 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local Attention Graph-based Transformer for Multi-target Genetic Alteration Prediction
May 13, 2022
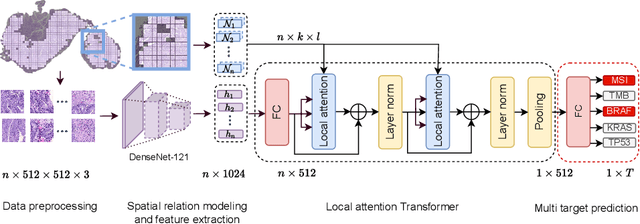

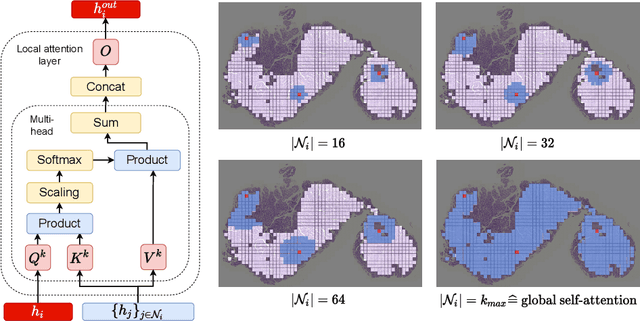
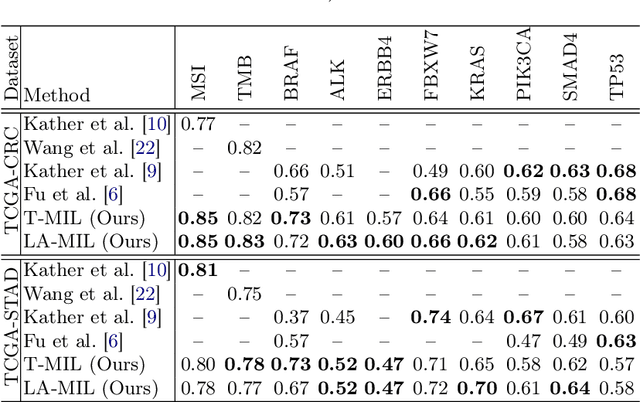
Classical multiple instance learning (MIL) methods are often based on the identical and independent distributed assumption between instances, hence neglecting the potentially rich contextual information beyond individual entities. On the other hand, Transformers with global self-attention modules have been proposed to model the interdependencies among all instances. However, in this paper we question: Is global relation modeling using self-attention necessary, or can we appropriately restrict self-attention calculations to local regimes in large-scale whole slide images (WSIs)? We propose a general-purpose local attention graph-based Transformer for MIL (LA-MIL), introducing an inductive bias by explicitly contextualizing instances in adaptive local regimes of arbitrary size. Additionally, an efficiently adapted loss function enables our approach to learn expressive WSI embeddings for the joint analysis of multiple biomarkers. We demonstrate that LA-MIL achieves state-of-the-art results in mutation prediction for gastrointestinal cancer, outperforming existing models on important biomarkers such as microsatellite instability for colorectal cancer. This suggests that local self-attention sufficiently models dependencies on par with global modules. Our implementation will be published.
