 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor
Jun 01, 2022
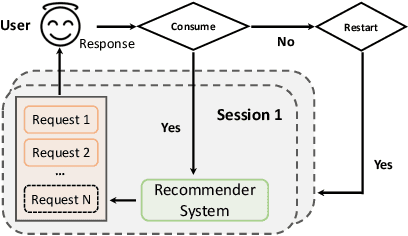
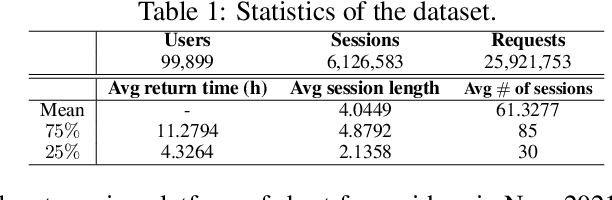
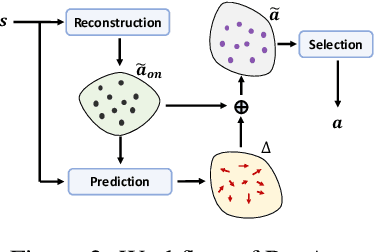
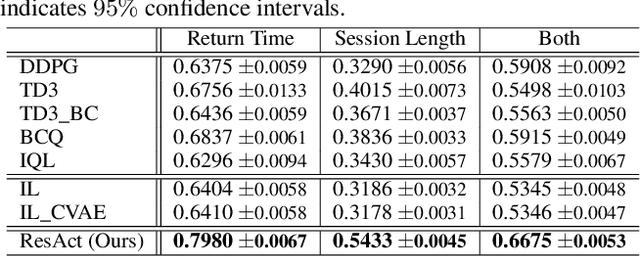
Long-term engagement is preferred over immediate engagement in sequential recommendation as it directly affects product operational metrics such as daily active users (DAUs) and dwell time. Meanwhile, reinforcement learning (RL) is widely regarded as a promising framework for optimizing long-term engagement in sequential recommendation. However, due to expensive online interactions, it is very difficult for RL algorithms to perform state-action value estimation, exploration and feature extraction when optimizing long-term engagement. In this paper, we propose ResAct which seeks a policy that is close to, but better than, the online-serving policy. In this way, we can collect sufficient data near the learned policy so that state-action values can be properly estimated, and there is no need to perform online exploration. Directly optimizing this policy is difficult due to the huge policy space. ResAct instead solves it by first reconstructing the online behaviors and then improving it. Our main contributions are fourfold. First, we design a generative model which reconstructs behaviors of the online-serving policy by sampling multiple action estimators. Second, we design an effective learning paradigm to train the residual actor which can output the residual for action improvement. Third, we facilitate the extraction of features with two information theoretical regularizers to confirm the expressiveness and conciseness of features. Fourth, we conduct extensive experiments on a real world dataset consisting of millions of sessions, and our method significantly outperforms the state-of-the-art baselines in various of long term engagement optimization tasks.
