 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Supervised Machine Learning Approach for Sequence Based Protein-protein Interaction (PPI) Prediction
Mar 27, 2022
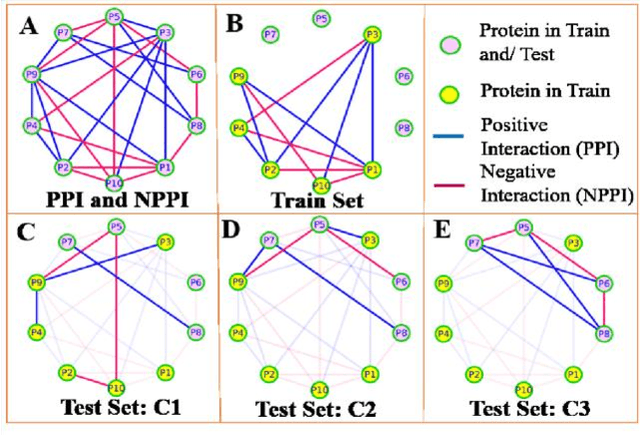
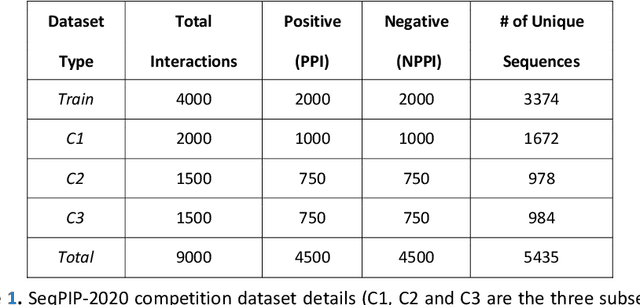
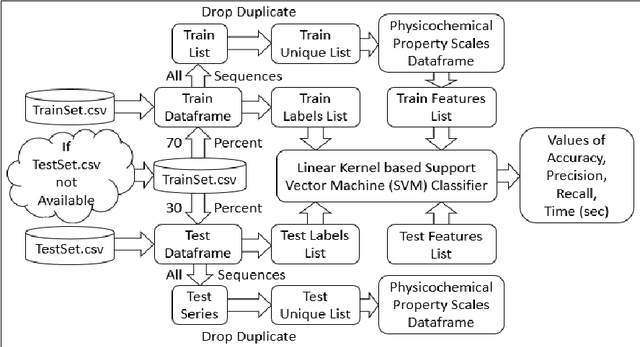
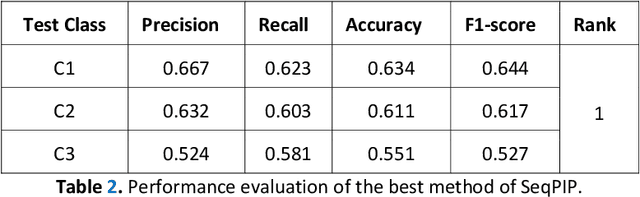
Computational protein-protein interaction (PPI) prediction techniques can contribute greatly in reducing time, cost and false-positive interactions compared to experimental approaches. Sequence is one of the key and primary information of proteins that plays a crucial role in PPI prediction. Several machine learning approaches have been applied to exploit the characteristics of PPI datasets. However, these datasets greatly influence the performance of predicting models. So, care should be taken on both dataset curation as well as design of predictive models. Here, we have described our submitted solution with the results of the SeqPIP competition whose objective was to develop comprehensive PPI predictive models from sequence information with high-quality bias-free interaction datasets. A training set of 2000 positive and 2000 negative interactions with sequences was given to us. Our method was evaluated with three independent high-quality interaction test datasets and with other competitors solutions.
