 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DropMessage: Unifying Random Dropping for Graph Neural Networks
Apr 21, 2022
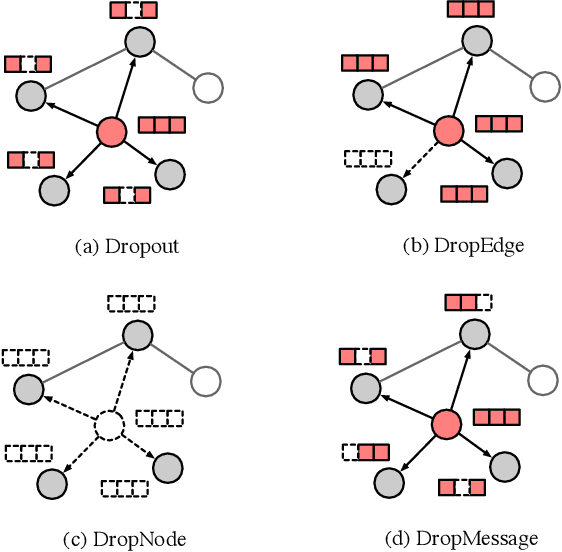

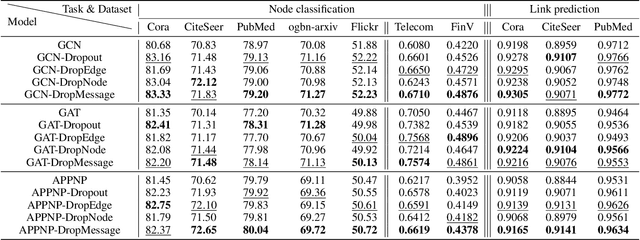
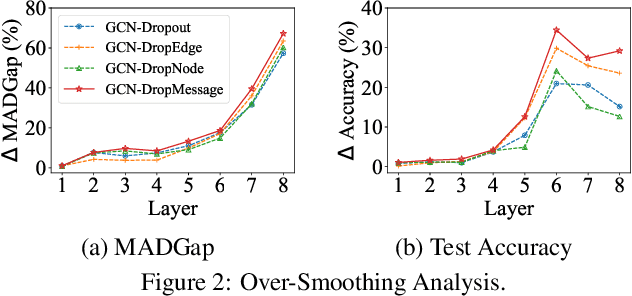
Graph Neural Networks (GNNs) are powerful tools for graph representation learning. Despite their rapid development, GNNs also faces some challenges, such as over-fitting, over-smoothing, and non-robustness. Previous works indicate that these problems can be alleviated by random dropping methods, which integrate noises into models by randomly masking parts of the input. However, some open-ended problems of random dropping on GNNs remain to solve. First, it is challenging to find a universal method that are suitable for all cases considering the divergence of different datasets and models. Second, random noises introduced to GNNs cause the incomplete coverage of parameters and unstable training process. In this paper, we propose a novel random dropping method called DropMessage, which performs dropping operations directly on the message matrix and can be applied to any message-passing GNNs. Furthermore, we elaborate the superiority of DropMessage: it stabilizes the training process by reducing sample variance; it keeps information diversity from the perspective of information theory, which makes it a theoretical upper bound of other methods. Also, we unify existing random dropping methods into our framework and analyze their effects on GNNs. To evaluate our proposed method, we conduct experiments that aims for multiple tasks on five public datasets and two industrial datasets with various backbone models. The experimental results show that DropMessage has both advantages of effectiveness and generalization.
