 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An unsupervised approach for semantic place annotation of trajectories based on the prior probability
Apr 20, 2022
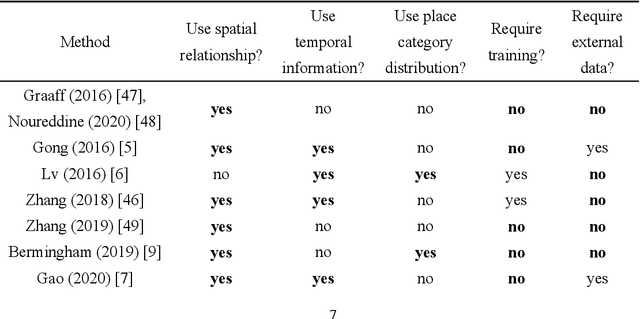
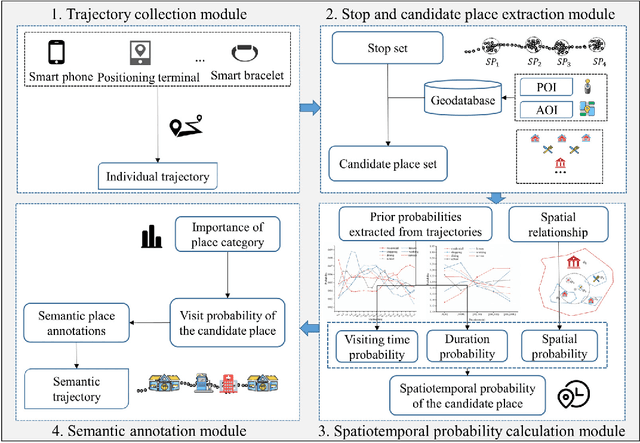
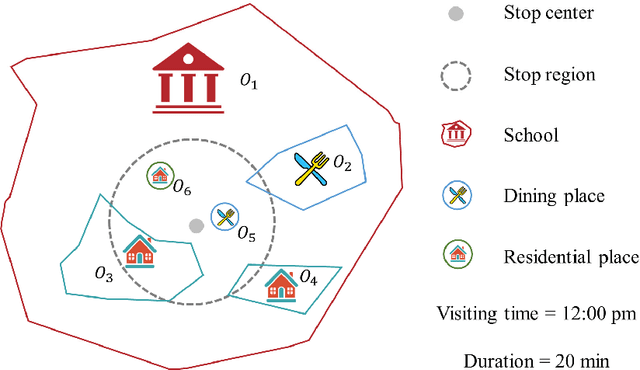
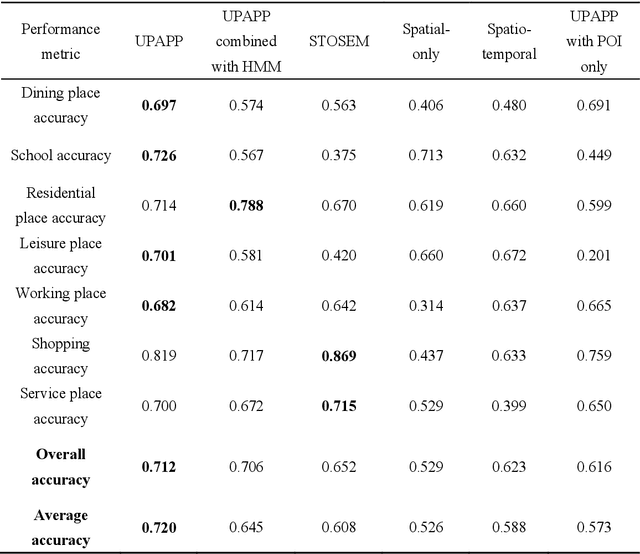
Semantic place annotation can provide individual semantics, which can be of great help in the field of trajectory data mining. Most existing methods rely on annotated or external data and require retraining following a change of region, thus preventing their large-scale applications. Herein, we propose an unsupervised method denoted as UPAPP for the semantic place annotation of trajectories using spatiotemporal information. The Bayesian Criterion is specifically employed to decompose the spatiotemporal probability of the candidate place into spatial probability, duration probability, and visiting time probability. Spatial information in ROI and POI data is subsequently adopted to calculate the spatial probability. In terms of the temporal probabilities, the Term Frequency Inverse Document Frequency weighting algorithm is used to count the potential visits to different place types in the trajectories, and generates the prior probabilities of the visiting time and duration. The spatiotemporal probability of the candidate place is then combined with the importance of the place category to annotate the visited places. Validation with a trajectory dataset collected by 709 volunteers in Beijing showed that our method achieved an overall and average accuracy of 0.712 and 0.720, respectively, indicating that the visited places can be annotated accurately without any external data.