An Information Retrieval Approach to Building Datasets for Hate Speech Detection
Jun 21, 2021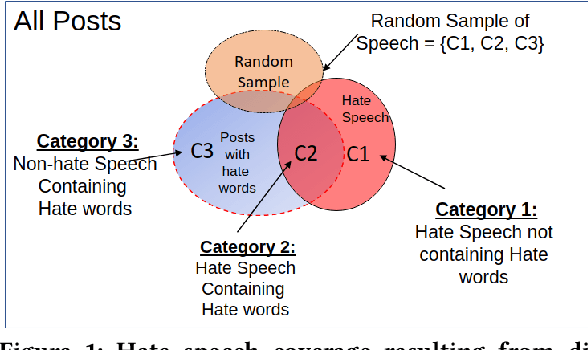

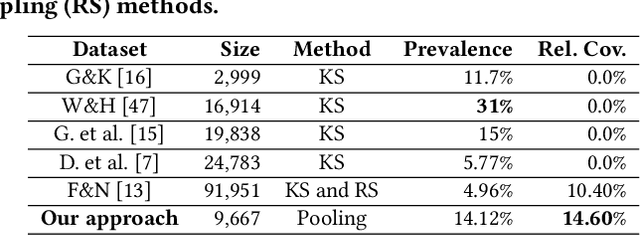
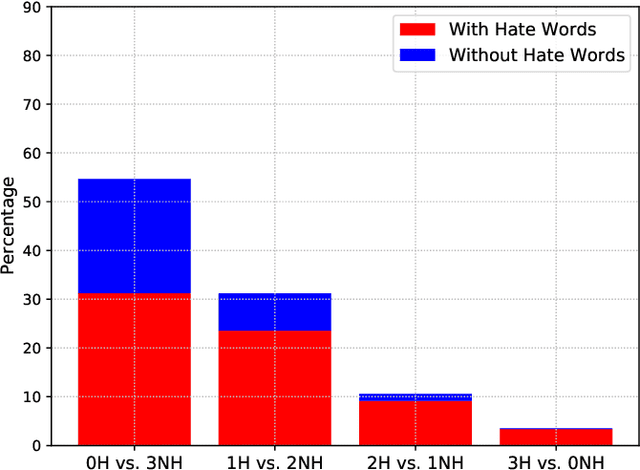
Building a benchmark dataset for hate speech detection presents several challenges. Firstly, because hate speech is relatively rare -- e.g., less than 3\% of Twitter posts are hateful \citep{founta2018large} -- random sampling of tweets to annotate is inefficient in capturing hate speech. A common practice is to only annotate tweets containing known ``hate words'', but this risks yielding a biased benchmark that only partially captures the real-world phenomenon of interest. A second challenge is that definitions of hate speech tend to be highly variable and subjective. Annotators having diverse prior notions of hate speech may not only disagree with one another but also struggle to conform to specified labeling guidelines. Our key insight is that the rarity and subjectivity of hate speech are akin to that of relevance in information retrieval (IR). This connection suggests that well-established methodologies for creating IR test collections might also be usefully applied to create better benchmark datasets for hate speech detection. Firstly, to intelligently and efficiently select which tweets to annotate, we apply established IR techniques of {\em pooling} and {\em active learning}. Secondly, to improve both consistency and value of annotations, we apply {\em task decomposition} \cite{Zhang-sigir14} and {\em annotator rationale} \cite{mcdonnell16-hcomp} techniques. Using the above techniques, we create and share a new benchmark dataset\footnote{We will release the dataset upon publication.} for hate speech detection with broader coverage than prior datasets. We also show a dramatic drop in accuracy of existing detection models when tested on these broader forms of hate. Collected annotator rationales not only provide documented support for labeling decisions but also create exciting future work opportunities for dual-supervision and/or explanation generation in modeling.
RCP: Recurrent Closest Point for Scene Flow Estimation on 3D Point Clouds
May 24, 2022
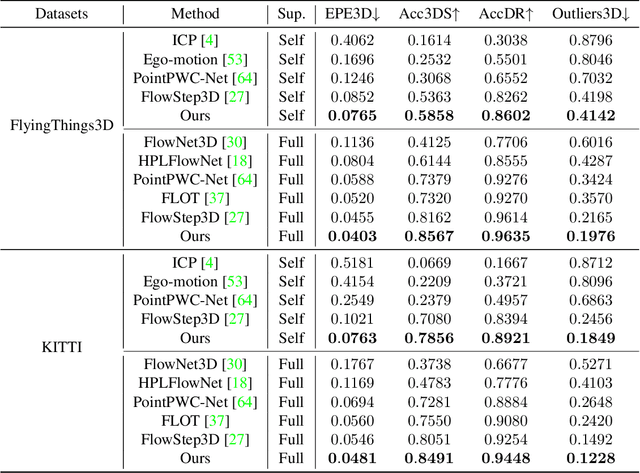
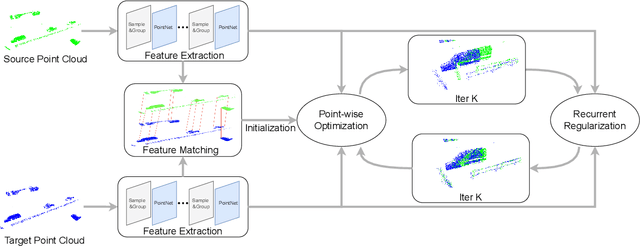
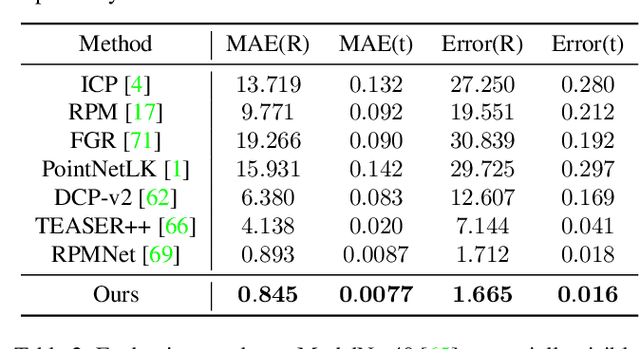
