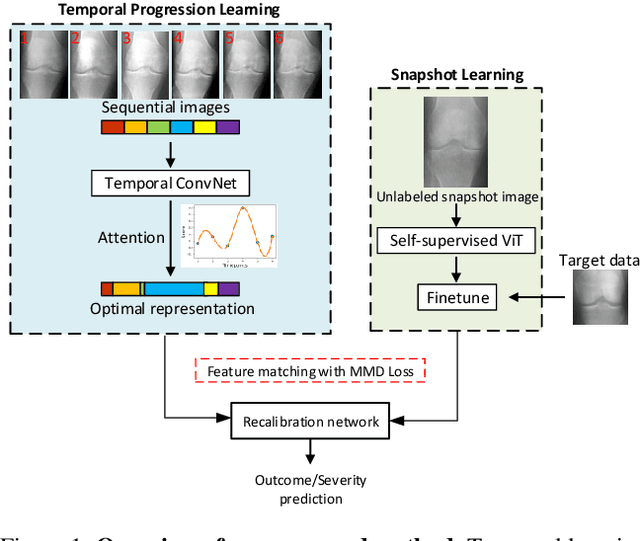
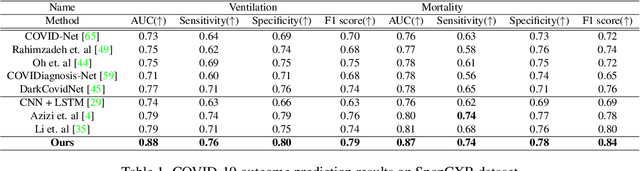
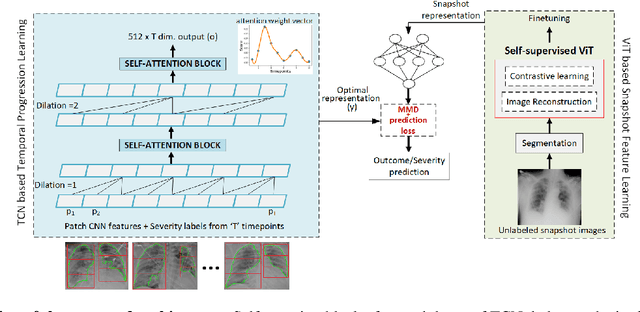
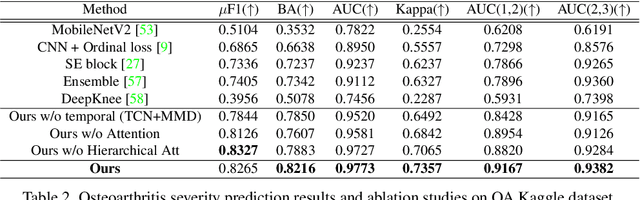
Clinical outcome or severity prediction from medical images has largely focused on learning representations from single-timepoint or snapshot scans. It has been shown that disease progression can be better characterized by temporal imaging. We therefore hypothesized that outcome predictions can be improved by utilizing the disease progression information from sequential images. We present a deep learning approach that leverages temporal progression information to improve clinical outcome predictions from single-timepoint images. In our method, a self-attention based Temporal Convolutional Network (TCN) is used to learn a representation that is most reflective of the disease trajectory. Meanwhile, a Vision Transformer is pretrained in a self-supervised fashion to extract features from single-timepoint images. The key contribution is to design a recalibration module that employs maximum mean discrepancy loss (MMD) to align distributions of the above two contextual representations. We train our system to predict clinical outcomes and severity grades from single-timepoint images. Experiments on chest and osteoarthritis radiography datasets demonstrate that our approach outperforms other state-of-the-art techniques.
