 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Posterior Distribution-based Embedding for Hyperspectral Image Super-resolution
May 30, 2022
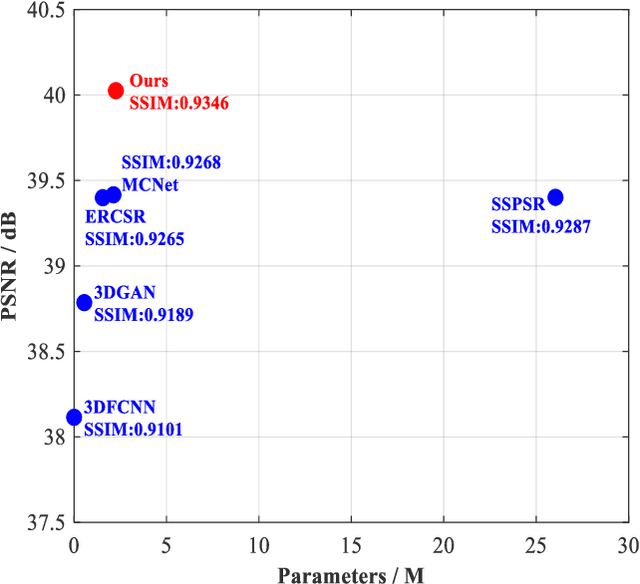
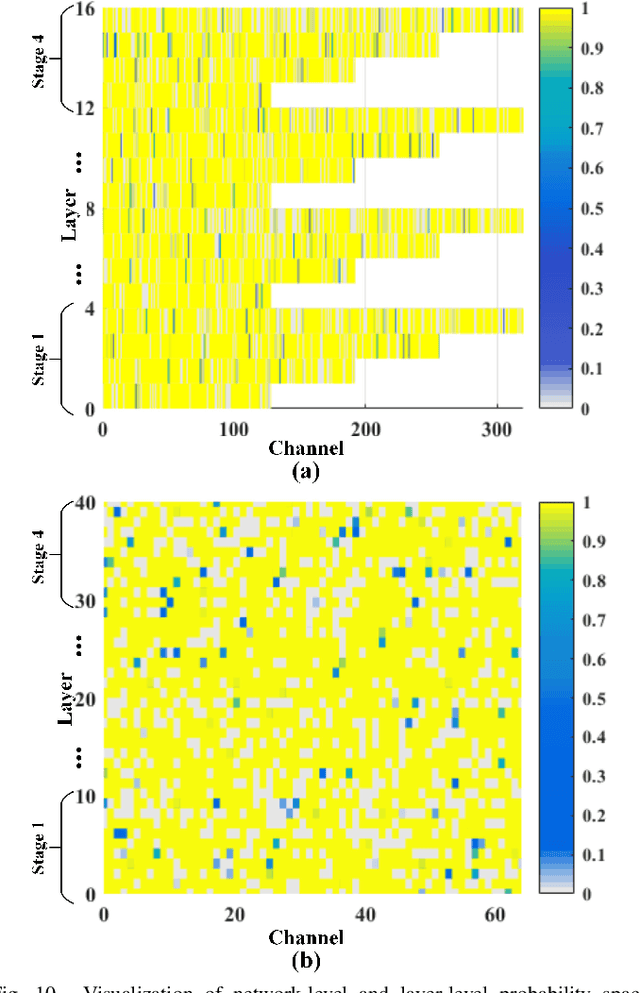
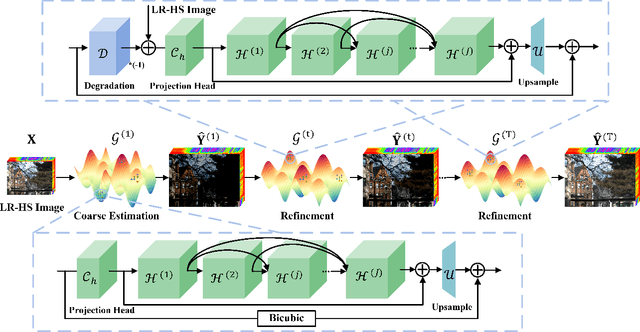
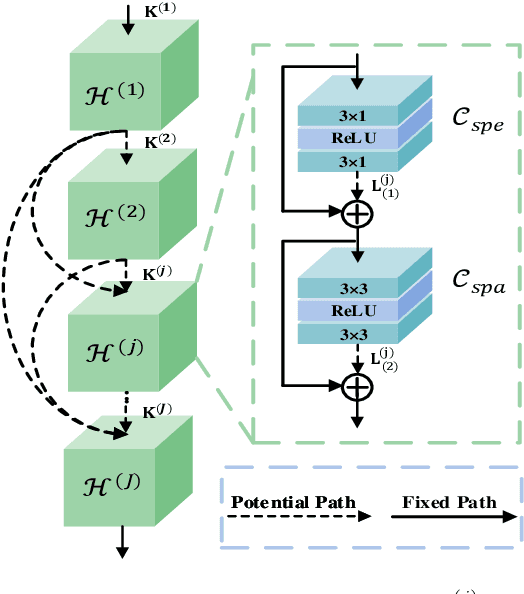
In this paper, we investigate the problem of hyperspectral (HS) image spatial super-resolution via deep learning. Particularly, we focus on how to embed the high-dimensional spatial-spectral information of HS images efficiently and effectively. Specifically, in contrast to existing methods adopting empirically-designed network modules, we formulate HS embedding as an approximation of the posterior distribution of a set of carefully-defined HS embedding events, including layer-wise spatial-spectral feature extraction and network-level feature aggregation. Then, we incorporate the proposed feature embedding scheme into a source-consistent super-resolution framework that is physically-interpretable, producing lightweight PDE-Net, in which high-resolution (HR) HS images are iteratively refined from the residuals between input low-resolution (LR) HS images and pseudo-LR-HS images degenerated from reconstructed HR-HS images via probability-inspired HS embedding. Extensive experiments over three common benchmark datasets demonstrate that PDE-Net achieves superior performance over state-of-the-art methods. Besides, the probabilistic characteristic of this kind of networks can provide the epistemic uncertainty of the network outputs, which may bring additional benefits when used for other HS image-based applications. The code will be publicly available at https://github.com/jinnh/PDE-Net.