3D motion estimation including scene flow and point cloud registration has drawn increasing interest. Inspired by 2D flow estimation, recent methods employ deep neural networks to construct the cost volume for estimating accurate 3D flow. However, these methods are limited by the fact that it is difficult to define a search window on point clouds because of the irregular data structure. In this paper, we avoid this irregularity by a simple yet effective method.We decompose the problem into two interlaced stages, where the 3D flows are optimized point-wisely at the first stage and then globally regularized in a recurrent network at the second stage. Therefore, the recurrent network only receives the regular point-wise information as the input. In the experiments, we evaluate the proposed method on both the 3D scene flow estimation and the point cloud registration task. For 3D scene flow estimation, we make comparisons on the widely used FlyingThings3D and KITTIdatasets. For point cloud registration, we follow previous works and evaluate the data pairs with large pose and partially overlapping from ModelNet40. The results show that our method outperforms the previous method and achieves a new state-of-the-art performance on both 3D scene flow estimation and point cloud registration, which demonstrates the superiority of the proposed zero-order method on irregular point cloud data.
A Dataset for N-ary Relation Extraction of Drug Combinations
May 04, 2022

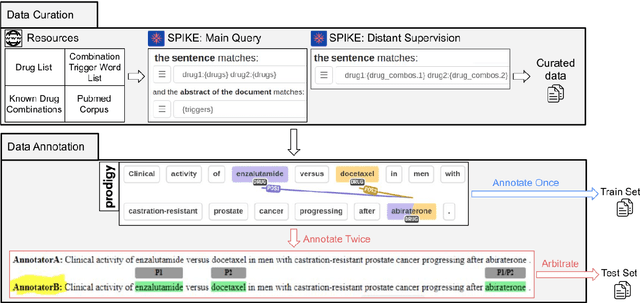
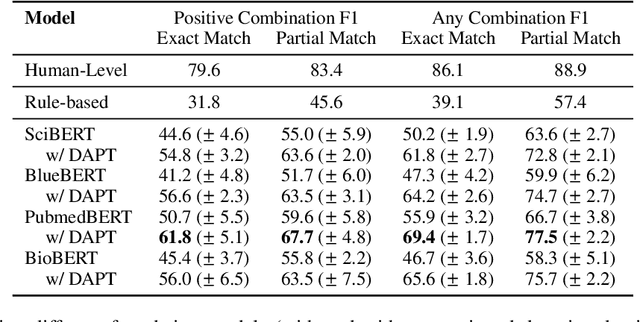
Combination therapies have become the standard of care for diseases such as cancer, tuberculosis, malaria and HIV. However, the combinatorial set of available multi-drug treatments creates a challenge in identifying effective combination therapies available in a situation. To assist medical professionals in identifying beneficial drug-combinations, we construct an expert-annotated dataset for extracting information about the efficacy of drug combinations from the scientific literature. Beyond its practical utility, the dataset also presents a unique NLP challenge, as the first relation extraction dataset consisting of variable-length relations. Furthermore, the relations in this dataset predominantly require language understanding beyond the sentence level, adding to the challenge of this task. We provide a promising baseline model and identify clear areas for further improvement. We release our dataset, code, and baseline models publicly to encourage the NLP community to participate in this task.