Trading Positional Complexity vs. Deepness in Coordinate Networks
May 18, 2022



It is well noted that coordinate-based MLPs benefit -- in terms of preserving high-frequency information -- through the encoding of coordinate positions as an array of Fourier features. Hitherto, the rationale for the effectiveness of these positional encodings has been mainly studied through a Fourier lens. In this paper, we strive to broaden this understanding by showing that alternative non-Fourier embedding functions can indeed be used for positional encoding. Moreover, we show that their performance is entirely determined by a trade-off between the stable rank of the embedded matrix and the distance preservation between embedded coordinates. We further establish that the now ubiquitous Fourier feature mapping of position is a special case that fulfills these conditions. Consequently, we present a more general theory to analyze positional encoding in terms of shifted basis functions. In addition, we argue that employing a more complex positional encoding -- that scales exponentially with the number of modes -- requires only a linear (rather than deep) coordinate function to achieve comparable performance. Counter-intuitively, we demonstrate that trading positional embedding complexity for network deepness is orders of magnitude faster than current state-of-the-art; despite the additional embedding complexity. To this end, we develop the necessary theoretical formulae and empirically verify that our theoretical claims hold in practice.
Capacitive imaging using fused amplitude and phase information for improved defect detection
Mar 25, 2021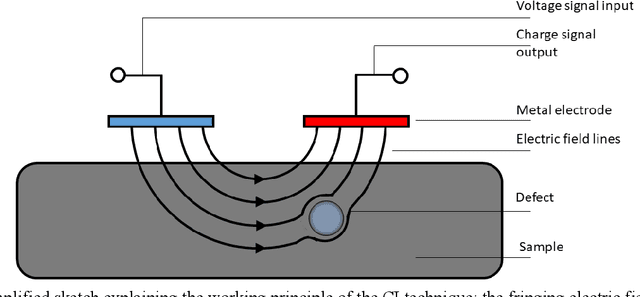
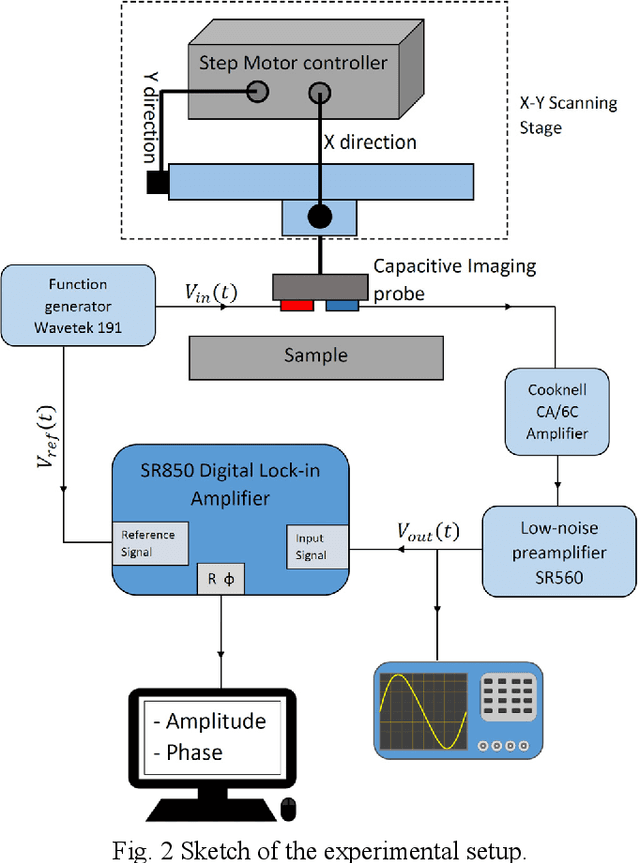
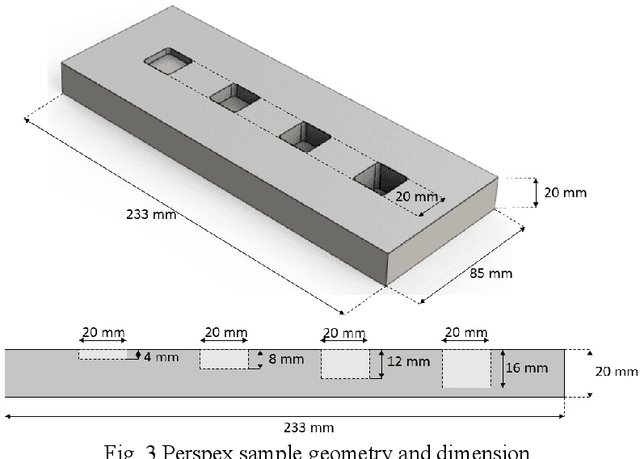

This paper introduces an improved image processing method usable in capacitive imaging applications. Standard capacitive imaging tends to prefer amplitude-based images over the use of phase due to better signal-to-noise ratios. The new approach exploits the best features of both types of information by combining them to form clearer images, hence improving both defect detection and characterization in non-destructive evaluation. The methodology is demonstrated and optimized using a benchmark sample. Additional experiments on glass fibre composite sample illustrate the advantages of the technique.