Using Type Information to Improve Entity Coreference Resolution
Oct 12, 2020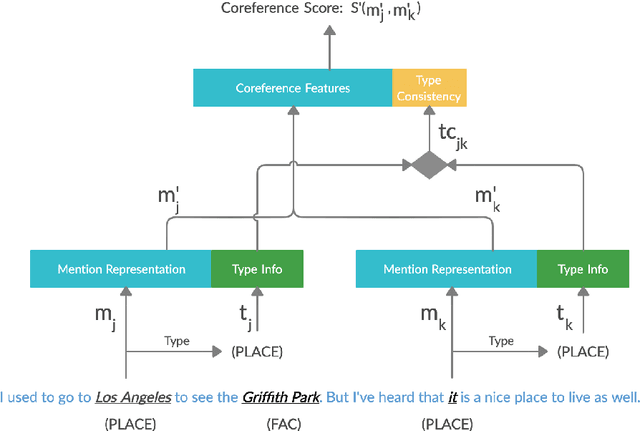
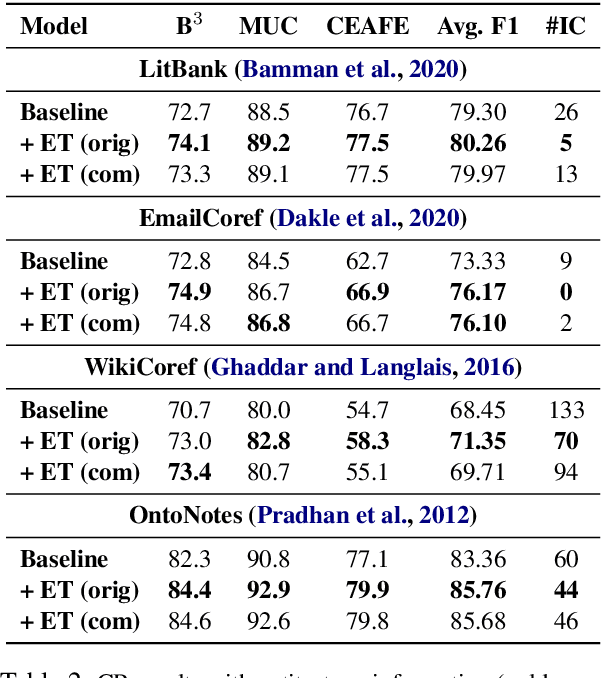
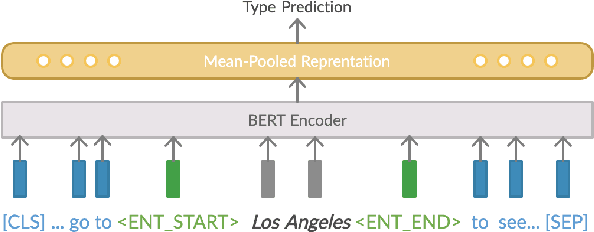
Coreference resolution (CR) is an essential part of discourse analysis. Most recently, neural approaches have been proposed to improve over SOTA models from earlier paradigms. So far none of the published neural models leverage external semantic knowledge such as type information. This paper offers the first such model and evaluation, demonstrating modest gains in accuracy by introducing either gold standard or predicted types. In the proposed approach, type information serves both to (1) improve mention representation and (2) create a soft type consistency check between coreference candidate mentions. Our evaluation covers two different grain sizes of types over four different benchmark corpora.
Deep Learning for Omnidirectional Vision: A Survey and New Perspectives
May 24, 2022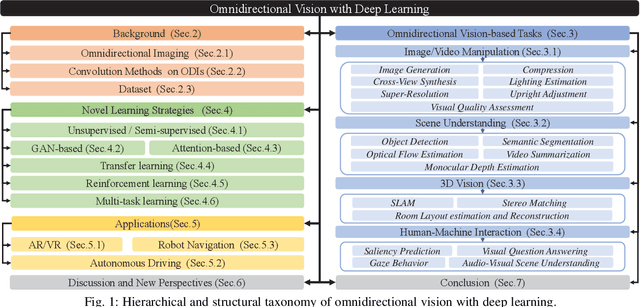
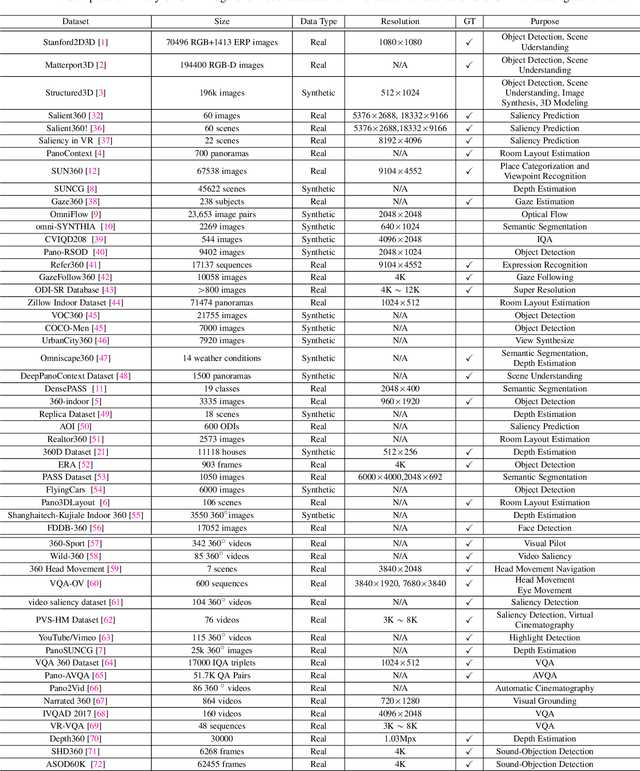


Omnidirectional image (ODI) data is captured with a 360x180 field-of-view, which is much wider than the pinhole cameras and contains richer spatial information than the conventional planar images. Accordingly, omnidirectional vision has attracted booming attention due to its more advantageous performance in numerous applications, such as autonomous driving and virtual reality. In recent years, the availability of customer-level 360 cameras has made omnidirectional vision more popular, and the advance of deep learning (DL) has significantly sparked its research and applications. This paper presents a systematic and comprehensive review and analysis of