Adaptive Few-Shot Learning Algorithm for Rare Sound Event Detection
May 26, 2022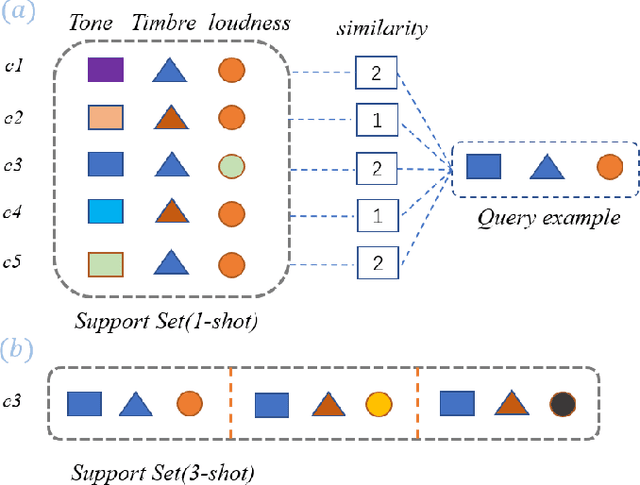
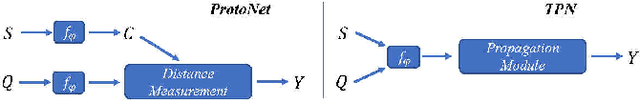
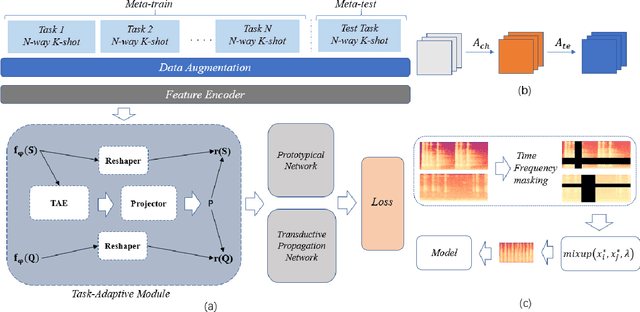
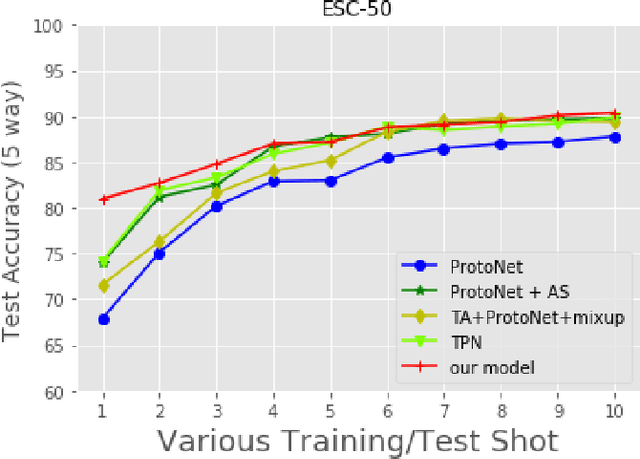
Sound event detection is to infer the event by understanding the surrounding environmental sounds. Due to the scarcity of rare sound events, it becomes challenging for the well-trained detectors which have learned too much prior knowledge. Meanwhile, few-shot learning methods promise a good generalization ability when facing a new limited-data task. Recent approaches have achieved promising results in this field. However, these approaches treat each support example independently, ignoring the information of other examples from the whole task. Because of this, most of previous methods are constrained to generate a same feature embedding for all test-time tasks, which is not adaptive to each inputted data. In this work, we propose a novel task-adaptive module which is easy to plant into any metric-based few-shot learning frameworks. The module could identify the task-relevant feature dimension. Incorporating our module improves the performance considerably on two datasets over baseline methods, especially for the transductive propagation network. Such as +6.8% for 5-way 1-shot accuracy on ESC-50, and +5.9% on noiseESC-50. We investigate our approach in the domain-mismatch setting and also achieve better results than previous methods.