Two-stream Hierarchical Similarity Reasoning for Image-text Matching
Mar 10, 2022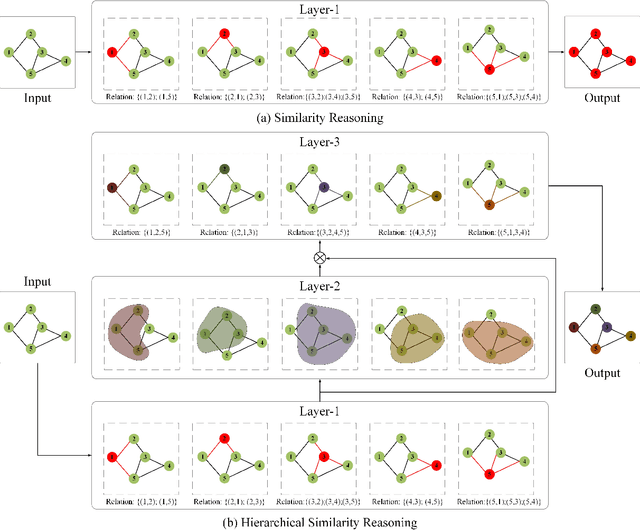
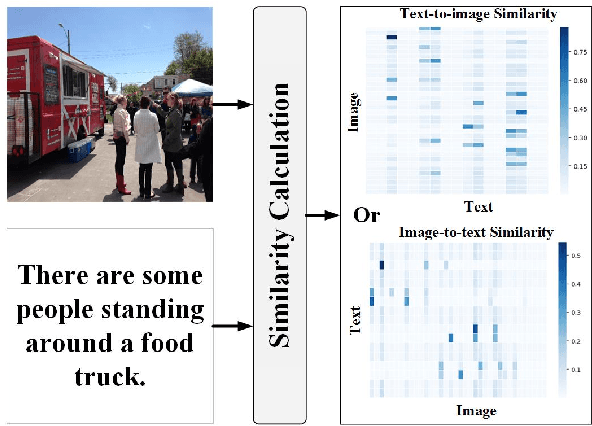
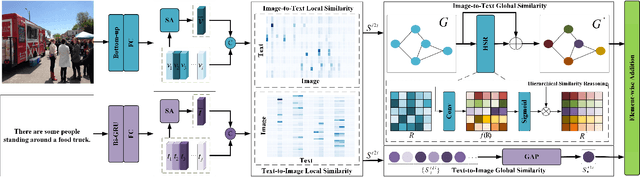
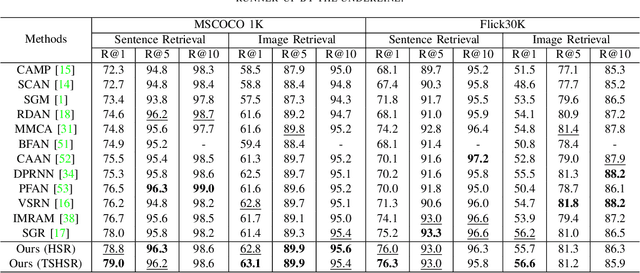
Reasoning-based approaches have demonstrated their powerful ability for the task of image-text matching. In this work, two issues are addressed for image-text matching. First, for reasoning processing, conventional approaches have no ability to find and use multi-level hierarchical similarity information. To solve this problem, a hierarchical similarity reasoning module is proposed to automatically extract context information, which is then co-exploited with local interaction information for efficient reasoning. Second, previous approaches only consider learning single-stream similarity alignment (i.e., image-to-text level or text-to-image level), which is inadequate to fully use similarity information for image-text matching. To address this issue, a two-stream architecture is developed to decompose image-text matching into image-to-text level and text-to-image level similarity computation. These two issues are investigated by a unifying framework that is trained in an end-to-end manner, namely two-stream hierarchical similarity reasoning network. The extensive experiments performed on the two benchmark datasets of MSCOCO and Flickr30K show the superiority of the proposed approach as compared to existing state-of-the-art methods.