the recent progress in DL methods for omnidirectional vision. Our work covers four main contents: (i) An introduction to the principle of omnidirectional imaging, the convolution methods on the ODI, and datasets to highlight the differences and difficulties compared with the 2D planar image data; (ii) A structural and hierarchical taxonomy of the DL methods for omnidirectional vision; (iii) A summarization of the latest novel learning strategies and applications; (iv) An insightful discussion of the challenges and open problems by highlighting the potential research directions to trigger more research in the community.
A Quadrature Rule combining Control Variates and Adaptive Importance Sampling
May 24, 2022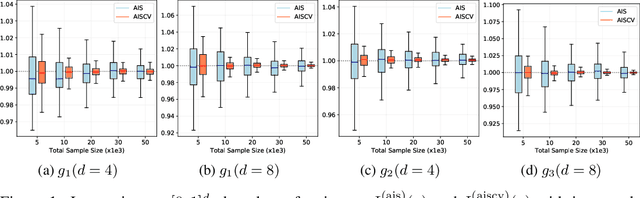
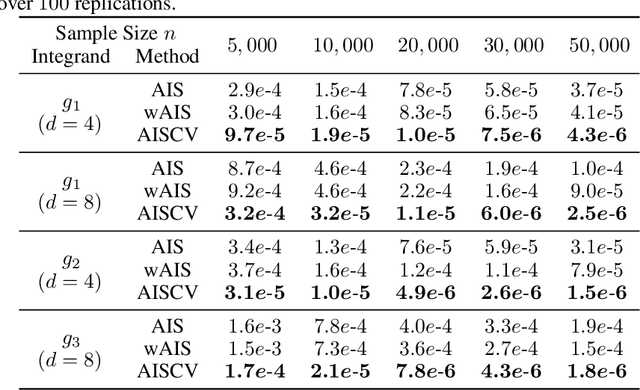
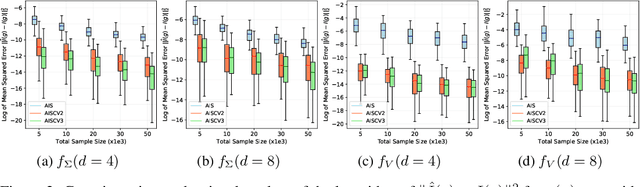
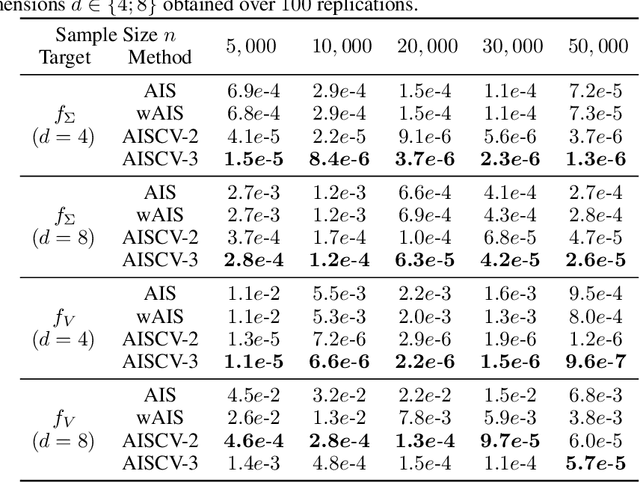
Driven by several successful applications such as in stochastic gradient descent or in Bayesian computation, control variates have become a major tool for Monte Carlo integration. However, standard methods do not allow the distribution of the particles to evolve during the algorithm, as is the case in sequential simulation methods. Within the standard adaptive importance sampling framework, a simple weighted least squares approach is proposed to improve the procedure with control variates. The procedure takes the form of a quadrature rule with adapted quadrature weights to reflect the information brought in by the control variates. The quadrature points and weights do not depend on the integrand, a computational advantage in case of multiple integrands. Moreover, the target density needs to be known only up to a multiplicative constant. Our