 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interpretable travel distance on the county-wise COVID-19 by sequence to sequence with attention
May 26, 2022
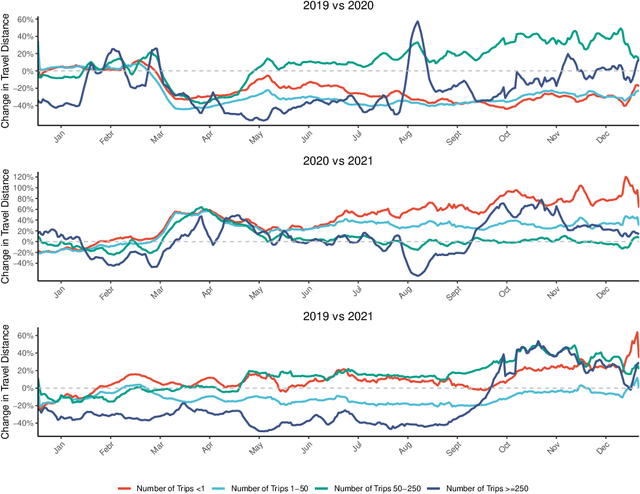
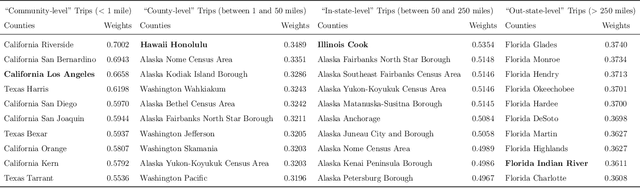
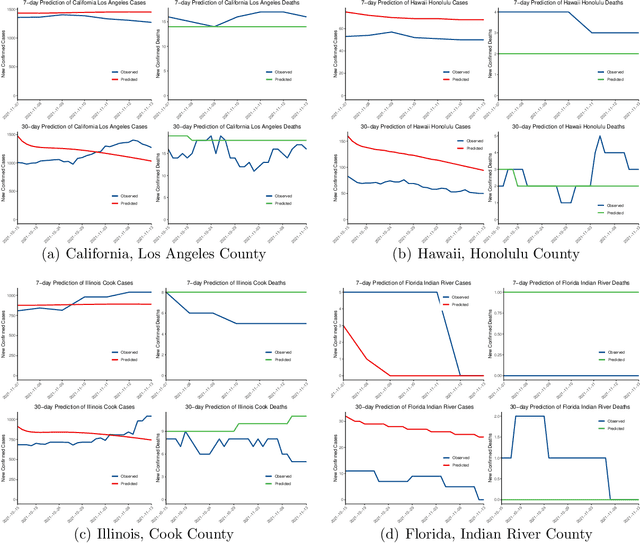
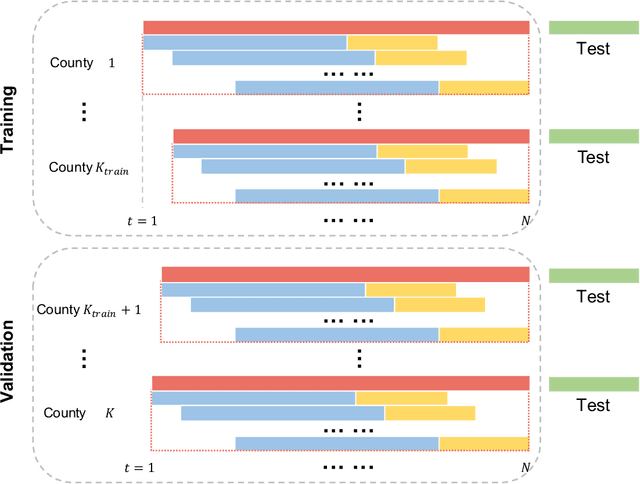
Background: Travel restrictions as a means of intervention in the COVID-19 epidemic have reduced the spread of outbreaks using epidemiological models. We introduce the attention module in the sequencing model to assess the effects of the different classes of travel distances. Objective: To establish a direct relationship between the number of travelers for various travel distances and the COVID-19 trajectories. To improve the prediction performance of sequencing model. Setting: Counties from all over the United States. Participants: New confirmed cases and deaths have been reported in 3158 counties across the United States. Measurements: Outcomes included new confirmed cases and deaths in the 30 days preceding November 13, 2021. The daily number of trips taken by the population for various classes of travel distances and the geographical information of infected counties are assessed. Results: There is a spatial pattern of various classes of travel distances across the country. The varying geographical effects of the number of people travelling for different distances on the epidemic spread are demonstrated. Limitation: We examined data up to November 13, 2021, and the weights of each class of travel distances may change accordingly as the data evolves. Conclusion: Given the weights of people taking trips for various classes of travel distances, the epidemics could be mitigated by reducing the corresponding class of travellers.