Masking Adversarial Damage: Finding Adversarial Saliency for Robust and Sparse Network
Apr 06, 2022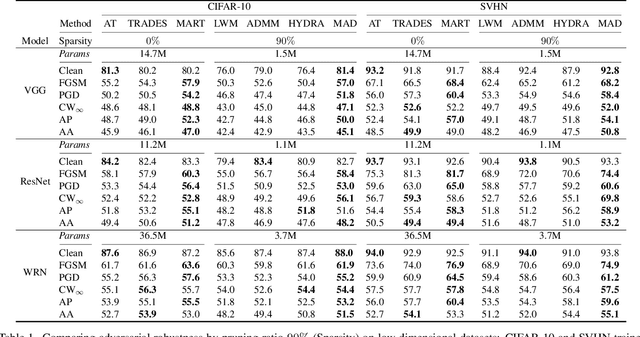
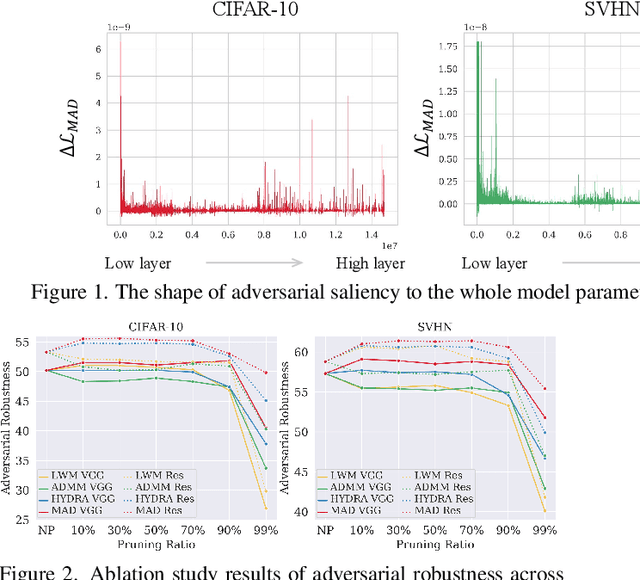
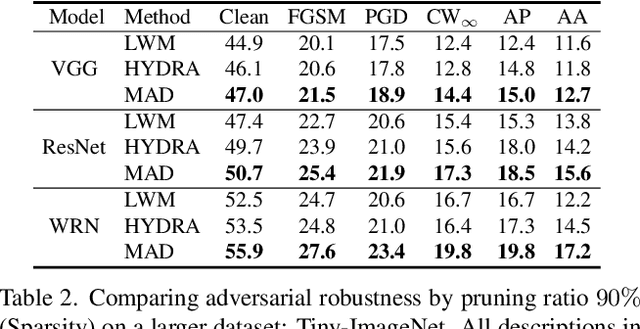
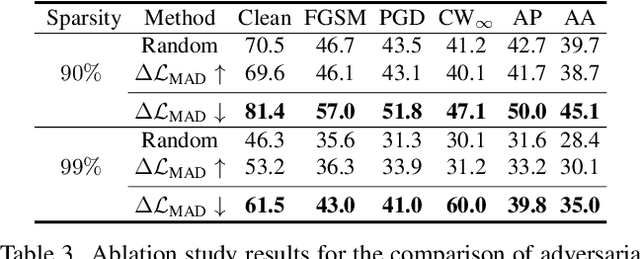
Adversarial examples provoke weak reliability and potential security issues in deep neural networks. Although adversarial training has been widely studied to improve adversarial robustness, it works in an over-parameterized regime and requires high computations and large memory budgets. To bridge adversarial robustness and model compression, we propose a novel adversarial pruning method, Masking Adversarial Damage (MAD) that employs second-order information of adversarial loss. By using it, we can accurately estimate adversarial saliency for model parameters and determine which parameters can be pruned without weakening adversarial robustness. Furthermore, we reveal that model parameters of initial layer are highly sensitive to the adversarial examples and show that compressed feature representation retains semantic information for the target objects. Through extensive experiments on three public datasets, we demonstrate that MAD effectively prunes adversarially trained networks without loosing adversarial robustness and shows better performance than previous adversarial pruning methods.