Physics guided neural networks for modelling of non-linear dynamics
May 13, 2022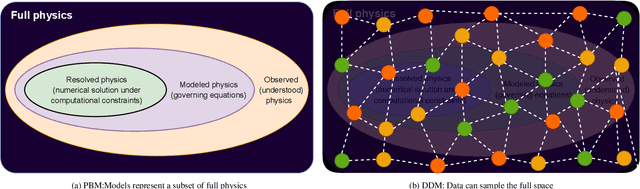
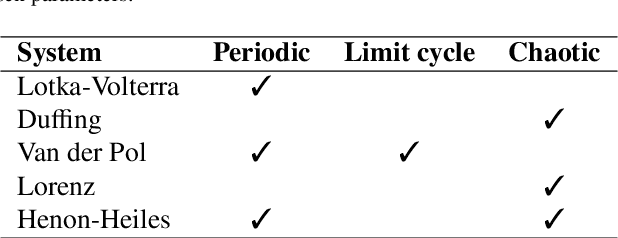
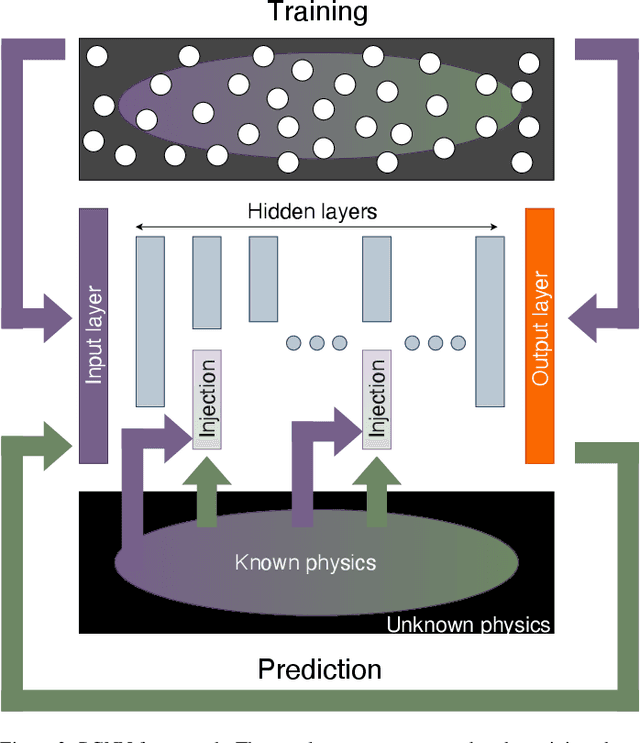

The success of the current wave of artificial intelligence can be partly attributed to deep neural networks, which have proven to be very effective in learning complex patterns from large datasets with minimal human intervention. However, it is difficult to train these models on complex dynamical systems from data alone due to their low data efficiency and sensitivity to hyperparameters and initialisation. This work demonstrates that injection of partially known information at an intermediate layer in a DNN can improve model accuracy, reduce model uncertainty, and yield improved convergence during the training. The value of these physics-guided neural networks has been demonstrated by learning the dynamics of a wide variety of nonlinear dynamical systems represented by five well-known equations in nonlinear systems theory: the Lotka-Volterra, Duffing, Van der Pol, Lorenz, and Henon-Heiles systems.