Semi-Supervised Super-Resolution
Apr 19, 2022
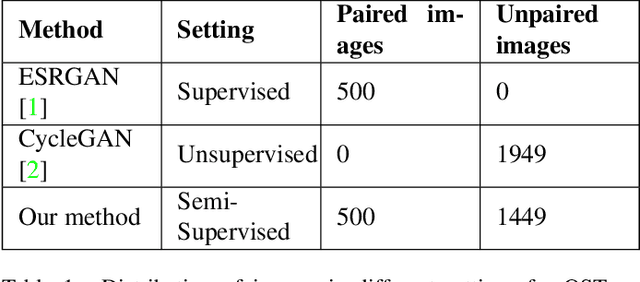
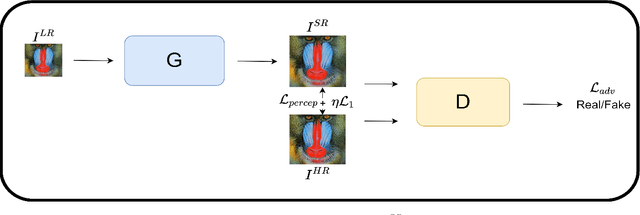
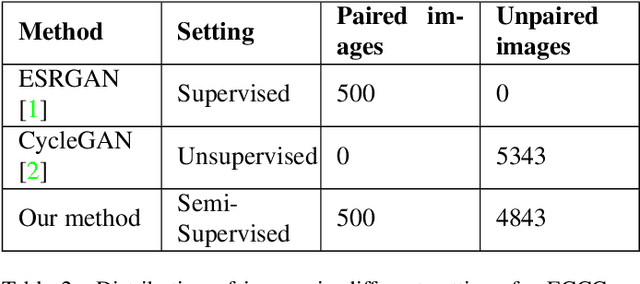
Super-Resolution is the technique to improve the quality of a low-resolution photo by boosting its plausible resolution. The computer vision community has extensively explored the area of Super-Resolution. However, previous Super-Resolution methods require vast amounts of data for training which becomes problematic in domains where very few low-resolution, high-resolution pairs might be available. One such area is statistical downscaling, where super-resolution is increasingly being used to obtain high-resolution climate information from low-resolution data. Acquiring high-resolution climate data is extremely expensive and challenging. To reduce the cost of generating high-resolution climate information, Super-Resolution algorithms should be able to train with a limited number of low-resolution, high-resolution pairs. This paper tries to solve the aforementioned problem by introducing a semi-supervised way to perform super-resolution that can generate sharp, high-resolution images with as few as 500 paired examples. The proposed semi-supervised technique can be used as a plug-and-play module with any supervised GAN-based Super-Resolution method to enhance its performance. We quantitatively and qualitatively analyze the performance of the proposed model and compare it with completely supervised methods as well as other unsupervised techniques. Comprehensive evaluations show the superiority of our method over other methods on different metrics. We also offer the applicability of our approach in statistical downscaling to obtain high-resolution climate images.
ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor
Jun 01, 2022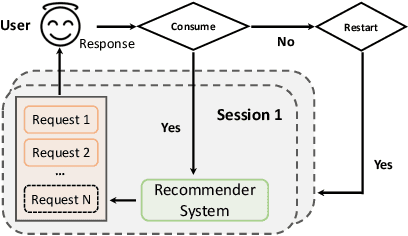
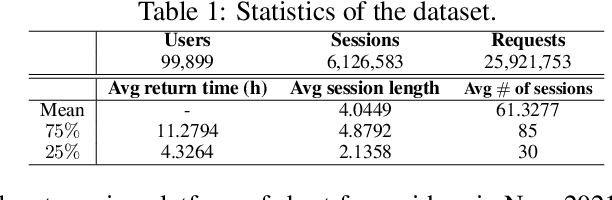
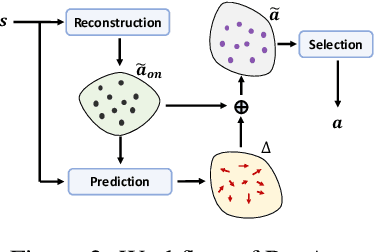
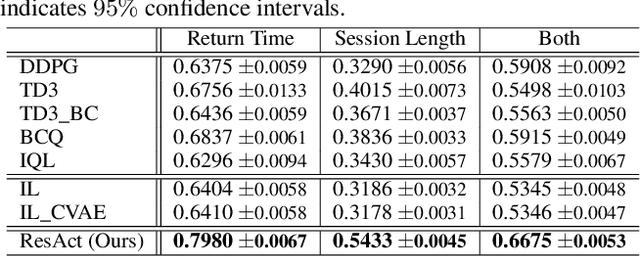
Long-term engagement is preferred over immediate engagement in sequential recommendation as it directly affects product operational metrics such as daily active users (DAUs) and dwell time. Meanwhile, reinforcement learning (RL) is widely regarded as a promising framework for optimizing long-term engagement in sequential recommendation. However, due to expensive online interactions, it is very difficult for RL algorithms to perform state-action value estimation, exploration and feature extraction when optimizing long-term engagement. In this paper, we propose ResAct which seeks a policy that is close to, but better than, the online-serving policy. In this way, we can collect sufficient data near the learned policy so that state-action values can be properly estimated, and there is no need to perform online exploration. Directly optimizing this policy is difficult due to the huge policy space. ResAct instead solves it by first reconstructing the online behaviors and then improving it. Our main contributions are fourfold. First, we design a generative model which reconstructs behaviors of the online-serving policy by sampling multiple action estimators. Second, we design an effective learning paradigm to train the residual actor which can output the residual for action improvement. Third, we facilitate the extraction of features with two information theoretical regularizers to confirm the expressiveness and conciseness of features. Fourth, we conduct extensive experiments on a real world dataset consisting of millions of sessions, and our method significantly outperforms the state-of-the-art baselines in various of long term engagement optimization tasks.
MonoTrack: Shuttle trajectory reconstruction from monocular badminton video
Apr 04, 2022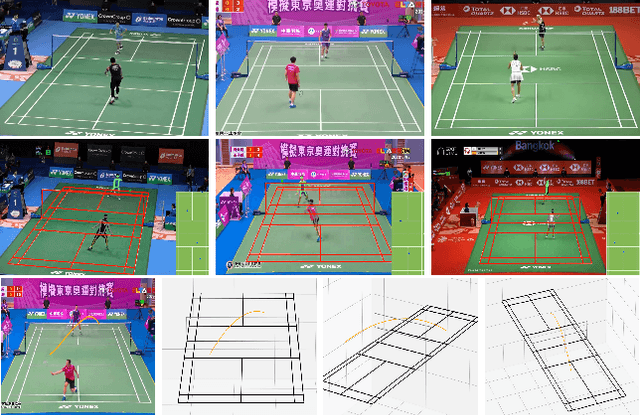
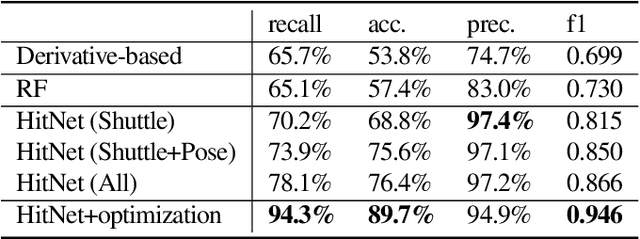
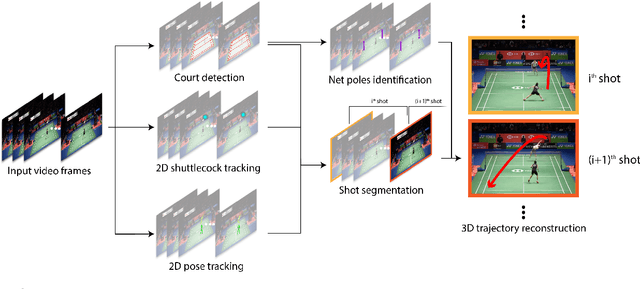

Trajectory estimation is a fundamental component of racket sport analytics, as the trajectory contains information not only about the winning and losing of each point, but also how it was won or lost. In sports such as badminton, players benefit from knowing the full 3D trajectory, as the height of shuttlecock or ball provides valuable tactical information. Unfortunately, 3D reconstruction is a notoriously hard problem, and standard trajectory estimators can only track 2D pixel coordinates. In this work, we present the first complete end-to-end system for the extraction and segmentation of 3D shuttle trajectories from monocular badminton videos. Our system integrates badminton domain knowledge such as court dimension, shot placement, physical laws of motion, along with vision-based features such as player poses and shuttle tracking. We find that significant engineering efforts and model improvements are needed to make the overall system robust, and as a by-product of our work, improve state-of-the-art results on court recognition, 2D trajectory estimation, and hit recognition.
