 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Deep Learning Approach to Probabilistic Forecasting of Weather
Mar 24, 2022
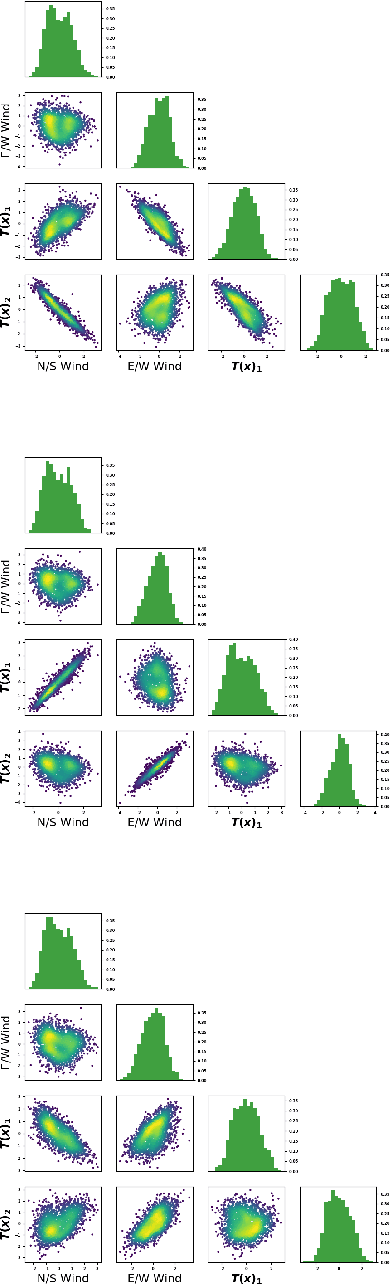
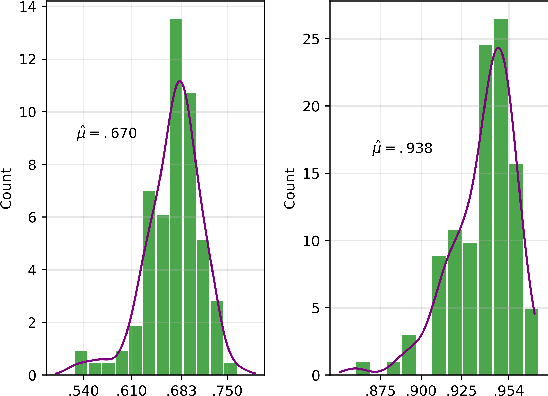
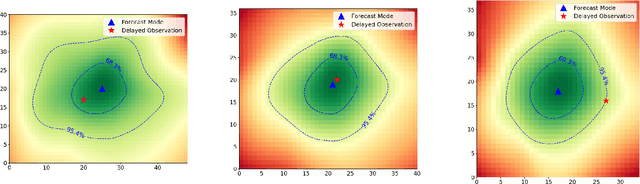
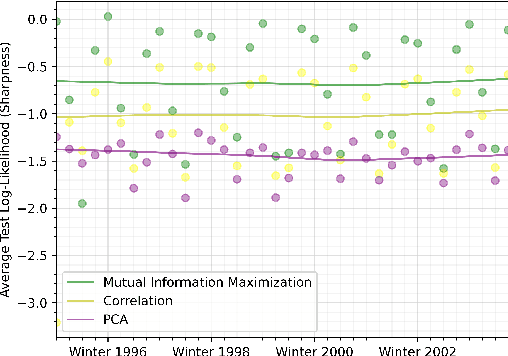
We discuss an approach to probabilistic forecasting based on two chained machine-learning steps: a dimensional reduction step that learns a reduction map of predictor information to a low-dimensional space in a manner designed to preserve information about forecast quantities; and a density estimation step that uses the probabilistic machine learning technique of normalizing flows to compute the joint probability density of reduced predictors and forecast quantities. This joint density is then renormalized to produce the conditional forecast distribution. In this method, probabilistic calibration testing plays the role of a regularization procedure, preventing overfitting in the second step, while effective dimensional reduction from the first step is the source of forecast sharpness. We verify the method using a 22-year 1-hour cadence time series of Weather Research and Forecasting (WRF) simulation data of surface wind on a grid.
Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
May 20, 2022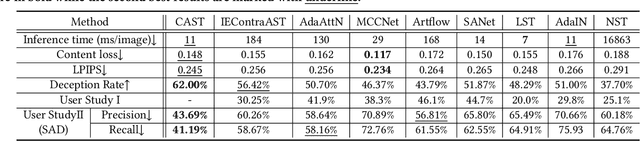

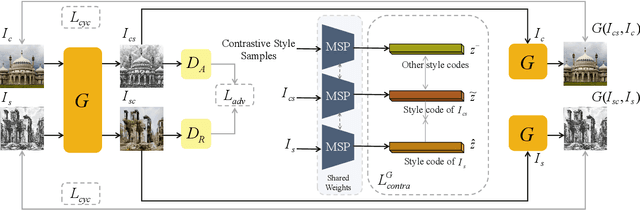
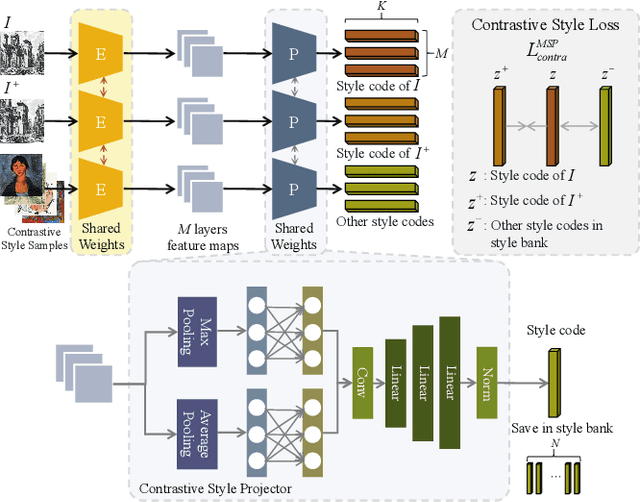
In this work, we tackle the challenging problem of arbitrary image style transfer using a novel style feature representation learning method. A suitable style representation, as a key component in image stylization tasks, is essential to achieve satisfactory results. Existing deep neural network based approaches achieve reasonable results with the guidance from second-order statistics such as Gram matrix of content features. However, they do not leverage sufficient style information, which results in artifacts such as local distortions and style inconsistency. To address these issues, we propose to learn style representation directly from image features instead of their second-order statistics, by analyzing the similarities and differences between multiple styles and considering the style distribution. Specifically, we present Contrastive Arbitrary Style Transfer (CAST), which is a new style representation learning and style transfer method via contrastive learning. Our framework consists of three key components, i.e., a multi-layer style projector for style code encoding, a domain enhancement module for effective learning of style distribution, and a generative network for image style transfer. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results compared to those obtained via state-of-the-art methods. Code and models are available at https://github.com/zyxElsa/CAST_pytorch
Assembly Planning from Observations under Physical Constraints
Apr 20, 2022
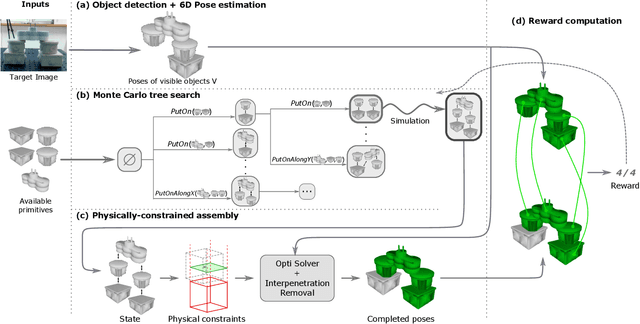


This paper addresses the problem of copying an unknown assembly of primitives with known shape and appearance using information extracted from a single photograph by an off-the-shelf procedure for object detection and pose estimation. The proposed algorithm uses a simple combination of physical stability constraints, convex optimization and Monte Carlo tree search to plan assemblies as sequences of pick-and-place operations represented by STRIPS operators. It is efficient and, most importantly, robust to the errors in object detection and pose estimation unavoidable in any real robotic system. The proposed approach is demonstrated with thorough experiments on a UR5 manipulator.