Loco-Manipulation Planning for Legged Robots: Offline and Online Strategies
May 20, 2022
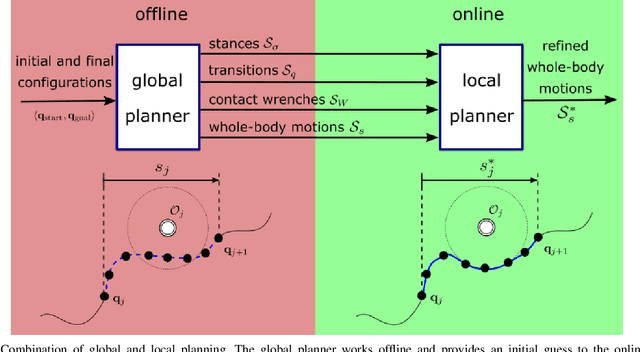

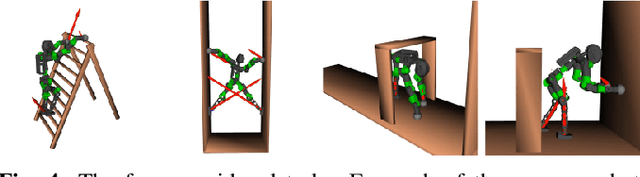
The deployment of robots within realistic environments requires the capability to plan and refine the loco-manipulation trajectories on the fly to avoid unexpected interactions with a dynamic environment. This extended abstract provides a pipeline to offline plan a configuration space global trajectory based on a randomized strategy, and to online locally refine it depending on any change of the dynamic environment and the robot state. The offline planner directly plans in the contact space, and additionally seeks for whole-body feasible configurations compliant with the sampled contact states. The planned trajectory, made by a discrete set of contacts and configurations, can be seen as a graph and it can be online refined during the execution of the global trajectory. The online refinement is carried out by a graph optimization planner exploiting visual information. It locally acts on the global initial plan to account for possible changes in the environment. While the offline planner is a concluded work, tested on the humanoid COMAN+, the online local planner is still a work-in-progress which has been tested on a reduced model of the CENTAURO robot to avoid dynamic and static obstacles interfering with a wheeled motion task. Both the COMAN+ and the CENTAURO robots have been designed at the Italian Institute of Technology (IIT).
Masked Spectrogram Modeling using Masked Autoencoders for Learning General-purpose Audio Representation
Apr 26, 2022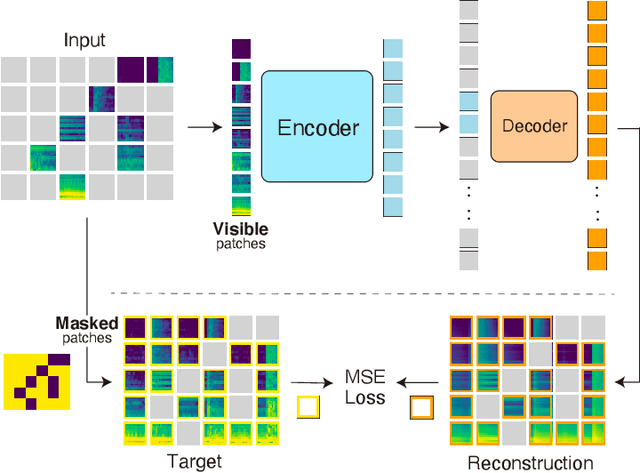
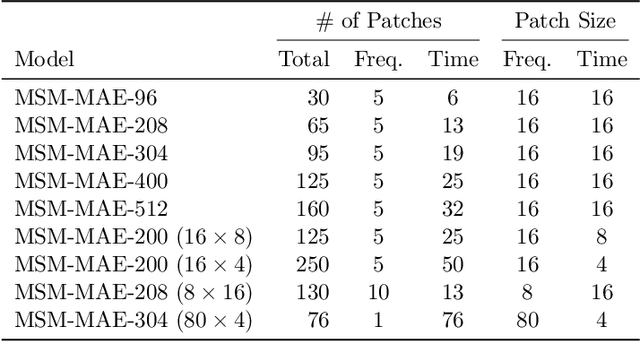
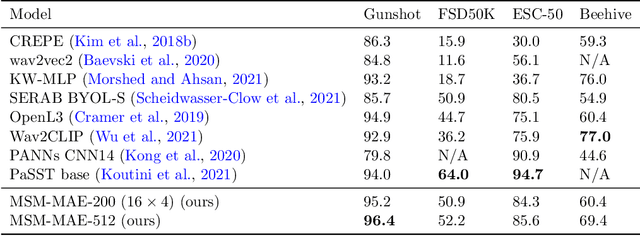
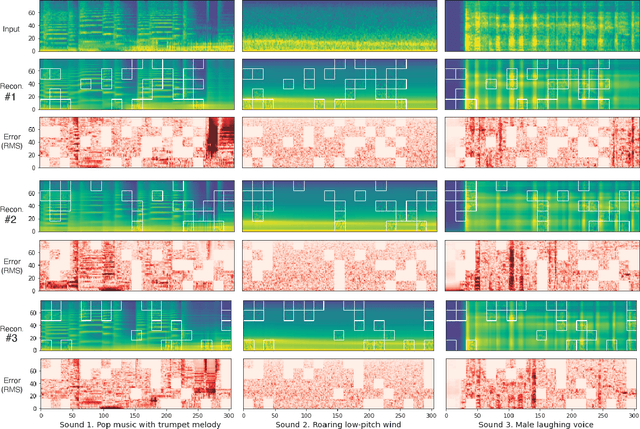