DSGN++: Exploiting Visual-Spatial Relation for Stereo-based 3D Detectors
Apr 09, 2022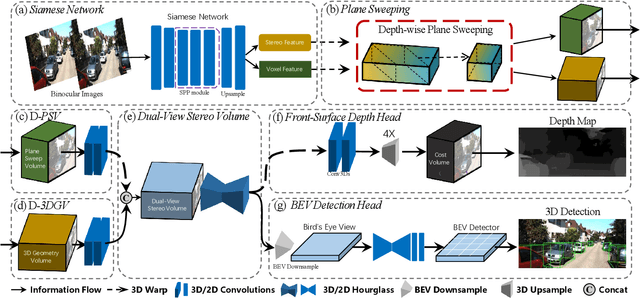
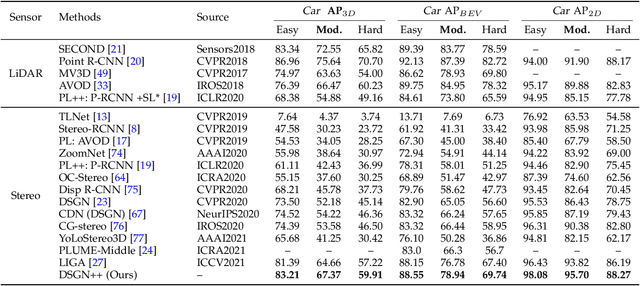
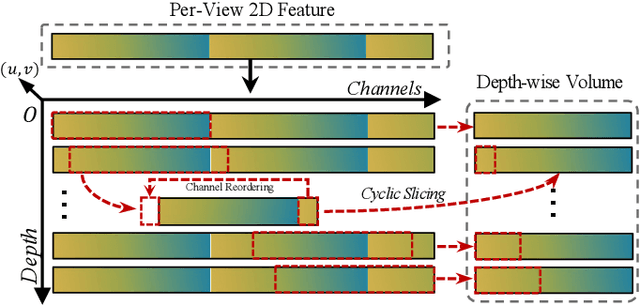
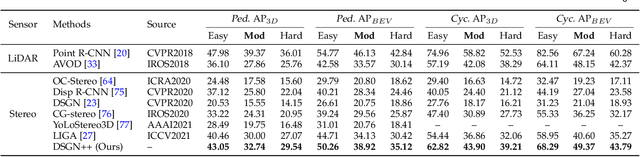
Camera-based 3D object detectors are welcome due to their wider deployment and lower price than LiDAR sensors. We revisit the prior stereo modeling DSGN about the stereo volume constructions for representing both 3D geometry and semantics. We polish the stereo modeling and propose our approach, DSGN++, aiming for improving information flow throughout the 2D-to-3D pipeline in the following three main aspects. First, to effectively lift the 2D information to stereo volume, we propose depth-wise plane sweeping (DPS) that allows denser connections and extracts depth-guided features. Second, for better grasping differently spaced features, we present a novel stereo volume -- Dual-view Stereo Volume (DSV) that integrates front-view and top-view features and reconstructs sub-voxel depth in the camera frustum. Third, as the foreground region becomes less dominant in 3D space, we firstly propose a multi-modal data editing strategy -- Stereo-LiDAR Copy-Paste, which ensures cross-modal alignment and improves data efficiency. Without bells and whistles, extensive experiments in various modality setups on the popular KITTI benchmark show that our method consistently outperforms other camera-based 3D detectors for all categories. Code will be released at https://github.com/chenyilun95/DSGN2.
Multiscale Convolutional Transformer with Center Mask Pretraining for Hyperspectral Image Classificationtion
Mar 09, 2022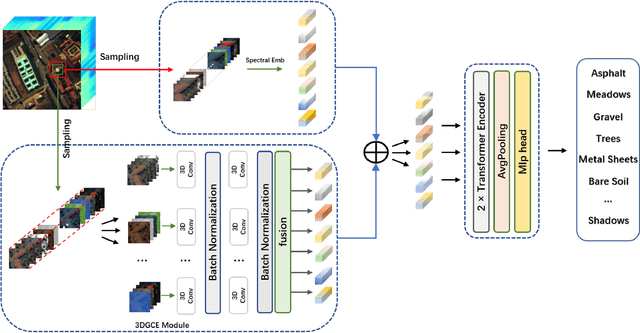
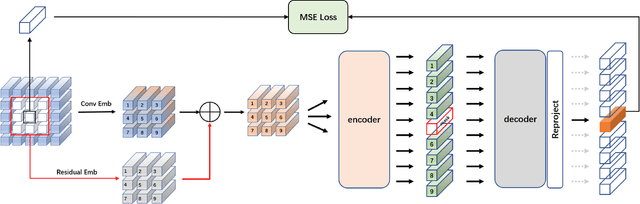
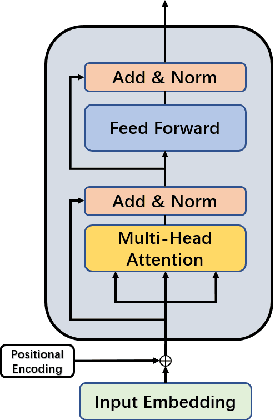
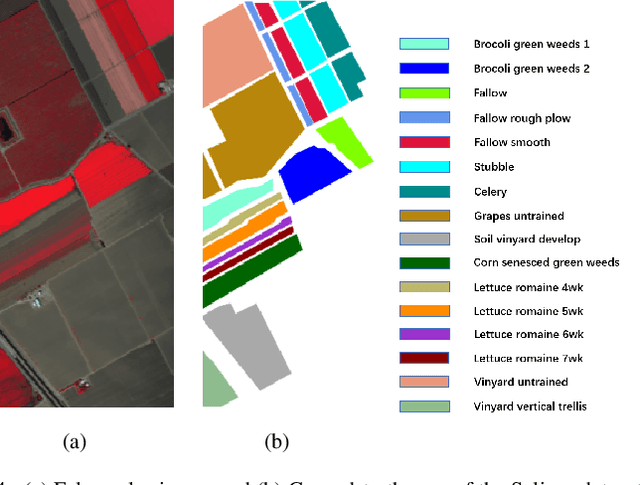