Confidence-rich Localization and Mapping based on Particle Filter for Robotic Exploration
Mar 07, 2022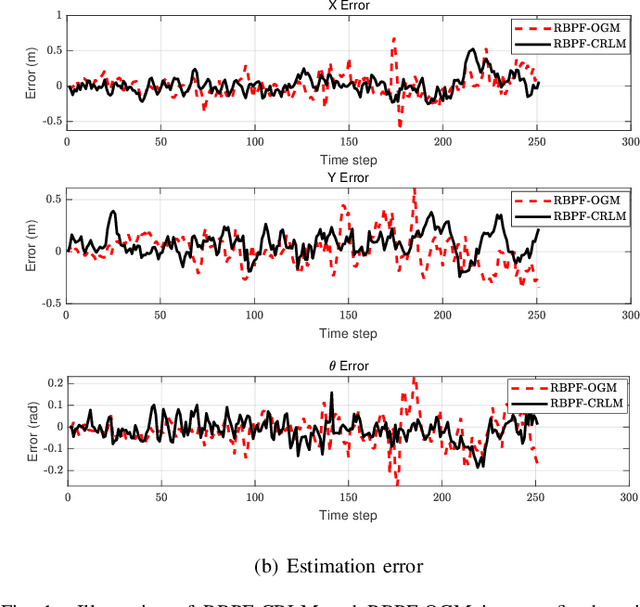
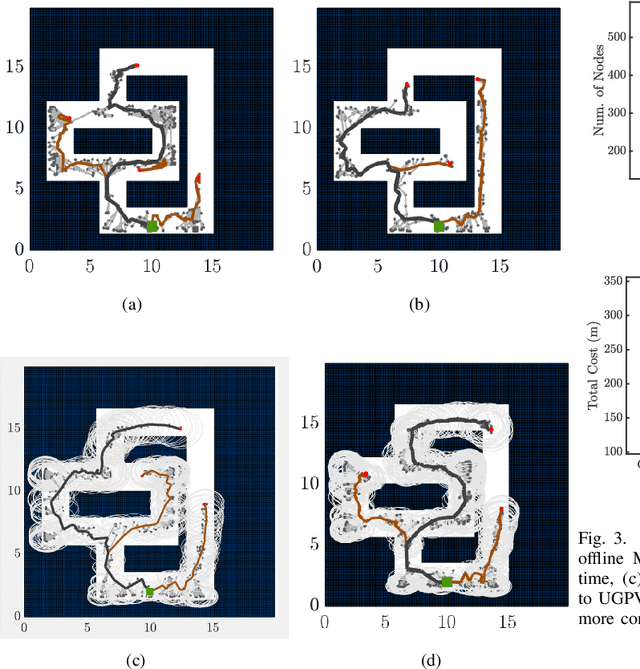
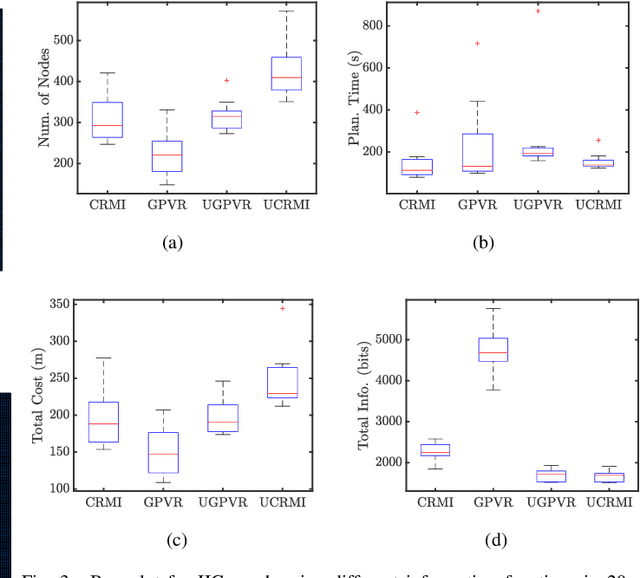
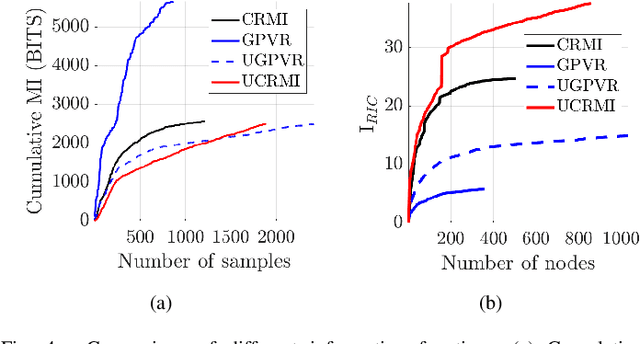
This paper mainly studies the localization and mapping of range sensing robots in the confidence-rich map (CRM), a dense environmental representation with continuous belief, and then extends to information-theoretic exploration to reduce the pose uncertainty. Most previous works about active simultaneous localization and mapping (SLAM) and exploration always assumed the known robot poses or utilized inaccurate information metrics to approximate pose uncertainty, resulting in imbalanced exploration performance and efficiency in the unknown environment. This inspires us to extend the confidence-rich mutual information (CRMI) with measurable pose uncertainty. Specifically, we propose a Rao-Blackwellized particle filter-based localization and mapping scheme (RBPF-CLAM) for CRMs, then we develop a new closed-form weighting method to improve the localization accuracy without scan matching. We further compute the uncertain CRMI (UCRMI) with the weighted particles by a more accurate approximation. Simulations and experimental evaluations show the localization accuracy and exploration performance of the proposed methods in unstructured and confined scenes.
CARNet: A Dynamic Autoencoder for Learning Latent Dynamics in Autonomous Driving Tasks
May 26, 2022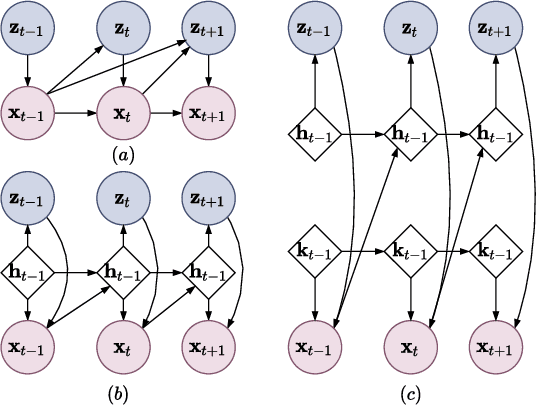


Autonomous driving has received a lot of attention in the automotive industry and is often seen as the future of transportation. Passenger vehicles equipped with a wide array of sensors (e.g., cameras, front-facing radars, LiDARs, and IMUs) capable of continuous perception of the environment are becoming increasingly prevalent. These sensors provide a stream of high-dimensional, temporally correlated data that is essential for reliable autonomous driving. An autonomous driving system should effectively use the information collected from the various sensors in order to form an abstract description of the world and maintain situational awareness. Deep learning models, such as autoencoders, can be used for that purpose, as they can learn compact latent representations from a stream of incoming data. However, most autoencoder models process the data independently, without assuming any temporal interdependencies. Thus, there is a need for deep learning models that explicitly consider the temporal dependence of the data in their architecture. This work proposes CARNet, a Combined dynAmic autoencodeR NETwork architecture that utilizes an autoencoder combined with a recurrent neural network to learn the current latent representation and, in addition, also predict future latent representations in the context of autonomous driving. We demonstrate the efficacy of the proposed model in both imitation and reinforcement learning settings using both simulated and real datasets. Our results show that the proposed model outperforms the baseline state-of-the-art model, while having significantly fewer trainable parameters.