Recent general-purpose audio representations show state-of-the-art performance on various audio tasks. These representations are pre-trained by self-supervised learning methods that create training signals from the input. For example, typical audio contrastive learning uses temporal relationships among input sounds to create training signals, whereas some methods use a difference among input views created by data augmentations. However, these training signals do not provide information derived from the intact input sound, which we think is suboptimal for learning representation that describes the input as it is. In this paper, we seek to learn audio representations from the input itself as supervision using a pretext task of auto-encoding of masked spectrogram patches, Masked Spectrogram Modeling (MSM, a variant of Masked Image Modeling applied to audio spectrogram). To implement MSM, we use Masked Autoencoders (MAE), an image self-supervised learning method. MAE learns to efficiently encode the small number of visible patches into latent representations to carry essential information for reconstructing a large number of masked patches. While training, MAE minimizes the reconstruction error, which uses the input as training signal, consequently achieving our goal. We conducted experiments on our MSM using MAE (MSM-MAE) models under the evaluation benchmark of the HEAR 2021 NeurIPS Challenge. Our MSM-MAE models outperformed the HEAR 2021 Challenge results on seven out of 15 tasks (e.g., accuracies of 73.4% on CREMA-D and 85.8% on LibriCount), while showing top performance on other tasks where specialized models perform better. We also investigate how the design choices of MSM-MAE impact the performance and conduct qualitative analysis of visualization outcomes to gain an understanding of learned representations. We make our code available online.
Do Encoder Representations of Generative Dialogue Models Encode Sufficient Information about the Task ?