SATS: Self-Attention Transfer for Continual Semantic Segmentation
Mar 15, 2022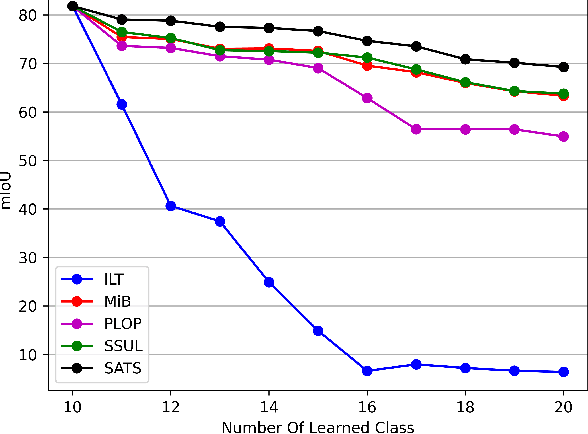
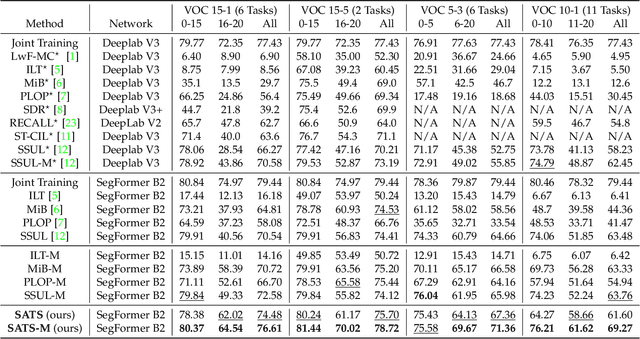
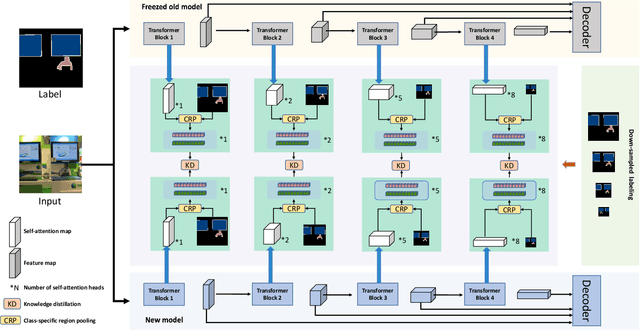
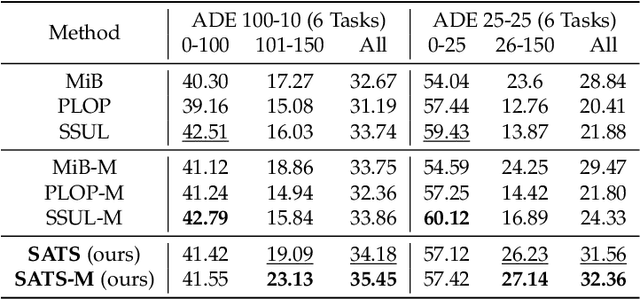
Continually learning to segment more and more types of image regions is a desired capability for many intelligent systems. However, such continual semantic segmentation suffers from the same catastrophic forgetting issue as in continual classification learning. While multiple knowledge distillation strategies originally for continual classification have been well adapted to continual semantic segmentation, they only consider transferring old knowledge based on the outputs from one or more layers of deep fully convolutional networks. Different from existing solutions, this study proposes to transfer a new type of information relevant to knowledge, i.e. the relationships between elements (Eg. pixels or small local regions) within each image which can capture both within-class and between-class knowledge. The relationship information can be effectively obtained from the self-attention maps in a Transformer-style segmentation model. Considering that pixels belonging to the same class in each image often share similar visual properties, a class-specific region pooling is applied to provide more efficient relationship information for knowledge transfer. Extensive evaluations on multiple public benchmarks support that the proposed self-attention transfer method can further effectively alleviate the catastrophic forgetting issue, and its flexible combination with one or more widely adopted strategies significantly outperforms state-of-the-art solu