SiPRNet: End-to-End Learning for Single-Shot Phase Retrieval
May 23, 2022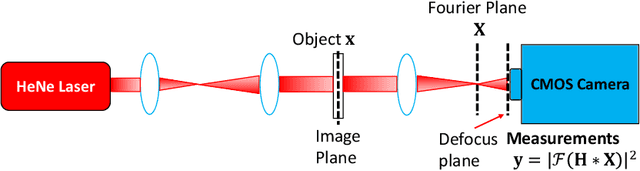
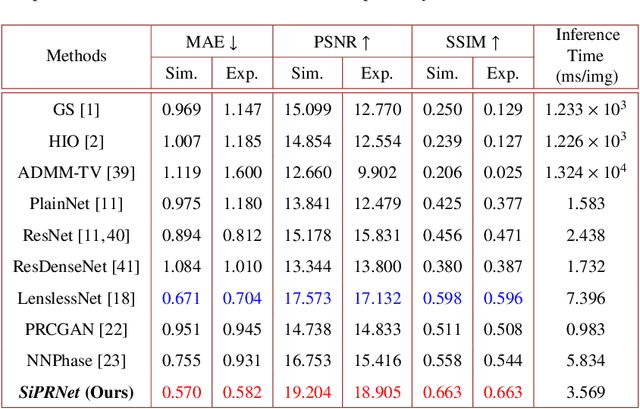
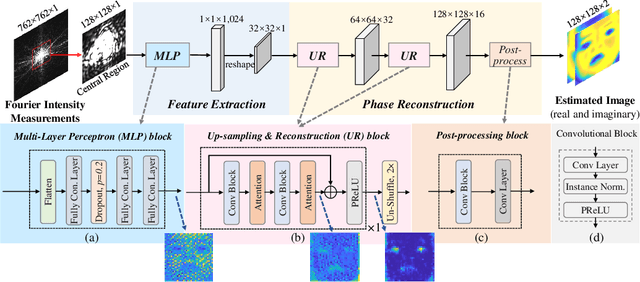
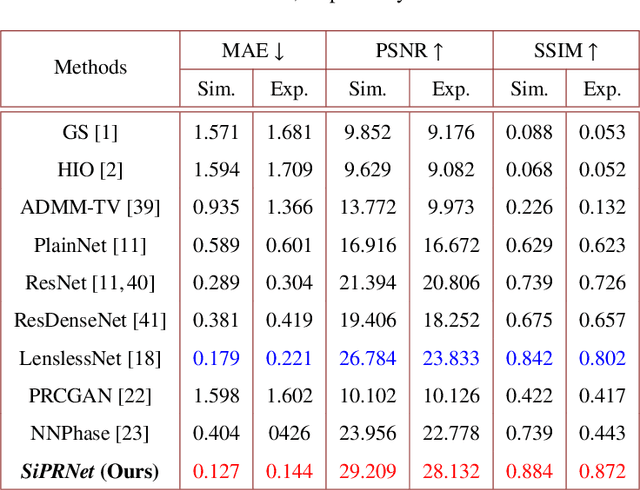
Traditional optimization algorithms have been developed to deal with the phase retrieval problem. However, multiple measurements with different random or non-random masks are needed for giving a satisfactory performance. This brings a burden to the implementation of the algorithms in practical systems. Even worse, expensive optical devices are required to implement the optical masks. Recently, deep learning, especially convolutional neural networks (CNN), has played important roles in various image reconstruction tasks. However, traditional CNN structure fails to reconstruct the original images from their Fourier measurements because of tremendous domain discrepancy. In this paper, we design a novel CNN structure, named SiPRNet, to recover a signal from a single Fourier intensity measurement. To effectively utilize the spectral information of the measurements, we propose a new Multi-Layer Perception block embedded with the dropout layer to extract the global representations. Two Up-sampling and Reconstruction blocks with self-attention are utilized to recover the signals from the extracted features. Extensive evaluations of the proposed model are performed using different testing datasets on both simulation and optical experimentation platforms. The results demonstrate that the proposed approach consistently outperforms other CNN-based and traditional optimization-based methods in single-shot maskless phase retrieval. The source codes of the proposed method have been released on Github: https://github.com/Qiustander/SiPRNet.