Initial Access for Millimeter-Wave and Terahertz Communications with Hybrid Beamforming
May 02, 2022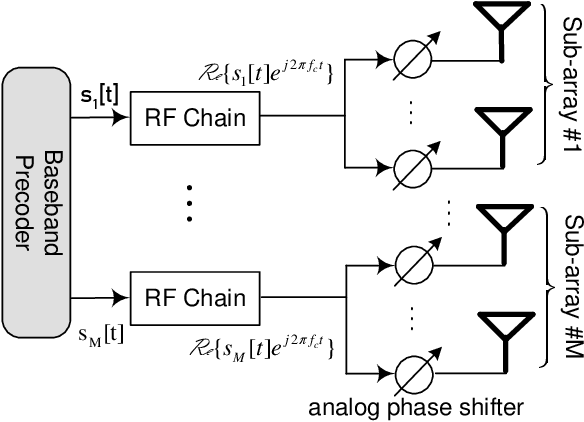

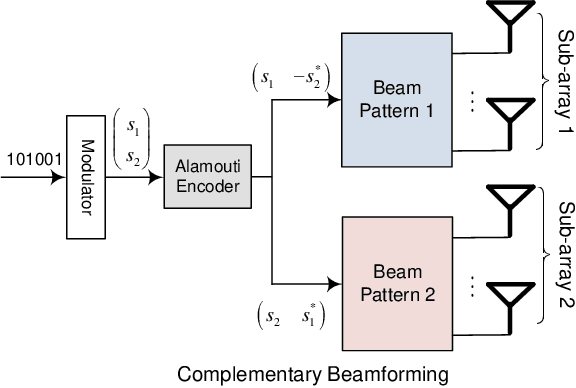
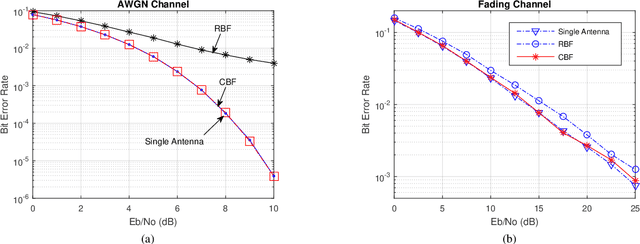
In order to achieve terabits-per-second (Tbps) data rates in the sixth-generation (6G) mobile system, wireless communications are required to exploit the abundant spectrum in the millimeter-wave (mmWave) and terahertz (THz) bands. However, high-frequency transmission heavily relies on high beamforming gain to compensate for severe propagation loss. A beam-based system faces a barrier in the process of initial access, where a base station must broadcast synchronization signals and system information to all users within its coverage. Hence, this paper proposes a novel omnidirectional broadcasting scheme for mmWave and THz systems with hybrid beamforming. It provides an instantaneously equal gain over all directions by forming complementary beams over sub-arrays. Numerical results verify that it can achieve omnidirectional coverage with a performance that remarkably outperforms the previous scheme.
Finding patterns in Knowledge Attribution for Transformers
May 04, 2022
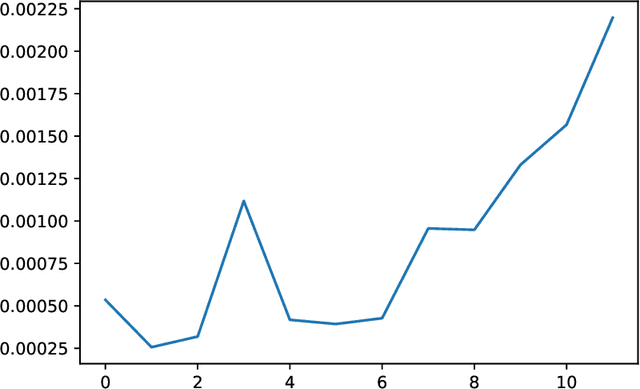
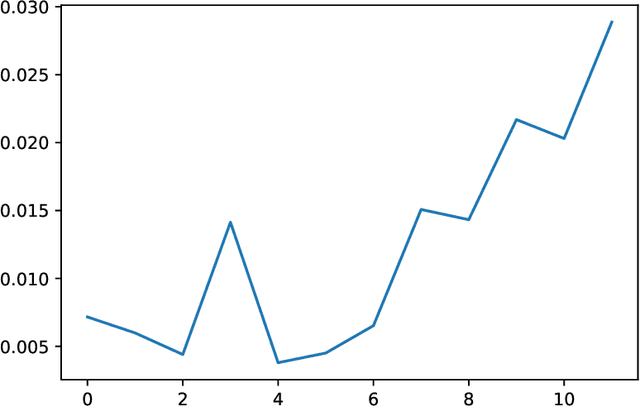
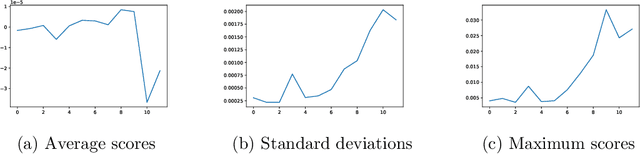
We analyze the Knowledge Neurons framework for the attribution of factual and relational knowledge to particular neurons in the transformer network. We use a 12-layer multi-lingual BERT model for our experiments. Our study reveals various interesting phenomena. We observe that mostly factual knowledge can be attributed to middle and higher layers of the network($\ge 6$). Further analysis reveals that the middle layers($6-9$) are mostly responsible for relational information, which is further refined into actual factual knowledge or the "correct answer" in the last few layers($10-12$). Our experiments also show that the model handles prompts in different languages, but representing the same fact, similarly, providing further evidence for effectiveness of multi-lingual pre-training. Applying the attribution scheme for grammatical knowledge, we find that grammatical knowledge is far more dispersed among the neurons than factual knowledge.