Jun 20, 2021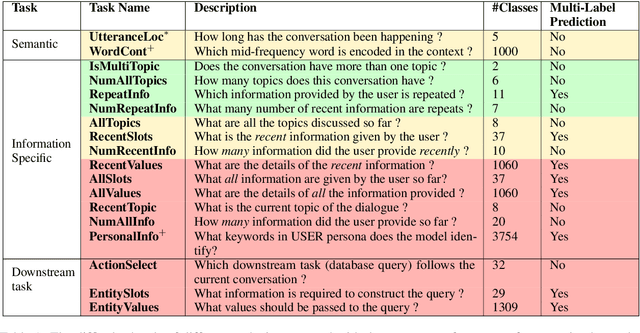
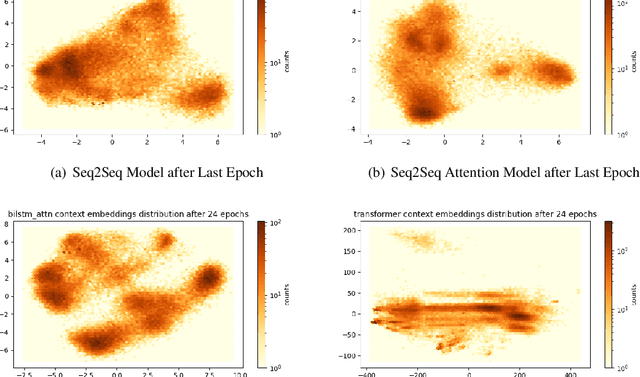
Predicting the next utterance in dialogue is contingent on encoding of users' input text to generate appropriate and relevant response in data-driven approaches. Although the semantic and syntactic quality of the language generated is evaluated, more often than not, the encoded representation of input is not evaluated. As the representation of the encoder is essential for predicting the appropriate response, evaluation of encoder representation is a challenging yet important problem. In this work, we showcase evaluating the text generated through human or automatic metrics is not sufficient to appropriately evaluate soundness of the language understanding of dialogue models and, to that end, propose a set of probe tasks to evaluate encoder representation of different language encoders commonly used in dialogue models. From experiments, we observe that some of the probe tasks are easier and some are harder for even sophisticated model architectures to learn. And, through experiments we observe that RNN based architectures have lower performance on automatic metrics on text generation than transformer model but perform better than the transformer model on the probe tasks indicating that RNNs might preserve task information better than the Transformers.
A Nonlocal Graph-PDE and Higher-Order Geometric Integration for Image Labeling
May 09, 2022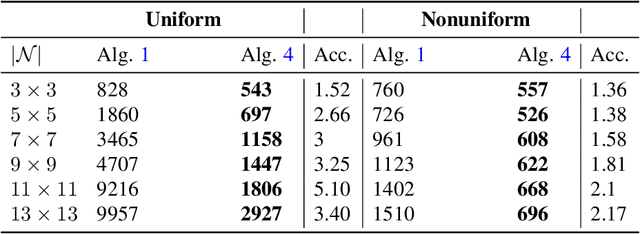
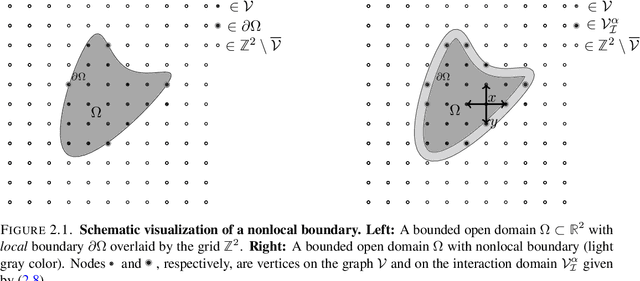
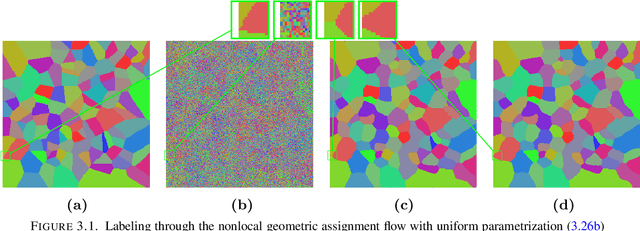
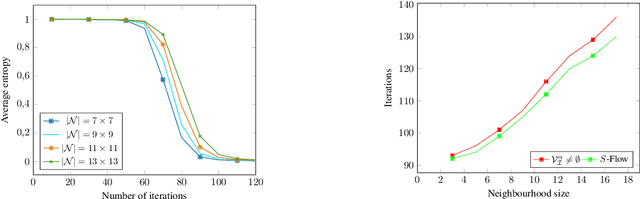
This paper introduces a novel nonlocal partial difference equation (PDE) for labeling metric data on graphs. The PDE is derived as nonlocal reparametrization of the assignment flow approach that was introduced in \textit{J.~Math.~Imaging \& Vision} 58(2), 2017. Due to this parameterization, solving the PDE numerically is shown to be equivalent to computing the Riemannian gradient flow with respect to a nonconvex potential. We devise an entropy-regularized difference-of-convex-functions (DC) decomposition of this potential and show that the basic geometric Euler scheme for integrating the assignment flow is equivalent to solving the PDE by an established DC programming scheme. Moreover, the viewpoint of geometric integration reveals a basic way to exploit higher-order information of the vector field that drives the assignment flow, in order to devise a novel accelerated DC programming scheme. A detailed convergence analysis of both numerical schemes is provided and illustrated by numerical experiments.