A Deep-Learning Usability Expansion Model of Ocean Observations
Jun 03, 2022
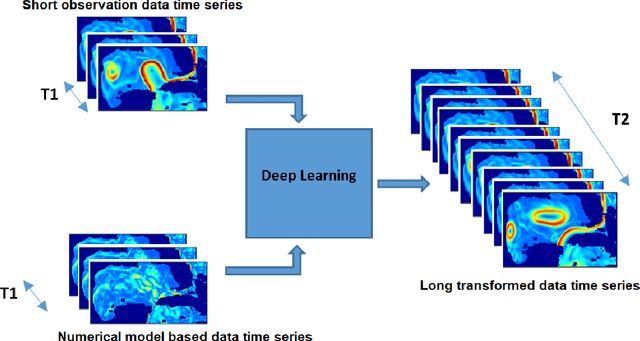
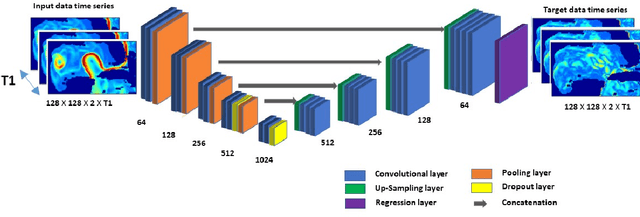
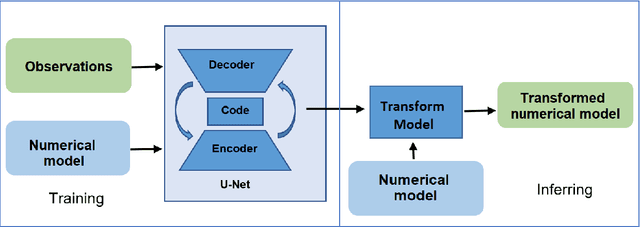
Today's ocean numerical prediction skills depend on the availability of in-situ and remote ocean observations at the time of the predictions only. Because observations are scarce and discontinuous in time and space, numerical models are often unable to accurately model and predict real ocean dynamics, leading to a lack of fulfillment of a range of services that require reliable predictions at various temporal and spatial scales. The process of constraining free numerical models with observations is known as data assimilation. The primary objective is to minimize the misfit of model states with the observations while respecting the rules of physics. The caveat of this approach is that measurements are used only once, at the time of the prediction. The information contained in the history of the measurements and its role in the determinism of the prediction is, therefore, not accounted for. Consequently, historical measurement cannot be used in real-time forecasting systems. The research presented in this paper provides a novel approach rooted in artificial intelligence to expand the usability of observations made before the time of the prediction. Our approach is based on the re-purpose of an existing deep learning model, called U-Net, designed specifically for image segmentation analysis in the biomedical field. U-Net is used here to create a Transform Model that retains the temporal and spatial evolution of the differences between model and observations to produce a correction in the form of regression weights that evolves spatially and temporally with the model both forward and backward in time, beyond the observation period. Using virtual observations, we show that the usability of the observation can be extended up to a one year prior or post observations.
Cross-Supervised Joint-Event-Extraction with Heterogeneous Information Networks
Oct 13, 2020
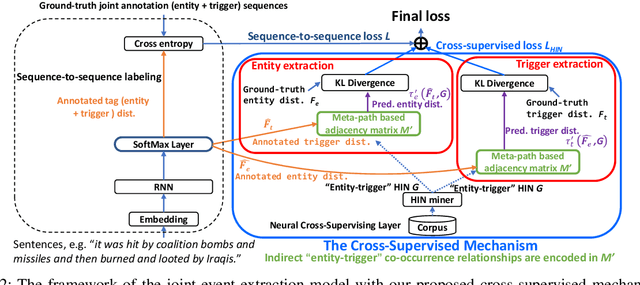
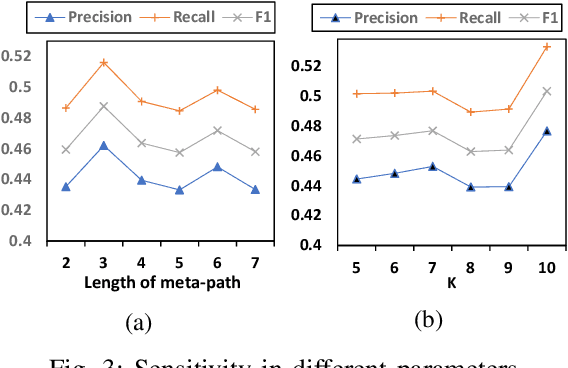

Joint-event-extraction, which extracts structural information (i.e., entities or triggers of events) from unstructured real-world corpora, has attracted more and more research attention in natural language processing. Most existing works do not fully address the sparse co-occurrence relationships between entities and triggers, which loses this important information and thus deteriorates the extraction performance. To mitigate this issue, we first define the joint-event-extraction as a sequence-to-sequence labeling task with a tag set composed of tags of triggers and entities. Then, to incorporate the missing information in the aforementioned co-occurrence relationships, we propose a Cross-Supervised Mechanism (CSM) to alternately supervise the extraction of either triggers or entities based on the type distribution of each other. Moreover, since the connected entities and triggers naturally form a heterogeneous information network (HIN), we leverage the latent pattern along meta-paths for a given corpus to further improve the performance of our proposed method. To verify the effectiveness of our proposed method, we conduct extensive experiments on three real-world datasets as well as compare our method with state-of-the-art methods. Empirical results and analysis show that our approach outperforms the state-of-the-art methods in both entity and trigger extraction.