BronchusNet: Region and Structure Prior Embedded Representation Learning for Bronchus Segmentation and Classification
May 24, 2022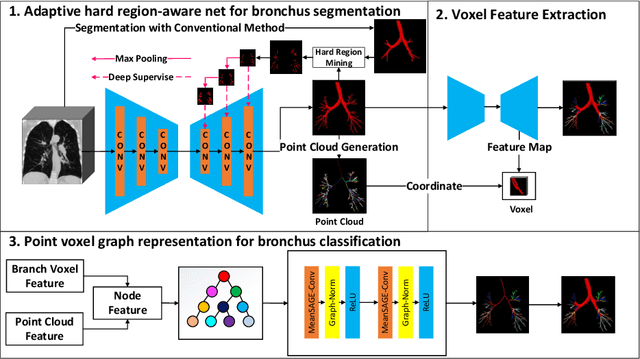


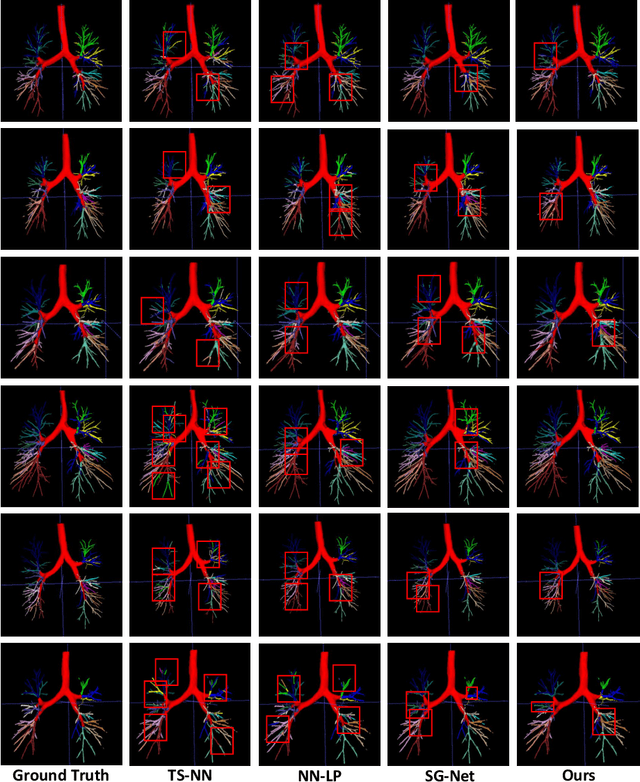
CT-based bronchial tree analysis plays an important role in the computer-aided diagnosis for respiratory diseases, as it could provide structured information for clinicians. The basis of airway analysis is bronchial tree reconstruction, which consists of bronchus segmentation and classification. However, there remains a challenge for accurate bronchial analysis due to the individual variations and the severe class imbalance. In this paper, we propose a region and structure prior embedded framework named BronchusNet to achieve accurate segmentation and classification of bronchial regions in CT images. For bronchus segmentation, we propose an adaptive hard region-aware UNet that incorporates multi-level prior guidance of hard pixel-wise samples in the general Unet segmentation network to achieve better hierarchical feature learning. For the classification of bronchial branches, we propose a hybrid point-voxel graph learning module to fully exploit bronchial structure priors and to support simultaneous feature interactions across different branches. To facilitate the study of bronchial analysis, we contribute~\textbf{BRSC}: an open-access benchmark of \textbf{BR}onchus imaging analysis with high-quality pixel-wise \textbf{S}egmentation masks and the \textbf{C}lass of bronchial segments. Experimental results on BRSC show that our proposed method not only achieves the state-of-the-art performance for binary segmentation of bronchial region but also exceeds the best existing method on bronchial branches classification by 6.9\%.