HAKG: Hierarchy-Aware Knowledge Gated Network for Recommendation
Apr 11, 2022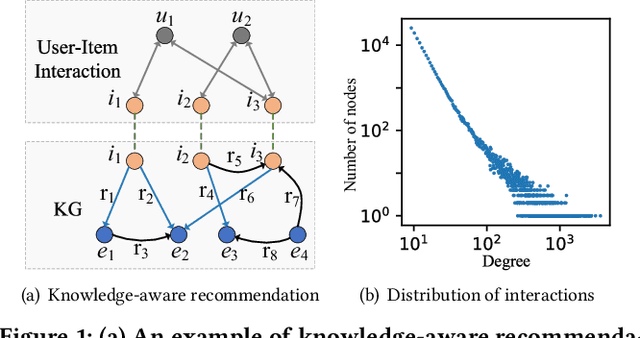
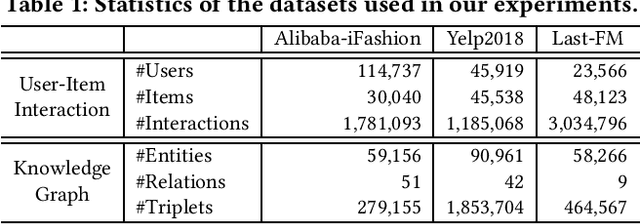
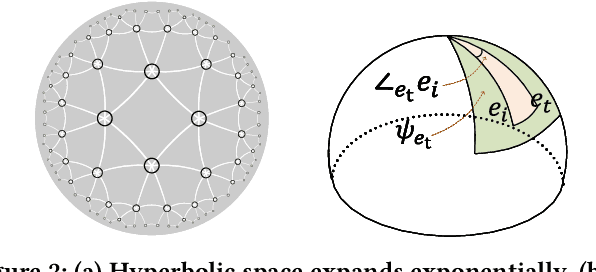
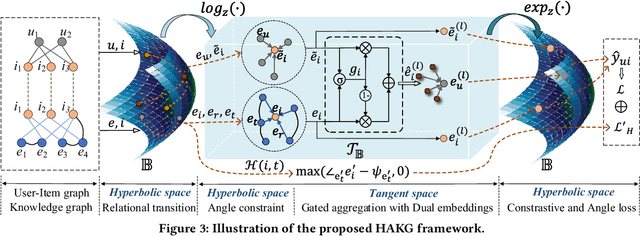
Knowledge graph (KG) plays an increasingly important role to improve the recommendation performance and interpretability. A recent technical trend is to design end-to-end models based on information propagation schemes. However, existing propagation-based methods fail to (1) model the underlying hierarchical structures and relations, and (2) capture the high-order collaborative signals of items for learning high-quality user and item representations. In this paper, we propose a new model, called Hierarchy-Aware Knowledge Gated Network (HAKG), to tackle the aforementioned problems. Technically, we model users and items (that are captured by a user-item graph), as well as entities and relations (that are captured in a KG) in hyperbolic space, and design a hyperbolic aggregation scheme to gather relational contexts over KG. Meanwhile, we introduce a novel angle constraint to preserve characteristics of items in the embedding space. Furthermore, we propose a dual item embeddings design to represent and propagate collaborative signals and knowledge associations separately, and leverage the gated aggregation to distill discriminative information for better capturing user behavior patterns. Experimental results on three benchmark datasets show that, HAKG achieves significant improvement over the state-of-the-art methods like CKAN, Hyper-Know, and KGIN. Further analyses on the learned hyperbolic embeddings confirm that HAKG offers meaningful insights into the hierarchies of data.