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 22, 2022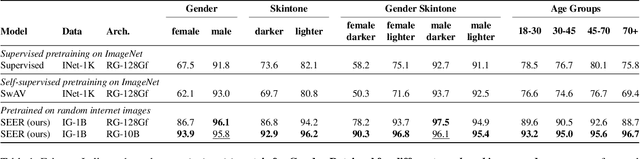
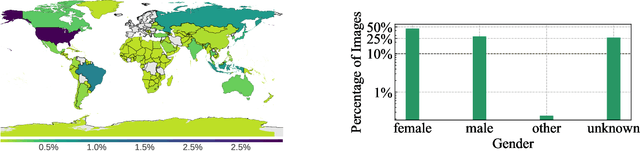
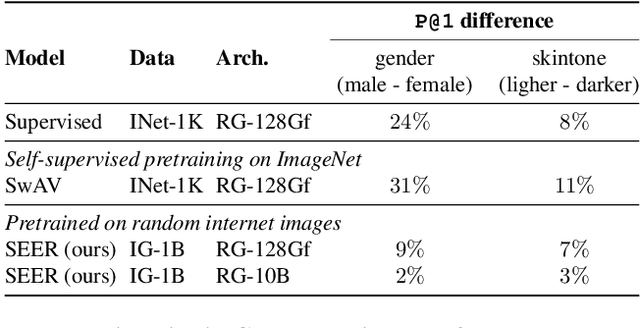
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.
HIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022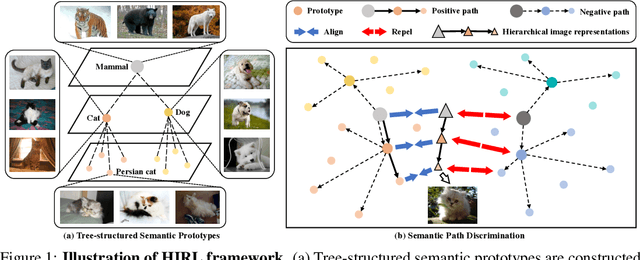
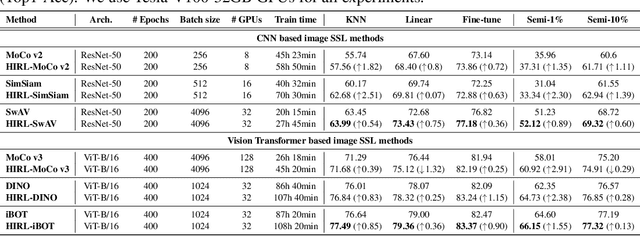


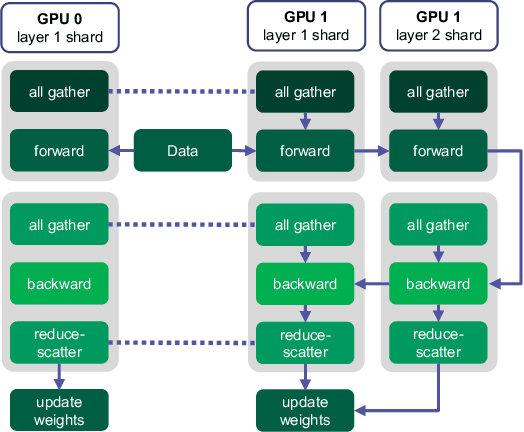
Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL
Textual Stylistic Variation: Choices, Genres and Individuals
May 01, 2022

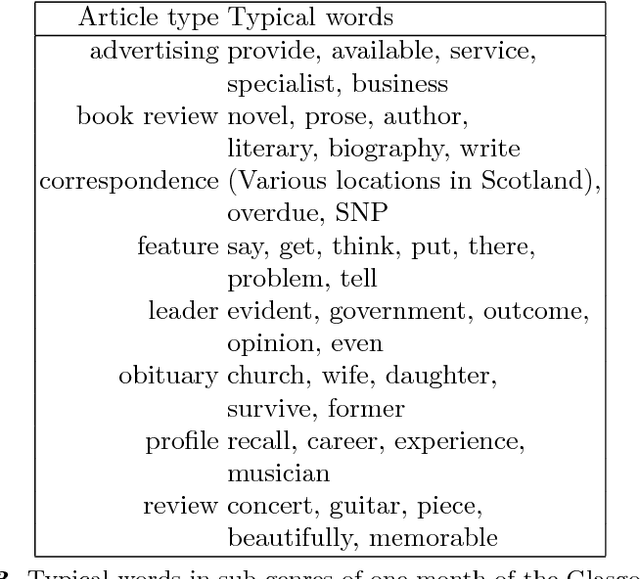

This chapter argues for more informed target metrics for the statistical processing of stylistic variation in text collections. Much as operationalised relevance proved a useful goal to strive for in information retrieval, research in textual stylistics, whether application oriented or philologically inclined, needs goals formulated in terms of pertinence, relevance, and utility - notions that agree with reader experience of text. Differences readers are aware of are mostly based on utility - not on textual characteristics per se. Mostly, readers report stylistic differences in terms of genres. Genres, while vague and undefined, are well-established and talked about: very early on, readers learn to distinguish genres. This chapter discusses variation given by genre, and contrasts it to variation occasioned by individual choice.