Encryption and encoding of facial images into quick response and high capacity color 2d code for biometric passport security system
Mar 17, 2022
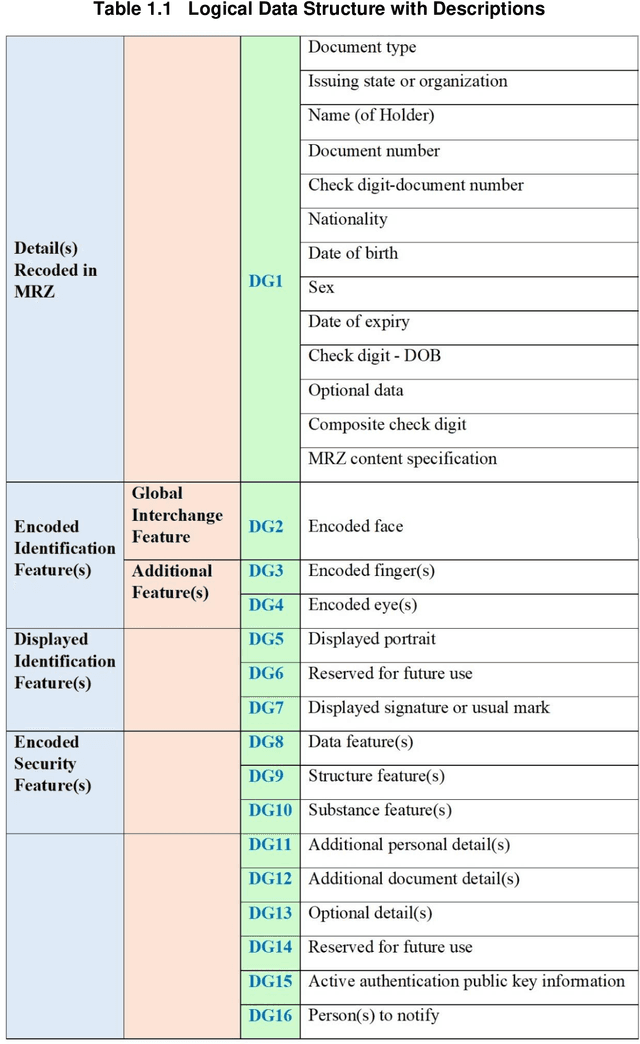

In this thesis, a multimodal biometric, secure encrypted data and encrypted biometric encoded into the QR code-based biometric-passport authentication method is proposed for national security applications. Firstly, using the Extended Profile - Local Binary Patterns (EP-LBP), a Canny edge detector, and the Scale Invariant Feature Transform (SIFT) algorithm with Image File Information (IMFINFO) process, the facial mark size recognition is initially achieved. Secondly, by using the Active Shape Model (ASM) into Active Appearance Model (AAM) to follow the hand and infusion the hand geometry characteristics for verification and identification, hand geometry recognition is achieved. Thirdly, the encrypted biometric passport information that is publicly accessible is encoded into the QR code and inserted into the electronic passport to improve protection. Further, Personal information and biometric data are encrypted by applying the Advanced Encryption Standard (AES) and the Secure Hash Algorithm (SHA) 256 algorithm. It will enhance the biometric passport security system.