Breaking with Fixed Set Pathology Recognition through Report-Guided Contrastive Training
May 14, 2022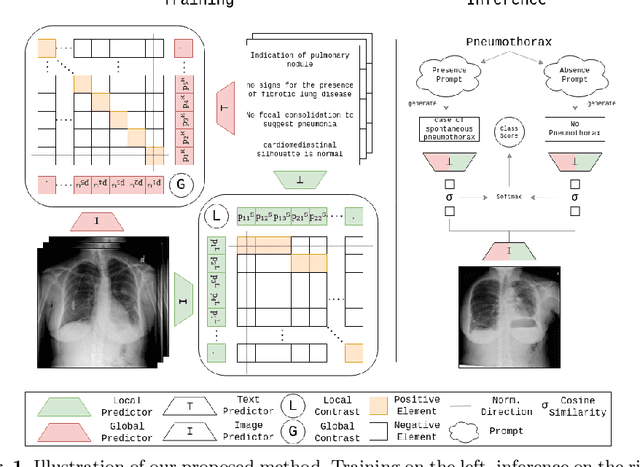
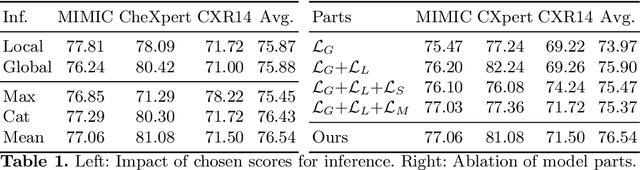
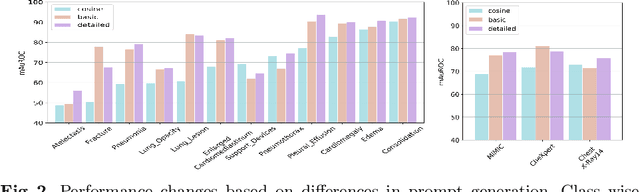
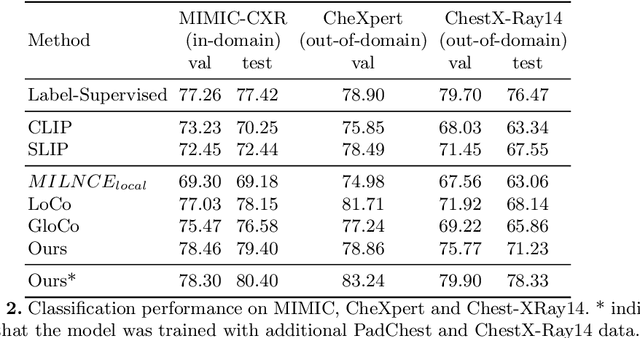
When reading images, radiologists generate text reports describing the findings therein. Current state-of-the-art computer-aided diagnosis tools utilize a fixed set of predefined categories automatically extracted from these medical reports for training. This form of supervision limits the potential usage of models as they are unable to pick up on anomalies outside of their predefined set, thus, making it a necessity to retrain the classifier with additional data when faced with novel classes. In contrast, we investigate direct text supervision to break away from this closed set assumption. By doing so, we avoid noisy label extraction via text classifiers and incorporate more contextual information. We employ a contrastive global-local dual-encoder architecture to learn concepts directly from unstructured medical reports while maintaining its ability to perform free form classification. We investigate relevant properties of open set recognition for radiological data and propose a method to employ currently weakly annotated data into training. We evaluate our approach on the large-scale chest X-Ray datasets MIMIC-CXR, CheXpert, and ChestX-Ray14 for disease classification. We show that despite using unstructured medical report supervision, we perform on par with direct label supervision through a sophisticated inference setting.