Hyperspectral images (HSI) not only have a broad macroscopic field of view but also contain rich spectral information, and the types of surface objects can be identified through spectral information, which is one of the main applications in hyperspectral image related research.In recent years, more and more deep learning methods have been proposed, among which convolutional neural networks (CNN) are the most influential. However, CNN-based methods are difficult to capture long-range dependencies, and also require a large amount of labeled data for model training.Besides, most of the self-supervised training methods in the field of HSI classification are based on the reconstruction of input samples, and it is difficult to achieve effective use of unlabeled samples. To address the shortcomings of CNN networks, we propose a noval multi-scale convolutional embedding module for HSI to realize effective extraction of spatial-spectral information, which can be better combined with Transformer network.In order to make more efficient use of unlabeled data, we propose a new self-supervised pretask. Similar to Mask autoencoder, but our pre-training method only masks the corresponding token of the central pixel in the encoder, and inputs the remaining token into the decoder to reconstruct the spectral information of the central pixel.Such a pretask can better model the relationship between the central feature and the domain feature, and obtain more stable training results.
MTLDesc: Looking Wider to Describe Better
Mar 14, 2022
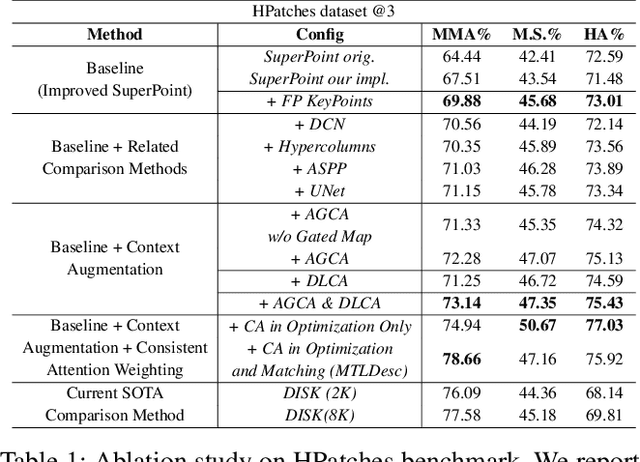
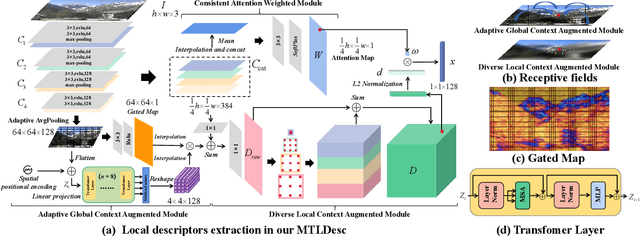
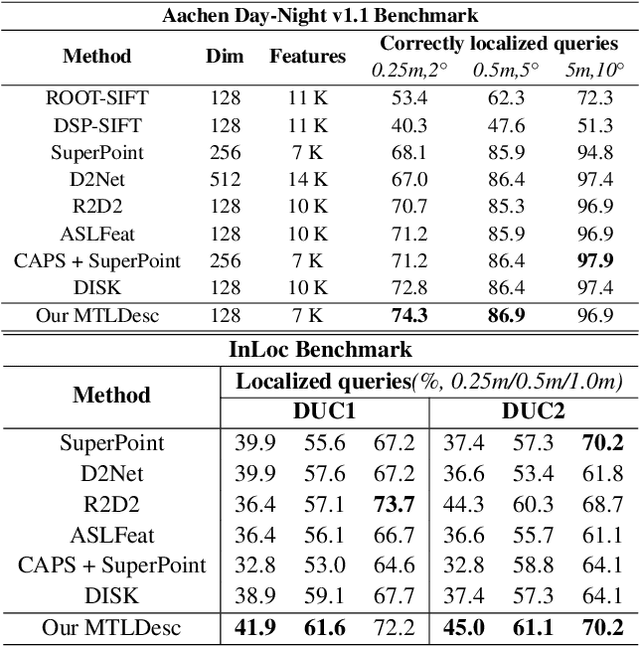
Limited by the locality of convolutional neural networks, most existing local features description methods only learn local descriptors with local information and lack awareness of global and surrounding spatial context. In this work, we focus on making local descriptors "look wider to describe better" by learning local Descriptors with More Than just Local information (MTLDesc). Specifically, we resort to context augmentation and spatial attention mechanisms to make our MTLDesc obtain non-local awareness. First, Adaptive Global Context Augmented Module and Diverse Local Context Augmented Module are proposed to construct robust local descriptors with context information from global to local. Second, Consistent Attention Weighted Triplet Loss is designed to integrate spatial attention awareness into both optimization and matching stages of local descriptors learning. Third, Local Features Detection with Feature Pyramid is given to obtain more stable and accurate keypoints localization. With the above innovations, the performance of our MTLDesc significantly surpasses the prior state-of-the-art local descriptors on HPatches, Aachen Day-Night localization and InLoc indoor localization benchmarks.
Visual Knowledge Discovery with Artificial Intelligence: Challenges and Future Directions
May 04, 2022
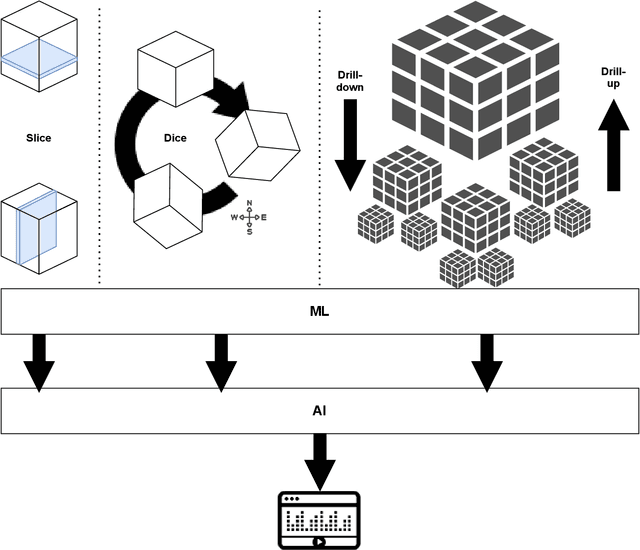
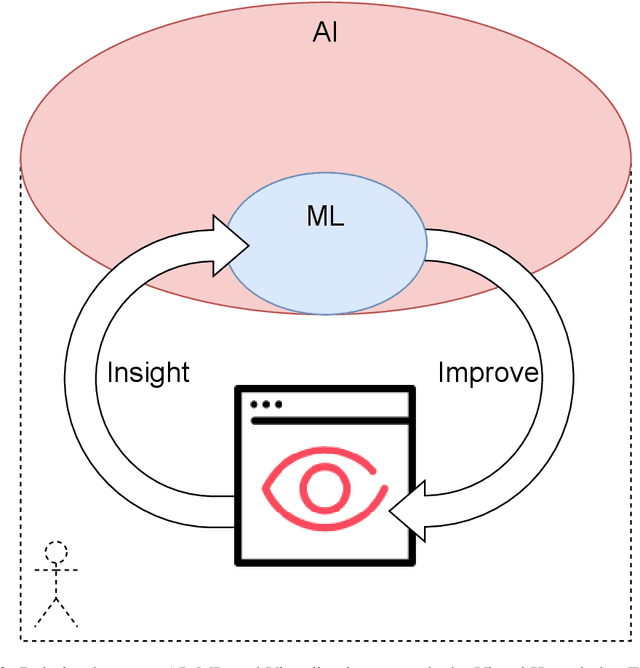
This volume is devoted to the emerging field of Integrated Visual Knowledge Discovery that combines advances in Artificial Intelligence/Machine Learning (AI/ML) and Visualization/Visual Analytics. Chapters included are extended versions of the selected AI and Visual Analytics papers and related symposia at the recent International Information Visualization Conferences (IV2019 and IV2020). AI/ML face a long-standing challenge of explaining models to humans. Models explanation is fundamentally human activity, not only an algorithmic one. In this chapter we aim to present challenges and future directions within the field of Visual Analytics, Visual Knowledge Discovery and AI/ML, and to discuss the role of visualization in visual AI/ML. In addition, we describe progress in emerging Full 2D ML, natural language processing, and AI/ML in multidimensional data aided by visual means.
HIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022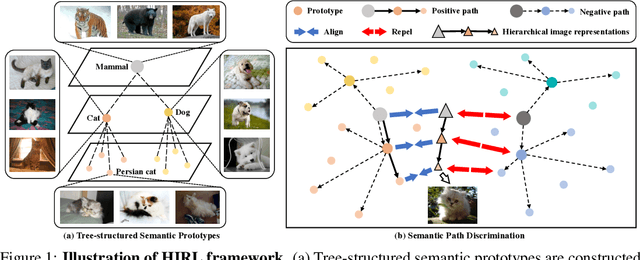
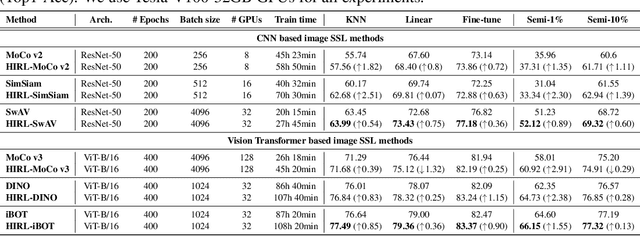


Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL
Edge Data Based Trailer Inception Probabilistic Matrix Factorization for Context-Aware Movie Recommendation
Feb 16, 2022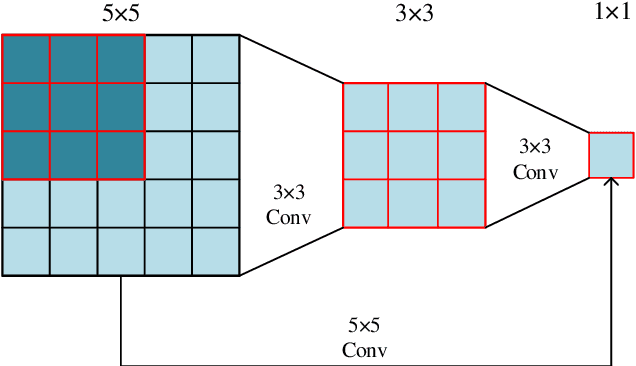

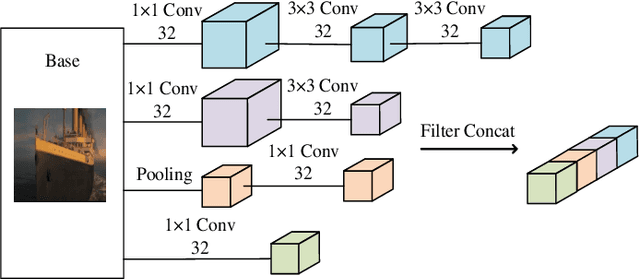
The rapid growth of edge data generated by mobile devices and applications deployed at the edge of the network has exacerbated the problem of information overload. As an effective way to alleviate information overload, recommender system can improve the quality of various services by adding application data generated by users on edge devices, such as visual and textual information, on the basis of sparse rating data. The visual information in the movie trailer is a significant part of the movie recommender system. However, due to the complexity of visual information extraction, data sparsity cannot be remarkably alleviated by merely using the rough visual features to improve the rating prediction accuracy. Fortunately, the convolutional neural network can be used to extract the visual features precisely. Therefore, the end-to-end neural image caption (NIC) model can be utilized to obtain the textual information describing the visual features of movie trailers. This paper proposes a trailer inception probabilistic matrix factorization model called Ti-PMF, which combines NIC, recurrent convolutional neural network, and probabilistic matrix factorization models as the rating prediction model. We implement the proposed Ti-PMF model with extensive experiments on three real-world datasets to validate its effectiveness. The experimental results illustrate that the proposed Ti-PMF outperforms the existing ones.
SSCU-Net: Spatial-Spectral Collaborative Unmixing Network for Hyperspectral Images
Mar 12, 2022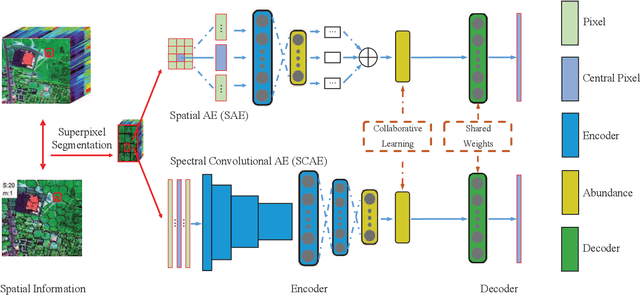