Adversarial Training Reduces Information and Improves Transferability
Aug 21, 2020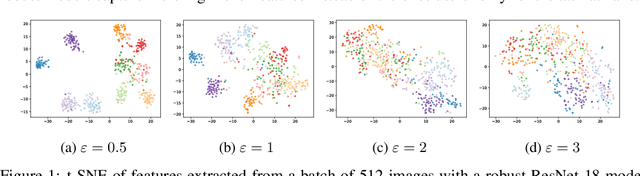
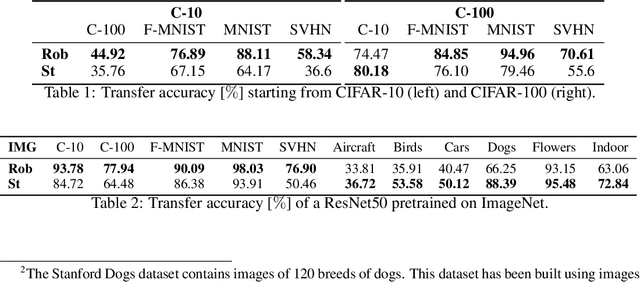
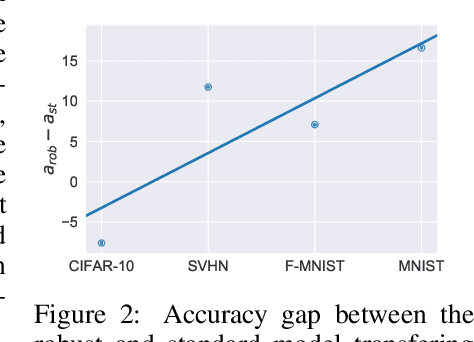
Recent results show that features of adversarially trained networks for classification, in addition to being robust, enable desirable properties such as invertibility. The latter property may seem counter-intuitive as it is widely accepted by the community that classification models should only capture the minimal information (features) required for the task. Motivated by this discrepancy, we investigate the dual relationship between Adversarial Training and Information Theory. We show that the Adversarial Training can improve linear transferability to new tasks, from which arises a new trade-off between transferability of representations and accuracy on the source task. We validate our results employing robust networks trained on CIFAR-10, CIFAR-100 and ImageNet on several datasets. Moreover, we show that Adversarial Training reduces Fisher information of representations about the input and of the weights about the task, and we provide a theoretical argument which explains the invertibility of deterministic networks without violating the principle of minimality. Finally, we leverage our theoretical insights to remarkably improve the quality of reconstructed images through inversion.