TSAM: A Two-Stream Attention Model for Causal Emotion Entailment
Mar 02, 2022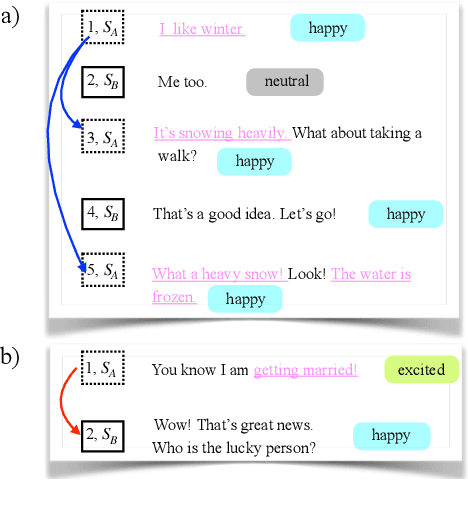
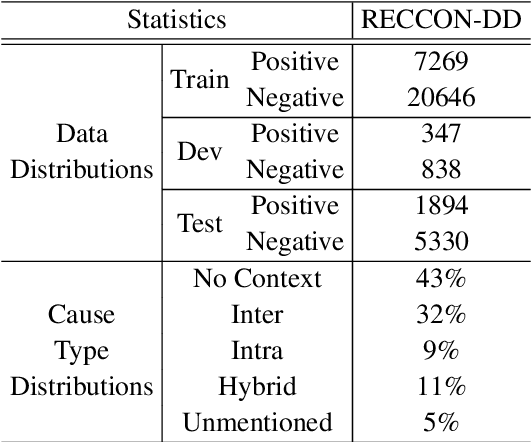
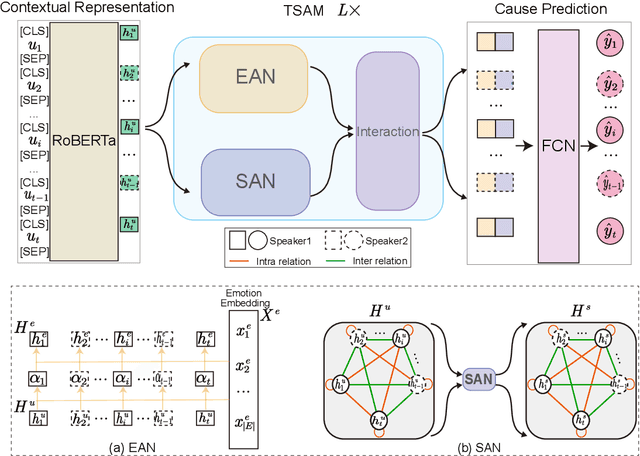
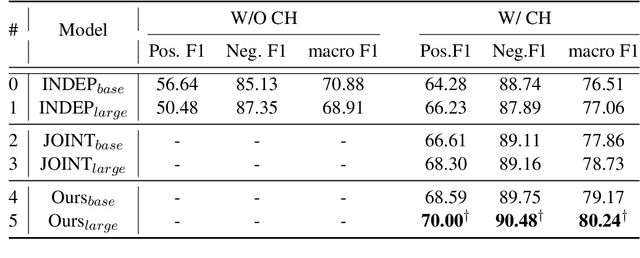
Causal Emotion Entailment (CEE) aims to discover the potential causes behind an emotion in a conversational utterance. Previous works formalize CEE as independent utterance pair classification problems, with emotion and speaker information neglected. From a new perspective, this paper considers CEE in a joint framework. We classify multiple utterances synchronously to capture the correlations between utterances in a global view and propose a Two-Stream Attention Model (TSAM) to effectively model the speaker's emotional influences in the conversational history. Specifically, the TSAM comprises three modules: Emotion Attention Network (EAN), Speaker Attention Network (SAN), and interaction module. The EAN and SAN incorporate emotion and speaker information in parallel, and the subsequent interaction module effectively interchanges relevant information between the EAN and SAN via a mutual BiAffine transformation. Experimental results on a benchmark dataset demonstrate that our model achieves new State-Of-The-Art (SOTA) performance and outperforms baselines remarkably.