Age Minimization in Outdoor and Indoor Communications with Relay-aided Dual RIS
May 06, 2022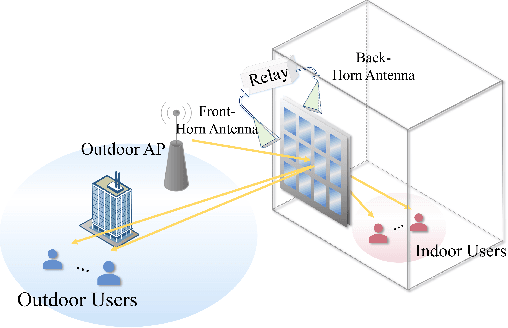

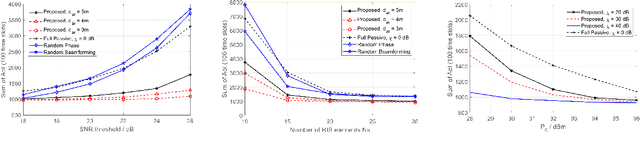
In this paper, we investigate an outdoor and indoor wireless communication network with the assistance of a novel relay-aided double-sided reconfigurable intelligent surface (RIS). A scheduling problem is considered at the outdoor access point (AP) to minimize the sum of age of information (AoI). To serve the indoor users and further enhance the wireless link quality, a novel double-sided RIS with relay is utilized. Since the formulated problem is non-convex with highly-coupled variables, a successive convex approximation (SCA) based alternating optimization (AO) algorithm is proposed to solve it in an iterative manner. Finally, simulation results show the effectiveness and significant performance improvement in terms of AoI of the proposed algorithm compared with other benchmarks.
Self-Supervised Ego-Motion Estimation Based on Multi-Layer Fusion of RGB and Inferred Depth
Mar 03, 2022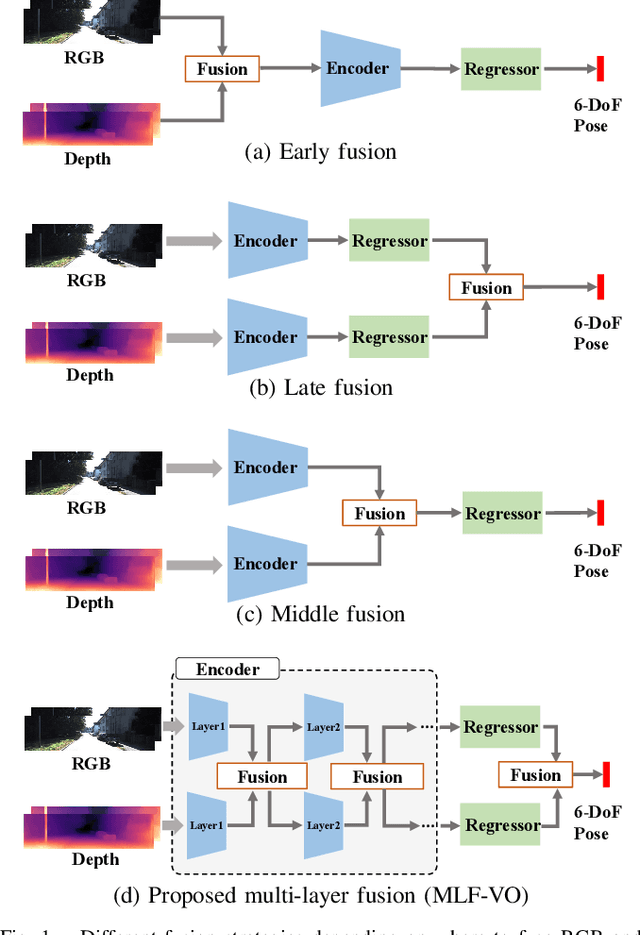
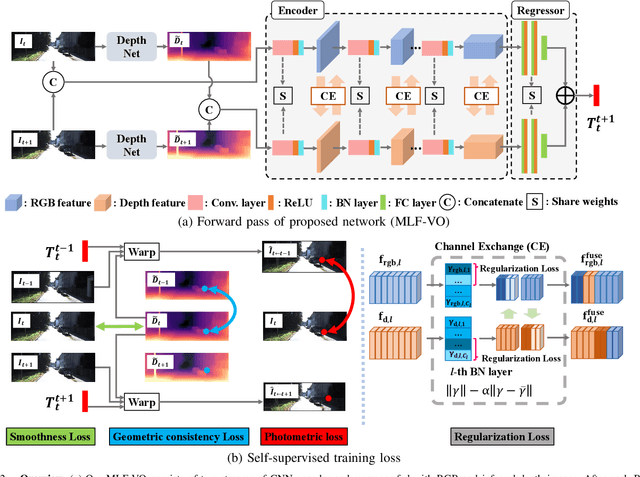
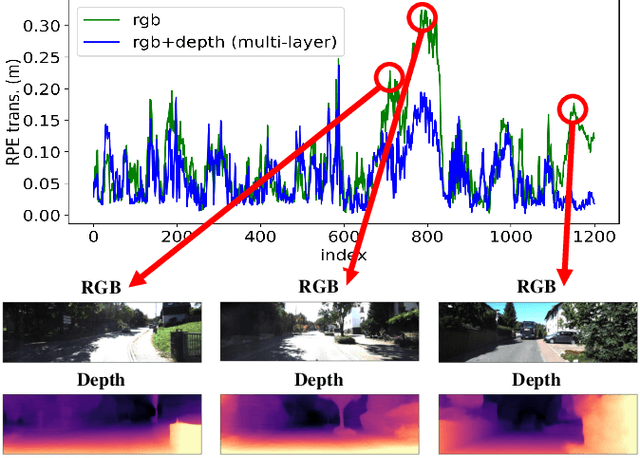
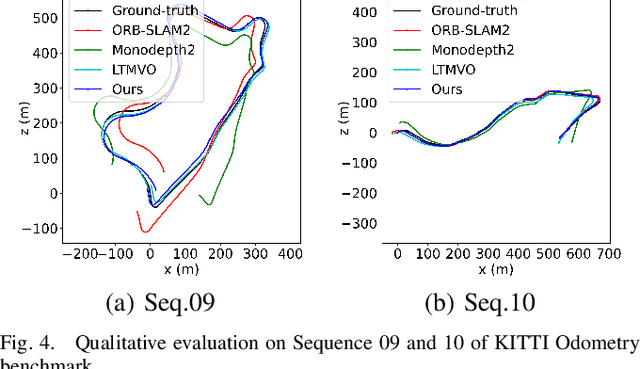
In existing self-supervised depth and ego-motion estimation methods, ego-motion estimation is usually limited to only leveraging RGB information. Recently, several methods have been proposed to further improve the accuracy of self-supervised ego-motion estimation by fusing information from other modalities, e.g., depth, acceleration, and angular velocity. However, they rarely focus on how different fusion strategies affect performance. In this paper, we investigate the effect of different fusion strategies for ego-motion estimation and propose a new framework for self-supervised learning of depth and ego-motion estimation, which performs ego-motion estimation by leveraging RGB and inferred depth information in a Multi-Layer Fusion manner. As a result, we have achieved state-of-the-art performance among learning-based methods on the KITTI odometry benchmark. Detailed studies on the design choices of leveraging inferred depth information and fusion strategies have also been carried out, which clearly demonstrate the advantages of our proposed framework.