Effect of Prefix/Suffix Configurations on OTFS Systems with Rectangular Waveforms
May 30, 2022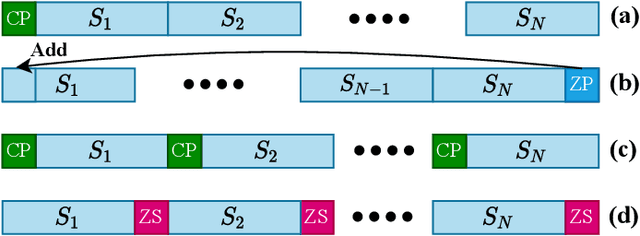
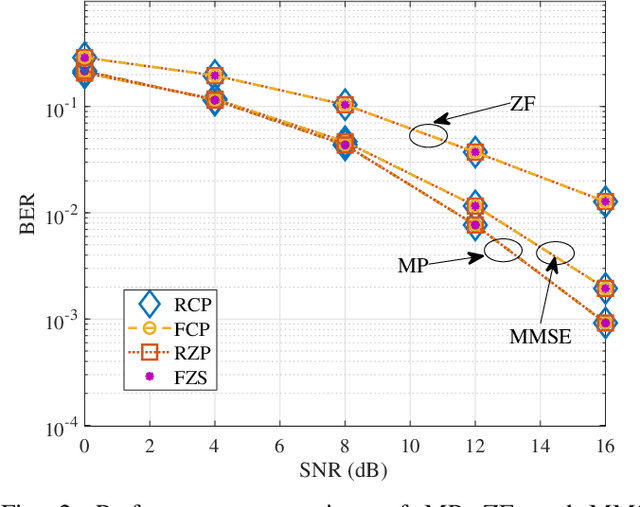
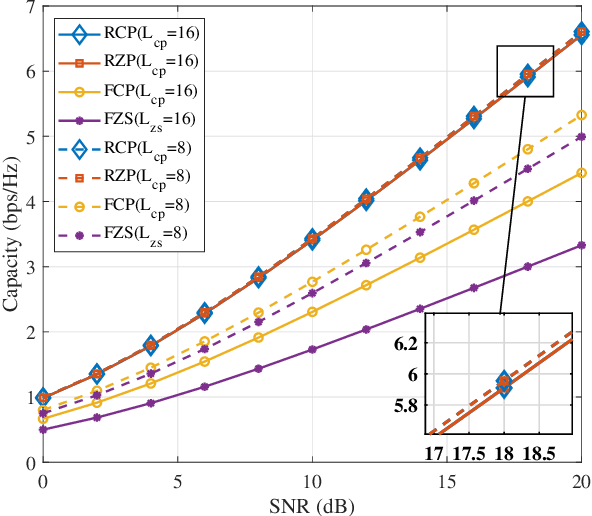
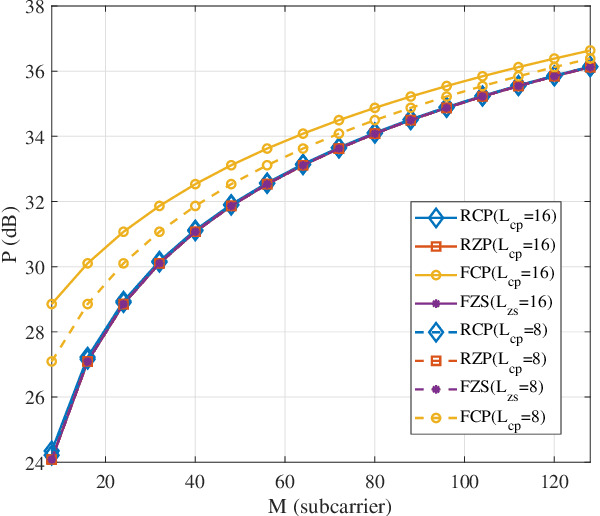
Recently, orthogonal time-frequency-space (OTFS) modulation is used as a promising candidate waveform for high mobility communication scenarios. In practical transmission, OTFS with rectangular pulse shaping is implemented using different prefix/suffix configurations including reduced-cyclic prefix (RCP), full-CP (FCP), full-zero suffix (FZS), and reduced-zero padded (RZP). However, for each prefix/suffix type, different effective channel are seen at the receiver side resulting in dissimilar performance of the various OTFS configurations given a specific communication scenario. To fulfill this gap, in this paper, we study and model the effective channel in OTFS systems using various prefix/suffix configurations. Then, from the input-output relation analysis of the received signal, we show that the OTFS has a simple sparse structure for all prefix/suffix types, where the only difference is the phase term introduced when extending quasi-periodically in the delay-Doppler grid. We provide a comprehensive comparison between all OTFS types in terms of channel estimation/equalization complexity, symbol detection performance, power and spectral efficiencies, which helps in deciding the optimal prefix/suffix configuration for a specific scenario. Finally, we propose a novel OTFS structure namely reduced-FCP (RFCP) where the information of the CP block is decodable.