main result is a non-asymptotic bound on the probabilistic error of the procedure. The bound proves that for improving the estimate's accuracy, the benefits from adaptive importance sampling and control variates can be combined. The good behavior of the method is illustrated empirically on synthetic examples and real-world data for Bayesian linear regression.
Residual-Guided Non-Intrusive Speech Quality Assessment
Mar 22, 2022
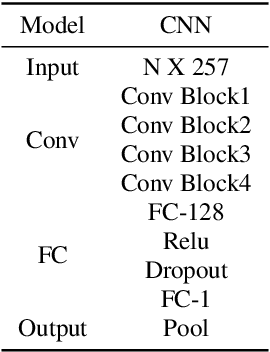
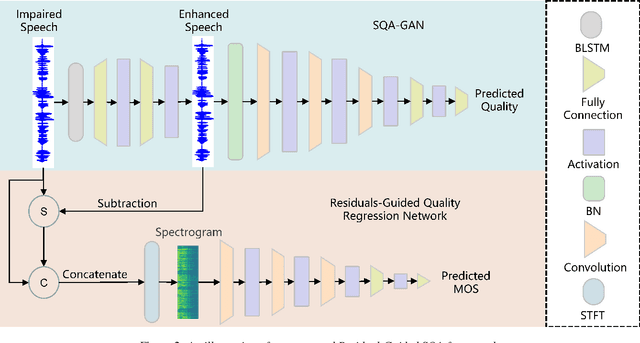

This paper proposes an approach to improve Non-Intrusive speech quality assessment(NI-SQA) based on the residuals between impaired speech and enhanced speech. The difficulty in our task is particularly lack of information, for which the corresponding reference speech is absent. We generate an enhanced speech on the impaired speech to compensate for the absence of the reference audio, then pair the information of residuals with the impaired speech. Compared to feeding the impaired speech directly into the model, residuals could bring some extra helpful information from the contrast in enhancement. The human ear is sensitive to certain noises but different to deep learning model. Causing the Mean Opinion Score(MOS) the model predicted is not enough to fit our subjective sensitive well and causes deviation. These residuals have a close relationship to reference speech and then improve the ability of the deep learning models to predict MOS. During the training phase, experimental results demonstrate that paired with residuals can quickly obtain better evaluation indicators under the same conditions. Furthermore, our final results improved 31.3 percent and 14.1 percent, respectively, in PLCC and RMSE.