Monitoring of Perception Systems: Deterministic, Probabilistic, and Learning-based Fault Detection and Identification
May 22, 2022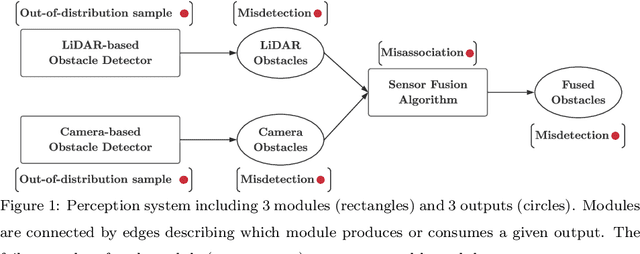
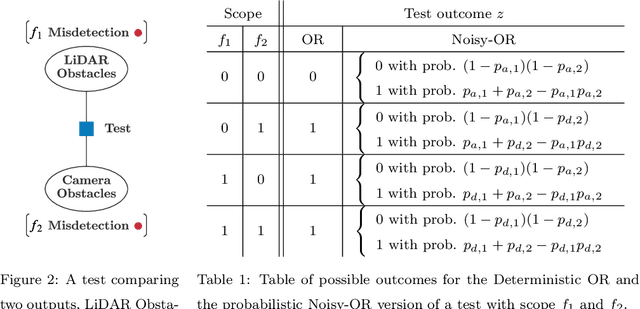

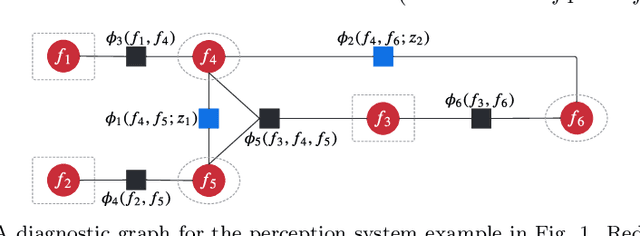
This paper investigates runtime monitoring of perception systems. Perception is a critical component of high-integrity applications of robotics and autonomous systems, such as self-driving cars. In these applications, failure of perception systems may put human life at risk, and a broad adoption of these technologies requires the development of methodologies to guarantee and monitor safe operation. Despite the paramount importance of perception, currently there is no formal approach for system-level perception monitoring. In this paper, we formalize the problem of runtime fault detection and identification in perception systems and present a framework to model diagnostic information using a diagnostic graph. We then provide a set of deterministic, probabilistic, and learning-based algorithms that use diagnostic graphs to perform fault detection and identification. Moreover, we investigate fundamental limits and provide deterministic and probabilistic guarantees on the fault detection and identification results. We conclude the paper with an extensive experimental evaluation, which recreates several realistic failure modes in the LGSVL open-source autonomous driving simulator, and applies the proposed system monitors to a state-of-the-art autonomous driving software stack (Baidu's Apollo Auto). The results show that the proposed system monitors outperform baselines, have the potential of preventing accidents in realistic autonomous driving scenarios, and incur a negligible computational overhead.