Case-Aware Adversarial Training
Apr 20, 2022
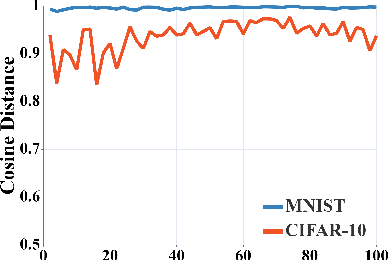
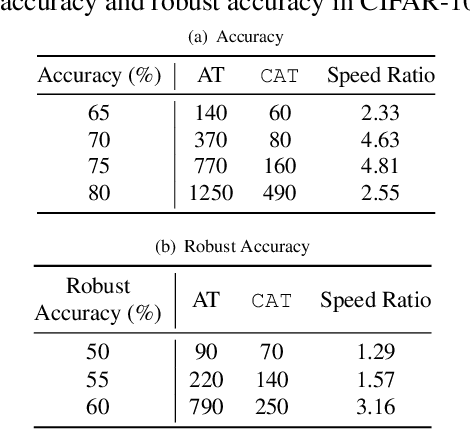

The neural network (NN) becomes one of the most heated type of models in various signal processing applications. However, NNs are extremely vulnerable to adversarial examples (AEs). To defend AEs, adversarial training (AT) is believed to be the most effective method while due to the intensive computation, AT is limited to be applied in most applications. In this paper, to resolve the problem, we design a generic and efficient AT improvement scheme, namely case-aware adversarial training (CAT). Specifically, the intuition stems from the fact that a very limited part of informative samples can contribute to most of model performance. Alternatively, if only the most informative AEs are used in AT, we can lower the computation complexity of AT significantly as maintaining the defense effect. To achieve this, CAT achieves two breakthroughs. First, a method to estimate the information degree of adversarial examples is proposed for AE filtering. Second, to further enrich the information that the NN can obtain from AEs, CAT involves a weight estimation and class-level balancing based sampling strategy to increase the diversity of AT at each iteration. Extensive experiments show that CAT is faster than vanilla AT by up to 3x while achieving competitive defense effect.
What do we learn? Debunking the Myth of Unsupervised Outlier Detection
Jun 08, 2022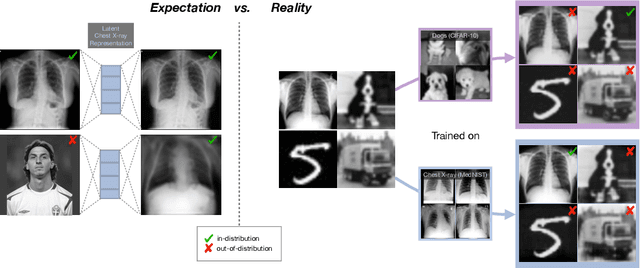
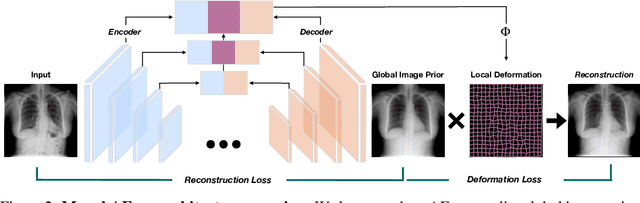
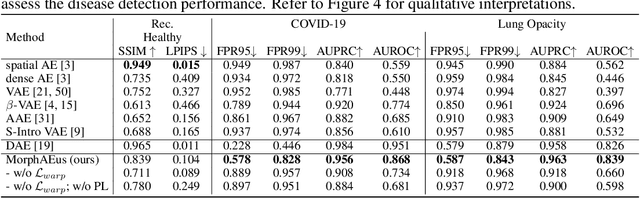
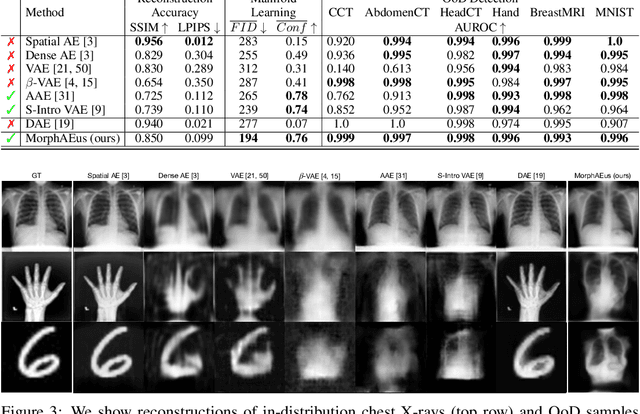
Even though auto-encoders (AEs) have the desirable property of learning compact representations without labels and have been widely applied to out-of-distribution (OoD) detection, they are generally still poorly understood and are used incorrectly in detecting outliers where the normal and abnormal distributions are strongly overlapping. In general, the learned manifold is assumed to contain key information that is only important for describing samples within the training distribution, and that the reconstruction of outliers leads to high residual errors. However, recent work suggests that AEs are likely to be even better at reconstructing some types of OoD samples. In this work, we challenge this assumption and investigate what auto-encoders actually learn when they are posed to solve two different tasks. First, we propose two metrics based on the Fr\'echet inception distance (FID) and confidence scores of a trained classifier to assess whether AEs can learn the training distribution and reliably recognize samples from other domains. Second, we investigate whether AEs are able to synthesize normal images from samples with abnormal regions, on a more challenging lung pathology detection task. We have found that state-of-the-art (SOTA) AEs are either unable to constrain the latent manifold and allow reconstruction of abnormal patterns, or they are failing to accurately restore the inputs from their latent distribution, resulting in blurred or misaligned reconstructions. We propose novel deformable auto-encoders (MorphAEus) to learn perceptually aware global image priors and locally adapt their morphometry based on estimated dense deformation fields. We demonstrate superior performance over unsupervised methods in detecting OoD and pathology.