Deciding What to Model: Value-Equivalent Sampling for Reinforcement Learning
Jun 04, 2022The quintessential model-based reinforcement-learning agent iteratively refines its estimates or prior beliefs about the true underlying model of the environment. Recent empirical successes in model-based reinforcement learning with function approximation, however, eschew the true model in favor of a surrogate that, while ignoring various facets of the environment, still facilitates effective planning over behaviors. Recently formalized as the value equivalence principle, this algorithmic technique is perhaps unavoidable as real-world reinforcement learning demands consideration of a simple, computationally-bounded agent interacting with an overwhelmingly complex environment, whose underlying dynamics likely exceed the agent's capacity for representation. In this work, we consider the scenario where agent limitations may entirely preclude identifying an exactly value-equivalent model, immediately giving rise to a trade-off between identifying a model that is simple enough to learn while only incurring bounded sub-optimality. To address this problem, we introduce an algorithm that, using rate-distortion theory, iteratively computes an approximately-value-equivalent, lossy compression of the environment which an agent may feasibly target in lieu of the true model. We prove an information-theoretic, Bayesian regret bound for our algorithm that holds for any finite-horizon, episodic sequential decision-making problem. Crucially, our regret bound can be expressed in one of two possible forms, providing a performance guarantee for finding either the simplest model that achieves a desired sub-optimality gap or, alternatively, the best model given a limit on agent capacity.