Constructing dynamic residential energy lifestyles using Latent Dirichlet Allocation
Apr 22, 2022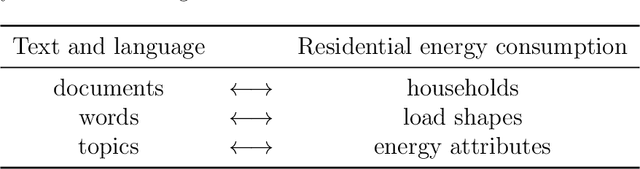
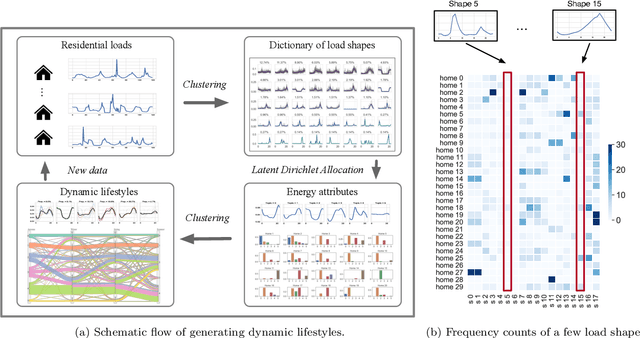
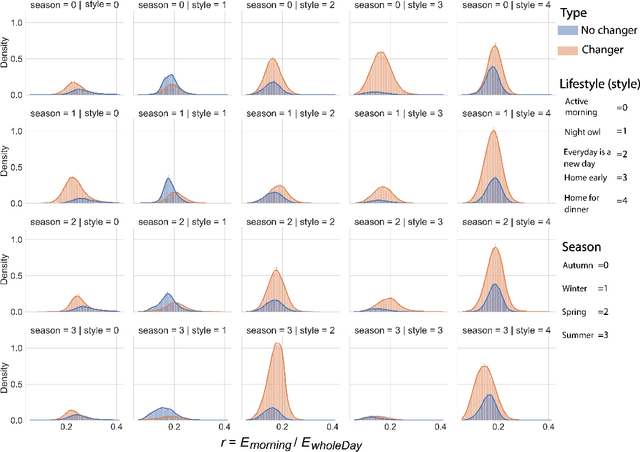
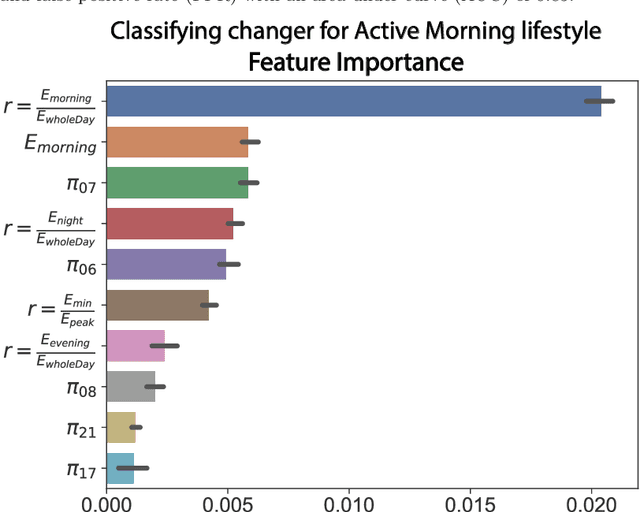
The rapid expansion of Advanced Meter Infrastructure (AMI) has dramatically altered the energy information landscape. However, our ability to use this information to generate actionable insights about residential electricity demand remains limited. In this research, we propose and test a new framework for understanding residential electricity demand by using a dynamic energy lifestyles approach that is iterative and highly extensible. To obtain energy lifestyles, we develop a novel approach that applies Latent Dirichlet Allocation (LDA), a method commonly used for inferring the latent topical structure of text data, to extract a series of latent household energy attributes. By doing so, we provide a new perspective on household electricity consumption where each household is characterized by a mixture of energy attributes that form the building blocks for identifying a sparse collection of energy lifestyles. We examine this approach by running experiments on one year of hourly smart meter data from 60,000 households and we extract six energy attributes that describe general daily use patterns. We then use clustering techniques to derive six distinct energy lifestyle profiles from energy attribute proportions. Our lifestyle approach is also flexible to varying time interval lengths, and we test our lifestyle approach seasonally (Autumn, Winter, Spring, and Summer) to track energy lifestyle dynamics within and across households and find that around 73% of households manifest multiple lifestyles across a year. These energy lifestyles are then compared to different energy use characteristics, and we discuss their practical applications for demand response program design and lifestyle change analysis.