Targeted Adaptive Design
May 27, 2022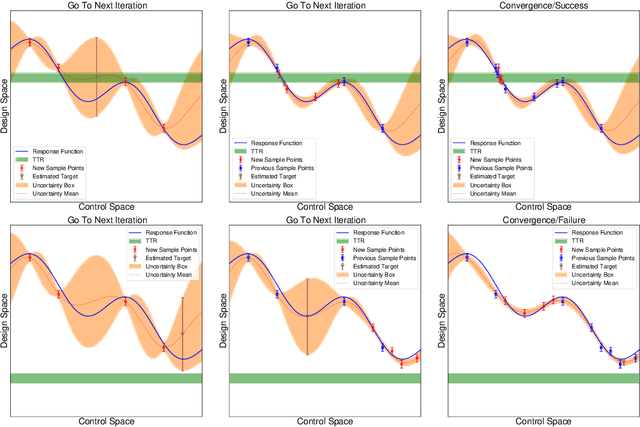
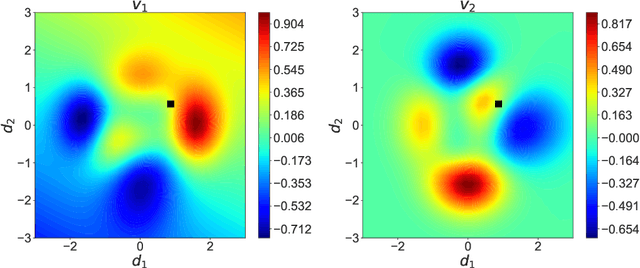
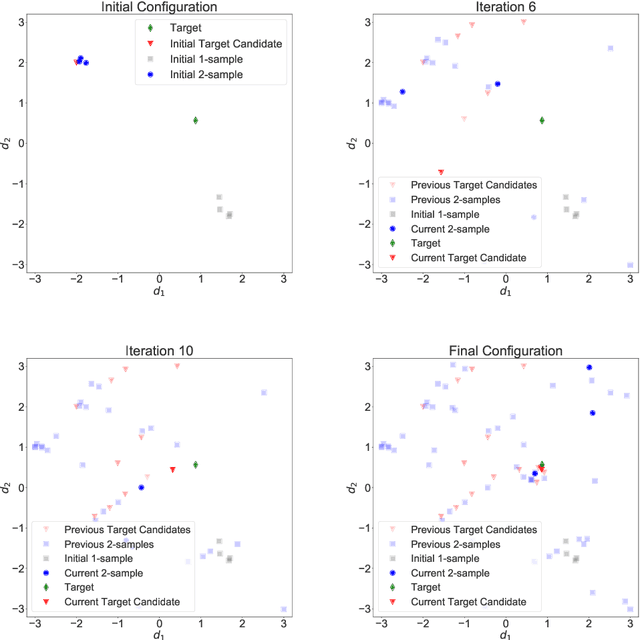
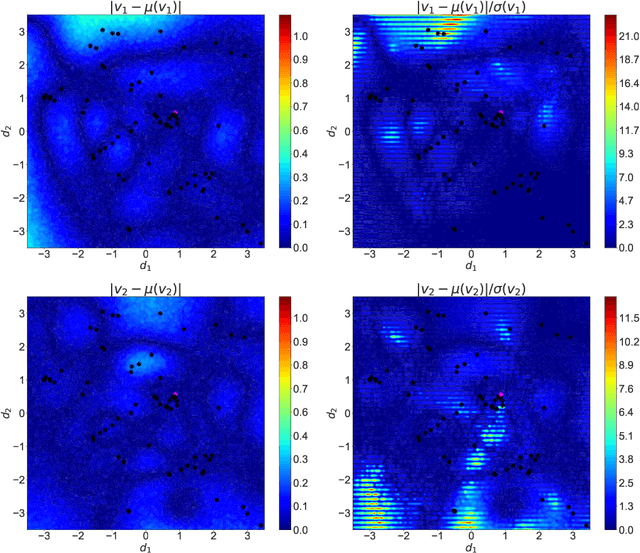
Modern advanced manufacturing and advanced materials design often require searches of relatively high-dimensional process control parameter spaces for settings that result in optimal structure, property, and performance parameters. The mapping from the former to the latter must be determined from noisy experiments or from expensive simulations. We abstract this problem to a mathematical framework in which an unknown function from a control space to a design space must be ascertained by means of expensive noisy measurements, which locate optimal control settings generating desired design features within specified tolerances, with quantified uncertainty. We describe targeted adaptive design (TAD), a new algorithm that performs this optimal sampling task. TAD creates a Gaussian process surrogate model of the unknown mapping at each iterative stage, proposing a new batch of control settings to sample experimentally and optimizing the updated log-predictive likelihood of the target design. TAD either stops upon locating a solution with uncertainties that fit inside the tolerance box or uses a measure of expected future information to determine that the search space has been exhausted with no solution. TAD thus embodies the exploration-exploitation tension in a manner that recalls, but is essentially different from, Bayesian optimization and optimal experimental design.