Sparse Graph Learning for Spatiotemporal Time Series
May 26, 2022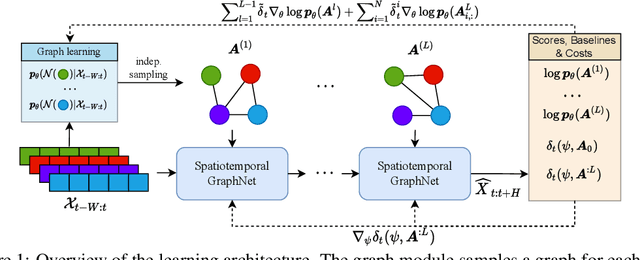
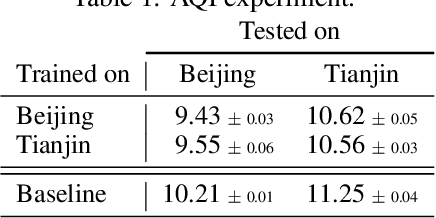
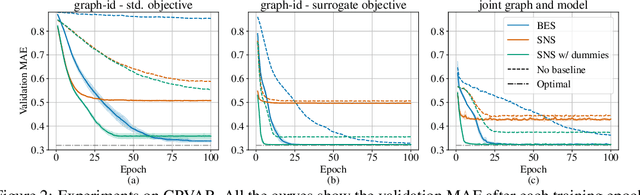
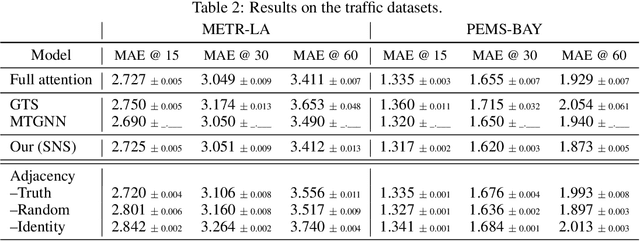
Outstanding achievements of graph neural networks for spatiotemporal time series prediction show that relational constraints introduce a positive inductive bias into neural forecasting architectures. Often, however, the relational information characterizing the underlying data generating process is unavailable; the practitioner is then left with the problem of inferring from data which relational graph to use in the subsequent processing stages. We propose novel, principled -- yet practical -- probabilistic methods that learn the relational dependencies by modeling distributions over graphs while maximizing, at the same time, end-to-end the forecasting accuracy. Our novel graph learning approach, based on consolidated variance reduction techniques for Monte Carlo score-based gradient estimation, is theoretically grounded and effective. We show that tailoring the gradient estimators to the graph learning problem allows us also for achieving state-of-the-art forecasting performance while controlling, at the same time, both the sparsity of the learned graph and the computational burden. We empirically assess the effectiveness of the proposed method on synthetic and real-world benchmarks, showing that the proposed solution can be used as a stand-alone graph identification procedure as well as a learned component of an end-to-end forecasting architecture.