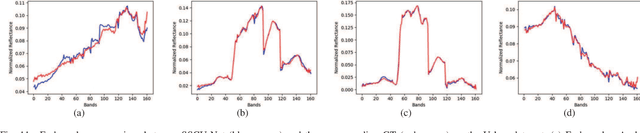
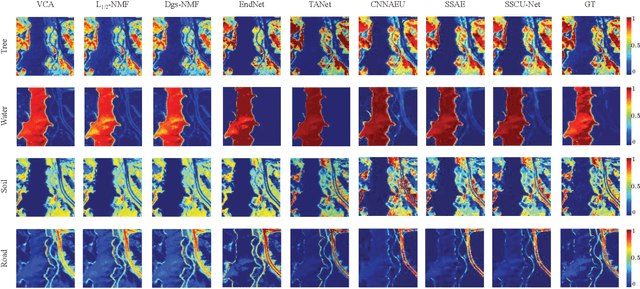
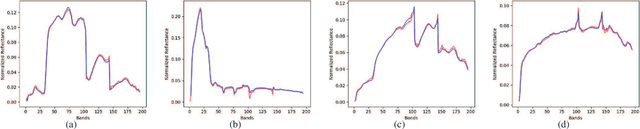
Linear spectral unmixing is an essential technique in hyperspectral image processing and interpretation. In recent years, deep learning-based approaches have shown great promise in hyperspectral unmixing, in particular, unsupervised unmixing methods based on autoencoder networks are a recent trend. The autoencoder model, which automatically learns low-dimensional representations (abundances) and reconstructs data with their corresponding bases (endmembers), has achieved superior performance in hyperspectral unmixing. In this article, we explore the effective utilization of spatial and spectral information in autoencoder-based unmixing networks. Important findings on the use of spatial and spectral information in the autoencoder framework are discussed. Inspired by these findings, we propose a spatial-spectral collaborative unmixing network, called SSCU-Net, which learns a spatial autoencoder network and a spectral autoencoder network in an end-to-end manner to more effectively improve the unmixing performance. SSCU-Net is a two-stream deep network and shares an alternating architecture, where the two autoencoder networks are efficiently trained in a collaborative way for estimation of endmembers and abundances. Meanwhile, we propose a new spatial autoencoder network by introducing a superpixel segmentation method based on abundance information, which greatly facilitates the employment of spatial information and improves the accuracy of unmixing network. Moreover, extensive ablation studies are carried out to investigate the performance gain of SSCU-Net. Experimental results on both synthetic and real hyperspectral data sets illustrate the effectiveness and competitiveness of the proposed SSCU-Net compared with several state-of-the-art hyperspectral unmixing methods.