Your Transformer May Not be as Powerful as You Expect
May 26, 2022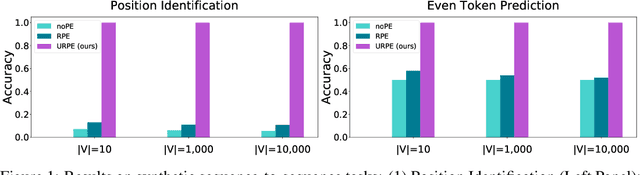
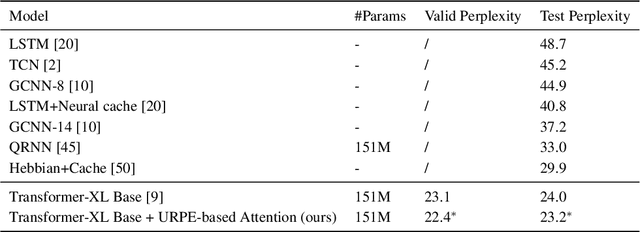
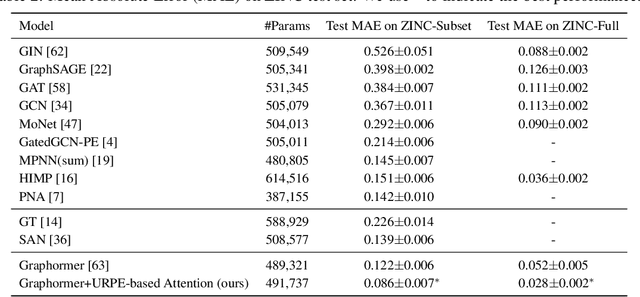
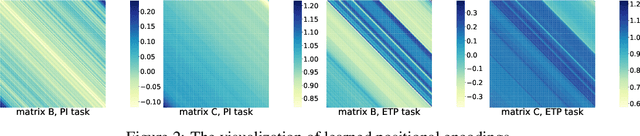
Relative Positional Encoding (RPE), which encodes the relative distance between any pair of tokens, is one of the most successful modifications to the original Transformer. As far as we know, theoretical understanding of the RPE-based Transformers is largely unexplored. In this work, we mathematically analyze the power of RPE-based Transformers regarding whether the model is capable of approximating any continuous sequence-to-sequence functions. One may naturally assume the answer is in the affirmative -- RPE-based Transformers are universal function approximators. However, we present a negative result by showing there exist continuous sequence-to-sequence functions that RPE-based Transformers cannot approximate no matter how deep and wide the neural network is. One key reason lies in that most RPEs are placed in the softmax attention that always generates a right stochastic matrix. This restricts the network from capturing positional information in the RPEs and limits its capacity. To overcome the problem and make the model more powerful, we first present sufficient conditions for RPE-based Transformers to achieve universal function approximation. With the theoretical guidance, we develop a novel attention module, called Universal RPE-based (URPE) Attention, which satisfies the conditions. Therefore, the corresponding URPE-based Transformers become universal function approximators. Extensive experiments covering typical architectures and tasks demonstrate that our model is parameter-efficient and can achieve superior performance to strong baselines in a wide range of applications.