A Deep-Learning Usability Expansion Model of Ocean Observations
Jun 03, 2022
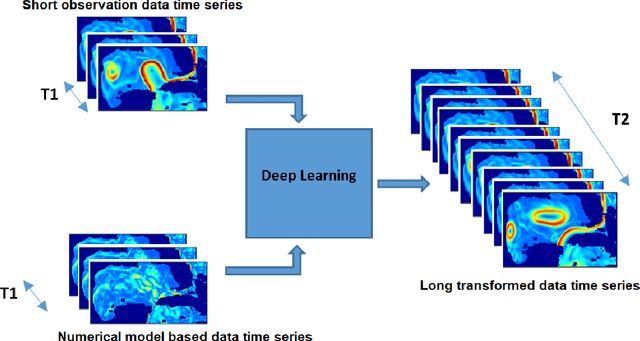
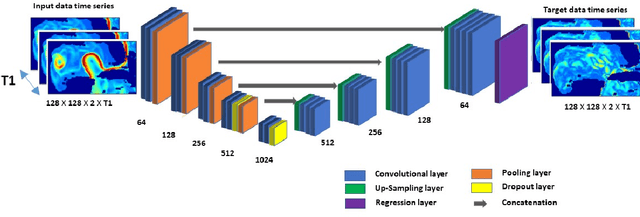
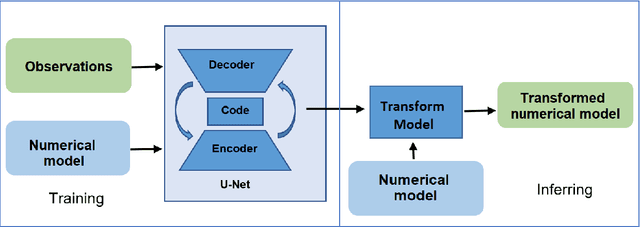
Today's ocean numerical prediction skills depend on the availability of in-situ and remote ocean observations at the time of the predictions only. Because observations are scarce and discontinuous in time and space, numerical models are often unable to accurately model and predict real ocean dynamics, leading to a lack of fulfillment of a range of services that require reliable predictions at various temporal and spatial scales. The process of constraining free numerical models with observations is known as data assimilation. The primary objective is to minimize the misfit of model states with the observations while respecting the rules of physics. The caveat of this approach is that measurements are used only once, at the time of the prediction. The information contained in the history of the measurements and its role in the determinism of the prediction is, therefore, not accounted for. Consequently, historical measurement cannot be used in real-time forecasting systems. The research presented in this paper provides a novel approach rooted in artificial intelligence to expand the usability of observations made before the time of the prediction. Our approach is based on the re-purpose of an existing deep learning model, called U-Net, designed specifically for image segmentation analysis in the biomedical field. U-Net is used here to create a Transform Model that retains the temporal and spatial evolution of the differences between model and observations to produce a correction in the form of regression weights that evolves spatially and temporally with the model both forward and backward in time, beyond the observation period. Using virtual observations, we show that the usability of the observation can be extended up to a one year prior or post observations.
BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis
Apr 06, 2022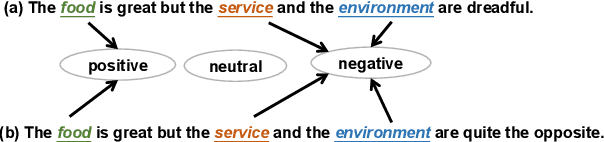
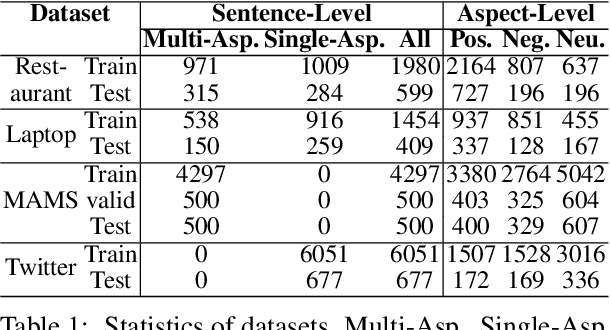
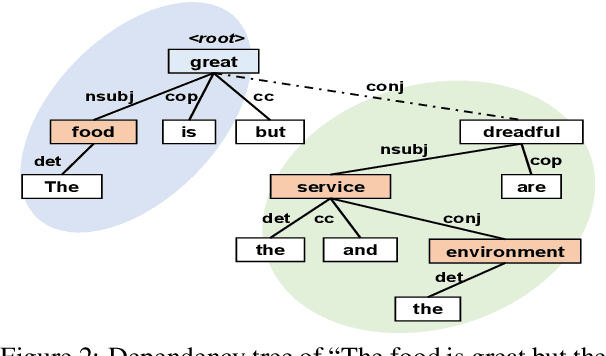
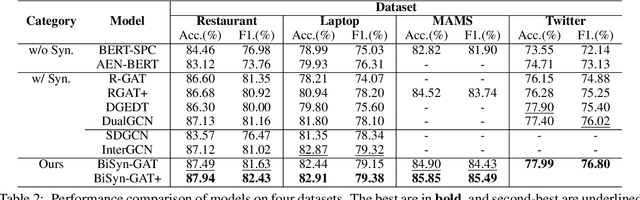
Aspect-based sentiment analysis (ABSA) is a fine-grained sentiment analysis task that aims to align aspects and corresponding sentiments for aspect-specific sentiment polarity inference. It is challenging because a sentence may contain multiple aspects or complicated (e.g., conditional, coordinating, or adversative) relations. Recently, exploiting dependency syntax information with graph neural networks has been the most popular trend. Despite its success, methods that heavily rely on the dependency tree pose challenges in accurately modeling the alignment of the aspects and their words indicative of sentiment, since the dependency tree may provide noisy signals of unrelated associations (e.g., the "conj" relation between "great" and "dreadful" in Figure 2). In this paper, to alleviate this problem, we propose a Bi-Syntax aware Graph Attention Network (BiSyn-GAT+). Specifically, BiSyn-GAT+ fully exploits the syntax information (e.g., phrase segmentation and hierarchical structure) of the constituent tree of a sentence to model the sentiment-aware context of every single aspect (called intra-context) and the sentiment relations across aspects (called inter-context) for learning. Experiments on four benchmark datasets demonstrate that BiSyn-GAT+ outperforms the state-of-the-art methods consistently.
Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
May 20, 2022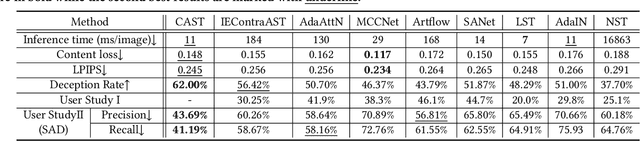

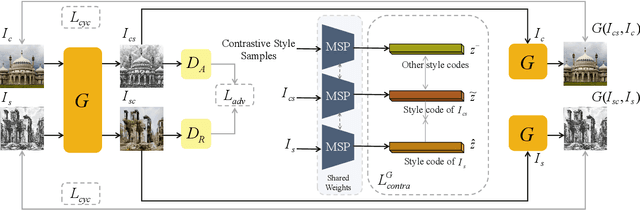
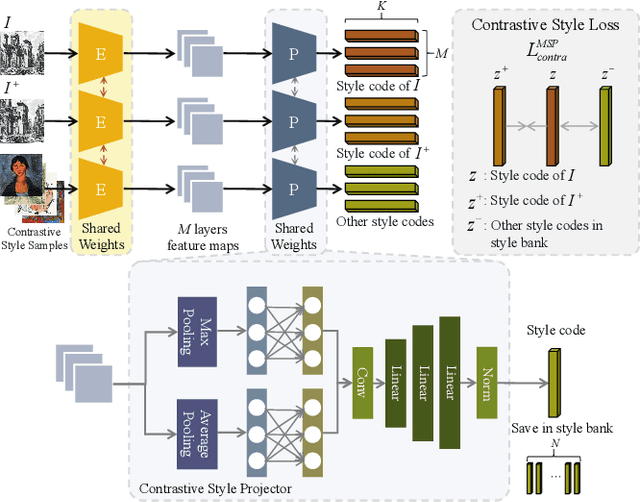
In this work, we tackle the challenging problem of arbitrary image style transfer using a novel style feature representation learning method. A suitable style representation, as a key component in image stylization tasks, is essential to achieve satisfactory results. Existing deep neural network based approaches achieve reasonable results with the guidance from second-order statistics such as Gram matrix of content features. However, they do not leverage sufficient style information, which results in artifacts such as local distortions and style inconsistency. To address these issues, we propose to learn style representation directly from image features instead of their second-order statistics, by analyzing the similarities and differences between multiple styles and considering the style distribution. Specifically, we present Contrastive Arbitrary Style Transfer (CAST), which is a new style representation learning and style transfer method via contrastive learning. Our framework consists of three key components, i.e., a multi-layer style projector for style code encoding, a domain enhancement module for effective learning of style distribution, and a generative network for image style transfer. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results compared to those obtained via state-of-the-art methods. Code and models are available at https://github.com/zyxElsa/CAST_pytorch
CARNet: A Dynamic Autoencoder for Learning Latent Dynamics in Autonomous Driving Tasks
May 26, 2022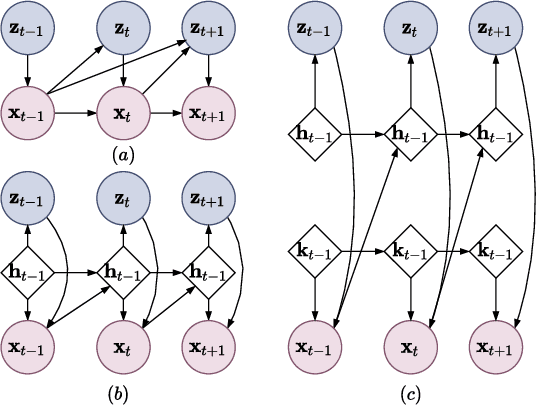
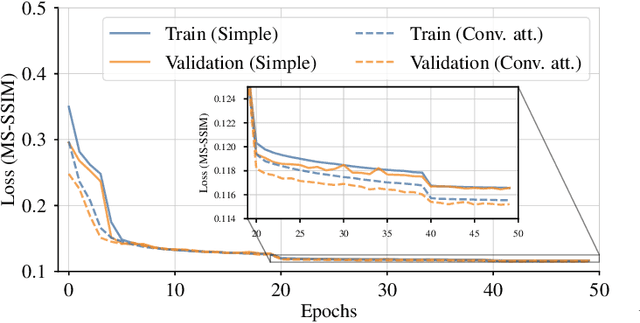


Autonomous driving has received a lot of attention in the automotive industry and is often seen as the future of transportation. Passenger vehicles equipped with a wide array of sensors (e.g., cameras, front-facing radars, LiDARs, and IMUs) capable of continuous perception of the environment are becoming increasingly prevalent. These sensors provide a stream of high-dimensional, temporally correlated data that is essential for reliable autonomous driving. An autonomous driving system should effectively use the information collected from the various sensors in order to form an abstract description of the world and maintain situational awareness. Deep learning models, such as autoencoders, can be used for that purpose, as they can learn compact latent representations from a stream of incoming data. However, most autoencoder models process the data independently, without assuming any temporal interdependencies. Thus, there is a need for deep learning models that explicitly consider the temporal dependence of the data in their architecture. This work proposes CARNet, a Combined dynAmic autoencodeR NETwork architecture that utilizes an autoencoder combined with a recurrent neural network to learn the current latent representation and, in addition, also predict future latent representations in the context of autonomous driving. We demonstrate the efficacy of the proposed model in both imitation and reinforcement learning settings using both simulated and real datasets. Our results show that the proposed model outperforms the baseline state-of-the-art model, while having significantly fewer trainable parameters.