The RATTLE Motion Planning Algorithm for Robust Online Parametric Model Improvement with On-Orbit Validation
Mar 03, 2022
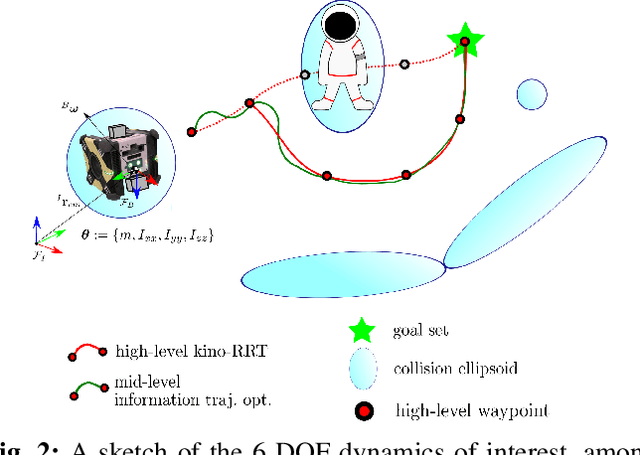
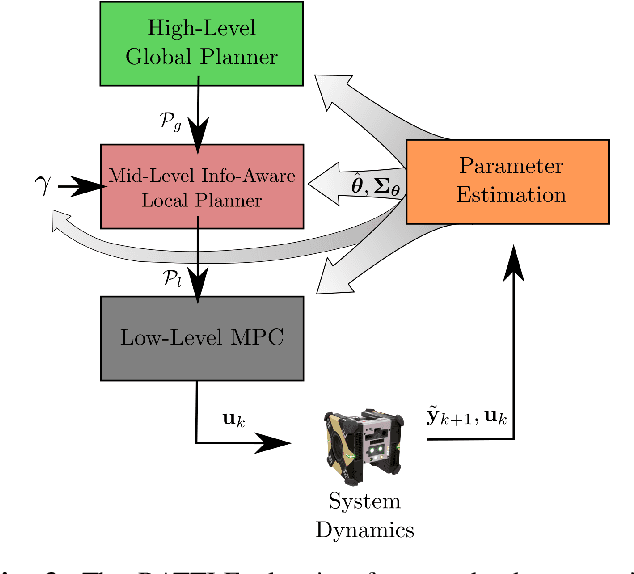
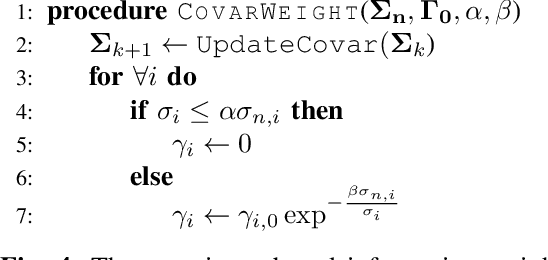
Certain forms of uncertainty that robotic systems encounter can be explicitly learned within the context of a known model, like parametric model uncertainties such as mass and moments of inertia. Quantifying such parametric uncertainty is important for more accurate prediction of the system behavior, leading to safe and precise task execution. In tandem, providing a form of robustness guarantee against prevailing uncertainty levels like environmental disturbances and current model knowledge is also desirable. To that end, the authors' previously proposed RATTLE algorithm, a framework for online information-aware motion planning, is outlined and extended to enhance its applicability to real robotic systems. RATTLE provides a clear tradeoff between information-seeking motion and traditional goal-achieving motion and features online-updateable models. Additionally, online-updateable low level control robustness guarantees and a new method for automatic adjustment of information content down to a specified estimation precision is proposed. Results of extensive experimentation in microgravity using the Astrobee robots aboard the International Space Station and practical implementation details are presented, demonstrating RATTLE's capabilities for real-time, robust, online-updateable, and model information-seeking motion planning capabilities under parametric uncertainty.