ES-GNN: Generalizing Graph Neural Networks Beyond Homophily with Edge Splitting
May 27, 2022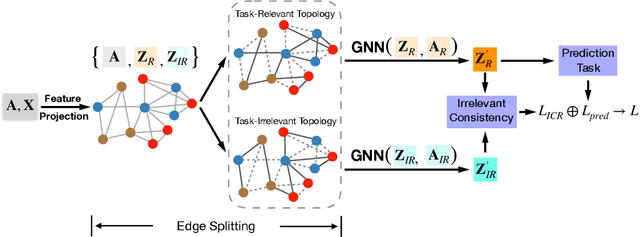
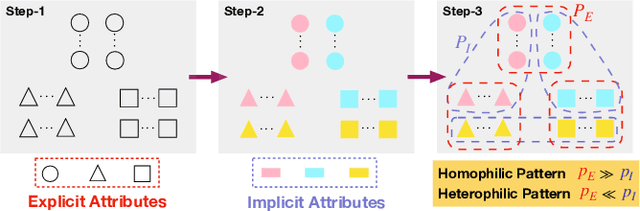
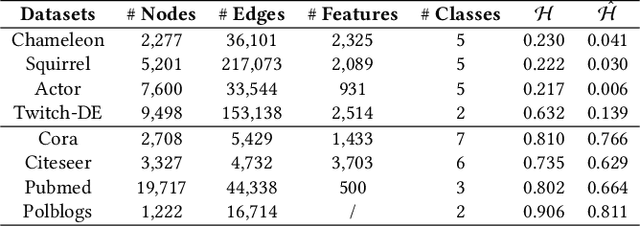
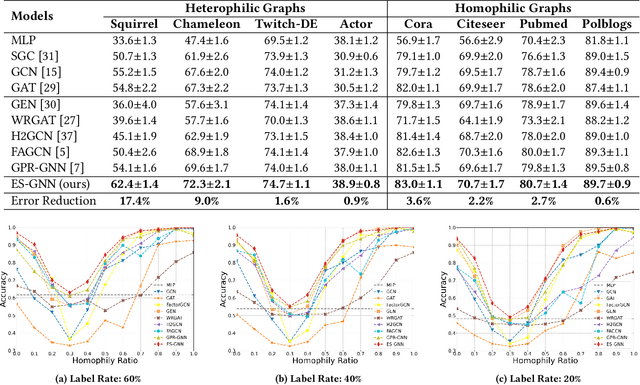
Graph Neural Networks (GNNs) have achieved enormous success in tackling analytical problems on graph data. Most GNNs interpret nearly all the node connections as inductive bias with feature smoothness, and implicitly assume strong homophily on the observed graph. However, real-world networks are not always homophilic, but sometimes exhibit heterophilic patterns where adjacent nodes share dissimilar attributes and distinct labels. Therefore,GNNs smoothing the node proximity holistically may aggregate inconsistent information arising from both task-relevant and irrelevant connections. In this paper, we propose a novel edge splitting GNN (ES-GNN) framework, which generalizes GNNs beyond homophily by jointly partitioning network topology and disentangling node features. Specifically, the proposed framework employs an interpretable operation to adaptively split the set of edges of the original graph into two exclusive sets indicating respectively the task-relevant and irrelevant relations among nodes. The node features are then aggregated separately on these two partial edge sets to produce disentangled representations, based on which a more accurate edge splitting can be attained later. Theoretically, we show that our ES-GNN can be regarded as a solution to a graph denoising problem with a disentangled smoothness assumption, which further illustrates our motivations and interprets the improved generalization. Extensive experiments over 8 benchmark and 1 synthetic datasets demonstrate that ES-GNN not only outperforms the state-of-the-arts (including 8 GNN baselines), but also can be more robust to adversarial graphs and alleviate the over-smoothing problem.
BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis
Apr 06, 2022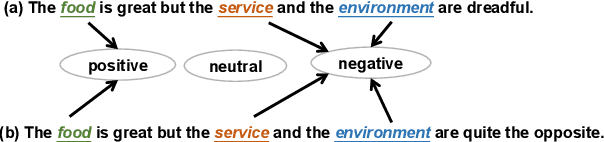
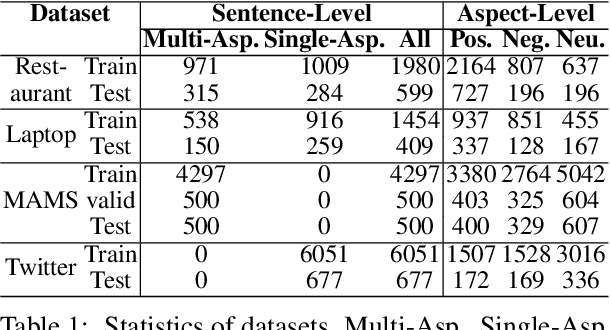
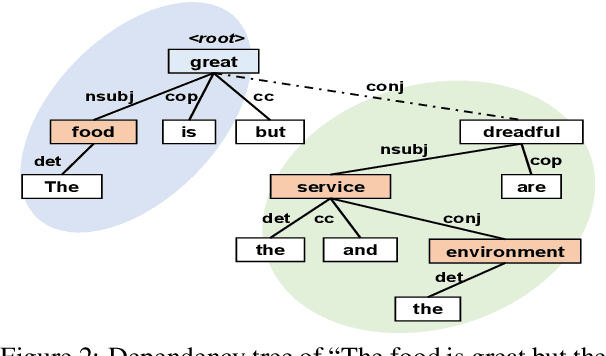
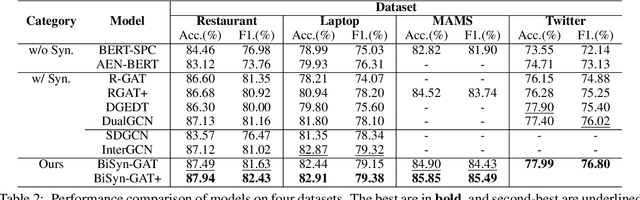
Aspect-based sentiment analysis (ABSA) is a fine-grained sentiment analysis task that aims to align aspects and corresponding sentiments for aspect-specific sentiment polarity inference. It is challenging because a sentence may contain multiple aspects or complicated (e.g., conditional, coordinating, or adversative) relations. Recently, exploiting dependency syntax information with graph neural networks has been the most popular trend. Despite its success, methods that heavily rely on the dependency tree pose challenges in accurately modeling the alignment of the aspects and their words indicative of sentiment, since the dependency tree may provide noisy signals of unrelated associations (e.g., the "conj" relation between "great" and "dreadful" in Figure 2). In this paper, to alleviate this problem, we propose a Bi-Syntax aware Graph Attention Network (BiSyn-GAT+). Specifically, BiSyn-GAT+ fully exploits the syntax information (e.g., phrase segmentation and hierarchical structure) of the constituent tree of a sentence to model the sentiment-aware context of every single aspect (called intra-context) and the sentiment relations across aspects (called inter-context) for learning. Experiments on four benchmark datasets demonstrate that BiSyn-GAT+ outperforms the state-of-the-art methods consistently.