Training Efficient CNNS: Tweaking the Nuts and Bolts of Neural Networks for Lighter, Faster and Robust Models
May 23, 2022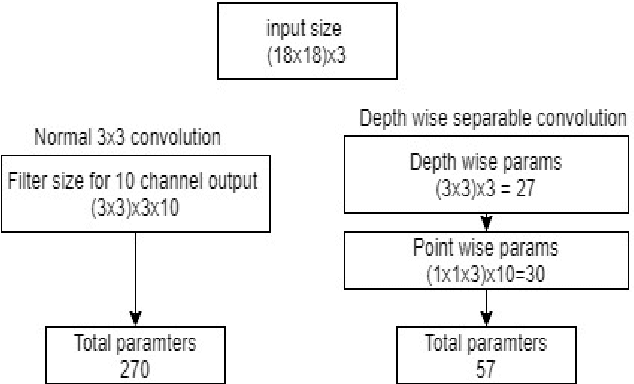
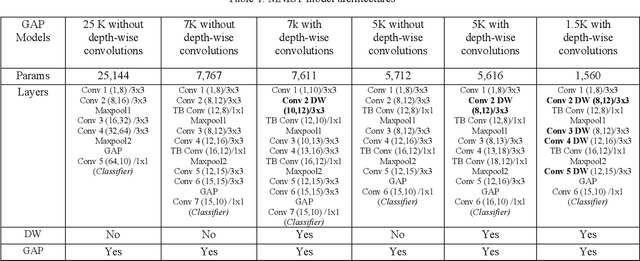
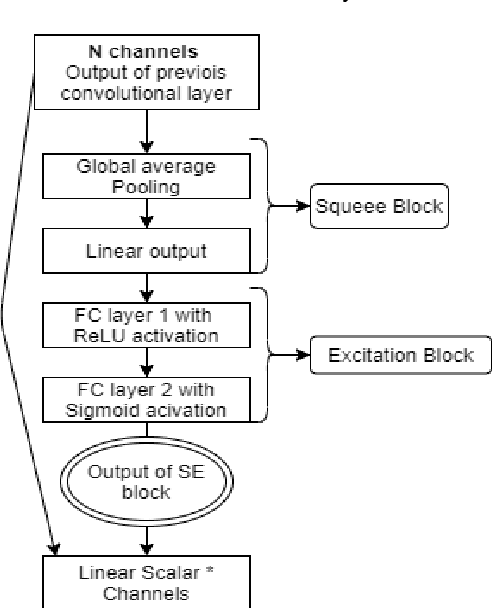
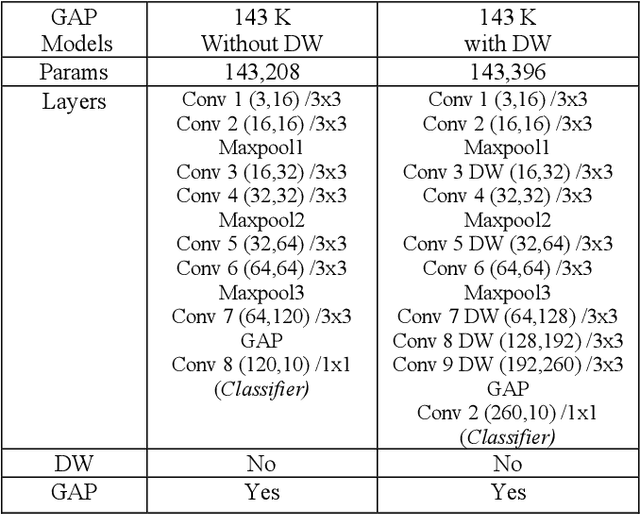
Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. Many techniques have evolved over the past decade that made models lighter, faster, and robust with better generalization. However, many deep learning practitioners persist with pre-trained models and architectures trained mostly on standard datasets such as Imagenet, MS-COCO, IMDB-Wiki Dataset, and Kinetics-700 and are either hesitant or unaware of redesigning the architecture from scratch that will lead to better performance. This scenario leads to inefficient models that are not suitable on various devices such as mobile, edge, and fog. In addition, these conventional training methods are of concern as they consume a lot of computing power. In this paper, we revisit various SOTA techniques that deal with architecture efficiency (Global Average Pooling, depth-wise convolutions & squeeze and excitation, Blurpool), learning rate (Cyclical Learning Rate), data augmentation (Mixup, Cutout), label manipulation (label smoothing), weight space manipulation (stochastic weight averaging), and optimizer (sharpness aware minimization). We demonstrate how an efficient deep convolution network can be built in a phased manner by sequentially reducing the number of training parameters and using the techniques mentioned above. We achieved a SOTA accuracy of 99.2% on MNIST data with just 1500 parameters and an accuracy of 86.01% with just over 140K parameters on the CIFAR-10 dataset.