Learning to Truncate Ranked Lists for Information Retrieval
Mar 01, 2021

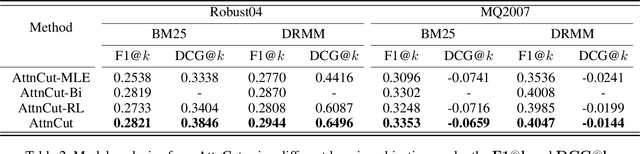
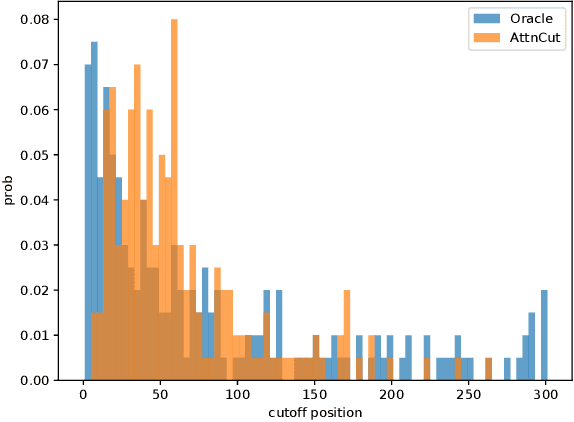
Ranked list truncation is of critical importance in a variety of professional information retrieval applications such as patent search or legal search. The goal is to dynamically determine the number of returned documents according to some user-defined objectives, in order to reach a balance between the overall utility of the results and user efforts. Existing methods formulate this task as a sequential decision problem and take some pre-defined loss as a proxy objective, which suffers from the limitation of local decision and non-direct optimization. In this work, we propose a global decision based truncation model named AttnCut, which directly optimizes user-defined objectives for the ranked list truncation. Specifically, we take the successful transformer architecture to capture the global dependency within the ranked list for truncation decision, and employ the reward augmented maximum likelihood (RAML) for direct optimization. We consider two types of user-defined objectives which are of practical usage. One is the widely adopted metric such as F1 which acts as a balanced objective, and the other is the best F1 under some minimal recall constraint which represents a typical objective in professional search. Empirical results over the Robust04 and MQ2007 datasets demonstrate the effectiveness of our approach as compared with the state-of-the-art baselines.
Modeling Reservoir Release Using Pseudo-Prospective Learning and Physical Simulations to Predict Water Temperature
Feb 11, 2022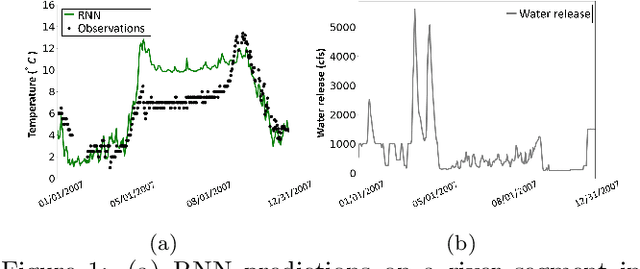
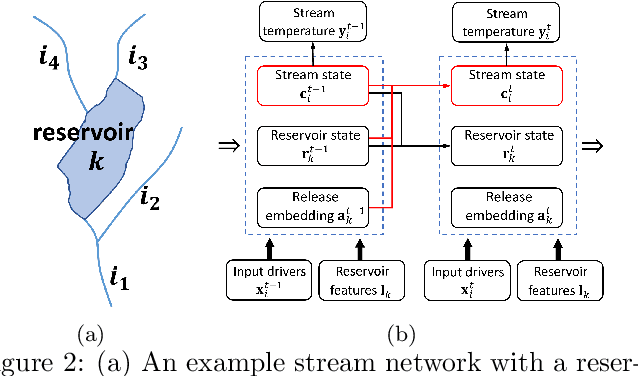

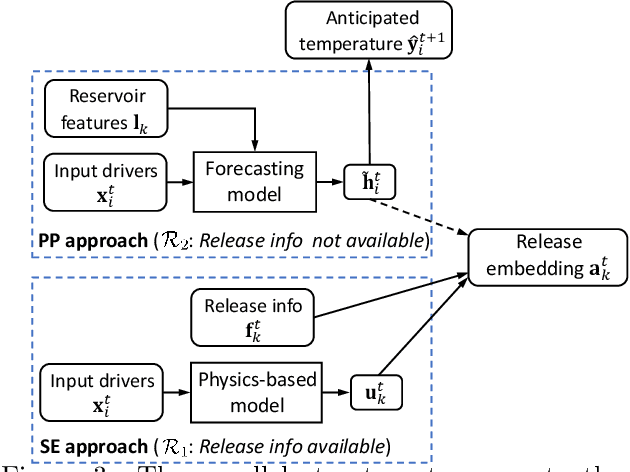
This paper proposes a new data-driven method for predicting water temperature in stream networks with reservoirs. The water flows released from reservoirs greatly affect the water temperature of downstream river segments. However, the information of released water flow is often not available for many reservoirs, which makes it difficult for data-driven models to capture the impact to downstream river segments. In this paper, we first build a state-aware graph model to represent the interactions amongst streams