Masked Spectrogram Modeling using Masked Autoencoders for Learning General-purpose Audio Representation
Apr 26, 2022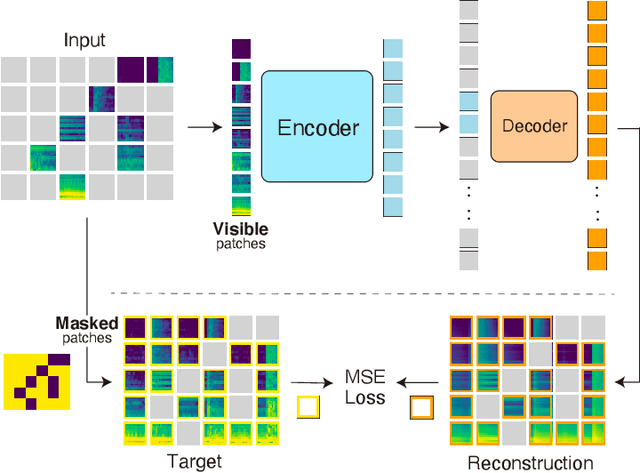
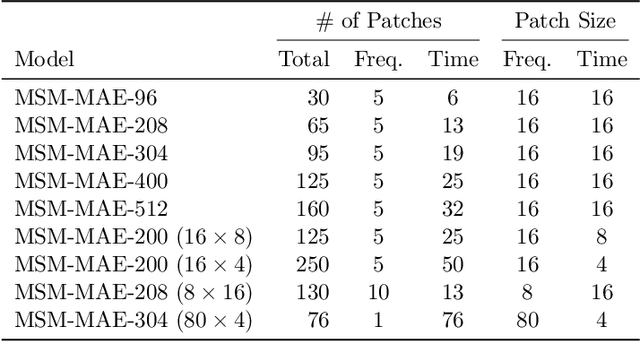
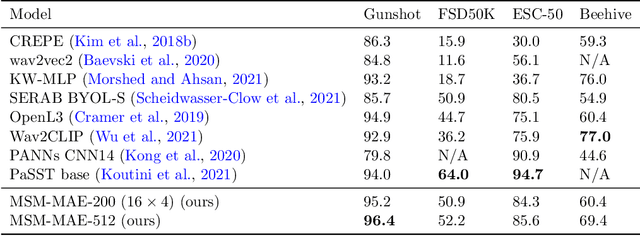
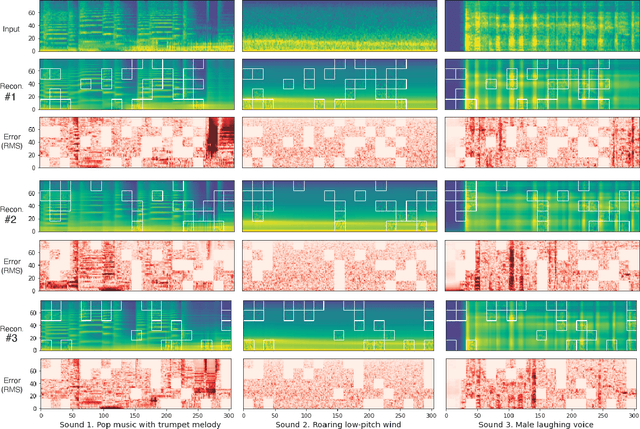
Recent general-purpose audio representations show state-of-the-art performance on various audio tasks. These representations are pre-trained by self-supervised learning methods that create training signals from the input. For example, typical audio contrastive learning uses temporal relationships among input sounds to create training signals, whereas some methods use a difference among input views created by data augmentations. However, these training signals do not provide information derived from the intact input sound, which we think is suboptimal for learning representation that describes the input as it is. In this paper, we seek to learn audio representations from the input itself as supervision using a pretext task of auto-encoding of masked spectrogram patches, Masked Spectrogram Modeling (MSM, a variant of Masked Image Modeling applied to audio spectrogram). To implement MSM, we use Masked Autoencoders (MAE), an image self-supervised learning method. MAE learns to efficiently encode the small number of visible patches into latent representations to carry essential information for reconstructing a large number of masked patches. While training, MAE minimizes the reconstruction error, which uses the input as training signal, consequently achieving our goal. We conducted experiments on our MSM using MAE (MSM-MAE) models under the evaluation benchmark of the HEAR 2021 NeurIPS Challenge. Our MSM-MAE models outperformed the HEAR 2021 Challenge results on seven out of 15 tasks (e.g., accuracies of 73.4% on CREMA-D and 85.8% on LibriCount), while showing top performance on other tasks where specialized models perform better. We also investigate how the design choices of MSM-MAE impact the performance and conduct qualitative analysis of visualization outcomes to gain an understanding of learned representations. We make our code available online.