Recurrent Video Restoration Transformer with Guided Deformable Attention
Jun 05, 2022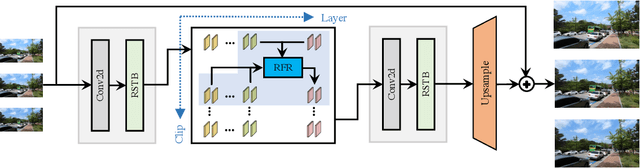
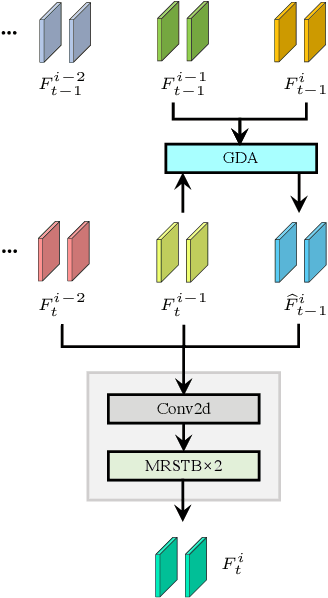
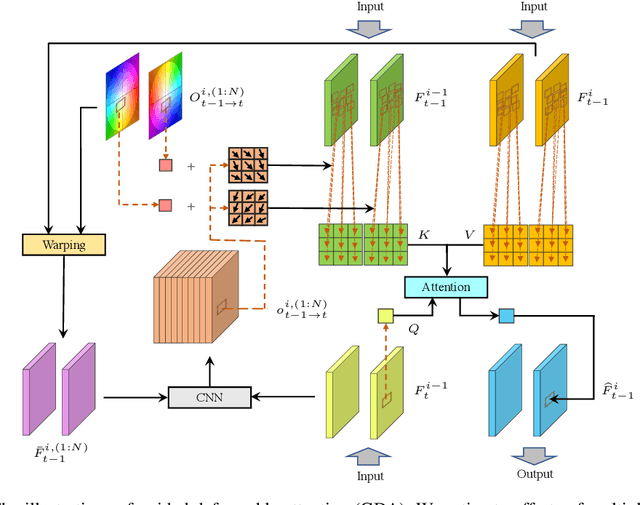
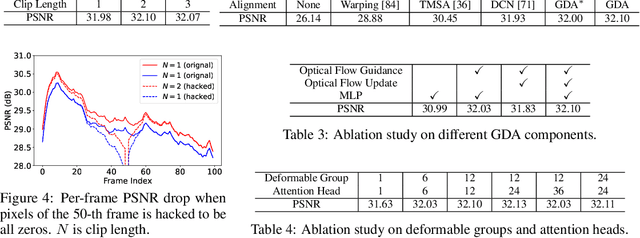
Video restoration aims at restoring multiple high-quality frames from multiple low-quality frames. Existing video restoration methods generally fall into two extreme cases, i.e., they either restore all frames in parallel or restore the video frame by frame in a recurrent way, which would result in different merits and drawbacks. Typically, the former has the advantage of temporal information fusion. However, it suffers from large model size and intensive memory consumption; the latter has a relatively small model size as it shares parameters across frames; however, it lacks long-range dependency modeling ability and parallelizability. In this paper, we attempt to integrate the advantages of the two cases by proposing a recurrent video restoration transformer, namely RVRT. RVRT processes local neighboring frames in parallel within a globally recurrent framework which can achieve a good trade-off between model size, effectiveness, and efficiency. Specifically, RVRT divides the video into multiple clips and uses the previously inferred clip feature to estimate the subsequent clip feature. Within each clip, different frame features are jointly updated with implicit feature aggregation. Across different clips, the guided deformable attention is designed for clip-to-clip alignment, which predicts multiple relevant locations from the whole inferred clip and aggregates their features by the attention mechanism. Extensive experiments on video super-resolution, deblurring, and denoising show that the proposed RVRT achieves state-of-the-art performance on benchmark datasets with balanced model size, testing memory and runtime.