Graph Enhanced Contrastive Learning for Radiology Findings Summarization
Apr 01, 2022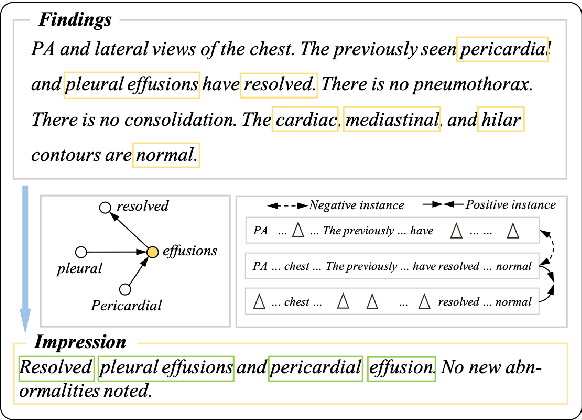
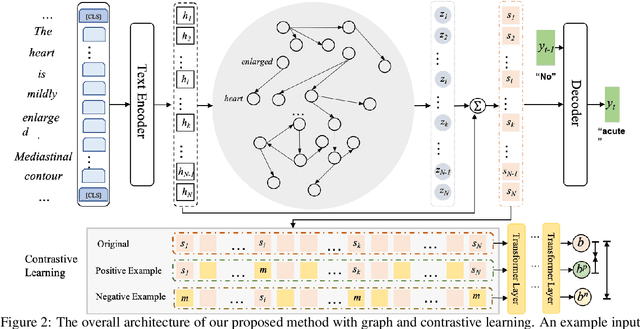
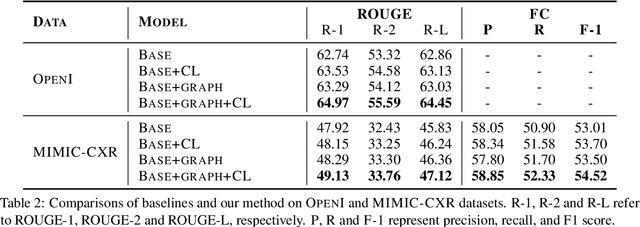
The impression section of a radiology report summarizes the most prominent observation from the findings section and is the most important section for radiologists to communicate to physicians. Summarizing findings is time-consuming and can be prone to error for inexperienced radiologists, and thus automatic impression generation has attracted substantial attention. With the encoder-decoder framework, most previous studies explore incorporating extra knowledge (e.g., static pre-defined clinical ontologies or extra background information). Yet, they encode such knowledge by a separate encoder to treat it as an extra input to their models, which is limited in leveraging their relations with the original findings. To address the limitation, we propose a unified framework for exploiting both extra knowledge and the original findings in an integrated way so that the critical information (i.e., key words and their relations) can be extracted in an appropriate way to facilitate impression generation. In detail, for each input findings, it is encoded by a text encoder, and a graph is constructed through its entities and dependency tree. Then, a graph encoder (e.g., graph neural networks (GNNs)) is adopted to model relation information in the constructed graph. Finally, to emphasize the key words in the findings, contrastive learning is introduced to map positive samples (constructed by masking non-key words) closer and push apart negative ones (constructed by masking key words). The experimental results on OpenI and MIMIC-CXR confirm the effectiveness of our proposed method.