and reservoirs, and then propose a parallel learning structure to extract the reservoir release information and use it to improve the prediction. In particular, for reservoirs with no available release information, we mimic the water managers' release decision process through a pseudo-prospective learning method, which infers the release information from anticipated water temperature dynamics. For reservoirs with the release information, we leverage a physics-based model to simulate the water release temperature and transfer such information to guide the learning process for other reservoirs. The evaluation for the Delaware River Basin shows that the proposed method brings over 10\% accuracy improvement over existing data-driven models for stream temperature prediction when the release data is not available for any reservoirs. The performance is further improved after we incorporate the release data and physical simulations for a subset of reservoirs.
V3GAN: Decomposing Background, Foreground and Motion for Video Generation
Mar 26, 2022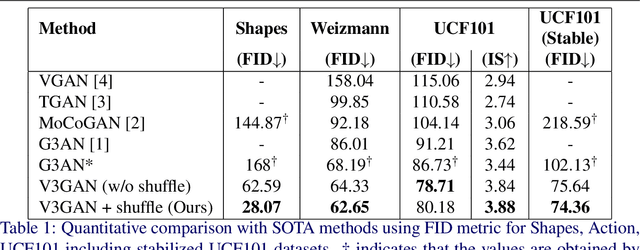
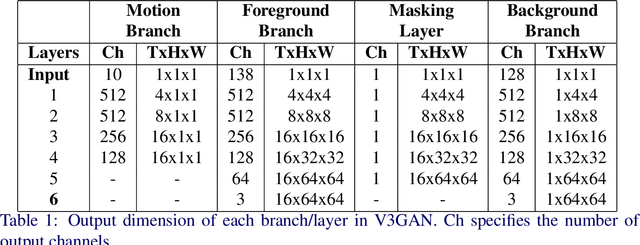

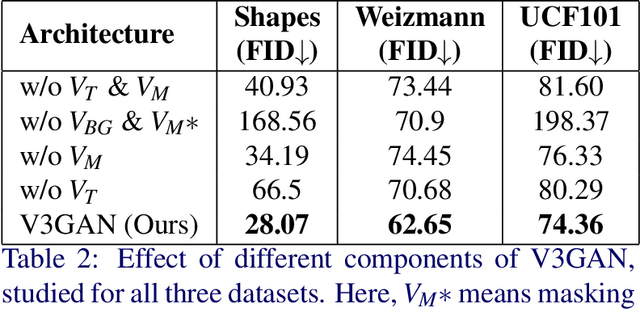
Video generation is a challenging task that requires modeling plausible spatial and temporal dynamics in a video. Inspired by how humans perceive a video by grouping a scene into moving and stationary components, we propose a method that decomposes the task of video generation into the synthesis of foreground, background and motion. Foreground and background together describe the appearance, whereas motion specifies how the foreground moves in a video over time. We propose V3GAN, a novel three-branch generative adversarial network where two branches model foreground and background information, while the third branch models the temporal information without any supervision. The foreground branch is augmented with our novel feature-level masking layer that aids in learning an accurate mask for foreground and background separation. To encourage motion consistency, we further propose a shuffling loss for the video discriminator. Extensive quantitative and qualitative analysis on synthetic as well as real-world benchmark datasets demonstrates that V3GAN outperforms the state-of-the-art methods by a significant margin.