Self-supervised Learning of Audio Representations from Audio-Visual Data using Spatial Alignment
Jun 02, 2022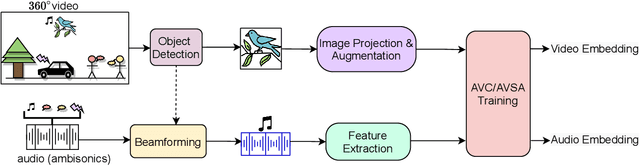
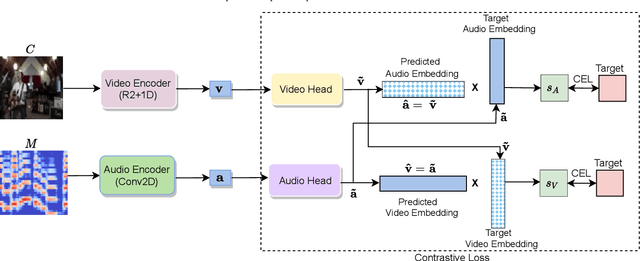
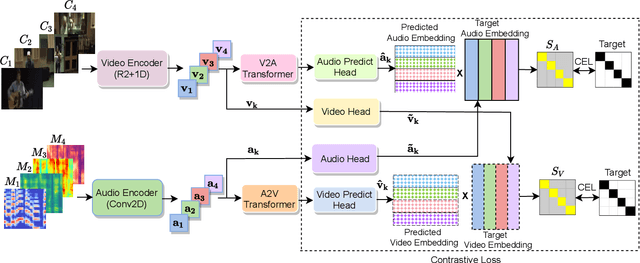

Learning from audio-visual data offers many possibilities to express correspondence between the audio and visual content, similar to the human perception that relates aural and visual information. In this work, we present a method for self-supervised representation learning based on audio-visual spatial alignment (AVSA), a more sophisticated alignment task than the audio-visual correspondence (AVC). In addition to the correspondence, AVSA also learns from the spatial location of acoustic and visual content. Based on 360$^\text{o}$ video and Ambisonics audio, we propose selection of visual objects using object detection, and beamforming of the audio signal towards the detected objects, attempting to learn the spatial alignment between objects and the sound they produce. We investigate the use of spatial audio features to represent the audio input, and different audio formats: Ambisonics, mono, and stereo. Experimental results show a 10 $\%$ improvement on AVSA for the first order ambisonics intensity vector (FOA-IV) in comparison with log-mel spectrogram features; the addition of object-oriented crops also brings significant performance increases for the human action recognition downstream task. A number of audio-only downstream tasks are devised for testing the effectiveness of the learnt audio feature representation, obtaining performance comparable to state-of-the-art methods on acoustic scene classification from ambisonic and binaural audio.
Identifying concept libraries from language about object structure
May 11, 2022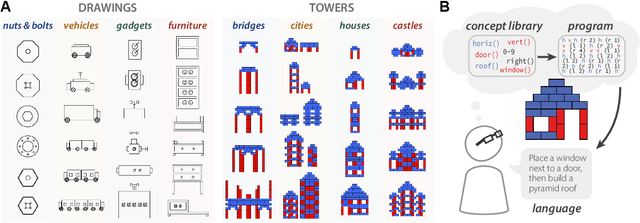
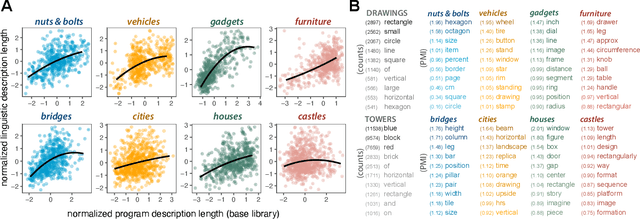
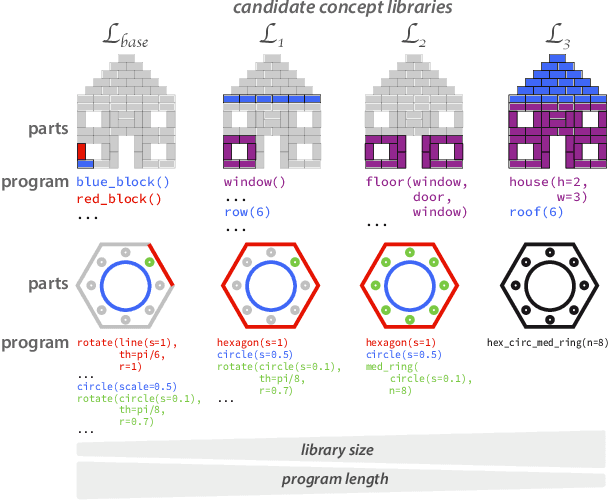
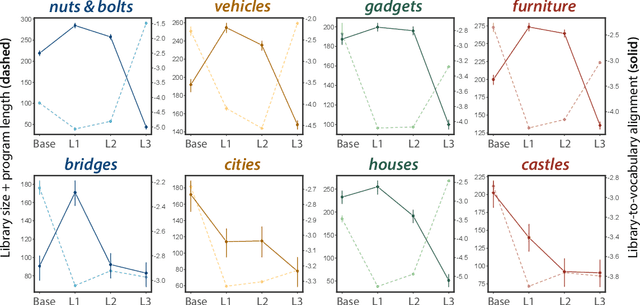
Our understanding of the visual world goes beyond naming objects, encompassing our ability to parse objects into meaningful parts, attributes, and relations. In this work, we leverage natural language descriptions for a diverse set of 2K procedurally generated objects to identify the parts people use and the principles leading these parts to be favored over others. We formalize our problem as search over a space of program libraries that contain different part concepts, using tools from machine translation to evaluate how well programs expressed in each library align to human language. By combining naturalistic language at scale with structured program representations, we discover a fundamental information-theoretic tradeoff governing the part concepts people name: people favor a lexicon that allows concise descriptions of each object, while also minimizing the size of the lexicon itself.