Active Learning of Sequential Transducers with Side Information about the Domain
Apr 23, 2021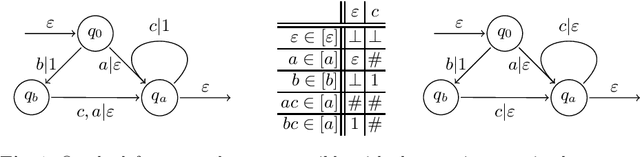
Active learning is a setting in which a student queries a teacher, through membership and equivalence queries, in order to learn a language. Performance on these algorithms is often measured in the number of queries required to learn a target, with an emphasis on costly equivalence queries. In graybox learning, the learning process is accelerated by foreknowledge of some information on the target. Here, we consider graybox active learning of subsequential string transducers, where a regular overapproximation of the domain is known by the student. We show that there exists an algorithm using string equation solvers that uses this knowledge to learn subsequential string transducers with a better guarantee on the required number of equivalence queries than classical active learning.
MTBF-33: A multi-temporal building footprint dataset for 33 counties in the United States (1900-2015)
Mar 21, 2022
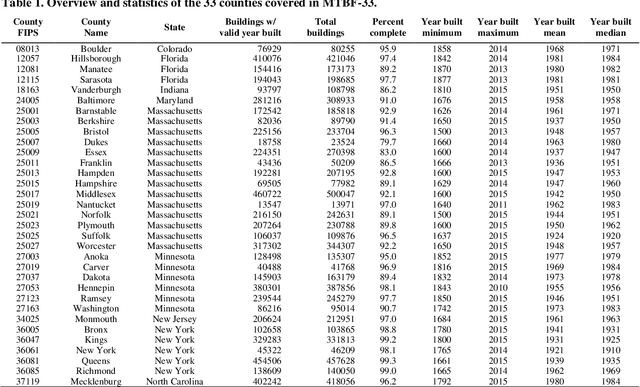
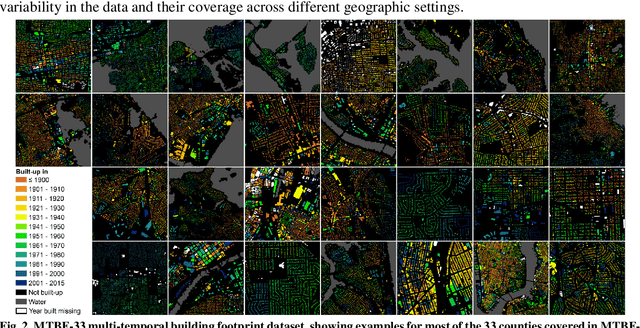
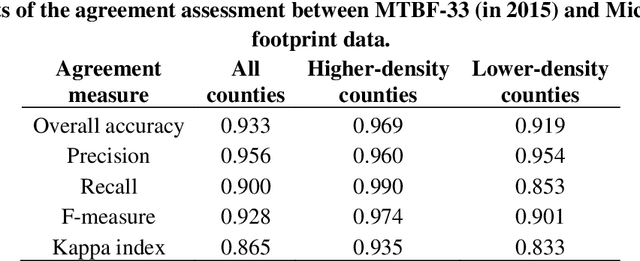
Despite abundant data on the spatial distribution of contemporary human settlements, historical data on the long-term evolution of human settlements at fine spatial and temporal granularity is scarce, limiting our quantitative understanding of long-term changes of built-up areas. This is because commonly used mapping methods (e.g., image classification) and suitable data sources (i.e., aerial imagery, multi-spectral remote sensing data, LiDAR) have only been available in recent decades. However, there are alternative data sources such as cadastral records that are digitally available, containing relevant information such as building age information, allowing for an approximate, digital reconstruction of past building distributions. We conducted a non-exhaustive search of open and publicly available data resources from administrative institutions in the United States and gathered, integrated, and harmonized cadastral parcel data, tax assessment data, and building footprint data for 33 counties, wherever building footprint geometries and building construction year information was available. The result of this effort is a unique dataset which we call the Multi-Temporal Building Footprint Dataset for 33 U.S. Counties (MTBF-33). MTBF-33 contains over 6.2 million building footprints including their construction year, and can be used to derive retrospective depictions of built-up areas from 1900 to 2015, at fine spatial and temporal grain and can be used for data validation purposes, or to train statistical learning approaches aiming to extract historical information on human settlements from remote sensing data, historical maps, or similar data sources. MTBF-33 is available at http://doi.org/10.17632/w33vbvjtdy.