Vocalsound: A Dataset for Improving Human Vocal Sounds Recognition
May 06, 2022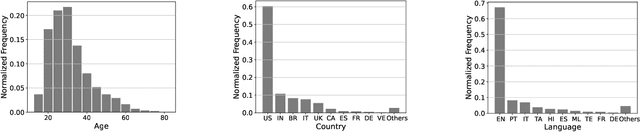
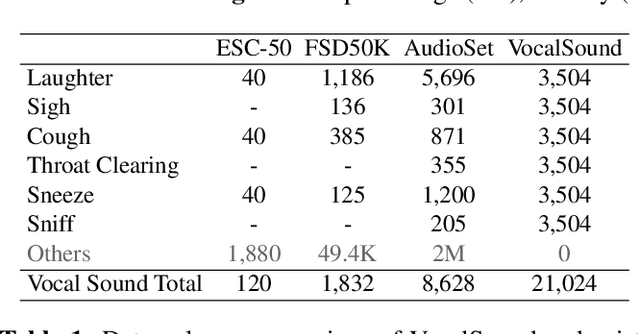
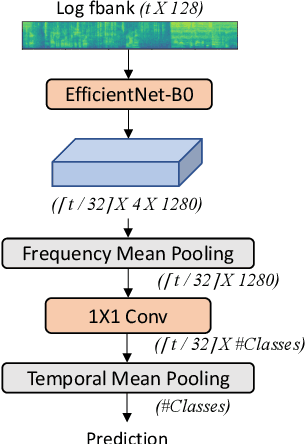
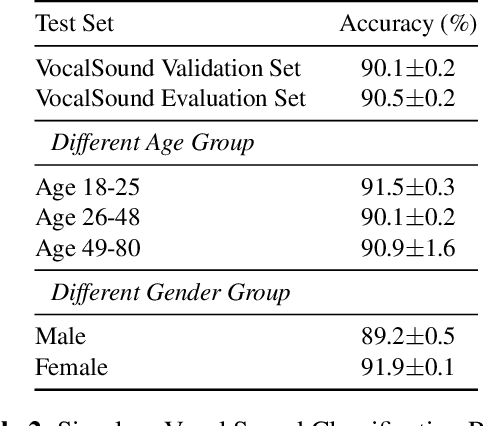
Recognizing human non-speech vocalizations is an important task and has broad applications such as automatic sound transcription and health condition monitoring. However, existing datasets have a relatively small number of vocal sound samples or noisy labels. As a consequence, state-of-the-art audio event classification models may not perform well in detecting human vocal sounds. To support research on building robust and accurate vocal sound recognition, we have created a VocalSound dataset consisting of over 21,000 crowdsourced recordings of laughter, sighs, coughs, throat clearing, sneezes, and sniffs from 3,365 unique subjects. Experiments show that the vocal sound recognition performance of a model can be significantly improved by 41.9% by adding VocalSound dataset to an existing dataset as training material. In addition, different from previous datasets, the VocalSound dataset contains meta information such as speaker age, gender, native language, country, and health condition.