Time-aware Graph Neural Networks for Entity Alignment between Temporal Knowledge Graphs
Mar 04, 2022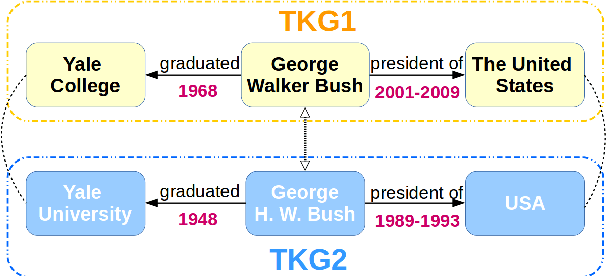

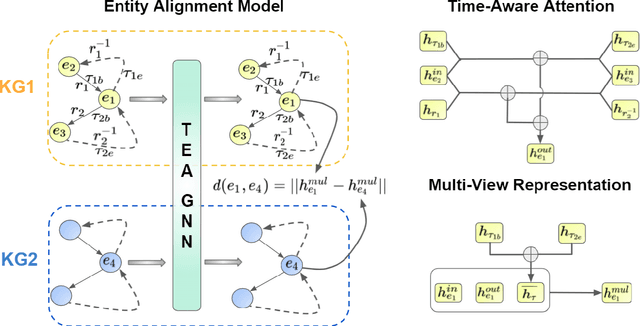
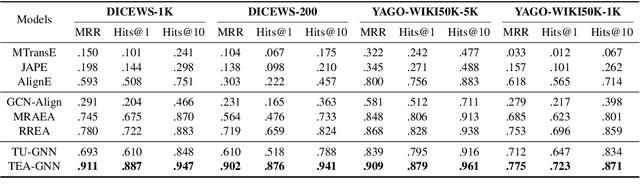
Entity alignment aims to identify equivalent entity pairs between different knowledge graphs (KGs). Recently, the availability of temporal KGs (TKGs) that contain time information created the need for reasoning over time in such TKGs. Existing embedding-based entity alignment approaches disregard time information that commonly exists in many large-scale KGs, leaving much room for improvement. In this paper, we focus on the task of aligning entity pairs between TKGs and propose a novel Time-aware Entity Alignment approach based on Graph Neural Networks (TEA-GNN). We embed entities, relations and timestamps of different KGs into a vector space and use GNNs to learn entity representations. To incorporate both relation and time information into the GNN structure of our model, we use a time-aware attention mechanism which assigns different weights to different nodes with orthogonal transformation matrices computed from embeddings of the relevant relations and timestamps in a neighborhood. Experimental results on multiple real-world TKG datasets show that our method significantly outperforms the state-of-the-art methods due to the inclusion of time information.
DPSNN: A Differentially Private Spiking Neural Network
May 24, 2022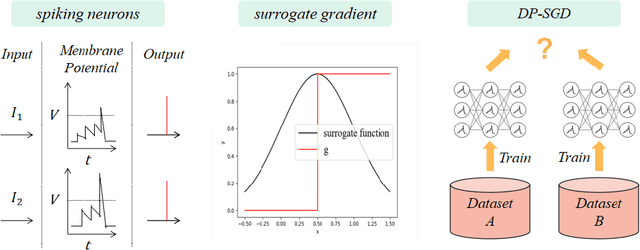

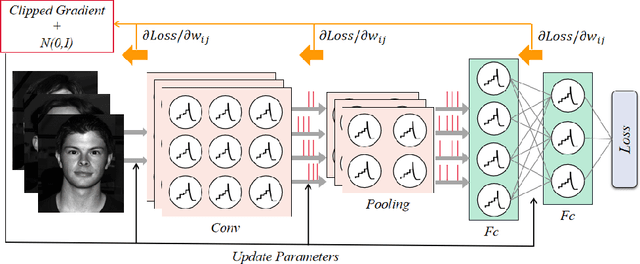
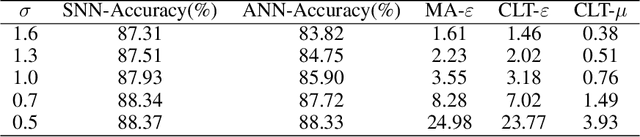
Privacy-preserving is a key problem for the machine learning algorithm. Spiking neural network (SNN) plays an important role in many domains, such as image classification, object detection, and speech recognition, but the study on the privacy protection of SNN is urgently needed. This study combines the differential privacy (DP) algorithm and SNN and proposes differentially private spiking neural network (DPSNN). DP injects noise into the gradient, and SNN transmits information in discrete spike trains so that our differentially private SNN can maintain strong privacy protection while still ensuring high accuracy. We conducted experiments on MNIST, Fashion-MNIST, and the face recognition dataset Extended YaleB. When the privacy protection is improved, the accuracy of the artificial neural network(ANN) drops significantly, but our algorithm shows little change in performance. Meanwhile, we analyzed different factors that affect the privacy protection of SNN. Firstly, the less precise the surrogate gradient is, the better the privacy protection of the SNN. Secondly, the Integrate-And-Fire (IF) neurons perform better than leaky Integrate-And-Fire (LIF) neurons. Thirdly, a large time window contributes more to privacy protection and performance.
LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents
Apr 01, 2022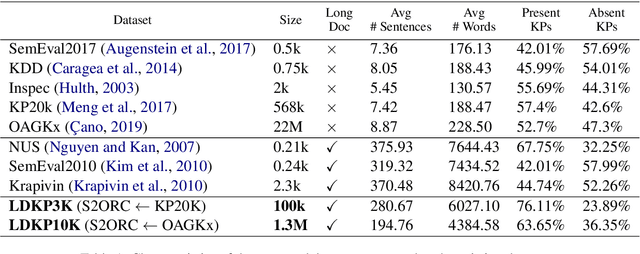
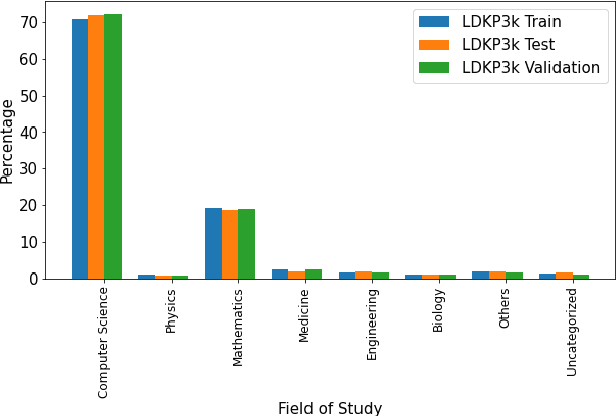
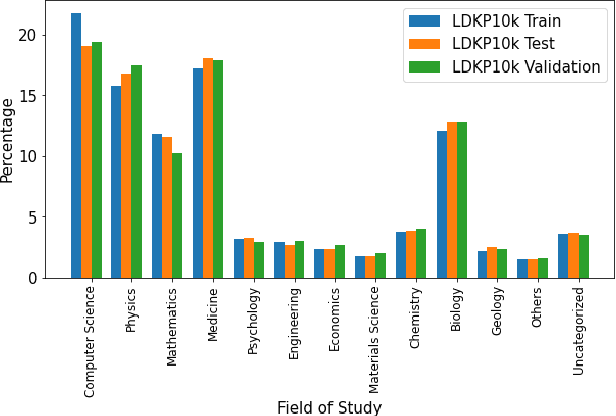
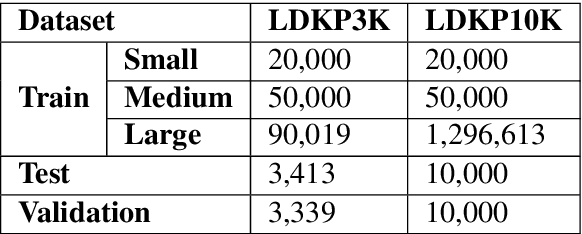
Identifying keyphrases (KPs) from text documents is a fundamental task in natural language processing and information retrieval. Vast majority of the benchmark datasets for this task are from the scientific domain containing only the document title and abstract information. This limits keyphrase extraction (KPE) and keyphrase generation (KPG) algorithms to identify keyphrases from human-written summaries that are often very short (approx 8 sentences). This presents three challenges for real-world applications: human-written summaries are unavailable for most documents, the documents are almost always long, and a high percentage of KPs are directly found beyond the limited context of title and abstract. Therefore, we release two extensive corpora mapping KPs of ~1.3M and ~100K scientific articles with their fully extracted text and additional metadata including publication venue, year, author, field of study, and citations for facilitating research on this real-world problem.