GraphPMU: Event Clustering via Graph Representation Learning Using Locationally-Scarce Distribution-Level Fundamental and Harmonic PMU Measurements
May 26, 2022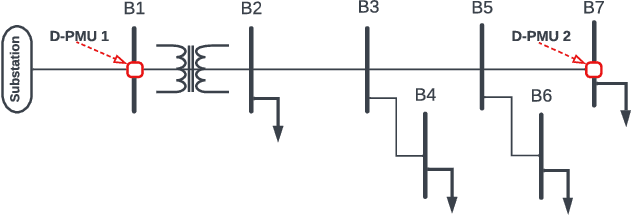
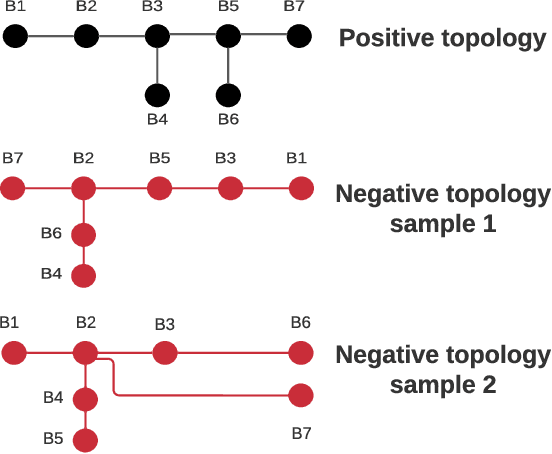
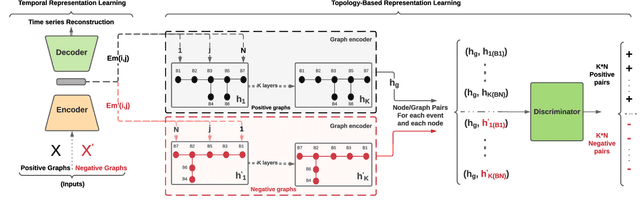

This paper is concerned with the complex task of identifying the type and cause of the events that are captured by distribution-level phasor measurement units (D-PMUs) in order to enhance situational awareness in power distribution systems. Our goal is to address two fundamental challenges in this field: a) scarcity in measurement locations due to the high cost of purchasing, installing, and streaming data from D-PMUs; b) limited prior knowledge about the event signatures due to the fact that the events are diverse, infrequent, and inherently unscheduled. To tackle these challenges, we propose an unsupervised graph-representation learning method, called GraphPMU, to significantly improve the performance in event clustering under locationally-scarce data availability by proposing the following two new directions: 1) using the topological information about the relative location of the few available phasor measurement units on the graph of the power distribution network; 2) utilizing not only the commonly used fundamental phasor measurements, bus also the less explored harmonic phasor measurements in the process of analyzing the signatures of various events. Through a detailed analysis of several case studies, we show that GraphPMU can highly outperform the prevalent methods in the literature.