CABACE: Injecting Character Sequence Information and Domain Knowledge for Enhanced Acronym and Long-Form Extraction
Dec 25, 2021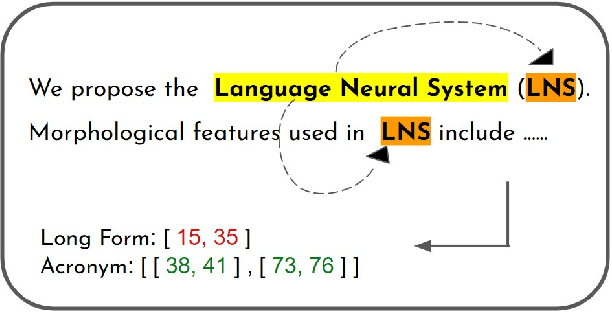
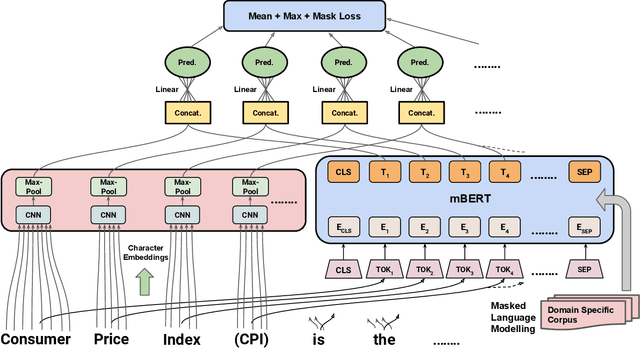
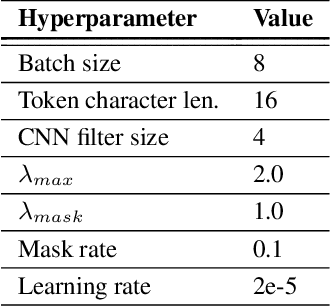
Acronyms and long-forms are commonly found in research documents, more so in documents from scientific and legal domains. Many acronyms used in such documents are domain-specific and are very rarely found in normal text corpora. Owing to this, transformer-based NLP models often detect OOV (Out of Vocabulary) for acronym tokens, especially for non-English languages, and their performance suffers while linking acronyms to their long forms during extraction. Moreover, pretrained transformer models like BERT are not specialized to handle scientific and legal documents. With these points being the overarching motivation behind this work, we propose a novel framework CABACE: Character-Aware BERT for ACronym Extraction, which takes into account character sequences in text and is adapted to scientific and legal domains by masked language modelling. We further use an objective with an augmented loss function, adding the max loss and mask loss terms to the standard cross-entropy loss for training CABACE. We further leverage pseudo labelling and adversarial data generation to improve the generalizability of the framework. Experimental results prove the superiority of the proposed framework in comparison to various baselines. Additionally, we show that the proposed framework is better suited than baseline models for zero-shot generalization to non-English languages, thus reinforcing the effectiveness of our approach. Our team BacKGProp secured the highest scores on the French dataset, second-highest on Danish and Vietnamese, and third-highest in the English-Legal dataset on the global leaderboard for the acronym extraction (AE) shared task at SDU AAAI-22.